2023美赛各题分析,2024美赛数学建模思路解析2.2日第一时间更新
目录
2024美赛数学建模各题思路模型代码:开赛后第一时间更新,更新见文末
一、2023题目重述
拟解决的问题
我们的工作:
二、模型和计算
1.数据预处理
2.报告数量区间预测模型
3.猜词结果分布预测模型
2024美赛数学建模交流,历年获奖论文获取
2024美赛数学建模各题思路模型代码:开赛后第一时间更新,更新见文末
一、2023题目重述
Homer是棒球运动中的术语,是非正式的美式英语单词。令人惊讶的是,Homer(本垒打)在剑桥词典网站的搜索次数超过79000次,在5月5日这一天内被搜索65401次。就这样,Homer成为《剑桥词典》的2022年度词汇。可能你会好奇其中的原因,这就要从海外非常火的一款猜词游戏Wordle说起了。在2022年,在线益智游戏Wordle在社交媒体刷屏。而Wordle那天的答案是Homer,这难倒了不熟悉这个单词的非美国用户。
Wordle是目前《纽约时报》每日提供的一个热门谜题。Wordle的受欢迎程度不断提高,目前已有60多种语言版本。玩家可以选择的模式有“常规模式”或"困难模式"。玩家试图在六次或更少的尝试中猜测一个五字词来解决这个难题,每次猜测都会得到反馈,方块的颜色会发生变化(绿色、黄色、灰色)。注意:每个猜测都必须是英语中的一个实词。不被比赛认可为文字的猜测是不被允许的。
拟解决的问题
开发一个模型来解释报道结果的数量变化,并创建2023年3月1日报告结果的数量预测区间。分析单词的属性对玩家的模式选择的影响程度。
开发一个模型来预测报告结果的分布。分析模型和预测存在的不确定性因素。
开发一个模型来分类解答词难度。识别与每个分类相关联单词的属性。
描述数据集的其他有趣特征。
(大致能看出来,三个问题,最后一个语文建模。后来我们发现把前三个问踩过的坑扔到第四问,就够了。)
我们的工作:
我们共提出了三个模型来挖掘报告结果数据的信息。
本文的其余部分组织如下。第二部分介绍了本文的前提假设与合理解释。第三节提及了文中使用的公式中的常用变量。第四节进行了建模前对的数据预处理工作。第五节建立了报告数量区间预测模型,并探索了单词属性与模式选择的关系。第六节建立了报告结果分布预测模型。第七节建立了词汇难度分类模型。第八节继续探索数据集的有趣特征。第九节和第十节分别对模型的灵敏度进行分析,进一步评估模型的优缺点。最后,第十一节给出了结论。
二、模型和计算
1.数据预处理
这套数据有几个词不是五个字母,但因为都是发生过的统计,我们直接翻到了过去这些期词汇的统计修改了一下。还有529号study的结果目测就有问题,我们取前后几天的均值修正了一下。这里怎么处理问题都不大。
2.报告数量区间预测模型
**我们希望在已有数据的基础上建立一种数学模型,用于描述Twitter上报告结果数量随时间变化的过程和预测未来一定时间内的热度,且模型对于变化过程具有解释性。该问题是近年来常受到讨论的热度预测问题。
通过查阅文献[4],我们得知业界目前两类常用的热度预测算法,包括基于节点行为动力学的时序模型和深度学习类方法。但是它们并不适用于本文所研究的情形。主要因为如下两个原因:
现有数据集中并不包含报告人是谁、所有时间内总共有多少人等具体信息,基于该数据集无法建立节点模型;
深度学习等技术不具有良好的可解释性,并且大都需要更多的训练数据才能达到较好的预测效果。
因此,我们从统计学角度出发,基于非齐次泊松过程和3阶高斯回归(3rd-order gaussian regression)建立了wordle报告数量预测模型。**
(这一问从建立模型到计算求解我几乎全程没参与,因为我没学过信息论,从这个模型提出开始我就不懂了。我贴一些原文的内容和记忆中当时的一些处理办法。)
一眼需要时间预测模型。当时建模队友恰好在复习信息论(和开学考期末和解),这个趋势画出来特别像对数正态分布的曲线。刚开始的时候上涨很快,后期逐渐下降,最后能剩下的都是坚持在玩的老玩家。当时建模哥觉得这个很符合实际,并且会挺新颖的,就顺着这个研究下去了。后来发现有地方解释不了,报告数量的分布在时间上并非均匀的,而对数正态分布没有考虑时间因素。卡在这里很久,一度考虑过要不要换一个预测模型。后来还是顺着拟合的路走下去了。
基于高斯回归的趋势预测模型
在本数据集中,报告数量的时间序列存在明显的趋势迹象。我们尝试了多种回归算法对报告数量随时间的变化趋势进行拟合,其中效果最好的是3阶高斯回归。
(如果我没记错,这个是从matlab的cftool里挨个试出来的。就是简单的拟合了一下,我们也没有做过多的说明)
然后考虑预测区间,也就是每天的随机波动。
基于非齐次泊松过程的报告数量预测模型
泊松分布描述了在事件发生速率为常数的条件下,一段时间内一定数量事件发生的概率,因此可以描述一天内上传的一定数量的报告的概率。我们假设每一天的报告数量均服从于泊松分布,则这些泊松分布在时间上组成了一个非齐次泊松过程,即到达强度随时间变化的泊松过程。
真的按照这个公式来计算区间,会发现预测的效果没有那么理想。后期较为平稳的部分有一些地方反倒波动比较大,出现非常离谱的尖刺。为了消掉后期区间的尖刺,需要进行一定的比例放缩,也就是基于热度松弛函数的随机过程修正部分。这部分先找到了一个可以消掉尖刺的函数,然后根据这个函数去找适合它的定义,还真找到了这个热度松弛现象。
(我个人觉得这一问模型套模型的解法,整个论文写下来,松弛函数这里显得很秀。其实只是为了得到一个比较好看的预测结果凑出来的罢了)
最后我们预测出来的大致是这样。上面松弛函数乘进去直接让前面的预测区间更大,后面的更小。看起来就跟实际比较像了。
(其实这个结果得出来的特别波折,但是论文写出来的逻辑相当流畅,把解释不了的地方避重就轻的一带而过,能解释出来的部分狠狠夸了一波。展现出来的就是这种,很厉害但又有点云里雾里的感觉。)
分析单词的属性对玩家困难模式选择的影响程度这里,我们把能想到的所有属性都列了一遍。画出来散点图发现除了时间以外都没什么关系。然后就大胆写上了,也没去刻意寻找什么关系。
3.猜词结果分布预测模型
为了预测未来报告结果的分布,我们首先对数据特征进行了提取与构建。接着,我们搭建BP神经网络模型,将7个数据特征作为输入,输出7种猜词结果的分布。最后,采取Bagging算法对多个BP神经网络进行集成,通过硬投票机制得出最终预测结果,降低预测结果的泛化误差。
(第一问的模型还没建的时候,建模哥就跟我说,这个数据量太适合BP神经网络了。于是他在那边想办法搞定上一问,我在这边炼丹。)
后来引入背包算法的原因是不管怎么调,单个神经网络输出的准确率,都只有40%不到。看起来很离谱,于是我们抓出来几次跑出来的结果,发现预测不准的词汇相对来说并不固定,也就是说纯纯是这个词本身的问题,而不是变量抓的不准。
于是建模哥提出来投票,一个网络预测不准就让一堆网络一起预测。
让100个神经网络投票以后,误差依旧不太小,但没之前那么离谱了。
还有一个小细节就是,我们的训练集和测试集不是纯随机选的,而是固定的前85%的数据作为总训练集。相当于用完全相同的数据训练出不同的网络。这样比随机抽的训练集误差更小一些。
其实最后结果也不是相当理想,所以我们把每一个词汇的每一个猜词次数预测误差的分布具体拆开统计,大部分误差其实都不大。最后得出来的结论是”我们对预测结果绝对误差不超过5%有80%以上的信心”。这写完以后我们仨都乐了,确实不太像人话。但要是直接说绝对误差不超过20%那也显得我们做的太拉胯了。
最后这个ERRIE的结果分布,我们仗着神经网络不可能完全复现,预测了10次左右,找最接近的几个值取了个平均。按照误差的统计分布来看,这样基本拿到的结果就是准的了。
3.词汇难度分类模型
为了能对solution words进行合理的分类,我们首先根据用户的猜词次数分布并基于K-Means聚类算法对难度进行划分。接着,我们基于Pearson相关系数来探索单词属性与难度划分的关联,构建了单词难度分类模型。最后,按照此关联性对新的单词进行难度分类。
我们做到这一问的时候,已经是最后一个中午了,而且深度学习的结果刚出来,还没有写文章。前面做的确实慢了一些。
刚开始我们也受了网上各种言论和b站那个大神的信息熵预测视频的影响,本来打算用信息熵。当时我还开玩笑说,这题纯纯给你们通信人出的。最开始我们捋出来一套解法,拿动态规划进行的步骤模拟。
单词的不确定度来自于字母的不确定度和位置的不确定度。如果我们拿到绿色方框,就可以一次性消除掉该位置和该字母的所有不确定性;如果拿到黄色方框,可以消除掉字母的不确定性,只剩位置的不确定性;如果拿到灰色方框,则某个字母一定不会存在,也可以消除掉一些不确定性。用动态规划的思想迭代,最后拿到每次预测的难度。
大概是这么个想法,后来没用这个的原因,一个是太难了,最后一个晚上了,程序都不一定能写完,更别说论文;另一个原因是建模哥说的,他说始终感觉,C题是对数据的处理,而不是对过程的追踪(大概是这个意思)。动态规划这种解法不像是用在这道题的。
其实当时我们觉得前两问的模型都很low,一心想在第三问整个花活。确实也纠结了一下要不要用聚类分类,总感觉太平庸了。最后还是选择了相信建模哥的直觉,用的最简单的kmeans。
难度直接反映在猜词次数上,于是我们通过猜词次数得到了四个聚类。聚类这样做没问题,分类用什么向量的问题上我们也纠结过。我倾向于直接使用上一问预测的分布次数进行分类,还能反过来证明第二问算出来的结果是对的;建模哥觉得这个不是单词的本质属性,只是外部表现而已,应该用单词的属性来分类。
最后,用相关系数把属性和猜词次数联系起来,然后用属性分类。
对于未来的solution word而言,我们可以通过计算它与各个典型样本的相似度判断其难度。由于我们在第6.2节中建立了对未来日期给定solution word的猜词次数分布预测模型,所以我们对于词汇难度有两种判断依据。一种是基于预测的猜词次数分布,一种是基于solution word的属性向量 。
(其实单纯从得到的结果看,直接用猜词次数分类的结果比这个要好一些,但少一个Pearson系数模型,而且变量不是单词本身属性这一点,大概可能描述起来会有逻辑上的漏洞。)
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdf=pd.read_excel('Problem_C_Data_Wordle.xlsx',skiprows=1)
data=df[['Date','Number of reported results']]def secondaryExponentialSmoothingMethod(list, n_average, alpha,day): # 参数list为你要传入的时间序列,n_average表示数列两端取多少个数(要取奇数),alpha为平滑系数,day为向后预测的天数# 准备好解二元一次方程组的方法def fangChengZu(a1, b1, a2, b2, c1, c2):a = np.array([[a1, b1], [a2, b2]])b = np.array([c1, c2])x, y = np.linalg.solve(a, b)return x, y# 取数列两端各n_average个值加以平均list_left = list[0:n_average] # data中前n_average个值构成的listlist_right = list[n_average + 1:len(list)] # data中后n_average个值构成的listlist_left_average = np.mean(list_left) # list_left包含元素的均值list_right_average = np.mean(list_right)x1 = (n_average + 1) / 2x2 = (len(list) - x1) + 1# print(list_left_average,list_right_average)# 代入线性趋势方程,解出a1,b1a1, b1 = fangChengZu(1, x1, 1, x2, list_left_average, list_right_average)# print(a1,b1)# 代入公式(12),解出S11,S12S11, S12 = fangChengZu(2, -1, a1, b1, -b1, (alpha / (1 - alpha)))# print(S11,S12)a_tao = 0 # 初始化b_tao = 0for i in range(len(list)):S1 = alpha * list[i] + (1 - alpha) * S11S2 = alpha * S1 + (1 - alpha) * S12S11 = S1S12 = S2a_tao = 2 * S1 - S2b_tao = (alpha / (1 - alpha)) / (S1 - S2)H = a_tao + b_tao * day # 预测值return Hif __name__ == '__main__':data =data['Number of reported results'] # 时间序列prediction_day1 = secondaryExponentialSmoothingMethod(data, 3, 0.5, 1) #预测下一天prediction_day2 = secondaryExponentialSmoothingMethod(data, 3, 0.5, 53)#预测3.2号print(prediction_day2)plt.figure(figsize=(25, 7))
plt.plot(data,color='b', label='Original')
plt.plot(414,prediction_day2,color='c', label='Predict',marker='+')
plt.show()相关文章:

2023美赛各题分析,2024美赛数学建模思路解析2.2日第一时间更新
目录 2024美赛数学建模各题思路模型代码:开赛后第一时间更新,更新见文末 一、2023题目重述 拟解决的问题 我们的工作: 二、模型和计算 1.数据预处理 2.报告数量区间预测模型 3.猜词结果分布预测模型 2024美赛数学建模交流࿰…...
分享一个学习git的网站
Learn Git Branching...

用户拉新的4大关键策略,照着做就对了!
今天给大家分享用户拉新的4个关键策略,掌握了这些策略,不仅有助于增加用户数量,还能让对方成为你忠实的粉丝。 1、制定明确的目标:在开始拉新之前,你需要明确自己的目标。你想要吸引什么样的用户?你希望他…...
如何用“VMware安装Ubuntu”win11系统?
一、 下载Ubuntu 企业开源和 Linux |Ubuntu的 二、 安装 三、 启动虚拟机 选中Try or Install Ubuntu Server,按回车...

ZJOI2009 对称的正方形
P2601 [ZJOI2009] 对称的正方形 题目大意 给定一个 n m n\times m nm的矩阵,求这个矩阵中满足上下对称且左右对称的正方形子矩阵的个数。 1 ≤ n , m ≤ 1000 1\leq n,m\leq 1000 1≤n,m≤1000 题解 首先,我们对原矩阵、左右翻转后的矩阵、上下翻转后…...
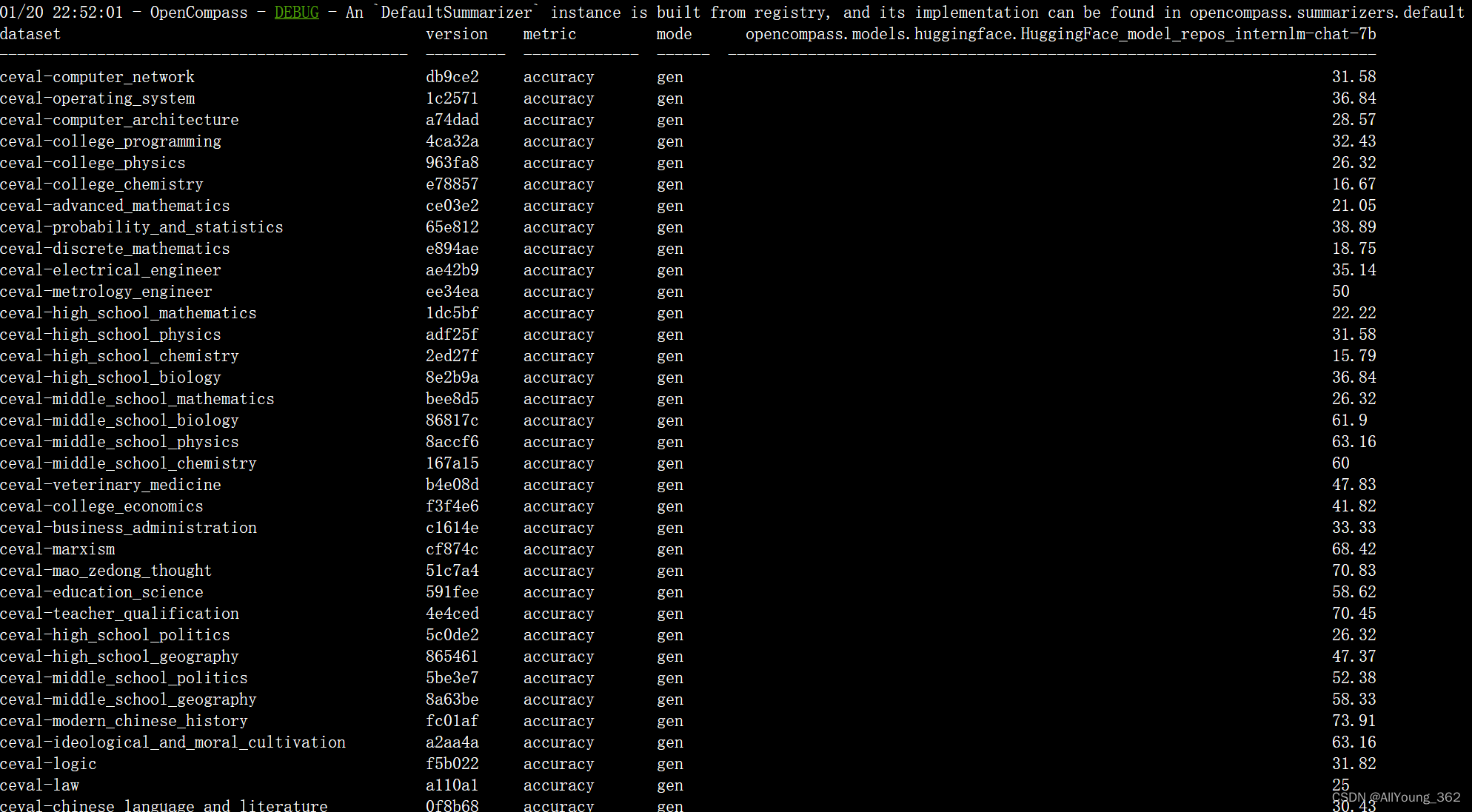
大模型学习与实践笔记(十一)
一、使用OpenCompass 对模型进行测评 1.环境安装: git clone https://github.com/open-compass/opencompass cd opencompass pip install -e . 当github超时无法访问时,可以在原命令基础上加上地址: https://mirror.ghproxy.com git clon…...
Elasticsearch+Kibana 学习记录
文章目录 安装Elasticsearch 安装Kibana 安装 Rest风格API操作索引基本概念示例创建索引查看索引删除索引映射配置(不配置好像也行、智能判断)新增数据随机生成ID自定义ID 修改数据删除数据 查询基本查询查询所有(match_all)匹配查…...

Cesium叠加超图二维服务、三维场景模型
前言 Cesium作为开源的库要加超图的服务则需要适配层去桥接超图与Cesium的数据格式。这个工作iClient系列已经做好,相比用过超图二维的道友们可以理解:要用Openlayer加载超图二维,那就用iClient for Openlayer库去加载;同样的要用…...

【低危】OpenSSL 拒绝服务漏洞
漏洞描述 OpenSSL 是广泛使用的开源加密库。 在 OpenSSL 3.0.0 到 3.0.12, 3.1.0 到 3.1.4 和 3.2.0 中 ,使用函数 EVP_PKEY_public_check() 来检查 RSA 公钥的应用程序可能会遇到长时间延迟。如果检查的密钥是从不可信任的来源获取的,这可能会导致拒绝…...

TDL-Tiny Synopsis-TED-ED 网络理论 Network Theory
Tiny Synopsis on TED-ED-Network Theory I) Webpage addressII)Context ExceptionIII) Diagram/Chart Research&Developement I) Webpage address URL Resource II)Context Exception what does “going viral” on Internet really mean? (网络…...

GIS项目实战08:JetBrains IntelliJ IDEA 2022 激活
为什么选择 IntelliJ IDEA 使用编码辅助功能更快地编写高质量代码,这些功能可在您键入时搜索可能的错误并提供改进建议,同时无缝地向您介绍编码、新语言功能等方面的社区最佳实践。 IntelliJ IDEA 了解您的代码,并利用这些知识通过在每种上…...
Linux 命令大全 CentOS常用运维命令
文章目录 1、Linux 目录结构2、解释目录3、命令详解3.1、shutdown命令3.1、文件目录管理命令ls 命令cd 命令pwd 命令tree 命令mkdir 命令touch 命令cat 命令cp 命令more 命令less 命令head 命令mv 命令rm 命令ln 命令tail 命令cut命令 3.2、用户管理useradd/userdel 命令用户的…...

6.3.5编辑视频
6.3.5编辑视频 除了上面的功能外,Camtasia4还能进行简单的视频编辑工作,如媒体的剪辑、连接、画中画等。 下面我们就利用Camtasia4的强大功能来实现一个画中画效果,在具体操作之前,需要准备好两个视频文件,一个作为主…...

同星多通道CAN FD转USB/WIFI设备,解决近距离无线通讯问题
新品发布/New products release 2024年1月,同星智能连续发布FlexRay系列产品TP1034和以太网系列产品TP1051,上周发布多通道总线记录仪产品TLog1004。1月19日,同星智能又推出一款2/4路CAN FD转USB和WIFI的工具,解决近距离无线通讯…...

wamp环境的组成
wamp环境介绍 简介 Wamp 就是 Windows Apache Mysql PHP集成安装环境,即在window下的apache、php和mysql的服务器软件。 w--windows Windows操作系统,是由美国微软公司(Microsoft)研发的操作系统,问世于1985年。起初…...
Idea 开发环境不断切换git代码分支导致冲掉别人代码
问题分析 使用git reflog查看执行命令,以下是发生事故的切换和提交动作 46f72622e1 HEAD{41}: commit: feat: 【Sales - 6.3】小程序端不登录也可以录入客户线索 c5e7d9f6e1 HEAD{42}: fetch origin feature/20240102_Sales6.3_xingang:feature/20240102_Sales6.3…...

GO 中如何防止 goroutine 泄露
文章目录 概述如何监控泄露一个简单的例子泄露情况分类chanel 引起的泄露发送不接收接收不发送nil channel真实的场景 传统同步机制MutexWaitGroup 总结参考资料 今天来简单谈谈,Go 如何防止 goroutine 泄露。 概述 Go 的并发模型与其他语言不同,虽说它…...

Linux练习题
1 简答题:请列举你所知道的Linux发行版 常见的Linux发行版: Red Hat Enterprise Linux 6/7/8 CentOS 6/7/8 Suse Linux Enterprise 15 Debian Linux 11 Ubuntu Linux 20.04/21.04 Rocky Linux 8/9 2 简答题:Linux系统的根目录、/dev目录的作用是什么 /:linux文件系统的…...
storm统计服务开启zookeeper、kafka 、Storm(sasl认证)
部署storm统计服务开启zookeeper、kafka 、Storm(sasl认证) 当前测试验证结果: 单独配置zookeeper 支持acl 设置用户和密码,在storm不修改代码情况下和kafka支持当kafka 开启ACL时,storm 和ccod模块不清楚配置用户和密…...

YOLOv8加入AIFI模块,附带项目源码链接
YOLOv8" 是一个新一代的对象检测框架,属于YOLO(You Only Look Once)系列的最新版本。YOLOv8中提及的AIFI(Attention-based Intrascale Feature Interaction)模块是一种用于增强对象检测性能的机制,它是…...

顶伯在线语音工具背后的技术力量:AI语音合成与深度学习解析
顶伯在线语音工具背后的技术力量在人工智能浪潮中,语音交互正成为人机沟通的核心方式。顶伯作为行业领先的在线语音工具,凭借自主研发的深度学习架构,将文字转化为高度自然的语音,广泛应用于有声阅读、智能客服、教育辅助等领域。…...

NVDC充电架构深度解析:智能电源管理如何提升笔记本性能与电池寿命
1. 项目概述:NVDC充电器,一个被低估的“能量管家”如果你是一位经常需要带着笔记本电脑移动办公的资深用户,或者是一位对设备续航和充电效率有极致追求的硬件爱好者,那么“NVDC”这个词,很可能已经或即将进入你的视野。…...

体验Taotoken分钟级接入与标准OpenAI协议的无缝切换
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken分钟级接入与标准OpenAI协议的无缝切换 对于已经熟悉OpenAI API的开发者而言,尝试新的模型服务通常意味着…...

如何用Inkscape实现专业级光学设计?终极免费光线追踪插件完整指南
如何用Inkscape实现专业级光学设计?终极免费光线追踪插件完整指南 【免费下载链接】inkscape-raytracing An extension for Inkscape that makes it easier to draw optical diagrams. 项目地址: https://gitcode.com/gh_mirrors/in/inkscape-raytracing 你…...

ARM ETM10硬件追踪系统设计与信号完整性优化
1. ARM ETM10硬件追踪系统设计精要在嵌入式系统开发领域,ARM ETM10(Embedded Trace Macrocell)作为一款高性能硬件追踪模块,为开发者提供了处理器指令和数据流的实时可视性。不同于软件调试工具,ETM10通过在芯片内部直…...

标签系统的底层同步拓扑:大批量客户标签异步更新的一致性方案
标签(Tag)是私域精细化运营的灵魂。在进行大规模广告投放、或者老客清洗时,企业系统经常需要同时为上万个外部客户批量追加或清空标签。 1. 标签同步的复杂性在哪里? 原生设计中,企业微信的标签是以“企业标签组&#…...

【LLM推理加速】Lookahead:无损加速新范式,如何用Trie树与多分支策略突破IO瓶颈
1. 为什么我们需要无损推理加速? 大语言模型在实际应用中面临的最大痛点之一就是推理速度慢。想象一下,当你向AI助手提问时,每次等待回复都要花上好几秒,这种体验有多糟糕。传统的加速方法比如量化(把模型参数从16位压…...

别再手动搬虚拟机了!手把手教你配置vSphere DRS集群,实现ESXi主机负载自动均衡
企业级虚拟化资源调度实战:vSphere DRS集群的智能配置与优化策略 虚拟化技术已成为现代企业IT基础设施的核心支柱,而资源的高效调度则是保障业务连续性和性能的关键。在传统虚拟化环境中,管理员往往需要手动监控主机负载并迁移虚拟机…...

告别论文 “双杀” 困局:okbiye 如何用一套闭环方案,破解重复率与 AIGC 检测双重难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 当你对着导师的红笔批注,第三次修改论文时,有没有想过一个问题:为什么你改了又改的句子,重…...

2026职场进阶:数据分析技能的价值与应用
一、数据分析在职场中的核心价值市场需求增长:2026年企业对数据驱动决策的需求持续上升,数据分析成为跨行业通用技能。薪资竞争力:掌握数据分析能力的人才平均薪资高于同岗位非技术背景从业者。职业扩展性:从运营、市场到产品经理…...