JAVA 学习 面试(五)IO篇
- BIO是阻塞I/O,NIO是非阻塞I/O,AIO是异步I/O。BIO每个连接对应一个线程,NIO多个连接共享少量线程,AIO允许应用程序异步地处理多个操作。
- NIO,通过Selector,只需要一个线程便可以管理多个客户端连接,当客户端数据到了之后,才会为其服务
- AIO是适合高吞吐量的应用程序,异步 IO 基于时间和回调机制实现的:也就是应用操作之后会直接返回,不会阻塞在那里,后台处理完成后,操作系统会通知相应的线程进行后续的操作。但AIO在Java中的支持相对有限,不是所有操作系统都支持。
JAVA BIO

服务端会有个ServerSocket,每一个ServerSocket都有一个与之对应ClientSocket,每一个连接都需要有一个线程来维护
JAVA NIO
1.Java NIO 全称 Java non-blocking IO,是指 JDK 提供的新 API。从 JDK1.4 开始,Java 提供了一系列改进的输入/输出的新特性,被统称为 NIO(即 NewIO),是同步非阻塞的。
Java NIO 的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。

ByteBuffer
缓冲区(ByteBuffer):缓冲区本质上是一个可以读写数据的内存块,可以理解成是一个容器对象(含数组),该对象提供了一组方法,可以更轻松地使用内存块,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况。ByteBuffer的指针有postion

Channel
NIO 的通道类似于流,主要的区别是:通道可以同时进行读写,而流只能读或者只能写。通道可以实现异步读写数据。通道可以从缓冲读数据,也可以写数据到缓冲。BIO的流是单向的,NIO的通道是双向的,可以读也可以写操作。
Selector
Java 的 NIO,用非阻塞的 IO 方式。可以用一个线程,处理多个的客户端连接,就会使用到 Selector(选择器)。Selector 能够检测多个注册的通道上是否有事件发生(注意:多个 Channel 以事件的方式可以注册到同一个 Selector),如果有事件发生,便获取事件然后针对每个事件进行相应的处理。
这样就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求。只有在连接/通道真正有读写事件发生时,才会进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程。避免了多线程之间的上下文切换导致的开销。
流
- 流不能通过索引读写数据
- 流中的数据只能顺序读取
// 将流整合起来以便实现更高级的输入和输出操作。如可以把InputStream包装到BufferedInputStream中以实现缓冲,即从磁盘中一次读取一大块数据
InputStream input = new BufferedInputStream(new FileInputStream("c:\data\input-file.txt"));
OutputStream output = new BufferedOutputStream(new FileOutputStream("c:\data\output-file.txt"));
Java的IO流共涉及40多个类,实际上非常规则,都是从以上4个抽象基类派生的
-
java.io.InputStream
int read()从输入流中读取数据的下一个字节。返回 0 到 255 范围内的 int 字节值。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。 int read(byte[] b)从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。否则以整数形式返回实际读取的字节数。 int read(byte[] b, int off, int len)将输入流中最多 len 个数据字节读入 byte 数组。尝试读取 len 个字节,但读取的字节也可能小于该值。 -
java.io.OutputStream
void write(int b) 将指定的字节写入此输出流。write 的常规协定是:向输出流写入一个字节。要写入的字节是参数 b 的八个低位。b 的 24 个高位将被忽略。 即写入0~255范围的。 void write(byte[] b) 将 b.length 个字节从指定的 byte 数组写入此输出流。 void write(byte[] b,int off,int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。 public void flush()throws IOException 刷新此输出流并强制写出所有缓冲的输出字节,调用此方法指示应将这些字节立即写入它们预期的目标。 -
java.io.Reader
int read()读取单个字符。作为整数读取的字符,范围在 0 到 65535 之间 (0x00-0xffff)(2个字节的Unicode码),如果已到达流的末尾,则返回 -1 int read(char[] cbuf)将字符读入数组。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。 int read(char[] cbuf,int off,int len)将字符读入数组的某一部分。存到数组cbuf中,从off处开始存储,最多读len个字符。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。 -
java.io.Writer
void write(int c) 写入单个字符。要写入的字符包含在给定整数值的 16 个低位中,16 高位被忽略。 即写入0 到 65535 之间的Unicode码。 void write(char[] cbuf) 写入字符数组。 void write(char[] cbuf,int off,int len) 写入字符数组的某一部分。从off开始,写入len个字符 void write(String str) 写入字符串。 void write(String str,int off,int len) 写入字符串的某一部分。 void flush() 刷新该流的缓冲,则立即将它们写入预期目标
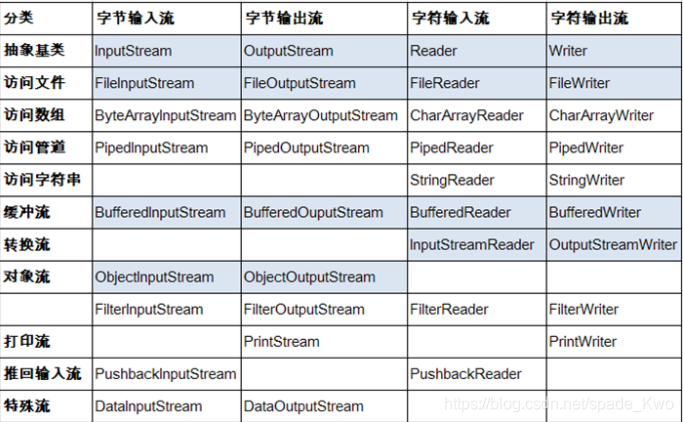
用来将文件转换为二进制字节流或字符流
- FileInputStream(二进制型数据):按顺序地读取文件中的字节,每次读取一个字节
- FileReader(字符型数据):按顺序地读取文件中的字符,每次读取一个字符
- FileOutputStream(二进制型数据):每次写入一个字节,数据按照写入顺序存储在文件当中
- FileWriter(字符型数据):每次写入一个字符,数据按照写入顺序存储在文件当中
//二进制流范例,打开一个文件的输入流,读取到字节数组,再写入另一个文件的输出流
public void test1() {try {FileInputStream fileInputStream = new FileInputStream(new File("a.txt"));FileOutputStream fileOutputStream = new FileOutputStream(new File("b.txt"));byte []buffer = new byte[128];while (fileInputStream.read(buffer) != -1) {fileOutputStream.write(buffer);}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}
}
// 字符流范例
public static void main(String[] args) throws IOException {FileReader fileReader = new FileReader("file.txt");FileWriter fileWriter = new FileWriter("file2.txt");//一次拷贝4个字节char[] chars = new char[1024*1024];int read;while ((read = fileReader.read(chars)) != -1) {fileWriter.write(chars, 0, read);}fileWriter.flush();if (fileReader != null) {fileReader.close();}if (fileWriter != null) {fileWriter.close();}}
Java IO中的管道为运行在同一个JVM中的两个线程提供通信的能力,所以管道也可以作为数据源以及目标媒介。不同的JVM中线程不能利用管道进行通信
//使用管道来完成两个线程间的数据点对点传递
@Test
public void test2() throws IOException {PipedInputStream pipedInputStream = new PipedInputStream();PipedOutputStream pipedOutputStream = new PipedOutputStream(pipedInputStream);new Thread(new Runnable() {@Overridepublic void run() {try {pipedOutputStream.write("hello input".getBytes());pipedOutputStream.close();} catch (IOException e) {e.printStackTrace();}}}).start();new Thread(new Runnable() {@Overridepublic void run() {try {byte []arr = new byte[128];while (pipedInputStream.read(arr) != -1) {System.out.println(Arrays.toString(arr));}pipedInputStream.close();} catch (IOException e) {e.printStackTrace();}}}).start();
不仅可以用来做缓存数据的临时存储空间,同时也可以作为数据来源或者写入目的
//字符数组和字节数组在io过程中的作用
public void test4() {//arr和brr分别作为数据源char []arr = {'a','c','d'};CharArrayReader charArrayReader = new CharArrayReader(arr);byte []brr = {1,2,3,4,5};ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(brr);
}
通过ObjectInputStream转换InputStream为Object
ObjectInputStream input = new ObjectInputStream(new FileInputStream("object.data"));
MyClass object = (MyClass) input.readObject();
input.close();
- BufferedReader:为字符输入流提供缓冲区,可以提高许多IO处理的速度(默认为8KB)
- BufferedInputStream:为原始字节输入流提供缓冲区,可以提高许多IO处理的速度
@Testpublic void BufferedStreamTest() throws FileNotFoundException {BufferedInputStream bis = null;BufferedOutputStream bos = null;try {//1.造文件File srcFile = new File("爱情与友情.jpg");File destFile = new File("爱情与友情3.jpg");//2.造流//2.1 造节点流FileInputStream fis = new FileInputStream((srcFile));FileOutputStream fos = new FileOutputStream(destFile);//2.2 造缓冲流bis = new BufferedInputStream(fis);bos = new BufferedOutputStream(fos);//3.复制的细节:读取、写入byte[] buffer = new byte[10];int len;while((len = bis.read(buffer)) != -1){bos.write(buffer,0,len);// bos.flush();//刷新缓冲区}} catch (IOException e) {e.printStackTrace();} finally {//4.资源关闭//要求:先关闭外层的流,再关闭内层的流if(bos != null){try {bos.close();} catch (IOException e) {e.printStackTrace();}}if(bis != null){try {bis.close();} catch (IOException e) {e.printStackTrace();}}//说明:关闭外层流的同时,内层流也会自动的进行关闭。关于内层流的关闭,我们可以省略.
// fos.close();
// fis.close();}}
通过InputStreamReader、OutputStreamWriter
@Testpublic void test1() throws IOException {FileInputStream fis = new FileInputStream("dbcp.txt");
// InputStreamReader isr = new InputStreamReader(fis);//使用系统默认的字符集//参数2指明了字符集,具体使用哪个字符集,取决于文件dbcp.txt保存时使用的字符集InputStreamReader isr = new InputStreamReader(fis,"UTF-8");//使用系统默认的字符集char[] cbuf = new char[20];int len;while((len = isr.read(cbuf)) != -1){String str = new String(cbuf,0,len);System.out.print(str);}isr.close();}
System.in和System.out分别代表了系统标准的输入和输出设备
默认输入设备是:键盘,输出设备是:显示器
System.in的类型是InputStream
System.out的类型是PrintStream,其是OutputStream的子类FilterOutputStream 的子类
BufferedReader br = null;
InputStreamReader isr = new InputStreamReader(System.in);
br = new BufferedReader(isr);while (true) {System.out.println("请输入字符串:");String data = br.readLine();if ("e".equalsIgnoreCase(data) || "exit".equalsIgnoreCase(data)) {System.out.println("程序结束");break;
}
字节流和字符流的区别
字节流:处理字节和字节数组或二进制对象(stream命名); 字符流:处理字符、字符数组或字符串(Reader、Writer命名)。
- 1、字节流在操作的时候本身是不会用到缓冲区(内存)的,是与文件本身直接操作的,而字符流在操作的时候是使用到缓冲区的
- 2、字节流在操作文件时,即使不关闭资源(close方法),文件也能输出,但是如果字符流不使用close方法的话,则不会输出任何内容,说明字符流用的是缓冲区,并且可以使用flush方法强制进行刷新缓冲区,这时才能在不close的情况下输出内容
- 字节流用于操作包含ASCII字符的文件;字符流用于读取包含Unicode字符的文件;对于英文字符文件,字节流和字符流都可以用
序列化
- 序列化 (Serialization):将对象的状态信息转换为可以存储或传输的形式的过程
- 反序列化:将字节对象或XML编码格式还原成完全相等的对象
public class 序列化和反序列化 {
//注意,内部类不能进行序列化,因为它依赖于外部类
@Test
public void test() throws IOException {
A a = new A();
a.i = 1;
a.s = "a";
FileOutputStream fileOutputStream = null;
FileInputStream fileInputStream = null;
try {
//将obj写入文件
fileOutputStream = new FileOutputStream("temp");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(a);
fileOutputStream.close();//通过文件读取obj
fileInputStream = new FileInputStream("temp");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
A a2 = (A) objectInputStream.readObject();
fileInputStream.close();
System.out.println(a2.i);
System.out.println(a2.s);
//打印结果和序列化之前相同
} catch (IOException e)
{ e.printStackTrace();
} catch (ClassNotFoundException e)
{ e.printStackTrace(); } } }class A implements Serializable {int i;String s;
}
序列化ID
反序列化的前提是序列化ID得相同,Eclipse提供两种产生序列化ID的方法,一种是:属性名+时间戳,另一种是我们一般用1L表示。
// 虽然两个类的路径和功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化
public class A implements Serializable { private static final long serialVersionUID = 1L; private String name; public String getName() { return name; } public void setName(String name) { this.name = name; }
} public class A implements Serializable { private static final long serialVersionUID = 2L; private String name; public String getName() { return name; } public void setName(String name) { this.name = name; }
}
- 序列化引擎会根据对象时候实现了
Serializable接口类,如果没有则抛NotSerializableException异常(这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。),如果实现了则会创建ObjectOutputStream对象,绑定到输出流上 - 扫描对象中
static(因为其为类的状态)、transient关键字的字段,不对其进行序列化,Object对象流不写入,也不读出。 - 如果对象有其他对象的引用则需要递归将引用对象也进行序列化
- 如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该集成java.io.Serializable接口,父类没实现Serializable接口那么,子类序列化时父类不会序列化。当反序列化变为对象时,因为子类对象创建会先创建父类,所以会调用父类的构造方法。子类对象的属性的值存在,父类对象的属性的值为0或者为null
- ArrayList实现了java.io.Serializable接口,可以对它进行序列化及反序列化。但是其中数组elementData(用来保存列表中的元素的)是transient的,正常不应该被序列化保存下来。
为什么ArrayList要通过重写writeObject 和 readObject 方法来实现序列化呢?为什么数组elementData是transient的
ArrayList实际上是动态数组,每次在放满以后自动增长设定的长度值,如果数组自动增长长度设为100,而实际只放了一个元素,那就会序列化99个null元素。为了保证在序列化的时候不会将这么多null同时进行序列化,ArrayList把元素数组设置为transient为什么要重写writeObject 和 readObject 方法前面说过,为了防止一个包含大量空对象的数组被序列化,为了优化存储,所以,ArrayList使用transient来声明elementData。但是,作为一个集合,在序列化过程中还必须保证其中的元素可以被持久化下来,所以,通过重写writeObject 和 readObject方法的方式把其中的元素保留下来。writeObject方法把elementData数组中的元素遍历的保存到输出流(ObjectOutputStream)中。readObject方法从输入流(ObjectInputStream)中读出对象并保存赋值到elementData数组中。
序列化引擎:Dubbo 框架中的 Hession、JDK 自带的 Serializable、跨语言的 Hessian、ProtoBuf、ProtoStuff
相关文章:
JAVA 学习 面试(五)IO篇
BIO是阻塞I/O,NIO是非阻塞I/O,AIO是异步I/O。BIO每个连接对应一个线程,NIO多个连接共享少量线程,AIO允许应用程序异步地处理多个操作。NIO,通过Selector,只需要一个线程便可以管理多个客户端连接࿰…...
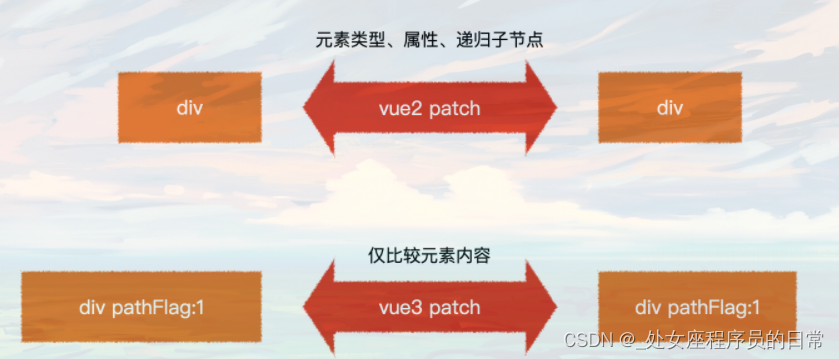
vue3相比vue2的效率提升
1、静态提升 2、预字符串化 3、缓存事件处理函数 4、Block Tree 5、PatchFlag 一、静态提升 在vue3中的app.vue文件如下: 在服务器中,template中的内容会变异成render渲染函数。 最终编译后的文件: 1.静态节点优化 那么这里为什么是两部分…...

web terminal - 如何在mac os上运行gotty
gotty可以让你使用web terminal的方式与环境进行交互,实现终端效果 假设你已经配置好了go环境,首先使用go get github.com/yudai/gotty命令获取可执行文件,默认会安装在$GOPATH/bin这个目录下,注意如果你的go版本比较高ÿ…...
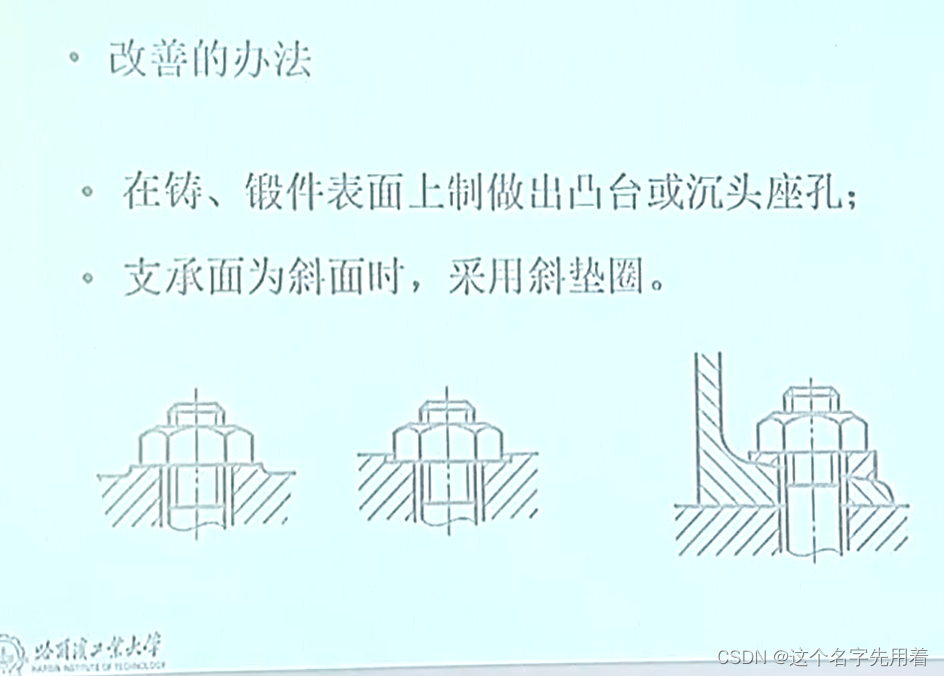
机械设计-哈工大课程学习-螺纹连接
圆柱螺纹主要几何参数螺纹参数 ①外径(大径),与外螺纹牙顶或内螺纹牙底相重合的假想圆柱体直径。螺纹的公称直径即大径。 ②内径(小径),与外螺纹牙底或内螺纹牙顶相重合的假想圆柱体直径。 ③中径ÿ…...

ai绘画|stable diffusion的发展史!简短易懂!!!
手把手教你入门绘图超强的AI绘画,用户只需要输入一段图片的文字描述,即可生成精美的绘画。给大家带来了全新保姆级教程资料包 (文末可获取) 一、stable diffusion的发展史 本文目标:学习交流 对于熟悉SD的同学&#x…...

水塘抽样算法
水塘抽样算法 1、问题描述 最近经常能看到面经中出现在大数据流中的随机抽样问题 即:当内存无法加载全部数据时,如何从包含未知大小的数据流中随机选取k个数据,并且要保证每个数据被抽取到的概率相等。 假设数据流含有N个数,我…...
easyui渲染隐藏域<input type=“hidden“ />为textbox可作为分割条使用
最近在修改前端代码的时候,偶然发现使用javascript代码渲染的方式将<input type"hidden" />渲染为textbox时,会显示一个神奇的效果,这个textbox输入框并不会隐藏,而是显示未一个细条,博主发现非常适合…...

100天精通Python(实用脚本篇)——第113天:基于Tesseract-OCR实现OCR图片文字识别实战
文章目录 专栏导读1. OCR技术介绍2. 模块介绍3. 模块安装4. 代码实战4.1 英文图片测试4.2 数字图片测试4.3 中文图片识别 书籍分享 专栏导读 🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准…...

Go七天实现RPC
0.前言 本文是学习自7天用Go从零实现RPC框架GeeRPC | 极客兔兔 在此基础上,加入自己的学习过程与理解。 1.RPC 框架 RPC(Remote Procedure Call,远程过程调用)是一种计算机通信协议,允许调用不同进程空间的程序。RPC 的客户端和服务器可以…...
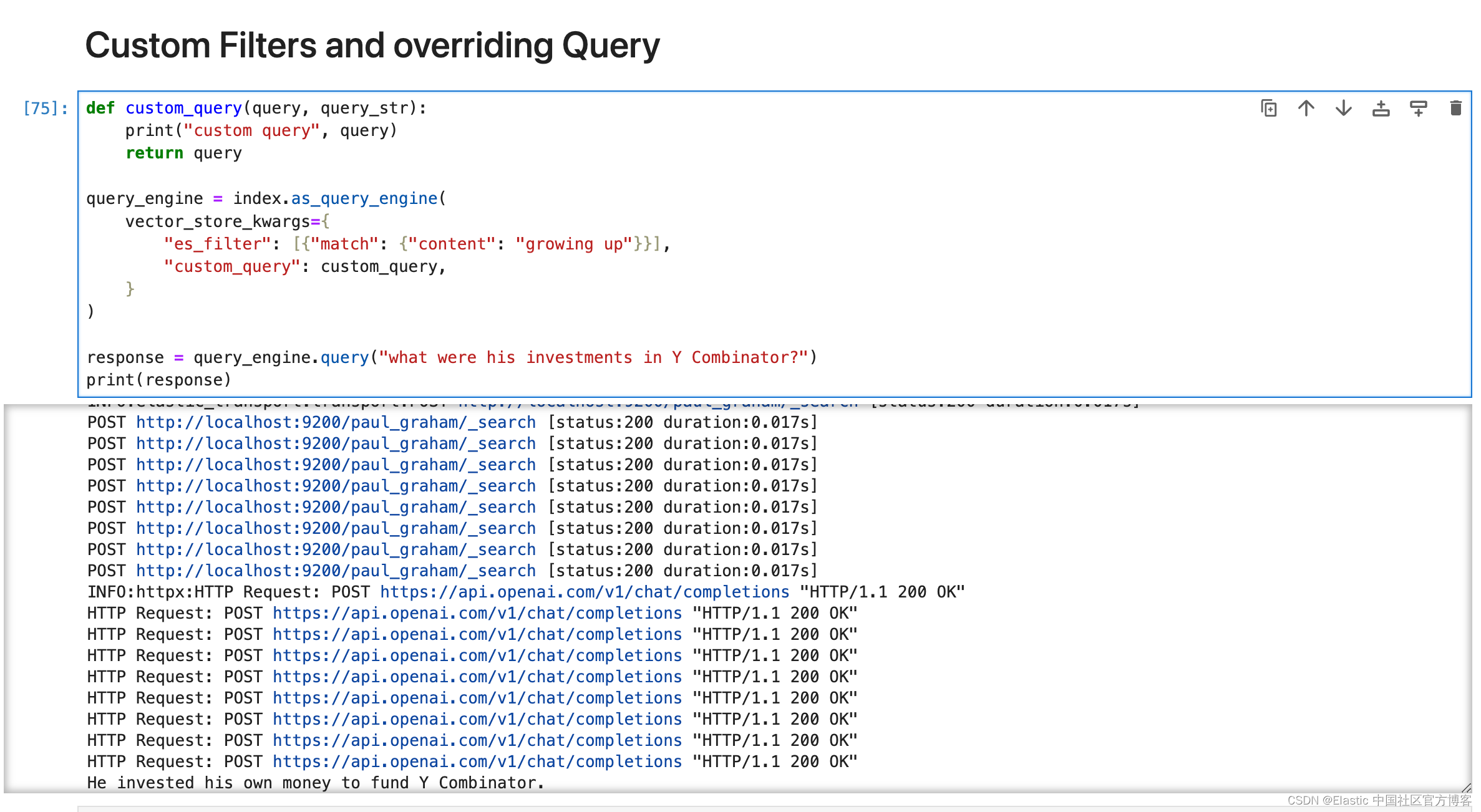
Elasticsearch:和 LIamaIndex 的集成
LlamaIndex 是一个数据框架,供 LLM 应用程序摄取、构建和访问私有或特定领域的数据。 LlamaIndex 是开源的,可用于构建各种应用程序。 在 GitHub 上查看该项目。 安装 在 Docker 上设置 Elasticsearch 使用以下 docker 命令启动单节点 Elasticsearch 实…...
QT操作office实例)
QT基础篇(14)QT操作office实例
1.QT操作office的基本方式 通过QT操作Office软件,可以使用Qt的QAxObject类来进行操作。下面是一个例子,展示了通过Qt操作Excel的基本方式: #include <QApplication> #include <QAxObject>int main(int argc, char *argv[]) {QA…...

重拾计网-第四弹 计算机网络性能指标
ps:本文章的图片内容来源都是来自于湖科大教书匠的视频,声明:仅供自己复习,里面加上了自己的理解 这里附上视频链接地址:1.5 计算机网络的性能指标(1)_哔哩哔哩_bilibili 目录 &#x…...
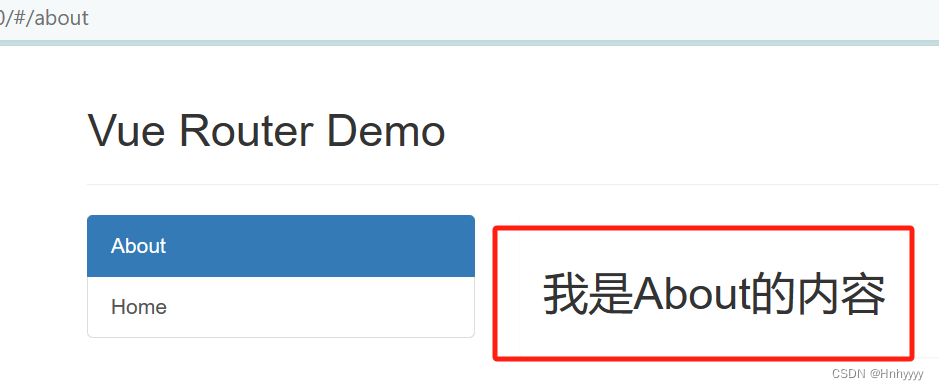
【Vue】Vue 路由的配置及使用
目录捏 前言一、路由是什么?1.前端路由2.后端路由 二、路由配置1.安装路由2.配置路由 三、路由使用1.route 与 router2. 声明式导航3. 指定组件的呈现位置 四、嵌套路由(多级路由)五、路由重定向1.什么是路由重定向?2.设置 redire…...

网络安全事件分级指南
一、特别重大网络安全事件 符合下列情形之一的,为特别重大网络安全事件: 1.重要网络和信息系统遭受特别严重的系统损失,造成系统大面积瘫痪,丧失业务处理能力。 2.国家秘密信息、重要敏感信息、重要数据丢失或被窃取、篡改、假…...

uniapp组件库SwipeAction 滑动操作 使用方法
目录 #平台差异说明 #基本使用 #修改按钮样式 #点击事件 #API #Props #Event 该组件一般用于左滑唤出操作菜单的场景,用的最多的是左滑删除操作。 注意 如果把该组件通过v-for用于左滑删除的列表,请保证循环的:key是一个唯一值,可以…...
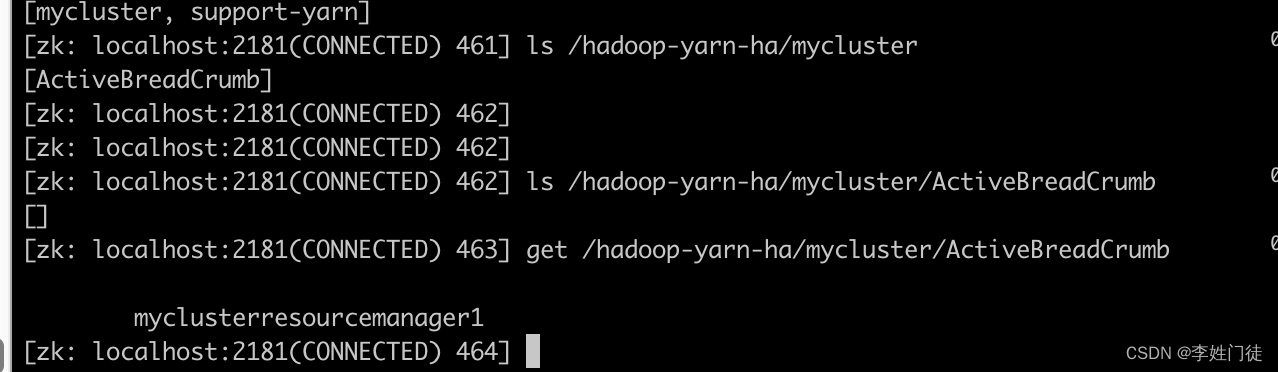
YARN节点故障的容错方案
YARN节点故障的容错方案 1. RM高可用1.1 选主和HA切换逻辑 2. NM高可用2.1 感知NM节点异常2.2 异常NM上的任务处理 4. 疑问和思考4,1 RM感知NM异常需要10min,对于app来说是否太长了? 5. 参考文档 本文主要探讨yarn集群的高可用容错方案和容错能力的探讨。…...

C++后端笔记
C后端笔记 资源整理一、高级语言程序设计1.1 进制1.2 程序结构基本知识1.3 数据类型ASCII码命名规则变量间的赋值浮点型变量的作用字符变量常变量 const运算符 二、高级语言程序设计(荣) 资源整理 C后端开发学习路线及推荐学习时间 C基础知识大全 C那…...

JavaEE中什么是Web容器?
Web容器(也称为Servlet引擎)是一个用于执行Java Servlet和JSP的服务器端环境。它负责管理和执行在其上运行的Web应用程序。 Tomcat是Web容器 Apache Tomcat 是一个流行的开源的Web容器,它实现了Java Servlet和JavaServer Pages(…...
(1))
MySQL 8.0 架构 之错误日志文件(Error Log)(1)
文章目录 MySQL 8.0 架构 之错误日志文件(Error Log)(1)MySQL错误日志文件(Error Log)MySQL错误日志在哪里Window环境Linux环境 错误日志相关参数log_error_services 参考 【声明】文章仅供学习交流&#x…...

51单片机实验课一
实验任务一:实现控制8个发光管的亮(灭) #include <REGX52.H> void Delay1ms(unsigned int xms) //11.0592MHz {unsigned char i, j;while(xms){xms--;i 12;j 169;do{while (--j);} while (--i);} } void main() {while(1){P20;//八…...

如何零风险升级SillyTavern:保护角色数据完整的终极指南
如何零风险升级SillyTavern:保护角色数据完整的终极指南 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 还在为SillyTavern版本更新而提心吊胆吗?担心升级过程中珍贵…...

STM32CubeMX实战:硬件CRC配置详解与软件算法性能实测
1. STM32硬件CRC模块初探 第一次接触STM32的硬件CRC模块时,我完全被它的效率震惊了。这个看似不起眼的外设,其实是个隐藏的性能怪兽。简单来说,CRC(循环冗余校验)就像给数据包贴上的防伪标签,而STM32内置的…...

STM32F103C8T6最小系统板避坑指南:从ST-LINK接线到Keil5乱码,新手必看的5个实战问题
STM32F103C8T6最小系统板避坑指南:从ST-LINK接线到Keil5乱码,新手必看的5个实战问题 第一次点亮STM32开发板的LED时,那种成就感就像电子工程师的"成人礼"。但通往成功的路上往往布满荆棘——接错一根线可能导致整晚的调试失败&…...

NotebookLM脑机接口性能天花板已破?斯坦福NeuroAI Lab最新benchmark显示延迟<83ms,但仅开放给签署NDA的前50个研究团队
更多请点击: https://kaifayun.com 第一章:NotebookLM脑机接口研究概览 NotebookLM 是 Google 推出的基于用户自有文档进行深度理解与推理的 AI 助手,虽其本身并非直接实现脑机接口(BCI)的硬件系统,但正成…...

网站建设公司推荐:业内公认高水准网站制作公司一览
在数字化竞争日益激烈的2026年,企业官网已从单纯的信息展示窗口升级为品牌战略核心载体与业务增长引擎。面对市场上众多的网站建设服务商,企业如何精准匹配需求?本文作为第三方深度测评,从高端定制、模板建站、低成本快速上线三类…...

京东滑块验证码JS逆向实战:从接口分析到轨迹加密
1. 京东滑块验证码逆向分析入门 第一次接触京东滑块验证码逆向时,我也被那一堆加密参数搞得头晕眼花。但经过多次实战后,我发现只要掌握几个关键点,就能轻松破解这个看似复杂的验证系统。滑块验证码的核心逻辑其实很简单:系统通过…...
)
What Are You Talking About(HDU- P1075)
伊格纳修斯真是走了狗屎运,昨天居然遇到了火星人!可惜他完全听不懂火星人的语言。临走时,火星人给了他一本火星历史书和一本词典。现在伊格纳修斯想把这本历史书翻译成英语,你能帮帮他吗?输入本题只有一组测试数据&…...

Cursor Pro终极破解教程:三步免费解锁AI编程助手完整指南
Cursor Pro终极破解教程:三步免费解锁AI编程助手完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your …...

实测对比:百度OCR车牌识别在夜间、侧拍、模糊场景下的效果到底怎么样?
百度OCR车牌识别实战评测:夜间、侧拍与模糊场景下的真实表现 当停车场道闸自动抬起,交通卡口违章记录自动生成,这些看似简单的场景背后都依赖一项关键技术——车牌识别。作为计算机视觉领域的经典应用,车牌识别技术已经从实验室走…...

VMware Unlocker终极指南:在Windows/Linux上运行macOS虚拟机
VMware Unlocker终极指南:在Windows/Linux上运行macOS虚拟机 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想要在Windows或Linux电脑上体验苹果macOS系统吗?无论你是开发者需要…...