数据分析-Pandas如何整合多张数据表
数据分析-Pandas如何整合多张数据表
数据表,时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。数据分析过程中表格重整,重新调整,重塑数据表是很重要的技巧,此处选择Titanic数据,以及巴黎、伦敦欧洲城市空气质量监测 N O 2 NO_2 NO2数据作为样例。
数据分析
数据分析-Pandas如何转换产生新列
数据分析-Pandas如何统计数据概况
数据分析-Pandas如何轻松处理时间序列数据
数据分析-Pandas如何选择数据子集
数据分析-Pandas如何重塑数据表-CSDN博客
本文用到的样例数据:
Titanic数据
样例代码:
源代码参考 Pandas如何重塑数据表
源代码参考 python数据分析-数据表读写到pandas
数据准备
拿到数据后,很多情况下数据分散在多张表格中,不能直接用,这就需要对数据进行加工处理。
比如在air_quality数据中,大多数情况下NO2和pm25数据是在两张表中的。NO2数据
In [1]: air_quality_no2 = air_quality_no2[["date.utc", "location",...: "parameter", "value"]]...: In [2]: air_quality_no2.head()
Out[2]: date.utc location parameter value
0 2019-06-21 00:00:00+00:00 FR04014 no2 20.0
1 2019-06-20 23:00:00+00:00 FR04014 no2 21.8
2 2019-06-20 22:00:00+00:00 FR04014 no2 26.5
3 2019-06-20 21:00:00+00:00 FR04014 no2 24.9
4 2019-06-20 20:00:00+00:00 FR04014 no2 21.4PM25数据,如下所示:
In [3]: air_quality_pm25 = air_quality_pm25[["date.utc", "location",...: "parameter", "value"]]...: In [4]: air_quality_pm25.head()
Out[4]: date.utc location parameter value
0 2019-06-18 06:00:00+00:00 BETR801 pm25 18.0
1 2019-06-17 08:00:00+00:00 BETR801 pm25 6.5
2 2019-06-17 07:00:00+00:00 BETR801 pm25 18.5
3 2019-06-17 06:00:00+00:00 BETR801 pm25 16.0
4 2019-06-17 05:00:00+00:00 BETR801 pm25 7.5
那么,Boss的各种数据分析处理要求就来了。
表格拼接
Boss:我就想合并不同监测站的 N O 2 和 P M 25 NO_2 和 PM_{25} NO2和PM25监测值到一张相同结构的表中,表格结构相同,直接加到尾巴上。以下为图示

concat
concat函数提供多个表格拼接到一个维度上,DataFrame有两个axis,可以是沿着列拼接,也可以沿着行拼接。默认如下:是axis=0,沿着列方向拼接起来。
In [5]: air_quality = pd.concat([air_quality_pm25, air_quality_no2], axis=0)In [6]: air_quality.head()
Out[6]: date.utc location parameter value
0 2019-06-18 06:00:00+00:00 BETR801 pm25 18.0
1 2019-06-17 08:00:00+00:00 BETR801 pm25 6.5
2 2019-06-17 07:00:00+00:00 BETR801 pm25 18.5
3 2019-06-17 06:00:00+00:00 BETR801 pm25 16.0
4 2019-06-17 05:00:00+00:00 BETR801 pm25 7.5
拼接的变化,可以通过shape属性观察到。如 axis=0时,行数变化:3178 = 1110 + 2068 行。这样操作:
In [7]: print('Shape of the ``air_quality_pm25`` table: ', air_quality_pm25.shape)
Shape of the ``air_quality_pm25`` table: (1110, 4)In [8]: print('Shape of the ``air_quality_no2`` table: ', air_quality_no2.shape)
Shape of the ``air_quality_no2`` table: (2068, 4)In [9]: print('Shape of the resulting ``air_quality`` table: ', air_quality.shape)
Shape of the resulting ``air_quality`` table: (3178, 4)
事实上,对日期重排后,不同表格源数据的行排序也发生变化。
merge
In [10]: air_quality = air_quality.sort_values("date.utc")In [11]: air_quality.head()
Out[11]: date.utc location parameter value
2067 2019-05-07 01:00:00+00:00 London Westminster no2 23.0
1003 2019-05-07 01:00:00+00:00 FR04014 no2 25.0
100 2019-05-07 01:00:00+00:00 BETR801 pm25 12.5
1098 2019-05-07 01:00:00+00:00 BETR801 no2 50.5
1109 2019-05-07 01:00:00+00:00 London Westminster pm25 8.0
用共同信息整合表格
如何依据某列属性,合并2个表格数据。比如学生身高,体重等体能信息表,和数理化等学科成绩表合并,住建是学生的ID。如下图所示:

如果需要把每个监测站地理坐标,和实时的 N O 2 NO_2 NO2监测值和 P M 2.5 PM_{2.5} PM2.5监测值合并。关键是两点:地理坐标和监测值是不同的属性,表格大小不一致,需要扩充。此处用merge()函数,提供拼接函数的功能。
In [12]: stations_coord.head()
Out[12]: location coordinates.latitude coordinates.longitude
0 BELAL01 51.23619 4.38522
1 BELHB23 51.17030 4.34100
2 BELLD01 51.10998 5.00486
3 BELLD02 51.12038 5.02155
4 BELR833 51.32766 4.36226In [13]: air_quality = pd.merge(air_quality, stations_coord, how="left", on="location")In [14]: air_quality.head()
Out[14]: date.utc ... coordinates.longitude
0 2019-05-07 01:00:00+00:00 ... -0.13193
1 2019-05-07 01:00:00+00:00 ... 2.39390
2 2019-05-07 01:00:00+00:00 ... 2.39390
3 2019-05-07 01:00:00+00:00 ... 4.43182
4 2019-05-07 01:00:00+00:00 ... 4.43182[5 rows x 6 columns]
对于air_quality 的每一行,对应的坐标会从stations_coord中,拼到每行中,其中它们有共同的列:location,作为拼接的key。而使用left拼接,主要是air_quality放在左边的缘故。
In [24]: air_quality = pd.merge(air_quality, air_quality_parameters,....: how='left', left_on='parameter', right_on='id')....: In [25]: air_quality.head()
Out[25]: date.utc ... name
0 2019-05-07 01:00:00+00:00 ... NO2
1 2019-05-07 01:00:00+00:00 ... NO2
2 2019-05-07 01:00:00+00:00 ... NO2
3 2019-05-07 01:00:00+00:00 ... PM2.5
4 2019-05-07 01:00:00+00:00 ... NO2[5 rows x 9 columns]
以上代码只是一个简单示例,示例代码中的表达式可以根据实际问题进行修改。
觉得有用 收藏 收藏 收藏
点个赞 点个赞 点个赞
End
数据分析
数据分析-Pandas如何转换产生新列
数据分析-Pandas如何统计数据概况
数据分析-Pandas如何轻松处理时间序列数据
数据分析-Pandas如何选择数据子集
数据分析-Pandas如何重塑数据表-CSDN博客
经典算法
经典算法-遗传算法的python实现
经典算法-模拟退火算法的python实现
经典算法-粒子群算法的python实现-CSDN博客
GPT专栏文章:
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
GPT实战系列-LangChain + ChatGLM3构建天气查询助手
大模型查询工具助手之股票免费查询接口
GPT实战系列-简单聊聊LangChain
GPT实战系列-大模型为我所用之借用ChatGLM3构建查询助手
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
GPT实战系列-Baichuan2等大模型的计算精度与量化
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-探究GPT等大模型的文本生成-CSDN博客
相关文章:
数据分析-Pandas如何整合多张数据表
数据分析-Pandas如何整合多张数据表 数据表,时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。数据分析过程中表格重整,重新调整,重塑数据表是很重要的技巧,…...

配置redis挂载
1. 暂停和删除redis 2.创建文件夹 /usr/local/software/redis/6379/conf/ /usr/local/software/redis/6379/data/ 把redis-conf文件上传到conf文件夹中 3.配置网络 docker network create --driver bridge --subnet172.18.12.0/16 --gateway172.18.1.1 wn_docker_net 4.运…...

C++ 实现游戏(例如MC)键位显示
效果: 是不是有那味儿了? 显示AWSD,空格,Shift和左右键的按键情况以及左右键的CPS。 彩虹色轮廓,黑白填充。具有任务栏图标,可以随时关闭字体是Minecraft AE Pixel,如果你没有装(大…...
力扣hot100 合并两个有序链表 递归 双指针
Problem: 21. 合并两个有序链表 文章目录 💖 递归思路 💖 双指针 💖 递归 思路 👨🏫 参考地址 n , m n,m n,m 分别为 list1 和 list2 的元素个数 ⏰ 时间复杂度: O ( n m ) O(nm) O(nm) 🌎 空间复杂…...

10个常用python自动化脚本
大家好,Python凭借其简单和通用性,能够为解决每天重复同样的工作提供最佳方案。本文将探索10个Python脚本,这些脚本可以帮助自动化完成任务,提高工作效率。无论是开发者、数据分析师还是仅仅想简化工作流程的普通用户,…...
)
C++中函数的默认参数(缺省参数)
一、函数默认参数的概念 在函数声明时,预先对函数参数进行赋值,该参数即为函数的默认参数,也叫缺省参数。 如下函数func1包含默认参数,若调用函数func1时没有给函数传入实参,则默认实参为10086 void func1(int a 1…...
在线扒站网PHP源码-在线扒站工具网站源码
源码介绍 这是一款在线的网站模板下载程序,也就是我们常说的扒站工具,利用它我们可以很轻松的将别人的网站模板样式下载下来,这样就可以大大提高我们编写前端的速度了!注:扒取的任何站点不得用于商业、违法用途&#…...

vue+elementUI el-select 中 没有加clearable出现一个或者多个×清除图标问题
1、现象:下方截图多清除图标了 2、在全局common.scss文件中加一个下方的全局样式noClear 3、在多清除图标的组件上层div加noClear样式 4、清除图标去除成功...
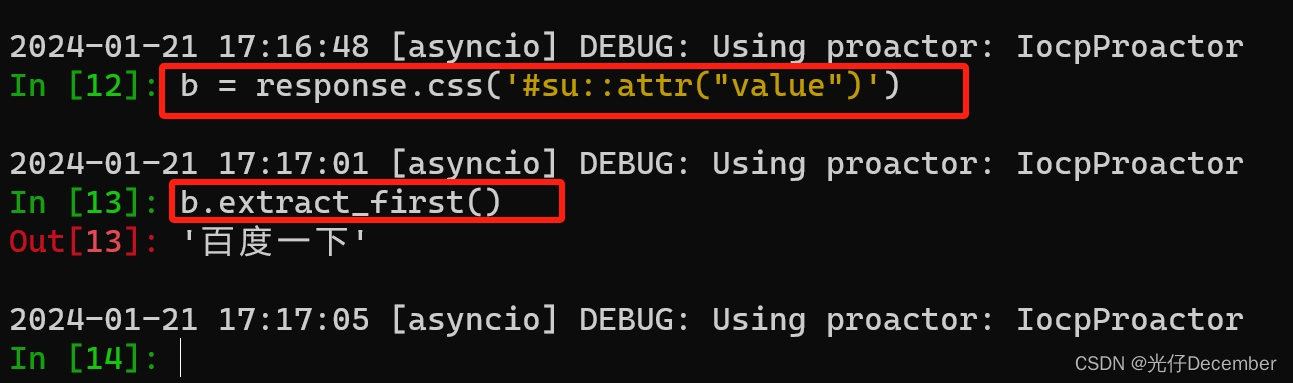
【Python从入门到进阶】47、Scrapy Shell的了解与应用
接上篇《46、58同城Scrapy项目案例介绍》 上一篇我们学习了58同城的Scrapy项目案例,并结合实际再次了项目结构以及代码逻辑的用法。本篇我们来学习Scrapy的一个终端命令行工具Scrapy Shell,并了解它是如何帮助我们更好的调试爬虫程序的。 一、Scrapy Sh…...

【ARM 嵌入式 编译系列 2.2 -- GCC 编译参数学习 assembler-with-cpp 使用介绍】
请阅读【嵌入式开发学习必备专栏 之 ARM GCC 编译专栏】 文章目录 GCC 编译选项 assembler-with-cpp GCC 编译选项 assembler-with-cpp 在 rt-thread 的编译脚本中经常会看到下面编译参数: AFLAGS -c DEVICE -x assembler-with-cpp -Wa,-mimplicit-itthumb a…...

深入理解java对象的内存布局
概述: 在HotSpot虚拟机里,对象在堆内存中的存储布局可以划分为三个部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。 在HotSpot虚拟机里,…...

MetaGPT中提到的SOP
MetaGPT框架中的提及的SOP概念指的是什么,有什么优点和缺点,为什么要使用SOP? 在MetaGPT框架中,SOP(Set of Procedures)指的是一套标准化的流程和步骤,用于指导模型完成特定任务。SOP可以帮助模型更好地理…...
第15届蓝桥杯嵌入式省赛准备第三天总结笔记(使用STM32cubeMX创建hal库工程+串口接收发送)
因为我是自己搞得板子,原本的下程序和串口1有问题,所以我用的是串口2,用的PA2和PA3 一,使用CubeMX配置串口 选择A开头的这个是异步通信。 配置串口参数,往届的题基本用的9600波特率,所以我这里设置为9600…...

centos安装redis,但是启动redis-server /home/redis/conf/redis7000.conf卡住,怎么解决
如果你在启动 Redis 服务器时发现过程卡住,这可能是由于几种不同的原因。下面是一些可能导致这种情况的原因以及相应的解决方法: 1. 后台启动 Redis 默认在前台运行。如果你在命令行启动 Redis 并且没有指定它在后台运行,它将在前台运行&am…...
开发实践6_project
要求: ① 页面写入超链接,获取所有数据item,显示在另一个页面,1min内,即使数据有变化,页面内容不变,1min后点击超链接可获取最新信息; ② 使用middleware完成用户请求路径判断 &am…...

HCIP----MGRE实验
实验要求: 第一步,基本的IP地址配置 R1: [R1]int g0/0/1 [R1-GigabitEthernet0/0/1]ip add 192.168.1.1 24 #配置PC的网关 [R1]int Serial 4/0/0 [R1-Serial4/0/0]link-protocol hdlc #R1和R2之间采用hdlc封装 [R1-S…...
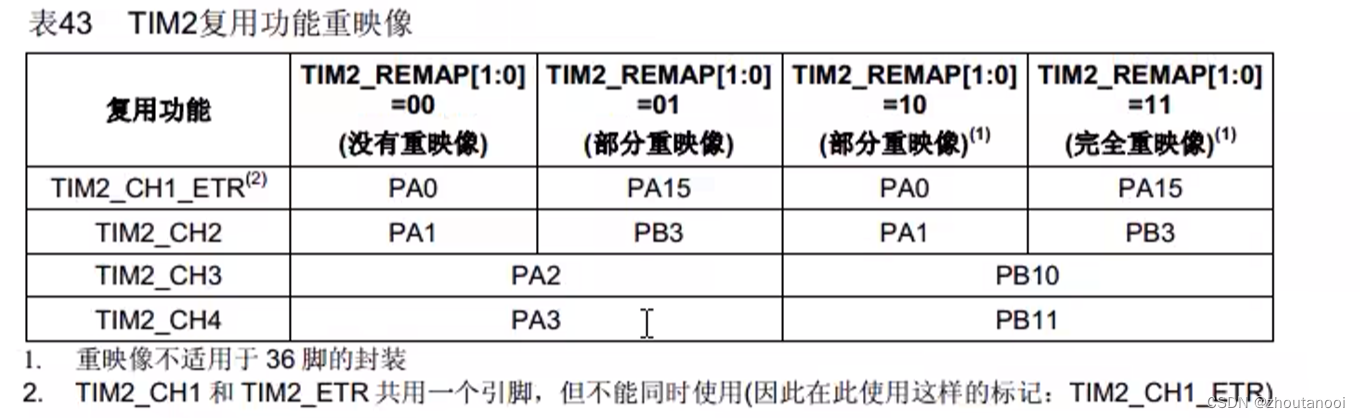
STM32标准库开发——PWM驱动代码
PWM驱动初始化代码 使能定时器二时钟 RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2,ENABLE);设置定时器时钟源 TIM_InternalClockConfig(TIM2);配置定时器二的时基单元 TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStruct; TIM_TimeBaseInitStruct.TIM_ClockDivisionTIM_CKD_D…...
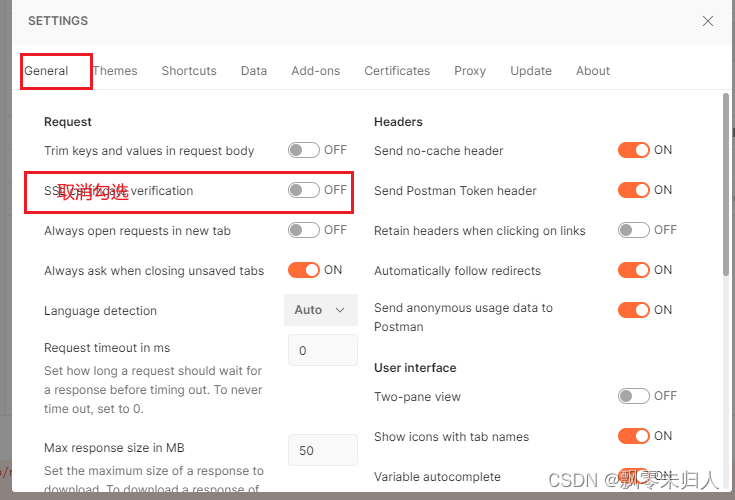
postman导入https证书
进入setting配置中Certificates配置项 点击“Add Certificate”,然后配置相关信息 以上配置完毕,如果测试出现“SSL Error:Self signed certificate” 则将“SSL certificate verification”取消勾选...

Spark UI中 Shuffle Exchange 和 BroadcastExchange 中的 dataSize 值为什么不一样
背景 Spark 3.5 最近在看Spark UI 上的一些指标看到一个很有意思的东西, 相邻的Shuffle Exechange 和 BroadcastExechange 中的 datasize 居然不一样, 前者为 765KB, 后者为 64.5MB。差别还不少,中间就增加了一个 AQEShuffleRead 计划 结论 Shuffle E…...

阿里云优惠券领取入口、使用方法和限制条件,2024最新
阿里云优惠代金券领取入口,阿里云服务器优惠代金券、域名代金券,在领券中心可以领取当前最新可用的满减代金券,阿里云百科aliyunbaike.com分享阿里云服务器代金券、领券中心、域名代金券领取、代金券查询及使用方法: 阿里云优惠券…...
)
GitHub本周热门项目(2026-05-18)
GitHub 本周热门项目推荐 更新时间:2026-05-18 数据来源:GitHub Trending 🔥 TOP 10 热门项目 1. mattpocock/skills 一句话描述:面向真实工程师的技能框架,提供Claude Code等AI编码工具的专业技能扩展。 项目信息详…...

【亲测免费】 CISP-DSG 数据安全培训教材课件标准版
CISP-DSG 数据安全培训教材课件标准版 【下载地址】CISP-DSG数据安全培训教材课件标准版 本仓库提供的是“注册数据安全治理专业人员”(Certified Information Security Professional - Data Security Governance,简称 CISP-DSG)的培训教材课…...
)
【免费下载】 JIRA用户操作指南(详细版)
JIRA用户操作指南(详细版) 【下载地址】JIRA用户操作指南详细版 JIRA用户操作指南(详细版)欢迎使用JIRA用户操作指南,本指南旨在帮助您全面理解并高效地使用JIRA这一强大的问题跟踪与项目管理工具 项目地址: https:/…...

更换背景图用什么工具?8个月来我测试过50+款产品,这是真实体验分享
买了新手机,想给证件照换个背景;电商运营需要批量处理商品图;自媒体博主要给头像去个背景……这些场景下,"更换背景图用什么工具"可能是你Google搜索框里最常打的一句话。说实话,这个问题看似简单࿰…...

别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器
别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器 信号处理工程师的日常工作中,滤波器设计是个绕不开的话题。无论是音频处理、通信系统还是生物医学信号分析,我们总需要根据不同的应用场景调整滤波器参数。传统方法中…...

证件照换装API实战指南:一键换装,告别服装不合格!
还在为证件照服装不符合要求而烦恼?可立图ClipImg证件照换装API,自动识别身形与姿态,一键替换为正装,让你的照片瞬间专业起来!一、痛点场景:你的证件照是否也遇到过这些尴尬吗?求职简历…...
 题解)
【LeetCode】50. pow(x,n) 题解
【LeetCode】50. pow(x,n)\text{pow}(x,n)pow(x,n) 题解 Link: https://leetcode.cn/problems/powx-n/ 实现 pow(x, n) ,即计算 xxx 的整数 nnn 次幂函数(即 xnx^nxn)。 其中 xxx 是浮点数,nnn 是可正可负的 323232 位有符号整…...

CodeWF.Markdown:一个基于 Avalonia 12 的 Markdown 渲染控件
今天这篇文章,站长来聊聊我最近基本开发完成的 CodeWF.Markdown。这是一个基于 C# Avalonia 12 Markdig 做的 Markdown 渲染控件。它最早来自 CodeWF.AvaloniaControls,后来我把 Markdown 相关代码单独拆成了一个仓库和一组 NuGet 包:渲染控…...

从10G到40G/50G:UltraScale+以太网IP核升级实战与GT资源规划
1. 从10G到40G/50G的升级挑战 当你第一次把项目从10G升级到40G/50G以太网时,最直观的感受就是"资源突然不够用了"。我去年接手一个视频处理项目时就深有体会——原本在10G环境下游刃有余的FPGA设计,切换到40G后GT资源立刻捉襟见肘。这里说的GT…...
)
告别全屏地球!用Cesium.js在地图上只显示一个县(附完整代码)
用Cesium.js实现区域聚焦:打造专属行政区划三维地图 在WebGIS开发中,我们经常遇到需要将三维地球的显示范围限定在特定行政区划内的需求。无论是为了突出展示某个城市的发展规划,还是为了制作县域级别的专题地图,区域聚焦技术都能…...