Apache Zeppelin结合Apache Airflow使用1
Apache Zeppelin结合Apache Airflow使用1
文章目录
- Apache Zeppelin结合Apache Airflow使用1
- 前言
- 一、安装Airflow
- 二、使用步骤
- 1.目标
- 2.编写DAG
- 2.加载、执行DAG
- 总结
前言
之前学了Zeppelin的使用,今天开始结合Airflow串任务。
Apache Airflow和Apache Zeppelin是两个不同的工具,各自用于不同的目的。Airflow用于编排和调度工作流,而Zeppelin是一个交互式数据分析和可视化的笔记本工具。虽然它们有不同的主要用途,但可以结合使用以满足一些复杂的数据处理和分析需求。
下面是一些结合使用Airflow和Zeppelin的方式:
-
Airflow调度Zeppelin Notebooks:
- 使用Airflow编写调度任务,以便在特定时间或事件触发时运行Zeppelin笔记本。
- 在Airflow中使用Zeppelin的REST API或CLI命令来触发Zeppelin笔记本的执行。
-
数据流管道:
- 使用Airflow编排数据处理和转换任务,例如从数据源提取数据、清理和转换数据。
- 在Zeppelin中创建笔记本,用于进一步的数据分析、可视化和报告生成。
- Airflow任务完成后,触发Zeppelin笔记本执行以基于最新数据执行分析。
-
参数传递:
- 通过Airflow参数传递,将一些参数值传递给Zeppelin笔记本,以便在不同任务之间共享信息。
- Zeppelin笔记本可以从Airflow任务中获取参数值,以适应特定的数据分析需求。
-
日志和监控:
- 使用Airflow监控工作流的运行情况,查看任务的日志和执行状态。
- 在Zeppelin中记录和可视化Airflow工作流的关键指标,以获得更全面的工作流性能洞察。
-
整合数据存储:
- Airflow可以用于从不同数据源中提取数据,然后将数据传递给Zeppelin进行进一步的分析。
- Zeppelin可以使用Airflow任务生成的数据,进行更深入的数据挖掘和分析。
结合使用Airflow和Zeppelin能够充分发挥它们各自的优势,实现更全面、可控和可视化的数据处理和分析工作流。
一、安装Airflow
安装参考:
https://airflow.apache.org/docs/apache-airflow/stable/start.html
CentOS 7.9安装后启动会报错,还需要配置下sqlite,参考:https://airflow.apache.org/docs/apache-airflow/2.8.0/howto/set-up-database.html#setting-up-a-sqlite-database
[root@slas bin]# airflow standalone
Traceback (most recent call last):File "/root/.pyenv/versions/3.9.10/bin/airflow", line 5, in <module>from airflow.__main__ import mainFile "/root/.pyenv/versions/3.9.10/lib/python3.9/site-packages/airflow/__init__.py", line 52, in <module>from airflow import configuration, settingsFile "/root/.pyenv/versions/3.9.10/lib/python3.9/site-packages/airflow/configuration.py", line 2326, in <module>conf.validate()File "/root/.pyenv/versions/3.9.10/lib/python3.9/site-packages/airflow/configuration.py", line 718, in validateself._validate_sqlite3_version()File "/root/.pyenv/versions/3.9.10/lib/python3.9/site-packages/airflow/configuration.py", line 824, in _validate_sqlite3_versionraise AirflowConfigException(
airflow.exceptions.AirflowConfigException: error: SQLite C library too old (< 3.15.0). See https://airflow.apache.org/docs/apache-airflow/2.8.0/howto/set-up-database.html#setting-up-a-sqlite-database
二、使用步骤
1.目标
我想做个简单的demo,包括两个节点,实现如图所示功能,读取csv,去重:

csv文件输入在airflow上实现,去重在zeppelin上实现。
2.编写DAG
先实现extract_data_script.py,做个简单的读取csv指定列数据写入新的csv文件。
import argparse
import pandas as pddef extract_and_write_data(date, output_csv, columns_to_extract):# 读取指定列的数据csv_file_path = f"/home/works/datasets/data_{date}.csv"df = pd.read_csv(csv_file_path, usecols=columns_to_extract)# 将数据写入新的 CSV 文件df.to_csv(output_csv, index=False)if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--date", type=str, required=True, help="Date parameter passed by Airflow")args = parser.parse_args()# 输出 CSV 文件路径(替换为实际的路径)output_csv_path = "/home/works/output/extracted_data.csv"# 指定要提取的列columns_to_extract = ['column1', 'column2', 'column3']# 调用函数进行数据提取和写入extract_and_write_data(args.date, output_csv_path, columns_to_extract)然后在 Zeppelin 中创建一个 Python 笔记本(Notebook),其中包含被 Airflow DAG 调用的代码。加载先前从 output/extracted_data.csv 文件中提取的数据:
%python# 导入必要的库
import pandas as pd# 加载先前从 CSV 文件中提取的数据
csv_file_path = "/home/works/output/extracted_data.csv"
# 读取 CSV 文件
df = pd.read_csv(csv_file_path)# 过滤掉 column1 为空的行
df = df[df['column1'].notnull()]# 去重,以 column2、column3 字段为联合去重依据
deduplicated_df = df.drop_duplicates(subset=["column2", "column3"])# 保存去重后的结果到新的 CSV 文件
deduplicated_df.to_csv("/home/works/output/dd_data.csv", index=False)
将这个 Zeppelin 笔记本保存,并记住笔记本的paragraph ID, Airflow DAG 需要使用这个 ID 来调用 Zeppelin 笔记本。
接下来,用VSCode编写zeppelin_integration.py代码如下,上传到$AIRFLOW_HOME/dags目录下:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedeltadefault_args = {'owner': 'airflow','depends_on_past': False,'start_date': datetime(2024, 1, 1),'email_on_failure': False,'email_on_retry': False,'retries': 1,'retry_delay': timedelta(minutes=5),
}dag = DAG('zeppelin_integration',default_args=default_args,schedule=timedelta(days=1),
)extract_data_task = BashOperator(task_id='extract_data',bash_command='python /home/works/z/extract_data_script.py --date {{ ds }}',dag=dag,
)run_zeppelin_notebook_task = BashOperator(task_id='run_zeppelin_notebook',bash_command='curl -X POST -HContent-Type:application/json http://IP:PORT/api/notebook/run/2JND7T68E/paragraph_1705372327640_1111015359',dag=dag,
)# Set the task dependencies
extract_data_task >> run_zeppelin_notebook_task2.加载、执行DAG
如下命令进行测试,先执行下代码看看语法是否都正确,然后list出tasks,并逐一test:
# python zeppelin_integration.py # airflow tasks list zeppelin_integration
extract_data
run_zeppelin_notebook# airflow tasks test zeppelin_integration extract_data 20240122
[2024-01-22T08:57:45.805+0800] {dagbag.py:538} INFO - Filling up the DagBag from /root/airflow/dags
[2024-01-22T08:57:47.853+0800] {taskinstance.py:1957} INFO - Dependencies all met for dep_context=non-requeueable deps ti=<TaskInstance: zeppelin_integration.extract_data __airflow_temporary_run_2024-01-22T00:57:47.740537+00:00__ [None]>
[2024-01-22T08:57:47.860+0800] {taskinstance.py:1957} INFO - Dependencies all met for dep_context=requeueable deps ti=<TaskInstance: zeppelin_integration.extract_data __airflow_temporary_run_2024-01-22T00:57:47.740537+00:00__ [None]>
[2024-01-22T08:57:47.861+0800] {taskinstance.py:2171} INFO - Starting attempt 1 of 2
[2024-01-22T08:57:47.861+0800] {taskinstance.py:2250} WARNING - cannot record queued_duration for task extract_data because previous state change time has not been saved
[2024-01-22T08:57:47.862+0800] {taskinstance.py:2192} INFO - Executing <Task(BashOperator): extract_data> on 2024-01-20T00:00:00+00:00
[2024-01-22T08:57:47.900+0800] {taskinstance.py:2481} INFO - Exporting env vars: AIRFLOW_CTX_DAG_OWNER='airflow' AIRFLOW_CTX_DAG_ID='zeppelin_integration' AIRFLOW_CTX_TASK_ID='extract_data' AIRFLOW_CTX_EXECUTION_DATE='2024-01-20T00:00:00+00:00' AIRFLOW_CTX_TRY_NUMBER='1' AIRFLOW_CTX_DAG_RUN_ID='__airflow_temporary_run_2024-01-22T00:57:47.740537+00:00__'
[2024-01-22T08:57:47.904+0800] {subprocess.py:63} INFO - Tmp dir root location: /tmp
[2024-01-22T08:57:47.905+0800] {subprocess.py:75} INFO - Running command: ['/bin/bash', '-c', 'python /home/works/z/extract_data_script.py --date 2024-01-20']
[2024-01-22T08:57:47.914+0800] {subprocess.py:86} INFO - Output:
[2024-01-22T08:57:48.553+0800] {subprocess.py:97} INFO - Command exited with return code 0
[2024-01-22T08:57:48.632+0800] {taskinstance.py:1138} INFO - Marking task as SUCCESS. dag_id=zeppelin_integration, task_id=extract_data, execution_date=20240120T000000, start_date=, end_date=20240122T005748# airflow tasks test zeppelin_integration run_zeppelin_notebook 20240122
[2024-01-22T09:01:43.665+0800] {dagbag.py:538} INFO - Filling up the DagBag from /root/airflow/dags
[2024-01-22T09:01:45.835+0800] {taskinstance.py:1957} INFO - Dependencies all met for dep_context=non-requeueable deps ti=<TaskInstance: zeppelin_integration.run_zeppelin_notebook __airflow_temporary_run_2024-01-22T01:01:45.733341+00:00__ [None]>
[2024-01-22T09:01:45.843+0800] {taskinstance.py:1957} INFO - Dependencies all met for dep_context=requeueable deps ti=<TaskInstance: zeppelin_integration.run_zeppelin_notebook __airflow_temporary_run_2024-01-22T01:01:45.733341+00:00__ [None]>
[2024-01-22T09:01:45.844+0800] {taskinstance.py:2171} INFO - Starting attempt 1 of 2
[2024-01-22T09:01:45.844+0800] {taskinstance.py:2250} WARNING - cannot record queued_duration for task run_zeppelin_notebook because previous state change time has not been saved
[2024-01-22T09:01:45.845+0800] {taskinstance.py:2192} INFO - Executing <Task(BashOperator): run_zeppelin_notebook> on 2024-01-22T00:00:00+00:00
[2024-01-22T09:01:45.904+0800] {taskinstance.py:2481} INFO - Exporting env vars: AIRFLOW_CTX_DAG_OWNER='airflow' AIRFLOW_CTX_DAG_ID='zeppelin_integration' AIRFLOW_CTX_TASK_ID='run_zeppelin_notebook' AIRFLOW_CTX_EXECUTION_DATE='2024-01-22T00:00:00+00:00' AIRFLOW_CTX_TRY_NUMBER='1' AIRFLOW_CTX_DAG_RUN_ID='__airflow_temporary_run_2024-01-22T01:01:45.733341+00:00__'
[2024-01-22T09:01:45.909+0800] {subprocess.py:63} INFO - Tmp dir root location: /tmp
[2024-01-22T09:01:45.910+0800] {subprocess.py:75} INFO - Running command: ['/bin/bash', '-c', 'curl -X POST -HContent-Type:application/json http://100.100.30.220:8181/api/notebook/run/2JND7T68E/paragraph_1705372327640_1111015359']
[2024-01-22T09:01:45.921+0800] {subprocess.py:86} INFO - Output:
[2024-01-22T09:01:45.931+0800] {subprocess.py:93} INFO - % Total % Received % Xferd Average Speed Time Time Time Current
[2024-01-22T09:01:45.931+0800] {subprocess.py:93} INFO - Dload Upload Total Spent Left Speed
100 50 100 50 0 0 8 0 0:00:06 0:00:06 --:--:-- 12
[2024-01-22T09:01:52.003+0800] {subprocess.py:93} INFO - {"status":"OK","body":{"code":"SUCCESS","msg":[]}}
[2024-01-22T09:01:52.003+0800] {subprocess.py:97} INFO - Command exited with return code 0
[2024-01-22T09:01:52.098+0800] {taskinstance.py:1138} INFO - Marking task as SUCCESS. dag_id=zeppelin_integration, task_id=run_zeppelin_notebook, execution_date=20240122T000000, start_date=, end_date=20240122T010152最后用命令airflow scheduler将它添加到airflow里。
# airflow scheduler____________ _________________ |__( )_________ __/__ /________ __
____ /| |_ /__ ___/_ /_ __ /_ __ \_ | /| / /
___ ___ | / _ / _ __/ _ / / /_/ /_ |/ |/ /_/_/ |_/_/ /_/ /_/ /_/ \____/____/|__/
[2024-01-22T09:28:21.829+0800] {task_context_logger.py:63} INFO - Task context logging is enabled
[2024-01-22T09:28:21.831+0800] {executor_loader.py:115} INFO - Loaded executor: SequentialExecutor
[2024-01-22T09:28:21.868+0800] {scheduler_job_runner.py:808} INFO - Starting the scheduler
[2024-01-22T09:28:21.869+0800] {scheduler_job_runner.py:815} INFO - Processing each file at most -1 times
。。。
页面上会增加一个DAG,如图:

在Actions里可以点击执行。
总结
以上就是今天要讲的内容,总体来说集成两个工具还是很方便的,期待后面更多的应用。
相关文章:
Apache Zeppelin结合Apache Airflow使用1
Apache Zeppelin结合Apache Airflow使用1 文章目录 Apache Zeppelin结合Apache Airflow使用1前言一、安装Airflow二、使用步骤1.目标2.编写DAG2.加载、执行DAG 总结 前言 之前学了Zeppelin的使用,今天开始结合Airflow串任务。 Apache Airflow和Apache Zeppelin是两…...

分组循环A
模板 i 0 while(i<n){start iwhile( i<n && check(args) ) {i1} }1. LC 3011 判断一个数组是否可以变为有序 这题我比赛时用的并查集。看灵神视频学了个分组循环的做法。 对于每个分组,如果可以交换,则扩展分组的窗口,直至…...

《WebKit 技术内幕》学习之九(4): JavaScript引擎
4 实践——高效的JavaScript代码 4.1 编程方式 关于如何使用JavaScript语言来编写高效的代码,有很多铺天盖地的经验分享,以及很多特别好的建议,读者可以搜索相关的词条,就能获得一些你可能需要的结果。同时,本节希望…...

[SpringBoot2.6.13]FastJsonHttpMessageConverter不生效
文章目录 错误描述问题分析打印目前所有的消息处理器寻找适配版本消息解释器加载顺序 错误原因正确写法使用最新版本fastjson(2024-1-22)配置fastjson2消息转换器(保留系统原消息转换器)替换消息转换器配置fastjson2 错误描述 采用Bean的方式配置FastJsonHttpMessageConverter…...
 Object Pascal 学习笔记---第3章第一节(简单语句与复合语句))
(delphi11最新学习资料) Object Pascal 学习笔记---第3章第一节(简单语句与复合语句)
Object Pascal 学习笔记,Delphi 11 编程语言的完整介绍 作者: Marco Cantu 笔记:豆豆爸 3.1 简单语句与复合语句 编程指令通常称为语句。一个程序块可以由多个语句组成。有两种类型的语句,简单语句和复合语句。当语句不包含任何其他子语…...

Unity - 简单音频
“Test_04” AudioTest public class AudioTest : MonoBehaviour {// 声明音频// AudioClippublic AudioClip music;public AudioClip se;// 声明播放器组件private AudioSource player;void Start(){// 获取播放器组件player GetComponent<AudioSource>();// 赋值…...

SpringCloud中服务间通信(应用间通信)-亲测有效-源码下载-连载2
1、微服务概述 本案例主要解决微服务之间的相互调用问题 如果已经理解什么是微服务,可以直接跳到实战。 本案例采用springBoot3.1.7springCloud2022.0.4版本测试 本案例使用springboot2.7.x版本测试代码相同 1、微服务是分布式架构,那么为什么要需要…...
Axios取消请求:AbortController
AbortController AbortController() 构造函数创建了一个新的 AbortController 实例。MDN官网给出了一个利用AbortController取消下载视频的例子。 核心逻辑是:利用AbortController接口的只读属性signal标记fetch请求;然后在需要取消请求的时候࿰…...

【江科大】STM32:(超级详细)定时器输出比较
文章目录 输出比较单元特点 高级定时器:均有4个通道 PWM简介PWM(Pulse Width Modulation)脉冲宽度调制输出比较通道PWM基本结构基本定时器 参数计算捕获/比较通道的输出部分详细介绍如下: 舵机介绍硬件电路 直流电机介绍ÿ…...
Go 复合数据类型
1. 数组(array)(OK) 数组数组的概念数组是具有固定长度且拥有零个或多个相同数据类型元素的序列 i. 元素的数据类型相同 ii. 长度固定的序列 iii. 零个或多个元素的序列 与 slice 对比 由于数组的长度固定,所以在 G…...

Redis(01)——常用指令
基础指令 select 数字:切换到其他数据库flushdb:清空当前数据库flushall:清空所有数据库dbsize:查看数据库大小exists key1[key2 …]:判断当前的key是否存在keys *:查看所有的keyexpire key 时间ÿ…...
基本语法和 package 与 jar
3.基本语法 1.输入输出 // 导入 java.util 包中的 Scanner 类 import java.util.Scanner;// 定义名为 ScannerExample 的公共类 public class ScannerExample {// 主方法,程序的入口点public static void main(String[] args) {// 创建 Scanner 对象,用…...
本地读取Excel文件并进行数据压缩传递到服务器
在项目开发过程中,读取excel文件,可能存在几百或几百万条数据内容,那么对于大型文件来说,我们应该如何思考对于大型文件的读取操作以及性能的注意事项。 类库:Papa Parse - Powerful CSV Parser for JavaScript 第一步…...

【开源】基于JAVA的停车场收费系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 停车位模块2.2 车辆模块2.3 停车收费模块2.4 IC卡模块2.5 IC卡挂失模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 停车场表3.2.2 车辆表3.2.3 停车收费表3.2.4 IC 卡表3.2.5 IC 卡挂失表 四、系统实现五、核心代码…...
基于java+Springboot操作系统教学交流平台详细设计实现
基于javaSpringboot操作系统教学交流平台详细设计实现 🍅 作者主页 央顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各种定制系统…...
Nginx 基础使用
目录结构 进入Nginx的主目录我们可以看到这些文件夹 client_body_temp conf fastcgi_temp html logs proxy_temp sbin scgi_temp uwsgi_temp其中这几个文件夹在刚安装后是没有的,主要用来存放运行过程中的临时文件 client_body_temp fastcgi_temp proxy_temp scg…...

JavaEE:多线程(2):线程状态,线程安全
目录 线程状态 线程安全 线程不安全 加锁 互斥性 可重入 死锁 死锁的解决方法 Java标准库中线程安全类 内存可见性引起的线程安全问题 等待和通知机制 线程饿死 wait notify 线程状态 就绪:线程随时可以去CPU上执行,也包含在CPU上执行的…...
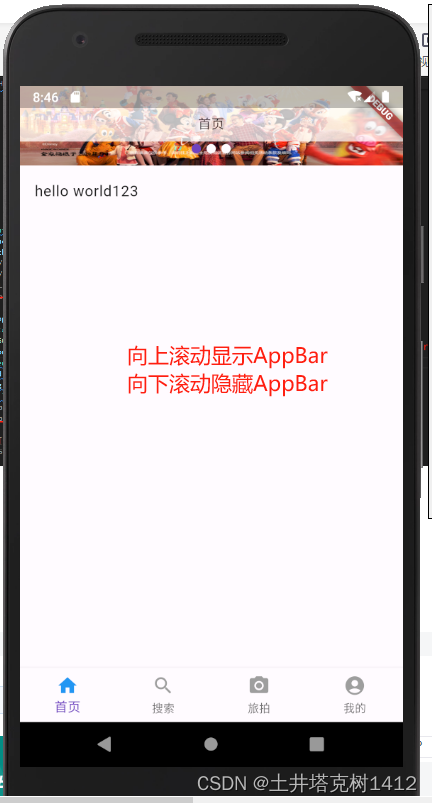
Flutter 自定义AppBar实现滚动渐变
1、使用ListView实现上下滚动。 2、使用Stack:允许将其子部件放在彼此的顶部,第一个子部件将放置在底部。所以AppBar,写在ListView下面。 3、MediaQuery.removePadding:当使用ListView的时候发现,顶部有块默认的Padd…...

编程语言MoonBit新增矩阵函数的语法糖
MoonBit更新 1. 新增矩阵函数的语法糖 新增矩阵函数的语法糖,用于方便地定义局部函数和具有模式匹配的匿名函数: fn init {fn boolean_or { // 带有模式匹配的局部函数true, _ > true_, true > true_, _ > false}fn apply(f, x) {f(x)}le…...

Angular:跨域请求携带 cookie
新建拦截器,设置 XMLHttpRequest:withCredentials 属性 1. 新建文件夹 http-interceptors 该文件夹下可有多个不同用途的拦截器2. 新建拦截器 common.interceptor.ts import { HttpEvent, HttpHandler, HttpInterceptor, HttpRequest } from "an…...

【2026年5月16日最新】别再用Cursor了!这5款AI编程神器让我效率暴涨300%
2026年5月,AI编程工具迎来了史诗级更新潮。OpenAI发布GPT-5.5后,代码理解和工程重构能力达到历史最强;字节跳动Trae凭借全链路AI原生IDE和免费无限制政策迅速崛起;DeepSeek V4更是用极致算法效率撕开了算力铁幕 。作为一名每天和代…...

AI技能框架实战:构建可扩展的智能体工具调用系统
1. 项目概述:当AI技能成为你的私人助理 最近在折腾AI应用开发的朋友,可能都绕不开一个核心问题:如何让大语言模型(LLM)不只是个“聊天高手”,而是能真正帮你处理具体事务的“实干家”?比如&…...

如何解决Noah-MP陆面模型编译与配置中的三大技术挑战
如何解决Noah-MP陆面模型编译与配置中的三大技术挑战 【免费下载链接】NoahMP 项目地址: https://gitcode.com/gh_mirrors/no/NoahMP Noah-MP(Noah with Multi-Parameterization options)作为先进的陆面过程模型,在水文循环模拟、能量…...

智慧树网课自动化学习插件:三步告别手动刷课的完整指南
智慧树网课自动化学习插件:三步告别手动刷课的完整指南 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台冗长的网课视频而烦恼吗࿱…...

基于PyPortal与CircuitPython的桌面空气质量监测站DIY指南
1. 项目概述:打造你的桌面级空气质量监测站如果你和我一样,对身边的空气质量有点“强迫症”,总想知道窗外空气到底怎么样,但又不想总去翻手机App,那么这个项目就是为你量身定做的。我们将利用一块名为PyPortal的开发板…...
)
Aspose全家桶实战:从零构建一个.NET 6的文档转换微服务(含Docker部署)
Aspose全家桶实战:从零构建.NET 6文档转换微服务 在数字化转型浪潮中,企业文档处理需求正经历从碎片化到集中化的转变。传统单体应用中分散的Word转PDF、Excel报表生成等功能,不仅难以维护,更无法适应云原生时代对弹性伸缩和高可用…...

钉钉机器人消息解析器:基于JSON Path与模板的自动化数据提取方案
1. 项目概述:一个钉钉消息解析器的诞生最近在做一个内部自动化工具时,遇到了一个挺有意思的需求:需要把钉钉机器人推送过来的消息,从原始的、结构复杂的JSON格式里,精准地“抠”出我们关心的业务数据。比如,…...

5个技巧快速掌握Happy Island Designer:免费在线岛屿设计工具终极指南
5个技巧快速掌握Happy Island Designer:免费在线岛屿设计工具终极指南 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(A…...

助力销售会议转任务,识别准整理快,任务清晰更省心
2026年做销售,若仍靠手写整理销售会议转任务,很容易面临客户信息漏记、整理效率偏低的问题,管理层要求提效并提供可量化改善方案时,也难以快速响应。AI助力销售会议转任务,可有效解决这类困扰,提升识别准确…...

Python锚点链接解析利器pyanchor:高效处理HTML/Markdown文档内部链接
1. 项目概述:一个Python实现的锚点链接解析利器最近在整理一个大型文档项目时,遇到了一个挺头疼的问题:我需要从成千上万个Markdown文件中,批量提取所有指向文档内部特定章节的锚点链接,并验证这些链接是否有效。手动操…...