Lesson12---人工神经网络(1)
12.1 神经元与感知机
12.1.1 感知机
感知机: 1957, Fank Rosenblatt

由两层神经元组成,可以简化为右边这种,输入通常不参与计算,不计入神经网络的层数,因此感知机是一个单层神经网络
- 感知机
训练法则(Perceptron Training Rule)

- 使用感知机训练法则,能够根据训练样本的标签值和感知机输出之间的误差,来自动的调整权值,具备学习能力
- 第一个用算法来精确定义的神经网络模型
- 线性二分类的分类器,分类决策边界为直线(2v)、平面(3v)、超平面(多维)
- 感知机算法存在多个解,受到权值向量初始值,错误样本顺序的影响
- 对于非线性可分得数据集,感知机训练法则无法收敛,迭代结果会一直震荡。
- 为了克服非线性数据集无法收敛的情况,提出了delta法则
12.1.2 Delta法则
- Delta法则:使用梯度下降法,找到能够最佳拟合训练样本集的权向量
- 逻辑回归可以看作是最简单的单层神经网络,单个感知机只有一个输出节点,只能实现二分类问题
12.2 实例: 单层神经网络实现鸢尾花分类
- 这里我们使用神经网络的思想来实现对鸢尾花的分类,这个程序的实现过程和sofmax回归几乎是完全一样的,我们只是从设计和实现神经网络的角度重新描述这个过程
12.2.1 神经网络的设计
- 设计
- 首先设计 神经网络的结构,确定神经网络有几层,每层中有几个节点,节点间是如何连接的。
- 使用什么激活函数
- 使用什么损失函数
- 选择
- 选择单层前馈型神经网络的结构,实现对鸢尾花的分类,输入节点的个数由属性的个数决定,输出曾节点个数由分类类别的个数决定

- 因为是分类问题,所以选择softmax函数作为激活函数,标签值使用独热编码来表示
- 使用交叉熵损失函数来计算误差
12.2.2 神经网络的实现

前面为了简化编程,将B融入w,为

在本节中,我们将W和b分离开来,单独表示,这是考虑到后面实现多层神经网络时,编程更加直观
12.2.3 神经网络的实现的重要函数
12.2.3.1 softmax函数
tf.nn.softmax()
对于Y=XW+BY=XW+BY=XW+B
tf.nn.softmax(tf.matmul(X_train,W)+b)
12.2.3.2 独热编码-tf.one_hot()
tf.one_hot(indices,depth)
- indices:要求是一个整数
- depth:独热编码的深度
对于该例鸢尾花数据
tf.one_hot(tf.constant(y_test,dtype=tf.int32),3)
12.2.3.3 交叉熵损失函数-tf.keras.losses.categorical_crossentropy()
使用其自带的来实现
tf.keras.losses.categorical_crossentropy(y_true,y_pred)
- y_true :表示独热编码的标签值
- y_pred:softmax函数的输出
- 该函数的结果时一个一维张量,其中的每一个元素是每个样本的交叉熵损失,使用求平均值函数得到平均交叉熵损失
tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=PRED_train))
12.2.4 完整的程序实现
12.2.4.1 导入库
- InternalError: Bias GEMM launch failed报错解决如下
# 1 导入库
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 在使用GPU版本的Tensorflow训练模型时,有时候会遇到显存分配的错误
# InternalError: Bias GEMM launch failed
# 这是在调用GPU运行程序时,GPU的显存空间不足引起的,为了避免这个错误,可以对GPU的使用模式进行设置
gpus = tf.config.experimental.list_physical_devices('GPU')# 这是列出当前系统中的所有GPU,放在列表gpus中
# 使用第一块gpu,所以是gpus[0],把它设置为memory_growth模式,允许内存增长也就是说在程序运行过程中,根据需要为TensoFlow进程分配显存
# 如果系统中有多个GPU,可以使用循环语句把它们都设置成为true模式
tf.config.experimental.set_memory_growth(gpus[0], True)
12.2.4.2 加载数据
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)
test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1],TEST_URL)df_iris_train = pd.read_csv(train_path, header=0)
df_iris_test = pd.read_csv(test_path, header=0)iris_train = np.array(df_iris_train) # (120,5)
iris_train = np.array(df_iris_test) # (30 5)
12.2.4.3 数据预处理
# 3 数据预处理
x_train = iris_train[:,0:4] # (120,4)
y_train = iris_train[:,4] # (120,)x_test = iris_test[:,0:4] # (30,4)
y_test = iris_test[:,4] # (30,)
# 以上4个数据都是64位浮点数('float64')# 对属性值进行标准化处理,使它均值为0
x_train = x_train - np.mean(x_train, axis=0)
x_test = x_test - np.mean(x_test, axis=0)X_train = tf.cast(x_train,tf.float32)
Y_train = tf.one_hot(tf.costant(y_train,dtype=tf.int32),3)X_test = tf.cast(x_test,tf.float32)
Y_test = tf.one_hot(tf.constant(y_test,dtype=tf.int32),3)
# 以上4个数据都是float32形式的tensorflow的张量
12.2.4.4 设置超参数和显示间隔
# 4 设置超参数和显示间隔
learn_rate = 0.5
iter = 50display_step = 10
12.2.4.5 设置模型参数初始值
# 5 设置模型参数初始值
np.random.seed(612)
W = tf.Variable(np.random.randn(4,3),dtype=tf.float32)# W为4行3列的二维张量,取正态分布的随机值
B = tf.Variable(np.zeros([3]),dtype=tf.float32) # B为长度为3的一维张量,在神经网络中,初始化为0
12.2.4.6 训练模型
# 6 训练模型# 准确率
acc_train=[]
acc_test=[]
# 交叉熵损失
cce_train=[]
cce_test=[]for i in range(0,iter+1):with tf.GradientTape() as tape:PRED_train = tf.nn.softmax(tf.matmul(X_train,W)+B) # 激活函数为S函数Loss_train = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=PRED_train)) # 训练集的交叉熵损失PRED_test = tf.nn.softmax(tf.matmul(X_test,W)+B)Loss_test = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test,y_pred=PRED_test)) # 测试集的交叉熵损失accuracy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_train.numpy(),axis=1),y_train),tf.float32))accuracy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_test.numpy(),axis=1),y_test),tf.float32))acc_train.append(accuracy_train)acc_test.append(accuracy_test)cce_train.append(Loss_train)cce_test.append(Loss_test)grads = tape.gradient(Loss_train,[W,B])W.assign_sub(learn_rate*grads[0])B.assign_sub(learn_rate*grads[1])if i % display_step == 0:print("i: %i,TrainAcc:%f, TrainLoss:%f,TestAcc:%f,TestLoss:%f" % (i,accuracy_train,Loss_train,accuracy_test,Loss_test))
运行结果:
i: 0,TrainAcc:0.333333, TrainLoss:2.066978,TestAcc:0.266667,TestLoss:1.880856
i: 10,TrainAcc:0.875000, TrainLoss:0.339410,TestAcc:0.866667,TestLoss:0.461705
i: 20,TrainAcc:0.875000, TrainLoss:0.279647,TestAcc:0.866667,TestLoss:0.368414
i: 30,TrainAcc:0.916667, TrainLoss:0.245924,TestAcc:0.933333,TestLoss:0.314814
i: 40,TrainAcc:0.933333, TrainLoss:0.222922,TestAcc:0.933333,TestLoss:0.278643
i: 50,TrainAcc:0.933333, TrainLoss:0.205636,TestAcc:0.966667,TestLoss:0.251937
12.2.4.7 可视化
# 7 结果可视化
plt.figure(figsize=(10,3))plt.subplot(121)
plt.plot(cce_train,c='b',label="train")
plt.plot(cce_test,c='r',label="test")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.legend()plt.subplot(122)
plt.plot(acc_train,c='b',label="train")
plt.plot(acc_test,c='r',label="test")
plt.xlabel("Iteration")
plt.ylabel("Accuracy")
plt.legend()plt.show()
输出结果:

12.2.4.8 完整程序
# 1 导入库
from sys import displayhook
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 在使用GPU版本的Tensorflow训练模型时,有时候会遇到显存分配的错误
# InternalError: Bias GEMM launch failed
# 这是在调用GPU运行程序时,GPU的显存空间不足引起的,为了避免这个错误,可以对GPU的使用模式进行设置
gpus = tf.config.experimental.list_physical_devices('GPU')# 这是列出当前系统中的所有GPU,放在列表gpus中
# 使用第一块gpu,所以是gpus[0],把它设置为memory_growth模式,允许内存增长也就是说在程序运行过程中,根据需要为TensoFlow进程分配显存
# 如果系统中有多个GPU,可以使用循环语句把它们都设置成为true模式
tf.config.experimental.set_memory_growth(gpus[0], True)# 2 加载数据TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)
test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1],TEST_URL)df_iris_train = pd.read_csv(train_path, header=0)
df_iris_test = pd.read_csv(test_path, header=0)iris_train = np.array(df_iris_train) # (120,5)
iris_test = np.array(df_iris_test) # (30 5)# 3 数据预处理
x_train = iris_train[:,0:4] # (120,4)
y_train = iris_train[:,4] # (120,)x_test = iris_test[:,0:4] # (30,4)
y_test = iris_test[:,4] # (30,)
# 以上4个数据都是64位浮点数('float64')# 对属性值进行标准化处理,使它均值为0
x_train = x_train - np.mean(x_train, axis=0)
x_test = x_test - np.mean(x_test, axis=0)X_train = tf.cast(x_train,tf.float32)
Y_train = tf.one_hot(tf.constant(y_train,dtype=tf.int32),3)X_test = tf.cast(x_test,tf.float32)
Y_test = tf.one_hot(tf.constant(y_test,dtype=tf.int32),3)
# 以上4个数据都是float32形式的tensorflow的张量# 4 设置超参数和显示间隔
learn_rate = 0.5
iter = 50display_step = 10# 5 设置模型参数初始值
np.random.seed(612)
W = tf.Variable(np.random.randn(4,3),dtype=tf.float32)# W为4行3列的二维张量,取正态分布的随机值
B = tf.Variable(np.zeros([3]),dtype=tf.float32) # B为长度为3的一维张量,在神经网络中,初始化为0# 6 训练模型# 准确率
acc_train=[]
acc_test=[]
# 交叉熵损失
cce_train=[]
cce_test=[]for i in range(0,iter+1):with tf.GradientTape() as tape:PRED_train = tf.nn.softmax(tf.matmul(X_train,W)+B) # 激活函数为S函数Loss_train = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=PRED_train)) # 训练集的交叉熵损失PRED_test = tf.nn.softmax(tf.matmul(X_test,W)+B)Loss_test = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test,y_pred=PRED_test)) # 测试集的交叉熵损失accuracy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_train.numpy(),axis=1),y_train),tf.float32))accuracy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_test.numpy(),axis=1),y_test),tf.float32))acc_train.append(accuracy_train)acc_test.append(accuracy_test)cce_train.append(Loss_train)cce_test.append(Loss_test)grads = tape.gradient(Loss_train,[W,B])W.assign_sub(learn_rate*grads[0])B.assign_sub(learn_rate*grads[1])if i % display_step == 0:print("i: %i,TrainAcc:%f, TrainLoss:%f,TestAcc:%f,TestLoss:%f" % (i,accuracy_train,Loss_train,accuracy_test,Loss_test))# 7 结果可视化
plt.figure(figsize=(10,3))plt.subplot(121)
plt.plot(cce_train,c='b',label="train")
plt.plot(cce_test,c='r',label="test")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.legend()plt.subplot(122)
plt.plot(acc_train,c='b',label="train")
plt.plot(acc_test,c='r',label="test")
plt.xlabel("Iteration")
plt.ylabel("Accuracy")
plt.legend()plt.show()
12.3多层神经网络


12.3.1多层神经网络














12.3.2超参数和验证集




12.4误差反向传播法















12.5激活函数










12.6 实例:多层神经网络实现鸢尾花分类

# 1 导入库
from sys import displayhook
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 在使用GPU版本的Tensorflow训练模型时,有时候会遇到显存分配的错误
# InternalError: Bias GEMM launch failed
# 这是在调用GPU运行程序时,GPU的显存空间不足引起的,为了避免这个错误,可以对GPU的使用模式进行设置
gpus = tf.config.experimental.list_physical_devices('GPU')# 这是列出当前系统中的所有GPU,放在列表gpus中
# 使用第一块gpu,所以是gpus[0],把它设置为memory_growth模式,允许内存增长也就是说在程序运行过程中,根据需要为TensoFlow进程分配显存
# 如果系统中有多个GPU,可以使用循环语句把它们都设置成为true模式
tf.config.experimental.set_memory_growth(gpus[0], True)# 2 加载数据TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)
test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1],TEST_URL)df_iris_train = pd.read_csv(train_path, header=0)
df_iris_test = pd.read_csv(test_path, header=0)iris_train = np.array(df_iris_train) # (120,5)
iris_test = np.array(df_iris_test) # (30 5)# 3 数据预处理
x_train = iris_train[:,0:4] # (120,4)
y_train = iris_train[:,4] # (120,)x_test = iris_test[:,0:4] # (30,4)
y_test = iris_test[:,4] # (30,)
# 以上4个数据都是64位浮点数('float64')# 对属性值进行标准化处理,使它均值为0
x_train = x_train - np.mean(x_train, axis=0)
x_test = x_test - np.mean(x_test, axis=0)X_train = tf.cast(x_train,tf.float32)
Y_train = tf.one_hot(tf.constant(y_train,dtype=tf.int32),3)X_test = tf.cast(x_test,tf.float32)
Y_test = tf.one_hot(tf.constant(y_test,dtype=tf.int32),3)
# 以上4个数据都是float32形式的tensorflow的张量# 4 设置超参数和显示间隔
learn_rate = 0.5
iter = 50display_step = 10# 5 设置模型参数初始值
np.random.seed(612)
W1 = tf.Variable(np.random.randn(4,16),dtype=tf.float32)# W1为4行16列的二维张量,取正态分布的随机值
B1 = tf.Variable(np.zeros([16]),dtype=tf.float32) # B1为长度为16的一维张量,在神经网络中,初始化为0
W2 = tf.Variable(np.random.randn(16,3),dtype=tf.float32)# W2为16行3列的二维张量,取正态分布的随机值
B2 = tf.Variable(np.zeros([3]),dtype=tf.float32) # B2为长度为3的一维张量,在神经网络中,初始化为0
# 6 训练模型# 准确率
acc_train=[]
acc_test=[]
# 交叉熵损失
cce_train=[]
cce_test=[]for i in range(0,iter+1):with tf.GradientTape() as tape:Hidden_train = tf.nn.relu(tf.matmul(X_train,W1)+B1)PRED_train = tf.nn.softmax(tf.matmul(Hidden_train,W2)+B2) # 激活函数为S函数Loss_train = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=PRED_train)) # 训练集的交叉熵损失
#tf.keras.losses.categorical_crossentropy(y_true, y_pred)语句表示通过调用tf.keras库中的交叉熵损失函数计算标签值与预测值之间的误差。Hidden_test = tf.nn.relu(tf.matmul(X_test,W1)+B1)PRED_test = tf.nn.softmax(tf.matmul(Hidden_test,W2)+B2)Loss_test = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test,y_pred=PRED_test))# 这里也可以选择不放在with语句里面,因为我们只选择了训练数据更新梯度accuracy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_train.numpy(),axis=1),y_train),tf.float32))accuracy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_test.numpy(),axis=1),y_test),tf.float32))acc_train.append(accuracy_train)acc_test.append(accuracy_test)cce_train.append(Loss_train)cce_test.append(Loss_test)grads = tape.gradient(Loss_train,[W1,B1,W2,B2])W1.assign_sub(learn_rate*grads[0])B1.assign_sub(learn_rate*grads[1])W2.assign_sub(learn_rate*grads[2])B2.assign_sub(learn_rate*grads[3])if i % display_step == 0:print("i: %i,TrainAcc:%f, TrainLoss:%f,TestAcc:%f,TestLoss:%f" % (i,accuracy_train,Loss_train,accuracy_test,Loss_test))# 7 结果可视化
plt.figure(figsize=(10,3))plt.subplot(121)
plt.plot(cce_train,c='b',label="train")
plt.plot(cce_test,c='r',label="test")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.legend()plt.subplot(122)
plt.plot(acc_train,c='b',label="train")
plt.plot(acc_test,c='r',label="test")
plt.xlabel("Iteration")
plt.ylabel("Accuracy")
plt.legend()plt.show()输出结果为
i: 0,TrainAcc:0.433333, TrainLoss:2.205641,TestAcc:0.400000,TestLoss:1.721138
i: 10,TrainAcc:0.941667, TrainLoss:0.205314,TestAcc:0.966667,TestLoss:0.249661
i: 20,TrainAcc:0.950000, TrainLoss:0.149540,TestAcc:1.000000,TestLoss:0.167103
i: 30,TrainAcc:0.958333, TrainLoss:0.122346,TestAcc:1.000000,TestLoss:0.124693
i: 40,TrainAcc:0.958333, TrainLoss:0.105099,TestAcc:1.000000,TestLoss:0.099869
i: 50,TrainAcc:0.958333, TrainLoss:0.092934,TestAcc:1.000000,TestLoss:0.084885

相关文章:
Lesson12---人工神经网络(1)
12.1 神经元与感知机 12.1.1 感知机 感知机: 1957, Fank Rosenblatt 由两层神经元组成,可以简化为右边这种,输入通常不参与计算,不计入神经网络的层数,因此感知机是一个单层神经网络 感知机 训练法则&am…...
)
算法练习-排序(二)
算法练习-排序(二) 文章目录算法练习-排序(二)1 合并排序的数组1.1 题目1.2 题解2 有效的字母异位词2.1 题目2.2 题解3 判断能否形成等差数列3.1 题目3.2 题解4 合并区间4.1 题目3.2 题解5 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面5.1 题目5.2 题解6 颜色分类6.1 题目6.…...

202302读书笔记|《长安的荔枝》——只要肯努力,办法总比困难多
202302读书笔记|《长安的荔枝》——只要肯努力,办法总比困难多 《长安的荔枝》这本书真是酣畅淋漓啊,读起来一气呵成,以讲故事的口吻叙述,上林署九品小官员——李善德,兢兢业业工作多年,终于借贷买了房&…...
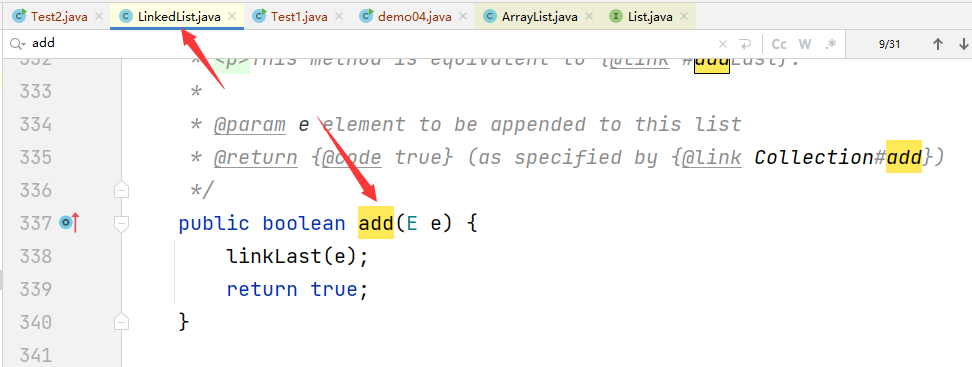
java封装继承多态详解
1.封装 所谓封装,就是将客观事物封装成抽象的类,并且类可以把数据和方法让可信的类或者对象进行操作,对不可信的类或者对象进行隐藏。类就是封装数据和操作这些数据代码的逻辑实体。在一个类的内部,某些属性和方法是私有的&#…...
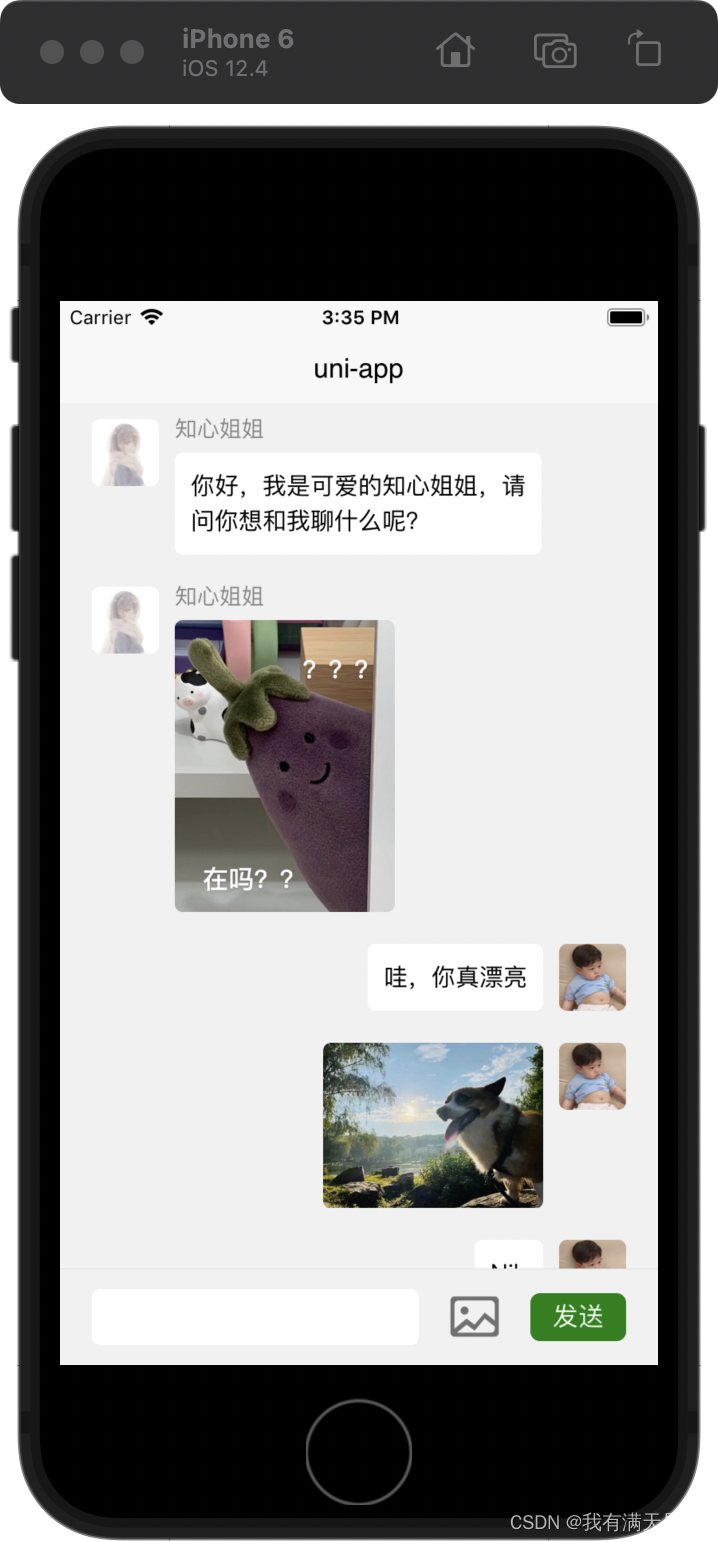
【uni-app教程】UniAPP 常用组件和 常用 API 简介# 知心姐姐聊天案例
五、UniAPP 常用组件简介 uni-app 为开发者提供了一系列基础组件,类似 HTML 里的基础标签元素,但 uni-app 的组件与 HTML 不同,而是与小程序相同,更适合手机端使用。 虽然不推荐使用 HTML 标签,但实际上如果开发者写了…...
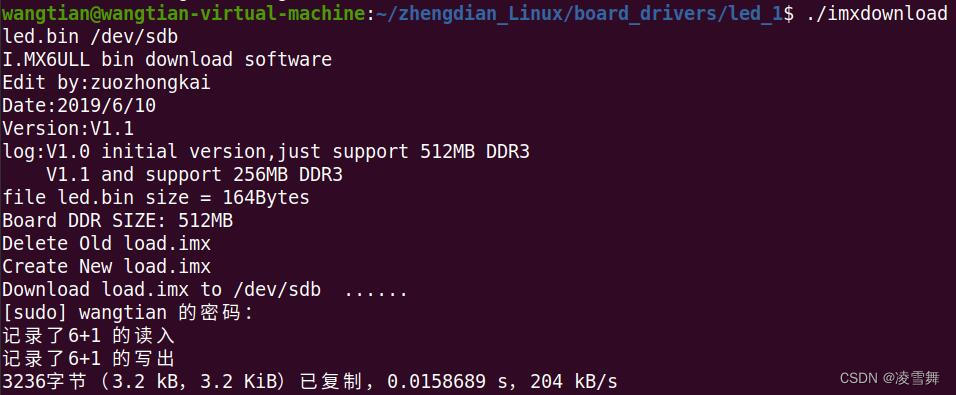
阿尔法开发板 .bin 文件烧写
一. IMX6ULL 开发板简介 IMX6ULL 开发板是正点原子提供的阿尔法开发板,所用芯片为恩智浦,基于 Cortex-A7 架构。 这里介绍一下裸机篇中,关于如何将 .bin 文件烧写进 SD 卡,从而设备运行程序。 二. xx.bin 文件烧写 IMX6ULL支…...
Ceres-Solver 安装与卸载ubuntu20.04
卸载 sudo rm -rf /usr/local/lib/cmake/Ceres /usr/local/include/ceres /usr/local/lib/libceres.a 安装 sudo apt-get install libatlas-base-dev libsuitesparse-dev git clone https://github.com/ceres-solver/ceres-solver cd ceres-solver git checkout $(git descr…...
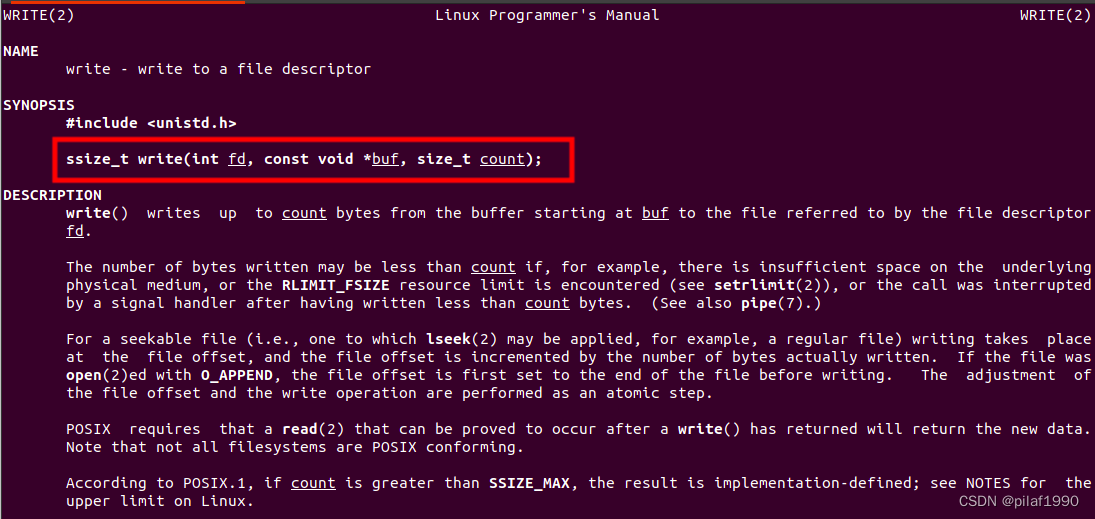
汇编系列02-借助操作系统输出Hello World
说明:本节的程序使用的是x86_64指令集的。 汇编语言是可以编译成机器指令的,机器指令是可以直接在CPU上面执行的。我们编写的汇编程序既可以直接在操作系统的帮助下执行,也可以绕过操作系统,直接在硬件上执行。 如果你打算编写的汇编程序在…...

【2023unity游戏制作-mango的冒险】-前六章API,细节,BUG总结小结
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 收录于专栏:unity游戏制作 ⭐mango的冒险前六章总结⭐ 文章目录⭐mango的冒险前六章总结⭐👨&a…...

进程控制及其操作
进程创建1.1 fork()函数1.2 fork()函数的返回值进程等待2.1 进程等待的必要性1.之前讲过,子进程退出,父进程如果不管不顾,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。 2.另外,进程一旦变成僵尸状态,那…...

Git常用命令复习笔记
1. Git与SVN区别,各自优缺点 Git: 分布式,每个参与开发的人的电脑上都有一个完整的仓库,不担心硬盘出问题;在不联网的情况下,照样可以提交到本地仓库,可以查看以往的所有log,等到有…...
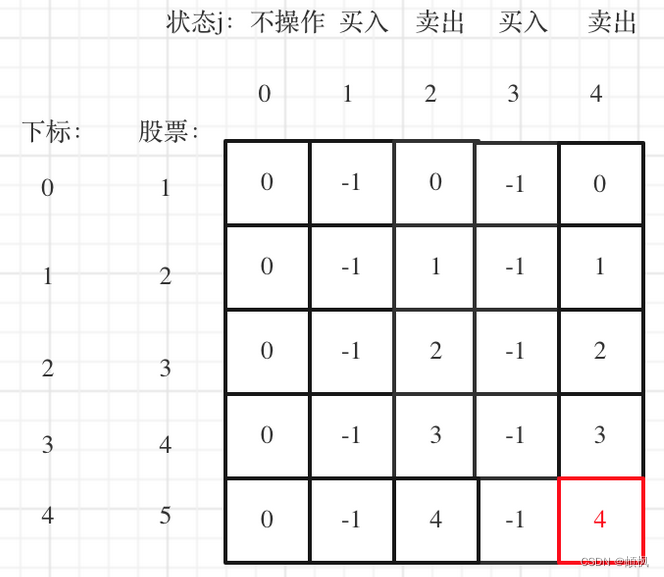
代码随想录算法训练营day49 | 动态规划 123.买卖股票的最佳时机III 188.买卖股票的最佳时机IV
day49123.买卖股票的最佳时机III1.确定dp数组以及下标的含义2.确定递推公式3.dp数组如何初始化4.确定遍历顺序5.举例推导dp数组188.买卖股票的最佳时机IV1.确定dp数组以及下标的含义2.确定递推公式4.dp数组如何初始化4.确定遍历顺序5.举例推导dp数组123.买卖股票的最佳时机III …...
【教学典型案例】14.课程推送页面整理-增加定时功能
目录一:背景介绍1、代码可读性差,结构混乱2、逻辑边界不清晰,封装意识缺乏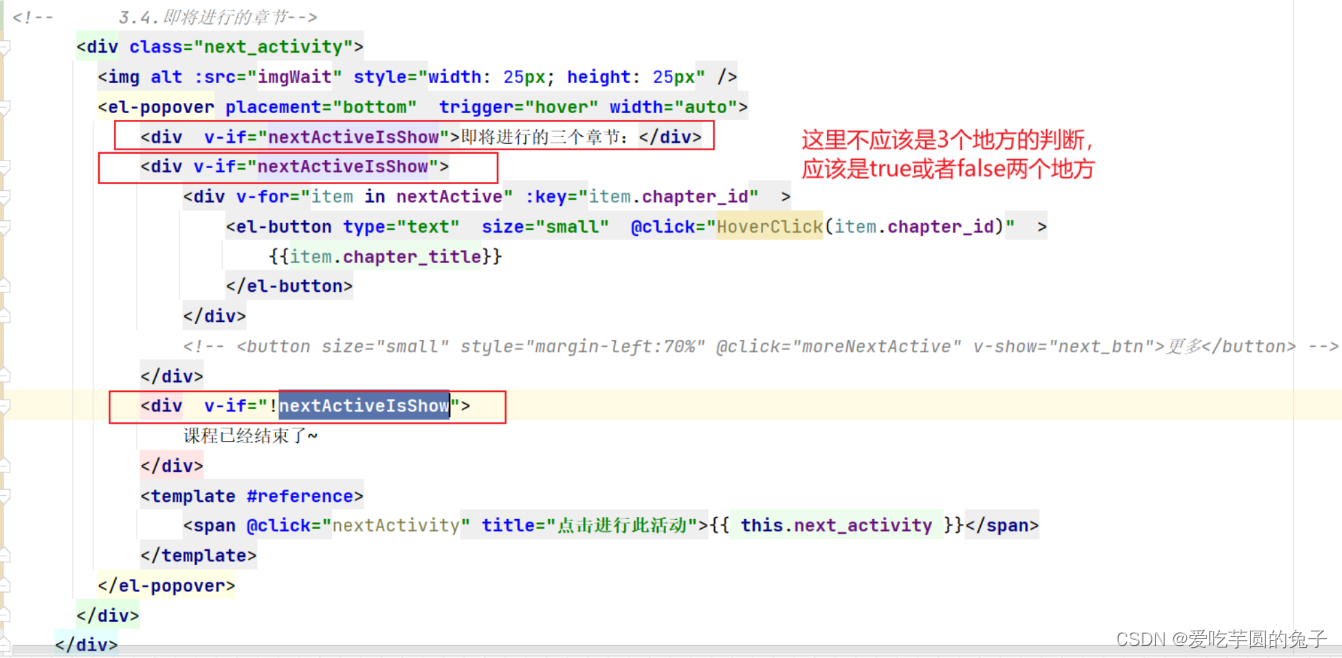3、展示效果不美观二:案例问题分析以及解决过程1、代码可读性…...

【算法基础】DFS BFS 进阶训练
DFS与BFS的基础篇详见:https://blog.csdn.net/m0_51339444/article/details/129301451?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129301451%22%2C%22source%22%3A%22m0_51339444%22%7D 一、案例分析1 (树的重心 —— D…...

GO语言中的回调函数
0.前言 回调函数是一种在编程中常见的技术,通常在异步编程中使用。简单来说,回调函数是一个被传递给另一个函数的函数,它在该函数的某个时间点被调用,以完成某些特定的操作或任务。 在Go语言中,可以将函数直接作为参…...
28个案例问题分析---014课程推送页面逻辑整理--vue
一:背景介绍 项目开发过程中,前端出现以下几类问题: 代码结构混乱代码逻辑不清晰页面细节问题 二:问题分析 代码结构混乱问题 <template><top/><div style"position: absolute;top: 10px"><C…...

佛科院单片机原理2——80C51单片机结构
一、程序存储器的入口地址:程序入口地址:0000H外部中断0入口地址:0003H定时器0溢出中断入口地址:000BH外部中断1入口地址:00013H定时器1溢出中断入口地址:001BH串行口中断入口地址:0023H定时器2…...

数据结构与算法_动态顺序表
顺序表是线性表的一种。 线性表是n个具有相同特性的数据元素的有限序列。 逻辑上,它们是线性结构,是一条连续的直线;但是在物理上,它们通常以数组和链式结构存储。 常见的线性表有顺序表、栈、队列、字符串等。 顺序表是用一段…...

逃避浏览器JS检测打开开发者工具
20230304 - 0. 引言 看到一些视频网站之后,想把视频离线下载下来怎么办?直接的方法是通过开发者工具来查看网络流量,一般可以在传输的请求类型中搜索m3u8,然后找到这部分请求,然后利用某些播放器或者下载器直接下载。…...
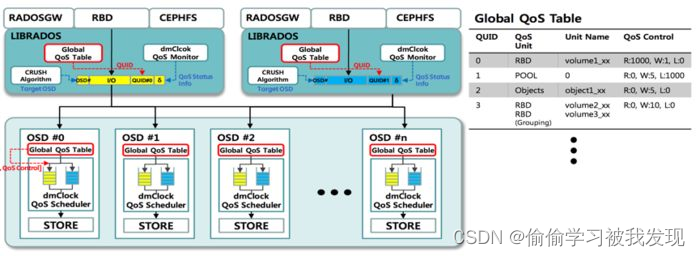
ceph介绍、原理、架构、算法...个人学习记录
前言 之前公司安排出差支援非结构化项目,采用springcloud(redismysql数据冷热处理)s3escephkafka还涉及一些区块链技术等等…,在与大佬的沟通交流下对ceph产生了兴趣,私下学习记录一下;后续工作之余会采用上面相关技术栈手动实现不…...

GyroFlow:用陀螺仪数据重塑视频稳定技术
GyroFlow:用陀螺仪数据重塑视频稳定技术 【免费下载链接】gyroflow Video stabilization using gyroscope data 项目地址: https://gitcode.com/GitHub_Trending/gy/gyroflow 在数字影像创作领域,画面稳定性直接决定作品专业度。无论是运动相机拍…...

2026年,山东专业联想服务器解决方案,涵盖SR858 V3等众多型号!
在当今数字化飞速发展的时代,服务器作为企业数据处理和存储的核心设备,其性能和可靠性至关重要。联想服务器凭借其卓越的性能、丰富的功能和广泛的应用场景,成为众多企业的首选。今天,我们就来详细了解一下联想SR858 V3服务器。联…...

5个Rust驱动特性解决存储清理难题:Czkawka技术深度解析
5个Rust驱动特性解决存储清理难题:Czkawka技术深度解析 【免费下载链接】czkawka Multi functional app to find duplicates, empty folders, similar images etc. 项目地址: https://gitcode.com/GitHub_Trending/cz/czkawka Czkawka是一款基于Rust语言开发…...

别再到处找了!这12个三维点云开源数据集,够你从入门到项目实战
三维点云实战指南:12个精选开源数据集与精准匹配策略 当你第一次打开三维点云处理软件,面对空白的项目界面,最迫切的问题往往是:"我该从哪里获取高质量的训练数据?"这个问题困扰过每一位初学者,…...

AI图像抠图新体验:cv_unet_image-matting参数调优全解析
AI图像抠图新体验:cv_unet_image-matting参数调优全解析 1. 引言:为什么需要专业抠图工具 在日常工作和生活中,我们经常需要处理图片——制作证件照、设计海报、编辑产品图等等。传统的手动抠图不仅耗时耗力,而且对技术要求高&a…...

终极指南:如何快速构建响应式React网格布局
终极指南:如何快速构建响应式React网格布局 【免费下载链接】react-grid-layout A draggable and resizable grid layout with responsive breakpoints, for React. 项目地址: https://gitcode.com/gh_mirrors/re/react-grid-layout React网格布局࿰…...
)
从零开始:在Unity中完美实现视频播放功能的完整指南(附常见报错解决方案)
从零开始:在Unity中完美实现视频播放功能的完整指南(附常见报错解决方案) 在游戏开发中,视频播放功能的应用场景越来越广泛——从开场动画、过场剧情到UI背景,视频元素能为玩家带来更丰富的视听体验。Unity作为主流的…...

避坑指南:在K210上跑人脸68关键点,这些细节让你的疲劳检测更准
K210人脸疲劳检测实战:68关键点调优与工程化避坑指南 当你在车载监控或工业安全场景部署基于K210的疲劳检测系统时,是否遇到过这些情况?明明按照开源代码跑通了68关键点检测,但实际场景中闭眼判断总是不准;白天阳光直射…...

cv_resnet101_face-detection_cvpr22papermogface 模型部署的网络安全考量:防范403 Forbidden等常见攻击
cv_resnet101_face-detection_cvpr22papermogface 模型部署的网络安全考量:防范403 Forbidden等常见攻击 把一个人脸检测模型,比如 cv_resnet101_face-detection_cvpr22papermogface,部署成一个Web API,这事儿听起来挺酷的。想象…...

Psins实战:从零解析SINS/GPS松组合导航中的Kalman滤波器初始化与调参
1. 初识SINS/GPS松组合导航与Kalman滤波 刚接触导航算法的朋友可能会被"SINS/GPS松组合"这个术语吓到,其实拆开看很简单。SINS(捷联惯性导航系统)就像是个不知疲倦的计步器,通过IMU(惯性测量单元)…...