Java入门高频考查基础知识4(字节跳动面试题18题2.5万字参考答案)
Java 是一种广泛使用的面向对象编程语言,在软件开发领域有着重要的地位。Java 提供了丰富的库和强大的特性,适用于多种应用场景,包括企业应用、移动应用、嵌入式系统等。
以下是几个面试技巧:
1. 复习核心概念:回顾 Java 的核心概念,如面向对象编程、类和对象、继承和多态、异常处理、集合框架等。确保对这些基础知识有清晰的理解。
2. 熟悉常见问题:预测并准备常见的面试问题,如 "什么是 Java 的封装、继承和多态?","什么是抽象类和接口?它们的区别是什么?" 等。熟悉这些问题的答案,以便能够流利、清晰地回答面试官的提问。
3. 编码实践:练习编写一些简单的 Java 代码,以加深对基础概念的理解。尝试解决一些常见的编程问题,如逆序字符串、查找数组中的最大值等。这将有助于您在面试中展示自己的编码能力。
4. 项目经验准备:复习您在 Java 开发方面的项目经验。准备一些项目细节和亮点,强调您在项目中所承担的角色和技术贡献。面试官通常会关注您的项目经验,因此务必能够清晰而有条理地介绍您的项目经历。
5. 注意优缺点:在回答问题时,尽量不仅停留在正确的答案上,还要深入思考并表达特定功能、概念或语言特性的优缺点。面试官通常会更关注您的思考能力和对技术的全面理解。
6. 积极参与:在面试中,积极与面试官互动。表达自己的观点和思考,提出问题或寻求澄清。这不仅能展示您的积极性和好奇心,还能促进面试的互动和对话。
7. 准备好问题:在面试结束时,通常会给您提供机会提问。为了展示您对岗位和公司的兴趣,准备一些相关问题,例如关于公司文化、技术栈、团队合作等方面的问题。
最重要的是保持自信和冷静。提前准备,并对自己的知识和经验有自信,这样您就能在面试中展现出最佳的表现。祝您面试顺利!
目录
一、Java Object类有哪些方法,分别作用
二、HashMap原理,是否存在线程安全问题
三、Java如何进⾏线程同步
四、CAS原理
五、JVM垃圾回收之GC算法有哪些
六、Mysql索引原理以及查询优化
七、TCP拥塞控制
八、算法: 给定—棵二叉树,找到这棵树最中最后—行中最左边的值
九、知道什么设计模式,分别介绍
十、算法:求⽆序数组中第k⼤的数
十一、算法:求旋转数组找最⼩值(⼆分法)
十二、算法:判断⼆叉树是否镜像(递归)
十三、如何理解前后端分离
十四、有哪些后端开发经验,做了什么
十五、介绍HashMap与TreeMap区别
十六、⽤HashMap实现⼀个有过期功能的缓存
十七、平时怎么学习新知识
十八、最近看了什么书
(一面题)
一、Java Object类有哪些方法,分别作用
Java中的
Object类是所有类的超类(父类),任何类都直接或间接地继承自Object类。因此,Object类中的方法对所有Java对象都是可用的。下面是一些最常用的Object类方法及其作用:
1. public boolean equals(Object obj)
- 检查调用该方法的对象是否等于参数传递的对象。默认实现是比较两个对象的内存地址(即它们是否为同一对象),但很多类重写此方法以提供有意义的相等性比较。
- Object中的equals方法比较的是对象的地址是否相同; equals方法可以被重写,重写后equals方法比较的是两个对象值是否相同。
- 在Java规范中,对equals方法的使用必须遵循以下几个规则:
- 自反性:对于任何非空引用值X,X.equals(X)都应返回true;
- 对称性:对于任何非空引用值X和Y,当且仅当 Y.equals(X)返回true时, X.equals(Y)也应该返回true;
- 传递性:对于任何非空引用值X,Y,Z,如果X.equals(Y)返回true,并且Y.equals(Z)返回true,那么X.equals(Z)应返回true;
- 一致性:对于任何非空引用值X和Y,多次调用 X.equals(Y)始终返回true或始终返回false。
- equals和 ==的区别
- equals比较的是两个对象值是否相等,如果没有被重写,比较的是对象的引用地址是否相同;
==用于比较基本数据类型的值是否相等,或比较两个对象的引用地址是否相等;
String hello = new String("hello"); String hello1 = new String("hello"); System.out .println(hello.equals(hello1)); //重写了 ,比较的是值 ,输出结果为true System.out .println(hello == hello1); //比较的是引用地址 ,输出结果为false int age = 10; int age2 = 10; //比较基本类型的值 System.out.println(age == age2); //输出为true
2. public int hashCode()
- 返回调用对象的哈希码值。默认情况下,这个方法返回对象的内存地址转换成的整数值。重写
equals()时通常也需要重写hashCode(),以便保持equals()为true的两个对象具有相同的哈希码。
3. public String toString()
- 返回对象的字符串表示形式。
Object类的默认实现返回一个由类名,符号“@”以及对象哈希码的无符号十六进制表示组成的字符串。通常,类会重写这个方法,提供更有意义的信息。- 比如System.out.print(person)等价于System.out.print(person.toString()); //默认返回对象的地址
getClass().getName是返回对象的全类名, Integer.toHexString(hashCode())是以16进制无符号整数形式返回此哈希码的字符串表示
形式。
4. public final native Class<?> getClass()
- 返回运行时类的
Class对象。Class类的实例表示正在运行的Java应用程序中的类和接口。
5. protected native Object clone() throws CloneNotSupportedException
- 创建并返回调用该方法的对象的一个副本。
- 对象的类必须实现
Cloneable接口,否则抛出CloneNotSupportedException。clone生成的新对象与原对象的关系,区别在于两个对象间是否存在相同的引用或对应的内存地址是否存在共用情况;若存在,则为 “浅复
制” ,否则为 “深复制” ,“深复制”时需要将共同关联的引用也复制完全。
6. public void finalize()
- 当垃圾收集器确定不存在对该对象的更多引用时,由垃圾收集器在垃圾回收前调用此方法。子类可以重写
finalize()以进行清理工作(诸如释放资源等)。
7. protected void finalize() throws Throwable
- 虽然标记为
protected,但这是对finalize()方法的解释。从Java 9开始,已经不再推荐使用finalize()方法,取而代之的是使用Cleaner和PhantomReference这样的替代方案。
8. public final void wait()throws InterruptedException
- 导致当前线程等待,直到另一个线程调用此对象的
notify()方法或notifyAll()方法。- 调用wait方法的当前线程一定要拥有对象的监视器锁。
- wait方法会把当前线程放在对应的等待队列中,在这个对象上的所有同步请求都不会得到响应。线程调用将不会调用线程,线程一直处于休眠状态。要注意的是, wait方法把当前线程放置到这个对象的等待队列中,解锁也仅仅是在这个对象上;当前线程在等待过程中仍然持有其他对象的锁。
- 如果当前线程被其他线程在当前线程等待之前或正在等待时调用了interrupt()中断了,那么就会抛出InterruptException异常。
- 为什么wait方法一般要写在while循环里?
- 在某个线程调用notify到等待线程被唤醒的过程中,有可能出现另一个线程得到了锁并修改了条件使得条件不再满足;只有某些等待 线程的条件满足了,但通知线程调用了notifyAll有可能出现“伪唤醒”。
- wait方法和sleep方法的区别?
- wait方法属于object类,当调用wait方法时,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify方法后 本线程才会进入对象锁定池,准备获取对象锁进入运行状态。
- sleep方法属于thread类,sleep方法导致程序暂停执行指定的时间,让出CPU给其他线程,但是它的监控状态依然保持,当指定的时间到了又会恢复运行状态。在调用sleep方法过程中,线程不会释放对象锁。
9. public final native void notify()
- 唤醒正在等待对象监视器的单个线程。
唤醒可能等待该对象的对象锁的其他线程。由JVM(与优先级无关)随机挑选一个处于wait状态的线程。
在调用notify()之前,线程必须获取该对象的对象锁,执行完notify()方法后,不会马上释放锁,直到退出synchronized代码块,当前线程 才会释放锁; notify一次只能随机通知一个线程进行唤醒。
10. public final native void notifyAll()
- 唤醒正在等待对象监视器的所有线程。
使所有正在等待池中等待同一个共享资源的全部线程从等待状态退出,进入可运行状态,让它们同时竞争对象锁,只有获得锁的线程才能进
入就绪状态。
11. public final void wait(long timeout) throws InterruptedException
- 使当前线程等待指定的毫秒数,除非另一个线程调用
notify()或notifyAll(),或当前线程被中断。使用该方法时,传入的timeout参数是最大等待时间。如果timeout为0,则一直等待直到被通知或中断。
12. public final void wait(long timeout, int nanos) throws InterruptedException
- 使当前线程等待至多
timeout毫秒加nanos纳秒,除非另一个线程调用notify()或notifyAll(),或当前线程被中断。这个方法允许更精细的控制等待的时间。注意,在使用
wait()、notify()和notifyAll()这几个方法时,必须在同步块或同步方法中调用,这是因为它们需要锁定对象监视器。虽然
Object类提供了这些基本方法,通常在实际开发中会通过各种并发工具类(如java.util.concurrent包中的类)来处理线程同步和通知问题,因为它们提供了更加高级、易于使用和更可靠的并发管理功能。最后需要提醒的是,
Object类的某些方法如finalize()已被标记为过时,因为它可能会导致程序性能问题,并且不保证垃圾收集器会按时调用它。从Java 9开始,finalize()方法被明确标记为过时(deprecated),并推荐使用其他资源释放机制,如try-with-resources语句来管理资源自动关闭。
二、HashMap原理,是否存在线程安全问题
HashMap是 Java 中一种基于哈希表的Map接口的实现。它存储的内容是键值对 (key-value对),每个键映射到一个值。HashMap允许使用 null 值和 null 键。HashMap简单说就是它根据键的hashCode值存储数据,⼤多数情况下可以直接定位到它的值,因⽽具有很快的访问速 度,但遍历顺序却是不确定的。
HashMap基于哈希表,底层结构由数组来实现,添加到集合中的元素以“key--value”形式保存到数组中,在数组中key- -value被包装成⼀个实体来处理---也就是上⾯Map接⼝中的Entry。
在HashMap中, Entry[]保存了集合中所有的键值对,当我们需要快速存储、获取、删除集合中的元素时, HashMap会 根据hash算法来获得“键值对”在数组中存在的位置,以来实现对应的操作⽅法。
HashMap底层是采⽤数组来维护的.Entry静态内部类的数组
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}}HashMap添加元素:将准备增加到map中的对象与该位置上的对象进⾏⽐较(equals⽅法),如果相同,那么就将该位置上 的那个对象(Entry类型)的value值替换掉,否则沿着该Entry的链继续重复上述过程,如果到链的最后任然没有找到与此对象相同的对 象,那么这个时候就会被增加到数组中,将数组中该位置上的那个Entry对象链到该对象的后⾯(先hashcode计算位置,如果找到相同 位置便替换值,找不到则重复hashcode计算,直到最后在添加到hashmap最后⾯; )
HashMap是基于哈希表的Map接⼝的⾮同步实现,允许null键值,但不保证映射的顺序 ;底层使⽤数组实现,数组中的 每项是⼀个链表 ;存储时根据key的hash算法来决定其存储位置;数组扩容需要重新计算扩容后每个元素在数组中的位置 很耗性能;
ConcurrentHashMap是HashMap的线程安全实现,允许多个修改操作同时进⾏(使⽤了锁分离技术),它使⽤了多个锁来
控制对hash表的不同段进⾏的修改,每个段其实就是⼀个⼩的hashtable,它们有⾃⼰的锁。使⽤了多个⼦hash表(段 Segment),允许多个读操作并发进⾏,读操作并不需要锁,因为它的HashEntry⼏乎是不可变的
这是
HashMap的一些主要原理和工作方式:
存储结构:
HashMap在内部使用一个数组来存储数据,这个数组又被称为“桶”(Bucket)。每个桶是一个链表,链表的每一个节点是一个Entry对象,该对象包含键、值以及指向下一个Entry节点的引用。哈希函数:
当我们向HashMap中插入一个key-value对时,它首先会使用哈希函数计算出键对象的哈希码。HashMap通过使用key.hashCode()方法来获取哈希码,然后通过内部的哈希函数来转换成数组索引。冲突解决:
由于桶的数量有限,会发生不同键的哈希码产生相同数组索引的情况,这称为“哈希冲突”。HashMap使用链表来解决冲突,所有哈希值相同的元素会被存储在同一个桶的链表中。从 Java 8 开始,当同一个桶中的元素个数超过一定的阈值(默认是链表长度大于 8),链表会被转换成红黑树以提高性能。查找元素:
在需要获取元素时,HashMap使用键对象的哈希码来找到其在数组中的桶位,然后遍历链表或红黑树(如果转换成红黑树的话)来找到对应的节点。扩容:
当HashMap中的元素数量达到数组大小和加载因子(load factor,默认是 0.75)的乘积时,HashMap会进行扩容操作,即创建一个新的更大的数组,并将旧数组中的所有元素重新插入到新数组中。这个过程叫做“rehash”。迭代:
HashMap的迭代器(Iterator)遍历时按照哈希桶的顺序进行,而不是按照键或值的排序顺序。若在迭代过程中对HashMap结构进行修改,很可能会抛出ConcurrentModificationException(快速失败行为)。
HashMap的这些特性使它成为一个在大多数情况下都有良好性能的键值存储结构。但是正确地了解和使用HashMap的原理对于避免性能问题和正确地进行内存使用仍然非常重要。
由于
HashMap是非线程安全的,当多个线程同时对其进行修改时,可能会出现几种问题。这些问题不只限制于数据的不一致性,还可能引发程序的崩溃。以下是一些可能出现的具体问题:
数据丢失:
当两个线程同时执行put操作,它们可能计算出相同的存储位置从而覆盖对方的数据,这将导致其中一个键值对丢失。无限循环:
在 JDK 7 及之前版本的HashMap中,多线程环境下扩容(rehashing)可以导致循环链表的出现,这会导致get方法陷入无限循环。数据不一致:
如果一个线程正在读取,而另一个线程同时修改了数据结构,读线程可能会看到部分更新的数据,从而导致不可预料的结果。
ConcurrentModificationException异常:
当一个线程迭代HashMap时,如果另外一个线程修改了HashMap的结构(添加或删除任何元素),那么迭代器将快速失败并抛出ConcurrentModificationException。内存泄漏:
在并发环境下,由于线程修改的不同步可能导致某些Entry节点从未正确删除,致使垃圾收集器无法回收这部分内存,随之产生内存泄漏。如果需要在多线程环境下使用
Map结构而又不想处理上述问题,可以使用一些线程安全的替代方案,例如:
Collections.synchronizedMap(new HashMap<>():使用 Collections 工具为HashMap提供同步的包装器,但是每个方法调用都是同步的,可能会导致不必要的性能损耗。ConcurrentHashMap:一种线程安全且高效的HashMap替代实现。它利用分锁机制提供更高的并发性,通常是多线程环境下HashMap的最佳选择。了解问题和可能的解决方案,可以确保在多线程环境中有效地使用
HashMap,避免竞态条件和其他同步相关问题。
三、Java如何进⾏线程同步
在 Java 中,线程同步是指多个线程访问共享资源时,确保每个线程看到一致的内存状态且不会相互干扰的机制。为了防止线程间出现冲突,Java 提供了多种线程同步的机制。
同步方法 (Synchronized Methods):
在方法声明中加入synchronized关键字可以使该方法在同一时间内只能被一个线程访问。当一个线程访问一个对象的synchronized方法时,其他试图访问该对象的synchronized方法的线程将会阻塞。public synchronized void method() {// 同步代码 }同步块 (Synchronized Blocks):
如果只有方法中的某个代码块需要同步,可以使用synchronized关键字来同步一个代码块,这比同步整个方法更加细粒度,可以减少等待时间,从而提高性能。public void method() {// ... 非同步代码synchronized(this) { // this 是锁定的对象,也可以是其他对象// 同步代码}// ... 非同步代码 }锁 (Locks):
Javajava.util.concurrent.locks包提供了更加灵活的锁定机制。其中ReentrantLock是常用的实现,它具有与使用关键字synchronized类似的基本行为和语义,但拥有额外的功能。import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock;public class Counter {private final Lock lock = new ReentrantLock();private int count = 0;public void increment() {lock.lock();try {count++;} finally {// 确保在发生异常时锁能被释放lock.unlock();}} }原子变量:
java.util.concurrent.atomic包提供了一组原子类,例如AtomicInteger,AtomicLong,AtomicReference等。这些类利用底层硬件的原子指令来实现同步,而无需使用传统的锁机制。这些操作是非阻塞的,并且往往是性能更高的选项。import java.util.concurrent.atomic.AtomicInteger;public class Counter {private AtomicInteger count = new AtomicInteger(0);public void increment() {count.incrementAndGet();}public int getValue() {return count.get();} }volatile 关键字:
当一个变量被声明为volatile,那么线程每次读取变量时都会从内存中读,每次写回变量时都会写入到内存中。这确保了该变量的可见性,即当一个线程更新了该变量时,其他线程能立刻看到修改后的值。public class SharedObject {private volatile int sharedVariable = 0;public void increment() {sharedVariable++;}public int getSharedVariable() {return sharedVariable;} }请注意,
volatile不能保证复合操作(如自增)的原子性,它仅保证变量的读写操作的可见性。使用哪种同步机制取决于具体的情况,正确的选择可以提供良好的性能同时确保线程安全。对于一些高级的同步需要,我们可能还需要使用到
Semaphore,CountDownLatch,CyclicBarrier,Phaser等同步工具,它们在java.util.concurrent包下提供了更为复杂的并发控制。
四、CAS原理
CAS(Compare-And-Swap 或 Compare-And-Set)是一种用于实现多线程同步的技术。它涉及对内存中的某些值进行原子地比较和更新。"原子"指的是操作作为一个不可分割的单元执行,要么完全执行,要么完全不执行,不会出现中间状态。
CAS 操作通常包括以下三个操作数:
- 内存位置(V):要操作的内存地址。
- 期望原值(A):期望读到的值。
- 新值(B):若期望原值验证为真,即内存位置的值与期望原值相等,则更新为此新值。
这个操作的伪代码可以表示为:
if memory_value == expected_valuememory_value = new_value elsehandle the failure (do nothing or retry or abort, etc.)执行 CAS 操作的基本步骤是:
- 系统从内存地址 V 读取当前值。
- 检查当前值是否与期望原值 A 相等。
- 如果相等,则将新值 B 更新到内存地址 V。
- 如果不等,则不做任何操作或者采取其他补救措施(比如重试或回滚)。
CAS 操作是无锁编程中常用的技术,有助于在不使用传统锁机制的情况下实现对共享数据的安全操作。在多处理器系统中,CAS 是通过硬件指令直接支持的,因此可以高效地执行。
CAS 有以下优点:
- 性能:由于不需要锁定,CAS 可以减少线程上下文切换的成本,通常比使用锁更高效。
- 死锁避免:既然没有使用传统的锁,也就不可能出现死锁的情况。
不过,CAS 也存在一些问题:
- ABA 问题:如果值从 A 变成 B,然后又变回 A,CAS 会认为什么都没有改变,然而实际上可能发生了重要的变动。
- 循环时间长:如果很多线程同时尝试进行 CAS,那么只有一个能成功,其他线程可能不得不多次尝试。
- 只能保证一个共享变量的原子操作:如果需要同时更新多个共享变量,则不能直接使用 CAS。
总的来说,CAS 是一种基于硬件实现的轻量级同步机制,适用于某些不需要严格的锁定机制就能解决的线程安全问题。它是 Java 中
java.util.concurrent.atomic包中的原子变量类的关键实现技术。
五、JVM垃圾回收之GC算法有哪些
Java 虚拟机(JVM)使用垃圾回收(GC)算法来管理和回收不再使用的内存。主要的垃圾回收算法包括:
标记-清除(Mark-Sweep)算法:
- 标记:该阶段标记出所有从根集合开始可达的对象。
- 清除:回收所有未被标记的对象占用的内存。
缺点是两个主要方面:标记和清除过程的效率不高,以及清除后容易产生内存碎片。复制(Copy or Scavenge)算法:
- 将内存分为两个相等的区域,每次只使用其中的一个。
- 当进行垃圾回收时,将正在使用的内存区域中存活的对象复制到未使用的区域,然后清除正在使用的内存区域中的所有对象。
- 优点是避免了内存碎片,缺点是内存利用效率为 50%。
标记-整理(Mark-Compact)算法:
- 结合了“标记-清除”和“复制”算法的优点。
- 标记:和标记-清除算法一样进行标记。
- 整理:将所有存活的对象压缩到内存的一端,清理掉端边界外的内存。
优点是解决内存碎片问题而不需要牺牲过多的内存。增量(Incremental)垃圾回收:
- 让垃圾回收分批进行,不是一次性清理完所有垃圾。
- 目的是减少每次垃圾回收的时间,使得垃圾回收对系统的影响更为平滑。
分代收集(Generational Collection)算法:
- 根据对象存活周期的不同,将内存划分为新生代(Young Generation)、老年代(Old Generation)和永久代(Permanent Generation,但在 Java 8 中已经被移除,改成了元空间(MetaSpace))。
- 新生代使用复制算法,老年代一般采用标记-清除或标记-整理算法。
并行(Parallel)垃圾回收:
- 使用多个垃圾回收线程并行执行垃圾回收,以提高垃圾回收的效率。
- 适用于多核处理器,能够更高效地进行垃圾回收。
并发(Concurrent)垃圾回收:
- 允许垃圾回收线程与应用程序线程同时工作。
- 旨在减少应用程序的停顿时间,适合需要响应时间快的应用。
JVM 中有不同的垃圾回收器实现上述算法。常见的垃圾回收器有:
- Serial GC:单线程运行,采用标记-复制算法,适合单核处理器或小内存环境。
- Parallel GC (也称为吞吐量收集器):多线程执行,侧重增加吞吐量。
- CMS (Concurrent Mark-Sweep) GC:以获取最短停顿时间为目标,使用并发标记清除算法。
- G1 (Garbage-First) GC:旨在为多核机器提供高吞吐量和低延迟的性能表现,适用于大内存。
与这些收集器相关的具体细节和性能特征,取决于 JVM 的实现和版本。在 OpenJDK 和 Oracle JDK 9 及以后的版本中,还提供了新的垃圾回收器(如 ZGC 和 Shenandoah),旨在降低停顿时间,同时适应大内存和多处理器环境。
六、Mysql索引原理以及查询优化
MySQL索引是帮助MySQL高效获取数据的数据结构。以下是一些基本的MySQL索引类型和它们的工作原理:
B+Tree索引:最常用的索引类型,适合用于全键值、键值范围或键值前缀查找。B-Tree索引能够加速数据的读取,但会额外消耗一些空间来存储索引,并且在插入、更新和删除时需要同步更新索引。
哈希索引:基于哈希表的实现,适合等值查询,不适合范围查询和部分键匹配查询。主要优点是查找速度快,缺点是不支持排序和分组。
全文索引 (Fulltext Indexes):特别适用于对文本内容进行搜索的应用,可以快速定位包含某个词或短语的记录。
空间数据索引 (R-Tree):用于空间数据类型,如GIS数据。
工作原理:
- B+Tree索引:通过维护一个平衡搜索树来进行优化检索,数据按照顺序存储,可用于查找、排序和分组操作。
查询优化:
- 选择正确的索引:了解不同类型的查询和哪些情况下最适合使用索引。找出查询中常用的列并为它们建立索引。
- 索引列上进行操作:避免在索引列上做运算或使用函数,这将导致无法使用索引。
- 使用最左前缀法则:对于复合索引,确保查询条件与索引中列的顺序一致。
- 避免全表扫描:尽量使用索引来避免全表扫描,适当地限制查询返回的行数。
- 索引的选择性:选择性是不重复的索引值与数据表中的记录数的比例,选择性越高的索引性能越好。
- 使用Explain来分析查询:使用EXPLAIN语句来分析你的查询以及索引使用情况,可以帮助发现性能瓶颈。
- 适当的Like语句:当必须使用LIKE查询时,如果模式以通配符开头,索引将不会被使用。尽可能避免
'%value%'这种模式,而使用'value%'。确保定期维护索引以防止索引碎片,导致查询效率下降。通过定期运行
OPTIMIZE TABLE命令,可以帮助重新组织存储和重新构建数据库索引,进而提高查询效率。
七、TCP拥塞控制
TCP拥塞控制是一种网络机制,它旨在防止过多的数据同时注入网络,从而避免网络中的路由器或链路过载,导致过度的延迟或丢包。TCP的拥塞控制通过动态调整各TCP连接的发送窗口大小来控制它们各自的发送速率。
以下是TCP拥塞控制的主要算法:
1. 慢启动(Slow Start):
- TCP连接开始时,拥塞窗口(cwnd)从一个很小的值(通常是一个MSS,即最大报文段大小)开始增长,每当收到一个ACK,cwnd就增加一个MSS,这样,cwnd每个RTT(往返时间)就翻倍增长,呈指数增长。
- 当cwnd达到慢启动阈值(ssthresh)时,TCP切换到拥塞避免算法。
2. 拥塞避免(Congestion Avoidance):
- 这个阶段TCP转变为更稳健的增长方式,每个RTT只增加一个MSS,呈线性增长,以稳步增加网络负载。
- 如果出现丢包(如超时或接收到重复ACKs),TCP认为网络出现拥塞,并且将ssthresh设置为当前cwnd的一半,并进入快速恢复或慢启动。
3. 快速重传(Fast Retransmit):
- 如果发送端收到三个重复的ACK,它就知道该段后面的报文段一定是丢失了,而不是需要等待定时器超时。
- 它会立即重传这个失序的报文段而不是等待超时,同时不减小cwnd的大小以避免降低传输速率。
4. 快速恢复(Fast Recovery):
- 在执行快速重传之后,TCP进入快速恢复阶段,ssthresh被设置为当前cwnd的一半,cwnd被设置为ssthresh加3倍MSS(对于之前接收的三个重复ACK),然后每接收一个重复的ACK就增加一个MSS。
- 当终于收到了一个新的ACK,认为网络恢复了,cwnd被重新设置为ssthresh的值,TCP进入拥塞避免阶段。
5. 超时处理:
- 如果等待ACK的时间超过了预定的超时时间,TCP认为发生了严重的拥塞,并将ssthresh设置为当前cwnd的一半,并且将cwnd重新设置为1MSS,然后进入慢启动阶段。
随着时间的推移,TCP的拥塞控制算法也不断发展和完善,例如引入了更为复杂的算法如BBR(Bottleneck Bandwidth and RTT)等,旨在进一步优化性能。
TCP拥塞控制的工作原理是一个动态的过程,它需要根据网络的实时状态不断地调整发送速率。这些机制使得TCP能够动态适应不同的网络拥塞情况,能够在各种类型的网络中有效地传输数据,同时又不会因为过多的数据流量而导致网络崩溃。
八、算法: 给定—棵二叉树,找到这棵树最中最后—行中最左边的值
为了在Java中实现这个算法,您可以创建一个
TreeNode类表示二叉树节点,然后使用广度优先搜索(BFS)遍历整棵树。通过队列来实现BFS算法,您可以轻松地按层遍历二叉树,并记录下每层的第一个节点。以下是一个实现这一功能的Java代码示例:
import java.util.Queue; import java.util.LinkedList;class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) {val = x;} }public class BinaryTreeBottomLeftValue {public int findBottomLeftValue(TreeNode root) {if (root == null) return -1;Queue<TreeNode> queue = new LinkedList<>();queue.add(root);int result = root.val; // 初始化结果为根节点的值while (!queue.isEmpty()) {int size = queue.size(); // 当前层的节点数量for (int i = 0; i < size; i++) {TreeNode node = queue.poll();// 如果是当前层的第一个节点,更新结果值if (i == 0) result = node.val;// 添加子节点到队列if (node.left != null) queue.add(node.left);if (node.right != null) queue.add(node.right);}}return result; // 返回最后一行最左边的值}public static void main(String[] args) {// 示例二叉树// 1// / \// 2 3// / / \// 4 5 6// /// 7// 示例二叉树构建TreeNode root = new TreeNode(1);root.left = new TreeNode(2);root.right = new TreeNode(3);root.left.left = new TreeNode(4);root.right.left = new TreeNode(5);root.right.right = new TreeNode(6);root.right.left.left = new TreeNode(7);BinaryTreeBottomLeftValue solution = new BinaryTreeBottomLeftValue();int bottomLeft = solution.findBottomLeftValue(root);System.out.println("Bottom left value: " + bottomLeft); // 应输出 7} }在这个Java程序中,我们定义了
TreeNode类来表示树的节点,然后在BinaryTreeBottomLeftValue类中添加了findBottomLeftValue方法。这个方法使用队列来追踪需要访问的节点,遍历所有层,并记录下每一层中的第一个节点值。最终,返回的就是最后一行中最左边的值。在
main方法中,我们建立了一个示例二叉树,并调用findBottomLeftValue方法来获取最后一行最左边的值。
(二面题,考察代码能力。60分钟)
九、知道什么设计模式,分别介绍
设计模式是解决软件设计中常见问题的通用、可重用的解决方案。设计模式可以分为三个主要类别:创建型、结构型和行为型。下面是每一类中一些常用的设计模式及其简要介绍:
创建型模式
创建型模式专注于如何创建对象或类的实例。
工厂方法模式(Factory Method):
允许接口定义创建对象的方法,但由子类决定要实例化的类的类型。工厂方法将对象的创建延迟到子类。抽象工厂模式(Abstract Factory):
提供一个接口用于创建相关或依赖对象的家族,而不需要明确指定具体类。建造者模式(Builder):
分离复杂对象的构建和表示,同样的构建过程可以创建不同的表示。原型模式(Prototype):
通过拷贝一个现有对象的方式来创建对象,而不是通过实例化。单例模式(Singleton):
确保一个类仅有一个实例,并提供一个全局访问点。
结构型模式
结构型模式与类和对象的组织有关,它们定义了类之间的关系来实现更大的功能。
适配器模式(Adapter):
允许将不兼容的接口转换为其他类可以工作的接口。桥接模式(Bridge):
分离抽象部分和实现部分,使它们可以独立变化。组合模式(Composite):
允许将对象组成树形结构来表示“部分-整体”的层次结构。使得用户对单个对象和组合对象的使用具有一致性。装饰器模式(Decorator):
向一个现有的对象添加新的功能,同时又不改变其结构。外观模式(Facade):
提供了一个统一的接口,用来访问子系统中的一群接口。外观定义了一个高层接口,让子系统更容易使用。享元模式(Flyweight):
运用共享技术有效地支持大量细粒度的对象。代理模式(Proxy):
为其他对象提供一种代理以控制对这个对象的访问。
行为型模式
行为型模式专注于算法和对象间职责的分配。
责任链模式(Chain of Responsibility):
为请求创建一个接收者对象的链。这种模式给更多的对象一个机会处理请求。命令模式(Command):
将请求封装为一个对象,从而允许我们使用不同的请求、队列请求、记录日志等来参数化其他对象。解释器模式(Interpreter):
定义一种语法用于一个某个特定类型的问题,并提供该语法的解释器。迭代器模式(Iterator):
提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示。中介者模式(Mediator):
封装多个对象之间复杂的交互和协作关系,中介者通过减少类之间的通信线条数量,来减少依赖性。备忘录模式(Memento):
在不破坏封装的前提下,捕获并保存一个对象的内部状态,以便在以后可以恢复到这个状态。观察者模式(Observer):
一种订阅机制,当一个对象状态变化时,所有依赖它的对象都会收到通知并自动更新。状态模式(State):
允许一个对象在其内部状态改变时改变它的行为。策略模式(Strategy):
定义一系列算法,并将每一个算法封装起来,使他们可以互相替换。模板方法模式(Template Method):
定义算法的框架,允许子类在不改变算法结构的情况下,重写算法的某些步骤。访问者模式(Visitor):
对于一个对象结构中的元素,允许一个外部的访问者来访问,无需改变对象结构的具体元素类。这些设计模式在软件开发中被广泛应用,能够帮助开发者通过事先定义好的、经过实战考验的方法来解决各种设计问题,从而编写出更加可维护、更加清晰、更加可靠的代码。
详解设计模式专栏:http://t.csdnimg.cn/bzp55(后续慢慢更新)
十、算法:求⽆序数组中第k⼤的数
要在无序数组中找到第k大的数,可以使用快速选择(Quickselect)算法。该算法的思想是基于快速排序的分治思想,但是只执行必要的分区操作,从而更高效地找到第k大的数。
下面是使用Java实现快速选择算法来找到无序数组中第k大的数的示例代码:
import java.util.Random;public class QuickSelect {private static Random random = new Random();public static int findKthLargest(int[] nums, int k) {return quickSelect(nums, 0, nums.length - 1, nums.length - k);}private static int quickSelect(int[] nums, int start, int end, int k) {if (start == end) {return nums[start];}int pivotIndex = partition(nums, start, end);if (pivotIndex == k) {return nums[pivotIndex];} else if (pivotIndex < k) {return quickSelect(nums, pivotIndex + 1, end, k);} else {return quickSelect(nums, start, pivotIndex - 1, k);}}private static int partition(int[] nums, int start, int end) {// 随机选择一个pivotint randomIndex = start + random.nextInt(end - start + 1);swap(nums, randomIndex, end);int pivot = nums[end];int pivotIndex = start;for (int i = start; i < end; i++) {if (nums[i] < pivot) {swap(nums, i, pivotIndex);pivotIndex++;}}swap(nums, pivotIndex, end);return pivotIndex;}private static void swap(int[] nums, int i, int j) {int temp = nums[i];nums[i] = nums[j];nums[j] = temp;}public static void main(String[] args) {int[] nums = {3, 5, 2, 1, 6, 4};int k = 2;int result = findKthLargest(nums, k);System.out.println("第" + k + "大的数是: " + result);} }在示例代码中,
findKthLargest方法接受一个无序数组和一个整数k作为输入,返回第k大的数。quickSelect方法是实现快速选择的递归函数,用于分区和选择。partition方法根据选定的pivot元素将数组分成两部分,并返回pivot的索引。在示例代码的
main方法中,我们提供了一个无序数组和一个k值进行测试,并打印出结果。需要注意的是,上述代码的示例是找无序数组中第k大的数。如果要找第k小的数,只需修改递归调用的条件和相应返回的数值即可。
快速选择算法的时间复杂度为O(N),其中N是数组的长度。
十一、算法:求旋转数组找最⼩值(⼆分法)
求解旋转数组中最小值的问题可以使用二分法进行高效求解。旋转数组是指将一个升序排列的数组的前若干个元素搬到数组末尾而得到的数组。
下面是使用Java实现二分法求解旋转数组中最小值的示例代码:
public class MinimumInRotatedArray {public static int findMin(int[] nums) {int left = 0;int right = nums.length - 1;while (left < right) {int mid = left + (right - left) / 2;if (nums[mid] > nums[right]) {left = mid + 1;} else if (nums[mid] < nums[right]) {right = mid;} else {right--;}}return nums[left];}public static void main(String[] args) {int[] nums = {4, 5, 6, 7, 0, 1, 2};int min = findMin(nums);System.out.println("旋转数组中的最小值是: " + min);} }在示例代码中,
findMin方法接受一个旋转数组作为输入,并使用二分法来搜索旋转数组中的最小值。算法首先初始化左右两个指针,指向数组的第一个和最后一个元素。然后,通过计算中间元素的索引,将问题的规模缩小为子数组。在每一次迭代中,比较中间元素和最右侧元素的大小关系,根据比较结果调整左右指针的位置,直到最小值被找到。在示例代码的
main方法中,我们提供了一个旋转数组进行测试,并打印出最小值。该算法的时间复杂度为O(logN),其中N是旋转数组的长度。二分法的每一次迭代都将问题的规模减半,因此算法的时间复杂度是对数级别的。
十二、算法:判断⼆叉树是否镜像(递归)
判断二叉树是否镜像可以使用递归的方式来解决。对于两棵树是镜像的,意味着它们的根节点的值相同,并且每个树的右子树都与另一个树的左子树镜像对称。
下面是使用Java递归实现判断二叉树是否镜像的示例代码:
class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int val) {this.val = val;} }public class MirrorBinaryTree {public static boolean isMirror(TreeNode root) {if (root == null) {return true;}return isSymmetric(root.left, root.right);}private static boolean isSymmetric(TreeNode left, TreeNode right) {if (left == null && right == null) {return true;}if (left == null || right == null || left.val != right.val) {return false;}return isSymmetric(left.left, right.right) && isSymmetric(left.right, right.left);}public static void main(String[] args) {TreeNode root = new TreeNode(1);root.left = new TreeNode(2);root.right = new TreeNode(2);root.left.left = new TreeNode(3);root.left.right = new TreeNode(4);root.right.left = new TreeNode(4);root.right.right = new TreeNode(3);boolean result = isMirror(root);System.out.println("二叉树是否镜像: " + result);} }在示例代码中,
isMirror方法接受一个二叉树的根节点作为输入,使用递归判断二叉树是否镜像。在isSymmetric方法中,首先判断左右子树是否都为空,如果是,则表示当前节点及其子树镜像对称。其次,判断左右子树是否都不为空,并且当前节点的值相同,如果是,则递归判断左子树的左子树和右子树的右子树,以及左子树的右子树和右子树的左子树是否镜像对称。最后,如果上述条件都不满足,则表示二叉树不是镜像。在示例代码的
main方法中,我们构建了一个镜像二叉树进行测试,并打印出结果。如果二叉树为空,也可视为空镜像,因此在
isMirror方法中增加了对空树的处理。该算法的时间复杂度为O(N),其中N是二叉树中的节点数量。因为算法需要遍历每个节点且只访问一次,所以时间复杂度与节点数量成线性关系。
(三面,开放式问题,40分钟)
十三、如何理解前后端分离
前后端分离是一种Web应用开发模式,它将用户界面(UI)及前端业务逻辑与后端服务及数据处理逻辑分开,使得前端和后端可独立开发与部署。这种模式带来了一系列的优势,同时也对开发流程和架构提出了新的要求。
以下是前后端分离的几个主要方面和好处:
1. 角色和技术栈分离:
- 前端(Front-end):负责展示用户界面和用户交互,通常使用HTML、CSS和JavaScript等技术构建,使用现代框架和库如React、Vue、Angular,进行丰富的交互式体验的开发。
- 后端(Back-end):负责处理业务逻辑、数据库交云、认证授权等服务器端功能,可以使用各种编程语言和框架,如Java Spring Boot、Python Django、Node.js Express等。
2. 开发和部署独立:
- 开发人员可以专注于各自擅长的领域,前端开发者专注于用户体验和界面构建,后端开发者专注于数据处理和业务规则实现。
- 前后端代码可以分别部署在不同的服务器上,提供更灵活的扩展和管理选项。
3. 通讯通过API:
- 前后端之间通过定义良好的API接口交互,通常是RESTful API或GraphQL等形式。
- 使用JSON或XML等数据交换格式,前端通过HTTP请求与后端通讯。
4. 增强用户体验:
- 由于前端可独立更新,所以能够快速响应市场变化,提高用户体验。
- 前端可实现单页面应用(SPA),动态加载内容而无需重新加载整个页面。
5. 提高开发效率:
- 前后端分离允许前后端团队并行工作,只要API契约定义好,双方即可独立进行开发。
- 可利用各种前端开发和调试工具,加快前端开发进度。
6. 便于扩展和维护:
- 各自的更新和维护不会互相影响,减少了开发和部署的复杂性。
- 由于前后端的解耦,更容易对系统进行扩展和整合新技术。
尽管前后端分离带来了上述优点,但同时也带来了一些挑战,例如跨域资源共享(CORS)问题、API版本管理、前后端接口联调需要更好的沟通和文档支持等。解决这些挑战需要团队之间良好的沟通,以及合适的工具和流程来协调工作。
十四、有哪些后端开发经验,做了什么
应该准备一个简洁而详细的回答来展示你的后端开发技能、所使用的技术栈以及你在以往项目中的具体贡献。以下是几个方面参考:
1. 概述后端技术栈:
开始时简要介绍你使用过的后端语言和框架,如Java/Spring Boot、C#/ASP.NET、Python/Django、Node.js/Express等。2. 描述特定的项目经验:
提供一个或几个具体的项目例子,这些例子应该能够反映出你在后端开发方面的专业水平和经验。对每个项目,介绍以下信息:
- 项目的目标和你的角色。
- 使用的技术栈和工具。
- 你主要负责的功能和任务。
- 所解决的关键问题和挑战。
- 项目的成果和你对成功所做的贡献。
3. 展示解决问题的能力:
谈谈你在后端开发中遇到的最有挑战性的问题以及你是如何解决这些问题的。4. 强调团队合作:
如果适用,讨论你如何与前端开发者、设计师和其他团队成员合作,以确保项目的顺利进行。5. 讨论性能和安全:
如果你有在项目中针对性能优化或安全措施做出贡献的经验,一定要提到。6. 提供维护和扩展的经验:
如果你参与了现有项目的维护或是为系统提供了扩展功能,说明你的工作如何提高了代码质量、系统可靠性或用户体验。7. 量化成果:
如果可能,提供一些量化的结果,比如性能提升的百分比、处理的请求量、减少的加载时间等。
示例:
“我在后端开发方面有5年的经验,主要使用Java和Spring Boot框架。我参与过多个企业级项目,例如开发了一个支持数百万并发用户的电子商务平台,其中我负责实现订单处理系统和用户身份验证模块。
除了Java,我也使用过Node.js开发API服务,并且熟悉数据库技术,比如MySQL和MongoDB。在最近的一个项目中,我优化了数据库查询,使关键操作的速度提高了30%以上。
我还处理过对系统安全的改进。我曾经实现了一套基于OAuth 2.0的权限管理系统,确保了我们的用户数据的安全性。团队合作方面,我通常与前端开发人员密切协作,确定API规格,并通过持续集成和代码评审来维护代码质量。我们的协作导致了项目按时交付,客户反馈表明用户满意度显著提高。”
根据自己的经验调整这个回答,保持真实性,并根据应聘的岗位特点强调最相关的部分。
十五、介绍HashMap与TreeMap区别
HashMap和TreeMap是 Java 的两种常用的Map实现,它们都提供了键-值对存储机制,但在内部工作原理和特性上有所不同。以下是它们之间的主要区别:1. 内部结构:
HashMap基于散列表(哈希表)实现,使用哈希函数来确定每个键值对(节点)的存储位置。TreeMap基于红黑树实现,红黑树是一种自平衡的排序二叉树。2. 排序:
HashMap不保证任何排序,键值对的存储是根据哈希值来决定的,迭代它时得到的顺序是无序的。TreeMap根据键的自然顺序或者构造时所指定的Comparator进行排序。这意味着键会按升序排列,或者按Comparator实现的顺序排列。3. 时间复杂度:
HashMap提供了常数时间的性能,即O(1),对于get、put和remove操作,理想情况下是这样。但是,在最坏的情况下(例如当所有元素都映射到同一个桶中时),性能可能会退化到O(n)。TreeMap保证了get、put和remove操作的时间复杂度为O(log n),因为它是基于树的。4. null 值:
HashMap允许键和值为null,意味着你可以将null作为一个键或值插入到HashMap中。TreeMap不允许键为null(因为它需要按照某种顺序对键进行排序),但允许值为null。5. 线程安全:
- 两者都不是线程安全的。在多线程环境下,如果没有正确的同步,任何结构性修改都可能引发并发问题。
- 如果需要线程安全,可以通过
Collections.synchronizedMap来包装HashMap,或者使用ConcurrentHashMap代替HashMap。而TreeMap没有直接的线程安全对应,但可以考虑使用ConcurrentSkipListMap。6. 性能:
HashMap通常在大部分场景下提供更好的性能,尤其是在添加和查询元素时。而TreeMap在维持映射的有序状态方面表现更好,尤其适用于需要有序遍历键时。选择
HashMap还是TreeMap取决于应用程序的具体需求。如果不需要排序,并且想要最快的访问速度,HashMap是较好的选项。如果需要一个总是处于排序状态的键集合,TreeMap是更加适合的选择。
十六、⽤HashMap实现⼀个有过期功能的缓存
要使用 HashMap 实现一个具有过期功能的缓存,可以创建一个包装类,这个类将包含每个缓存项的值和过期时间。我们可以在每次访问缓存时检查该项是否过期。如果过期,我们就从缓存中移除这个项。另外,我们还可以创建一个维护过期项的线程或定时任务,来定期清理过期的缓存项。
下面是一个简单的缓存实现,使用了 HashMap:
import java.util.concurrent.*;public class ExpiringCache<K, V> {// 缓存项类包含值和过期时间private class CacheItem {V value;long expiryTime;public CacheItem(V value, long expiryTime) {this.value = value;this.expiryTime = expiryTime;}}private final ConcurrentHashMap<K, CacheItem> cacheMap;private final ScheduledExecutorService executorService;public ExpiringCache() {cacheMap = new ConcurrentHashMap<>();executorService = Executors.newSingleThreadScheduledExecutor();// 定期执行过期缓存清理任务executorService.scheduleAtFixedRate(() -> {long currentTime = System.currentTimeMillis();cacheMap.entrySet().removeIf(entry -> currentTime > entry.getValue().expiryTime);}, 1, 1, TimeUnit.SECONDS);}// 向缓存添加项,并设置过期时间public void put(K key, V value, long expiryDurationInMillis) {long expiryTime = System.currentTimeMillis() + expiryDurationInMillis;cacheMap.put(key, new CacheItem(value, expiryTime));}// 从缓存中获取项,如果不存在或已过期,则返回 nullpublic V get(K key) {CacheItem item = cacheMap.get(key);if (item != null && System.currentTimeMillis() < item.expiryTime) {return item.value;}cacheMap.remove(key); // 如果已过期,移除return null;}public void shutdown() {executorService.shutdownNow();} }在以上代码中,我们创建了一个内部类
CacheItem来存储缓存的值和该项的过期时间。通过ScheduledExecutorService, 我们安排了定期执行的任务,以清理所有过期的缓存项。put方法添加缓存项时需要指定一个过期时间。get方法只返回未过期的缓存项,如果检测到缓存项已过期,则将其移除。这个实现是线程安全的,因为我们使用了
ConcurrentHashMap,它是一个支持完全并发的哈希表。我们也使用了ScheduledExecutorService来定期检查和清除过期项。请记得,在停止使用缓存或者程序结束时调用
shutdown()方法来关闭ScheduledExecutorService。这很重要,因为我们不希望后台线程在不需要时继续运行。
Google 的 Guava 库中包含了一个功能强大的缓存实现
Cache类(你可以自己用Cache来实现缓存过期功能试试)。下面是使用 Guava 缓存的一个简单例子:
import com.google.common.cache.CacheBuilder; import com.google.common.cache.CacheLoader; import com.google.common.cache.LoadingCache;import java.util.concurrent.TimeUnit;public class GuavaCacheExample {public static void main(String[] args) throws Exception {// 创建缓存LoadingCache<String, String> cache = CacheBuilder.newBuilder().maximumSize(100) // 最多缓存项.expireAfterWrite(10, TimeUnit.MINUTES) // 写入10分钟后过期.build(new CacheLoader<String, String>() {public String load(String key) {return fetchData(key);}});// 从缓存中取值,可能直接取缓存,或者加载数据后缓存String value = cache.get("myKey");System.out.println("Value for 'myKey': " + value);// 直接向缓存里添加一个键值对cache.put("anotherKey", "anotherValue");// 得到某个键对应的值(如果存在)System.out.println("Value for 'anotherKey': " + cache.getIfPresent("anotherKey"));}// 示范的数据加载方法,实际应用中应更复杂,例如数据库查询操作private static String fetchData(String key) {// Here you should implement actual data fetching logicreturn "Data for " + key;} }在这个例子中,我们使用 Guava 来创建一个缓存,它有一个最大项数限制,并且每个缓存项在写入10分钟后会自动过期。
CacheLoader被用来定义如何加载数据到缓存中。当你调用get()方法时,Guava 自动使用定义好的加载机制来提供值。如果缓存中已经有这个值了,就会立刻返回。Guava 的
Cache类也提供了很多其他功能,比如监听器,手动移除,缓存统计等。如果需要在商业项目中使用缓存,推荐使用成熟的缓存框架,比如 Guava,Caffeine,Ehcache 或者 Hazelcast 等。这些框架提供了更复杂的缓存策略,性能监控,以及和其他技术的集成。
十七、平时怎么学习新知识
下面是一些常见的学习方法和技巧:
设定学习目标:开始学习前,先设定清晰的、具体的学习目标,这可以帮助你保持专注并衡量自己的进步。
按计划学习:建立一个学习计划,为每个学习阶段设定时间表和里程碑,按计划执行可以提高学习效率。
多样化学习渠道:使用书籍、在线课程、视频教学、博客文章、技术文档等不同的学习资源可以帮助你全面理解新知识。
实践操作:通过实际编程、设计、写作或其他实践活动将所学知识运用到实际中去,实践是检验学习成果的最佳方式。
参与讨论:加入学习小组或在线社区,参与讨论可以让你从不同的角度理解新知识,同时,解答他人问题也是一种很好的学习方式。
建立联系:尝试将新学的知识和你已经知道的知识联系起来,这样有助于记忆和深化理解。
定期复习:周期性地检查和复习你所学的内容,避免遗忘,并确保知识点能够牢固记在脑中。
灵活调整:在学习过程中,根据自己的学习进展和理解情况,适当调整学习目标和计划。
保持好奇心和耐心:学习新知识可能会遇到困难和挑战,保持开放和有好奇心的态度是很重要的,耐心地对待每一步学习过程。
运用现代技术辅助学习:可以利用各种软件和Apps来辅助学习,比如使用笔记软件整理学习笔记,用时间管理工具追踪学习时间等。
十八、最近看了什么书
这个就⾃由发挥了。
要回答好这个问题,一定要保持看书学习的状态,否则肯定回答不好这个问题,至少不能瞎编,多问两个问题就被看穿。
所以,随时保持学习充电状态。一起加油!未来可期。
相关文章:
)
Java入门高频考查基础知识4(字节跳动面试题18题2.5万字参考答案)
Java 是一种广泛使用的面向对象编程语言,在软件开发领域有着重要的地位。Java 提供了丰富的库和强大的特性,适用于多种应用场景,包括企业应用、移动应用、嵌入式系统等。 以下是几个面试技巧: 1. 复习核心概念:回顾 Ja…...

视觉空间效应
一、视觉空间效应 概况 视觉空间效应,是人类视觉系统(Human Visual System,HVS)的一个特点,也称为"视觉距离效应"。即距离观察者更近的目标像素对颜色感知产生更强烈的影响,而距离较远的目标像素…...
C#,入门教程(07)——软件项目的源文件与目录结构
上一篇: C#,入门教程(06)——解决方案资源管理器,代码文件与文件夹的管理工具https://blog.csdn.net/beijinghorn/article/details/124895033 创建新的 C# 项目后, Visual Studio 会自动创建一系列的目录与文件。 程序员后面的工…...
)
三国游戏(第十四届蓝桥杯)
题目 小蓝正在玩一款游戏。游戏中魏蜀吴三个国家各自拥有一定数量的士兵 X,Y,Z(一开始可以认为都为 0)。 游戏有 n个可能会发生的事件,每个事件之间相互独立且最多只会发生一次,当第 i个事件发生时会分别让 X,Y,Z 增加 A i , B…...
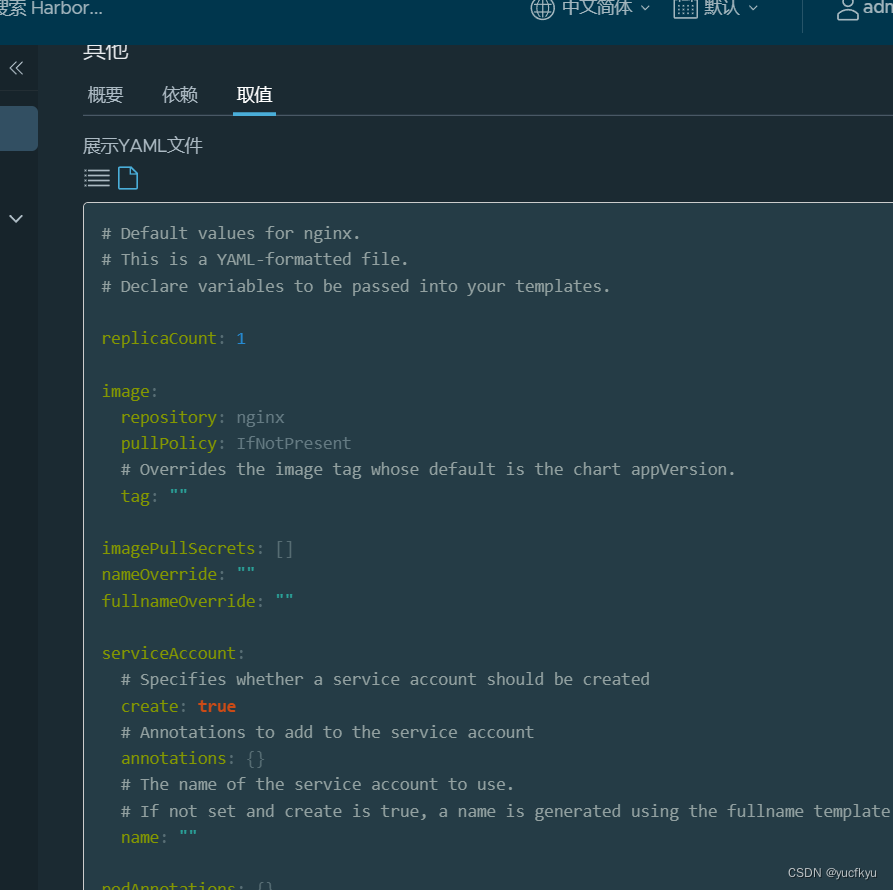
k8s---包管理器helm
内容预知 目录 内容预知 helm相关知识 Helm的简介与了解 helm的三个重要概念 helm的安装和使用 将软件包拖入master01上 使用 helm 安装 Chart 对chart的基本使用 查看chart信息 安装chart 对chart的基本管理 helm自定义模板 在镜像仓库中拉取chart,查…...
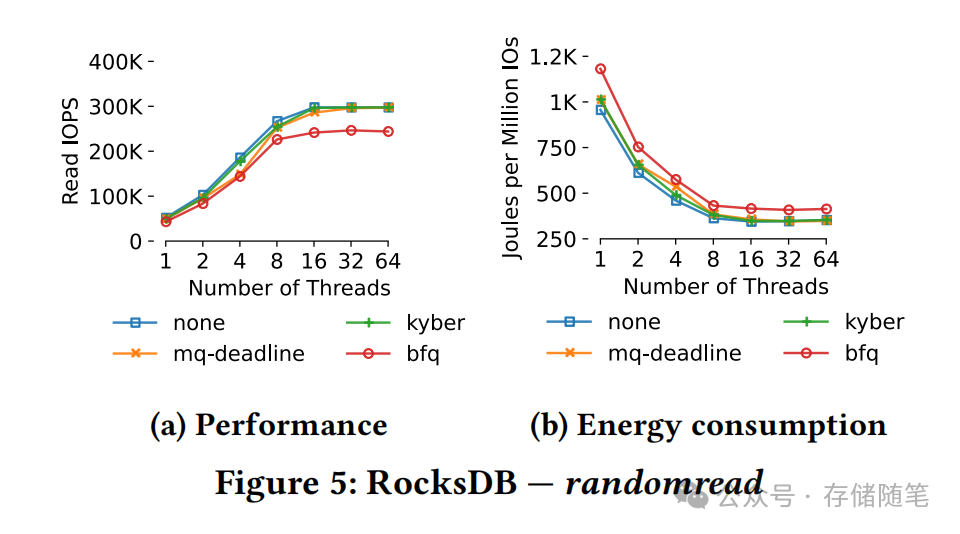
对于超低延迟SSD,IO调度器已经过时了吗?-part2
为了进行这项研究,他们设计了一套严谨的实验方法论,包括在配备了高速Intel Optane P4801X Series NVMe SSD的服务器上执行一系列微观和宏观基准测试,同时监测系统能耗情况。这些测试涵盖了多种工作负载场景,从单一进程提交大量请求…...

【C++】list的使用
目录 1 构造1.1 无参构造1.2 构造的list中包含n个值为val的元素1.3 用[first, last)区间中的元素构造list1.4 拷贝构造 2 迭代器的使用2.1 begin end2.2 rbegin rend 3 容量操作3.1 empty size 4 获取元素4.1 front back 5 插入、删除、修改5.1 头插-push_front和尾插-push…...
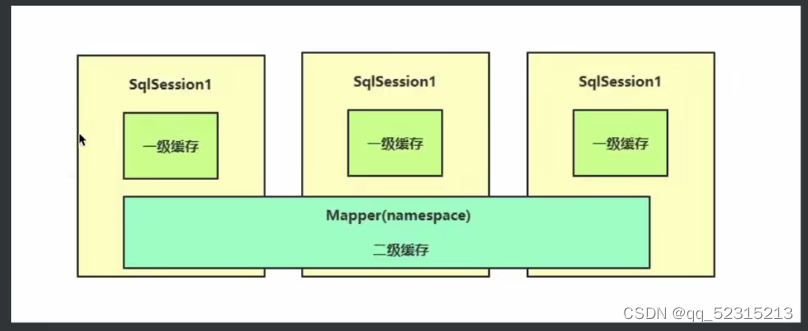
mybatis的缓存机制
视频教程_免费高速下载|百度网盘-分享无限制 (baidu.com) MyBatis 有一套灵活而强大的缓存机制,主要分为两级缓存:一级缓存(本地缓存)和二级缓存(全局缓存)。 一级缓存(本地缓存)&a…...

ChatGLM3报错:No chat template is defined for this tokenizer
使用官方提供的脚本创建ChatGLM3的DEMO: cd basic_demo python web_demo_gradio.py 出现效果异常问题: conversation [{role: user, content: 你好}, {role: assistant, content: 你好,有什么我可以帮助你的吗?\n\n<|im_end|…...

大数据学习之Flink、搞懂Flink的恢复策略
第一章、Flink的容错机制 第二章、Flink核心组件和工作原理 第三章、Flink的恢复策略 第四章、Flink容错机制的注意事项 第五章、Flink的容错机制与其他框架的容错机制相比较 目录 第三章、Flink的恢复策略 Ⅰ、恢复策略 1. Checkpoint: 2. Savepoint&#…...

C语言易忘操作符全集
目录 位操作符 1.按位与(&) 2.按位或(|) 3.按位异或(^) 4.按位取反(~) 5.左移(<<) 6.右移(>>) 逻辑操作符 1.逻辑与(&&) 2.逻辑或(||) 3.逻辑非(!) 位操作符 1.按位与(…...

网络请求 mvp mvvm get post delete put 请求
get 参数拼接 如下接口 localhost:8080/uav/plotting/page/app?pageNum1&pageSize10&appIde3c59e28-2032-4ddf-a762-7cec96f772a4&orgId65&plottingTypepoint GET("https:/uav/plotting/page/app") Observable<PlotList.DataBean> allPoin…...

研究生开题报告撰写:文言一心VSChatgpt3.5
文言一心 问:我是一名研二学生,请帮我生成一份研究生毕设开题答辩ppt框架。 答:好的,以下是一份研究生毕设开题答辩PPT的框架,供您参考: 幻灯片1:封面页 标题:研究生毕设开题答辩…...
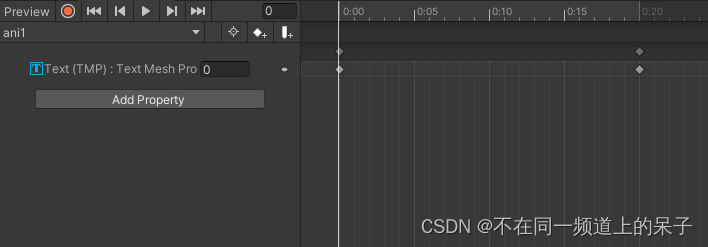
Unity animator动画倒放的方法
在Unity中, 我们有时候不仅需要animator正放的效果,也需要倒放的效果。但我们在实际制作动画的时候可以只制作一个正放的动画,然后通过代码控制倒放。 实现方法其实很简单,只需要把animator动画的speed设置为-1即为倒放ÿ…...

Dubbo源码解析第一期:如何使用Netty4构建RPC
一、背景 早期学习和使用Dubbo的时候(那时候Dubbo还没成为Apache顶级项目),写过一些源码解读,但随着Dubbo发生了翻天覆地的变化,那些文章早已过时,所以现在计划针对最新的Apache Dubbo源码来进行“阅读理解…...
unity刷新grid,列表
获取UIGrid 组件,更新列表 listParent.GetComponent().repositionNow true;...

蓝桥杯备赛 day 3 —— 高精度(C/C++,零基础,配图)
目录 🌈前言: 📁 高精度的概念 📁 高精度加法和其模板 📁 高精度减法和其模板 📁 高精度乘法和其模板 📁 高精度除法和其模板 📁 总结 🌈前言: 这篇文…...

人形机器人创新发展顶层设计与关键技术布局
系列文章目录 前言 随着新一轮科技革命和产业变革的深入推进,我国高度重视人形机器人的创新发展,提出了一系列具有前瞻性和战略性的指导意见。规划指出,到2025年,我国将初步建立人形机器人创新体系,攻克“大脑”、“小…...

C语言-算法-最小生成树
【模板】最小生成树 题目描述 如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出 orz。 输入格式 第一行包含两个整数 N , M N,M N,M,表示该图共有 N N N 个结点和 M M M 条无向边。 接下来 M M M 行…...

android 扫描某个包下的所有类
注意事项 如果在用Android Studio开发过程中,如果新增了类,扫描不到。只能把APP卸载了,才能扫描到。 可能是Instance Run 的影响。 后面研究一下这篇文章,看看能不能解决 Android 遍历Apk下的所有类文件 package com.trs.nmip.…...

STM32CubeIDE实战指南:从代码编译到一键下载的完整流程解析
1. STM32CubeIDE开发环境概述 对于刚接触STM32开发的工程师来说,选择一款合适的集成开发环境(IDE)至关重要。STM32CubeIDE是ST官方推出的免费开发工具,它集成了代码编辑、编译、调试和下载功能于一体,特别适合新手快速上手。我在实际项目中使…...

Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具
Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费用…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解
如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...
Pixel Framebuf库:图形化编程驱动LED矩阵,告别底层坐标换算
1. 项目概述:告别点灯,拥抱图形化LED矩阵编程如果你玩过Arduino或者树莓派,大概率接触过WS2812B这类可寻址LED,也就是大家常说的NeoPixel。单个灯珠的控制很简单,setPixelColor一下就能亮。但当你面对一个8x8、16x16甚…...

ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题
ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 当我们面对复杂的脑部MRI数据、肿瘤CT扫描或心血管影像时,最大…...

MedAgentBench:大模型临床决策能力评估基准详解与应用
1. 项目概述:当大模型成为医疗决策的“实习生” 最近在医疗AI的圈子里,一个名为“MedAgentBench”的开源项目引起了不小的讨论。这个由斯坦福机器学习组(Stanford ML Group)发布的项目,其核心目标非常明确:…...

基于WebSocket的机械爪远程控制桥接系统设计与实战
1. 项目概述:一个连接物理世界与数字世界的“机械爪”远程控制桥最近在捣鼓一个挺有意思的开源项目,叫lucas-jo/openclaw-bridge-remote。光看名字,你可能觉得这又是一个关于机器人或者机械臂的遥控项目,但实际深入进去࿰…...

基于规则引擎与AI Agent的Google Ads自动化营销系统设计与实践
1. 项目概述:当AI遇上Google Ads,一个自动化营销引擎的诞生最近在折腾一个挺有意思的项目,起因是发现很多团队在管理Google Ads广告时,依然在重复着大量手动、低效的操作。无论是关键词的日常拓词、否定关键词的筛选,还…...