GraphQL的力量:简化复杂数据查询
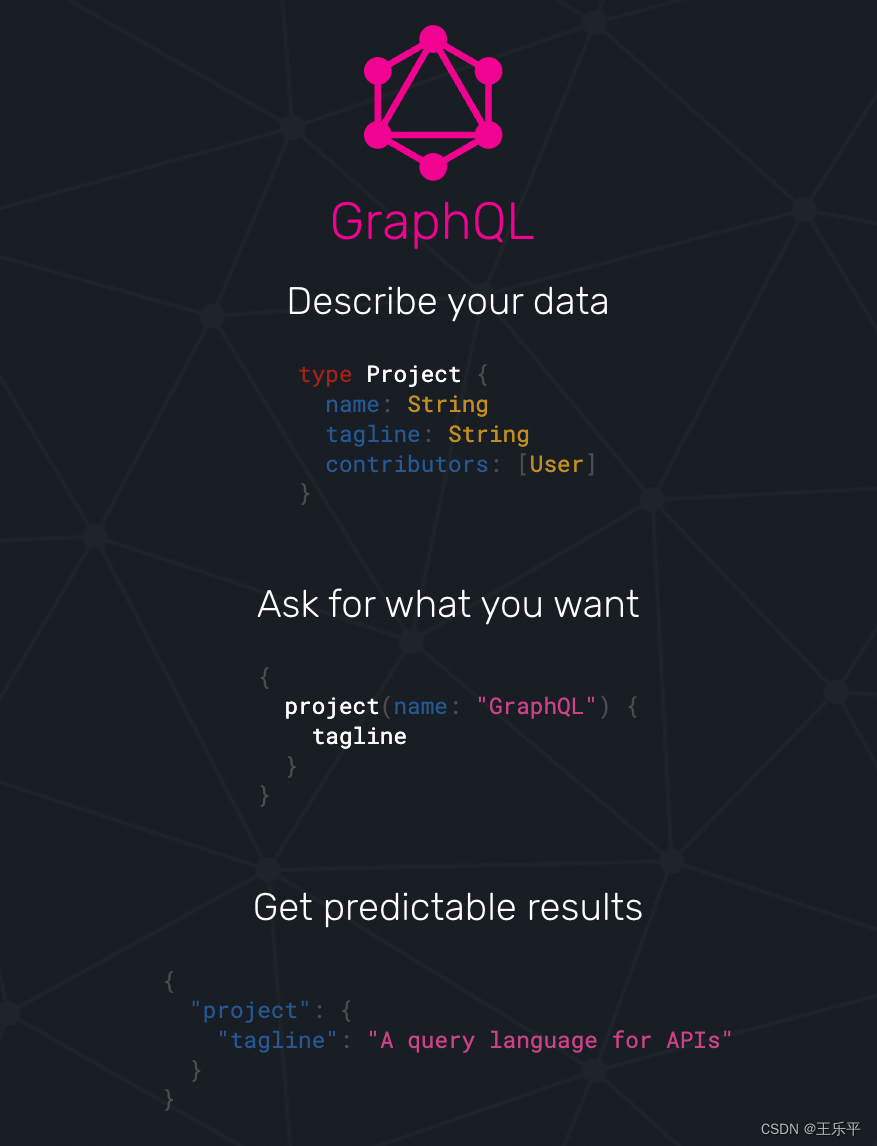
1. GraphQL
GraphQL 是一种由 Facebook 开发并于 2015 年公开发布的数据查询和操作语言,也是运行在服务端的运行时(runtime)用于处理 API 查询的一种规范。不同于传统的 REST API,GraphQL 允许客户端明确指定它们需要哪些数据,因此可以避免过度获取或者获取不足的问题。
GraphQL 有以下几个核心概念:
- 查询 (Query): 类似于 GET 请求,用于获取数据。
- 变更 (Mutation): 类似于 POST、PUT、DELETE 等请求,用于修改数据。
- 订阅 (Subscription): 允许客户端实时地获取数据更新。
- 类型系统 (Type System): GraphQL 使用强类型系统,API 中的每个数据都有一个预定义的类型。
2. 诞生背景
在 GraphQL 出现之前,RESTful API 是构建网络应用程序中客户端与服务器之间通信的主流方式。随着移动设备和复杂单页应用(SPA)的兴起,应用程序的接口需求变得越来越复杂。REST 接口在某些场景中开始显现出一些不足之处:
-
过度获取 (Over-fetching): 获取比客户端实际需要更多的数据。一个 RESTful 请求通常返回一个固定结构的数据对象,如果客户端只需要其中的几个字段,也要接收整个对象。
-
获取不足 (Under-fetching): 得到的数据不足以满足客户端的需要,导致客户端不得不发送多个请求以获取所有所需数据。在 RESTful 架构中,这通常发生在服务端资源高度正规化时,客户端需要通过多个端点组装所需的数据。
-
多版本并存: 随着时间的推移,为了满足不同客户端的特定需求,可能会出现多个版本的 API 并存。
-
前后端协作: 在 RESTful 架构下,前端开发者常常需要后端对 API 进行调整以适应界面的需求变化,这增加了协作的复杂性。
3. GraphQL 的解决方式
GraphQL 通过其设计和特性提供了解决传统 REST API 问题的方法。以下是具体问题及其解决方式:
-
过度获取 (Over-fetching):
- 解决方法: 在 GraphQL 中,客户端可以准确指定它们需要的字段,并且只有这些指定的字段会返回给客户端。这意味着客户端永远不会收到多余的数据,从而减少了不必要的数据传输和提高了性能。
-
获取不足 (Under-fetching):
- 解决方法: GraphQL 允许客户端在单个查询中请求所有必需的信息,即使这些信息分布在不同的“资源”或实体中。这样客户端只需要发起一个网络请求,就可以获取到完整的、它们所需的数据集合。
-
多版本并存:
- 解决方法: GraphQL 只需要一个版本的 API。由于客户端可以精确地请求它们需要的数据,所以后端只需不断迭代其 GraphQL schema 而无需担心会破坏现有客户端。这样,客户端和服务器可以独立进化而不会互相影响。
-
前后端协作:
- 解决方法: 在 GraphQL 中,由于存在一个明确的类型系统,前端工程师可以独立于后端工程师根据需求构造查询。这减少了前后端之间的沟通成本,使前端开发者能够更加自由地开发和迭代产品,而无需等待后端调整 API。
具体来说,GraphQL 解决这些问题的一些关键特性包括:
-
强类型系统 (Type System): GraphQL 的每一个 API 都基于强类型定义的 schema,这样就为自动生成文档、前后端的协同开发以及工具链的构建提供了坚实的基础。
-
声明式数据获取: 客户端使用 GraphQL 的查询语言来声明它们所需的数据结构,并且服务端正好按照这种结构返回数据。这样做的好处是,无论数据需求如何变化,只要服务端的 schema 支持,客户端可以自行调整查询,而无需服务端进行修改。
-
单一端点: 与 REST API 不同的是,GraphQL 通常只有一个端点,所有的查询和变更都通过这个端点发起。这消除了处理多个端点可能导致的复杂性。
-
查询组合: GraphQL 查询可以很容易地组合在一起,即使它们涉及到不同的资源类型,客户端还可以在一个查询中请求关联数据。
通过这样一套机制,GraphQL 提供了比传统 RESTful API 更灵活、可扩展的数据交互方式,满足现代应用开发对接口灵活性和效率的要求。
5. 引入 graphQL 在服务端的变化
引入 GraphQL 后,后端开发会有一系列的变化,从设置服务器开始,到重新设计数据获取的方式,再到实现复杂的解析逻辑。以下是引入 GraphQL 后可能需要做的改动:
1. 设置 GraphQL 服务器
首先,你需要引入 GraphQL 相关的库,并设置一个 GraphQL 服务器,这通常意味着要添加一个新的端点来处理 GraphQL 请求。
前:RESTful API 服务器示例(使用 Express.js)
const express = require("express");
const app = express();app.get("/api/books/:id", (req, res) => {// 根据 id 获取书籍信息的逻辑
});app.listen(3000, () => {console.log("Server running on port 3000");
});
后:GraphQL 服务器示例(使用 Express.js + express-graphql)
const express = require("express");
const { graphqlHTTP } = require("express-graphql");
const { buildSchema } = require("graphql");const schema = buildSchema(`type Query {book(id: ID!): Book}type Book {id: ID!title: String!author: String!}
`);const root = {book: ({ id }) => {// 根据 id 获取书籍信息的逻辑},
};const app = express();
app.use("/graphql",graphqlHTTP({schema,rootValue: root,graphiql: true,})
);app.listen(3000, () => {console.log("GraphQL server running on port 3000");
});
2. 重新设计 API Schema
你需要根据业务数据设计 GraphQL schema,这通常涉及定义查询和变更类型、数据模型类型以及它们之间的关系。
前:RESTful API 设计通常是基于资源的 URL 设计
- GET /api/books/:id
- POST /api/books
- PUT /api/books/:id
- DELETE /api/books/:id
后:GraphQL 中只有单一端点,schema 定义了所有的查询和变更
type Query {book(id: ID!): Book
}type Mutation {createBook(title: String!, author: String!): BookupdateBook(id: ID!, title: String, author: String): BookdeleteBook(id: ID!): Book
}type Book {id: ID!title: String!author: String!
}
3. 实现解析函数
你需要为 schema 中定义的每一个字段编写解析函数,这些函数定义了如何获取或修改数据。
前:RESTful API 中,每个端点的处理函数通常直接操作数据库或调用服务层的代码
app.get("/api/books/:id", (req, res) => {const { id } = req.params;// 从数据库中找到书籍并返回
});
后:GraphQL 中,你编写解析函数来获取数据
const root = {book: ({ id }) => {// 使用 id 从数据库中找到书籍并返回},createBook: ({ title, author }) => {// 创建新书籍并返回},// ...更多解析函数
};
4. 调整前后端交互
在 GraphQL 中,前端不再需要知道许多不同的端点,而是通过构造查询和变更来获取所需的数据。
前:RESTful API 调用示例(使用 fetch)
fetch("/api/books/1").then((response) => response.json()).then((book) => console.log(book));
后:GraphQL 调用示例(使用 fetch)
fetch("/graphql", {method: "POST",headers: { "Content-Type": "application/json" },body: JSON.stringify({query: `{book(id: "1") {titleauthor}}`,}),
}).then((response) => response.json()).then((data) => console.log(data.data.book));
引入 GraphQL 后,后端需进行以下主要改动:
- 配置 GraphQL 服务端点。
- 定义 GraphQL schema,包括类型定义和操作。
- 实现对应的解析函数(resolvers),用于获取和修改数据。
- 适配现有数据源和服务层,以支持新的解析函数。
- 更新前后端交互方式,前端使用 GraphQL 查询和变更代替 REST API 调用。
6. 是否接入 GraphQL 的判断标准
判断项目是否需要接入 GraphQL 主要取决于项目的现有需求、未来的发展以及潜在的收益是否超过了接入成本。以下是一些评估是否需要接入 GraphQL 的考量因素:
现有 API 的局限性
- 数据获取问题:如果客户端经常面临过度获取或获取不足的问题,导致不必要的网络流量或多次往返请求,则 GraphQL 可以通过允许客户端精确指定所需数据来解决这些问题。
- 复杂的数据交互:如果你的应用需要处理复杂的数据交互,或者有多个数据模型之间有复杂的关联,GraphQL 的查询合并能力可以简化客户端的请求逻辑。
前后端开发流程
- 频繁的前后端协调:如果前端团队经常需要后端团队为新的界面或组件调整 API,引入 GraphQL 可以让前端独立于后端更灵活地获取数据。
- API 版本管理挑战:如果项目中存在多个版本的 API,并且难以统一和维护,GraphQL 可以提供更灵活的数据交互而无需维护多个 API 版本。
性能和优化需求
- 移动应用或带宽优化:对于移动或低带宽环境,GraphQL 的按需数据查询可减少不必要的数据传输,从而优化性能和用户体验。
技术生态和团队技能
- 团队技能和资源:考虑团队是否有能力学习和实现 GraphQL,以及是否有足够的资源来支持迁移过程。
- 社区支持和生态系统:考察 GraphQL 的社区支持程度以及是否有适合项目需求的库和工具。
成本与收益分析
- 长期收益:思考 GraphQL 是否能带来长期的收益,例如提升开发效率、减少错误和提升性能。
- 迁移成本:评估接入 GraphQL 的直接和间接成本,包括开发、测试、部署和维护。
策略和风险
- 逐步迁移的可行性:评估是否可以逐步引入 GraphQL,而不是一次性重构整个后端服务。
使用场景
- 公共 API:如果你的项目是面向广大开发者的公共 API,那么提供 GraphQL 接口可以增加其灵活性和吸引力。
- 多客户端应用:如果你的服务需要支持多种类型的客户端(如 Web、移动、桌面等),GraphQL 可以通过一个统一的接口满足不同客户端的数据需求。
最终是否接入 GraphQL 取决于对以上因素的评估以及对业务优先级的考量。如果经过分析,你认为现有的 REST API 已经足够好,且引入 GraphQL 的成本超出了预期收益,那么可能没有必要立即进行迁移。但如果 GraphQL 带来的好处明显,可以显著提升应用的数据交互效率和开发体验,那么接入 GraphQL 可能是一个值得的投资。在任何情况下,建议先进行小规模的试点项目来评估 GraphQL 在实际环境中的效果。
7. 高并发场景注意事项
在高并发场景下处理 GraphQL 请求需要考虑几个关键因素,以确保应用程序的性能和稳定性。以下是一些处理方法和最佳实践:
1. 查询优化
- 查询分析和限制:使用查询分析工具来防止复杂度过高的查询,限制查询的深度和大小,避免因为过于复杂的查询导致性能问题。
- 查询白名单:预定义允许的查询列表,避免不需要或恶意的查询对服务器造成负担。
2. 性能优化
- 数据加载器 (Data Loader):使用数据加载器(如 Facebook 的 DataLoader)来批处理和缓存后端数据请求,减少数据库访问次数,防止 N+1 查询问题。
- 持久化查询:将常见的查询结果持久化或缓存起来,以便更快地返回数据,减少对数据库和计算资源的请求。
3. 服务器优化
- 服务器扩展:在必要时扩展服务器实例,可以是水平扩展(增加更多服务器)或垂直扩展(增加单个服务器的资源)。
- 负载均衡:使用负载均衡器来分配请求到不同的服务器实例。
- 异步和非阻塞操作:使用异步 IO 和非阻塞操作来改善性能和资源利用率。
4. 缓存策略
- 应用级缓存:在应用层面实现对象缓存,如使用 Redis 或 Memcached 来缓存常用数据。
- CDN 缓存:使用内容分发网络(CDN)缓存静态内容和公共查询。
5. 模块化和微服务
- 模块化 schema:将 GraphQL schema 组织成模块,有助于分离关注点,提升维护性。
- 微服务架构:在复杂系统中,考虑使用微服务架构,可以独立扩展和维护不同的业务逻辑。
6. 监控和日志
- 性能监控:实现性能监控,记录响应时间和系统资源使用情况,以便快速发现性能瓶颈。
- 日志记录:记录详细的日志信息,以便在出现问题时进行调试和优化。
7. 安全性和控制
- 速率限制:实施速率限制和请求节流来控制每个用户或 IP 地址的请求数量。
- 身份验证和授权:确保所有请求都通过必要的身份验证和授权检查,防止未授权的访问和资源滥用。
8. 错误处理和冗余
- 错误处理:优化错误处理逻辑,防止异常导致的服务中断。
- 服务冗余:设置服务冗余,如数据库和服务器的冗余副本,确保服务的高可用性。
在高并发场景下处理 GraphQL 请求需要综合考虑查询优化、服务器性能、缓存、监控和安全等多个方面。通常需要根据实际场景和业务需求来定制解决方案,并通过持续的监控和优化来维护系统的健康状态。此外,也可以考虑使用云服务和 Serverless 架构来动态调整资源,应对高并发带来的挑战。
8. GraphQL 生态

GraphQL 的生态系统是由许多工具、库、平台和社区支持的资源组成的。这个生态系统可以帮助开发者在不同的阶段和不同的层面上使用 GraphQL,包括创建、运行、测试和集成 GraphQL API。以下是 GraphQL 生态系统的一些主要类别和资源:
查询语言和运行时
- GraphQL.js:Facebook 官方的 JavaScript GraphQL 实现。
- GraphQL-Java:用于 Java 的 GraphQL 库。
- graphql-ruby:Ruby 实现的 GraphQL 库。
- Graphene:用于 Python 的 GraphQL 框架,有 Django 集成版本 Graphene-Django。
客户端库
- Apollo Client:功能丰富的 GraphQL 客户端,用于管理数据和缓存,支持多个前端框架。
- Relay:为 React 应用构建的 GraphQL 客户端,专注于性能和紧密集成。
- urql:一个简单且可扩展的 GraphQL 客户端,支持 React 和其他 JavaScript 库。
服务端库和工具
- Apollo Server:一个用于构建 GraphQL 服务器的开源库,与 Express、Koa、Hapi 等多个 Node.js 服务器框架兼容。
- GraphQL Yoga:基于 Express 的轻量级 GraphQL 服务器,易于设置。
- Express-GraphQL:将 GraphQL API 集成到 Express 应用中的库。
- Hasura:即时的 GraphQL API 生成器,可以直接连接到你的数据库并自动创建 GraphQL API。
UI 开发工具
- GraphiQL:一个交互式的 Web IDE,用于在浏览器中测试 GraphQL 查询。
- GraphQL Playground:一个功能丰富的 GraphQL IDE,类似于 GraphiQL,但包含更多功能,如支持多个环境、交互式文档等。
代码生成器
- GraphQL Code Generator:一个工具,它可以从你的 GraphQL schema 和操作生成前端和后端的代码。
- Apollo Tooling:用于开发 GraphQL 的工具集,包括代码生成、类型生成等。
中间件和集成
- graphql-middleware:一个允许开发者为 GraphQL 服务器添加中间件的库。
- Prisma:将数据库转换为 GraphQL API 的工具,提供 ORM 支持。
测试工具
- EasyGraphQL Tester:用于测试 GraphQL API 的 JavaScript 库。
- Apollo Server Testing:Apollo Server 的测试工具,使得集成测试更加容易。
监控和性能
- Apollo Studio (以前的 Apollo Engine):用于监控和优化 GraphQL API 性能的工具。
- GraphQL Network Inspector:Chrome 扩展程序,用于监控 GraphQL 网络请求。
社区和学习资源
- GraphQL.org:官方 GraphQL 网站,包括文档、教程和社区资源。
- How to GraphQL:一个全面的学习平台,提供 GraphQL 的教程和课程。
安全工具
- graphql-shield:用于 GraphQL 服务器的权限系统,允许创建基于规则的访问控制。
数据库和持久化
- Postgraphile:可以快速将 PostgreSQL 数据库转变成一个强大的 GraphQL API 服务器。
- FaunaDB:提供图形支持的数据库,与 GraphQL 无缝集成。
GraphQL 生态系统不断发展,不断有新的工具和库被创建出来,以支持 GraphQL 在更多场景和平台上的应用。开发者可以根据项目的需求和团队的偏好,选择合适的工具来构建和维护 GraphQL API。
9. 旧项目改造建议
将一个原有的旧项目改造成 GraphQL 的确可能是一项复杂的任务,这取决于项目的规模、现存的 API 设计、后端架构以及你希望从 GraphQL 中获得的好处。以下是一些建议和考虑因素,帮助你评估和简化改造过程:
简化改造的方法:
-
逐步迁移:不需要一步到位地完成所有改造。你可以逐步迁移,例如,先为一小部分功能引入 GraphQL。同时保留 REST API 和 GraphQL,然后逐步扩大 GraphQL 的应用范围。
-
使用桥接层:在 REST API 之上构建一个 GraphQL 层,这个层作为翻译器,将 GraphQL 查询转换为对底层 REST API 的调用。这可以使得你在不触碰现存业务逻辑的情况下利用 GraphQL。
-
工具和库:使用现有的工具和库,如
Apollo Server,它可以帮你快速地搭建一个 GraphQL 服务,并集成到现有的 Node.js 应用程序中。 -
自动生成 Schema:考虑使用工具自动生成 GraphQL schema,特别是如果你的数据库模式非常稳定的话。例如,
Postgraphile和Prisma可以从现有的 PostgreSQL 数据库生成完整的 GraphQL API。 -
模块化:将 GraphQL schema 分解成多个模块,逐模块实施迁移。可以分类型,也可以按业务域来分。
判断是否应该进行改造:
-
客户端需求:如果你的前端团队经常因为数据过多或过少而不得不进行多余的网络请求,或者需要更灵活地获取数据,那么 GraphQL 可能是一个合适的选择。
-
API 版本管理:如果你在管理多个版本的 API,并且想简化这个流程,GraphQL 由于其灵活性,可能是一个更好的解决方案。
-
性能考虑:如果应用的性能受限于数据传输,例如移动应用或网络条件不佳的环境,GraphQL 的精确数据获取能力可以帮助优化性能。
-
前后端分离:如果你的项目是前后端分离的架构,并且希望前端有更大的自主性来决定数据需求,那么迁移到 GraphQL 可以减少前后端之间的依赖。
风险和挑战:
-
学习曲线:GraphQL 有自己的查询语言和概念,团队成员可能需要一些时间来学习和适应。
-
重构成本:重构可能会引入 bug 和性能问题,需要投入时间和资源来保证平稳过渡。
-
现有架构的兼容性:改造可能需要对现有的数据访问层进行大量修改,以适配 GraphQL 的解析器和类型系统。
-
监控和安全:引入 GraphQL 之后,需要考虑新的监控和安全策略,因为所有请求都通过单一端点进入,可能会有不同的安全挑战。
综合来看,是否对旧项目进行改造需要平衡项目需求、预期好处与可能的成本。如果决定迁移到 GraphQL,采取逐步迁移的策略通常更为稳妥,可以降低风险并逐步评估新技术的影响。
10. 简单示例
下面我将提供一些基本的 GraphQL 代码示例,包括定义一个简单的 GraphQL schema、编写查询(Query)、变更(Mutation)以及在 Node.js 环境中设置一个简单的 GraphQL 服务器。
定义 GraphQL Schema
在 GraphQL 中,你需要定义一个类型系统(schema),在这个 schema 中指定你的数据模型和可用的查询和变更操作。以下是一个简单的 schema 示例:
type Query {book(id: ID!): Bookauthor(name: String!): Author
}type Mutation {addBook(title: String!, author: String!): Book
}type Book {id: ID!title: String!author: Author!
}type Author {id: ID!name: String!books: [Book!]
}
编写查询 (Query)
一旦你有了 schema,你就可以通过编写查询来获取数据。以下是一些查询示例:
# 获取 ID 为 1 的书籍信息
query {book(id: "1") {idtitleauthor {name}}
}# 获取名为 "J.K. Rowling" 的作者信息
query {author(name: "J.K. Rowling") {idnamebooks {title}}
}
编写变更 (Mutation)
如果你想修改数据,你可以通过编写变更来实现。以下是一个变更示例:
# 添加一本新书
mutation {addBook(title: "Harry Potter and the Sorcerer's Stone"author: "J.K. Rowling") {idtitle}
}
在 Node.js 中设置 GraphQL 服务器
你可以使用 express 和 express-graphql 快速设置一个 GraphQL 服务器。首先,安装必要的 npm 包:
npm install express express-graphql graphql
然后可以编写如下代码来启动服务器:
const express = require("express");
const { graphqlHTTP } = require("express-graphql");
const { buildSchema } = require("graphql");// 使用 GraphQL schema 语言构建一个 schema
const schema = buildSchema(`type Query {hello: String}
`);// 根提供者提供 API 的每个端点的解析器函数
const root = {hello: () => "Hello, world!",
};const app = express();
app.use("/graphql",graphqlHTTP({schema: schema,rootValue: root,graphiql: true, // 开启 GraphiQL 工具进行测试})
);app.listen(4000, () => {console.log("Running a GraphQL API server at http://localhost:4000/graphql");
});
运行上述代码后,你可以在浏览器中访问 http://localhost:4000/graphql 并使用 GraphiQL 工具来发送查询和变更请求。
这些示例保持简单明了的目的,并且没有涉及错误处理、认证、高级的 schema 设计或数据持久化等方面的内容。在实际项目中,GraphQL 服务端的实现会更为复杂。

github原文地址
相关文章:
GraphQL的力量:简化复杂数据查询
1. GraphQL GraphQL 是一种由 Facebook 开发并于 2015 年公开发布的数据查询和操作语言,也是运行在服务端的运行时(runtime)用于处理 API 查询的一种规范。不同于传统的 REST API,GraphQL 允许客户端明确指定它们需要哪些数据&am…...
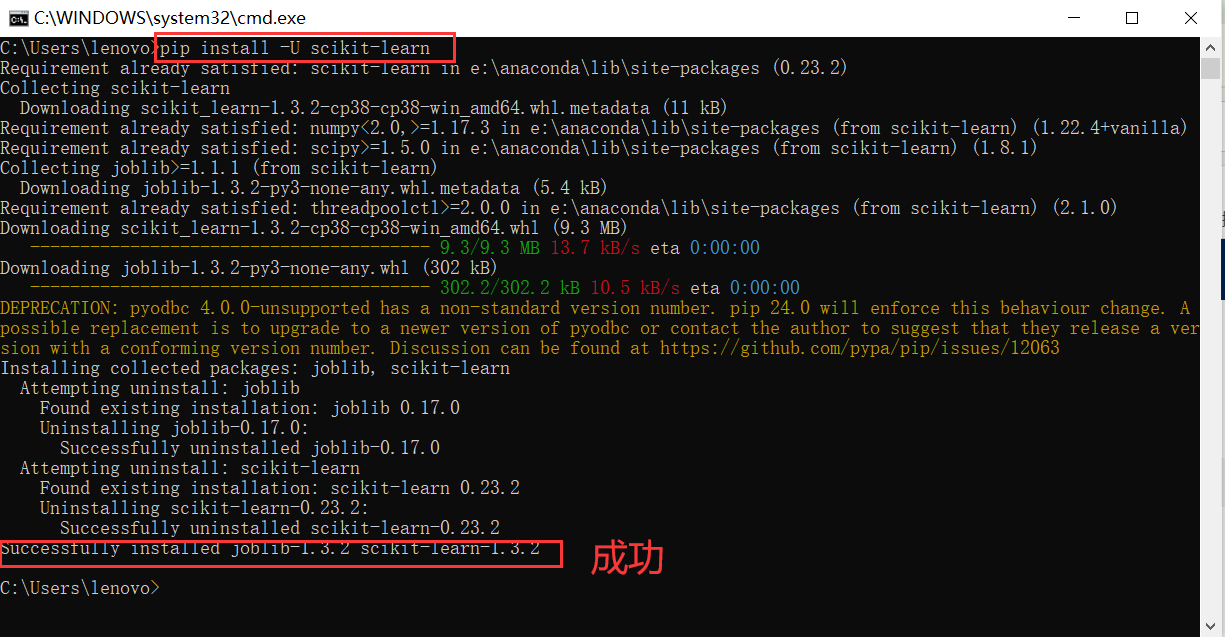
python环境安装sklearn及报错解决
安装 如刚开始安装,还未遇到问题请直接从重新安装库开始看,如果遇到报错,从问题开始看 问题 python安装sklearn报错 ,报错信息如下 File "<stdin>", line 1pip install scikit-learn^ SyntaxError: invalid s…...

log4j:WARN Please initialize the log4j system properly的解决办法
背景:很多次创建新项目log4j都出现以下2个警告: log4j:WARN No appenders could be found for logger (org.springframework.boot.ApplicationServletEnvironment).log4j:WARN Please initialize the log4j system properly 网上查询都是在说缺少以下jar…...

虹科分享丨汽车技术的未来:Netropy如何测试和确保汽车以太网的性能
来源:艾特保IT 虹科分享丨汽车技术的未来:Netropy如何测试和确保汽车以太网的性能 原文链接:https://mp.weixin.qq.com/s/G8wihrzqpJJOx5i0o63fkA 欢迎关注虹科,为您提供最新资讯! #汽车以太网 #车载网络 #Netropy …...

代码CE:reference to ‘XX‘ is ambiguous
代码CE:reference to ‘XX’ is ambiguous 今天提交代码的时候一直错误,CE,搞不明白明明在dev上成功,为什么提交失败。 现在懂了,因为定义的变量和C内部函数或变量重名了。修改之后即可AC。 int data[21][21]{0}; int maxsum[21…...
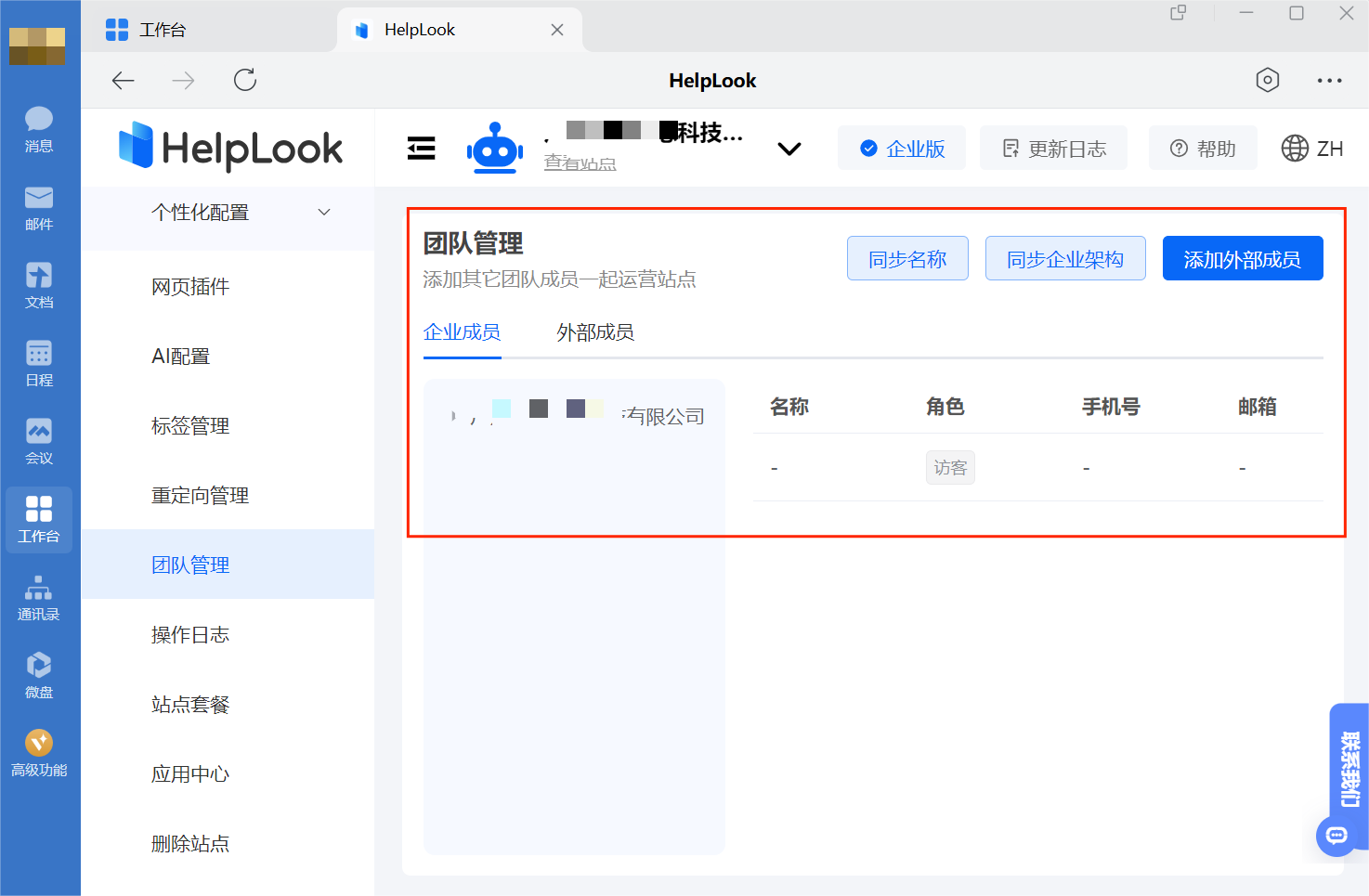
如果想将企业微信的组织架构同步到内部知识库咋搞?方法来也!
在现代企业的运营中,内部知识库不仅储存了公司的宝贵知识资产,还充当着员工信息共享和协作的核心平台。为了保障知识库的效能最大化,使其成为支持决策、创新和培训的强大工具,企业必须拥有一套周到的权限管理机制。对此࿰…...
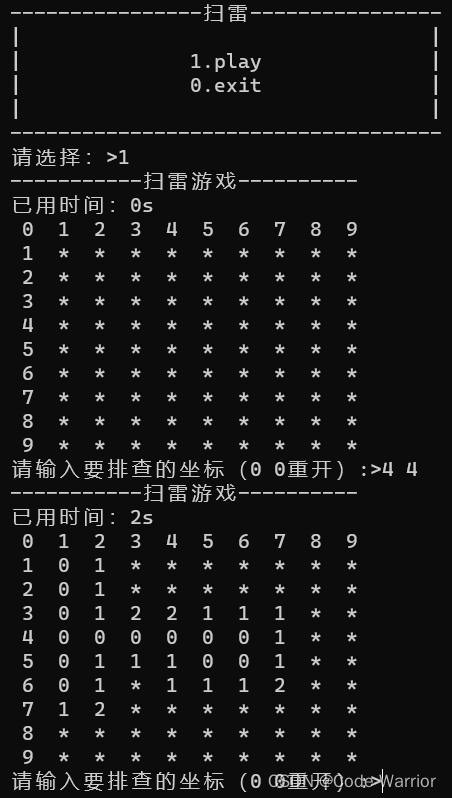
【c语言】扫雷
前言: 扫雷是一款经典的单人益智游戏,它的目标是在一个方格矩阵中找出所有的地雷,而不触碰到任何一颗地雷。在计算机编程领域,扫雷也是一个非常受欢迎的项目,因为它涉及到许多重要的编程概念,如数组、循环…...

自然语言处理的崛起:从初步分析到深度理解
自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,旨在让计算机能够理解和生成人类语言。随着时间的推移,NLP 经历了一系列革命性的变化,从简单的规则和模式匹配到如今的深度学习模型,它们使计算…...

Git学习笔记:版本回滚
文章目录 回到过去:开启新时间线,时间分叉路口1. 回溯开发2. 临时恢复特性3. 实验性开发4. 分支维护和发布5. 调试历史问题类比推理: 方法:1. 临时查看旧版本2. 永久回滚到旧版本3. 创建新的分支指向旧版本 回到过去:开…...

OpenCV图像的基本操作
图像的基本操作(Python) 素材图 P1:die.jpg P2:cool.jpg V:rabbit.mp4, 下载地址 读取展示-图像 import cv2img_1 cv2.imread(./die.jpg) # default cv2.IMREAD_COLOR print("die.jpg shape(imre…...

小白水平理解面试经典题目LeetCode 594 Longest Harmonious Subsequence(最大和谐字符串)
594 最大和谐字符串 这道题属于字符串类型题目,解决的办法还是有很多的,暴力算法,二分法,双指针等等。 题目描述 和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。 现在,给你一个整数数组 nums …...
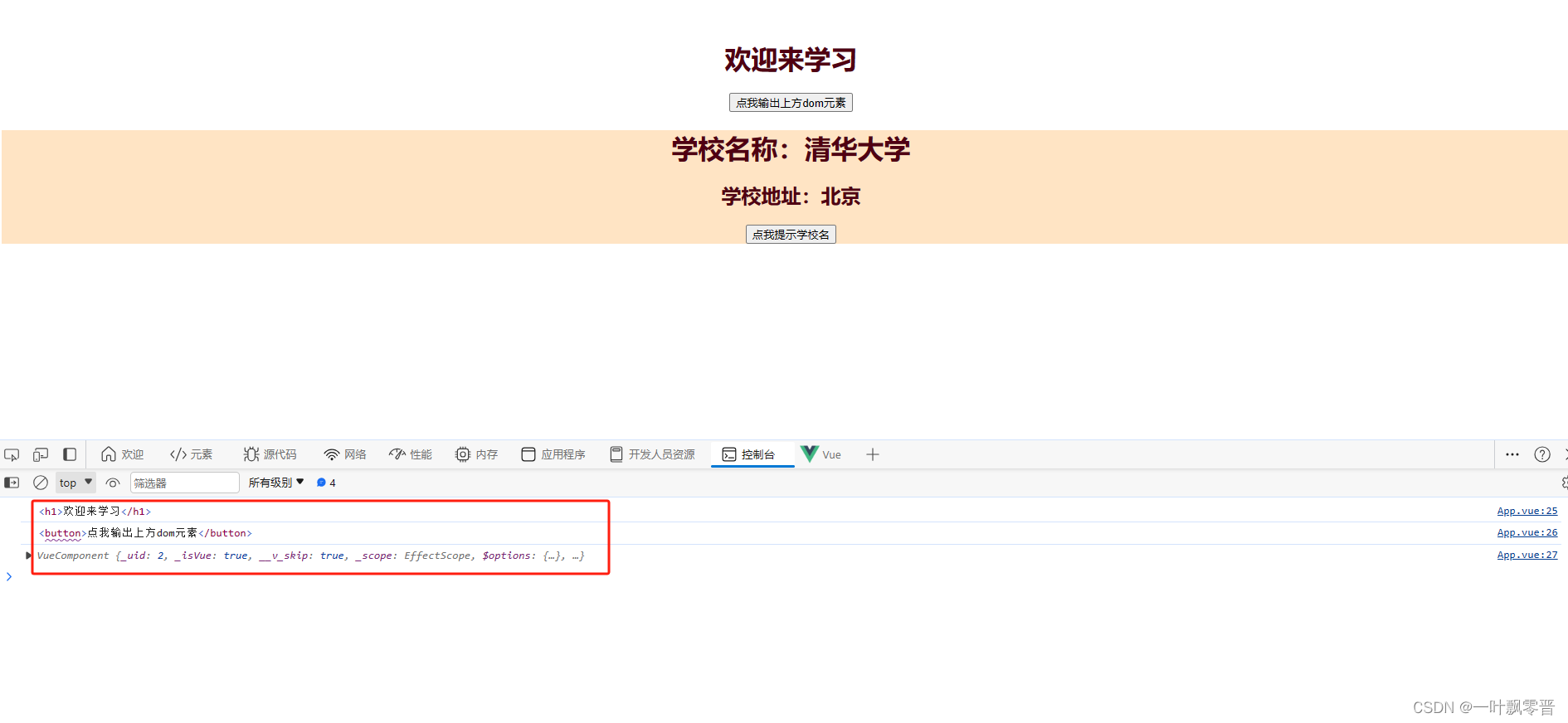
Vue-35、Vue中使用ref属性
1、ref属性 2、代码 <template><div id"app"> <!-- <img alt"Vue logo" src"./assets/logo.png">--><h1 v-text"msg" ref"title"></h1><button click"showDOM" ref&…...
网络通信(15)-C#TCP客户端掉线重连实例
本文上接前面的文章使用Socket在C#语言环境下完成TCP客户端的掉线重连实例。 掉线重连需要使用心跳包发送测试网络的状态,进而进入重连循环线程。 前面实例完成的功能: 客户端与服务器连接,实现实时刷新状态。 客户端接收服务器的数据。 客户端发送给服务器的数据。 客…...
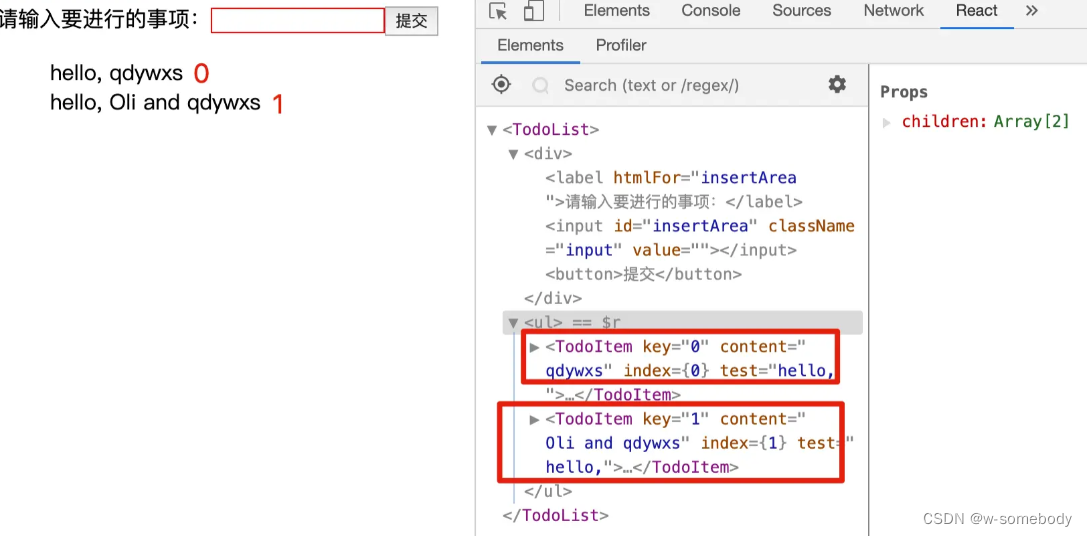
React进阶 - 14(说一说”虚拟DOM“中的”Diff算法“)
本章内容 目录 一、了解 Diff 算法二、key 值的重要性三、为什么不建议使用 index 做 key 值 上一节我们初步了解了 React中的”虚拟 DOM“ ,本节我们来说一说”虚拟DOM“中的”Diff算法“ 一、了解 Diff 算法 在上一篇中,我们有讲到:当 st…...

#GPU|LLM|AIGC#集成显卡与独立显卡|显卡在深度学习中的选择与LLM GPU推荐
区别 核心区别:显存,也被称作帧缓存。独立显卡拥有独立显存,而集成显卡通常是没有的,需要占用部分主内存来达到缓存的目的 集成显卡: 是集成在主板上的,与主处理器共享系统内存。 一般会在很多轻便薄型的…...

HCIP-IPV6实验
实验拓扑 实验需求 全网可达 实验思路 配置IP地址 配置路由协议-ospf 配置R2 配置IPV6 配置R2Tunnel 将所有地址引流到Tunnel0/0/0接口 ripng配置 汇总 实验步骤 配置IP地址 以R2为例 [Huawei]sys r2 [r2]int g0/0/0 [r2-GigabitEthernet0/0/0]ip address 12.1.1…...

如何训练和导出模型
介绍如何通过DI-engine使用DQN算法训练强化学习模型 一、什么是DQN算法 DQN算法,全称为Deep Q-Network算法,是一种结合了Q学习(一种价值基础的强化学习算法)和深度学习的算法。该算法是由DeepMind团队在2013年提出的,…...

Springboot注解@Aspect(一)之@Aspect 作用和Aop关系详解
目录 Aspect的使用 配置 作用 通知相关的注解 例子 结果: Aspect作用和Spring Aop关系 示例 标签表达式 Aspect的使用 配置 要启用 Spring AOP 和 Aspect 注解,需要在 Spring 配置中启用 AspectJ 自动代理,但是在 Spring Boot 中&a…...

自动化防DDoS脚本
简介 DDoS (分布式拒绝服务攻击)是一种恶意的网络攻击,旨在通过占用目标系统的资源,使其无法提供正常的服务。在DDoS攻击中,攻击者通常控制大量的被感染的计算机或其他网络设备,同时将它们协调起来向目标系…...

ubuntu怎么查看有几个用户
在Ubuntu中,可以使用以下命令来查看系统中的用户数量: cat /etc/passwd | wc -l这个命令会读取 /etc/passwd 文件中的用户信息,并使用 wc -l 命令来计算行数,即用户数量。 另外,你也可以使用以下命令来查看当前登录到…...

UWB车内目标探测技术【附仿真】
✨ 长期致力于UWB雷达、活体、目标检测、生命体征、信号模型研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)UWB雷达生命体征信号建模与自适应杂波抑制…...

如何快速将STL转换为STEP:5个高效转换技巧指南
如何快速将STL转换为STEP:5个高效转换技巧指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp STL到STEP格式转换是3D设计和工程制造领域的关键桥梁,而stltostp正是解决…...

Avogadro 2:开源分子可视化库的终极技术解析
Avogadro 2:开源分子可视化库的终极技术解析 【免费下载链接】avogadrolibs Avogadro libraries provide 3D rendering, visualization, analysis and data processing useful in computational chemistry, molecular modeling, bioinformatics, materials science,…...

HiveWE:现代魔兽争霸III地图编辑器终极指南
HiveWE:现代魔兽争霸III地图编辑器终极指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版地图编辑器的缓慢加载和复杂操作而烦恼吗?HiveWE作为一款专注于速度…...

如何通过Python快速接入Taotoken并调用多模型API完成文本生成任务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何通过Python快速接入Taotoken并调用多模型API完成文本生成任务 1. 准备工作:获取API Key与模型ID 在开始编写代码之…...

【Arcgis实战技巧】巧用DOM目视解译,从DSM中精准“挖”出地面高程点
1. 为什么需要从DSM中提取地面高程点? 在测绘和地理信息领域,数字表面模型(DSM)记录了地表所有物体的顶部高程信息,包括建筑物、树木、电线杆等。但很多时候我们需要的是数字高程模型(DEM)&…...

长期使用后观察Taotoken聚合路由在高并发下的稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后观察Taotoken聚合路由在高并发下的稳定性 在构建和运营依赖大模型API的中大型项目时,服务的长期稳定性是技术…...
)
用Arduino UNO和L298N驱动板,手把手教你让麦轮小车原地画个‘8’字(附完整代码)
用Arduino UNO和L298N驱动板实现麦轮小车8字轨迹编程实战 想让你的麦克纳姆轮小车跳出机械舞步吗?一个完美的"8"字轨迹不仅能展示麦轮的全向移动特性,更是检验运动控制算法的绝佳试金石。作为已经完成基础搭建的Arduino玩家,这个项…...

基于ChatGPT与Next.js的React组件自然语言生成器开发实战
1. 项目概述:一个由ChatGPT驱动的React组件实时生成器 作为一名在React生态里摸爬滚打了多年的前端开发者,我深知从零开始构建一个UI组件,尤其是那些需要反复调整样式和交互逻辑的组件,是多么耗时耗力。我们常常在Figma里画好了设…...

机器学习在芯片电容提取中的应用与挑战
1. 电容提取的技术挑战与机器学习机遇在芯片设计流程中,电容提取是决定最终产品性能的关键环节。当设计进入物理实现阶段,工程师需要精确计算互连结构中导体间的寄生电容,这些数据直接影响时序收敛和功耗分析。传统基于数值求解器的方法&…...