【Storm】【六】Storm 集成 Redis 详解
Storm 集成 Redis 详解
一、简介
Storm-Redis 提供了 Storm 与 Redis 的集成支持,你只需要引入对应的依赖即可使用:
<dependency><groupId>org.apache.storm</groupId><artifactId>storm-redis</artifactId><version>${storm.version}</version><type>jar</type>
</dependency>
Storm-Redis 使用 Jedis 为 Redis 客户端,并提供了如下三个基本的 Bolt 实现:
- RedisLookupBolt:从 Redis 中查询数据;
- RedisStoreBolt:存储数据到 Redis;
- RedisFilterBolt : 查询符合条件的数据;
RedisLookupBolt、RedisStoreBolt、RedisFilterBolt 均继承自 AbstractRedisBolt 抽象类。我们可以通过继承该抽象类,实现自定义 RedisBolt,进行功能的拓展。
二、集成案例
2.1 项目结构
这里首先给出一个集成案例:进行词频统计并将最后的结果存储到 Redis。项目结构如下:

用例源码下载地址:storm-redis-integration
2.2 项目依赖
项目主要依赖如下:
<properties><storm.version>1.2.2</storm.version>
</properties><dependencies><dependency><groupId>org.apache.storm</groupId><artifactId>storm-core</artifactId><version>${storm.version}</version></dependency><dependency><groupId>org.apache.storm</groupId><artifactId>storm-redis</artifactId><version>${storm.version}</version></dependency>
</dependencies>
2.3 DataSourceSpout
/*** 产生词频样本的数据源*/
public class DataSourceSpout extends BaseRichSpout {private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");private SpoutOutputCollector spoutOutputCollector;@Overridepublic void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {this.spoutOutputCollector = spoutOutputCollector;}@Overridepublic void nextTuple() {// 模拟产生数据String lineData = productData();spoutOutputCollector.emit(new Values(lineData));Utils.sleep(1000);}@Overridepublic void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {outputFieldsDeclarer.declare(new Fields("line"));}/*** 模拟数据*/private String productData() {Collections.shuffle(list);Random random = new Random();int endIndex = random.nextInt(list.size()) % (list.size()) + 1;return StringUtils.join(list.toArray(), "\t", 0, endIndex);}}
产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
2.4 SplitBolt
/*** 将每行数据按照指定分隔符进行拆分*/
public class SplitBolt extends BaseRichBolt {private OutputCollector collector;@Overridepublic void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {this.collector = collector;}@Overridepublic void execute(Tuple input) {String line = input.getStringByField("line");String[] words = line.split("\t");for (String word : words) {collector.emit(new Values(word, String.valueOf(1)));}}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word", "count"));}
}
2.5 CountBolt
/*** 进行词频统计*/
public class CountBolt extends BaseRichBolt {private Map<String, Integer> counts = new HashMap<>();private OutputCollector collector;@Overridepublic void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {this.collector=collector;}@Overridepublic void execute(Tuple input) {String word = input.getStringByField("word");Integer count = counts.get(word);if (count == null) {count = 0;}count++;counts.put(word, count);// 输出collector.emit(new Values(word, String.valueOf(count)));}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word", "count"));}
}
2.6 WordCountStoreMapper
实现 RedisStoreMapper 接口,定义 tuple 与 Redis 中数据的映射关系:即需要指定 tuple 中的哪个字段为 key,哪个字段为 value,并且存储到 Redis 的何种数据结构中。
/*** 定义 tuple 与 Redis 中数据的映射关系*/
public class WordCountStoreMapper implements RedisStoreMapper {private RedisDataTypeDescription description;private final String hashKey = "wordCount";public WordCountStoreMapper() {description = new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH, hashKey);}@Overridepublic RedisDataTypeDescription getDataTypeDescription() {return description;}@Overridepublic String getKeyFromTuple(ITuple tuple) {return tuple.getStringByField("word");}@Overridepublic String getValueFromTuple(ITuple tuple) {return tuple.getStringByField("count");}
}
2.7 WordCountToRedisApp
/*** 进行词频统计 并将统计结果存储到 Redis 中*/
public class WordCountToRedisApp {private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";private static final String SPLIT_BOLT = "splitBolt";private static final String COUNT_BOLT = "countBolt";private static final String STORE_BOLT = "storeBolt";//在实际开发中这些参数可以将通过外部传入 使得程序更加灵活private static final String REDIS_HOST = "192.168.200.226";private static final int REDIS_PORT = 6379;public static void main(String[] args) {TopologyBuilder builder = new TopologyBuilder();builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout());// splitbuilder.setBolt(SPLIT_BOLT, new SplitBolt()).shuffleGrouping(DATA_SOURCE_SPOUT);// countbuilder.setBolt(COUNT_BOLT, new CountBolt()).shuffleGrouping(SPLIT_BOLT);// save to redisJedisPoolConfig poolConfig = new JedisPoolConfig.Builder().setHost(REDIS_HOST).setPort(REDIS_PORT).build();RedisStoreMapper storeMapper = new WordCountStoreMapper();RedisStoreBolt storeBolt = new RedisStoreBolt(poolConfig, storeMapper);builder.setBolt(STORE_BOLT, storeBolt).shuffleGrouping(COUNT_BOLT);// 如果外部传参 cluster 则代表线上环境启动否则代表本地启动if (args.length > 0 && args[0].equals("cluster")) {try {StormSubmitter.submitTopology("ClusterWordCountToRedisApp", new Config(), builder.createTopology());} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {e.printStackTrace();}} else {LocalCluster cluster = new LocalCluster();cluster.submitTopology("LocalWordCountToRedisApp",new Config(), builder.createTopology());}}
}
2.8 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true
启动后,查看 Redis 中的数据:

三、storm-redis 实现原理
3.1 AbstractRedisBolt
RedisLookupBolt、RedisStoreBolt、RedisFilterBolt 均继承自 AbstractRedisBolt 抽象类,和我们自定义实现 Bolt 一样,AbstractRedisBolt 间接继承自 BaseRichBolt。

AbstractRedisBolt 中比较重要的是 prepare 方法,在该方法中通过外部传入的 jedis 连接池配置 ( jedisPoolConfig/jedisClusterConfig) 创建用于管理 Jedis 实例的容器 JedisCommandsInstanceContainer。
public abstract class AbstractRedisBolt extends BaseTickTupleAwareRichBolt {protected OutputCollector collector;private transient JedisCommandsInstanceContainer container;private JedisPoolConfig jedisPoolConfig;private JedisClusterConfig jedisClusterConfig;......@Overridepublic void prepare(Map map, TopologyContext topologyContext, OutputCollector collector) {// FIXME: stores map (stormConf), topologyContext and expose these to derived classesthis.collector = collector;if (jedisPoolConfig != null) {this.container = JedisCommandsContainerBuilder.build(jedisPoolConfig);} else if (jedisClusterConfig != null) {this.container = JedisCommandsContainerBuilder.build(jedisClusterConfig);} else {throw new IllegalArgumentException("Jedis configuration not found");}}.......
}
JedisCommandsInstanceContainer 的 build() 方法如下,实际上就是创建 JedisPool 或 JedisCluster 并传入容器中。
public static JedisCommandsInstanceContainer build(JedisPoolConfig config) {JedisPool jedisPool = new JedisPool(DEFAULT_POOL_CONFIG, config.getHost(), config.getPort(), config.getTimeout(), config.getPassword(), config.getDatabase());return new JedisContainer(jedisPool);}public static JedisCommandsInstanceContainer build(JedisClusterConfig config) {JedisCluster jedisCluster = new JedisCluster(config.getNodes(), config.getTimeout(), config.getTimeout(), config.getMaxRedirections(), config.getPassword(), DEFAULT_POOL_CONFIG);return new JedisClusterContainer(jedisCluster);}
3.2 RedisStoreBolt和RedisLookupBolt
RedisStoreBolt 中比较重要的是 process 方法,该方法主要从 storeMapper 中获取传入 key/value 的值,并按照其存储类型 dataType 调用 jedisCommand 的对应方法进行存储。
RedisLookupBolt 的实现基本类似,从 lookupMapper 中获取传入的 key 值,并进行查询操作。
public class RedisStoreBolt extends AbstractRedisBolt {private final RedisStoreMapper storeMapper;private final RedisDataTypeDescription.RedisDataType dataType;private final String additionalKey;public RedisStoreBolt(JedisPoolConfig config, RedisStoreMapper storeMapper) {super(config);this.storeMapper = storeMapper;RedisDataTypeDescription dataTypeDescription = storeMapper.getDataTypeDescription();this.dataType = dataTypeDescription.getDataType();this.additionalKey = dataTypeDescription.getAdditionalKey();}public RedisStoreBolt(JedisClusterConfig config, RedisStoreMapper storeMapper) {super(config);this.storeMapper = storeMapper;RedisDataTypeDescription dataTypeDescription = storeMapper.getDataTypeDescription();this.dataType = dataTypeDescription.getDataType();this.additionalKey = dataTypeDescription.getAdditionalKey();}@Overridepublic void process(Tuple input) {String key = storeMapper.getKeyFromTuple(input);String value = storeMapper.getValueFromTuple(input);JedisCommands jedisCommand = null;try {jedisCommand = getInstance();switch (dataType) {case STRING:jedisCommand.set(key, value);break;case LIST:jedisCommand.rpush(key, value);break;case HASH:jedisCommand.hset(additionalKey, key, value);break;case SET:jedisCommand.sadd(key, value);break;case SORTED_SET:jedisCommand.zadd(additionalKey, Double.valueOf(value), key);break;case HYPER_LOG_LOG:jedisCommand.pfadd(key, value);break;case GEO:String[] array = value.split(":");if (array.length != 2) {throw new IllegalArgumentException("value structure should be longitude:latitude");}double longitude = Double.valueOf(array[0]);double latitude = Double.valueOf(array[1]);jedisCommand.geoadd(additionalKey, longitude, latitude, key);break;default:throw new IllegalArgumentException("Cannot process such data type: " + dataType);}collector.ack(input);} catch (Exception e) {this.collector.reportError(e);this.collector.fail(input);} finally {returnInstance(jedisCommand);}}.........
}3.3 JedisCommands
JedisCommands 接口中定义了所有的 Redis 客户端命令,它有以下三个实现类,分别是 Jedis、JedisCluster、ShardedJedis。Strom 中主要使用前两种实现类,具体调用哪一个实现类来执行命令,由传入的是 jedisPoolConfig 还是 jedisClusterConfig 来决定。

3.4 RedisMapper 和 TupleMapper
RedisMapper 和 TupleMapper 定义了 tuple 和 Redis 中的数据如何进行映射转换。

1. TupleMapper
TupleMapper 主要定义了两个方法:
-
getKeyFromTuple(ITuple tuple): 从 tuple 中获取那个字段作为 Key;
-
getValueFromTuple(ITuple tuple):从 tuple 中获取那个字段作为 Value;
2. RedisMapper
定义了获取数据类型的方法 getDataTypeDescription(),RedisDataTypeDescription 中 RedisDataType 枚举类定义了所有可用的 Redis 数据类型:
public class RedisDataTypeDescription implements Serializable { public enum RedisDataType { STRING, HASH, LIST, SET, SORTED_SET, HYPER_LOG_LOG, GEO }......}
3. RedisStoreMapper
RedisStoreMapper 继承 TupleMapper 和 RedisMapper 接口,用于数据存储时,没有定义额外方法。
4. RedisLookupMapper
RedisLookupMapper 继承 TupleMapper 和 RedisMapper 接口:
- 定义了 declareOutputFields 方法,声明输出的字段。
- 定义了 toTuple 方法,将查询结果组装为 Storm 的 Values 的集合,并用于发送。
下面的例子表示从输入 Tuple 的获取 word 字段作为 key,使用 RedisLookupBolt 进行查询后,将 key 和查询结果 value 组装为 values 并发送到下一个处理单元。
class WordCountRedisLookupMapper implements RedisLookupMapper {private RedisDataTypeDescription description;private final String hashKey = "wordCount";public WordCountRedisLookupMapper() {description = new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH, hashKey);}@Overridepublic List<Values> toTuple(ITuple input, Object value) {String member = getKeyFromTuple(input);List<Values> values = Lists.newArrayList();values.add(new Values(member, value));return values;}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("wordName", "count"));}@Overridepublic RedisDataTypeDescription getDataTypeDescription() {return description;}@Overridepublic String getKeyFromTuple(ITuple tuple) {return tuple.getStringByField("word");}@Overridepublic String getValueFromTuple(ITuple tuple) {return null;}
}
5. RedisFilterMapper
RedisFilterMapper 继承 TupleMapper 和 RedisMapper 接口,用于查询数据时,定义了 declareOutputFields 方法,声明输出的字段。如下面的实现:
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("wordName", "count"));
}四、自定义RedisBolt实现词频统计
4.1 实现原理
自定义 RedisBolt:主要利用 Redis 中哈希结构的 hincrby key field 命令进行词频统计。在 Redis 中 hincrby 的执行效果如下。hincrby 可以将字段按照指定的值进行递增,如果该字段不存在的话,还会新建该字段,并赋值为 0。通过这个命令可以非常轻松的实现词频统计功能。
redis> HSET myhash field 5
(integer) 1
redis> HINCRBY myhash field 1
(integer) 6
redis> HINCRBY myhash field -1
(integer) 5
redis> HINCRBY myhash field -10
(integer) -5
redis>
4.2 项目结构

4.3 自定义RedisBolt的代码实现
/*** 自定义 RedisBolt 利用 Redis 的哈希数据结构的 hincrby key field 命令进行词频统计*/
public class RedisCountStoreBolt extends AbstractRedisBolt {private final RedisStoreMapper storeMapper;private final RedisDataTypeDescription.RedisDataType dataType;private final String additionalKey;public RedisCountStoreBolt(JedisPoolConfig config, RedisStoreMapper storeMapper) {super(config);this.storeMapper = storeMapper;RedisDataTypeDescription dataTypeDescription = storeMapper.getDataTypeDescription();this.dataType = dataTypeDescription.getDataType();this.additionalKey = dataTypeDescription.getAdditionalKey();}@Overrideprotected void process(Tuple tuple) {String key = storeMapper.getKeyFromTuple(tuple);String value = storeMapper.getValueFromTuple(tuple);JedisCommands jedisCommand = null;try {jedisCommand = getInstance();if (dataType == RedisDataTypeDescription.RedisDataType.HASH) {jedisCommand.hincrBy(additionalKey, key, Long.valueOf(value));} else {throw new IllegalArgumentException("Cannot process such data type for Count: " + dataType);}collector.ack(tuple);} catch (Exception e) {this.collector.reportError(e);this.collector.fail(tuple);} finally {returnInstance(jedisCommand);}}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {}
}
4.4 CustomRedisCountApp
/*** 利用自定义的 RedisBolt 实现词频统计*/
public class CustomRedisCountApp {private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";private static final String SPLIT_BOLT = "splitBolt";private static final String STORE_BOLT = "storeBolt";private static final String REDIS_HOST = "192.168.200.226";private static final int REDIS_PORT = 6379;public static void main(String[] args) {TopologyBuilder builder = new TopologyBuilder();builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout());// splitbuilder.setBolt(SPLIT_BOLT, new SplitBolt()).shuffleGrouping(DATA_SOURCE_SPOUT);// save to redis and countJedisPoolConfig poolConfig = new JedisPoolConfig.Builder().setHost(REDIS_HOST).setPort(REDIS_PORT).build();RedisStoreMapper storeMapper = new WordCountStoreMapper();RedisCountStoreBolt countStoreBolt = new RedisCountStoreBolt(poolConfig, storeMapper);builder.setBolt(STORE_BOLT, countStoreBolt).shuffleGrouping(SPLIT_BOLT);// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动if (args.length > 0 && args[0].equals("cluster")) {try {StormSubmitter.submitTopology("ClusterCustomRedisCountApp", new Config(), builder.createTopology());} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {e.printStackTrace();}} else {LocalCluster cluster = new LocalCluster();cluster.submitTopology("LocalCustomRedisCountApp",new Config(), builder.createTopology());}}
}
参考资料
- Storm Redis Integration
相关文章:
【Storm】【六】Storm 集成 Redis 详解
Storm 集成 Redis 详解 一、简介二、集成案例三、storm-redis 实现原理四、自定义RedisBolt实现词频统计一、简介 Storm-Redis 提供了 Storm 与 Redis 的集成支持,你只需要引入对应的依赖即可使用: <dependency><groupId>org.apache.storm…...

算法代码题——模板
文章目录1. 双指针: 只有一个输入, 从两端开始遍历2. 双指针: 有两个输入, 两个都需要遍历完3. 滑动窗口4. 构建前缀和5. 高效的字符串构建6. 链表: 快慢指针7. 反转链表8. 找到符合确切条件的子数组数9. 单调递增栈10. 二叉树: DFS (递归)]11. 二叉树: DFS (迭代)12. 二叉树: …...
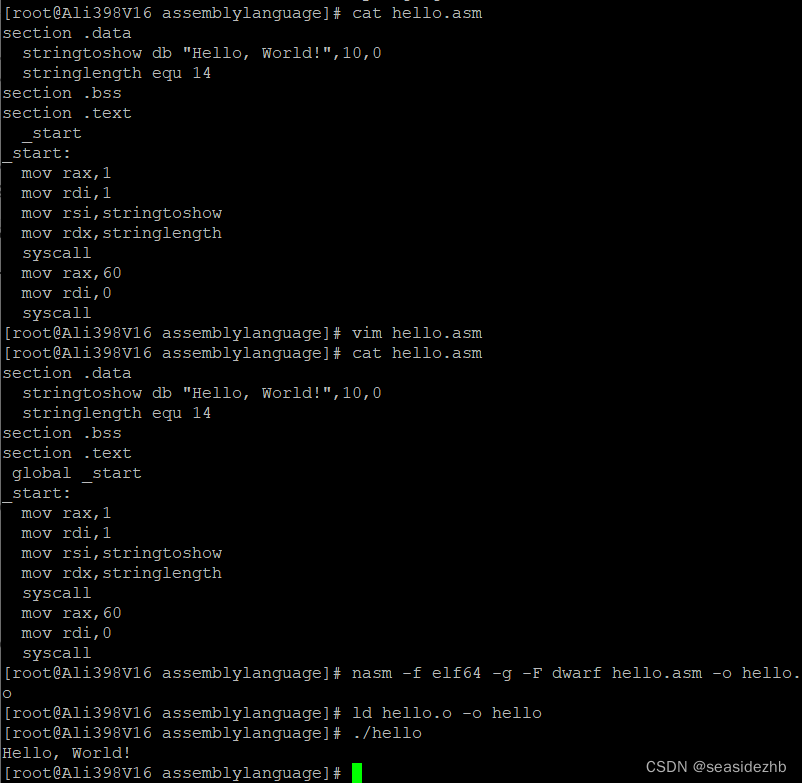
CentOS 7.9汇编语言版Hello World
先下载、编译nasm汇编器。NASM汇编器官网如下图所示: 可以点图中的List进入历史版本下载网址: 我这里下载的是nasm-2.15.05.tar.bz2 在CentOS 7中,使用 wget http://www.nasm.us/pub/nasm/releasebuilds/2.15.05/nasm-2.15.05.tar.bz2下载…...

CoreData数据库探索
CoreData是什么 Core Data 是苹果公司提供的一个对象-关系映射框架(Object-Relational Mapping,ORM),用于管理应用程序的数据模型。Core Data 提供了一个抽象层,使开发人员能够使用面向对象的方式访问和操作数据&…...
FreeRTOS入门
目录 一、简介 二、堆的概念 三、栈的概念 四、从官方源码中精简出第一个FreeRTOS程序 五、修改官方源码增加串口打印 一、简介 FreeRTOS是一个迷你的实时操作系统内核。作为一个轻量级的操作系统,功能包括:任务管理、时间管理、信号量、消息队列、…...
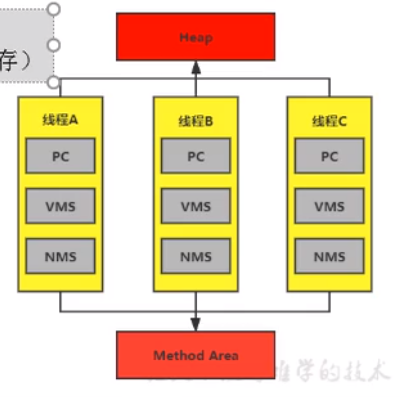
JVM运行时数据区划分
Java内存空间 内存是非常重要的系统资源,是硬盘和cpu的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了JAVA在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。不同的jvm对于内存的划分方式和管理机…...
重装系统一半电脑蓝屏如何解决
小编相信大家在使用电脑或者给电脑重装系统的时候都遇到过电脑蓝屏等等故障问题。最近有用户就遇到了这样一个问题,问小编重装系统一半电脑蓝屏怎么办,那么今天小编就告诉大家重装系统一半电脑蓝屏的解决方法。 工具/原料: 系统版本&#x…...
SpringBoot(tedu)——day01——环境搭建
SpringBoot(tedu)——day01——环境搭建 目录SpringBoot(tedu)——day01——环境搭建零、今日目标一、IDEA2021项目环境搭建1.1 通过 ctrl鼠标滚轮 实现字体大小缩放1.2 自动提示设置 去除大小写匹配1.3 设置参数方法自动提示1.4 设定字符集 要求都使用UTF-8编码1.5 设置自动编…...

springboot整合redis
1.redis的数据类型,一共有5种.后面结合Jedis和redistemplate,以及单元测试junit一起验证 1)字符串 2)hash 3)列表 4)set(无序集合) 5)zset(有序集合) 2.Jedis的使用 a)引入依赖 <!--加入springboot的starter的起步依赖--><dependency><groupId>…...
【Java】Spring Boot下的MVC
文章目录Spring MVC程序开发1. 什么是Spring MVC?1.1 MVC定义1.2 MVC 和 Spring MVC 的关系2. 为什么学习Spring MVC?3. 怎么学习Spring MVC?3.1 Spring MVC的创建和连接3.1.1 创建Spring MVC项目3.1.2 RequestMapping 注解介绍3.1.3 Request…...
【项目精选】 塞北村镇旅游网站设计(视频+论文+源码)
点击下载源码 摘要 城市旅游产业的日新月异影响着村镇旅游产业的发展变化。网络、电子科技的迅猛前进同样牵动着旅游产业的快速成长。随着人们消费理念的不断发展变化,越来越多的人开始注意精神文明的追求,而不仅仅只是在意物质消费的提高。塞北村镇旅游…...

十、Spring IoC注解式开发
1 声明Bean的注解 负责声明Bean的注解,常见的包括四个: ComponentControllerServiceRepository Controller、Service、Repository这三个注解都是Component注解的别名。 也就是说:这四个注解的功能都一样。用哪个都可以。 只是为了增强程序…...
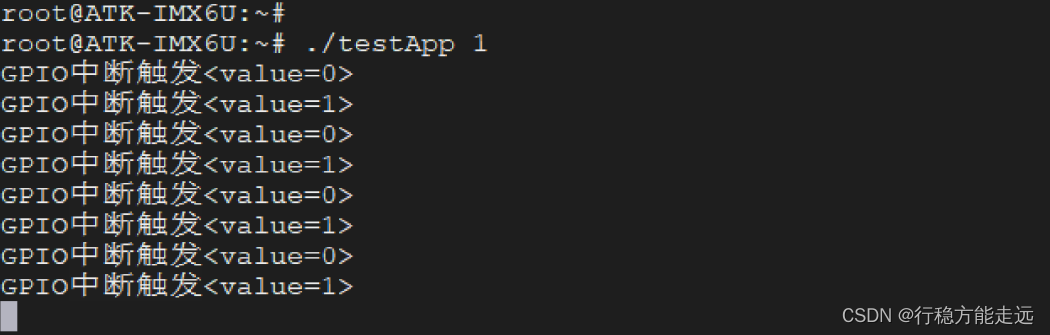
Linux系统GPIO应用编程
目录应用层如何操控GPIOGPIO 应用编程之输出GPIO 应用编程之输入GPIO 应用编程之中断在开发板上测试GPIO 输出测试GPIO 输入测试GPIO 中断测试本章介绍应用层如何控制GPIO,譬如控制GPIO 输出高电平、或输出低电平。应用层如何操控GPIO 与LED 设备一样,G…...
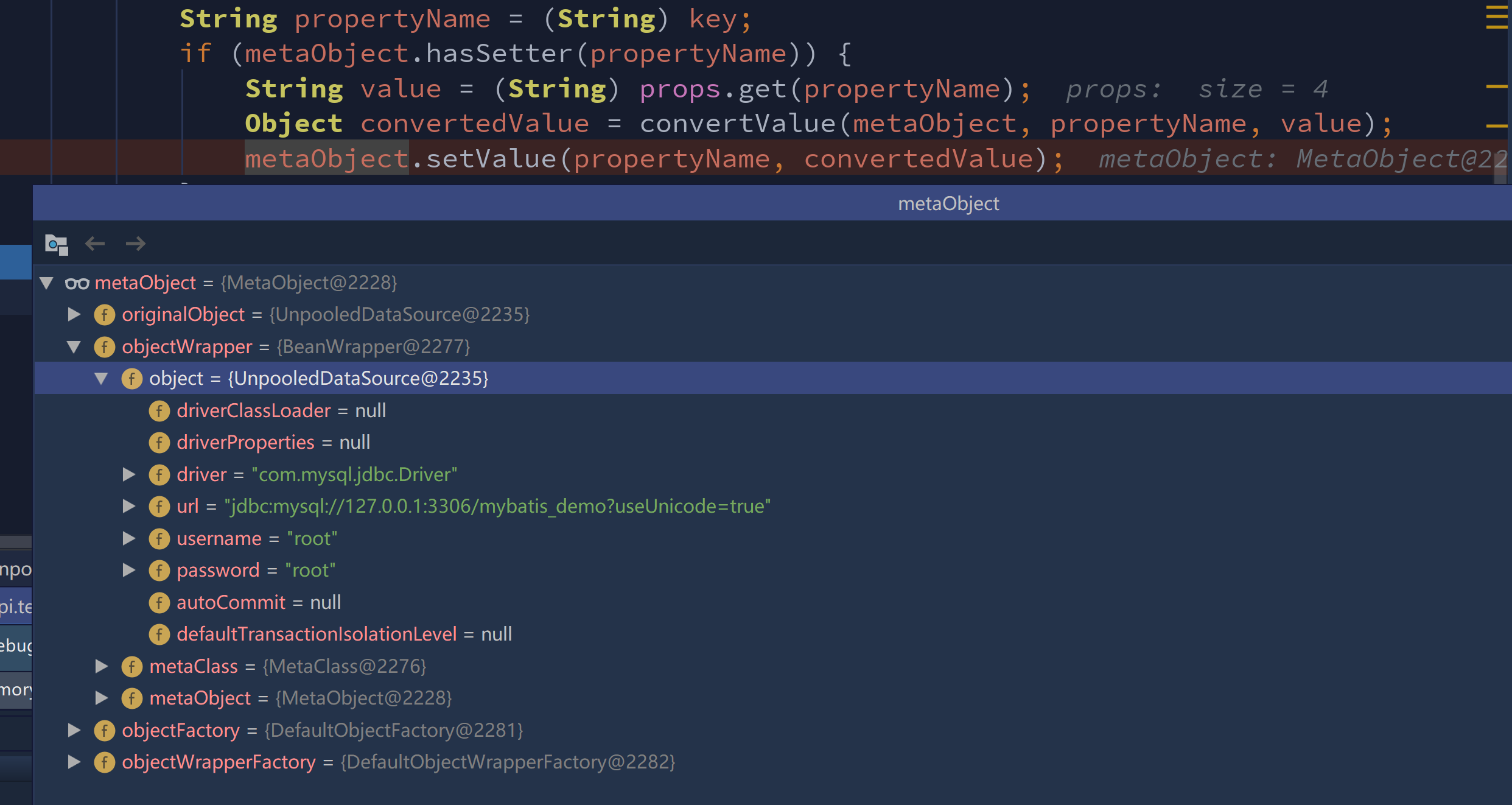
手敲Mybatis-反射工具天花板
历时漫长的岁月,终于鼓起勇气继续研究Mybatis的反射工具类们,简直就是把反射玩出花,但是理解起来还是很有难度的,涉及的内容代码也颇多,所以花费时间也比较浩大,不过当了解套路每个类的功能也好,…...
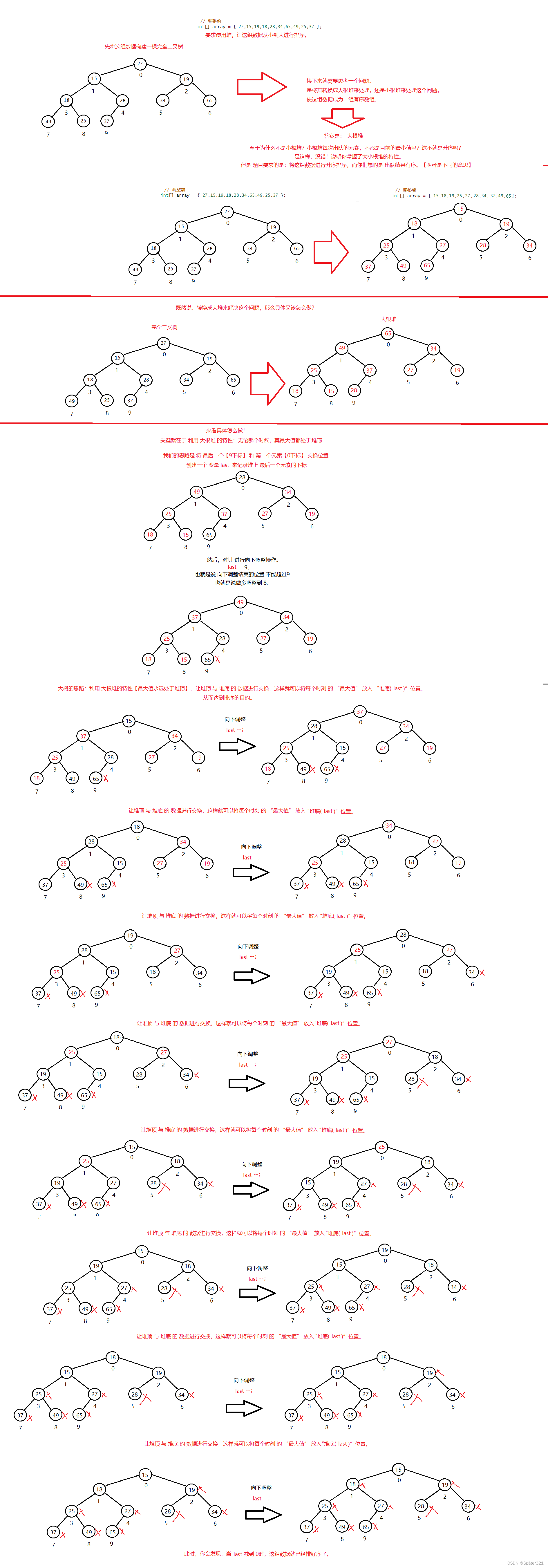
Java -数据结构,【优先级队列 / 堆】
一、二叉树的顺序存储 在前面我们已经讲了二叉树的链式存储,就是一棵树的左孩子和右孩子 而现在讲的是:顺序存储一棵二叉树。 1.1、存储方式 使用数组保存二叉树结构,方式即将二叉树用层序遍历方式放入数组中。 一般只适合表示完全二叉树&a…...

Python+Qt指纹录入识别考勤系统
PythonQt指纹录入识别考勤系统如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<PythonQt指纹录入识别考勤系统>>编写代码,代码整洁,规则,易读。 学…...
K_A14_004 基于STM32等单片机驱动旋转角度传感器模块 串口与OLED0.96双显示
K_A14_004 基于STM32等单片机驱动旋转角度传感器模块 串口与OLED0.96双显示一、资源说明二、基本参数参数引脚说明三、驱动说明IIC地址/采集通道选择/时序对应程序:四、部分代码说明1、接线引脚定义1.1、STC89C52RC旋转角度传感器模块1.2、STM32F103C8T6旋转角度传感器模块五、…...

2023年全国最新机动车签字授权人精选真题及答案12
百分百题库提供机动车签字授权人考试试题、机动车签字授权人考试预测题、机动车签字授权人考试真题、机动车签字授权人证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.注册登记前所有机动车都应进行安全技术检验。 答案…...
Linux小黑板(10):信号
我们写在linux系统环境下写一个程序,唔,"它的功能是每隔1s向屏幕打印hello world。"这时,我们在键盘上按出"Ctrl C"后,进程会发生什么??我们清晰地看到,进程已经在我们按出"Ctrl…...
GO 语言基础语法一 (快速入门 Go 语言)
Go语言基础语法一. golang 标识符,关键字,命名规则二. golang 变量三. golang 常量四. golang 数据类型五. golang 布尔类型六. golang 数字类型七. golang 字符串1. go语言字符串字面量2. go语言字符串连接(1). 使用加号(2). 使用 fmt.Sprintf() 函数(3…...

复古计算机复兴:OpenClaw+Qwen3-14B驱动命令行工作流
复古计算机复兴:OpenClawQwen3-14B驱动命令行工作流 1. 当AI遇见Unix哲学 我的书桌上至今保留着一台1984年的IBM PC/AT,那厚重的机械键盘和闪烁的绿色光标总能唤起某种仪式感。最近在调试OpenClaw对接Qwen3-14B时,突然意识到:我…...

龙虾白嫖指南,请查收~
故障表现 发现请求集群 demo 入口时卡住,并且对应 Pod 没有新的日志输出 rootce-demo-1:~# kubectl get pods -n deepflow-otel-spring-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NO…...

PCIe AVIP架构
验证工程师可以用C语言接口快速实现仿真加速。C实现的仿真文件testbench可以直接访问AVIP,与总线功能模块BFM交换数据。PCIe AVIP的C接口就是一组C类;C程序或工具可以调用这些类的方法。C类可以实现如下功能:与BFM建立通信;向BFM发…...

五层电梯MCGS7.7嵌入版与三菱PLC的联动编程实践
5五层电梯MCGS7.7嵌入版和三菱PLC联机程序调试电梯控制程序最头疼的莫过于通讯不稳定。上个月刚搞完一个五层电梯项目,MCGS7.7触摸屏和三菱FX3U的联机调试过程简直像坐过山车——楼层显示乱跳、按钮状态丢失这些幺蛾子接踵而来。今天咱就唠唠这个项目的实战经验。硬…...

Serverless测试噩梦:冷启动延迟搞垮电商大促
一场被“隐形杀手”击溃的战役凌晨两点,某头部电商平台的“双十一”大促作战指挥中心。流量曲线在预热阶段平稳爬升,技术团队信心满满——所有核心交易链路都已迁移至先进的Serverless架构,理论上具备无限弹性。然而,零点的钟声敲…...

GLM-4.1V-9B-Base多场景:教育题图解析、法律文书图示理解、科研图表解读
GLM-4.1V-9B-Base多场景应用:教育题图解析、法律文书图示理解、科研图表解读 1. 认识GLM-4.1V-9B-Base视觉理解模型 GLM-4.1V-9B-Base是智谱开源的一款强大的视觉多模态理解模型,专门设计用于处理图像内容识别和理解任务。与传统的纯文本模型不同&…...
Word2Vec扩充+TF-IDF)
上市公司数字化转型指数(2007-2024)Word2Vec扩充+TF-IDF
上市公司数字化转型指数(2007-2024)Word2Vec扩充TF-IDF数据名称:A股上市公司数字化转型指数 时间跨度:2007年-2024年 数据格式:Excel表格(dta可直接导入) 包含指标:股票代码、年份、…...

避坑指南:WFDB读取ECG数据时,.hea文件真的‘几乎没用’吗?
避坑指南:WFDB读取ECG数据时,.hea文件真的‘几乎没用’吗? 在生物信号处理领域,WFDB(Waveform Database)格式是存储心电图(ECG)数据的黄金标准。许多开发者习惯性地认为.hea头文件只…...

轻量级加密新选择:tiny-AES-c深度解析
轻量级加密新选择:tiny-AES-c深度解析 【免费下载链接】tiny-AES-c Small portable AES128/192/256 in C 项目地址: https://gitcode.com/gh_mirrors/ti/tiny-AES-c 在嵌入式系统与物联网设备等资源受限环境中,数据安全面临着独特挑战。轻量级AES…...

《YOLO11魔术师专栏》专栏介绍 专栏目录
《YOLO11魔术师专栏》将从以下各个方向进行创新(更新日期25.07.23): 【原创自研模块】【多组合点优化】【注意力机制】 【主干篇】【neck优化】【卷积魔改】 【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】 【小目标…...