6 时间序列(不同位置的装置如何建模): GRU+Embedding
很多算法比赛经常会遇到不同的物体产生同含义的时间序列信息,比如不同位置的时间序列信息,风力发电、充电桩用电。经常会遇到该如此场景,对所有数据做统一处理喂给模型,模型很难学到区分信息,因此设计如果对不同位置的装置做嵌入操作,这也是本文书写的主要目的之一,如果对不同位置装置的时序数据做模型呢?
RGU: 循环神经网络模块,经常用于处理时序数据。
Embedding : 是 PyTorch 中的一个类,用于将离散的整数序列映射为连续的向量表示。
使用下面比赛的数据作为一个处理的DEMO:
2023中国华录杯数据湖算法大赛

import package
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
#import tushare as ts
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from tqdm import tqdm
from torch.utils.data import Dataset, DataLoaderfrom sklearn.preprocessing import LabelEncoderimport matplotlib.pyplot as plt
import tqdm
import sys
import os
import gc
import argparse
import warningswarnings.filterwarnings('ignore')
load data
class Config():#data_path = '../data/data1/train/power.csv'timestep = 14 # 时间步长,就是利用多少时间窗口batch_size = 32 # 批次大小feature_size = 1 # 每个步长对应的特征数量,这里只使用1维,每天的风速hidden_size = 56 # 隐层大小output_size = 1 # 由于是单输出任务,最终输出层大小为1,预测未来1天风速num_layers = 1 # lstm的层数epochs = 10 # 迭代轮数best_loss = 0 # 记录损失learning_rate = 0.00003 # 学习率model_name = 'lstm' # 模型名称save_path = './{}.pth'.format(model_name) # 最优模型保存路径
config = Config()train_df = pd.read_csv('../初赛数据/phase1_train.csv')
test_df = pd.read_csv('../初赛数据/phase1_test.csv')labelEncoder = LabelEncoder()
train_df['line_label'] = labelEncoder.fit_transform(train_df['line'])
#labelEncoder.transform(test_df['line'])train_df = train_df.sort_values(["line",'date']).reset_index(drop=True)train_df.line.unique()
array(['L01', 'L02', 'L03', 'L04', 'L05', 'L06', 'L08', 'L09', 'L10'],dtype=object)
使用前面14天预测未来第七天:
1,2,3,4,5,6,7,8,9,10,11,12,13,14 -》14+7
【1,2,3,4,5,6,7,8,9,10,11,12,13,14】+1 -》 14+7+1
。。。。。
#train_df.head()
his_pow_feats = []
for i in range(config.timestep):train_df[f'shift_{7+i}'] = train_df.groupby("line_label")['passenger_flow'].shift(7+i)his_pow_feats.append(f'shift_{7+i}')
train_df_drop_na = train_df[train_df[his_pow_feats].isna().sum(axis=1)==0]class MyDataSet(Dataset):def __init__(self,train_df_drop_na,his_pow_feats):"""train_df_drop_na"""self.train_df = train_df_drop_na.reset_index(drop=True)def __len__(self):return len(self.train_df)def __getitem__(self,item):label = self.train_df.loc[item,'passenger_flow']id_encoder = self.train_df.loc[item,'line_label']his_feats_list = self.train_df.loc[item,his_pow_feats].values.tolist()return {"input_ids":torch.tensor(id_encoder,dtype=torch.long),"his_feats":torch.as_tensor(his_feats_list ,dtype=torch.float32).unsqueeze(-1),"labels":torch.tensor(label,dtype=torch.float32)}RANDOM_SEED = 1023
df_train, df_test = train_test_split(train_df_drop_na, test_size=0.2, random_state=RANDOM_SEED)
df_val, df_test = train_test_split(df_test, test_size=0.5, random_state=RANDOM_SEED)
df_train.shape, df_val.shape, df_test.shapedef create_data_loader(train_df_drop_na,his_pow_feats,batch_size=32):ds = MyDataSet(train_df_drop_na,his_pow_feats)return DataLoader(ds,batch_size=batch_size)
BATCH_SIZE = 32
train_data_loader = create_data_loader(df_train,his_pow_feats=his_pow_feats,batch_size=BATCH_SIZE)
val_data_loader = create_data_loader(df_val, his_pow_feats=his_pow_feats,batch_size=BATCH_SIZE)
test_data_loader = create_data_loader(df_test,his_pow_feats=his_pow_feats,batch_size=BATCH_SIZE)#train_df[cols]
# 7.定义LSTM网络
class GRUModel(nn.Module):def __init__(self, feature_size, hidden_size, num_layers, output_size):super(GRUModel, self).__init__()self.hidden_size = hidden_size # 隐层大小self.num_layers = num_layers # lstm层数# feature_size为特征维度,就是每个时间点对应的特征数量,这里为1self.gru = nn.GRU(feature_size, hidden_size, num_layers, batch_first=True,bidirectional=True)self.layer_norm = nn.LayerNorm(hidden_size*2)self.fc = nn.Linear(hidden_size*2+2, output_size)self.embedding = nn.Embedding(9, 2)def forward(self, x,id_label, hidden=None):#print(x.shape)batch_size = x.shape[0] # 获取批次大小 batch, time_stamp , feat_size# 初始化隐层状态h_0 = x.data.new(2*self.num_layers, batch_size, self.hidden_size).fill_(0).float()if hidden is not None:h_0 = hidden#print(h_0.size)# GRU 运算output, hidden = self.gru(x,h_0)output = self.layer_norm(output)last_output = output[:, -1, :]#print('output',last_output.shape)embed = self.embedding(id_label)#print("embed",embed.shape)#print('output',output.shape)concatenated = torch.cat((embed, last_output), dim=1)#print(concatenated.shape)# 全连接层output = self.fc(concatenated) # 形状为batch_size * timestep, 1#print(output.shape)# 我们只需要返回最后一个时间片的数据即可return output
model = GRUModel(config.feature_size, config.hidden_size, config.num_layers, config.output_size) # 定义LSTM网络loss_function = nn.L1Loss() # 定义损失函数
# class MAPELoss(nn.Module):
# def __init__(self):
# super(MAPELoss, self).__init__()# def forward(self, y_pred, y_true):
# epsilon = 1e-8 # 用于避免除以零的小常数
# absolute_error = torch.abs(y_true - y_pred)
# relative_error = absolute_error / (torch.abs(y_true) + epsilon)
# mape = torch.mean(relative_error) * 100
# return mape
# loss_function = MAPELoss() # 定义损失函数optimizer = torch.optim.AdamW(model.parameters(), lr=0.01) # 定义优化器
from tqdm import tqdm# 8.模型训练
for epoch in range(500):model.train()running_loss = 0train_bar = tqdm(train_data_loader) # 形成进度条for data in train_bar:x_train, y_train = data['his_feats'], data['labels'] # 解包迭代器中的X和Yoptimizer.zero_grad()y_train_pred = model(x_train,data['input_ids'])loss = loss_function(y_train_pred, y_train.reshape(-1, 1))loss.backward()optimizer.step()running_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,config.epochs,loss)# 模型验证model.eval()test_loss = 0with torch.no_grad():test_bar = tqdm(val_data_loader)for data in test_bar:x_test, y_test = data['his_feats'], data['labels']y_test_pred = model(x_test, data['input_ids'])test_loss = loss_function(y_test_pred, y_test.reshape(-1, 1))if test_loss < config.best_loss:config.best_loss = test_losstorch.save(model.state_dict(), save_path)print('Finished Training')相关文章:
6 时间序列(不同位置的装置如何建模): GRU+Embedding
很多算法比赛经常会遇到不同的物体产生同含义的时间序列信息,比如不同位置的时间序列信息,风力发电、充电桩用电。经常会遇到该如此场景,对所有数据做统一处理喂给模型,模型很难学到区分信息,因此设计如果对不同位置的…...

Git 基本概念
Git是一种版本控制系统,用于跟踪文件的更改并协同开发代码。它具有以下基本概念和使用方式: 仓库(Repository):Git将文件存储在仓库中,它是保存项目历史记录和更改的地方。一个项目通常有一个主要的仓库。 …...

android:excludeFromRecents
android:excludeFromRecents 基础从根上影响 TaskexcludeFromRecents 属性可能会影响系统 基础 android:excludeFromRecents是一种在Android应用程序清单文件(AndroidManifest.xml)中使用的属性,用于指定一个Activity是否应该在最近任务列表…...

微信小程序登录获取手机号教程(超详细)
1. 背景介绍: 在我们开发微信小程序时,登录时,需要获取用户手机号作为唯一标识,下面我介绍一下获取手机号的教程。 本篇文章介绍后端获取方法: 前端工作 后端工作 前端 新建Page页面,在xxx.wxml中加入…...

uniapp app更新
uniapp app更新 这个版本要随之增加,不然刚更新时直接用app, 新包增加的那些页面跳转会有问题,不能跳新的页面 //app更新检测 updataApp(){const that this;uni.showLoading({title:加载中...})plus.runtime.getProperty(plus.runtime.appid, functio…...
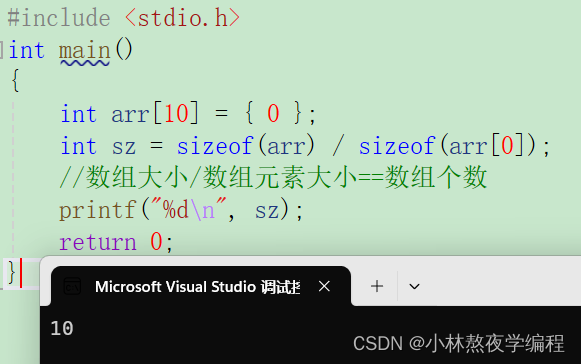
C语言第八弹---一维数组
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 一维数组 1、数组的概念 2、⼀维数组的创建和初始化 2.1、数组创建 2.2、数组的初始化 2.3、数组的类型 3、⼀维数组的使用 3.1、数组下标 3.2、数组元素…...

科普栏目 | 水离子水壁炉是如何打造清新环境,提升居家生活?
现代生活中,人们对于居家环境的品质有着越来越高的要求。水离子水壁炉作为一种创新科技,通过其独特的功能,为居家生活带来了一系列的提升。 1.采用先进的技术,减少了对传统能源的依赖,让我们在提高生活品质的同时&…...

python 进程
1创建一个爬虫程序 import requests urls [https://www.cnblogs.com/#p{page}for page in range(1, 501) ]def craw(url):r requests.get(url)print(url, len(r.text))craw(urls[0])2定义单进程和多进程 import blob_spider import threading import timedef single_thread…...
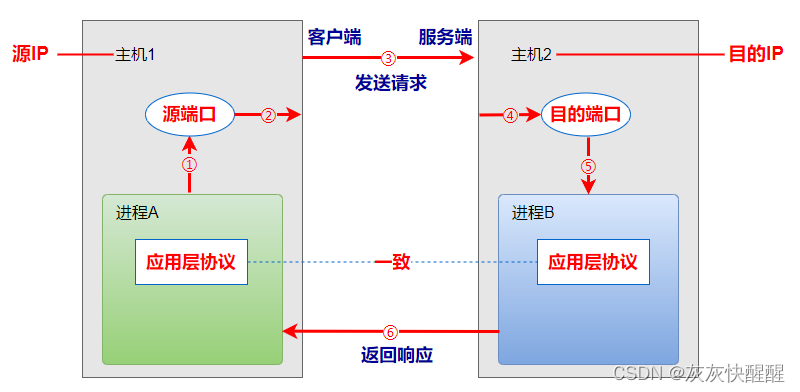
网络编程套接字(1)
网络编程基础 为什么需要网络编程? --丰富的网络资源 用户在浏览器中,打开在线视频网站,如优酷看视频,实质通过网络,获取到网络上的一个视频资源 与本地打开视频文件类似,只是视频文件这个资源的来源是网络. 相比于本地资源来说,网络提供了更为丰富的网络资源: 所谓的网络…...

harmonyOS app 开发环境配置流程
1.安装DevEco Studio,注意nodejs版本,安装过程中有提示,添加hdc到系统环境变量中,用于调用hdc命令 2.开启真机设备的开发人员选项,以及开启5555端口(需要连接usb线) https://developer.harmonyo…...
【嵌入式学习】C++QT-Day2-C++基础
笔记 见我的博客:https://lingjun.life/wiki/EmbeddedNote/19Cpp 作业 自己封装一个矩形类(Rect),拥有私有属性:宽度(width)、高度(height), 定义公有成员函数: 初始化函数:void init(int w, int h) 更改宽度的函数:set_w(int w) 更改高度…...

新手基础易懂的创建javaweb项目的方法(适用于IDEA 2023版)
新手基础易懂的创建javaweb项目的方法 前言我的IDEA版本新建项目步骤1步骤2步骤3步骤4步骤5步骤6<font colorred>特别注意,一定要注意步骤7步骤8 配置Tomcat服务器步骤9步骤10步骤11步骤12步骤13修改前修改后 步骤14 点击修复修改前修改后 试运行 前言 创建ja…...

决策树的基本构建流程
决策树的基本构建流程 决策树的本质是挖掘有效的分类规则,然后以树的形式呈现。 这里有两个重点: 有效的分类规则;树的形式。 有效的分类规则:叶子节点纯度越高越好,就像我们分红豆和黄豆一样,我们当然…...
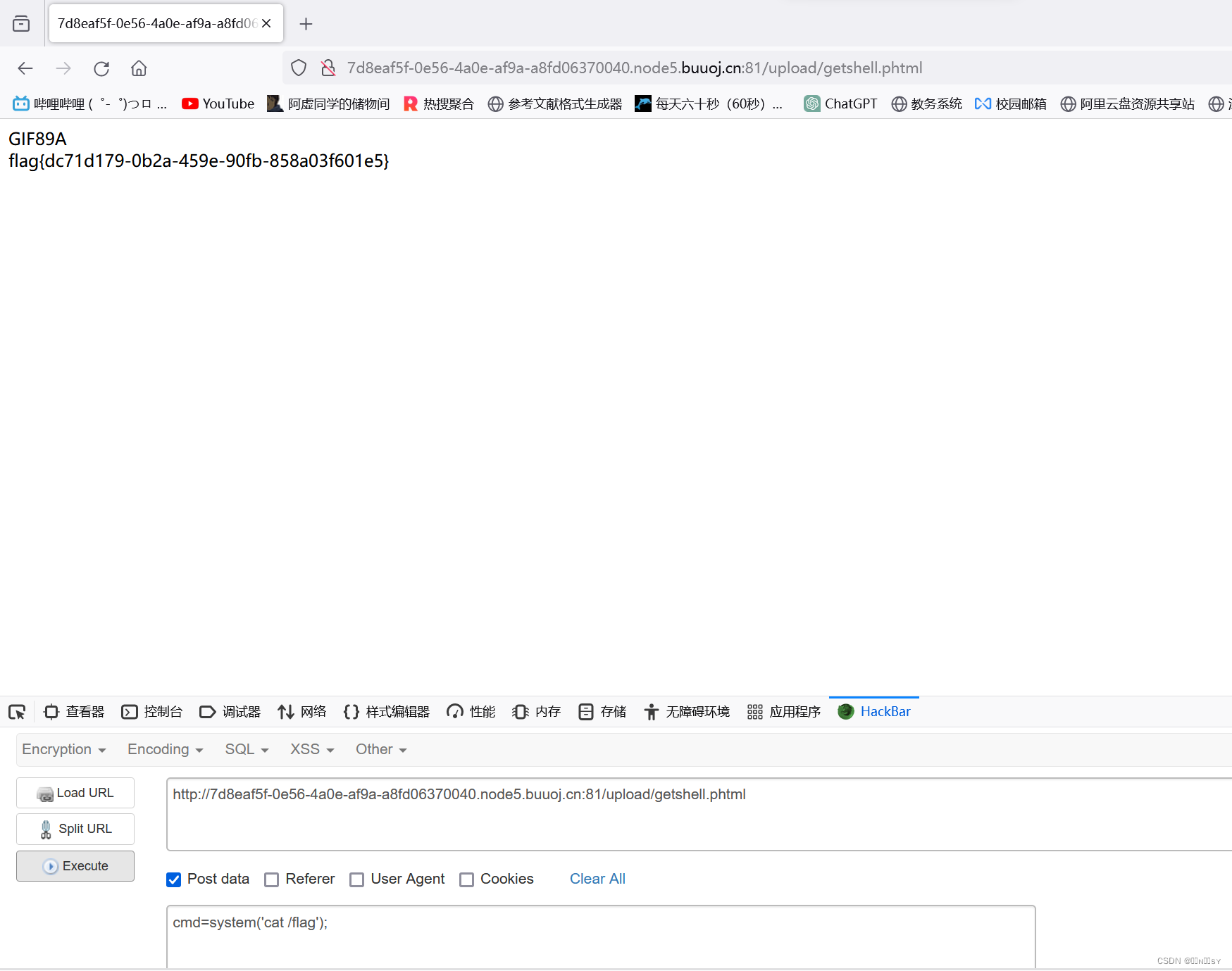
[极客大挑战 2019]Upload1
直接上传php一句话木马,提示要上传image 把文件名改成gif并加上gif文件头后,绕过了对image类型的检测,但是提示文件内含有<?,且bp抓包后改回php也会被检测 那我们考虑使用js执行php代码 <script languagephp>eval($_PO…...

Android 渲染机制
1 Android 渲染流程 一般情况下,一个布局写好以后,使用 Activity#setContentView 调用该布局,这个 View tree 就创建好了。Activity#setContentView 其实是通过 LayoutInflate 来把布局文件转化为 View tree 的(反射)…...

go语言Map与结构体
1. Map map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。 1.1. map定义 Go语言中 map的定义语法如下 map[KeyType]ValueType其中, KeyType:表示键的类型。ValueType:表示键对应的值的类型。map类型的…...

C#,打印漂亮杨辉三角形(帕斯卡三角形)的源代码
杨辉 Blaise Pascal 这是某些程序员看完会哭的代码。 杨辉三角形(Yanghui Triangle),是一种序列数值的三角形几何排列,最早出现于南宋数学家杨辉1261年所著的《详解九章算法》一书。 欧洲学者,最先由帕斯卡&#x…...
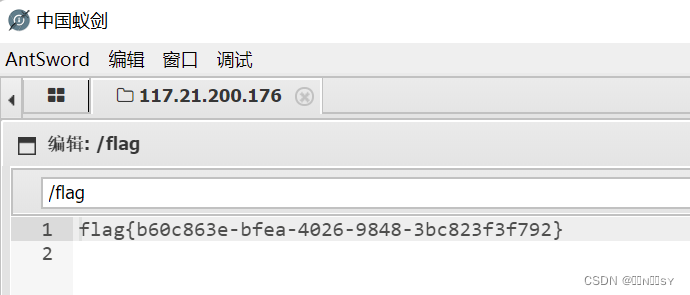
[SUCTF 2019]CheckIn1
黑名单过滤后缀’ph,并且白名单image类型要有对应文件头 对<?过滤,改用GIF89a<script languagephp>eval($_POST[cmd]);</script>,成功把getshell.gif上传上去了 尝试用.htaccess将上传的gif当作php解析,但是失败…...

C语言练习题110例(十)
91.杨辉三角 题目描述: KK知道什么叫杨辉三角之后对杨辉三角产生了浓厚的兴趣,他想知道杨辉三角的前n行,请编程帮他 解答。杨辉三角,本质上是二项式(ab)的n次方展开后各项的系数排成的三角形。其性质包括:每行的端点数为1&…...

前端学习-0125
<h>标签 含义:标题 级别:<h1> - <h6> 快捷键生成 :h$*[0,6] 属性:align"left|center|right" <p>标签 含义: 段落 <br>标签 含义:换行 <hr>标签 含义&…...

PortAudio性能测试与调优:如何实现最低延迟音频处理的完整指南
PortAudio性能测试与调优:如何实现最低延迟音频处理的完整指南 【免费下载链接】portaudio PortAudio is a cross-platform, open-source C language library for real-time audio input and output. 项目地址: https://gitcode.com/gh_mirrors/po/portaudio …...

过零电压比较器基础知识及Multisim电路仿真
目录 2.9 过零电压比较器 2.9.1 过零电压比较器基础知识 1.电路结构与核心定义 2. 工作原理 3. 核心特点与用途 2.9.2 过零电压比较器Multisim电路仿真 2. 仿真逻辑与工作原理 3. 波形解读(右侧瞬态分析结果) 摘要:过零电压比较器是一种阈值电压为0V的单限比较器,利…...

麻省理工博士生弃博投身数字人类研究:10年、100亿美元、5万台H100或可实现
【导语:麻省理工学院博士生Isaak Freeman放弃攻读博士学位,投身数字人类研究。他认为人类若保持碳基形态将在智力竞争中被AI淘汰,而将意识迁移到数字基质上是出路,并给出实现数字人类的粗略计算和路线图。】数字人类:从…...

【人生底稿 23】新疆出差记・上篇:初入边疆,三个半小时的漫长飞行
2024 年的 6 月,刚在赣州、河北、湖南的项目里连轴转完,手里的需求设计还没完全收尾,一通临时电话,打破了我短暂的节奏 —— 任务突然下达:陪客户前往新疆乌鲁木齐的甲方现场。这不是我第一次出差,却是第一…...

FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程
FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程 第一次在ModelSim 10.6d环境下配置FPGA仿真库时,我花了整整三天时间排查各种路径错误和权限问题。直到现在,我还清楚地记得那个深夜——当仿…...

droidrun-agent:基于MCP协议连接AI智能体与安卓设备的自动化桥梁
1. 项目概述:当AI助手需要“动手”时在AI Agent(智能体)领域,我们常常遇到一个瓶颈:模型可以生成完美的计划、写出漂亮的代码,但它如何与真实世界交互,尤其是如何操作一台物理设备?比…...

在新磁盘挂载点/data安装codex
实例是 Oracle Cloud Always Free VM.Standard.E2.1.Micro Linux, /data 目录。 Codex CLI 官方支持用 npm 安装:npm i -g openai/codex,首次运行需要登录 ChatGPT 或配置 API key; 建议:Codex 安装到 /data;bubblewr…...

工作进度管理工具有哪些?8款项目协作平台测评分享
本文将深入对比8款工作任务进度管理软件:Worktile、PingCode、Jira Confluence、Asana、monday.com、ClickUp、Trello、Microsoft Planner / Project。一、工作任务进度管理软件怎么选很多企业刚开始选任务管理软件时,容易只看两个点:能不能…...

冻|结D球 2026
通过网盘分享的文件:冻|结D球 2026 链接: https://pan.baidu.com/s/1-bhxibfD69ahEoufeQFRRQ?pwdhygv 提取码: hygv...

【限时公开】谷歌内部未文档化Gemini JavaScript SDK隐藏能力:流式响应中断控制、上下文压缩率提升63%实测数据
更多请点击: https://intelliparadigm.com 第一章:Gemini JavaScript SDK核心能力概览 Gemini JavaScript SDK 是 Google 官方提供的轻量级客户端库,专为在浏览器和 Node.js 环境中无缝集成 Gemini 模型能力而设计。它抽象了底层 HTTP 请求、…...