大白话解析LevelDB 3: SST Compaction
SST Compaction
文章目录
- SST Compaction
- 什么是`Compact SST`
- 什么时候触发`Compact SST`
- 第一处 读取 Key 的时候
- 第二处 使用迭代器遍历数据库时
- 第三处 写入 Key 时
- 第四处 刚打开数据库时
- 如何进行`Compact SST`
- 计算`Compaction`范围
- 进行`Compaction`
- 创建一个迭代器用于读取`Compaction`范围内的`Key-Value`
- 通过迭代器遍历每个`Key-Value`,丢弃或者写入新的`SST`
LevelDB中有两种Compaction,一种是Compact MemTable,另一种是Compact SST。Compact MemTable是将MemTable落盘为SST文件,Compact SST是将多个SST文件合并为一个SST文件。
本章讲述的是Compact SST的过程。
什么是Compact SST
相比于Compact MemTable,Compact SST复杂的多。首先看一下一次SST Compaction的示意图。
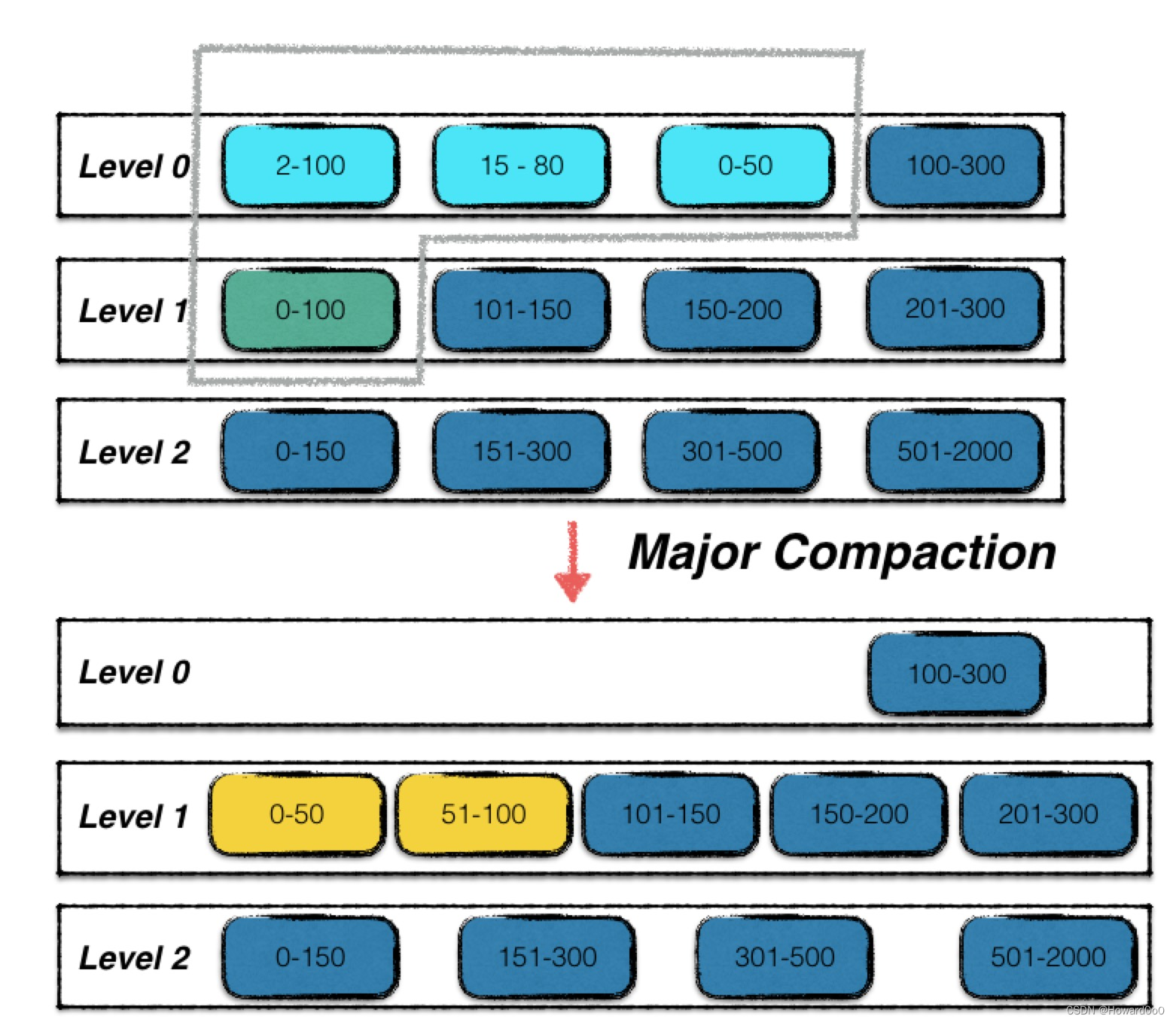
Level-0 中浅蓝色的三个 SST 文件,加上 Level-1 中的绿色的 SST 文件,这 4 个文件进行了合并,输出两个新的 SST 文件,替换原有的 SST 文件。
什么时候触发Compact SST
Compaction 的入口为MaybeScheduleCompaction(),MaybeScheduleCompaction()里面会判断是需要Compact SST还是Compact MemTable。
我们来看下有哪些地方调用了MaybeScheduleCompaction()。
第一处 读取 Key 的时候
我们调用DBImpl::Get()读取某个Key的时候,LevelDB 会按照MemTable => Immutable MemTable => SST的顺序查找,如果在MemTable或者Immutable MemTable中找到了,那么就不会触发 Compaction。但如果Key是在 SST 中找到的,这个 SST 的allowed_seeks就会减 1。当allowed_seeks为 0 时,就表示这个 SST 需要Compact了。
所以在DBImpl::Get()中,如果是从 SST 中查找的 Key,就需要调用一下MaybeScheduleCompaction(),尝试触发 Compaction。
Status DBImpl::Get(const ReadOptions& options, const Slice& key, std::string* value) {// ...bool have_stat_update = false;Version::GetStats stats;{mutex_.Unlock();LookupKey lkey(key, snapshot);if (mem->Get(lkey, value, &s)) {// 从 MemTable 中查找成功,// 不会触发 Compaction。} else if (imm != nullptr && imm->Get(lkey, value, &s)) {// 从 Immutable MemTable 中查找成功,// 也不会触发 Compaction。} else {// 如果查找 SST 了,有可能会触发 Compaction,s = current->Get(options, lkey, value, &stats);have_stat_update = true;}mutex_.Lock();}// 如果是从 SST 中查找的 Key,并且该 SST 的 Seek 次数// 已经超过了阈值,那么就会触发 Compaction。if (have_stat_update && current->UpdateStats(stats)) {MaybeScheduleCompaction();}// ...return s;
}
第二处 使用迭代器遍历数据库时
每当调用一次it->Next()或者it->Prev()移动迭代器时,迭代器内部都会调用一次DBIter::ParseKey(),将当前Key解析出来。
而在DBIter::ParseKey()中,会定期采样当前 Key,看看这个Key是否存在于多个SST中。如果是的话,就会将这个Key所在的SST的allowed_seeks减 1,然后调用MaybeScheduleCompaction()尝试触发 Compaction。
这样做的目的是定期检查SST中的Key是否存在于多个SST中,如果是的话,就通过Compaction将这个Key所在的SST合并到更高 Level 的SST中,这样就可以减少SST的数量,提高读取效率。
inline bool DBIter::ParseKey(ParsedInternalKey* ikey) {Slice k = iter_->key();// 当一个 iterator 已读取的数据大小超过 bytes_until_read_sampling_ 后,// 就会用当前 key 采一次样,查看这个 key.user_key 是否存在于多个(两个及以上) SST // 中。如果是的话,就把 key 所在的 SST.allowed_seeks 减 1,然后调用// MaybeScheduleCompaction() 尝试触发 Compaction。size_t bytes_read = k.size() + iter_->value().size();while (bytes_until_read_sampling_ < bytes_read) {bytes_until_read_sampling_ += RandomCompactionPeriod();db_->RecordReadSample(k);}assert(bytes_until_read_sampling_ >= bytes_read);bytes_until_read_sampling_ -= bytes_read;if (!ParseInternalKey(k, ikey)) {status_ = Status::Corruption("corrupted internal key in DBIter");return false;} else {return true;}
}void DBImpl::RecordReadSample(Slice key) {MutexLock l(&mutex_);if (versions_->current()->RecordReadSample(key)) {MaybeScheduleCompaction();}
}
第三处 写入 Key 时
写入Key(进MemTable)之前,会在DBImpl::MakeRoomForWrite()里检查MemTable是否已满。如果已满,就会调用MaybeScheduleCompaction()尝试触发 Compaction。此处的Compaction指的是Compact MemTable,在此就不详细赘述了,忘记的同学可以回头参考大白话解析LevelDB 2: MemTable 落盘为 SST 文件。
第四处 刚打开数据库时
在DBImpl::Open()中,会调用MaybeScheduleCompaction()尝试触发Compaction。
刚打开数据的时候为什么需要尝试触发Compaction呢?
因为当数据库上次关闭时,可能还有些没完成的Compaction,比如Compaction进行中途机器断电了。
所以当数据库打开时,需要尝试触发一次Compaction,检查下有没有未完成的Compaction。
Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) {// ...// 读取数据库文件,恢复数据库状态。Status s = impl->Recover(&edit, &save_manifest);// ...if (s.ok()) {impl->RemoveObsoleteFiles();// 当数据库关闭时,可能有些还没完成的 Compaction。// 所以打开数据库时尝试触发一次 Compaction,检查// 下有没有未完成的 Compaction。impl->MaybeScheduleCompaction();}// ...return s;
}
如何进行Compact SST
在MaybeScheduleCompaction()中,会通过versions_->NeedsCompaction()判断是否满足Compaction条件。
若条件满足,会将background_compaction_scheduled_标志位设置为true,然后将DBImpl::BGWork()加入线程池中,在后台线程中进行Compaction。
void DBImpl::MaybeScheduleCompaction() {mutex_.AssertHeld();if (background_compaction_scheduled_) {// 已经有 Compaction 在后台线程中执行了。} else if (shutting_down_.load(std::memory_order_acquire)) {// 数据库正在被关闭,不再进行 Compaction。} else if (!bg_error_.ok()) {// 存在错误,不再进行 Compaction。} else if (imm_ == nullptr && manual_compaction_ == nullptr && !versions_->NeedsCompaction()) {// 不满足 Compaction 条件} else {// 满足 Compaction 条件,把 Compaction Job 加入到后台线程池中。background_compaction_scheduled_ = true;env_->Schedule(&DBImpl::BGWork, this);}
}
DBImpl::BGWork()只是层包装,最终会调用到DBImpl::BackgroundCompaction(),也就是Compaction的实现函数。
DBImpl::BackgroundCompaction()里先计算出本次Compaction的范围,然后调用DoCompactionWork()进行Compaction。
void DBImpl::BackgroundCompaction() {mutex_.AssertHeld();// 先判断是否存在 Immutable MemTable,如果存在,// 就将本次 Compaction 判定为 MemTable Compaction。if (imm_ != nullptr) {CompactMemTable();return;}// 否则为判定为 SST Compaction,进入 SST Compaction 的流程。Compaction* c;bool is_manual = (manual_compaction_ != nullptr);InternalKey manual_end;// 如果是用户主动发起的手动 Compaction,本次 Compaction 的范围// 是由用户指定的,需要从 manual_compaction_ 中读取,而不是由 LevelDB 计算得出。// 否则,本次 Compaction 的范围由`PickCompaction()`计算得出。// 无论是手动 Compaction 还是自动 Compaction,最终都会把 Compaction 所// 涉及的 SST 文件编号记录到`Compaction* c`对象中。// c->inputs_[0] 中存放的是 Compaction Level 所涉及的 SST 文件编号。// c->inputs_[1] 中存放的是 Compaction Level+1 所涉及的 SST 文件编号。if (is_manual) {ManualCompaction* m = manual_compaction_;c = versions_->CompactRange(m->level, m->begin, m->end);m->done = (c == nullptr);if (c != nullptr) {manual_end = c->input(0, c->num_input_files(0) - 1)->largest;}Log(options_.info_log, "Manual compaction at level-%d from %s .. %s; will stop at %s\n",m->level, (m->begin ? m->begin->DebugString().c_str() : "(begin)"),(m->end ? m->end->DebugString().c_str() : "(end)"),(m->done ? "(end)" : manual_end.DebugString().c_str()));} else {// 由 leveldb 计算 Compaction 范围c = versions_->PickCompaction();}Status status;if (c == nullptr) {// 经过上面的计算,发现本次 Compaction 不需要进行,直接返回。} else if (!is_manual && c->IsTrivialMove()) {// IsTrivialMove() 表示本次 Compaction 只需要简单地将 SST 文件从// level 层移动到 level+1 层即可,不需要进行 SST 文件合并。// 在 TrivialMove 的情况下,level 层需要 Compaction 的 SST 文件// 只能有一个。assert(c->num_input_files(0) == 1);// 获取 level 层需要 Compaction 的第 0 个 SST 文件的元数据信息。 FileMetaData* f = c->input(0, 0);// 编辑 VersionEdit,将 level 层需要 Compact 的 SST 从 level 层移除,// 并将其添加到 level+1 层。c->edit()->RemoveFile(c->level(), f->number);c->edit()->AddFile(c->level() + 1, f->number, f->file_size, f->smallest, f->largest);// Apply 该 VersionEdit,将其应用到当前 VersionSet 中。status = versions_->LogAndApply(c->edit(), &mutex_);if (!status.ok()) {RecordBackgroundError(status);}VersionSet::LevelSummaryStorage tmp;Log(options_.info_log, "Moved #%lld to level-%d %lld bytes %s: %s\n",static_cast<unsigned long long>(f->number), c->level() + 1,static_cast<unsigned long long>(f->file_size), status.ToString().c_str(),versions_->LevelSummary(&tmp));} else {// 需要进行 SST 文件合并的 Compaction。// 构造一个 CompactionState 对象,用于记录本次 Compaction // 需要新生成的 SST 信息。CompactionState* compact = new CompactionState(c);// 进行真正的 SST Compaction 操作,将 Compaction SST// 文件合并生成新的 SST 文件。status = DoCompactionWork(compact);if (!status.ok()) {RecordBackgroundError(status);}// Compaction 结束后的清理工作工作。CleanupCompaction(compact);// Compaction 完成后,Input Version 就不再需要了,将其释放。c->ReleaseInputs();// 移除数据库中不再需要的文件。RemoveObsoleteFiles();}delete c;if (status.ok()) {// 没有异常,不需要进行任何异常处理。} else if (shutting_down_.load(std::memory_order_acquire)) {// 如果当前正在关闭数据库,那错误就先不需要处理了,留到下次打开// 数据时再处理,先以最快的时间关闭数据库。} else {Log(options_.info_log, "Compaction error: %s", status.ToString().c_str());}if (is_manual) {ManualCompaction* m = manual_compaction_;if (!status.ok()) {// Compaction 失败了,需要把 m->done 标记为 true,// 防止重复 Compact 该范围。m->done = true;}if (!m->done) {// Compaction 完成,需要把 m->begin 更新为本次// Compaction 的结尾,以便下次继续 Compact。m->tmp_storage = manual_end;m->begin = &m->tmp_storage;}manual_compaction_ = nullptr;}
}
计算Compaction范围
- 如果是手动触发的
Compaction,那么初始范围由用户指定,最终通过versions_->CompactRange()计算出Compaction的范围。 - 如果是自动触发的
Compaction,那么最终通过versions_->PickCompaction()计算出Compaction的范围。
versions_->CompactRange()的实现可移步参考大白话解析LevelDB: VersionSet
versions_->PickCompaction()的实现可移步参考大白话解析LevelDB: VersionSet
进行Compaction
- 如果计算出的
Compaction范围是nullptr,表示当前不需要进行Compaction,直接返回。 - 如果计算出的
Compaction范围符合TrivialMove条件,表示只需要将SST文件从level层移动到level+1层即可,不需要进行SST文件合并。 - 否则的话,就需要进行
SST文件合并,DoCompactionWork(c)将Compaction范围内的SST文件合并为一个新的SST文件。
DoCompactionWork(CompactionState* compact)的实现如下。
Status DBImpl::DoCompactionWork(CompactionState* compact) {const uint64_t start_micros = env_->NowMicros();int64_t imm_micros = 0; // Micros spent doing imm_ compactionsLog(options_.info_log, "Compacting %d@%d + %d@%d files",compact->compaction->num_input_files(0), compact->compaction->level(),compact->compaction->num_input_files(1), compact->compaction->level() + 1);assert(versions_->NumLevelFiles(compact->compaction->level()) > 0);assert(compact->builder == nullptr);assert(compact->outfile == nullptr);// 将当前存活着的最小 snapshot 版本号记录到`compact->smallest_snapshot`中。// Compaction 的时候会将 Sequence Number 小于`compact->smallest_snapshot`的// Key 都扔掉,因为已经没有 snapshot 需要这些 Key 了。if (snapshots_.empty()) {compact->smallest_snapshot = versions_->LastSequence();} else {compact->smallest_snapshot = snapshots_.oldest()->sequence_number();}// 创建一个 Iterator 来读取所有的 Compaction SST。Iterator* input = versions_->MakeInputIterator(compact->compaction);// 开始 Compaction,在这期间可以先释放 mutex_,让其他线程可以继续读写数据库。mutex_.Unlock();input->SeekToFirst();Status status;ParsedInternalKey ikey;std::string current_user_key;bool has_current_user_key = false;SequenceNumber last_sequence_for_key = kMaxSequenceNumber;// Compaction 的过程会比较耗时,每处理完一个 Key 就检查下是否正在关闭数据库。// 如果检查到正在关闭数据库,就先终止 Compaction,等下次打开数据库的时候再继续 Compaction。while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) {// 如果检测到有 Immutable MemTable 存在,优先处理 Immutable MemTable,// 把 Immutable MemTable 转成 SST 文件。if (has_imm_.load(std::memory_order_relaxed)) {const uint64_t imm_start = env_->NowMicros();mutex_.Lock();if (imm_ != nullptr) {CompactMemTable();// Compact MemTable 完成后唤醒在`MakeRoomForWrite()`中等待的线程。background_work_finished_signal_.SignalAll();}mutex_.Unlock();imm_micros += (env_->NowMicros() - imm_start);}Slice key = input->key();// 检查本次 Compaction 的范围是否太大,如果太大的话就缩小本次的 Compaction 范围,// Compact 到 key 为止即可,后面的 key 等下次 Compaction 的时候再处理。if (compact->compaction->ShouldStopBefore(key) && compact->builder != nullptr) {status = FinishCompactionOutputFile(compact, input);if (!status.ok()) {break;}}bool drop = false;if (!ParseInternalKey(key, &ikey)) {// 如果解析 Key 失败,那可能是数据损坏的情况。// 把坏掉的 Key 保留下来,写到新 SST 里,让用户// 来处理。current_user_key.clear();has_current_user_key = false;last_sequence_for_key = kMaxSequenceNumber;} else {if (!has_current_user_key ||user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) != 0) {current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());has_current_user_key = true;last_sequence_for_key = kMaxSequenceNumber;}// 当 key 的类型为 Deletion 时,// 或者 key 的 Sequence Number 小于 compact->smallest_snapshot,// 这个 key 就会被丢弃。// 举个例子:// compact->smallest_snapshot = 4// 读到的 key 为: key1-seq5, key1-seq4, key1-seq3, key1-seq2, key1-seq1。// key1-seq5 和 key1-seq4 会被保留写入到新 SST 中,// 剩下的 key1-seq3, key1-seq2, key1-seq1 都会被丢弃。if (last_sequence_for_key <= compact->smallest_snapshot) {// Hidden by an newer entry for same user keydrop = true; // (A)} else if (ikey.type == kTypeDeletion && ikey.sequence <= compact->smallest_snapshot &&compact->compaction->IsBaseLevelForKey(ikey.user_key)) {drop = true;}last_sequence_for_key = ikey.sequence;}
#if 0Log(options_.info_log," Compact: %s, seq %d, type: %d %d, drop: %d, is_base: %d, ""%d smallest_snapshot: %d",ikey.user_key.ToString().c_str(),(int)ikey.sequence, ikey.type, kTypeValue, drop,compact->compaction->IsBaseLevelForKey(ikey.user_key),(int)last_sequence_for_key, (int)compact->smallest_snapshot);
#endif// 如果当前 key 不需要被丢弃,就把它写入到新的 SST 中。if (!drop) {// 如果当前没有打开的 Output SST 文件,就打开一个新的 Output SST 文件。// 通过 compact->builder 来控制该新 SST 文件的写入。if (compact->builder == nullptr) {status = OpenCompactionOutputFile(compact);if (!status.ok()) {break;}}// 设置这个 Output SST 文件的最小 key 和最大 key。if (compact->builder->NumEntries() == 0) {compact->current_output()->smallest.DecodeFrom(key);}compact->current_output()->largest.DecodeFrom(key);// 往新 SST 中写入当前的 Key-Value。compact->builder->Add(key, input->value());// Output SST 大小达到了阈值,就完成该 Ouput SST 的构建,重新开一个新的 SST。if (compact->builder->FileSize() >= compact->compaction->MaxOutputFileSize()) {status = FinishCompactionOutputFile(compact, input);if (!status.ok()) {break;}}}input->Next();}// Compaction 和关闭数据库撞上了,终止 Compaction。if (status.ok() && shutting_down_.load(std::memory_order_acquire)) {status = Status::IOError("Deleting DB during compaction");}// 如果还有没收尾的 SST,做个收尾。if (status.ok() && compact->builder != nullptr) {status = FinishCompactionOutputFile(compact, input);}// 检查 input 迭代器有木有错误。if (status.ok()) {status = input->status();}delete input;input = nullptr;// 记录下本次 Compaction 所花费的时间。CompactionStats stats;stats.micros = env_->NowMicros() - start_micros - imm_micros;// 记录下本次 Compaction 一共读取了多少字节。for (int which = 0; which < 2; which++) {for (int i = 0; i < compact->compaction->num_input_files(which); i++) {stats.bytes_read += compact->compaction->input(which, i)->file_size;}}// 记录本次 Compaction 一共写入了多少字节。for (size_t i = 0; i < compact->outputs.size(); i++) {stats.bytes_written += compact->outputs[i].file_size;}mutex_.Lock();// 记录本次 Compaction 被推到哪个 level.stats_[compact->compaction->level() + 1].Add(stats);// 将本次 Compaction 产生的改动(删除和新增了哪些 SST)生成一个 VersionEdit,// 并应用到最新的 Version 上,产生一个新的 Version。if (status.ok()) {status = InstallCompactionResults(compact);}if (!status.ok()) {RecordBackgroundError(status);}VersionSet::LevelSummaryStorage tmp;Log(options_.info_log, "compacted to: %s", versions_->LevelSummary(&tmp));return status;
}
创建一个迭代器用于读取Compaction范围内的Key-Value
通过Iterator* input = versions_->MakeInputIterator(compact->compaction)创建一个迭代器,该迭代器可按顺序读取Compaction范围所有内的Key-Value。
通过迭代器遍历每个Key-Value,丢弃或者写入新的SST
leveldb 会先读取当前最小的Snapshot版本号,记录到compact->smallest_snapshot中。
如果当前Key的版本号小于compact->smallest_snapshot,或者Key的类型为Deletion,那么这个Key就会被丢弃。
否则的话,将当前Key写入新的SST。
相关文章:
大白话解析LevelDB 3: SST Compaction
SST Compaction 文章目录 SST Compaction什么是Compact SST什么时候触发Compact SST第一处 读取 Key 的时候第二处 使用迭代器遍历数据库时第三处 写入 Key 时第四处 刚打开数据库时 如何进行Compact SST计算Compaction范围进行Compaction创建一个迭代器用于读取Compaction范围…...
【Python】02快速上手爬虫案例二:搞定验证码
文章目录 前言1、不要相信什么验证码的库2、以古诗文网为例,获取验证码1)code_result.py2)gsw.py 前言 提示:以古诗文网为例,获取验证码: 登录:https://so.gushiwen.cn/user/login.aspx 1、不…...

C# 中的接口
简介 官方说明:接口定义协定。 实现该协定的任何 class 或 struct 必须提供接口中定义的成员的实现。 接口可为成员定义默认实现。 它还可以定义 static 成员,以便提供常见功能的单个实现。 从 C# 11 开始,接口可以定义 static abstract 或 …...
一篇文章带你了解C++中隐含的this指针
文章目录 一、this指针的引出二、this指针的特性【面试题】 一、this指针的引出 我们先来定义一个日期类Date,下面这段代码执行的结果是什么呢? class Date { public:void Init(int year, int month, int day){_year year;_month month;_day day;}v…...
shardinig-JDBC二开-支持sharding-jdbc的配置文件接入到nacos
代码在 https://gitee.com/lbmb/mb-live-app 中 【mb-live-framework】 模块里面的【mb-live-framework-datasource-stater】 如果喜欢 希望大家给给star 项目还在持续更新中。 背景介绍: 因为近期在自己写一套直播项目。使用到了sharding-jdbc来做分库分表的组件…...

a-table自定义展开图标
原文来自:vue 修改ant中table表格的展开图标 树形表格expandIcon自定义图标 <template #expandIcon"props"><span v-if"props.record.children?.length > 0"><divv-if"props.expanded"style"display: inline…...
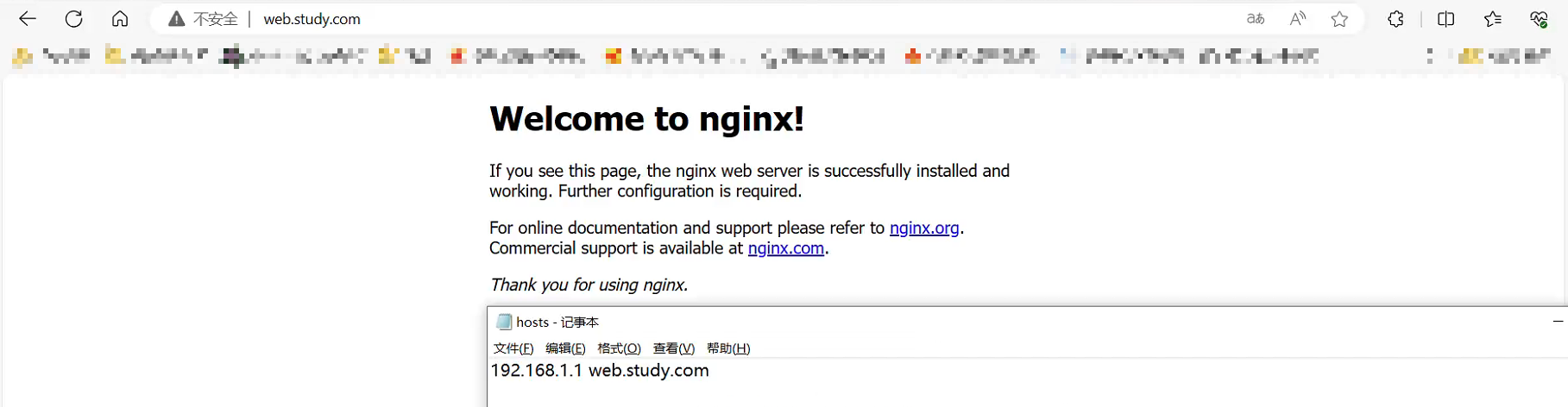
Kubernetes Ingress暴露应用的工作流程
文章目录 一、Igress是什么二、安装Igress Controller三、Service NodePort模式暴露Ingress Controller四、创建ingress 进行访问查看ingress controller生成的规则(两种类型通用) 五、HostNetwork模式暴露Ingress Controller总结: 一、Igress是什么 一般负载均衡器…...
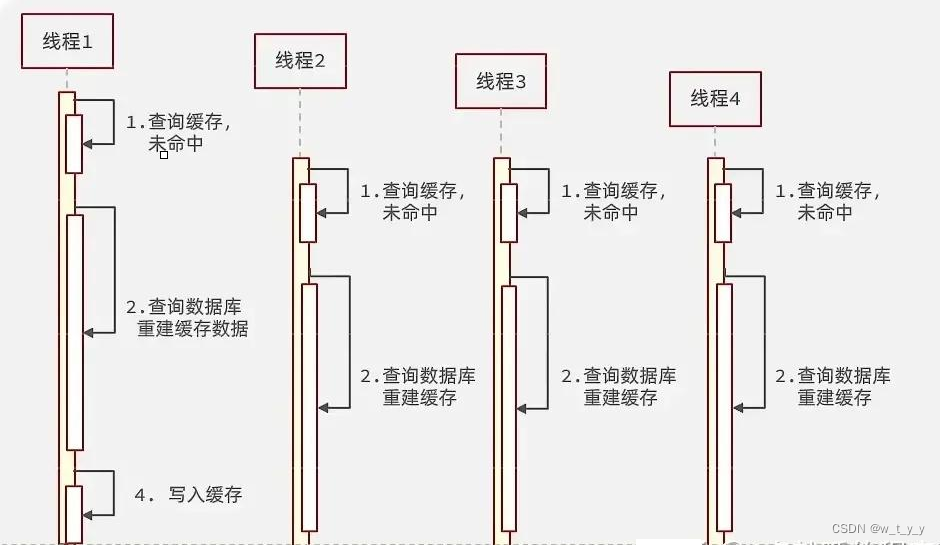
Redis应用(1)缓存(1.2)------Redis三种缓存问题
三者出现的根本原因是:Redis缓存命中率下降,请求直接打到DB上了。 一、 缓存穿透: 1、定义: 缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。…...

安全 专题
[实践总结] 日志注入问题(log4j2) [实践总结] Java 防止SQL注入的四种方案 [实践总结] 如何防护 order by 导致的SQL注入 [实践总结] 限制正则表达式匹配次数/时间 防止DoS攻击 [实践总结] java XML解析防止外部实体注入 [Ref] yaml.load的漏洞利用…...
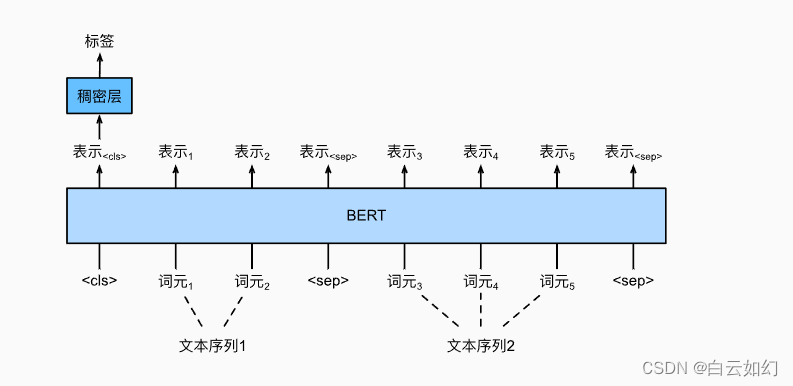
自然语言处理-文本对分类或回归
我们研究了自然语言推断。它属于文本对分类,这是一种对文本进行分类的应用类型。 以一对文本作为输入但输出连续值,语义文本相似度是一个流行的“文本对回归”任务。 这项任务评估句子的语义相似度。例如,在语义文本相似度基准数据集&#x…...

以梦为码,CodeArts Snap 缩短我与算法的距离
背景 最近一直在体验华为云的 CodeArts Snap,逐渐掌握了使用方法,代码自动生成的准确程度大大提高了。 自从上次跟着 CodeArts Snap 学习用 Python 编程,逐渐喜欢上了 Python。 我还给 CodeArts Snap 起了一个花名: 最佳智能学…...

SpringMVC-HttpMessageConverter 报文信息转化器
文章目录 HttpMessageConverter一、概念二、RequestBody三、RequestEntity四、 ResponseBody1.返回JSON格式的字符串 五、RestController六、ResponseEntity HttpMessageConverter 一、概念 报文信息转化器,将请求报文转化为Java对象,或将Java对象转化…...
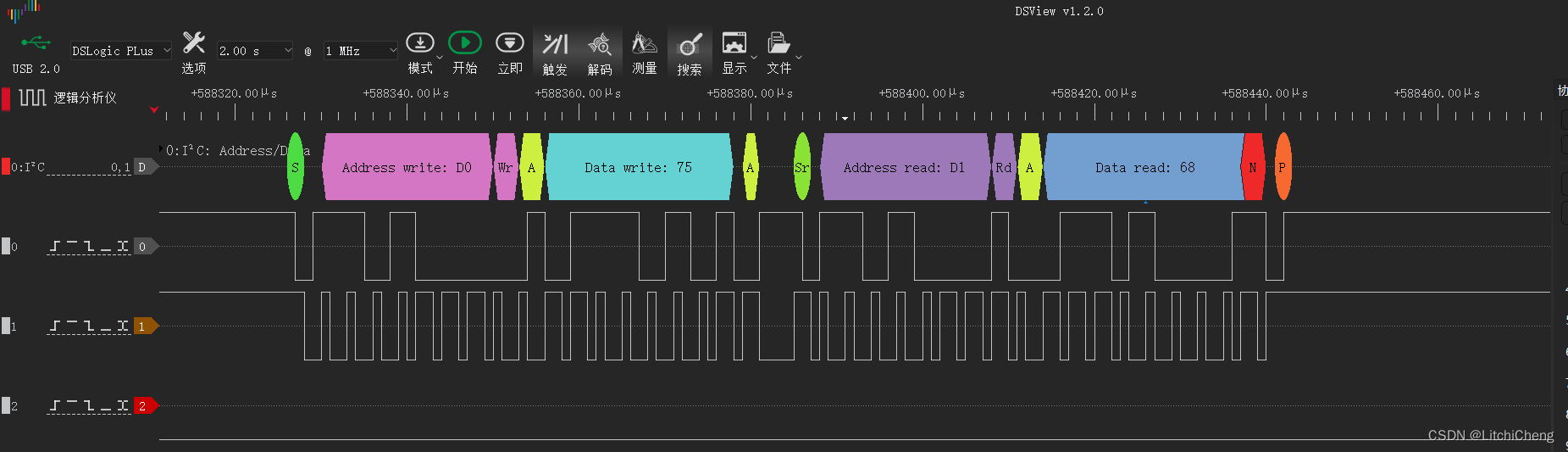
[AG32VF407]国产MCU+FPGA 使用I2C测试陀螺仪MPU6050
视频讲解 [AG32VF407]国产MCUFPGA 使用I2C测试陀螺仪MPU6050 实验过程 查看原理图中定义的I2C的管脚,PB0和PB1 在board.ve中定义的引脚功能 I2C0_SDA PIN_36 I2C0_SCL PIN_35新建工程 测试代码 #include "board.h"#define MIN_IRQ_PRIORITY 1 #define …...

ES 可扩展、高可靠、使用场景等常见问题
ElasticSearch的常见问题 什么是ElasticSearch ElasticSearch是一款非常强大的、基于Lucene的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。 它被用作全文检索、结构化搜索、分析…...

<网络安全>《4 网络安全产品之web应用防护系统》
1 基本概念 1.1 WAF Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称:WAF)。一般作为网关设备,防护Web、Webmail服务器等。 1.2 本质 WAF的本质是Web应…...

如何解决Flutter应用程序的兼容性问题
随着移动应用开发领域的不断发展,Flutter作为一种跨平台框架,受到了越来越多开发者的青睐。要确保Flutter应用程序能够在不同的设备和操作系统上稳定运行,并提供一致的用户体验,我们需要重视应用程序的兼容性问题。下面将简单的介…...

详解Mockito
详解Mockito 1. Mockito简介 在我们的编程世界中,测试是一个非常重要的环节,它能帮助我们确保代码的质量和稳定性。而在众多的测试方法中,Mock测试是一种非常有效的手段。 1.1 什么是 Mock 测试 Mock测试,顾名思义,…...

【论文+App试玩+图像到视频】2311.Animate-anyone:上传1张图片为任何人制作动画(用于角色动画的一致且可控的图像到视频合成)(暂未开源)
项目主页:https://humanaigc.github.io/animate-anyone/ 论文: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation 摩尔线程复现代码:https://github.com/MooreThreads/Moore-AnimateAnyone 摩尔windows一…...
【深度学习实验】TensorBoard使用教程【SCALARS、IMAGES、TIME SERIES】
文章目录 一、环境二、TensorBoard1. 使用TensorBoardXa. 安装TensorBoardXb. 使用示例 2. PyTorch内置的TensorBoard3. 启动TensorBoard服务 三、实战1. SCALARS(标量)找不同关卡1关卡2关卡3关卡4 Show data download linksIgnore outliers in chart sc…...
渗透测试(12)- WireShark 网络数据包分析
目录 1、WireShack 简介 2、WireShark 基本使用方法 3、 WireShack 抓包分析 3.1 Hypertext Transfer Protocol (应用层) 3.2 Transmission Control Protocol (传输层) 3.3 Internet Protocol Version 4(网络层) 3.4 Ethernet Il (链路层): 数据链路层以太网头部信息 …...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...

Agent OS:AI智能体开发的操作系统级解决方案
1. 项目概述:一个为AI智能体而生的操作系统最近在AI智能体开发圈子里,一个名为“Agent OS”的项目热度持续攀升。它来自Rivet.dev团队,定位非常清晰:一个专为构建、运行和管理AI智能体而设计的操作系统。如果你正在尝试将大语言模…...

STM32CubeIDE实战指南:从代码编译到一键下载的完整流程解析
1. STM32CubeIDE开发环境概述 对于刚接触STM32开发的工程师来说,选择一款合适的集成开发环境(IDE)至关重要。STM32CubeIDE是ST官方推出的免费开发工具,它集成了代码编辑、编译、调试和下载功能于一体,特别适合新手快速上手。我在实际项目中使…...

AICoverGen终极指南:5分钟用AI制作专业级翻唱歌曲
AICoverGen终极指南:5分钟用AI制作专业级翻唱歌曲 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想不想让AI…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...

JetBrains IDE 30天试用重置:一键解决方案的完整实践指南
JetBrains IDE 30天试用重置:一键解决方案的完整实践指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当您正专注于代码调试时,IDE突然弹出"评估期已结束"的红色警告…...

量子控制中的动态校正门与SCQC几何方法
1. 量子控制中的噪声挑战与动态校正门在超导量子处理器上实现高保真度的量子门操作,最大的障碍来自环境噪声。这些噪声主要分为两类:失谐噪声(δz)和幅度噪声(ϵ)。失谐噪声源于量子比特频率的漂移…...
)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码) 科研图表的美观程度直接影响论文的第一印象,而三维柱状图在展示多维度数据时尤为常见。传统手动调整每个柱体的颜色、透明度、光照效果不仅耗时&#…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

桌面自动化技能库:基于PyAutoGUI与Selenium的工程化实践
1. 项目概述:一个桌面操作员的技能库最近在GitHub上看到一个挺有意思的项目,叫Marways7/cua_desktop_operator_skill。光看这个名字,可能有点摸不着头脑,但作为一个在自动化运维和桌面支持领域摸爬滚打多年的老手,我立…...