【论文+App试玩+图像到视频】2311.Animate-anyone:上传1张图片为任何人制作动画(用于角色动画的一致且可控的图像到视频合成)(暂未开源)
项目主页:https://humanaigc.github.io/animate-anyone/
论文: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
摩尔线程复现代码:https://github.com/MooreThreads/Moore-AnimateAnyone
摩尔windows一键运行包:https://www.bilibili.com/video/BV1S5411i7Cn/
原作者讲解(需要手机端看): https://mp.weixin.qq.com/s/bSV-dxA618LvN76tg4Z0kQ
其他教程视频: 用Comfy UI + Animate Anyone来一键制作抖音视频
demo:在通义前问app上可以试用 (可生成12秒)

文章目录
- 简介
- 实测: 鸣人跳兔子舞
- 相关研究
- 方法
- Image Animation
- 基于diffusion的图片生成模型0
- 基于diffusion的视频生成
- (DreamPose )
- 23.07 DicCo(跳舞)
- 图像生成一致性改进:TryonDiffusion
- 视觉内容一致性: Emu Video
- *时序的diffusion model (逐渐成熟)
- 对上面方法总结
- Animate Anyone 算法原理
- 驱动2次元受到用户欢迎
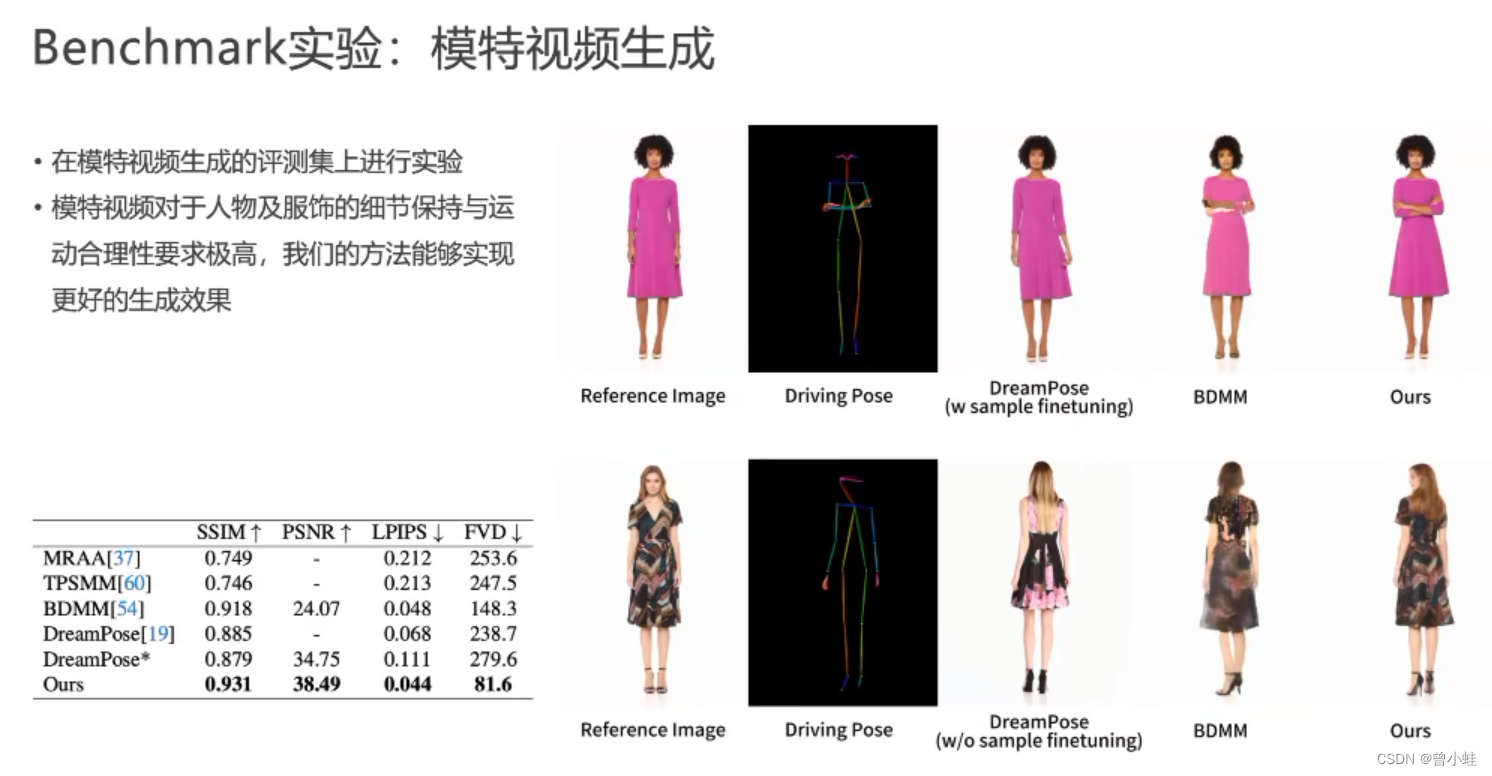
- 在量化的模特视频上
- 应用案例
- 试穿+电商
- 数字人相关
- 团队建设
- 附录 兵马俑跳科目三
简介
角色动画(Character Animation)是指在通过驱动信号从静止图像中生成角色视频。
图片到视频的难点在于:保持角色详细信息的一致性(consistency)

实测: 鸣人跳兔子舞

相关研究
-
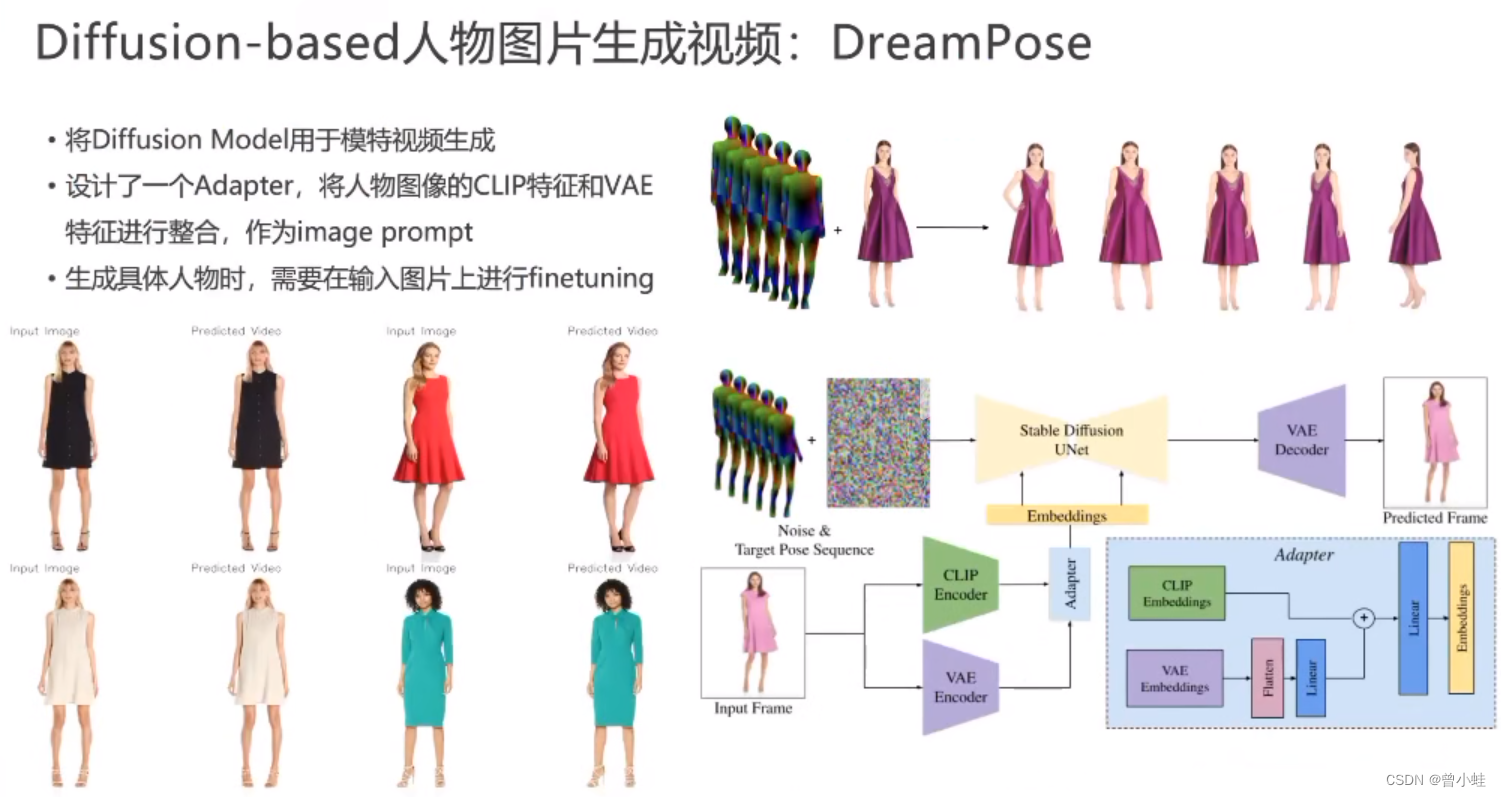
DreamPose 专注于时尚图像到视频的合成,并提出了一个适应模块来融合图像中的CLIP和VAE特征。但是缺点是需要
微调模型来保持生成图片的一致性。 -
DisCo : 探索人类的舞蹈生成,通过CLIP整合角色的特征(integrating character features),并通过ControlNet结合·背景特征·。然而,它在保留角色的细节方面存在缺陷,并且存在
帧间抖动问题。 -
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
能根据给的静态图片生成图片,未能从图像中捕获复杂的细节,提供更多的多样性,但缺乏精度,特别是在应用于角色动画时,导致角色外观的细粒度细节的时间变化 -
ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models 和T2I-Adapter
通过在stable diffusion上添加额外的编码层来生成视觉的可控性。促进各种条件下的受控生成,如姿势、蒙版、边缘和深度 -
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
使扩散模型能够保持给定图像的特点,生成提示指定的内容的图像。 -
23.02
GEN1: Runway : 基于扩散模型的结构和内容引导视频合成 Structure and Content-Guided Video Synthesis with Diffusion Models -
TryOnDiffusion: 23.06 A Tale of Two UNets
将扩散模型应用于虚拟服装试穿任务,并引入并行unet结构。 -
Emu Video:Meta提出 23.11 Factorizing Text-to-Video Generation by Explicit Image Conditioning
与之前的作品相比,该方法生成512像素、每秒16帧、4秒长视频,在Quality和Faithfulness上都取得了胜利:制作视频(MAV)、图像视频(Imagen)、Align Your Latents (AYL)、Reuse & Diffuse (R&D)、Cog Video (Cog)、Gen2和Pika Lab(Pika)
.
方法
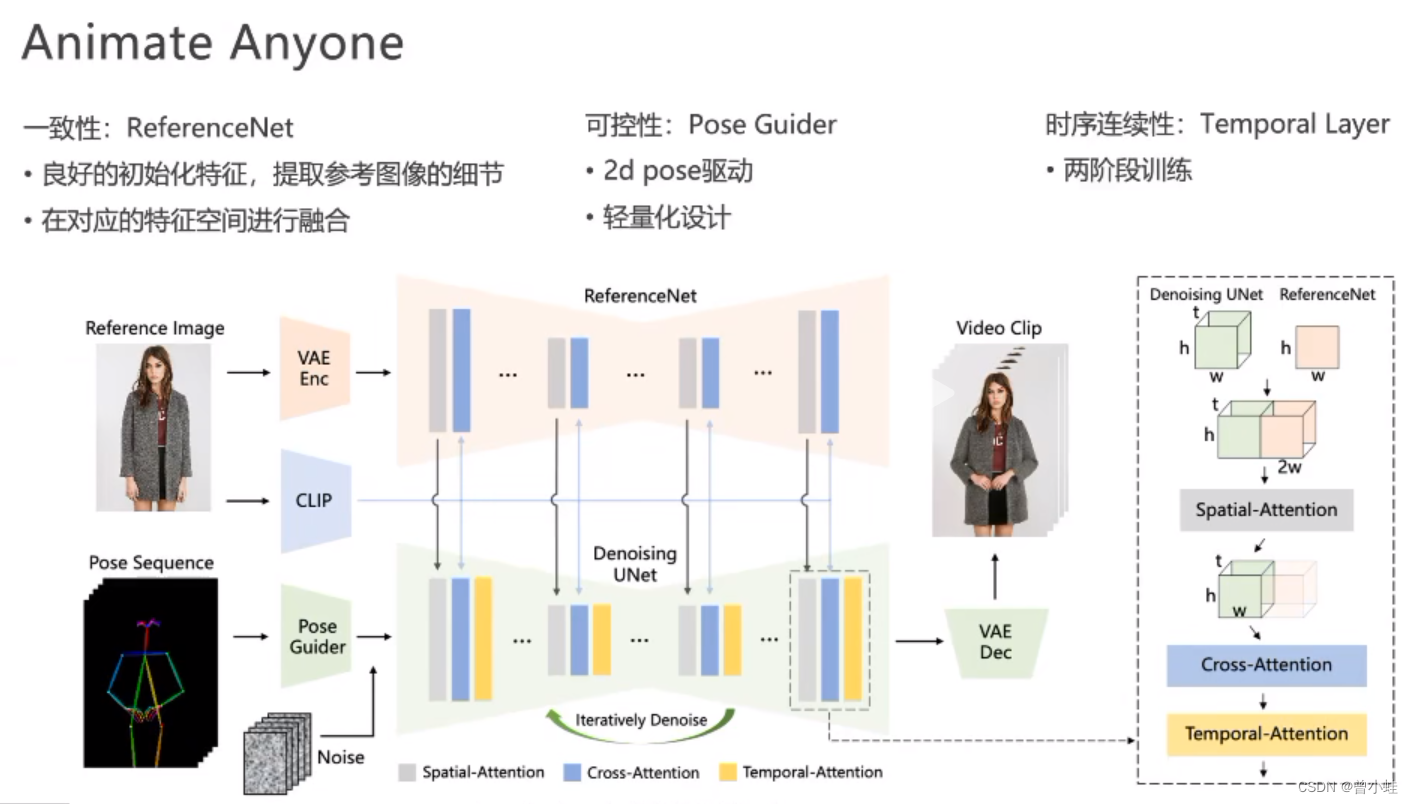
- 为了解决复杂的(intricate)外观特征的
一致性(appearance features),设计了ReferenceNet,并通过空间注意力模块(spatial attention)合并细节特征。
2.为了确保视频可控性和连续性(controllability and continuity),设计了姿态引导模块(pose guider)来指导角色的运动. - 为了确保视频帧之间的
平滑帧间转换(smooth inter-frame transitions),采用一种有效的时间建模(temporal modeling)方法
姿态序列(pose sequence)最初使用Pose Guider进行编码,并与多帧噪声融合,然后进行去噪UNet进行视频生成去噪过程。去噪UNet的计算块由空间注意、交叉注意和时间注意组成,如右边的虚线框所示。参考图像的集成涉及两个方面。首先,通过 ReferenceNet 提取详细的特征并用于 Spatial-Attention。其次,通过CLIP图像编码器提取语义特征进行交叉注意。时间注意在时间维度上运行。最后,VAE 解码器将结果解码为视频剪辑。
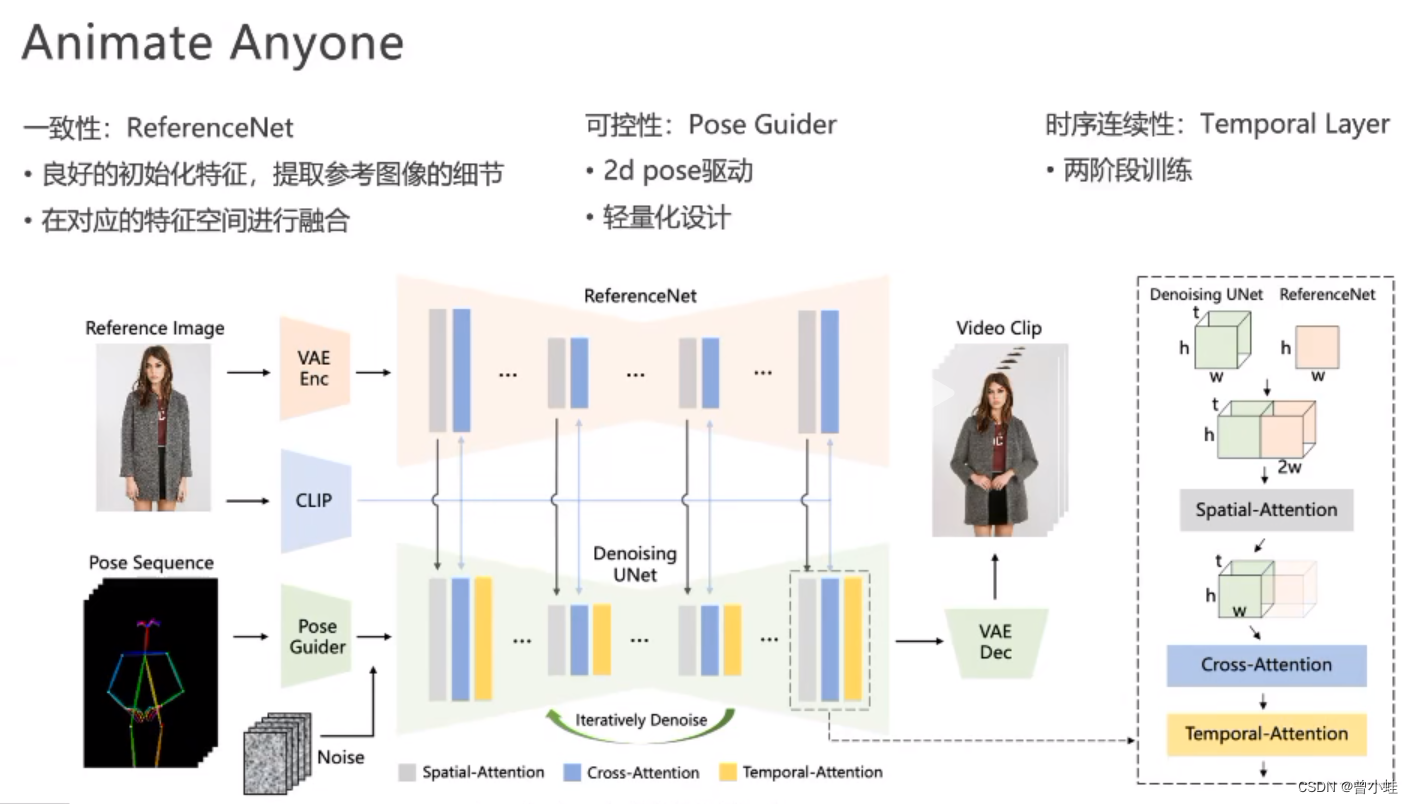
原作者胡立讲解
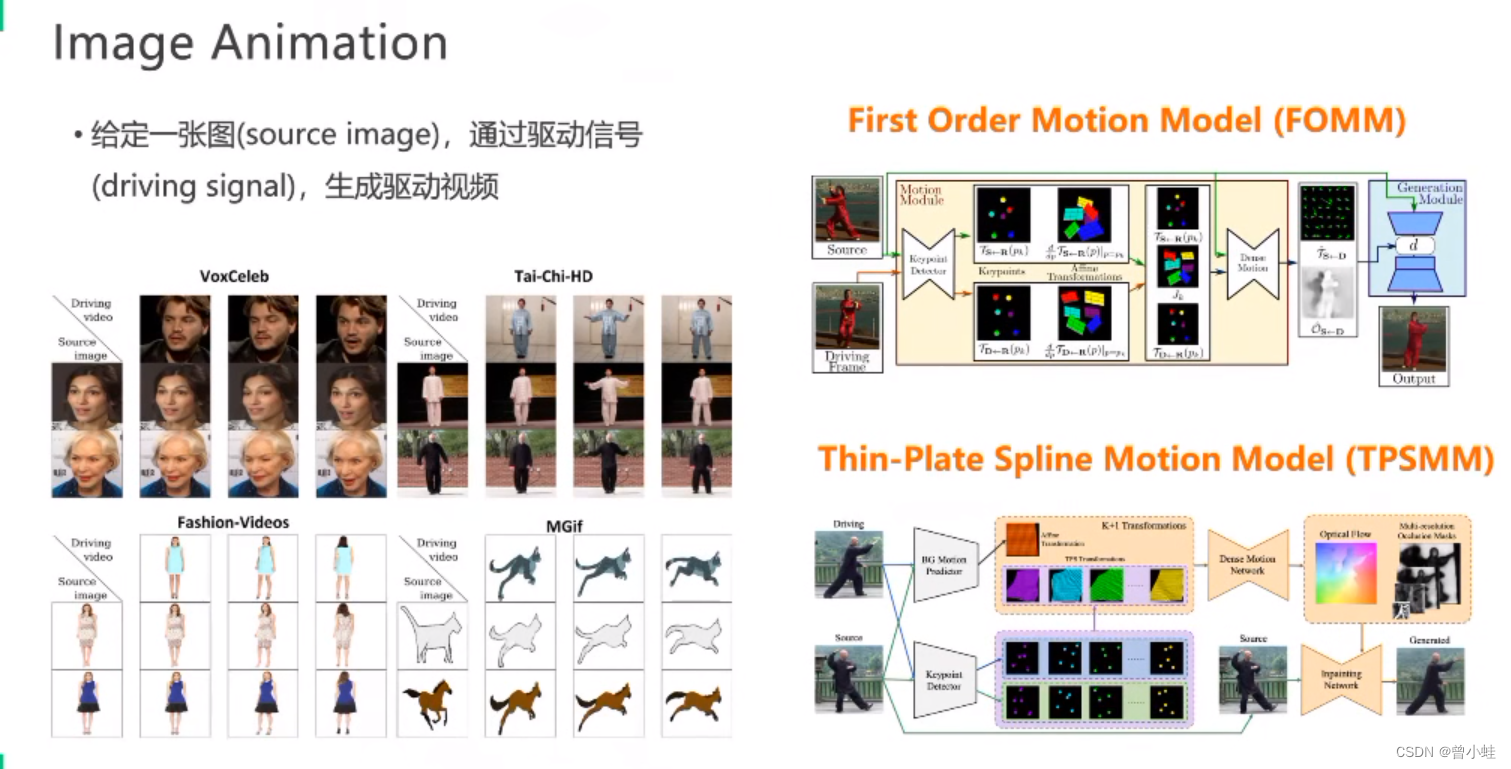
Image Animation
分析关键点、对运动过程建模、驱动
2019 FOMM
2022 TPSMM
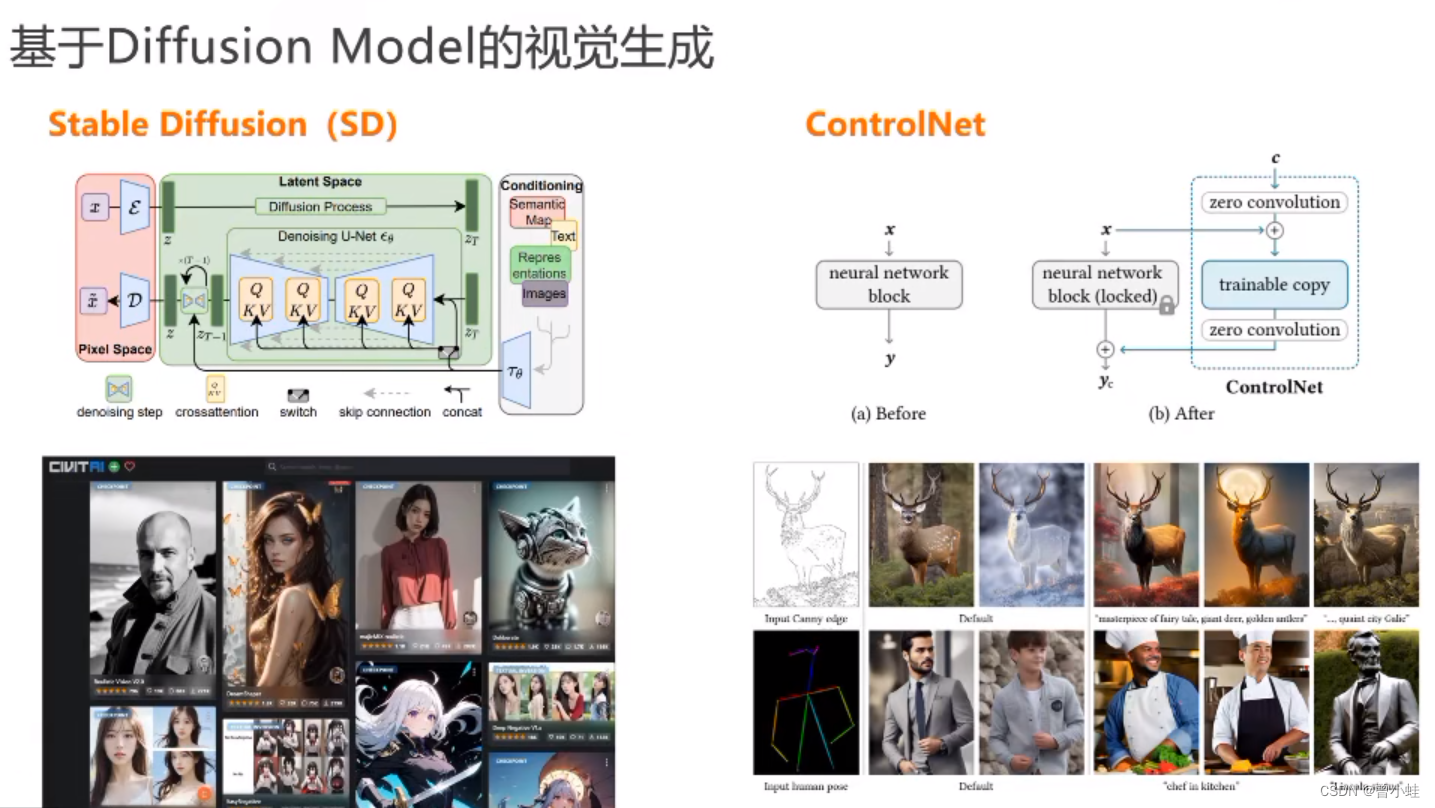
基于diffusion的图片生成模型0
代表工作为 stable diffusion +ControlNet (可控)
基于diffusion的视频生成
(DreamPose )
输入tuning
主要还是模特、连续性不好
23.07 DicCo(跳舞)
驱动跳舞、视频不连续, 一致性不好
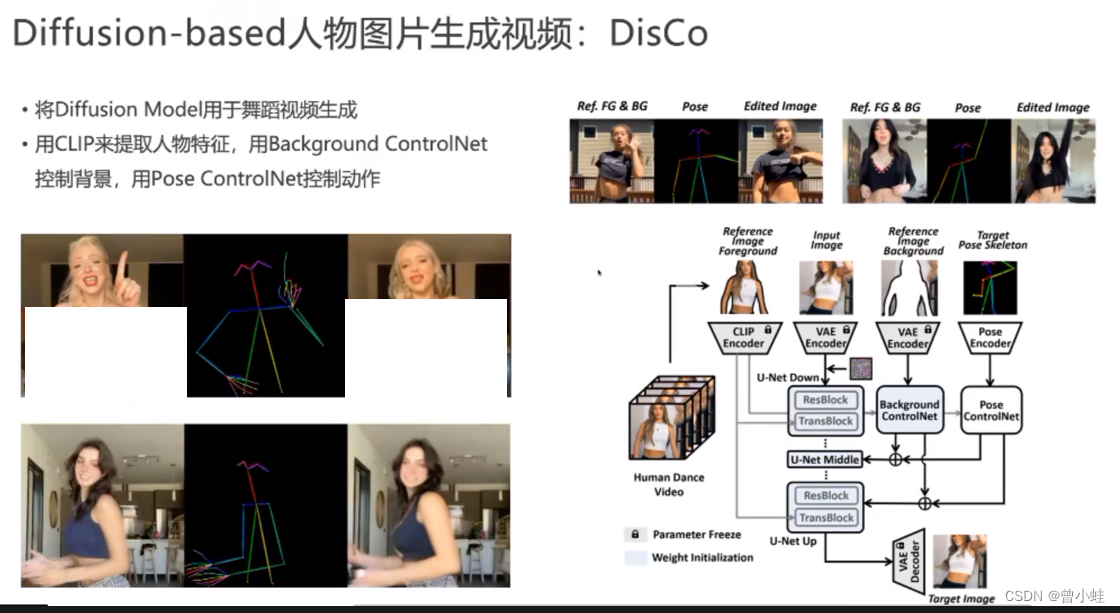
图像生成一致性改进:TryonDiffusion
生成的效果特别好
有效的图片特征

视觉内容一致性: Emu Video
人物效果一般,长时一致性不厚好

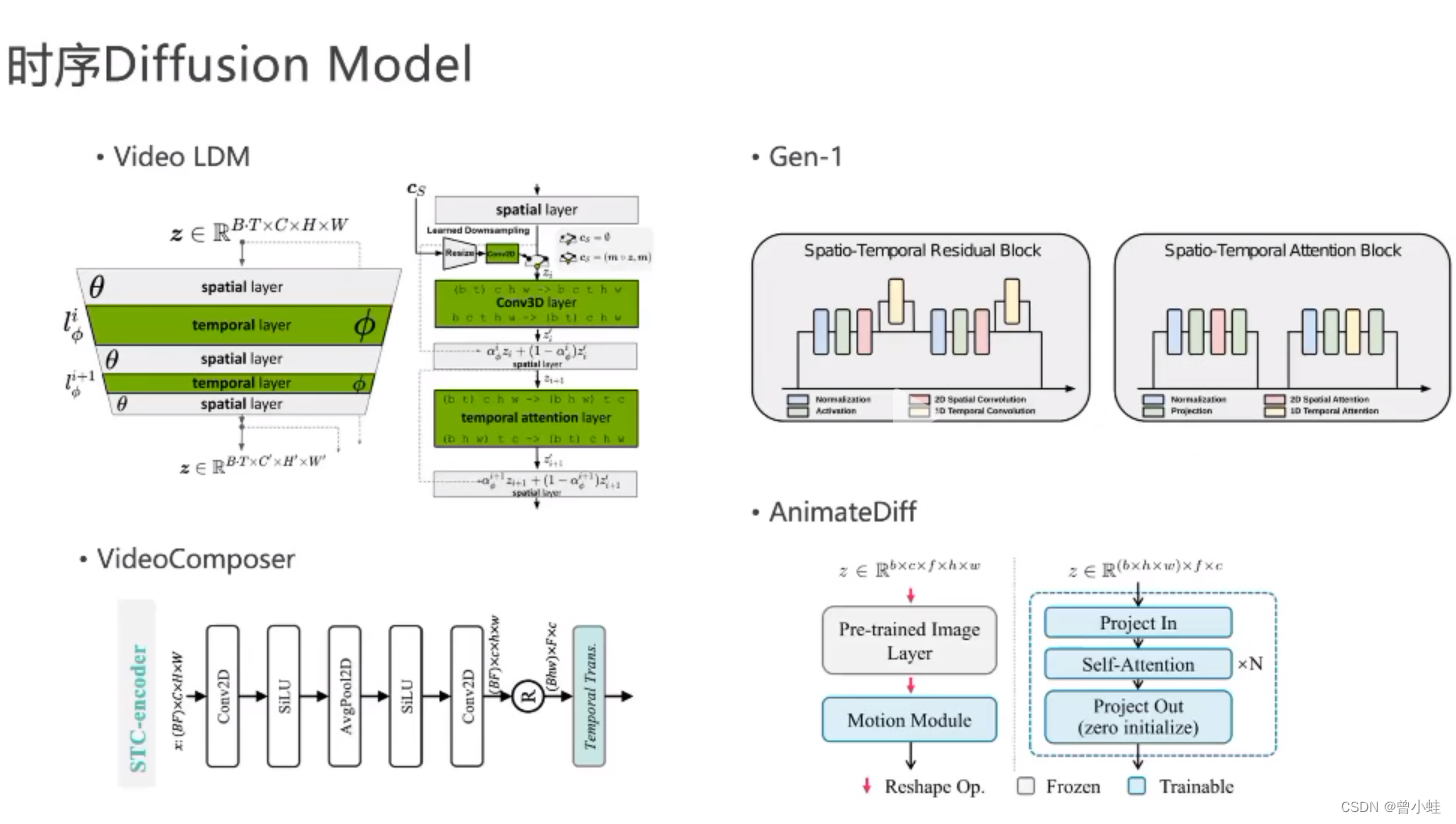
*时序的diffusion model (逐渐成熟)
video LDM
Gen-1
videoComposer
AnimateDiff
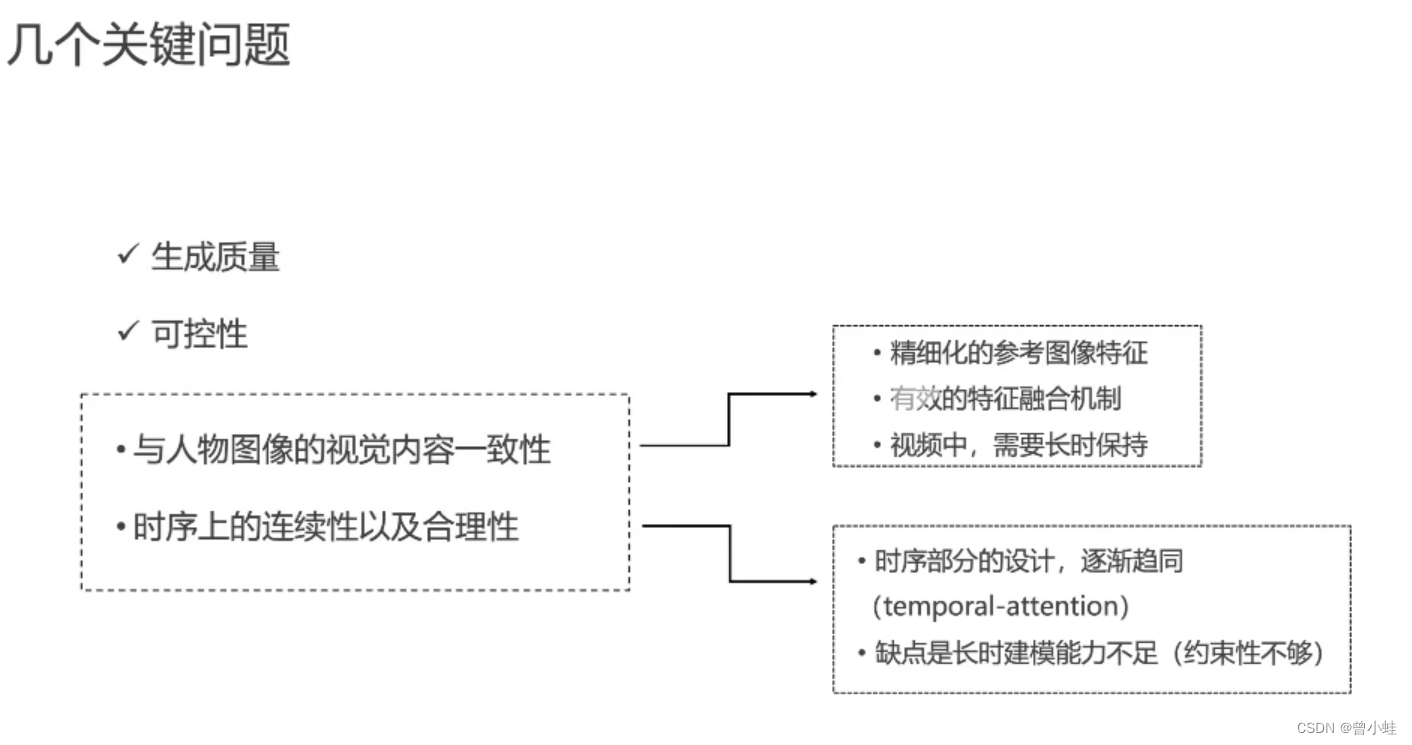
对上面方法总结
diffusion模型的生成与可控能力,但是之前的方法效果不稳定
Animate Anyone 算法原理
ReferenceNet 、PoseGuider 、Temporal Layer
输入:任务参考图片、驱动任务pose序列
denosing unet 就是stable diffusion的扩展
CLIP 提取图片语意特征、ReferenceNet 提取的是图像细节
问题:看不见地方,手部的精细度
效果

驱动2次元受到用户欢迎

在量化的模特视频上
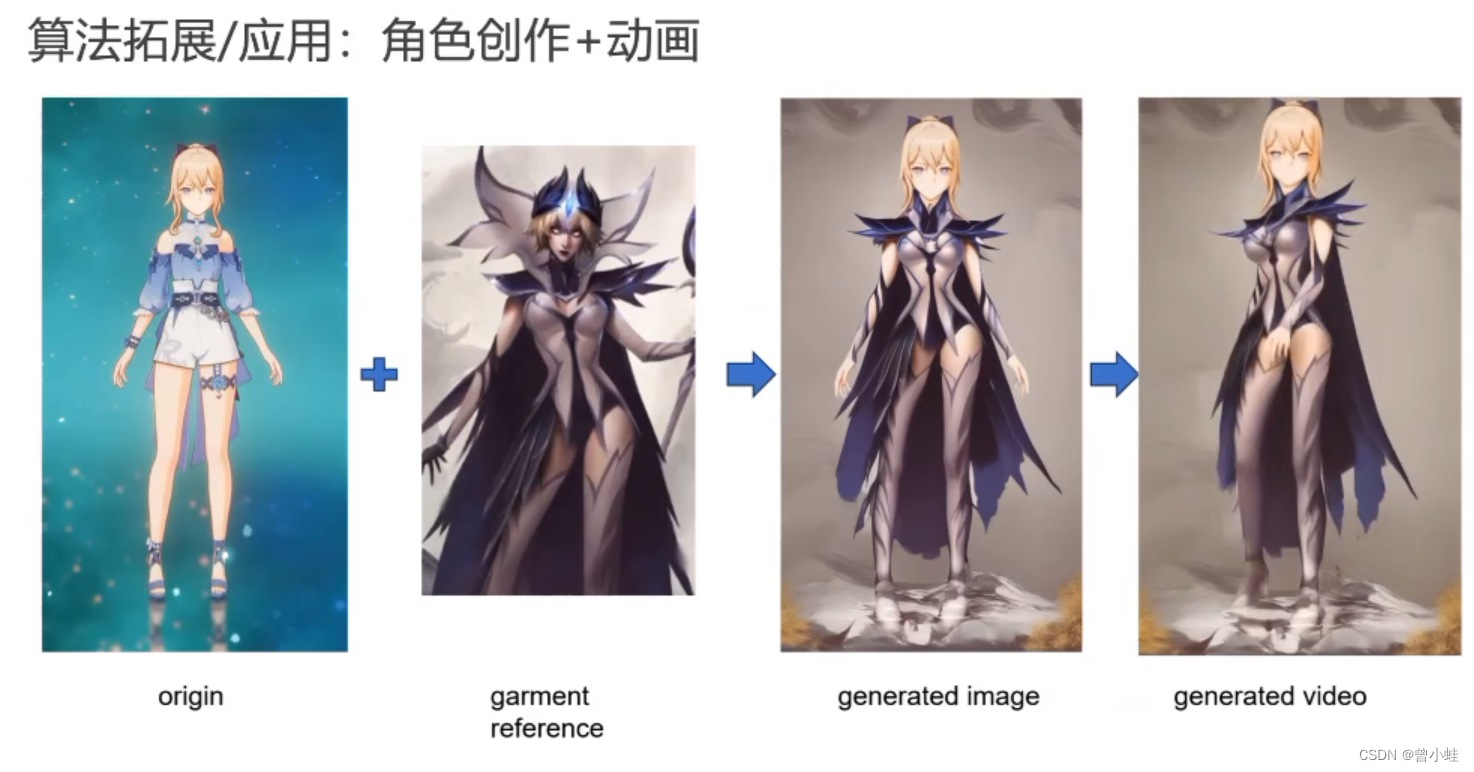
应用案例
结合换衣(outfit-anything),角色皮肤设计
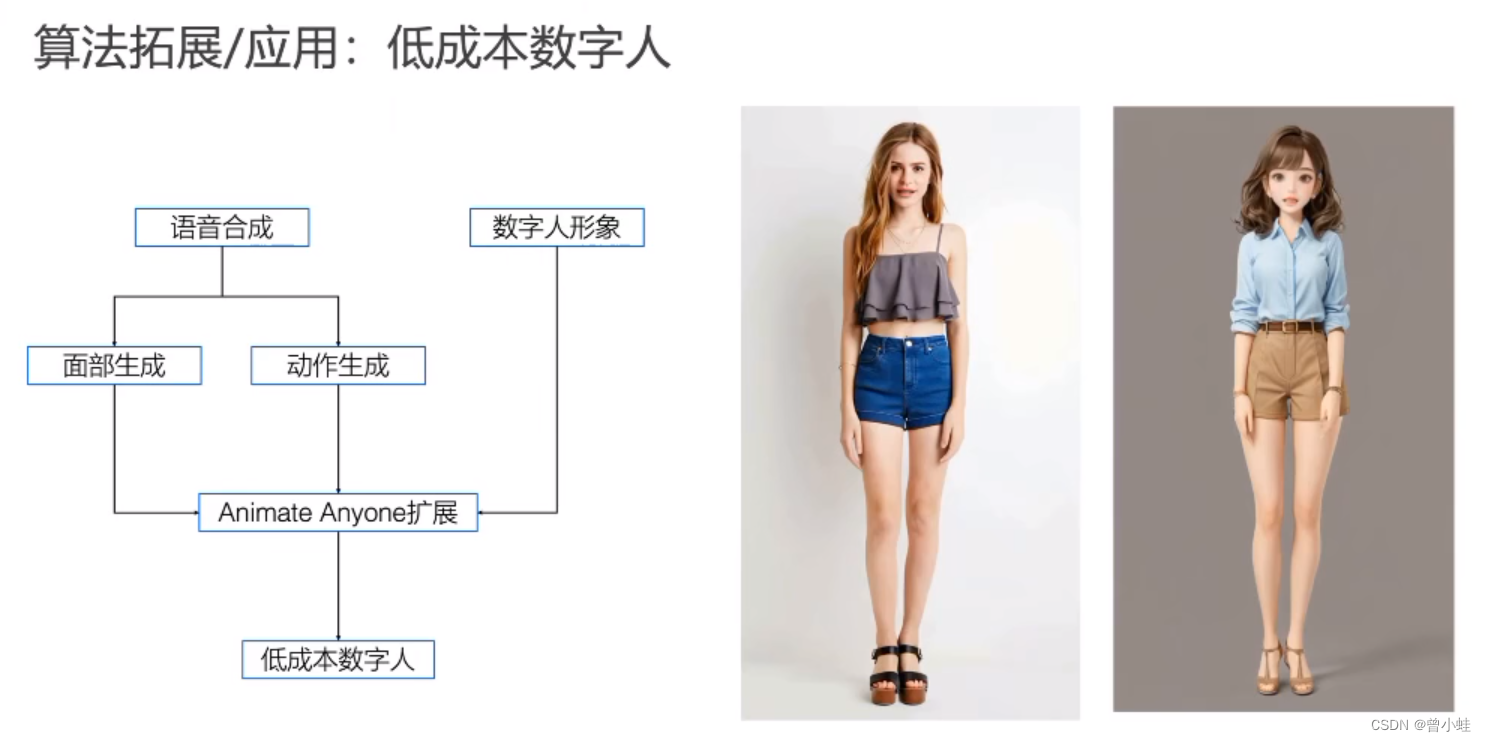
试穿+电商

数字人相关
团队建设

附录 兵马俑跳科目三

相关文章:
【论文+App试玩+图像到视频】2311.Animate-anyone:上传1张图片为任何人制作动画(用于角色动画的一致且可控的图像到视频合成)(暂未开源)
项目主页:https://humanaigc.github.io/animate-anyone/ 论文: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation 摩尔线程复现代码:https://github.com/MooreThreads/Moore-AnimateAnyone 摩尔windows一…...
【深度学习实验】TensorBoard使用教程【SCALARS、IMAGES、TIME SERIES】
文章目录 一、环境二、TensorBoard1. 使用TensorBoardXa. 安装TensorBoardXb. 使用示例 2. PyTorch内置的TensorBoard3. 启动TensorBoard服务 三、实战1. SCALARS(标量)找不同关卡1关卡2关卡3关卡4 Show data download linksIgnore outliers in chart sc…...
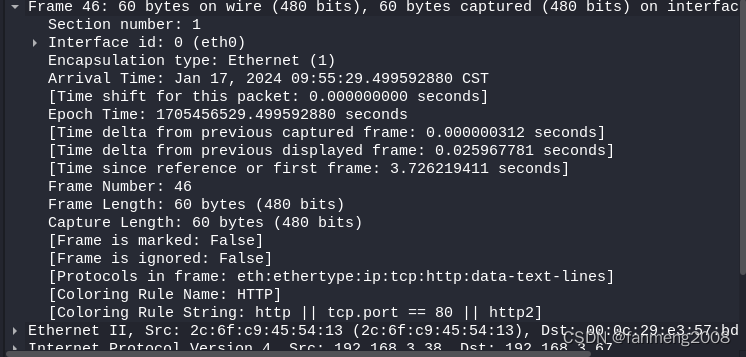
渗透测试(12)- WireShark 网络数据包分析
目录 1、WireShack 简介 2、WireShark 基本使用方法 3、 WireShack 抓包分析 3.1 Hypertext Transfer Protocol (应用层) 3.2 Transmission Control Protocol (传输层) 3.3 Internet Protocol Version 4(网络层) 3.4 Ethernet Il (链路层): 数据链路层以太网头部信息 …...
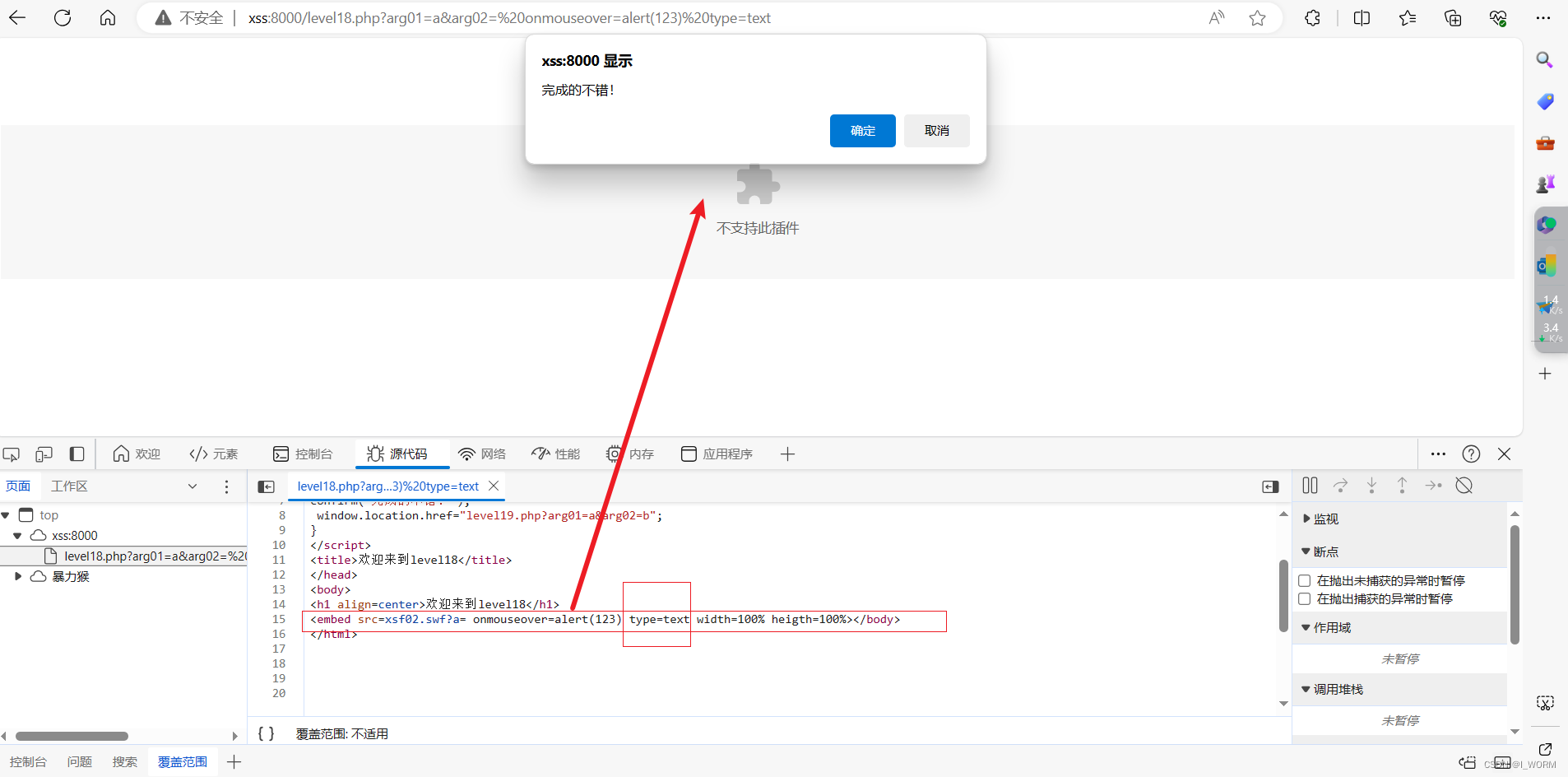
XSS_Labs靶场通关笔记
每一关的方法不唯一;可以结合源码进行分析后构造payload; 通关技巧(四步): 1.输入内容看源码变化; 2.找到内容插入点; 3.测试是否有过滤; 4.构造payload绕过 第一关 构造paylo…...

基于本地缓存制作一个分库分表的分布式ID生成器
引言: 代码在 https://gitee.com/lbmb/mb-live-app 中 【mb-live-id-generate-provider】 模块里面 如果喜欢 希望大家给给star 项目还在持续更新中。 背景介绍 项目整体架构是 基于springboot 3.0 开发 rpc 调用采用 dubbo 注册配置中心 使用 nacos 采用shardin…...

美易平台:金融市场的晴雨表与创新服务的融合
在金融市场中,利率的微妙变动往往预示着经济活动的脉动,而美国纽约联储发布的最新数据显示,上个交易日(1月25日)担保隔夜融资利率(SOFR)小幅上升至5.32%,而同期有效的联邦基金利率保…...

文旅项目包括什么?
文旅项目是指与文化和旅游相结合的项目,旨在通过提供丰富的文化体验和旅游服务来吸引游客,促进地方经济发展。 文旅项目通常包括多个方面,以下是对每块内容的详细介绍: 文化旅游景区:这类项目以展示人类文化和历史遗产…...

Pointnet++改进优化器系列:全网首发AdamW优化器 |即插即用,实现有效涨点
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入AdamW优化器,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步...

stm32 FOC 电机介绍
今年开始学习foc控制无刷电机,这几天把所学整理一下,记录一下知识内容。 前言: 为什么要学习FOC? 1.电机控制是自动化控制领域重要一环。 2.目前直流无刷电机应用越来越广泛,如无人机、机械臂、云台、仿生机器人等等。 需要什么基础&…...

【Linux】进程通信——管道
欢迎来到Cefler的博客😁 🕌博客主页:折纸花满衣 🏠个人专栏:题目解析 🌎推荐文章:【LeetCode】winter vacation training 目录 📋进程通信的目的📋管道匿名管道pipe函数创…...

3d gaussian splatting笔记(paper部分翻译)
本文为3DGS paper的部分翻译。 基于点的𝛼混合和 NeRF 风格的体积渲染本质上共享相同的图像形成模型。 具体来说,颜色 𝐶 由沿射线的体积渲染给出: 其中密度 𝜎、透射率 𝑇 和颜色 c 的样本是沿着射线以…...
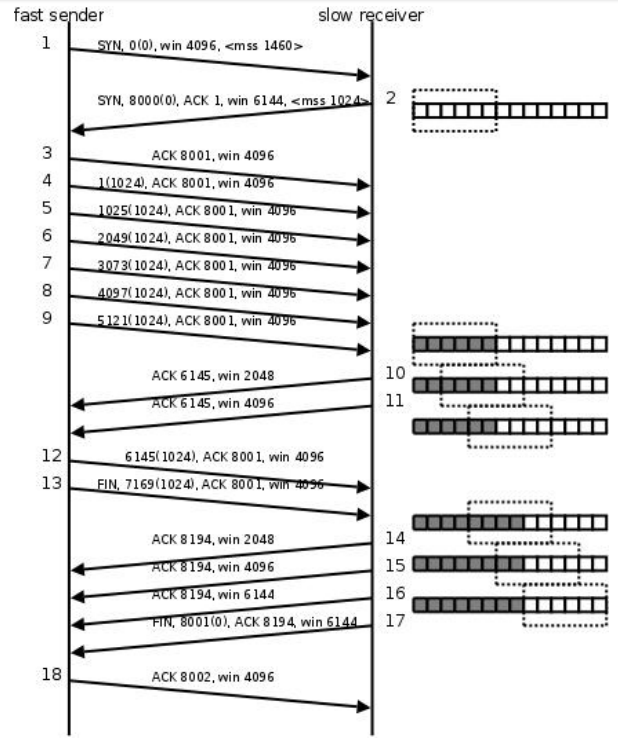
TCP 三次握手以及滑动窗口
TCP 三次握手 简介: TCP 是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的 “ 连接” ,其实是客户端和服务器的内存里保存的一份关于对方的信息,如 IP 地址、端口号等。 TCP 可以…...

Vue3 Cli5按需导入ElementPlus
1、安装环境 node:16.20.0 vue:3.2.36 vue/cli:5.0.0 element-plus:2.2.25 element-plus/icons-vue:2.0.10 unplugin-auto-import:0.16.1 // 当前环境用这个包,不然会提示各种错误 unplugin-vu…...

playwright自动化项目搭建
具备功能 关键技术: pylaywright测试库pytest单元测试框架pytest-playwright插件 非关键技术: pytest-html插件pytest-rerunfailures插件seldom 测试框架 实现功能: 元素定位与操作分离失败自动截图并保存到HTML报告失败重跑可配置不同…...

mysql字符集
一、查看字符集 //查看数据库字符集 SHOW CREATE DATABASE databasename; //查看表字符集 SHOW CREATE TABLE tablename; //查看指定表全部字段字符集 show full columns from table; 二、修改字符集 将超出utf8字符集范围的字符比如𪨧插入到utf8字符集的字…...
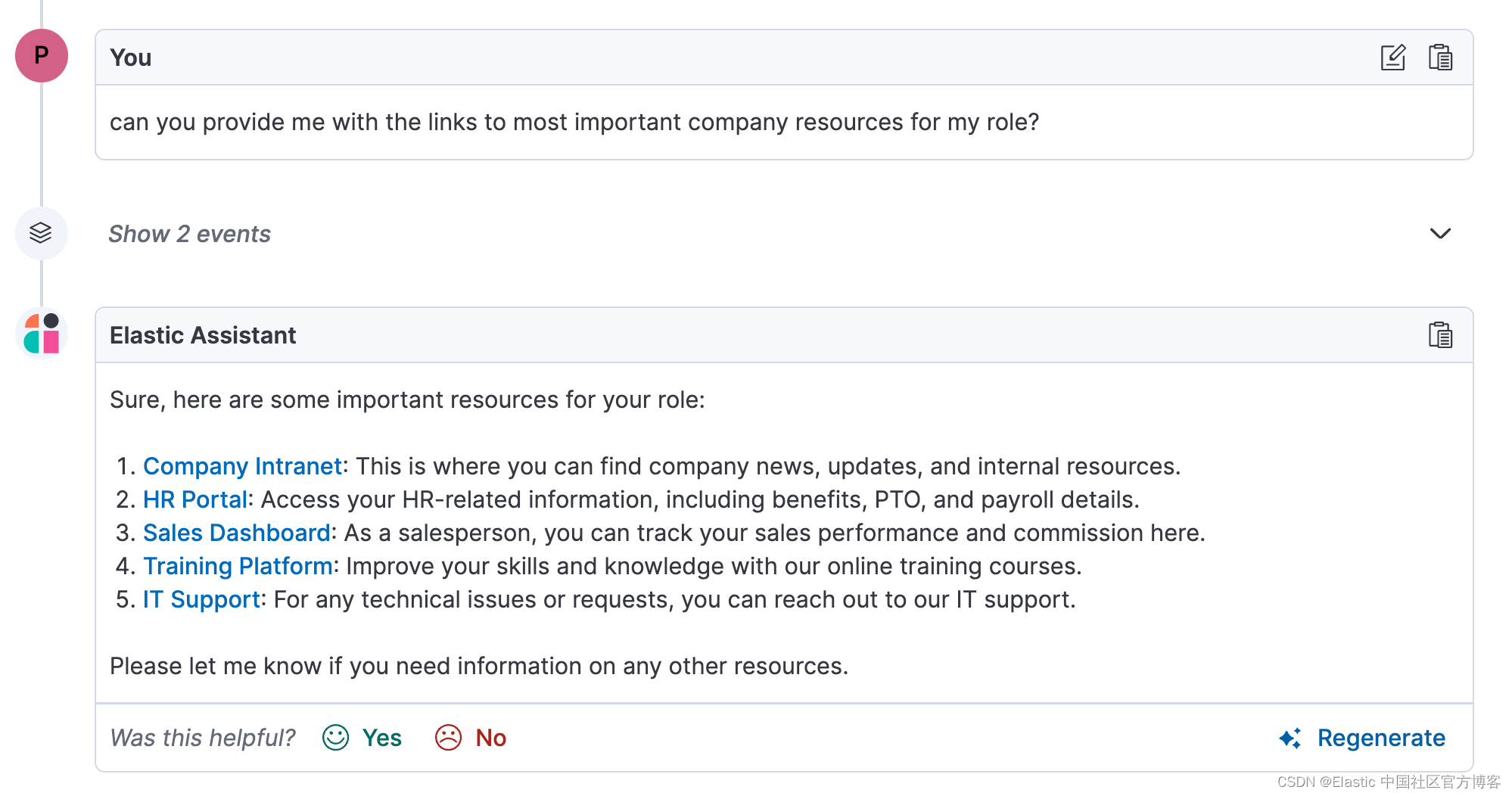
Elasticsearch:聊天机器人、人工智能和人力资源:电信公司和企业组织的成功组合
作者:来自 Elastic Jrgen Obermann, Piotr Kobziakowski 让我们来谈谈大型企业人力资源领域中一些很酷且改变游戏规则的东西:生成式 AI 和 Elastic Stack 的绝佳组合。 现在,想象一下大型电信公司的典型人力资源部门 — 他们正在处理一百万件…...

[AIGC大数据基础] Flink: 大数据流处理的未来
Flink 是一个分布式流处理引擎,它被广泛应用于大数据领域,具有高效、可扩展和容错的特性。它是由 Apache 软件基金会开发和维护的开源项目,并且在业界中受到了广泛认可和使用。 文章目录 什么是 FlinkFlink 的特点真正的流处理高性能和低延迟…...
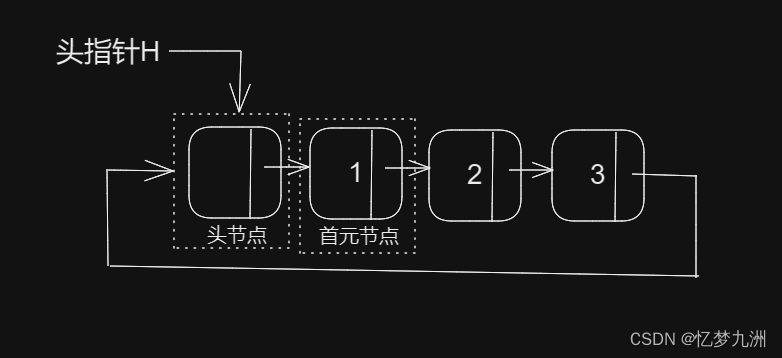
数据结构之线性表(一般的线性表)
前言 接下来就开始正式进入数据结构环节了,我们先从线性表开始。 线性表 线性表(linear list)也叫线性存储结构,即数据元素的逻辑结构为线性的数据表,它是数据结构中最简单和最常用的一种存储结构,专门存…...
uniapp安卓android离线打包本地打包整理
离线打包准备 下载Android studio 1.准备资源hbuilder 2.准备离线SDK 最新android平台SDK下载最新android平台SDK下载 3.离线打包key申请 4.直接导入HBuilder-Integrate-AS工程,直接运行simpleDemo项目即可 5.安装java 1.8 jdk-8u151-windows-x64 6.遇到这个报错报错Caus…...

vmware安装centos8-stream
VMware与CentOS8-stream的配置教程【2022-9-5】_centos stream 8-CSDN博客 启动进入后配置网络,/etc/sysconfig/network-scripts/网卡 vmware上的centos8没有网络_主机时wifi上网,centos 8 安装后无法连接网络 解决办法-CSDN博客 centos8配置网络_centos8网络配置…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...
安装与中文环境配置实战)
Halcon深度学习工具(DLT)安装与中文环境配置实战
1. Halcon DLT安装前的准备工作 第一次接触Halcon深度学习工具(DLT)时,我完全被各种专业术语搞晕了。后来才发现,只要做好前期准备,安装过程其实比想象中简单得多。首先需要确认的是你的Windows系统版本,DLT目前支持Windows 10和1…...

NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程
NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gitcode.c…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...
)
用51单片机和HC-SR04超声波模块DIY一个倒车雷达(附完整代码和立创EDA原理图)
51单片机与HC-SR04超声波模块实战:打造高精度倒车雷达系统 在汽车电子和智能硬件领域,倒车雷达作为基础安全装置,其DIY实现不仅能帮助理解超声波测距原理,更是掌握嵌入式系统开发的绝佳实践。本文将手把手教你使用经典的STC89C52单…...

PCL2启动器离线登录按钮消失?5分钟快速修复指南
PCL2启动器离线登录按钮消失?5分钟快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否遇到过PCL2启动器离线登录按钮突然消失的困扰࿱…...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...

量子最优控制中的iLQR算法实践与优化
1. 量子最优控制基础与挑战量子最优控制(Quantum Optimal Control, QOC)是现代量子计算中的核心技术,其核心目标是通过精心设计的控制脉冲序列,实现对量子系统状态演化的精确操控。在超导量子计算体系中,这一技术尤为重…...

影刀RPA跨境店群运营架构:多账号环境隔离与 Python 高并发调度系统实战
关于我一个曾经死磕底层算法、痴迷于压榨软硬件性能、满脑子分布式高可用架构的资深开发者,最后跑去给跨境工作室的“Boss”写店群底层自动化调度系统这件事。 很多以前在技术圈里混的同行,或者是看着我一路从 ImageTransPro 图像处理软件 1.0 重构做到…...

AI驱动Figma设计自动化:Claude插件实现自然语言到UI生成
1. 项目概述:当设计工具遇上AI助手最近在和一些资深UI/UX设计师朋友交流时,大家不约而同地提到了一个痛点:在Figma这类设计工具里,从概念到高保真原型的转化过程,依然充满了大量重复、机械的劳动。比如,我需…...