基于本地缓存制作一个分库分表的分布式ID生成器
引言:
代码在 https://gitee.com/lbmb/mb-live-app 中 【mb-live-id-generate-provider】 模块里面 如果喜欢 希望大家给给star 项目还在持续更新中。
背景介绍
项目整体架构是 基于springboot 3.0 开发 rpc 调用采用 dubbo
注册配置中心 使用 nacos 采用sharding-jdbc 来实现分库分表。
基于以上情况 我想生成分布式id。再根据生成的分布式id 存到不同的表中
例如 id 1000 存在 user01表 id 1001 存到 user02表,然后sharding-jdbc会根据我们
基础成长
- 可以学习到多线程、线程池的使用和设计
- 分布式id器的优化策略(预加载、类似hashmap扩容)
首先我们需要设计一张id策略表
CREATE TABLE `t_id_generate_config` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键 id',`remark` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '描述',`next_threshold` bigint DEFAULT NULL COMMENT '当前 id 所在阶段的阈\n值',`init_num` bigint DEFAULT NULL COMMENT '初始化值',`current_start` bigint DEFAULT NULL COMMENT '当前 id 所在阶段的开始\n值',`step` int DEFAULT NULL COMMENT 'id 递增区间',`is_seq` tinyint DEFAULT NULL COMMENT '是否有序(0 无序,1 有序)',`id_prefix` varchar(60) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '业务前缀码,如果没有则返回\n时不携带',`version` int NOT NULL DEFAULT '0' COMMENT '乐观锁版本号',`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时\n间',`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;INSERT INTO `t_id_generate_config` (`id`, `remark`,
`next_threshold`, `init_num`, `current_start`, `step`, `is_seq`,`id_prefix`, `version`, `create_time`, `update_time`)
VALUES
(1, '用户 id 生成策略', 10050, 10000, 10000, 50, 0,
'user_id', 0, '2023-05-23 12:38:21', '2023-05-23 23:31:45');
定义全局变量
变量解析
- localSeqIdBOMap 缓存中可分配的分布式id(有序id)
- localUnSeqIdBOMap 缓存中可分配的分布式id(无序id)
- SEQ_ID = 1; 判断是否为有序id 的操作(扩容 存取 等)
- threadPoolExecutor 移步线程池(用来异步动态扩容缓存的可分配id 池)
- semaphoreMap 信号量存放map 防止多线程环境下 多次重复触发异步扩容线程池。参考 ConcurrentHashMap 的扩容 实现(ConcurrentHashMap : )。
- UNDATE_RATE:动态扩容阀值
private static final Logger LOGGER = LoggerFactory.getLogger(IdGenerateService.class);private static Map<Integer, LocalSeqIdBO> localSeqIdBOMap = new ConcurrentHashMap<Integer, LocalSeqIdBO>();private static Map<Integer, LocalUnSeqIdBO> localUnSeqIdBOMap = new ConcurrentHashMap<Integer, LocalUnSeqIdBO>();private static final Integer SEQ_ID = 1;private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(8, 16, 3, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);thread.setName("id-generate-thread-" + ThreadLocalRandom.current().nextInt(1000));return null;}});/*** 使用Semaphore 信号量来防止多线程并发 多次刷新id段*/private static Map<Integer, Semaphore> semaphoreMap = new ConcurrentHashMap<>();/*** id段刷新优化 阈值为0.75 达到百分之75 执行异步任务创建 优化*/private static final float UNDATE_RATE = 0.75f;
有序 id 生成器
/*** 有序id生成器** @param id* @return*/@Overridepublic Long geSeqId(Integer id) {if (id == null) {LOGGER.error("[geSeqId] id is error,id is{}", id);return null;}LocalSeqIdBO localSeqIdBO = localSeqIdBOMap.get(id);if (localSeqIdBO == null) {LOGGER.error("[geSeqId] localSeqIdBO is null,id is{}", id);return null;}/*** 异步 预执行刷新id段*/this.refreshLocalSeqId(localSeqIdBO);long andIncrement = localSeqIdBO.getCurrentNum().getAndIncrement();if (andIncrement> localSeqIdBO.getNextThreshold()) {LOGGER.error("[geSeqId] id is over limit,id is{}", id);return null;}// 获取当前id 直增return andIncrement;}
代码解读 从数据库读取到对应的方案(有序id 和无序id 方案 会有当前 可用的 id段 开始值 和 结束值 以及步长等信息)
LocalSeqIdBO localSeqIdBO = localSeqIdBOMap.get(id);
预扩容:例如当前 可用id段是 1000-1500 判断 1000-1500 的id 被使用超过了 百分之75 就动态将id池 进行扩容
this.refreshLocalSeqId(localSeqIdBO);
取出当前已使用的id 最大值 并且进行+1
long andIncrement = localSeqIdBO.getCurrentNum().getAndIncrement();
// 优化逻辑 如果当前 已经用的id +1 后 超过了当前id池的最大值 则不会生成id。例: 当前id池最大是 1500 但是取出的当前已用的id 为 1500 则加一后是1501 超过了id池最大值1500 则不会生成id 继而下一次操作 会扩容id池
if (andIncrement> localSeqIdBO.getNextThreshold()) {
LOGGER.error(“[geSeqId] id is over limit,id is{}”, id);
return null;
}
异步刷新本地 id池
/*** 刷新本地有序的id段** @param localSeqIdBO*/private void refreshLocalSeqId(LocalSeqIdBO localSeqIdBO) {// 当前 id字段区间值long step = localSeqIdBO.getNextThreshold() - localSeqIdBO.getCurrentStart();/*** 使用Semaphore 信号量来防止多线程并发 多次刷新id段* 防止没扩容完成的时候过多线程进入到 if里面*/if (localSeqIdBO.getCurrentNum().get() - localSeqIdBO.getCurrentStart() > step * UNDATE_RATE) {Semaphore semaphore = semaphoreMap.get(localSeqIdBO.getId());if (semaphore == null) {LOGGER.error("semaphore is null ,id is{}", localSeqIdBO.getId());return;}boolean acquireStatus = semaphore.tryAcquire();if (acquireStatus) {// 异步进行同步id字段的操作LOGGER.info("尝试开始进行同步id段的同步操作");threadPoolExecutor.execute(new Runnable() {@Overridepublic void run() {try {IdGeneratePO idGeneratePO = mapper.selectById(localSeqIdBO.getId());tryUpdateMysqlRecord(idGeneratePO);// 释放semaphore资源} catch (Exception e) {LOGGER.error("[refreshLocalSeqId] error is {}", e);} finally {semaphoreMap.get(localSeqIdBO.getId()).release();LOGGER.info("有序id段同步完成,id is {}", localSeqIdBO.getId());}}});}}}
初次落第一批id数据到id池
spring 容器启动的时候 在初始化Bean后 会回调这个方法
//spring 启动的时候 bean 初始化的时候会回调这里@Overridepublic void afterPropertiesSet() throws Exception {List<IdGeneratePO> idGeneratePOList = mapper.selectAll();for (IdGeneratePO idGeneratePO : idGeneratePOList) {tryUpdateMysqlRecord(idGeneratePO);semaphoreMap.put(idGeneratePO.getId(), new Semaphore(1));}}
更新数据库里面的 id字段占用位置信息 并且尝试将 已更新的id 段写入到缓存
/*** 更新mysql里面的分布式id的配置信息,占用对应id段** @param idGeneratePO*/private void tryUpdateMysqlRecord(IdGeneratePO idGeneratePO) {int updateResult = mapper.updateNewIdCountAndVersion(idGeneratePO.getId(), idGeneratePO.getVersion());if (updateResult > 0) {localIdBoHandler(idGeneratePO);return;}for (int i = 0; i < 3; i++) {IdGeneratePO newIdGeneratePO = mapper.selectById(idGeneratePO.getId());updateResult = mapper.updateNewIdCountAndVersion(idGeneratePO.getId(), idGeneratePO.getVersion());if (updateResult > 0) {localIdBoHandler(idGeneratePO);
// LocalSeqIdBO localSeqIdBO = new LocalSeqIdBO();
// AtomicLong atomicLong = new AtomicLong(idGeneratePO.getCurrentStart());
// localSeqIdBO.setId(idGeneratePO.getId() );
// localSeqIdBO.setCurrentNum(atomicLong );
// localSeqIdBO.setCurrentStart(idGeneratePO.getCurrentStart() );
// localSeqIdBO.setNextThreshold(idGeneratePO.getNextThreshold() );
// localSeqIdBO.setCurrentNum(atomicLong );
// localSeqIdBOMap.put(localSeqIdBO.getId(),localSeqIdBO);return;}}throw new RuntimeException("表id字段占用失败, 竞争过于激烈 id is :" + idGeneratePO.getId());}
将更新的id段 实际落到缓存
/*** 专门处理如何将id对象放入本地缓存中** @param idGeneratePO*/private void localIdBoHandler(IdGeneratePO idGeneratePO) {long currentStart = idGeneratePO.getCurrentStart();long nextThreshold = idGeneratePO.getNextThreshold();long currentNum = currentStart;// 判断数据库取出来的id配置是有序还是无序 1 有序 非 1 无序if (idGeneratePO.getIsSeq() == SEQ_ID) {// 有序存储LocalSeqIdBO localSeqIdBO = new LocalSeqIdBO();AtomicLong atomicLong = new AtomicLong(currentStart);localSeqIdBO.setId(idGeneratePO.getId());localSeqIdBO.setCurrentStart(currentStart);localSeqIdBO.setNextThreshold(nextThreshold);localSeqIdBO.setCurrentNum(atomicLong);localSeqIdBOMap.put(localSeqIdBO.getId(), localSeqIdBO);} else {LocalUnSeqIdBO localUnSeqIdBO = new LocalUnSeqIdBO();localUnSeqIdBO.setId(idGeneratePO.getId());localUnSeqIdBO.setCurrentStart(currentStart);localUnSeqIdBO.setNextThreshold(nextThreshold);long begin = idGeneratePO.getCurrentStart();long end = idGeneratePO.getNextThreshold();ConcurrentLinkedQueue idQueue = new ConcurrentLinkedQueue();ArrayList<Long> idList = new ArrayList<>();for (long i = begin; i < end; i++) {idList.add(i);}// 无序操作将有序集合打乱Collections.shuffle(idList);idQueue.addAll(idList);localUnSeqIdBO.setIdQueue(idQueue);localUnSeqIdBOMap.put(localUnSeqIdBO.getId(), localUnSeqIdBO);}}
mapper 内容
@Mapper
public interface IdGenerateMapper extends BaseMapper<IdGeneratePO> {// @Update("update t_id_generate_config set next_threshold = next_threshold + step,current_start=current_start + step , version = version + 1 where id = #{id} and version = #{version}")
// int updateNewIdCountAndVersion(@Param("id") int id, @Param("version") int version);@Update("update t_id_generate_config set next_threshold=next_threshold+step," +"current_start=current_start+step,version=version+1 where id =#{id} and version=#{version}")int updateNewIdCountAndVersion(@Param("id") int id, @Param("version") int version);@Select("select * from t_id_generate_config")List<IdGeneratePO> selectAll();
}
相关文章:

基于本地缓存制作一个分库分表的分布式ID生成器
引言: 代码在 https://gitee.com/lbmb/mb-live-app 中 【mb-live-id-generate-provider】 模块里面 如果喜欢 希望大家给给star 项目还在持续更新中。 背景介绍 项目整体架构是 基于springboot 3.0 开发 rpc 调用采用 dubbo 注册配置中心 使用 nacos 采用shardin…...

美易平台:金融市场的晴雨表与创新服务的融合
在金融市场中,利率的微妙变动往往预示着经济活动的脉动,而美国纽约联储发布的最新数据显示,上个交易日(1月25日)担保隔夜融资利率(SOFR)小幅上升至5.32%,而同期有效的联邦基金利率保…...

文旅项目包括什么?
文旅项目是指与文化和旅游相结合的项目,旨在通过提供丰富的文化体验和旅游服务来吸引游客,促进地方经济发展。 文旅项目通常包括多个方面,以下是对每块内容的详细介绍: 文化旅游景区:这类项目以展示人类文化和历史遗产…...

Pointnet++改进优化器系列:全网首发AdamW优化器 |即插即用,实现有效涨点
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入AdamW优化器,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步...

stm32 FOC 电机介绍
今年开始学习foc控制无刷电机,这几天把所学整理一下,记录一下知识内容。 前言: 为什么要学习FOC? 1.电机控制是自动化控制领域重要一环。 2.目前直流无刷电机应用越来越广泛,如无人机、机械臂、云台、仿生机器人等等。 需要什么基础&…...

【Linux】进程通信——管道
欢迎来到Cefler的博客😁 🕌博客主页:折纸花满衣 🏠个人专栏:题目解析 🌎推荐文章:【LeetCode】winter vacation training 目录 📋进程通信的目的📋管道匿名管道pipe函数创…...

3d gaussian splatting笔记(paper部分翻译)
本文为3DGS paper的部分翻译。 基于点的𝛼混合和 NeRF 风格的体积渲染本质上共享相同的图像形成模型。 具体来说,颜色 𝐶 由沿射线的体积渲染给出: 其中密度 𝜎、透射率 𝑇 和颜色 c 的样本是沿着射线以…...
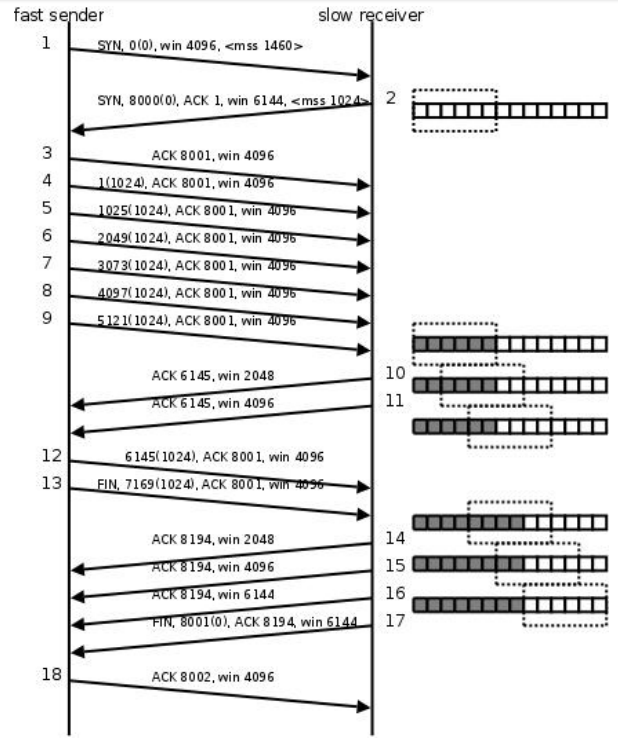
TCP 三次握手以及滑动窗口
TCP 三次握手 简介: TCP 是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的 “ 连接” ,其实是客户端和服务器的内存里保存的一份关于对方的信息,如 IP 地址、端口号等。 TCP 可以…...

Vue3 Cli5按需导入ElementPlus
1、安装环境 node:16.20.0 vue:3.2.36 vue/cli:5.0.0 element-plus:2.2.25 element-plus/icons-vue:2.0.10 unplugin-auto-import:0.16.1 // 当前环境用这个包,不然会提示各种错误 unplugin-vu…...

playwright自动化项目搭建
具备功能 关键技术: pylaywright测试库pytest单元测试框架pytest-playwright插件 非关键技术: pytest-html插件pytest-rerunfailures插件seldom 测试框架 实现功能: 元素定位与操作分离失败自动截图并保存到HTML报告失败重跑可配置不同…...

mysql字符集
一、查看字符集 //查看数据库字符集 SHOW CREATE DATABASE databasename; //查看表字符集 SHOW CREATE TABLE tablename; //查看指定表全部字段字符集 show full columns from table; 二、修改字符集 将超出utf8字符集范围的字符比如𪨧插入到utf8字符集的字…...
Elasticsearch:聊天机器人、人工智能和人力资源:电信公司和企业组织的成功组合
作者:来自 Elastic Jrgen Obermann, Piotr Kobziakowski 让我们来谈谈大型企业人力资源领域中一些很酷且改变游戏规则的东西:生成式 AI 和 Elastic Stack 的绝佳组合。 现在,想象一下大型电信公司的典型人力资源部门 — 他们正在处理一百万件…...

[AIGC大数据基础] Flink: 大数据流处理的未来
Flink 是一个分布式流处理引擎,它被广泛应用于大数据领域,具有高效、可扩展和容错的特性。它是由 Apache 软件基金会开发和维护的开源项目,并且在业界中受到了广泛认可和使用。 文章目录 什么是 FlinkFlink 的特点真正的流处理高性能和低延迟…...
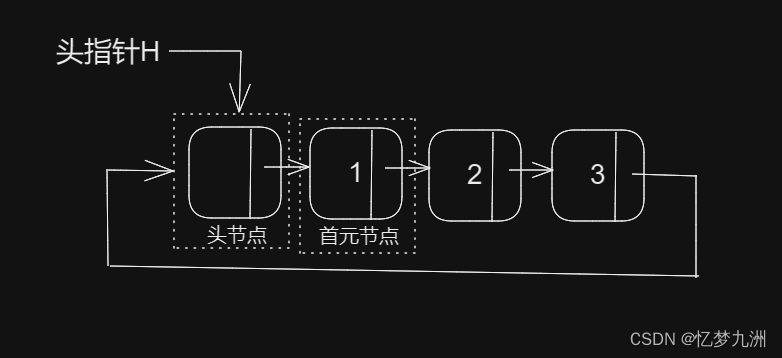
数据结构之线性表(一般的线性表)
前言 接下来就开始正式进入数据结构环节了,我们先从线性表开始。 线性表 线性表(linear list)也叫线性存储结构,即数据元素的逻辑结构为线性的数据表,它是数据结构中最简单和最常用的一种存储结构,专门存…...
uniapp安卓android离线打包本地打包整理
离线打包准备 下载Android studio 1.准备资源hbuilder 2.准备离线SDK 最新android平台SDK下载最新android平台SDK下载 3.离线打包key申请 4.直接导入HBuilder-Integrate-AS工程,直接运行simpleDemo项目即可 5.安装java 1.8 jdk-8u151-windows-x64 6.遇到这个报错报错Caus…...

vmware安装centos8-stream
VMware与CentOS8-stream的配置教程【2022-9-5】_centos stream 8-CSDN博客 启动进入后配置网络,/etc/sysconfig/network-scripts/网卡 vmware上的centos8没有网络_主机时wifi上网,centos 8 安装后无法连接网络 解决办法-CSDN博客 centos8配置网络_centos8网络配置…...

使用HttpServletRequestWrapper解决web项目request数据流无法重复读取的问题
在做web项目开发时,我们有时候需要做一些前置的拦截判断处理,比如非法参数校验,防攻击拦截,统一日志处理等,而请求参数如果是form表单提交还好处理;对于json这种输入流的数据就会有问题,统一处理…...
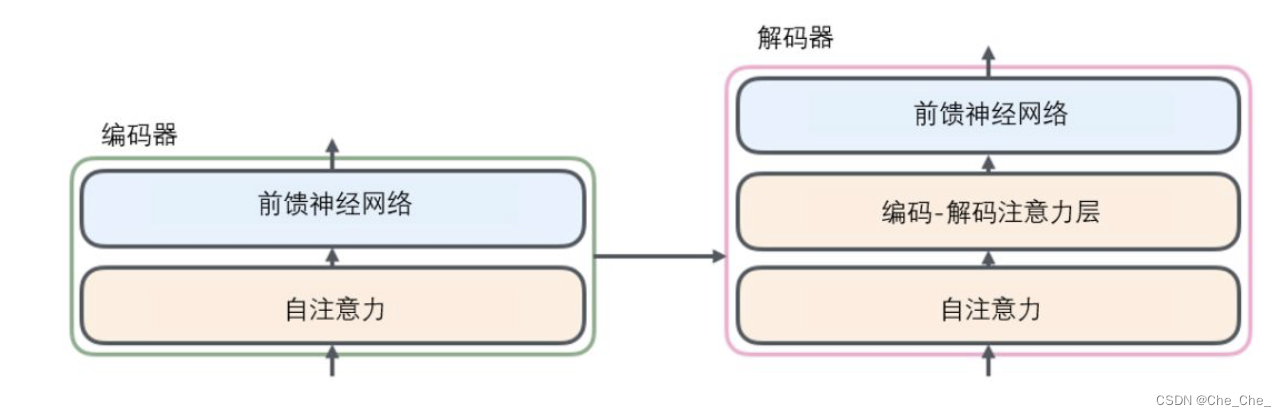
从CNN ,LSTM 到Transformer的综述
前情提要:文本大量参照了以下的博客,本文创作的初衷是为了分享博主自己的学习和理解。对于刚开始接触NLP的同学来说,可以结合唐宇迪老师的B站视频【【NLP精华版教程】强推!不愧是的最完整的NLP教程和学习路线图从原理构成开始学&a…...

Git学习笔记:1 基础命令详解
文章目录 Git基础命令详解: Git基础命令详解: git commit 用法:git commit -m "commit message"功能:将暂存区(stage)中的所有更改提交到本地仓库的当前分支,同时提供一个简短的提交信…...

【服务器】安装宝塔面板
目录 🌺【前言】 🌼【前提】连接服务器 🌷方式一 使用工具登录服务器如Xshell 🌷方式二 阿里云直接连接 🌼 1. 安装宝塔 🌷获取安装脚本 方式一 使用下面提供的脚本安装 方式二 使用官网提供的脚本…...

Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南
Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否经常因为…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

基于Readability算法的网页内容提取服务:从原理到工程实践
1. 项目概述:一个为现代阅读而生的开源工具 最近在折腾个人知识库和稍后读系统时,我一直在找一个能完美解决“网页内容净化与结构化”痛点的工具。市面上的方案要么太重,要么太简陋,直到我遇到了 Cat-tj/web-reader 。这不仅仅是…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

3D打印乐高手机支架:低成本打造高清视频会议摄像头方案
1. 项目概述与核心思路如果你和我一样,对视频会议、直播时笔记本自带摄像头那“感人”的画质感到无奈,同时又觉得单独购买一个高品质的网络摄像头是一笔不小的开销,那么这个项目绝对值得你花上一个周末的时间来折腾。它的核心思路非常巧妙&am…...

Godot游戏集成Discord状态:RPC插件原理与实战指南
1. 项目概述:在Godot引擎中点亮你的Discord状态 如果你是一名独立游戏开发者,或者正在用Godot引擎捣鼓一些有趣的个人项目,你可能会想让你的朋友或社区成员知道你现在正在“玩”什么。不是通过截图发到社交媒体,而是更实时、更优…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

轻量级服务器监控面板:从原理到部署实战
1. 项目概述:一个开源监控面板的诞生最近在折腾服务器和容器化应用,发现一个挺普遍的需求:当你手头有几台服务器,上面跑着几个Docker容器,或者一些自己写的服务,你总想知道它们现在“活”得怎么样。CPU是不…...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...