使用scyllaDb 或者cassandra存储聊天记录
一、使用scyllaDb的原因
目前开源的聊天软件主要还是使用mysql存储数据,数据量大的时候比较麻烦;
我打算使用scyllaDB存储用户的聊天记录,主要考虑的优点是:
1)方便后期线性扩展服务器;
2)partition更方便,clustering 可以将一组数据放在一起,加载更快;
我的后端服务使用go来写,
使用的库为https://github.com/scylladb/gocqlx/,目前版本为2.8
go get -u github.com/scylladb/gocqlx/v2二、测试代码
1. 连接数据库
cluster := gocql.NewCluster("127.0.0.1:9042")cluster.Keyspace = "chatdata"cluster.Authenticator = gocql.PasswordAuthenticator{Username: "cassandra",Password: "cassandra",}session, err := cluster.CreateSession()if err != nil {fmt.Println("创建会话时发生错误:", err)return}defer session.Close()sessionx, err := gocqlx.WrapSession(session, nil)if err != nil {}defer sessionx.Close()我是测试的机器,只有一个节点,后续在数据一致性要求也都写一个节点;
2. 定义数据结构
P2P的聊天,使用如下表:
CREATE TABLE pchat (pk int, // 分区uid1 bigint, // 用户自己,P2P时写扩散,每个用户存储一份数据uid2 bigint, // 对方id bigint, // 消息全局唯一ID,服务器分配usid bigint, // 发送方的消息唯一标记tm timestamp, // 时间戳tm1 timestamp, // 接收tm2 timestamp, // 已读draf text, // 数据io boolean, // 收,发del boolean, // 删除标记t smallint, // 消息类型PRIMARY KEY (pk, uid1, tm, id)) 在 Cassandra 中,PRIMARY KEY 的定义影响了数据如何进行分区(Partitioning)和在分区内如何进行排序(Clustering)。对于表定义 PRIMARY KEY (pk, uid1, tm, id),它的影响如下:
-
分区键 (pk): 数据将按照
pk的值进行分区。相同pk的数据会被存储在同一分区中。 -
聚簇键 (uid1,tm, id): 在同一分区内,数据将按照
(uid1, tm, id)进行排序。这意味着相同pk的分区内的数据将按照uid1的值进行子分区,然后在每个子分区内按照 tm,id的值进行排序。
简单来说,数据会先按照 pk 进行分区,然后在每个分区内,按照 (uid1, tm, id) 进行排序。这样的设计允许你在查询时方便地按照 pk、uid1 和tm, id 进行范围查询。
- 一对一的聊天,都是2个用户,使用写扩散方式每个用户1份数据,这样的的好处是,使用用户ID聚簇,可以提高加载速度。并且减少数据的加载次数,具体在用户的会话区分上,可以在客户端一侧,执行本地的SQLITE存储。
- 对比tinode的策略,它是按照每个会话做一个逻辑,需要管理当前所有的会话,逐个加载或者订阅,而且在测试过程中发现BUG,当如同微信一样删除了某个会话,等于拉了黑名单,无法后续会话了,这个不符合我们的习惯。
- 对于群组聊天,可以使用读扩散的方式,因为写扩散毕竟太占用系统资源了;按照组ID来聚簇;
相关代码如下:
// 定义表的元数据
var pchatMetadata = table.Metadata{Name: "pchat",Columns: []string{"pk", "uid1", "uid2", "id", "usid", "tm", "tm1", "tm2", "draf", "io", "del", "t"},PartKey: []string{"pk"},SortKey: []string{"uid1", "id"},
}// 创建表对象
var pchatTable = table.New(pchatMetadata)// 定义数据结构
type PchatData struct {Pk int `db:"pk"`Uid1 int `db:"uid1"`Uid2 int `db:"uid2"`Id int `db:"id"`Usid int `db:"usid"`Tm time.Time `db:"tm"`Tm1 time.Time `db:"tm1"`Tm2 time.Time `db:"tm2"`Draf string `db:"draf"`Io bool `db:"io"`Del bool `db:"del"`T int `db:"t"`
}func PchatDataToSlice(data PchatData) []interface{} {return []interface{}{data.Pk,data.Uid1,data.Uid2,data.Id,data.Usid,data.Tm,data.Tm1,data.Tm2,data.Draf,data.Io,data.Del,data.T,}
}3. 单条数据写入
func insertData(session *gocqlx.Session) error {data := PchatData{Pk: 1,Uid1: 123456,Uid2: 789012,Id: 987654,Usid: 654321,Tm: time.Now(),Tm1: time.UnixMilli(0),Tm2: time.UnixMilli(0),Draf: "你的草稿内容",Io: true,Del: false,T: 42,}// Insert using query builder.insertChat := qb.Insert("chatdata.pchat").Columns(pchatMetadata.Columns...).Query(*session).Consistency(gocql.One)insertChat.BindStruct(data)if err := insertChat.ExecRelease(); err != nil {fmt.Println(err)return err}return nil
}4. 批量插入
func insertBatch(session *gocqlx.Session) error {// 创建 Batchbatch := session.Session.NewBatch(gocql.LoggedBatch)// 创建 Batch//batch := gocql.NewBatch(gocql.LoggedBatch)batch.Cons = gocql.LocalOneindex := 1// 构建多个插入语句for i := index; i < index+1000; i++ {data := PchatData{Pk: 1,Uid1: 1001,Uid2: 1005,Id: i,Usid: i,Tm: time.Now(),Tm1: time.UnixMilli(0),Tm2: time.UnixMilli(0),Draf: "你的草稿内容",Io: true,Del: false,T: 1,}insertChatQry := qb.Insert("chatdata.pchat").Columns(pchatMetadata.Columns...).Query(*session).Consistency(gocql.One)batch.Query(insertChatQry.Statement(),PchatDataToSlice(data)...)}if err := session.ExecuteBatch(batch); err != nil {return err}return nil
}挺快的,我远程插入云主机,1000条数据,使用了50毫秒左右;
5. 查询所有
这里就是一个测试,真正使用中,不会这么用
func queryData(session *gocqlx.Session) error {var dataList []PchatDataq := qb.Select("chatdata.pchat").Columns(pchatMetadata.Columns...).Query(*session).Consistency(gocql.One)if err := q.Select(&dataList); err != nil {return err}//for _, c := range dataList {// fmt.Printf("%+v \n", c)//}for _, d := range dataList {fmt.Printf("pk: %d, uid1: %d, uid2: %d, id: %d, usid: %d, tm: %v, tm1: %v, tm2: %v, draf: %s, io: %t, del: %t, t: %d\n",d.Pk, d.Uid1, d.Uid2, d.Id, d.Usid, d.Tm, d.Tm1, d.Tm2, d.Draf, d.Io, d.Del, d.T)}return nil
}6. 游标与分页
库内部提供了一些分页机制,但是我总觉得似乎不是我想要的;测试发现比较慢,目前没深入去研究内部机制:
func queryDataByPage(session *gocqlx.Session) error {var pageSize = 10//chatTable := table.New(pchatMetadata)builder := qb.Select("chatdata.pchat").Columns(pchatMetadata.Columns...)builder.Where(qb.Eq("uid1"))builder.AllowFiltering()q := builder.Query(*session)defer q.Release()q.PageSize(pageSize)q.Consistency(gocql.One)q.Bind(1001)getUserChatFunc := func(userID int64, page []byte) (chats []PchatData, nextPage []byte, err error) {if len(page) > 0 {q.PageState(page)}iter := q.Iter()return chats, iter.PageState(), iter.Select(&chats)}var (dataList []PchatDatanextPage []byteerr error)for i := 1; ; i++ {dataList, nextPage, err = getUserChatFunc(1001, nextPage)if err != nil {fmt.Println(err)return err}fmt.Printf("Page %d: \n", i)for _, d := range dataList {//fmt.Printf("pk: %d, uid1: %d, uid2: %d, id: %d, usid: %d, tm: %v, tm1: %v, tm2: %v, draf: %s, io: %t, del: %t, t: %d\n",// d.Pk, d.Uid1, d.Uid2, d.Id, d.Usid, d.Tm, d.Tm1, d.Tm2, d.Draf, d.Io, d.Del, d.T)fmt.Printf("pk: %d, uid1: %d, uid2: %d, id: %d \n", d.Pk, d.Uid1, d.Uid2, d.Id)}if len(nextPage) == 0 {break}}return nil
}7. 按用户与id号来加载
我设想的用法是,既然按照user id 聚簇了,支持多个客户端使用时,某个客户端初次加载(冷加载),可以加载最近的部分,然后根据需要在根据条件加载;持续更新的用户(热加载)首先是考虑从redis中加载,已经落库的部分再根据时间段加载;
这里测试的是,从某个ID=900的条目之后,加载10条
func queryDataByIdPage(session *gocqlx.Session) error {var pageSize uint = 10//chatTable := table.New(pchatMetadata)builder := qb.Select("chatdata.pchat").Columns(pchatMetadata.Columns...)builder.Where(qb.Eq("uid1"), qb.Gt("id"))builder.AllowFiltering()builder.Limit(pageSize)q := builder.Query(*session)defer q.Release()q.Consistency(gocql.One)q.Bind(1002, 900)var dataList []PchatDataerr := q.Select(&dataList)if err != nil {fmt.Println(err)return err}fmt.Printf("size= %d: \n", len(dataList))for _, d := range dataList {//fmt.Printf("pk: %d, uid1: %d, uid2: %d, id: %d, usid: %d, tm: %v, tm1: %v, tm2: %v, draf: %s, io: %t, del: %t, t: %d\n",// d.Pk, d.Uid1, d.Uid2, d.Id, d.Usid, d.Tm, d.Tm1, d.Tm2, d.Draf, d.Io, d.Del, d.T)fmt.Printf("pk: %d, uid1: %d, uid2: %d, id: %d tm: %v \n", d.Pk, d.Uid1, d.Uid2, d.Id, d.Tm)}return nil
}8. 按照时间范围来找
func string2timeLoc(dateString string) (time.Time, error) {// 设置东八区(中国标准时间)的地理位置loc, err := time.LoadLocation("Asia/Shanghai")if err != nil {fmt.Println("加载地理位置错误:", err)return time.Now(), err}// 使用地理位置信息进行日期解析parsedTime, err := time.ParseInLocation("2006-01-02 15:04:05", dateString, loc)if err != nil {fmt.Println("日期解析错误:", err)return time.Now(), err}return parsedTime, nil
}
func queryDataBytmPage(session *gocqlx.Session) error {//var pageSize uint = 10//chatTable := table.New(pchatMetadata)builder := qb.Select("chatdata.pchat").Columns(pchatMetadata.Columns...)builder.Where(qb.Eq("uid1"), qb.GtOrEq("tm"), qb.LtOrEq("tm"))builder.AllowFiltering()//builder.Limit(pageSize)q := builder.Query(*session)defer q.Release()q.Consistency(gocql.One)tm1, _ := string2timeLoc("2024-01-27 13:24:00")tm2, _ := string2timeLoc("2024-01-27 13:25:56")q.Bind(1001, tm1, tm2)var dataList []PchatDataerr := q.Select(&dataList)if err != nil {fmt.Println(err)return err}fmt.Printf("size= %d: \n", len(dataList))for _, d := range dataList {//fmt.Printf("pk: %d, uid1: %d, uid2: %d, id: %d, usid: %d, tm: %v, tm1: %v, tm2: %v, draf: %s, io: %t, del: %t, t: %d\n",// d.Pk, d.Uid1, d.Uid2, d.Id, d.Usid, d.Tm, d.Tm1, d.Tm2, d.Draf, d.Io, d.Del, d.T)fmt.Printf("pk: %d, uid1: %d, uid2: %d, id: %d tm: %v \n", d.Pk, d.Uid1, d.Uid2, d.Id, d.Tm)}return nil
}9. 倒序
这个库的说明并不详细,readme.md还是过时的,chatgtp给的信息也是错误很多,目前根据测试发现,在设置排序方式时:
在 Cassandra 中,ORDER BY 子句需要按照聚簇键的声明顺序指定。在表定义中,聚簇键是 (uid1, tm, id),所以需要按照这个顺序指定 ORDER BY。
在代码中,需要按照以下方式指定 ORDER BY:
builder := qb.Select("chatdata.pchat").Columns(pchatMetadata.Columns...)builder.Where(qb.Eq("pk"), qb.Eq("uid1"), qb.GtOrEq("tm"), qb.LtOrEq("tm"))builder.OrderBy("uid1", qb.DESC)//builder.OrderBy("tm", qb.DESC)//builder.OrderBy("id", qb.DESC)// 写一个就够了builder.AllowFiltering()//builder.Limit(pageSize)q := builder.Query(*session)defer q.Release()q.Consistency(gocql.One)tm1, _ := string2timeLoc("2024-01-27 13:24:00")tm2, _ := string2timeLoc("2024-01-27 13:25:56")q.Bind(1, 1001, tm1, tm2)其中,pk 作为分区键,不能排序,而聚簇的键需要按照顺序指定,其中不能混!要么都是升序,要么都是降序,否则执行时候报错“Unsupported order by relation”。
相关文章:

使用scyllaDb 或者cassandra存储聊天记录
一、使用scyllaDb的原因 目前开源的聊天软件主要还是使用mysql存储数据,数据量大的时候比较麻烦; 我打算使用scyllaDB存储用户的聊天记录,主要考虑的优点是: 1)方便后期线性扩展服务器; 2)p…...
Visual Studio如何修改成英文版
1、打开 Visual Studio Installer 2、点击修改 3、找到语言包,选择需要的语言包,而后点击修改 4、等待下载 5、 安装完成后启动Visual Studio 6、在工具-->选项-->环境-->区域设置-->English并确定 7、重启 Visual Studio,配置…...
gin中使用swagger生成接口文档
想要使用gin-swagger为你的代码自动生成接口文档,一般需要下面三个步骤: 按照swagger要求给接口代码添加声明式注释,具体参照声明式注释格式。使用swag工具扫描代码自动生成API接口文档数据使用gin-swagger渲染在线接口文档页面 第一步&…...
最新AI创作系统ChatGPT网站系统源码,Midjourney绘画V6 ALPHA绘画模型,ChatFile文档对话总结+DALL-E3文生图
一、前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…...

解析dapp:从底层区块链看DApp的脆弱性和挑战
每天五分钟讲解一个互联网只是,大家好我是啊浩说模式Zeropan_HH 在Web3时代,去中心化应用程序(DApps)已成为数字经济的重要组成部分。它们的同生性,即与底层区块链网络紧密相连、共存亡的特性,为DApps带来…...

机器学习整理
绪论 什么是机器学习? 机器学习研究能够从经验中自动提升自身性能的计算机算法。 机器学习经历了哪几个阶段? 推理期:赋予机器逻辑推理能力 知识期:使机器拥有知识 学习期:让机器自己学习 什么是有监督学习和无监…...
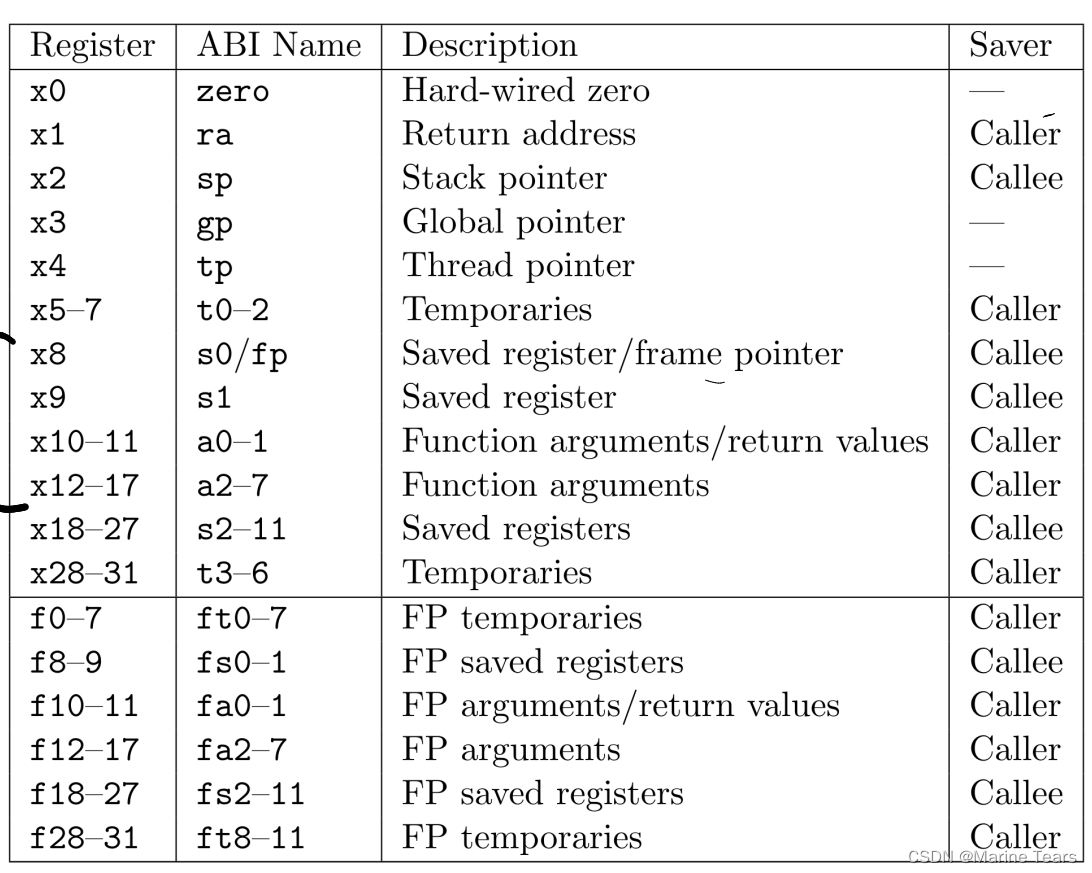
RISC-V常用汇编指令
RISC-V寄存器表: RISC-V和常用的x86汇编语言存在许多的不同之处,下面将列出其中部分指令作用: 指令语法描述addiaddi rd,rs1,imm将寄存器rs1的值与立即数imm相加并存入寄存器rdldld t0, 0(t1)将t1的值加上0,将这个值作为地址,取…...
第二篇:数据结构与算法-链表
概念 链表是线性表的链式存储方式,逻辑上相邻的数据在计算机内的存储位置不必须相邻, 可以给每个元素附加一个指针域,指向下一个元素的存储位 置。 每个结点包含两个域:数据域和指针域,指针域存储下一个结点的地址&…...

低代码配置-小程序配置
数据结构 {"data": {"layout": {"api":{"pageApi":{//api详情}},"config":{"title":"页面标题",},"listLayout": {"fields": [{"componentCode": "grid…...

第十八讲_HarmonyOS应用开发实战(实现电商首页)
HarmonyOS应用开发实战(实现电商首页) 1. 项目涉及知识点罗列2. 项目目录结构介绍3. 最终的效果图4. 部分源码展示 1. 项目涉及知识点罗列 掌握HUAWEI DevEco Studio开发工具掌握创建HarmonyOS应用工程掌握ArkUI自定义组件掌握Entry、Component、Builde…...

OJAC近屿智能张立赛博士揭秘GPT Store:技术创新、商业模式与未来趋势
Look!👀我们的大模型商业化落地产品📖更多AI资讯请👉🏾关注Free三天集训营助教在线为您火热答疑👩🏼🏫 亲爱的伙伴们: 1月31日晚上8:30,由哈尔滨工业大学的…...

Java接收curl发出的中文请求无法解析
最近做项目遇到了这种情况,Java接收curl发出的中文请求无法解析,英文请求一切正常,中文请求则对方服务器无法解析,可以猜测是中文导致的编码问题,但是奇怪的是,本地输出json也没有乱码,编解码正…...

Java设计模式-外观模式(11)
大家好,我是馆长!今天开始我们讲的是结构型模式中的外观模式。老规矩,讲解之前再次熟悉下结构型模式包含:代理模式、适配器模式、桥接模式、装饰器模式、外观模式、享元模式、组合模式,共7种设计模式。。 外观模式(Decorator Pattern) 定义 外观(Facade)模式一种通…...
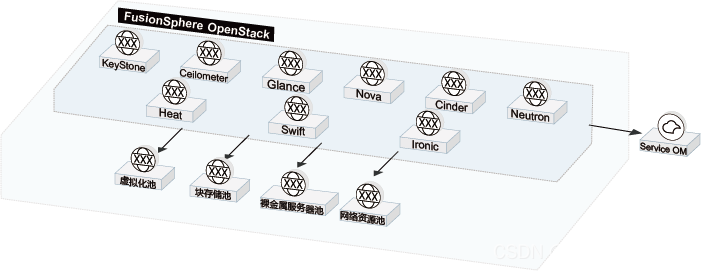
HCS-华为云Stack-FusionSphere
HCS-华为云Stack-FusionSphere FusionSphere是华为面向多行业客户推出的云操作系统解决方案。 FusionSphere基于开放的OpenStack架构,并针对企业云计算数据中心场景进行设计和优化,提供了强大的虚拟化功能和资源池管理能力、丰富的云基础服务组件和工具…...

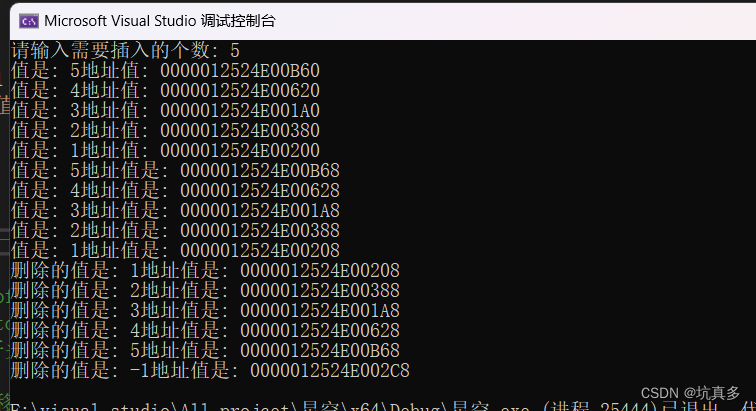
C++类模板实现顺序表SeqList
main函数 #include<iostream> #include<stdlib.h> #include"SeqList.cpp"using namespace std;typedef int ElementType; int main(void) {SeqList< ElementType, 10> SeqList(1);cout << SeqList.ListLength() << endl;bool result;…...
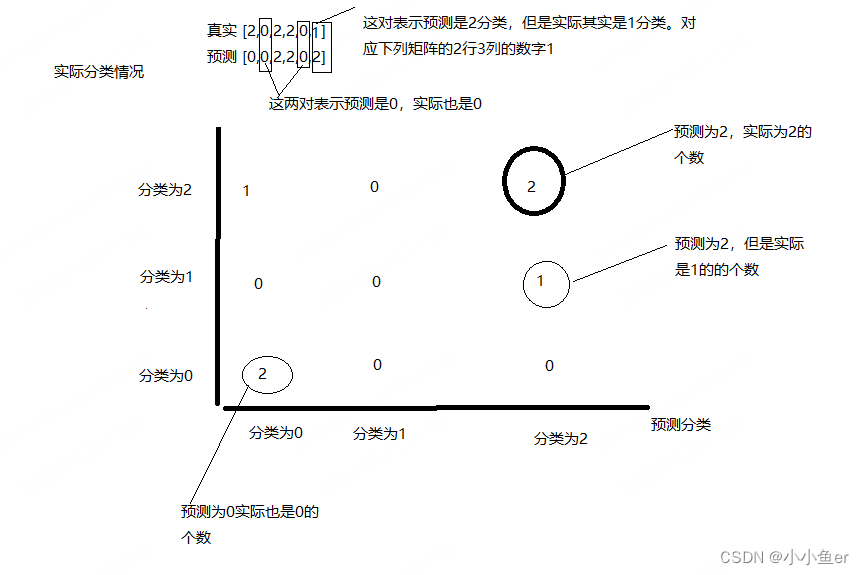
sklearn 学习-混淆矩阵 Confusion matrix
混淆矩阵Confusion matrix:也称为误差矩阵,通过计算得出矩阵的结果用来表示分类器的精度。其每一列代表预测值,每一行代表的是实际的类别。 from sklearn.metrics import confusion_matrixy_true [2, 0, 2, 2, 0, 1] y_pred [0, 0, 2, 2, 0…...
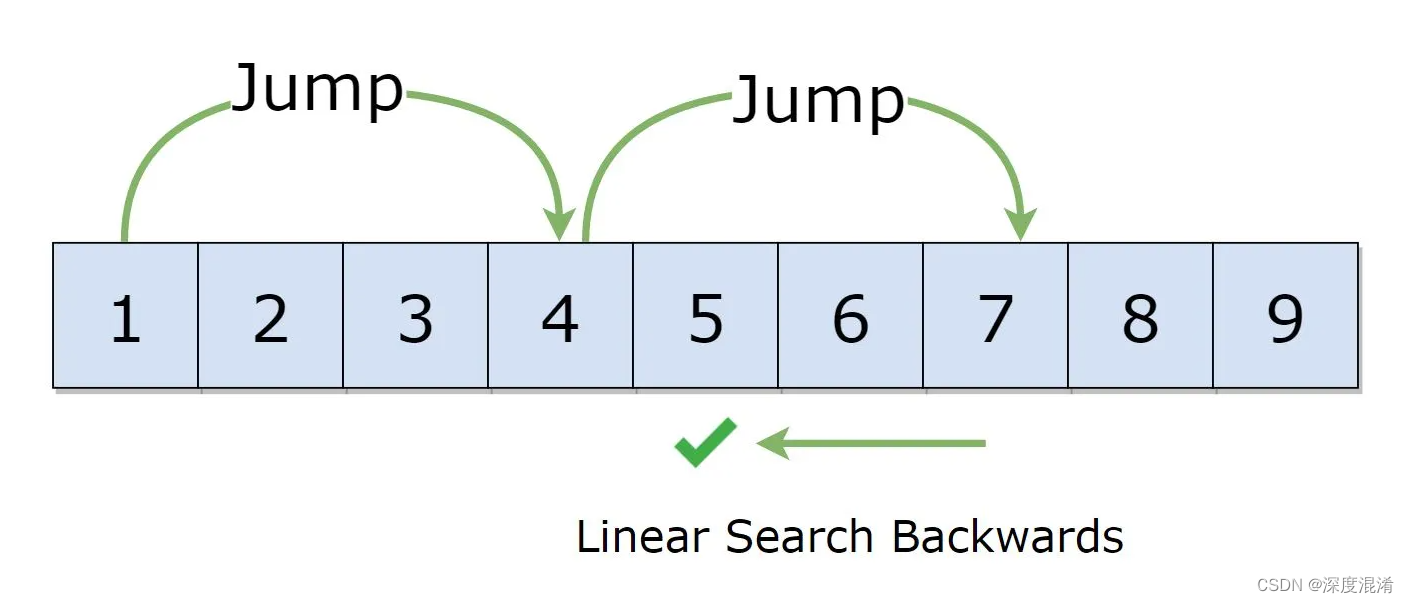
C#,数据检索算法之跳跃搜索(Jump Search)的源代码
数据检索算法是指从数据集合(数组、表、哈希表等)中检索指定的数据项。 数据检索算法是所有算法的基础算法之一。 本文提供跳跃搜索的源代码。 1 文本格式 using System; namespace Legalsoft.Truffer.Algorithm { public static class ArraySe…...
——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH)
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH-CSDN博客 1.SearchType ES的搜索类型 有一个类SearchType(如下图示),关于该类的描述: Search type repre…...
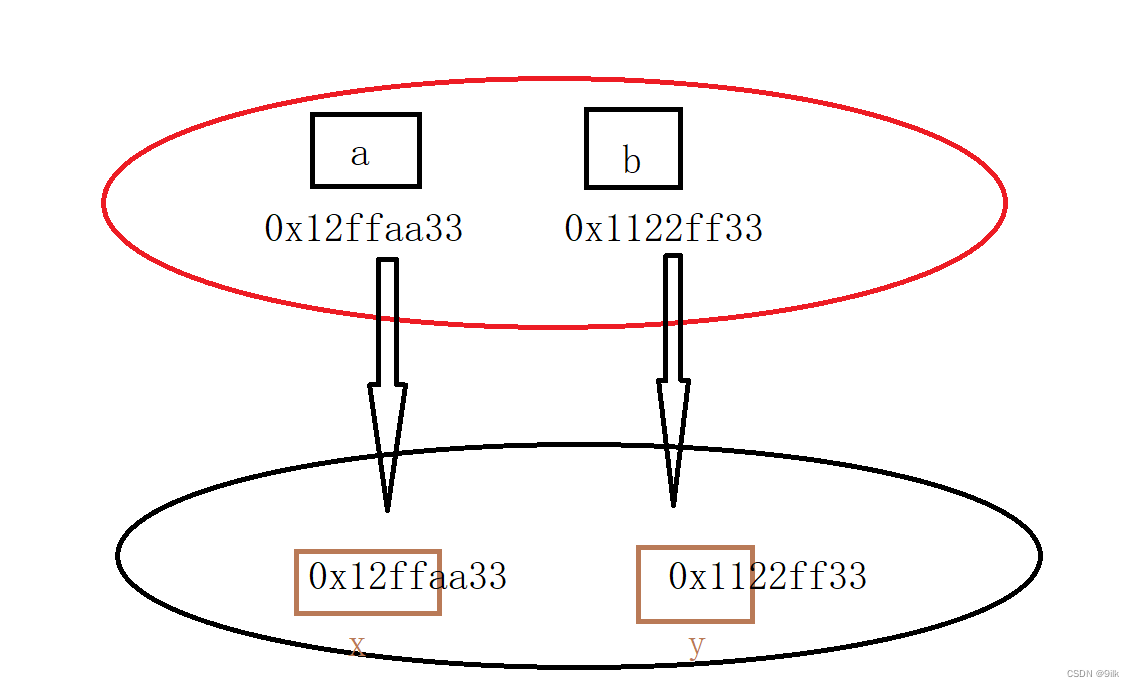
那些年与指针的爱恨情仇(一)---- 指针本质及其相关性质用法
关注小庄 顿顿解馋 (≧∇≦) 引言: 小伙伴们在学习c语言过程中是否因为指针而困扰,指针简直就像是小说女主,它逃咱追,我们插翅难飞…本篇文章让博主为你打理打理指针这个傲娇鬼吧~ 本节我们将认识到指针本质,何为指针和…...
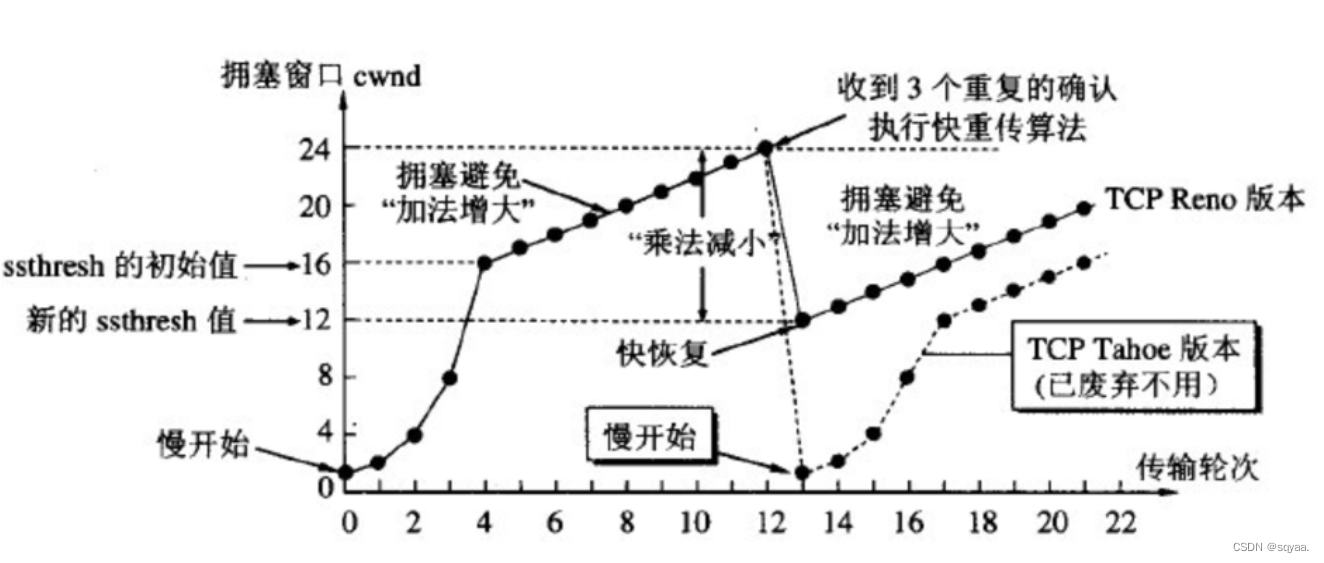
计算机网络——TCP协议
💡TCP的可靠不在于它是否可以把数据100%传输过去,而是 1.发送方发去数据后,可以知道接收方是否收到数据;2.如果接收方没收到,可以有补救手段; 图1.TCP组成图 TCP的可靠性是付出代价的,即传输效率…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

Go语言实现跨平台系统更新检查器:自动化运维与安全监控实践
1. 项目概述:一个被低估的系统运维“哨兵”在服务器和桌面系统的日常运维中,有一个场景大家一定不陌生:某天,你管理的服务器突然因为一个已知漏洞被攻击,事后排查发现,相关的安全补丁其实在几周前就已经发布…...

GitClaw:基于Go的轻量级Git钩子服务器与集中式权限管理方案
1. 项目概述与核心价值如果你是一名开发者,尤其是经常在团队协作中处理Git仓库的工程师,那么你一定对“权限管理”这四个字又爱又恨。爱的是它能保障代码安全,恨的是它配置起来繁琐,尤其是在处理跨项目、跨团队的复杂权限矩阵时。…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

数据流编排与异步任务调度中间件kelivo部署与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“Chevey339/kelivo”。乍一看这个标题,可能有点摸不着头脑,它不像那些直接告诉你“XX管理系统”或“XX工具库”的项目名那么直白。但恰恰是这种看似神秘的命名,背后往往隐藏…...

云原生安全工具:保护云原生环境
云原生安全工具:保护云原生环境 一、云原生安全工具概述 1.1 云原生安全工具的定义 云原生安全工具是指专为云原生环境设计的安全工具和解决方案。它们用于保护容器、Kubernetes集群、微服务和Serverless应用的安全。 1.2 云原生安全工具的价值 安全防护:…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

大语言模型可靠性监测与压缩的谱方法研究
1. 大语言模型可靠性监测与压缩的谱方法研究概述在深度学习领域,大语言模型(LLM)和视觉语言模型(VLM)的可靠性问题与计算效率挑战日益凸显。模型幻觉(生成与输入无关或错误的内容)和分布偏移(面对训练数据分布外的输入时性能下降)会严重损害用户信任,而庞…...

Linux内存使用分析与泄漏排查
Linux内存使用分析与泄漏排查内存问题往往不像磁盘满那样直观,也不像进程崩溃那样立刻可见。很多服务在内存异常初期仍然可以运行,只是响应逐渐变慢、交换开始活跃、最终被系统回收或触发 OOM。中级 Linux 工程师需要掌握的,不只是看“还剩多…...