Hadoop-MapReduce-源码跟读-客户端篇
一、源码下载
下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
Index of /dist/hadoop/core
二、从WordCount进入源码
用idea将源码加载进来后,找到org.apache.hadoop.examples.WordCount类(快捷方法:双击Shift输入WordCount)
/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/
package org.apache.hadoop.examples;import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {//构建一个新的Configuration,static代码块中加载了core-default.xml、core-site.xml配置//如果core-site.xml将某个属性的final设置为true,那么用户将无法进行修改Configuration conf = new Configuration();//获取用户命令行中指定的选项,并进行配置String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}//根据配置和job名称创建一个新的Job,Job是提交者面对的视图//此时Cluster是空的,只有在需要时,才会根据conf参数创建ClusterJob job = Job.getInstance(conf, "word count");//通过查找示例类位置来设置作业的jar文件,此时Job状态被设置为DEFINEjob.setJarByClass(WordCount.class);//为作业设置Mapper,该类必须是Mapper的子类,那么设置mapreduce.job.map.class的value为该类job.setMapperClass(TokenizerMapper.class);//为作业设置combiner,该类必须是Reducer的子类,那么设置mapreduce.job.combine.class的value为该类job.setCombinerClass(IntSumReducer.class);//为作业设置Reducer,该类必须是Reducer的子类,那么设置mapreduce.job.reduce.class的value为该类job.setReducerClass(IntSumReducer.class);//设置作业输出的Key类型类,即mapreduce.job.output.key.classjob.setOutputKeyClass(Text.class);//设置作业输出的Value类型类,即mapreduce.job.output.value.classjob.setOutputValueClass(IntWritable.class);//设置输入数据的路径,设置mapreduce.input.fileinputformat.inputdir为以逗号为连接符的多个输入路径for (int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}//设置输出数据的路径,即mapreduce.output.fileoutputformat.outputdirFileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length - 1]));//将Job提交到集群并等待其完成。传参为true表示实时监控作业和打印状态System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
注释已加,下面我们从job.waitForCompletion(true) 进入源码学习
其中涉及的方法有很多,不可能一一来看,我们这里只看主线上的方法以及重要的方法
1、Job.waitForCompletion
/*** Submit the job to the cluster and wait for it to finish.* @param verbose print the progress to the user* @return true if the job succeeded* @throws IOException thrown if the communication with the * <code>JobTracker</code> is lost*/public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException,ClassNotFoundException {//如果此时Job状态是否为DEFINE,就提交if (state == JobState.DEFINE) {//将作业提交到集群并立即返回。submit();}//如果传入的参数为true,就实时打印Job状态if (verbose) {//随着进度和任务的进行,实时监控作业和打印状态monitorAndPrintJob();} else {// get the completion poll interval from the client.//从客户端获取完成轮询间隔。可以通过mapreduce.client.completion.pollinterval设置,//默认5000ms,JobClient轮询MapReduce ApplicationMaster以获取有关作业状态的更新的间隔(以毫秒为单位)。//测试小数据量时可以设置间隔短些,生产上设置的间隔长一些可以减少客户端-服务器交互int completionPollIntervalMillis = Job.getCompletionPollInterval(cluster.getConf());//检查作业是否已完成。这是一个非阻塞呼叫。while (!isComplete()) {try {Thread.sleep(completionPollIntervalMillis);} catch (InterruptedException ie) {}}}return isSuccessful();}2、Job.submit
/*** Submit the job to the cluster and return immediately.* @throws IOException*/public void submit() throws IOException, InterruptedException, ClassNotFoundException {ensureState(JobState.DEFINE);//默认设置为新API,除非它们被显式设置,或者使用了旧的映射器或reduce属性。setUseNewAPI();//采用impersonation(doAs)机制,为符合身份和权限的用户构建Cluster//Cluster提供一种访问有关 map/reduce 群集的信息的方法。connect();//获取JobSubmitter 从字面上看时Job提交者 (参数为文件系统和客户端)//JobClient可以使用自有方法提交作业以供执行,并了解当前系统状态。final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {//用于向系统提交作业的内部方法。return submitter.submitJobInternal(Job.this, cluster);}});//更改作业状态为RUNNINGstate = JobState.RUNNING;//获取可以显示该作业进度信息的URL。LOG.info("The url to track the job: " + getTrackingURL());}3、JobSubmitter.submitJobInternal
/**
* 用于向系统提交Job的内部方法。
* Job提交过程包括:
* 1、检查Job的输入和输出规格
* 2、计算Job的InputSplit
* 3、如有必要,请为Job的DistributedCache设置必要的记帐信息
* 4、将Job的jar和配置复制到分布式文件系统上的map-reduce系统目录中
* 5、将作业提交到ResourceManager,并可选择监视其状态。
* @param job the configuration to submit
* @param cluster the handle to the Cluster
* @throws ClassNotFoundException
* @throws InterruptedException
* @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException {//验证作业输出规格,如果输出目录存在为避免重写则抛出异常checkSpecs(job);//根据Job获取Configuration,刚刚是根据配置创建Job,可见他们可以互相得到Configuration conf = job.getConfiguration();//加载MapReduce框架存档路径到分布式缓存conf//如果设置了MapReduce框架存档的路径(此路径通常位于HDFS文件系统中的公共位置),框架存档将自动与作业一起分发addMRFrameworkToDistributedCache(conf);//初始化临时目录并返回路径Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);//configure the command line options correctly on the submitting dfs//在提交的dfs上正确配置命令行选项//返回本地主机的地址。通过从系统中检索主机的名称,然后将该名称解析为InetAddress//注意:解析后的地址可能会被缓存一小段时间//如果存在安全管理器并被阻挡,那么返回表示环回地址的InetAddress//会获取系统的所有网卡信息,但是返回的是第一个InetAddress ip = InetAddress.getLocalHost();if (ip != null) {//设置提交端的ip地址submitHostAddress = ip.getHostAddress();//设置提交端的hostnamesubmitHostName = ip.getHostName();//设置job相关配置mapreduce.job.submithostnameconf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);//设置job相关配置mapreduce.job.submithostaddressconf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);}//作业分配一个唯一的jobIdJobID jobId = submitClient.getNewJobID();//为job设置jobIdjob.setJobID(jobId);//Path submitJobDir = new Path(jobStagingArea, jobId.toString());JobStatus status = null;try {//设置mapreduce.job.user.nameconf.set(MRJobConfig.USER_NAME,UserGroupInformation.getCurrentUser().getShortUserName());//设置hadoop.http.filter.initializers,默认的过滤类是org.apache.hadoop.http.lib.StaticUserWebFilter//这里设置的是AmFilterInitializer//该配置是以逗号分隔的类名列表,必须是FilterInitializer子类//这些Filter将应用于所有面向用户的jsp和servlet网页conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");//设置mapreduce.job.dirconf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir");// get delegation token for the dir//获取dir的委派令牌TokenCache.obtainTokensForNamenodes(job.getCredentials(),new Path[] { submitJobDir }, conf);//获取密钥和令牌并将其存储到TokenCache中populateTokenCache(conf, job.getCredentials());// generate a secret to authenticate shuffle transfers// 生成一个密钥以验证无序传输if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {KeyGenerator keyGen;try {keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);keyGen.init(SHUFFLE_KEY_LENGTH);} catch (NoSuchAlgorithmException e) {throw new IOException("Error generating shuffle secret key", e);}//设置MapReduce中Shuffle的密钥key,可见Shuffle的传输是有校验的,是有数据完整性保障的SecretKey shuffleKey = keyGen.generateKey();TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),job.getCredentials());}//判断是否加密中间MapReduce溢写文件,默认false(mapreduce.job.encrypted-intermediate-data)if (CryptoUtils.isEncryptedSpillEnabled(conf)) {//如果设置了加密,就把最大作业尝试次数设置为1,默认值是2//该参数是应用程序尝试的最大次数,如果失败ApplicationMaster会进行重试conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);LOG.warn("Max job attempts set to 1 since encrypted intermediate" +"data spill is enabled");}//上传和配置与传递job相关的文件、libjar、jobjar和归档文件。//如果启用了共享缓存,则此客户端将使用libjar、文件、归档和jobjar的共享缓存//1.对于已经成功共享的资源,我们将继续以共享的方式使用它们。//2.对于不在缓存中并且需要NM上传的资源,我们不会要求NM上传。copyAndConfigureFiles(job, submitJobDir);//获取job conf的文件路径Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);// Create the splits for the job//为job创建 splitsLOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));//重点看该方法,该方法为job计算分片int maps = writeSplits(job, submitJobDir);//设置map个数 mapreduce.job.maps 可见分片数=map个数conf.setInt(MRJobConfig.NUM_MAPS, maps);LOG.info("number of splits:" + maps);//获取最大map数 mapreduce.job.max.map 默认 -1 即无限制int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,MRJobConfig.DEFAULT_JOB_MAX_MAP);if (maxMaps >= 0 && maxMaps < maps) {throw new IllegalArgumentException("The number of map tasks " + maps +" exceeded limit " + maxMaps);}// write "queue admins of the queue to which job is being submitted"// to job file.//将“作业提交到的队列的队列管理员”写入作业文件//获取队列名称 mapreduce.job.queuename 默认是defaultString queue = conf.get(MRJobConfig.QUEUE_NAME,JobConf.DEFAULT_QUEUE_NAME);//获取给定作业队列的管理员。此方法仅供hadoop内部使用。AccessControlList acl = submitClient.getQueueAdmins(queue);//设置mapred.queue.default.acl-administer-jobsconf.set(toFullPropertyName(queue,QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());// removing jobtoken referrals before copying the jobconf to HDFS// as the tasks don't need this setting, actually they may break// because of it if present as the referral will point to a// different job.//在将job conf复制到HDFS之前删除jobtoken引用,因为任务不需要此设置,//实际上它们可能会因此而中断,因为引用将指向不同的作业。TokenCache.cleanUpTokenReferral(conf);//判断配置中mapreduce.job.token.tracking.ids.enabled(跟踪作业使用的令牌的ID的配置,默认false)if (conf.getBoolean(MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {// Add HDFS tracking idsArrayList<String> trackingIds = new ArrayList<String>();for (Token<? extends TokenIdentifier> t :job.getCredentials().getAllTokens()) {trackingIds.add(t.decodeIdentifier().getTrackingId());}conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,trackingIds.toArray(new String[trackingIds.size()]));}// Set reservation info if it exists//设置预订信息(如果存在)mapreduce.job.reservation.idReservationId reservationId = job.getReservationId();if (reservationId != null) {conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());}// Write job file to submit dir//写入作业文件以提交目录(HDFS上)writeConf(conf, submitJobFile);//// Now, actually submit the job (using the submit name)// 现在,真正提交作业(使用提交名称)//这里调用了YARNRunner.submitJob() 下面我们看下这个方法printTokens(jobId, job.getCredentials());status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());if (status != null) {return status;} else {throw new IOException("Could not launch job");}} finally {if (status == null) {LOG.info("Cleaning up the staging area " + submitJobDir);if (jtFs != null && submitJobDir != null)jtFs.delete(submitJobDir, true);}}}3.1 JobSubmitter.writeSplits
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,Path jobSubmitDir) throws IOException,InterruptedException, ClassNotFoundException {JobConf jConf = (JobConf)job.getConfiguration();int maps;//默认是false,在Job.submit是用setUseNewAPI()方法设置过trueif (jConf.getUseNewMapper()) {//重点看该方法maps = writeNewSplits(job, jobSubmitDir);} else {maps = writeOldSplits(jConf, jobSubmitDir);}return maps;}3.2 JobSubmitter.writeNewSplits
private <T extends InputSplit>int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,InterruptedException, ClassNotFoundException {Configuration conf = job.getConfiguration();//获取输入格式化类,可以通过mapreduce.job.inputformat.class设置,//默认为TextInputFormat.classInputFormat<?, ?> input =ReflectionUtils.newInstance(job.getInputFormatClass(), conf);//重点看这个方法//按逻辑拆分作业的输入文件集。//每个InputSplit都被分配给一个单独的Mapper进行处理(分片数量=MapTask数量)//注意:InputSplit是逻辑上的分割(比如 <输入文件路径,开始,偏移量>),并没有改变文件对应的块//InputFormat还创建RecordReader以读取InputSplit。List<InputSplit> splits = input.getSplits(job);T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);// sort the splits into order based on size, so that the biggest// go first//根据大小将拆分部分按顺序排序,使最大的优先Arrays.sort(array, new SplitComparator());JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array);return array.length;}3.3 FileInputFormat.getSplits
/** * Generate the list of files and make them into FileSplits.* 生成文件列表,并将它们制作成FileSplits。* @param job the job context* @throws IOException*/public List<InputSplit> getSplits(JobContext job) throws IOException {StopWatch sw = new StopWatch().start();//getFormatMinSplitSize() 返回 1//getMinSplitSize(job)) 获取mapreduce.input.fileinputformat.split.minsize值,默认1//两者取最大值,因为两者默认值都是1,那么 minSize = 1long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));//获取mapreduce.input.fileinputformat.split.maxsize的值,默认值Long.MAX_VALUE(2的63次方-1 MAX_VALUE=0x7fffffffffffffffL)long maxSize = getMaxSplitSize(job);// generate splits// 声明分片列表List<InputSplit> splits = new ArrayList<InputSplit>();//列出输入目录,仅选择与正则表达式匹配的文件List<FileStatus> files = listStatus(job);//获取mapreduce.input.fileinputformat.input.dir.recursive的值 默认false//获取mapreduce.input.fileinputformat.input.dir.nonrecursive.ignore.subdirs的值 默认false//两者都为true,才把ignoreDirs 设置为trueboolean ignoreDirs = !getInputDirRecursive(job)&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);//循环输入的每个文件,计算全部的InputSplitfor (FileStatus file: files) {//忽略目录if (ignoreDirs && file.isDirectory()) {continue;}//FileStatus接口,表示文件的客户端信息//Path 为FileSystem中文件或目录的名称//通过FileStatus获取PathPath path = file.getPath();//获取此文件的长度,以字节为单位。long length = file.getLen();//如果文件长度不等于0if (length != 0) {//BlockLocation 表示块的网络位置、有关包含块副本的主机的信息以及其他块元数据//(例如,与块相关的文件偏移量、长度、是否已损坏等)。//如果文件是3个复本,则BlockLocation的偏移量和长度表示文件中的绝对值,而主机是保存副本的3个数据节点。以下是一个示例://BlockLocation(offset: 0, length: BLOCK_SIZE,hosts: {"host1:9866", "host2:9866, host3:9866"})//如果文件是擦除编码的,则每个BlockLocation表示一个逻辑块组。值偏移是文件中块组的偏移,值长度是块组的总长度。BlockLocation的主机是保存块组的所有数据块和奇偶校验块的数据节点。//假设我们有一个RS_3_2编码文件(3个数据单元和2个奇偶校验单元)。BlockLocation示例如下://BlockLocation(offset: 0, length: 3 * BLOCK_SIZE, hosts: {"host1:9866","host2:9866","host3:9866","host4:9866","host5:9866"})BlockLocation[] blkLocations;//判断文件是否是LocatedFileStatus的实例//获取文件的 block 位置列表 if (file instanceof LocatedFileStatus) {blkLocations = ((LocatedFileStatus) file).getBlockLocations();} else {FileSystem fs = path.getFileSystem(job.getConfiguration());blkLocations = fs.getFileBlockLocations(file, 0, length);}//判断文件是可拆分的吗?通常情况下,这是真的,但如果文件是流压缩的,则不会。if (isSplitable(job, path)) {//获取该文件的块大小,HDFS允许文件可以指定自己的块大小和副本数long blockSize = file.getBlockSize();//计算该文件的分片大小://Math.max(minSize, Math.min(maxSize, blockSize));//minSize 默认 = 1//maxSize 默认 = Long.MAX_VALUE//那么默认情况下该文件的分片大小=blockSize(该文件的块大小)long splitSize = computeSplitSize(blockSize, minSize, maxSize);//默认剩下的字节长度=文件总的字节长度long bytesRemaining = length;//文件剩下的字节长度 / 分片大小(默认该文件块大小) > 1.1//含义:如果文件剩下的字节长度还有 块大小的1.1倍就继续 // 如果一个文件只有一个块 那么就不走该循环了while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {//length-bytesRemaining 相当于对于该文件整体的偏移量//根据偏移量获取对应该文件的第几个块int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);//添加分片splits.add(makeSplit(path, length-bytesRemaining, splitSize,blkLocations[blkIndex].getHosts(),blkLocations[blkIndex].getCachedHosts()));bytesRemaining -= splitSize;}//一般到最后一个分片会走这里,或者该文件特别小只有一个块会走这里if (bytesRemaining != 0) {int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,blkLocations[blkIndex].getHosts(),blkLocations[blkIndex].getCachedHosts()));}} else { // not splitableif (LOG.isDebugEnabled()) {// Log only if the file is big enough to be splittedif (length > Math.min(file.getBlockSize(), minSize)) {LOG.debug("File is not splittable so no parallelization "+ "is possible: " + file.getPath());}}//制作分片,分片数量=文件数量,分片为该文件对应的副本中第一个副本所在位置(优先取在缓存中的副本)splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),blkLocations[0].getCachedHosts()));}} else { //Create empty hosts array for zero length files//如果输入文件的字节大小=0,创建空的分片splits.add(makeSplit(path, 0, length, new String[0]));}}// Save the number of input files for metrics/loadgen// 为 job 设置文件数 mapreduce.input.fileinputformat.numinputfilesjob.getConfiguration().setLong(NUM_INPUT_FILES, files.size());sw.stop();if (LOG.isDebugEnabled()) {LOG.debug("Total # of splits generated by getSplits: " + splits.size()+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));}return splits;}4、YARNRunner.submitJob
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)throws IOException, InterruptedException {//添加TokensaddHistoryToken(ts);//构建启动MapReduce ApplicationMaster所需的所有信息// 1、设置LocalResources(表示运行容器所需的本地资源,NodeManager负责在启动容器之前本地化资源)// 2、设置安全令牌// 3、为ApplicationMaster容器设置ContainerLaunchContext(表示NodeManager启动容器所需的所有信息包括:ContainerId、资源情况、分配给谁、安全令牌、环境变量、启动容器的命令、容器失败退出时的重试策略、运行容器所必需的,如二进制文件、jar、共享对象、辅助文件等、)// 4、设置ApplicationSubmissionContext(表示ResourceManager启动应用程序的ApplicationMaster所需的所有信息。包括:ApplicationId、用户、名称、优先级、执行ApplicationMaster的容器的ContainerLaunchContext、可尝试的最大次数、尝试间隔、NodeManager处理应用程序日志所需的所有信息)// 5、设置ApplicationMaster资源请求// 6、为AM容器请求设置标签(如果存在)// 7、为job容器设置标签ApplicationSubmissionContext appContext =createApplicationSubmissionContext(conf, jobSubmitDir, ts);// Submit to ResourceManager// 向ResourceManager提交try {//最终是用YarnClient来提交到YarnApplicationId applicationId =resMgrDelegate.submitApplication(appContext);ApplicationReport appMaster = resMgrDelegate.getApplicationReport(applicationId);String diagnostics =(appMaster == null ?"application report is null" : appMaster.getDiagnostics());if (appMaster == null|| appMaster.getYarnApplicationState() == YarnApplicationState.FAILED|| appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) {throw new IOException("Failed to run job : " +diagnostics);}return clientCache.getClient(jobId).getJobStatus(jobId);} catch (YarnException e) {throw new IOException(e);}}5、YarnClientImpl.submitApplication
/*** 向YARN提交新申请,这是一个阻塞调用-在提交的应用程序成功提交并被ResourceManager接受之前,* 它不会返回ApplicationId。* 用户在提交新应用程序时应提供ApplicationId作为参数ApplicationSubmissionContext的一部分* 这在内部调用ApplicationClientProtocol.submitApplication() 之后在内部调用 ApplicationClientProtocol.getApplicationReport()* */
public ApplicationIdsubmitApplication(ApplicationSubmissionContext appContext)throws YarnException, IOException {//获取applicationIdApplicationId applicationId = appContext.getApplicationId();if (applicationId == null) {throw new ApplicationIdNotProvidedException("ApplicationId is not provided in ApplicationSubmissionContext");}//构建SubmitApplicationRequest(向ResourceManager提交应用程序的请求信息)SubmitApplicationRequest request =Records.newRecord(SubmitApplicationRequest.class);request.setApplicationSubmissionContext(appContext);// Automatically add the timeline DT into the CLC// Only when the security and the timeline service are both enabled//仅当安全和时间线服务都启用时自动将时间线DT添加到CLC中if (isSecurityEnabled() && timelineV1ServiceEnabled) {addTimelineDelegationToken(appContext.getAMContainerSpec());}//TODO: YARN-1763:Handle RM failovers during the submitApplication call.//提交作业//客户端用于向ResourceManager提交新应用程序的接口//客户端需要通过SubmitApplicationRequest提供详细信息,如运行ApplicationMaster所需的队列、用于启动Application Master的等效队列等rmClient.submitApplication(request);int pollCount = 0;long startTime = System.currentTimeMillis();//Job等待状态设置EnumSet<YarnApplicationState> waitingStates = EnumSet.of(YarnApplicationState.NEW,YarnApplicationState.NEW_SAVING,YarnApplicationState.SUBMITTED);//Job失败状态设置EnumSet<YarnApplicationState> failToSubmitStates = EnumSet.of(YarnApplicationState.FAILED,YarnApplicationState.KILLED); while (true) {try {//获取应用的报告,包括:// ApplicationId// Applications user// Application queue// Application name// 允许ApplicationMaster的主机// ApplicationMaster的RPC端口// 跟踪url// ApplicationMaster的各种状态// 出现错误时的诊断信息// 应用的开始时间// 如果开启了安全性,应用的客户端令牌ApplicationReport appReport = getApplicationReport(applicationId);YarnApplicationState state = appReport.getYarnApplicationState();if (!waitingStates.contains(state)) {if(failToSubmitStates.contains(state)) {throw new YarnException("Failed to submit " + applicationId + " to YARN : " + appReport.getDiagnostics());}LOG.info("Submitted application " + applicationId);break;}long elapsedMillis = System.currentTimeMillis() - startTime;if (enforceAsyncAPITimeout() &&elapsedMillis >= asyncApiPollTimeoutMillis) {throw new YarnException("Timed out while waiting for application " +applicationId + " to be submitted successfully");}// Notify the client through the log every 10 poll, in case the client// is blocked here too long.//每10次轮询通过日志通知客户端,以防客户端在此处被阻止的时间过长。if (++pollCount % 10 == 0) {LOG.info("Application submission is not finished, " +"submitted application " + applicationId +" is still in " + state);}try {//通过yarn.client.app-submission.poll-interval 设置,默认值200msThread.sleep(submitPollIntervalMillis);} catch (InterruptedException ie) {String msg = "Interrupted while waiting for application "+ applicationId + " to be successfully submitted.";LOG.error(msg);throw new YarnException(msg, ie);}} catch (ApplicationNotFoundException ex) {// FailOver or RM restart happens before RMStateStore saves// ApplicationState//故障转移或RM重新启动发生在RMStateStore保存ApplicationState之前LOG.info("Re-submit application " + applicationId + "with the " +"same ApplicationSubmissionContext");rmClient.submitApplication(request);}}return applicationId;}三、总结
1、构建Configuration,并加载hadoop默认的配置文件core-default.xml、core-site.xml
2、解析命令行参数,配置用户配置的环境变量
3、设置Job信息,比如:主类、Mapper类、Reduce类、Combiner类、输出格式、输入输出文件等
4、异步提交Job,实时监控作业并打印Job状态
5、根据用户身份和权限构建Cluster,并向集群提交Job
6、检查Job的输入和输出规格
7、计算Job的InputSplit(格式:<输入文件路径,开始,偏移量>,默认分片数量=所有输入文件对应的块的数量,且每个分片对应一个Mapper)
8、如有必要,请为Job的DistributedCache设置必要的记帐信息
9、将Job的jar和配置复制到分布式文件系统上的map-reduce系统目录中
10、将作业提交到ResourceManager,并可选择监视其状态
相关文章:

Hadoop-MapReduce-源码跟读-客户端篇
一、源码下载 下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧 Index of /dist/hadoop/core 二、从WordCount进入源码 用idea将源码加载进来后,找到org.apache.hadoop.examples.WordCount类(快捷方法&…...
《游戏-03_3D-开发》之—新输入系统人物移动攻击连击
本次修改unity的新输入输出系统。本次修改unity需要重启,请先保存项目, 点击加号起名为MyCtrl, 点击加号设置为一轴的, 继续设置W键, 保存 生成自动脚本, 修改MyPlayer代码: using UnityEngine;…...
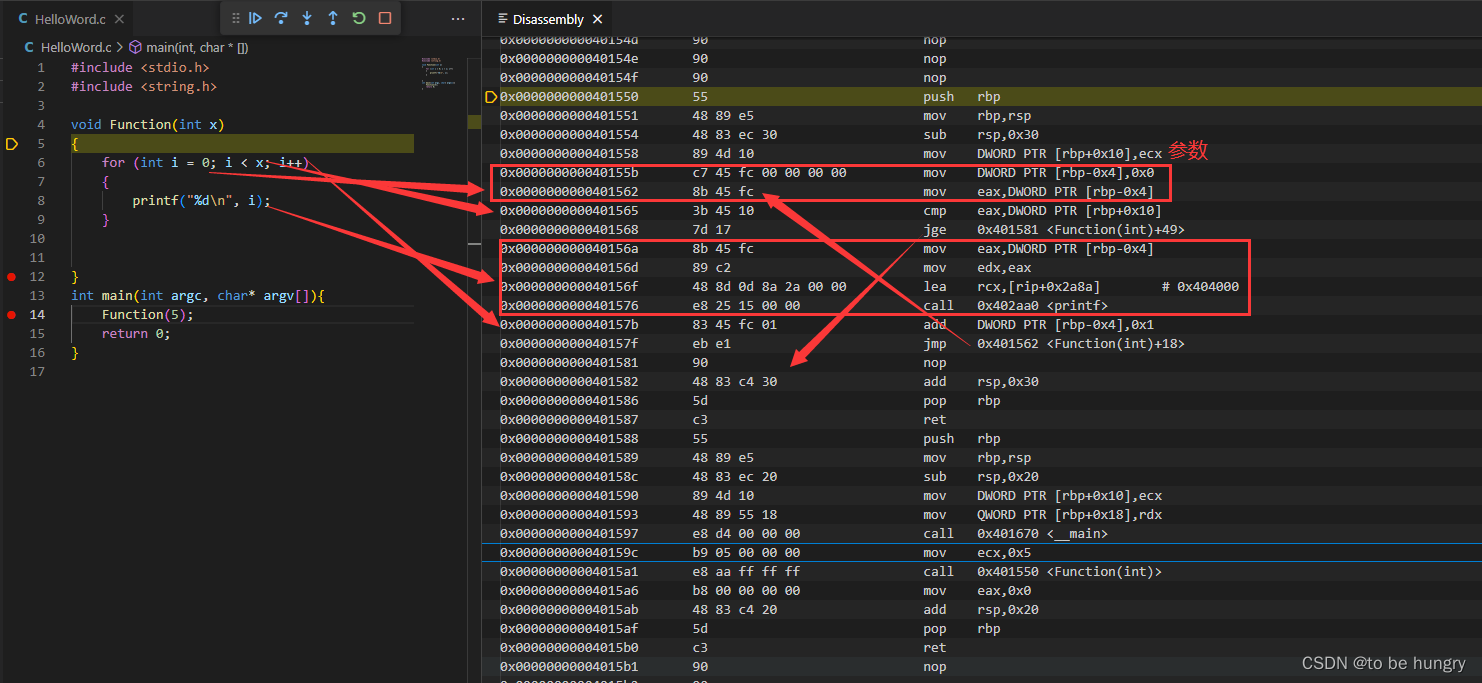
滴水逆向三期笔记与作业——02C语言——10 Switch语句反汇编
滴水逆向三期笔记与作业——02C语言——10 Switch语句反汇编 一、Switch语句1、switch语句 是if语句的简写2、break加与不加有什么特点?default语句可以省略吗?3、游戏中的switch语句(示例)4、添加case后面的值,一个一个增加&…...
燃烧的指针(三)
🌈个人主页:小田爱学编程 🔥 系列专栏:c语言从基础到进阶 🏆🏆关注博主,随时获取更多关于c语言的优质内容!🏆🏆 😀欢迎来到小田代码世界~ &#x…...

微服务架构实施攻略:如何选择合适的微服务通信机制?
随着业务的快速发展和系统的日益复杂,传统的单体应用逐渐显露出瓶颈,已无法满足现代软件研发的需求。微服务架构作为一种灵活、可扩展的解决方案,通过将复杂系统拆分为一系列小型服务来提高系统的可伸缩性、灵活性和可维护性。在实施微服务架…...
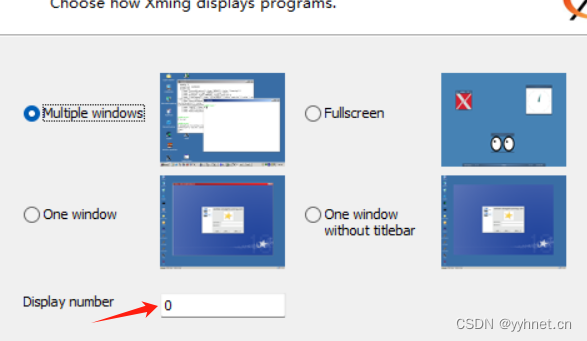
【jetson笔记】解决vscode远程调试qt.qpa.xcb: could not connect to display报错
配置x11转发 jetson远程安装x11转发 安装Xming Xming下载 安装完成后打开安装目录C:\Program Files (x86)\Xming 用记事本打开X0.hosts文件,添加jetson IP地址 后续IP改变需要重新修改配置文件 localhost 192.168.107.57打开Xlaunch Win菜单搜索Xlaundch打开 一…...

网络安全产品之认识安全隔离网闸
文章目录 一、什么是安全隔离网闸二、安全隔离网闸的主要功能三、安全隔离网闸的工作原理四、安全隔离网闸的分类五、安全隔离网闸与防火墙的区别四、安全隔离网闸的应用场景 随着互联网的发展,网络攻击和病毒传播的方式越来越复杂,对网络安全的要求也越…...
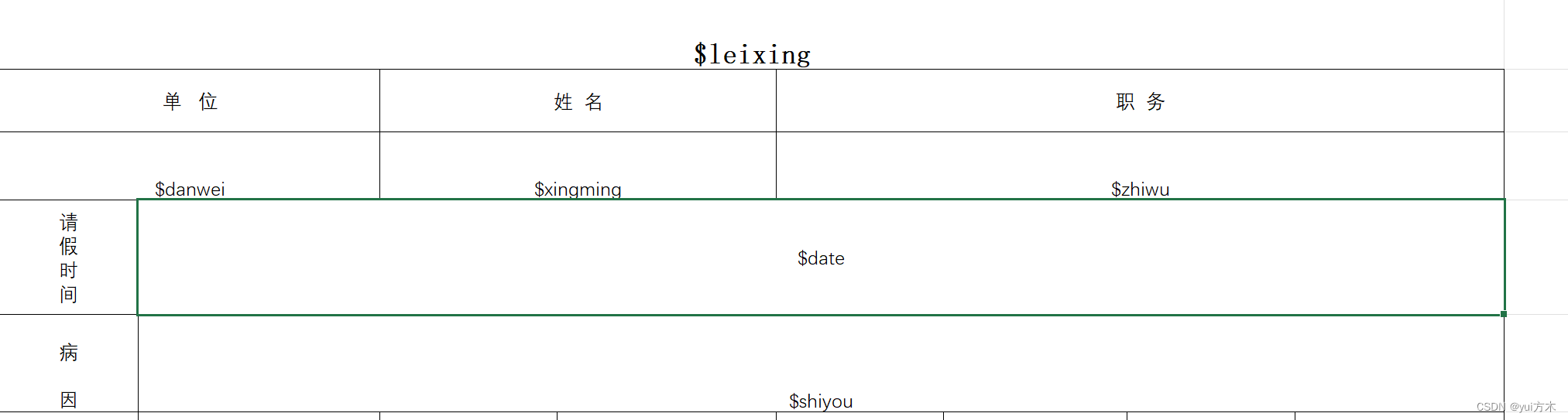
Java通过模板替换实现excel的传参填写
以模板为例子 将上面$转义的内容替换即可 package com.gxuwz.zjh.util;import org.apache.poi.ss.usermodel.*; import org.apache.poi.xssf.usermodel.XSSFWorkbook; import java.io.*; import java.util.HashMap; import java.util.Map; import java.io.IOException; impor…...
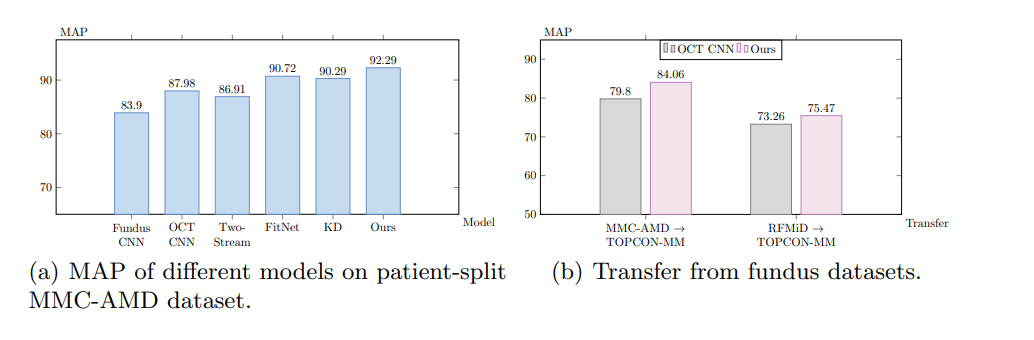
眼底增强型疾病感知蒸馏模型 FDDM:无需配对,fundus 指导 OCT 分类
眼底增强型疾病感知蒸馏模型 FDDM:fundus 指导 OCT 分类 核心思想设计思路训练和推理 效果总结子问题: 疾病特定特征的提取与蒸馏子问题: 类间关系的理解与建模 核心思想 论文:https://arxiv.org/pdf/2308.00291.pdf 代码:https://github.c…...
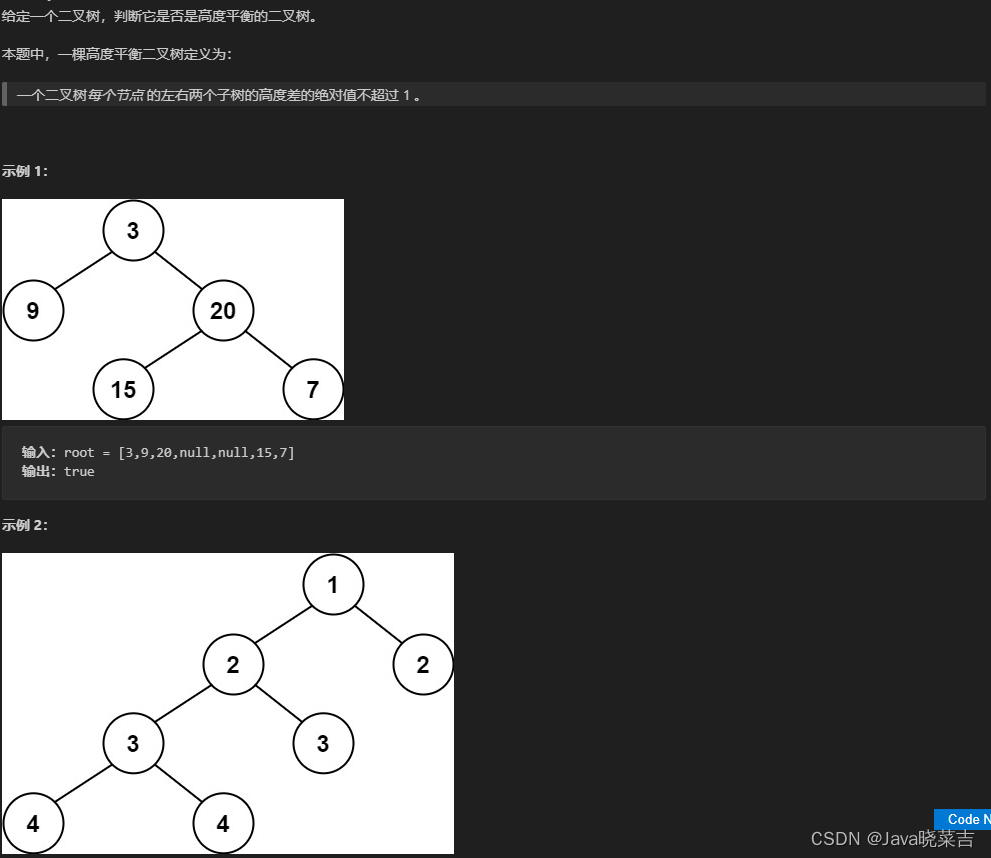
代码随想录算法刷题训练营day17
代码随想录算法刷题训练营day17:LeetCode(110)平衡二叉树 LeetCode(110)平衡二叉树 题目 代码 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(…...

Java集合如何选择
为什么使用集合 当需要存储一组类型相同的数据时,数组是最常用且最基本的容器之一。但是,使用数组存储对象存在一些不足之处,因为在实际开发中,存储的数据类型多种多样且数量不确定。这时,Java 集合就派上用场了。与数…...
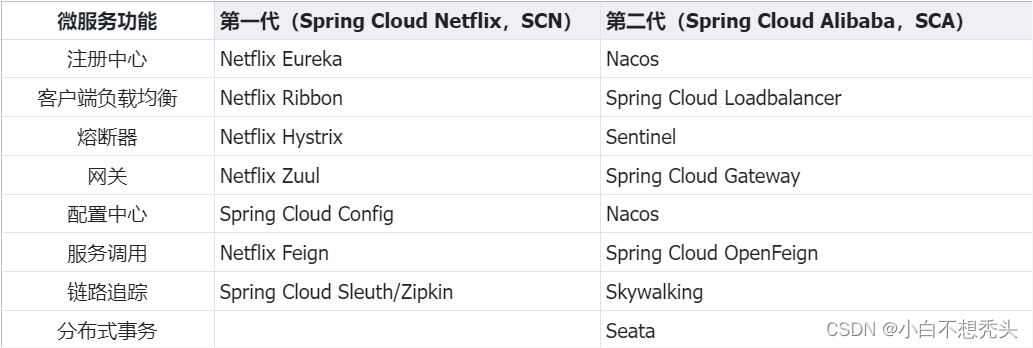
简单介绍----微服务和Spring Cloud
微服务和SpringCloud 1.什么是微服务? 微服务是将一个大型的、单一的应用程序拆分成多个小型服务,每个服务负责实现特定的业务功能,并且可以通过网络通信与其他服务通信。微服务的优点是开发更灵活(不同的微服务可以使用不同的开…...

Jenkins邮件推送配置
目录 涉及Jenkins插件: 邮箱配置 什么是授权码 在第三方客户端/服务怎么设置 IMAP/SMTP 设置方法 POP3/SMTP 设置方法 获取授权码: Jenkins配置 从Jenkins主面板System configuration>System进入邮箱配置 在Email Extension Plugin 邮箱插件…...

硬件知识(1) 手机的长焦镜头
#灵感# 手机总是配备好几个镜头,研究一下 目录 手机常配备的摄像头,及效果举例 长焦的焦距 焦距的定义和示图: IPC的焦距和适用场景: 手机常配备的摄像头,及效果举例 以下是小米某个手机的摄像头介绍:…...

华为机考入门python3--(3)牛客3-明明的随机数
分类:集合、排序 知识点: 集合添加元素 set.add(element) 集合转列表 list(set) 列表排序 list.sort() 题目来自【牛客】 N int(input().strip()) nums set()for i in range(N):nums.add(int(input().strip()))# 集合转列表 nums_list l…...

vue父子组件传值问题
在Vue中,父子组件之间的数据传递可以通过props和事件来实现。 使用props传递数据:父组件可以通过props将数据传递给子组件,子组件可以在模板中直接使用这些数据。父组件可以通过v-bind指令将数据绑定到子组件的props上。例如: v…...

Rider 打开Unity项目 Project 全部显示 load failed
电脑自动更新,导致系统重启,第二天Rider打开Unity 工程,没有任何代码提示,字符串查找也失效。 现象: 1.所有的Project均显示laod failed。点击load failed。右侧信息显示Can not start process 2.选中解决方案进行Bui…...
:依赖管理、依赖传递、依赖冲突、工程继承及工程聚合)
Maven(下):依赖管理、依赖传递、依赖冲突、工程继承及工程聚合
1. 基于IDEA 进行Maven依赖管理 1.1 依赖管理概念 Maven 依赖管理是 Maven 软件中最重要的功能之一。Maven 的依赖管理能够帮助开发人员自动解决软件包依赖问题,使得开发人员能够轻松地将其他开发人员开发的模块或第三方框架集成到自己的应用程序或模块中…...

网络基础---初识网络
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、局域网…...

【Java】Java类动态替换Class
Java类动态替换Class 通过Java的Class对象,可以实现动态替换Class。 预习几个知识点 getClassLoader Java提供的ClassLoader可用于动态加载的Java类,可以通过多种形式获取ClassLoader。比如通过Class类获取 // 通过Class获取 ClassLoader classLoade…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

从零构建本地化AI代码助手:架构、微调与工程实践
1. 项目概述:从零构建你自己的Claude代码助手最近在开发者社区里,一个名为“build-your-claude-code-from-scratch”的项目引起了我的注意。这个标题本身就充满了吸引力——它暗示着一种可能性:我们是否能够不依赖任何现成的、闭源的商业API&…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...

OpenClaw 小龙虾智能体联动 DeepSeek 大模型部署实操攻略
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常启动OpenClaw,右上角 Gateway 状态显示在线设备网络通畅,可正常访问 DeepSeek 开放平台拥有可接收验证码的手机号 / 微信,用于平…...

CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题
CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...

Mantic.sh:AI驱动的智能命令行工具,让自然语言生成终端命令
1. 项目概述:一个为开发者打造的智能终端伴侣 如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你一定对效率有着近乎偏执的追求。敲命令、查日志、管理进程、部署服务……这些重复且琐碎的操作…...

基于CircuitPython与加速度计的魔法9号球:嵌入式交互项目实践
1. 项目概述:当硬件遇上玄学,用代码打造你的专属“决策神器”在嵌入式开发的世界里,我们常常与传感器、显示屏和逻辑代码打交道,构建着一个个解决实际问题的智能设备。但谁说硬件项目就一定要严肃刻板?今天,…...