MODNet 剪枝再思考: 优化计算量的实验历程分享
目录
1 写在前面
2 模型分析
3 遇到问题
4 探索实验一
4.1 第一部分
4.2 第二部分
Error 1
Error 2
4.3 实验结果
①参数量与计算量
②模型大小
③推理时延
5 探索实验二
5.1 LR Branch
5.2 HR Branch
5.2.1 初步分析
5.2.2 第一部分 enc2x
5.2.3 第二部分 enc4x
5.2.4 第三部分 hr4x
5.2.5 第四部分 hr2x
5.2.6 第五部分
5.3 f_branch
6 总结与思考
1 写在前面
在前面两篇文章《对MODNet 主干网络 MobileNetV2的剪枝探索》《对 MODNet 其他模块的剪枝探索》中,笔者已成功对 MobileNet V2 进行剪枝并嵌入至 MODNet,其余部分也采用键值对赋值的方式成功完成了替换,得到了 MODNet 剪枝版本一代,我们简称为“V1”。V1代在推理测试中发现:模型大小、参数量的确减小了一半,但推理时延从 240ms --> 192ms 尽管降低了20%,但下降力度还不够大,既然来到了模型压缩领域,那我们就应当尽可能“压榨”深度模型!
再一次观察 MODNet 剪枝前、后的变化情况,可以发现:FLOPs在剪枝后仅减小了原来的 1/5!
考虑到相对参数量,计算复杂度 FLOPs 对推理速度的影响更大,因此,接下来对 MODNet 中 FLOPs 占比较高的层进行剪枝。
2 模型分析
从目前情况来看,下面两部分的 FLOPs 占比较高:

3 遇到问题
![]()
分析问题:网络需要的输入通道为16,但目前只获得了8个通道;
于是,通过调试,确定了权重矩阵的位置,进行修改:32 --> 16.
但这里一直存在着一个疑问:input 是如何来的?😅
按照往常的想法,上一层的输出作为下一层的输入,但这里由于正好是两个模块的交界点,因此无法满足这样的条件。所以,接下来需要找到 input 来源。(这也正是后续剪枝的基础)
通过 debug 可知,index57 的 input 源自 enc2x,如下:
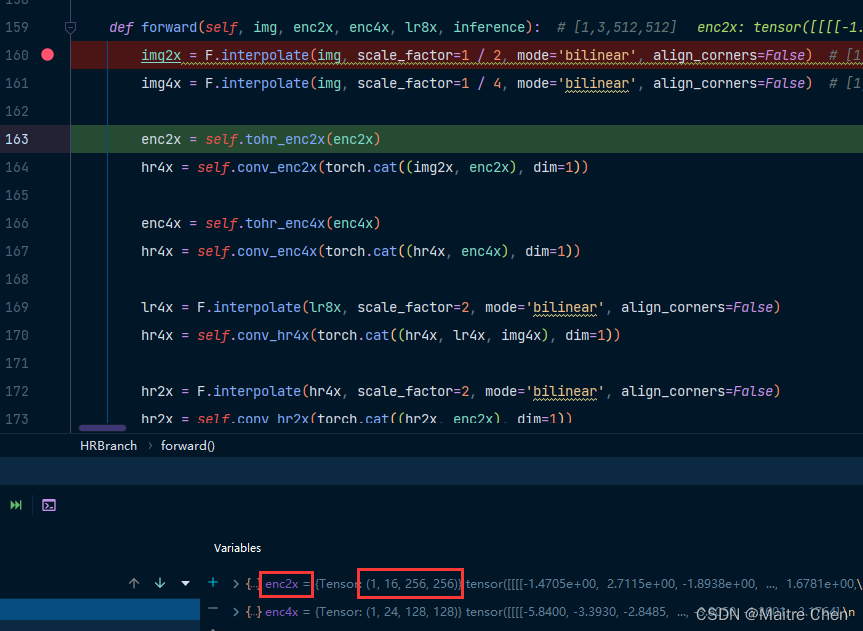
接下来,寻找 enc2x 的来源。
MODNet 定义处,通过 LR Branch 得到:

来到 LR Branch 定义处,发现是源自 backbone 的forward:

debug 得 enc2x shape [1,16,256,256],正是 backbone 中 feature1 的输出:


那么,在对 backbone 剪枝过后,feature1 的 output 变为 [1,8,256,256],故 enc2x 的输入也就变为了该 tensor。
也就是说,对 backbone 的某些 channel 裁剪后,hr branch 中的 channel 也就必须调整!
辩证法的一大特性就是联系!
既然如此,如何调整?
方式包括直接修改权重 channel、裁剪 output channel。但由于这里 input 在 backbone 裁剪后已经确定,因此直接修改权重的 channel,也就有了先前将 enc_channels 中的16---->8。
目前关于 input 的源头已确定,也就明确了对 backbone 的剪枝会决定 hr branch 中的输入!
因此,对 hr branch 中网络层的剪枝也就分为 input 以及weight:
(1)针对 input 部分
方法:直接裁剪 backbone 中对应的部分
存在的问题:需要顾及其内部的倍数关系,以及 channel 为8的倍数(倒置残差块)
(2)针对 weight 部分
方法:直接修改enc_channels
存在的问题:考虑output与下一层输入的匹配情况
4 探索实验一
✨开展思路:修改结构----->匹配结构----->模型剪枝----->参数嵌入------>模型推理
4.1 第一部分
关系:lr_branch input channel <------ Linear <-------- backbone.feature.18 (1280)
方法:按照剪枝的稀疏情况直接修改网络,满足网络层与层之间相互匹配的同时,降低FLOPs。然后,利用 NNI 对子模块中的相关层进行剪枝。
首先,将 backbone last layer 1280 --> 640,但遇到了一个问题:

先前也遇到过,为了满足上下网络层的关系匹配,又恢复到了1280。
由于相关层 FLOPs 较高,因此直接修改关联层 channels 为640。
MODNet 模型剪枝前、后的情况为:
参数量:3.36 M --> 1.87 M;
计算量:15315.94 M --> 14502.68 M
我们发现:params 大幅下降,但 FLOPs 变化不大!
4.2 第二部分
由于对 input 不能直接裁剪,因此对 weight output channel 进行裁剪。
在观察 hr branch 时,联想到了先前 MobileNet V2 部分的 interverted_residual:

在原先结构中是递增状态,因此这里遵循先前的规则,调换位置。
Error 1

由于先前已经明确了hr branch每一层的input,因此定位到相应部修改即可。
wrapper:24 --> 16
结果是计算量仅仅只是有了轻微的减少趋势:
参数量 :1.88 M;
计算量:14480.74 M
观察 hr branch 的 weight output channel,与预定义的 channels 有关:
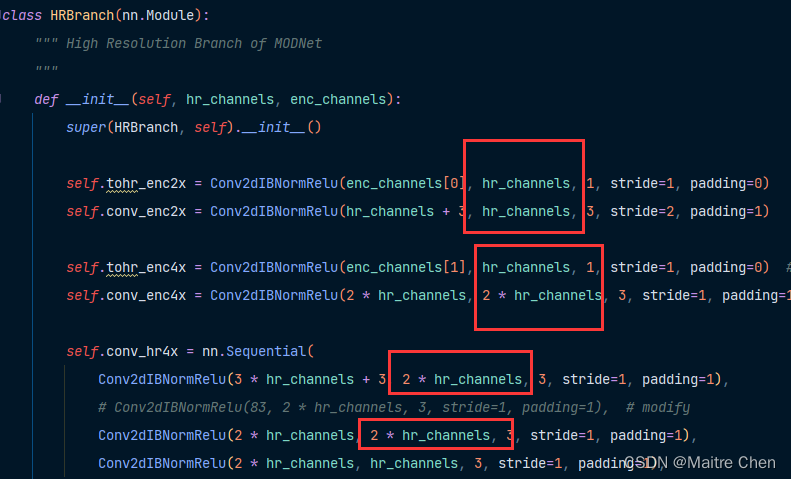
方法:直接修改channels:32 --> 24
Error 2
![]()
修改:
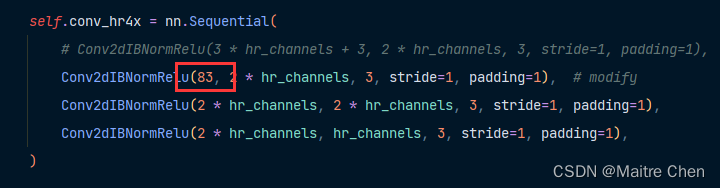
计算量相比先前的轻微减少有了明显的改进,目前达到了 8976.64 M,减小了一半:
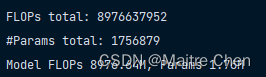
至此,我们将该模型作为 MODNet 剪枝版本二代,简称V2。
4.3 实验结果
整体改动情况:
- backbone中的last channel、wrapper、interverted_residual;
- MODNet hr_channels;
- HR Branch中的conv_hr4x;
①参数量与计算量
情况一:原模型
情况二:对 backbone 剪枝后的模型;
情况三:修改 backbone 最后一层 channel 以及 hr branch 中的 weight channel后的模型;
| 情况一 | 情况二 | 情况三 | |
|---|---|---|---|
| 参数量 | 6.45 M | 3.36 M | 1.76 M |
| 计算量 | 18117.07 M | 15315.94 M | 8976.64 M |
②模型大小
| 模型 | 模型大小 |
|---|---|
| 原模型 | 25641 K |
| V1 | 13256 K |
| V2 | 7213 K |
③推理时延
| 序号 | 原模型 | V1 | V2 |
|---|---|---|---|
| 1 | 0.85 | 0.67 | 0.54 |
| 2 | 0.88 | 0.67 | 0.56 |
| 3 | 0.84 | 0.65 | 0.54 |
5 探索实验二
由于 backbone 通道的剪枝会决定 HR branch,因此调整思路,先将 backbone 中的倒置残差块恢复到原先的情况。
5.1 LR Branch
backbone 部分修剪 last channel 1280 --> 640。
se_block、conv_lr16x,其余排除。
config 加入 Linear,将 se_block 以及 lrx 作为整体,与 backbone 剪枝。
变化如下:


读取 pth,并修改结构,验证是否可以成功加载:

加载失败,原因是涉及到了 Conv 中的 BN 层,如下:

解决方案:修改 IBNorm 定义即可。
于是,成功加载,且完成 lr_branch 的模拟推理,如下:

接下来,将 lr_branch 的参数嵌入到 MODNet,但在打印键时发现缺少了 running mean,尽管与inference 无关,但与 retrain 有关。换句话说,虽然可以成功嵌入,但对后续重训练精度的恢复有影响!

再次打印 lr_branch 参数,发现该键是存在的,但由于 model.named_parameters() 并没有获取到,因此这里采用 model.state_dict() 的方式重新嵌入。打印方式如下:
for name, params in model.state_dict().items(): print(name)
总共有751个键值对,注意 backbone 和 lr 中的 backbone,参数一致:

5.2 HR Branch
5.2.1 初步分析
将 HR Branch 划分为 5 个部分:

分析:3、4、5 部分 channel 有着明显的上、下层衔接关系;
而1、2部分从channel上看不出联系;
因此,接下来将对该 model 的5个部分分别处理,进而合并成 new branch。
5.2.2 第一部分 enc2x
利用 sequential 连接,剪枝:

无法绝对匹配,剪枝失败,源代码定义如下:

所以无法合并,考虑分层剪枝,但又存在两个问题:
- 无法对权重的input channel修改(16、35)
- 下一层的input channel(35)无法匹配
解决方案:手动剪枝
明确目标:

✨开展思路:
获取第57层,先使用 0.25 稀疏度剪枝,然后执行剪枝脚本将 input channel16 --> 8,参数保存,注意参数名 MODNet 内一致
获取58层同上,操作同上;
利用 sequential 连接 tohr 与 conv;
按照结构内的参数名,将 tohr 与 conv 参数连接,形成一个 ordereddict 格式;
将参数嵌入结构,形成第一个part;

剪枝后的参数名虽然和结构中相差了 hr,且一一对应,但填入结构仍然出现了参数初始化的情况。如下:

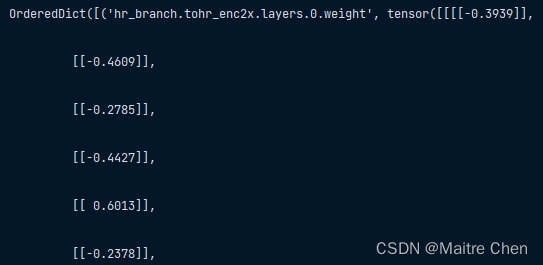
strict=false:
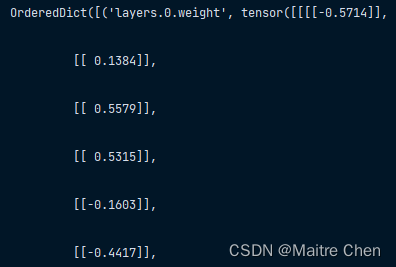
因此,这里采用键值替换进行修改。(结构不变,修改参数中的键名)
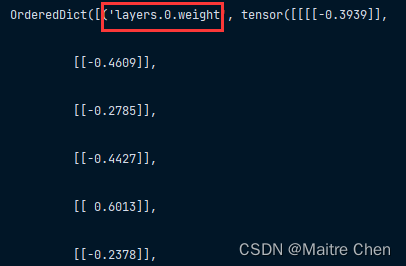
但这样的键名不利于下面的合并。
于是,笔者重新构建字典,修改键名,代码如下:
tohr_enc2x_ckpt = OrderedDict([(k.replace(k, 'hr_branch.tohr_enc2x.' + k), v) for k, v in tohr_enc2x.state_dict().items()])后来想想,这一参数(填入结构并修改参数名)和剪枝过后的是一致的,验证代码与结果如下:
for key in pruned_tohr_enc2x.keys():if tohr_enc2x_ckpt[key].equal(pruned_tohr_enc2x[key]):print("Match")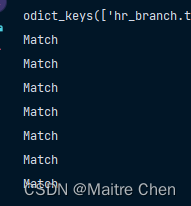
因此,这一操作意义不大。因为初心是为了与参数嵌入时命名一致,但实际上因为这一操作导致的中间过程较为繁琐。此外,剪枝过后的 pruned_tohr_enc2x 已经达到了目标状态,即shape:[24,8,1,1]
所以,第一部分两个 layer 没有连接的必要!
5.2.3 第二部分 enc4x
调整思路:NNI 剪枝 + 自定义通道剪枝 + 键名替换 + 参数嵌入
剪枝前:

剪枝后:

因此,这一部分成功嵌入!
5.2.4 第三部分 hr4x

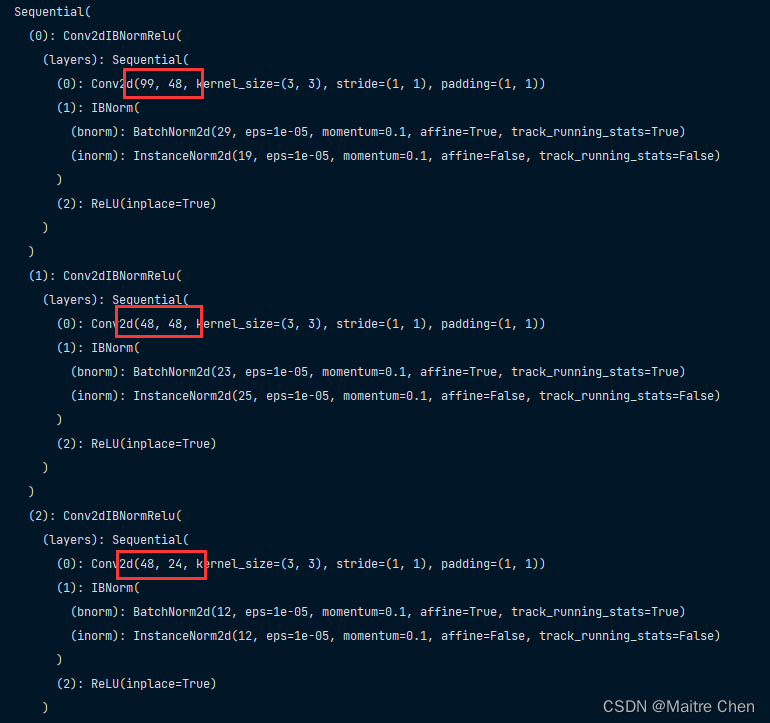
首先,channel 83 并不合理,与模型定义时产生了冲突,因此先前仅仅是为了满足模型结构做的微调。通过剪枝,除了layer 1 的weight channel,其他都可以实现。
如何将 weight 从(24,16,1,1)的尺寸裁剪为(24,8,1,1)?🥲🥲🥲
✨开展思路:
获取该层的参数,打印shape测试;
计算每一个输入通道的权重和,并排序;
将较小的8个通道去除;
创建去除后的tensor,进行参数替换;
于是,LeNet 它又来了!笔者很喜欢在 LeNet 上做一些测试。🌝
核心思想:编号 --> 排序 --> 去除通道 --> 重新编号 --> 参数替换
注意事项:①bias由 output channel 决定;②网络层类型为 OrderedDict()
测试:将输入 weight 由[6,3,3,3] -----> [4,3,3,3]
局限性:缺少稀疏度分析 + 单一层剪枝
针对 hr_branch 的第一个 layer channel(16---->8)成功剪枝!
针对第三部分 channel 99 ------->83,成功剪枝:
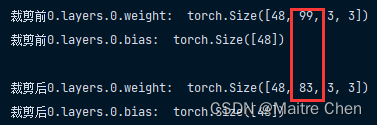
然后修改键名,与 MODNet 匹配,嵌入成功。
5.2.5 第四部分 hr2x
剪枝前:

剪枝后:

因此,这一部分成功嵌入!
5.2.6 第五部分
剪枝前:
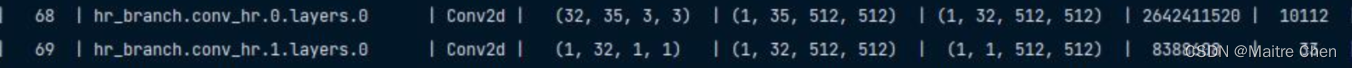
剪枝后:
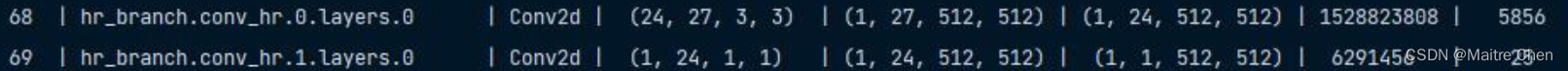
同样,这一部分成功嵌入!
5.3 f_branch
剪枝前:

剪枝后:

同时,也完成了模型嵌入,但遇到了下列问题:
💥问题一:保存的 hr branch 参数 bias 都为0、1,影响到了再训练的精度;

💥问题二:剪枝脚本仅仅针对 Conv 的 weight 以及 bias,尚未对包含于 Conv 块中的 BN 层进行处理,有待改进。

修改:针对input channel,BN层不被影响,因此直接添加如 dict 即可。
💥问题三:剪枝脚本执行后返回的网络层的名字没有和原先的匹配,这里有待处理。
修改:按照MODNet中的layer name修改,利用键值进行替换
OrderedDict([(k.replace(k, 'hr_branch.tohr_enc2x.' + k), v) for k, v in model.state_dict().items()])6 总结与思考
通过再一次分析 MODNet 网络结构,笔者发现 V1 代的剪枝版本在计算量上处理得不够好,于是,本文从计算量的角度分析,对 MODNet 网络结构中计算量占比较大的部分重新进行剪枝处理,并进行参数替换。实验结果表明,剪枝后的模型相比原模型降低了一半的计算量,推理时延也有了明显的改进,然而,模型精度并不好!
因此,关于模型剪枝后retrain精度较低的问题,笔者做了下列思考🤔🤔🤔:
(1)从剪枝本身考虑
相同情况下,大 sparse 导致更多的特征提取层无法提取到必要的特征,破坏了核心结构;
固定整体剪枝比例存在漏洞,导致有些模块去除了重要程度较高的通道;
缺少 BN 层中的 running mean 、var ,影响了再训练时的精度恢复;
解决方案:
①采用 少量剪枝---->微调---->少量剪枝------微调 的策略;
②不再采用固定整体比例剪枝,而是对特定的模块具体问题具体分析;
(2)从再训练考虑
- 由于参数的初始化以及算法的随机性,导致单一的训练无法得到较理想的效果?
- 如何准确设置超参?训练得到原模型的超参组合与剪枝后重训练的超参一样吗?
- 关于 learning rate,剪枝后,模型减小,参数减少,寻找最优解时的步长应当减小。反之,可能错过最优解。
- 是否可以设置动态参数?随着 epoch 的增加而变化?
相关文章:
MODNet 剪枝再思考: 优化计算量的实验历程分享
目录 1 写在前面 2 模型分析 3 遇到问题 4 探索实验一 4.1 第一部分 4.2 第二部分 Error 1 Error 2 4.3 实验结果 ①参数量与计算量 ②模型大小 ③推理时延 5 探索实验二 5.1 LR Branch 5.2 HR Branch 5.2.1 初步分析 5.2.2 第一部分 enc2x 5.2.3 第二部分 en…...

Flink多流转换(1)—— 分流合流
目录 分流 代码示例 使用侧输出流 合流 联合(Union) 连接(Connect) 简单划分的话,多流转换可以分为“分流”和“合流”两大类 目前分流的操作一般是通过侧输出流(side output)来实现&…...
CSS高级技巧导读
1,精灵图 1.1 为什么需要精灵图? 目的:为了有效地减少服务器接收和发送请求的次数,提高页面的加载速度 核心原理:将网页中的一些小背景图像整合到一张大图中,这样服务器只需要一次请求就可以了 1.2 精灵…...

Redis数据类型-string
Redis-string类型 Redis中的数据类型全局命令get&setredis中变量设置的过期时间是如何检测的 keysexistsdelexpirettlpexpirepttltype string数据类型的底层的数据结构操作string类型的常用命令get&setmset&mgetsetnxsetexpsetexincr&decrincrby&decrbyinc…...

【HDFS】一天一个RPC系列--updatePipeline
updatePipeline这个RPC一般都会配合updateBlockForPipeline RPC一起使用。 先updateBlockForPipeline、然后再updatePipeline。 建议先阅读【HDFS】一天一个RPC系列–updateBlockForPipeline 本文目标是弄清楚以下问题: 弄清updatePipeline这个RPC的作用。弄清updatePipeli…...

CentOS 7 上使用 wget 安装 Nginx 并设置开机自启
在 CentOS 7 上使用 wget 安装 Nginx 并设置开机自启,你可以按照以下步骤进行操作: 首先,确保你已经以 root 用户或者具有 sudo 权限的用户身份登录到 CentOS 7。 安装 Nginx 所需的依赖包。在终端中运行以下命令: sudo yum inst…...
Android源码设计模式解析与实战第2版笔记(一)
第一章 走向灵活软件之路 — 面向对象的六大原则 优化代码的第一步 — 单一职责原则 单一职责原则的英文名称是Single Responsibility Principle,缩写是SRP。 SRP:就一个类而言,应该仅有一个引起它变化的原因。 一个类中应该是一组相关性很…...
HTML+JavaScript-06
节点操作 目前对于节点操作还是有些困惑,只是了解简单的案例 具体操作可以看菜鸟教程:https://www.runoob.com/js/js-htmldom-elements.html 案例-1 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8…...
单元测试——题目十二
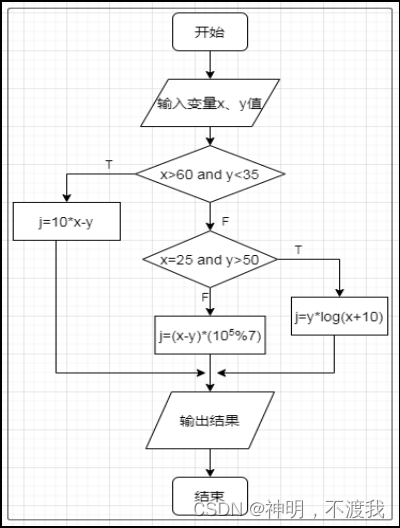
目录 题目要求: 定义类 测试类 题目要求: 根据下列流程图编写程序实现相应处理,执行j=10*x-y返回文字“j1=:”和计算值,执行j=(x-y)*(10⁵%7)返回文字“j2=:”和计算值,执行j=y*log(x+10)返回文字“j3=:”和计算值。 编写程序代码,使用JUnit框架编写测试类对编写的…...

详解:大数据信用报告信用等级怎么看?
在大数据技术的加持之下,金融风控也逐渐运用大数据技术了,也就是我们说的大数据或者大数据信用,在大数据信用报告中对个人的综合信用风险有着等级划分,那大数据信用报告信用等级怎么看呢?本文为你详细介绍一下,感兴趣…...

rsync命令常用参数详解
1、语法 Usage: rsync [OPTION]… SRC [SRC]… DEST or rsync [OPTION]… SRC [SRC]… [USER]HOST:DEST or rsync [OPTION]… SRC [SRC]… [USER]HOST::DEST or rsync [OPTION]… SRC [SRC]… rsync://[USER]HOST[:PORT]/DEST or rsync [OPTION]… [USER]HOST:SRC [DEST] or r…...

基于SpringBoot实现策略模式提供系统接口扩展能力
相信我们对策略模式都有耳闻,但是可能不知道它在项目中具体能有什么作用,我们需要在什么场景下才能去尽可能得去使用策略模式。 这里我简单的列出一个我之前在公司做的一个需求:跟第三方oa系统对接接口,对方需要回调我们当前系统…...
v43-47.problems
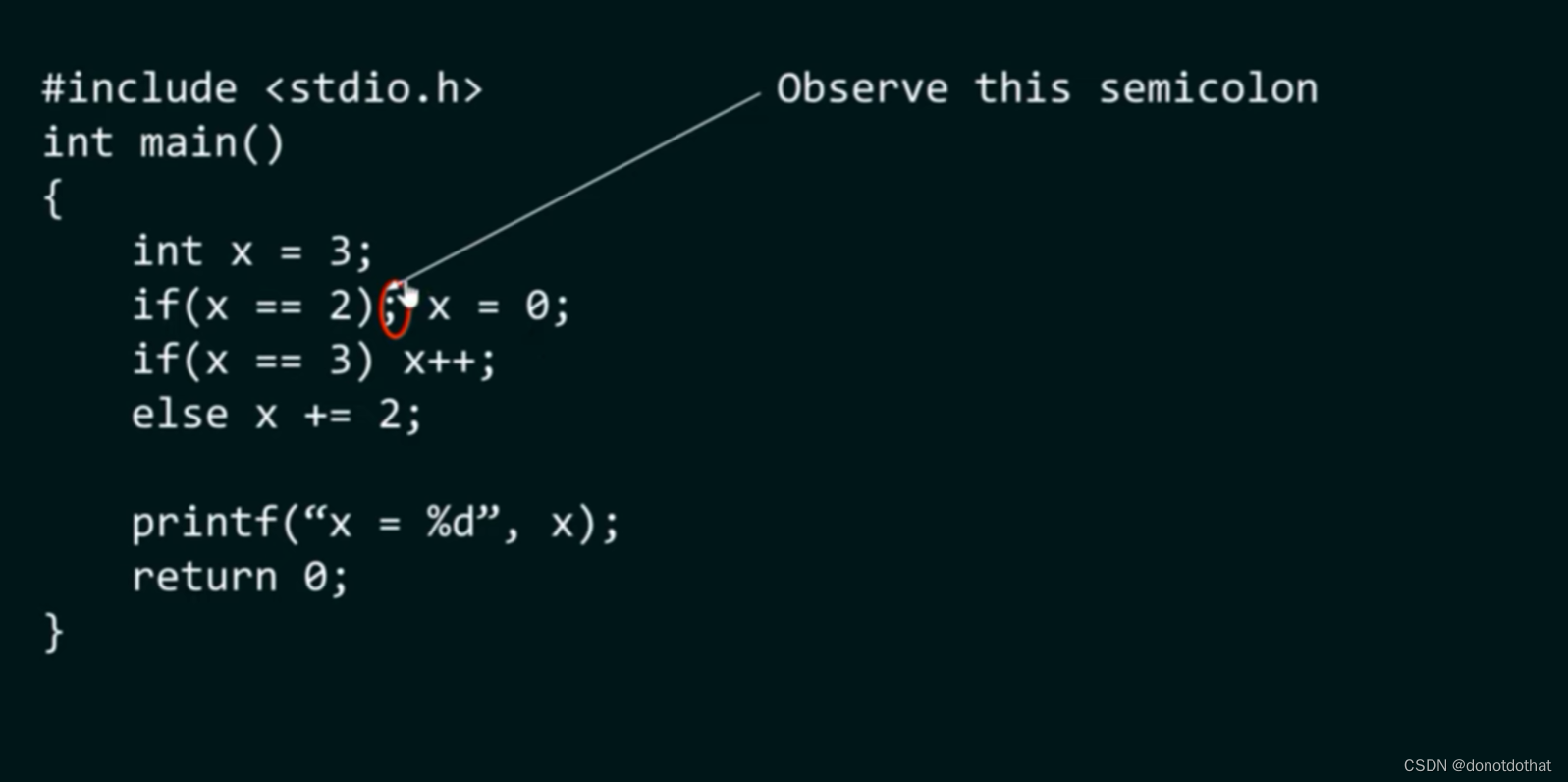
1.for循环 一般地,三步走: for(初始化;表达式判断;递增/递减) { ....... } 但是,如果说声明了全局变量,那么第一步初始化阶段可以省略但是要写分号‘ ; ’…...

华为HCIP Datacom H12-831 卷14
多选题 1、以下哪些Community属性可以保证BGP路由条目的传播范围只在AS内? A No_Export B No_Export_Subconfed C Interne D No_Advertise 正确答案 A,B 解析:Internet:缺省情况下,所有的路由都属于internet团体。具有此属性的路由可以被通告给所有的BGP对等体。n…...
)
《vtk9 book》 官方web版 第3章 - 计算机图形基础 (1 / 6)
计算机图形是数据可视化的基础。从实际角度来看,可视化是将数据转换为一组图形基元的过程。然后使用计算机图形的方法将这些基元转换为图片或动画。本章讨论了基本的计算机图形原理。我们首先描述了光线和物体如何相互作用形成我们所看到的景象。接下来,…...

负载均衡是什么,负载均衡有什么作用
一、什么是负载均衡 负载均衡是一种在计算机网络和系统架构中使用的技术,用于均衡分发工作负载到多个资源,比如:服务器、计算节点或存储设备上,以提高系统的性能、可伸缩性。 在传统的单个服务器架构中,当请求量增加…...

Leetcode 3020. Find the Maximum Number of Elements in Subset
Leetcode 3020. Find the Maximum Number of Elements in Subset 1. 解题思路2. 代码实现 题目链接:3020. Find the Maximum Number of Elements in Subset 1. 解题思路 这一题我做的是比较水的,首先就是统计下array当中各个元素出现的频次࿰…...
【Vue2 + ElementUI】更改el-select的自带的下拉图标为倒三角,并设置相关文字颜色和大小
效果图 实现 <template><div class"search_resources"><div class"search-content"><el-select class"search-select" v-model"query.channel" placeholder"请选择" change"handleResource&q…...
TensorFlow2实战-系列教程5:猫狗识别任务数据增强实例
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 1、猫狗识别任务 import os import warnings warnings.filterwarnings("ignore&…...

Unity中URP下额外灯角度衰减
文章目录 前言一、额外灯中聚光灯的角度衰减二、AngleAttenuation函数的传入参数1、参数:spotDirection.xyz2、_AdditionalLightsSpotDir3、参数:lightDirection4、参数:distanceAndSpotAttenuation.zw5、_AdditionalLightsAttenuation 三、A…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...