MYSQL中group by分组查询的用法详解(where和having的区别)!
文章目录
- 前言
- 一、数据准备
- 二、使用实例
- 1.如何显示每个部门的平均工资和最高工资
- 2.显示每个部门的每种岗位的平均工资和最低工资
- 3.显示平均工资低于2000的部门和它的平均工资
- 4.having 和 where 的区别
- 5.SQL查询中各个关键字的执行先后顺序
前言
在前面的文章中,我们介绍了MYSQL中常见的CURD操作,而今天要谈的是在select 中使用group by 子句可以对指定列进行分组查询。
一、数据准备
我们准备了3张表及以下数据进行测试:
部门表(部门编号、部门名称、地点):
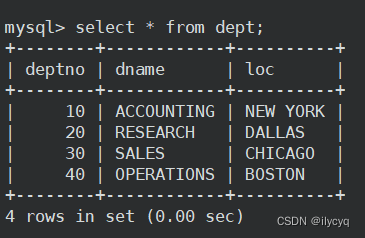
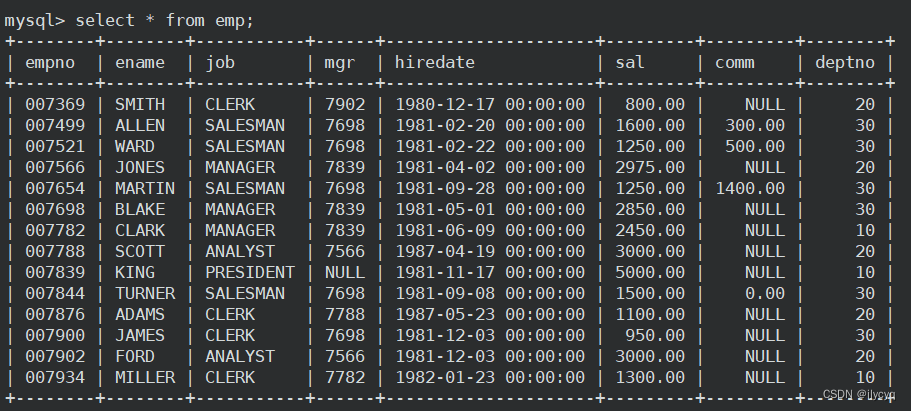
员工表(员工编号,名字,职位,领导编号,雇佣时间,月薪,奖金,部门编号):
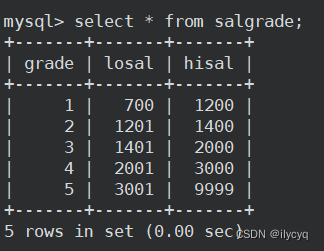
薪水等级表(等级,最低工资,最高工资):
创建实例的语句:
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;USE `scott`;DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
二、使用实例
1.如何显示每个部门的平均工资和最高工资
我们很容易拿到整张表的最高工资和平均工资,但是如果要按照每个部门来显示呢?
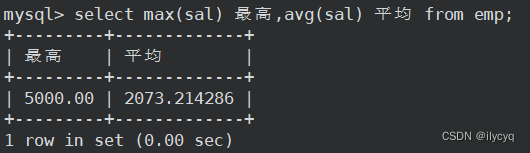
这种情况就需要用到 group by 子句来进行分组查询:
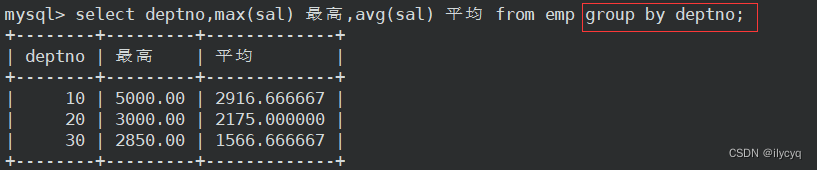
这时我们可以来理解一下分组:
- 分组的目的是为了进行分组后,方便进行聚合统计
- 指定列名分组,实际上是按照这一列数据是否相同而进行分组,相同则一组
2.显示每个部门的每种岗位的平均工资和最低工资
我们可以在 group by 后面添加多个列,同时满足这两个条件相等的数据会被分到一组:
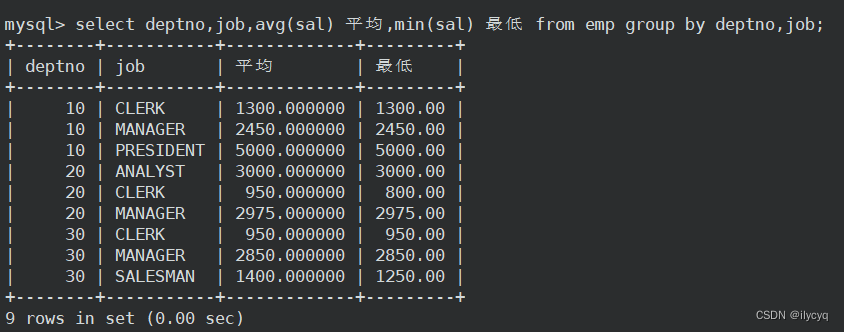
如果我们在 select 后面加上ename字段会报错:

MYSQL的报错信息是:
SELECT 列表的表达式 #1 不在 GROUP BY 子句中,并且包含非聚合列“scott.emp.ename”,
该列在功能上不依赖于 GROUP BY 子句中的列; 这与 sql_mode=only_full_group_by 不兼容
3.显示平均工资低于2000的部门和它的平均工资

这里having的功能和where类似,但如果我们换成where:

我们前面在介绍where时就说过,别名不能在where子句中使用!
4.having 和 where 的区别
我们用下面的例子来解释它们的区别:

这个语句的有5个动作,它们的顺序依此是:
- from:从emp表中进行查询
- where:对任意列进行条件筛选
- group by:进行分组
- having:对分组聚合之后的结果进行条件筛选
- select:筛选出符合条件的数据
所以我们现在很容易理解它们的区别:
- 作用时间不同:where执行优先级高于having
- 作用场景不同:having经常和group by搭配使用,作用是对分组进行筛选
但 having 作用和 where 类似,可以单独使用:
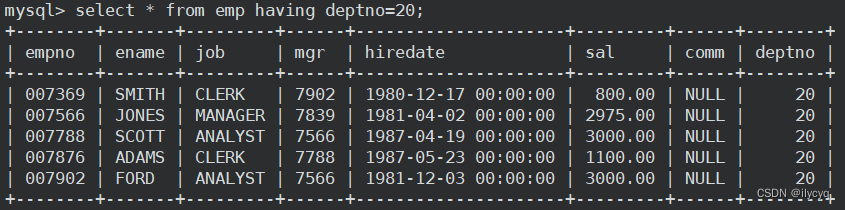
5.SQL查询中各个关键字的执行先后顺序
from > on> join > where > group by > with > having > select> distinct > order by > limit
相关文章:
MYSQL中group by分组查询的用法详解(where和having的区别)!
文章目录 前言一、数据准备二、使用实例1.如何显示每个部门的平均工资和最高工资2.显示每个部门的每种岗位的平均工资和最低工资3.显示平均工资低于2000的部门和它的平均工资4.having 和 where 的区别5.SQL查询中各个关键字的执行先后顺序 前言 在前面的文章中,我们…...
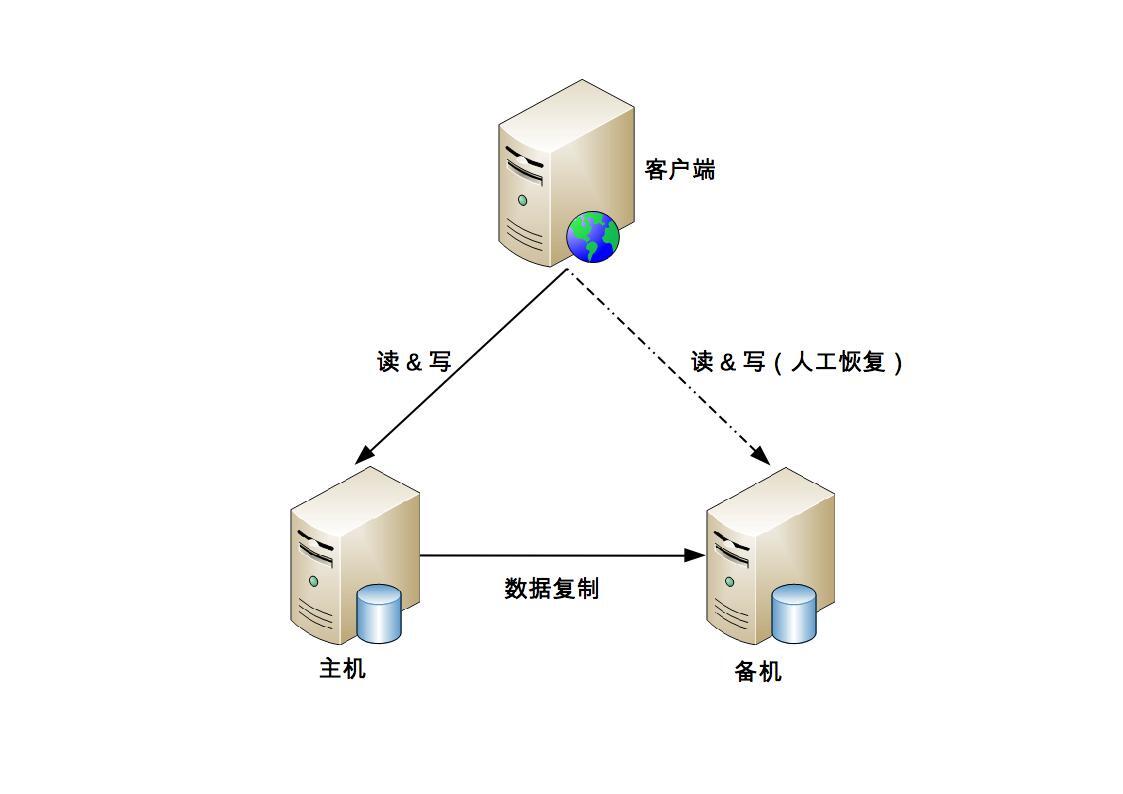
架构篇25:高可用存储架构-双机架构
文章目录 主备复制主从复制双机切换主主复制小结存储高可用方案的本质都是通过将数据复制到多个存储设备,通过数据冗余的方式来实现高可用,其复杂性主要体现在如何应对复制延迟和中断导致的数据不一致问题。因此,对任何一个高可用存储方案,我们需要从以下几个方面去进行思考…...

微信小程序(十五)自定义导航栏
注释很详细,直接上代码 上一篇 新增内容: 1.组件文件夹创建方法 2.自定义组件的配置方法 3.外部修改组件样式(关闭样式隔离或传参) 创建组件文件夹 如果是手动创建建议注意在json文件声明: mynav.json {//声明为组件可…...

Python3进行pdf文件分割及转word
今天有个pdf分割的需求,电脑装的Python3,网上查资料都是Python2的代码,所以整理一份3的 安装: pip install PyPDF2 import PyPDF2def funSplitPdf():pdf_file open(/path/fileName.pdf, rb)pdf_reader PyPDF2.PdfReader(pdf_fi…...
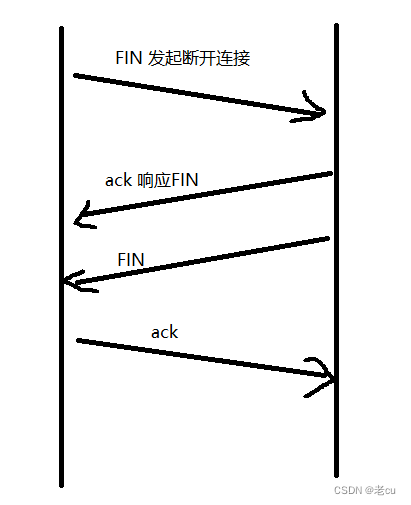
深入理解TCP网络协议(1)
目录 1.TCP协议的段格式 2.TCP原理 2.1确认应答 2.2超时重传 3.三次握手(重点) 4.四次挥手 1.TCP协议的段格式 我们先来观察一下TCP协议的段格式图解: 源/目的端口号:标识数据从哪个进程来,到哪个进程去 32位序号/32位确认号:TCP会话的每一端都包含一个32位(…...

QT 中如何使用 JSON 功能?
在 Qt 中,您可以使用 QJsonDocument、QJsonObject 和 QJsonArray 类来处理 JSON 数据。以下是一个简单的示例,说明如何在 Qt 中使用这些类来解析和生成 JSON 数据: 1. 包含必要的头文件 首先,确保您的项目中包含了必要的 Qt JSO…...

C++面试:算法的执行效率和资源消耗、时间和空间复杂度分析根据实际场景,选用合适的数据结构和算法进行程序设计
目录 算法的执行效率和资源消耗、时间和空间复杂度分析 执行效率和资源消耗 时间复杂度分析 空间复杂度分析 实际应用 面试技巧 根据实际场景,选用合适的数据结构和算法进行程序设计 所根据原则 实例 如何选择数据结构示例 合适的数据结构:哈…...

力扣100215-按键变更的次数
按键变更的次数 题目链接 解题思路 我们发现只要相邻的两个字母不一样(大小写算一样),那么按键变更次数就要加1 class Solution { public:int countKeyChanges(string s) {int ans 0;for(int i 1;i<s.size();i){if(s[i] - s[i-1] 32 || s[i] - s[i-1] -32 |…...
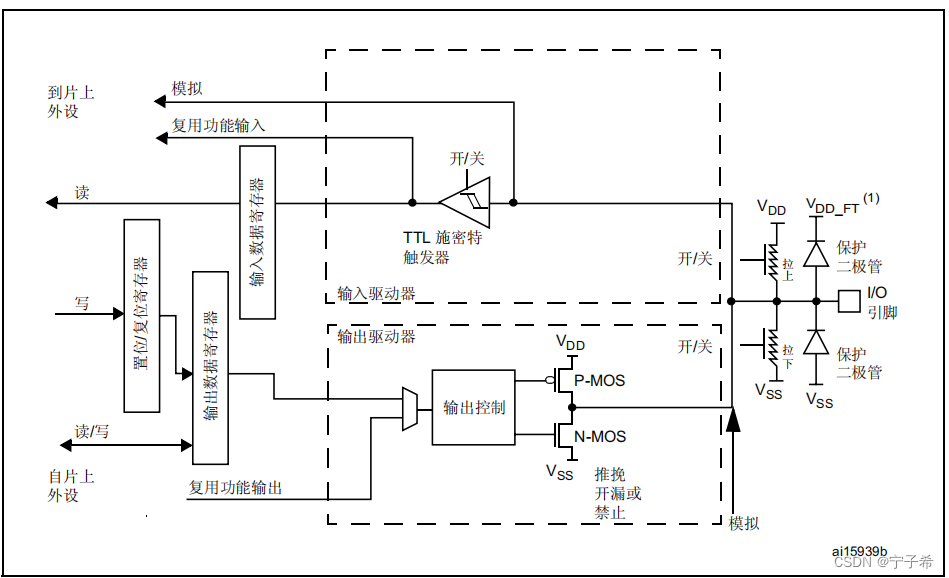
STM32-GPIO输出(HAL库)
STM32-GPIO 介绍 什么是GPIO? GPIO(通用输入/输出)是一种用于与外部设备进行数字通信的通用硬件接口。它允许微控制器或其他数字电路的引脚以灵活的方式配置为输入或输出,并在运行时进行动态控制。GPIO可用于连接和控制各种外围…...

倒计时80天
1.J-兔子不会种树_浙江机电职业技术学院第八届新生亮相赛(同步赛) (nowcoder.com) /****** __----~~~~~~~~~~~------___* . . ~~//...... __--~ ~~…...
PBM模型参数详解
本专栏着重讲解PBM学习所得,学习笔记、心得,并附有视频素材资料,视频详细目录如下: PBM相关参数解释1PBM相关参数解释2PBM相关案例实践1PBM相关案例实践2PBM相关案例实践2PBM相关案例实践3PBM多相流中次相界面设置1PBM多相流中次…...
贪吃蛇/链表实现(C/C++)
本篇使用C语言实现贪吃蛇小游戏,我们将其分为了三个大部分,第一个部分游戏开始GameStart,游戏运行GameRun,以及游戏结束GameRun。对于整体游戏主要思想是基于链表实现,但若仅仅只有C语言的知识还不够,我们还…...
)
Qlik Sense : IntervalMatch(离散匹配)
什么是IntervalMatch IntervalMatch 前缀用于创建表格以便将离散数值与一个或多个数值间隔进行匹配,并且任选匹配一个或多个额外关键值。 语法: IntervalMatch (matchfield)(loadstatement | selectstatement ) IntervalMatch (matchfield,keyfield…...

MySql45讲-08.事务到底是隔离的还是不隔离的?(结合MVCC视频)
命令的启动时机 begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作InnoDB表的语句,事务才真正启动。如果你想要马上启动一个事务,可以使用start transaction with consistent snapshot 这个命令。 事务的版本…...

备战蓝桥杯----数据结构及STL应用(基础2)
上次我们讲了vector的大致内容,接下来让我们讲一下栈,队列吧! 什么是栈呢? 很简单,我们用的羽毛球桶就是,我们取的球,是最后放的,栈是一种先进后出的数据结构。 方法函数 s.push(…...
日常学习之:vue + django + docker + heroku 对后端项目 / 前后端整体项目进行部署
文章目录 使用 docker 在 heroku 上单独部署 vue 前端使用 docker 在 heroku 上单独部署 django 后端创建 heroku 项目构建 Dockerfile设置 settings.pydatabase静态文件管理安全设置applicaiton & 中间件配置 设置 requirements.txtheroku container 部署应用 前后端分别部…...

LangGraph:一个基于LangChain构建的AI库,用于创建具有状态、多参与者的应用程序
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

04-Nacos-服务注册基于spring boot实现
官方参考 在不依赖spring cloud 组件基础上,单独的微服务项目,实现nacos接入 1、依赖文件pom.xml <dependency><groupId>com.alibaba.boot</groupId><artifactId>nacos-discovery-spring-boot-starter</artifactId><…...

iOS 闭包和Block的区别
iOS 闭包和Block的区别 原文地址: mob64ca12eb7baf 引言 在iOS开发中,闭包和Block是两个常用的概念。它们都是将一段代码作为变量传递和使用的方式。尽管它们在实现上有一些相似之处,但它们之间还是存在一些重要的区别。本文将会详细介绍闭包和Block的…...
)
后端学习笔记——后端细碎知识点(每天更新......)
细碎知识点 主要是go后端,也会设计到python、java的知识,懒得分类整理,所以都写在一篇文章里面了,方便自己查看笔记。 context.BindJSON获取POST请求中的json数据gin.H封装了生成json的方式 common.ReturnJSONSuccess(c, gin.H{&…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

03 - 变量与数据类型
03 - 变量与数据类型 变量是编程里最基础的概念,相当于你往电脑里存东西的"容器"。这章我们把变量的命名规则、Python 的几种基本数据类型都过一遍。 变量是什么 说白了,变量就是一个有名字的盒子。你往里面放个东西,以后想用这个…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...