主流排序算法
-
冒泡排序(Bubble Sort):
- 基本思想:通过比较相邻元素的大小,不断交换相邻元素的位置,使得较大的元素逐渐“浮”到数组的最后。
- 时间复杂度:O(n^2)。
-
选择排序(Selection Sort):
- 基本思想:每一次从未排序的部分中选择最小的元素,将其放在已排序部分的末尾。
- 时间复杂度:O(n^2)。
-
插入排序(Insertion Sort):
- 基本思想:将数组分为已排序和未排序两部分,每次从未排序部分选择一个元素插入到已排序部分的合适位置。
- 时间复杂度:O(n^2)。
-
快速排序(Quick Sort):
- 基本思想:通过选择一个基准元素,将数组划分为左右两部分,左边的元素都小于基准,右边的元素都大于基准,然后递归地对左右两部分进行排序。
- 时间复杂度:平均情况下为O(n log n)。
-
归并排序(Merge Sort):
- 基本思想:将数组分成两个部分,分别对这两个部分进行排序,然后合并这两个有序的部分。
- 时间复杂度:始终为O(n log n),但需要额外的空间。
-
堆排序(Heap Sort):
- 基本思想:利用堆的数据结构,将数组看作一个二叉堆,然后利用堆的性质进行排序。
- 时间复杂度:O(n log n)。
-
计数排序(Counting Sort):
- 基本思想:对每一个输入元素x,确定小于x的元素个数,从而确定x在输出序列中的位置。
- 时间复杂度:O(n + k),其中k是最大元素的范围。
-
基数排序(Radix Sort):
- 基本思想:从低位到高位,对输入元素进行多次排序,每次都是根据某一位上的数值进行排序。
- 时间复杂度:O(d * (n + k)),其中d是最大数字的位数,k是进制。
简单代码示例:
- 冒泡排序(Bubble Sort):
def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]# 示例
arr = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(arr)
print("冒泡排序结果:", arr)
- 选择排序(Selection Sort):
def selection_sort(arr):n = len(arr)for i in range(n):min_index = ifor j in range(i+1, n):if arr[j] < arr[min_index]:min_index = jarr[i], arr[min_index] = arr[min_index], arr[i]# 示例
arr = [64, 25, 12, 22, 11]
selection_sort(arr)
print("选择排序结果:", arr)
- 插入排序(Insertion Sort):
def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:arr[j + 1] = arr[j]j -= 1arr[j + 1] = key# 示例
arr = [12, 11, 13, 5, 6]
insertion_sort(arr)
print("插入排序结果:", arr)
- 快速排序(Quick Sort):
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)# 示例
arr = [3, 6, 8, 10, 1, 2, 1]
result = quick_sort(arr)
print("快速排序结果:", result)
- 堆排序(Heap Sort):
def heapify(arr, n, i):largest = ileft = 2 * i + 1right = 2 * i + 2if left < n and arr[i] < arr[left]:largest = leftif right < n and arr[largest] < arr[right]:largest = rightif largest != i:arr[i], arr[largest] = arr[largest], arr[i]heapify(arr, n, largest)def heap_sort(arr):n = len(arr)for i in range(n // 2 - 1, -1, -1):heapify(arr, n, i)for i in range(n - 1, 0, -1):arr[i], arr[0] = arr[0], arr[i]heapify(arr, i, 0)# 示例
arr = [12, 11, 13, 5, 6, 7]
heap_sort(arr)
print("堆排序结果:", arr)
- 归并排序(Merge Sort):
def merge_sort(arr):if len(arr) > 1:mid = len(arr) // 2left_half = arr[:mid]right_half = arr[mid:]merge_sort(left_half)merge_sort(right_half)i = j = k = 0while i < len(left_half) and j < len(right_half):if left_half[i] < right_half[j]:arr[k] = left_half[i]i += 1else:arr[k] = right_half[j]j += 1k += 1while i < len(left_half):arr[k] = left_half[i]i += 1k += 1while j < len(right_half):arr[k] = right_half[j]j += 1k += 1# 示例
arr = [12, 11, 13, 5, 6, 7]
merge_sort(arr)
print("归并排序结果:", arr)
- 计数排序(Counting Sort):
def counting_sort(arr):output = [0] * len(arr)count = [0] * (max(arr) + 1)for i in arr:count[i] += 1for i in range(1, len(count)):count[i] += count[i - 1]i = len(arr) - 1while i >= 0:output[count[arr[i]] - 1] = arr[i]count[arr[i]] -= 1i -= 1for i in range(len(arr)):arr[i] = output[i]# 示例
arr = [4, 2, 2, 8, 3, 3, 1]
counting_sort(arr)
print("计数排序结果:", arr)
- 基数排序(Radix Sort):
def counting_sort_for_radix(arr, exp):n = len(arr)output = [0] * ncount = [0] * 10for i in range(n):index = arr[i] // expcount[index % 10] += 1for i in range(1, 10):count[i] += count[i - 1]i = n - 1while i >= 0:index = arr[i] // expoutput[count[index % 10] - 1] = arr[i]count[index % 10] -= 1i -= 1for i in range(n):arr[i] = output[i]def radix_sort(arr):max_num = max(arr)exp = 1while max_num // exp > 0:counting_sort_for_radix(arr, exp)exp *= 10# 示例
arr = [170, 45, 75, 90, 802, 24, 2, 66]
radix_sort(arr)
print("基数排序结果:", arr)
相关文章:

主流排序算法
冒泡排序(Bubble Sort): 基本思想:通过比较相邻元素的大小,不断交换相邻元素的位置,使得较大的元素逐渐“浮”到数组的最后。时间复杂度:O(n^2)。 选择排序(Selection Sort…...

MySql的使用方法
一.什么是MySql MySql是一种数据库管理系统,是用来存储数据的,可以有效的管理数据,数据库的存储介质为硬盘和内存。 和文件相比,它具有以下优点: 文件存储数据是不安全的,且不方便数据的查找和管理…...
C#,数据检索算法之三元搜索(Ternary Search)的源代码
数据检索算法是指从数据集合(数组、表、哈希表等)中检索指定的数据项。 数据检索算法是所有算法的基础算法之一。 本文发布 三元搜索(Ternary Search)的源代码。 1 文本格式 using System; namespace Legalsoft.Truffer.Algo…...

windbg:常用指令
windbg 调试 参考文档 1、viewing-and-editing-global-variables-in-windbg WinDBG 常用调试命令 加载符号 .sympath // 查看当前符号查找路径 .sympath c:\symbols // 将符号查找路径设为:c:\symbols .sympath c:\symbols // 将c:\symbols添加…...

23. 集合类
集合 1. 概述2. 分类2.1 单列集合(Collection)2.2 双列集合(Map) 单列集合 Collection、List、Set、ArrayList、LinkedList’、Vector、HashSet、TreeSet、LinkedHashSet双列集合 Map、HashTable、HashMap、TreeMap、Properties、…...

OpenAI平台:引领人工智能的创新与应用
在当今迅速发展的技术世界中,OpenAI已成为人工智能(AI)研究和应用的先驱。作为一个致力于确保人工智能的安全和广泛受益的组织,OpenAI通过其平台提供了一系列强大的工具和API,这些工具和API正在重塑我们与技术的互动方…...
Lua语言)
redis原理(五)Lua语言
一、介绍: 1、背景: 在 Redis 的 2.6 以上版本中,除了可以使用命令外,还可以使用 Lua 语言操作 Redis。 Redis 命令的计算能力并不算很强大,而使用 Lua 语言则在很大程度上弥补了 Redis 的这个不足。 2、特点&#…...

SOHO外贸怎么建网站?做海洋建站的步骤?
SOHO外贸如何做跨境独立站?搭建外贸自建站的策略? 一位成功的SOHO外贸从业者不仅需要精湛的贸易技能,还需要一个优质的网站来展示产品、与客户互动,并建立强大的在线品牌形象。海洋建站将探讨在SOHO外贸领域如何建立一个成功的网…...
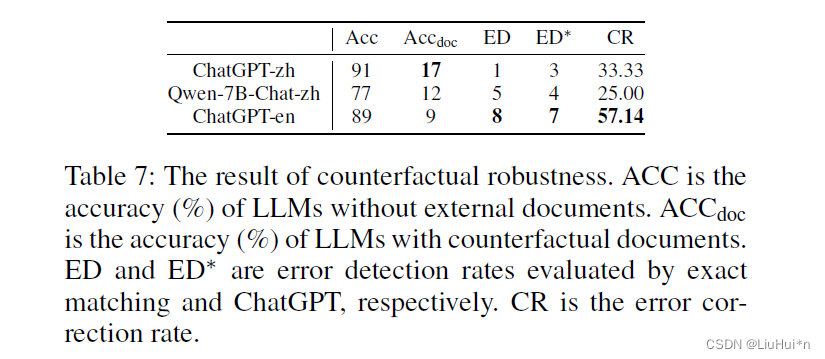
[论文阅读] |RAG评估_Retrieval-Augmented Generation Benchmark
写在前面 检索增强能够有效缓解大模型存在幻觉和知识时效性不足的问题,RAG通常包括文本切分、向量化入库、检索召回和答案生成等基本步骤。近期组里正在探索如何对RAG完整链路进行评估,辅助阶段性优化工作。上周先对评估综述进行了初步的扫描࿰…...
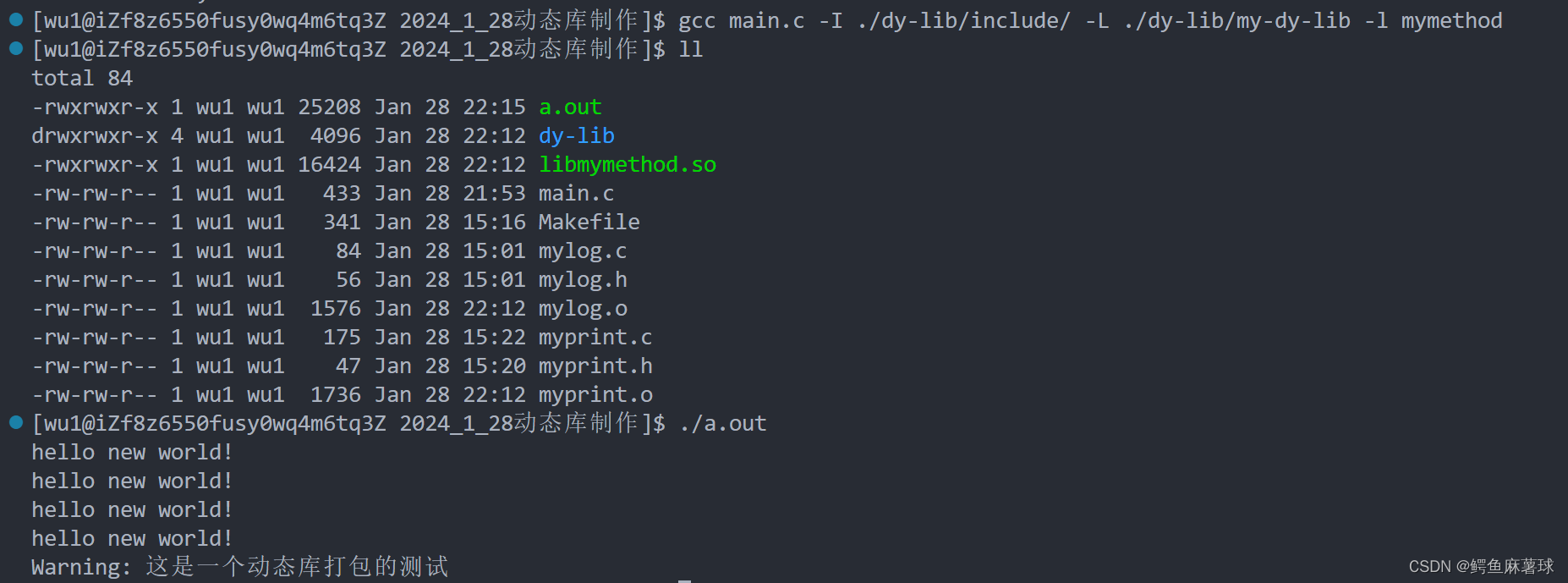
【Linux】动态库和静态库——动态库和静态库的打包和使用、gcc编译、拷贝到系统默认的路径、建立软连接
文章目录 动态库和静态库1.静态库和动态库的介绍2.静态库的打包和使用2.1生成静态库2.2使用静态库的三种方式2.2.1gcc编译2.2.2拷贝到系统默认的路径2.2.3建立软连接 3.动态库的打包和使用3.1生成动态库3.2使用动态库3.3解决加载不到动态库的方法 动态库和静态库 1.静态库和动…...

【Redis】Redis有哪些适合的场景
🍎个人博客:个人主页 🏆个人专栏:Redis ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 (1)会话缓存(Session Cache) (2)全页缓存(FPC…...
uniapp上传音频文件到服务器
视频教程地址: 【uniapp录音上传组件,将录音上传到django服务器】 https://www.bilibili.com/video/BV1wi4y1p7FL/?share_sourcecopy_web&vd_sourcee66c0e33402a09ca7ae1f0ed3d5ecf7c uniapp 录制音频文件上传到django服务器保存到服务器 …...

C#-正则表达式
1.C#功能点: 验证格式:通过正则表达式,我们可以检查一个字符串是否符合特定的格式要求,例如验证邮箱、电话号码、身份证号码等。 查找和提取:我们可以使用正则表达式来查找字符串中符合特定模式的部分,并将…...
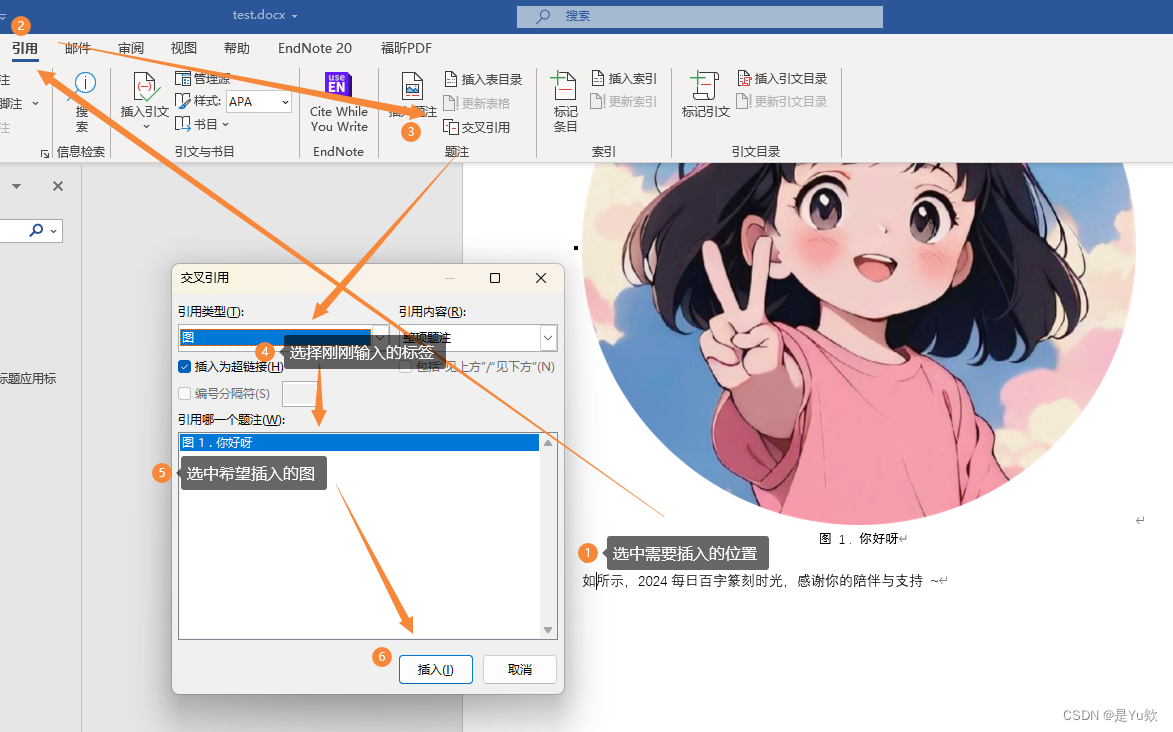
【word】论文、报告:①插入图表题注,交叉引用②快速插入图表目录③删改后一键更新
【word】①插入图表题注,②删改后一键更新 写在最前面插入题注交叉引用修改插入题注的文字格式快速插入图表目录 插入题注后有删改,实现编号一键更新 🌈你好呀!我是 是Yu欸 🌌 2024每日百字篆刻时光,感谢你…...

Spring Security 的TokenStore三种实现方式
博主介绍:✌专注于前后端领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦&…...

微信小程序 图片自适应高度 宽度 完美适配原生或者uniapp
-- - - - 查了一下百度看到网上图片高度自适应的解决方案 基本是靠JS获取图片的宽度进行按比例计算得出图片高度。 不是很符合我的需求/ 于是我脑瓜子一转 想到一种新的解决方案 不用JS计算也能完美解决。 我写了一个组件,直接导入可以使用。 - - - 1.新…...

Go语言基础之反射
1.变量的内在机制 Go语言中的变量是分为两部分的: 类型信息:预先定义好的元信息。值信息:程序运行过程中可动态变化的。 2.反射介绍 反射是指在程序运行期间对程序本身进行访问和修改的能力。程序在编译时,变量被转换为内存地址ÿ…...

MySQL十部曲之六:数据操作语句(DML)
文章目录 前言语法约定DELETEINSERTSELECT查询列表SELECT 选项子句FROMWHEREORDER BYGROUP BYHAVINGWINDOWLIMITFOR SELECT ... INTO连接查询CROSS JOIN和INNER JOINON和USINGOUTER JOINNATURE JOIN 子查询标量子查询使用子查询进行比较带有ANY、IN或SOME的子查询带有ALL的子查…...
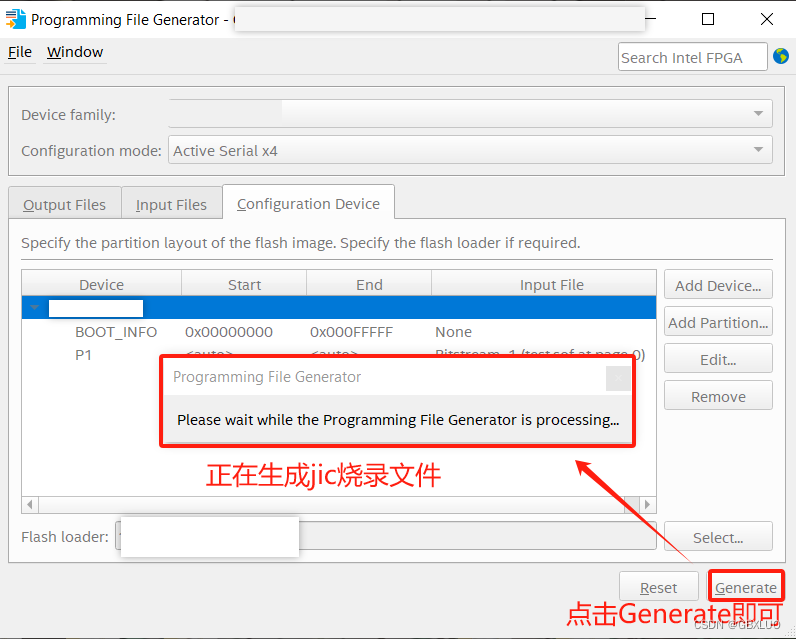
Quartus生成烧录到FPGA板载Flash的jic文件
简要说明: Altera的FPGA芯片有两种基本分类,一类是纯FPGA,另一类是FPGASoc(System on chip),也就是FPGAHPS(Hard Processor System,硬核处理器),对应两种Flash烧录方式&a…...

CSS 多色正方形上升
<template><view class="loop cubes"><view class="item cubes"></view> <!-- 方块1 --><view class="item cubes"></view> <!-- 方块2 --><view class="item cubes"></vie…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...