Elasticsearch的RESTful Api使用
Elasticsearch的RESTful Api使用
文章目录
- Elasticsearch的RESTful Api使用
- 查询集群健康情况
- 查看所有索引
- 其他的_cat命令
- 创建索引
- 删除索引
- 修改索引
- 查看索引
- 创建文档
- 批量操作文档
- 删除文档
- 查询文档
- 全量更新文档
- 局部更新文档
- 索引的搜索
- 分词分析
- 分数说明
- 查询类型分析
查询集群健康情况
GET /_cat/health?v
?v表示显示头信息
参数说明:
- cluster:集群名称
- status:集群状态 green 集群一切正常;yellow 集群不可靠但可用;red 集群不可用,有故障
- node.total:节点总数量
- node.data:数据节点的数量
- shards:存活的分片数量
- pri:主分片数量
- relo:迁移中的分片数量
- init:初始化中的分片数量
- unassign:未分配的分片
- pending_tasks:准备中的任务
- max_task_wait_time:任务最长等待时间
- active_shards_percent:激活的分片百分比
查看所有索引
GET /_cat/indices?v
若响应health status index uuid pri rep docs.count docs.deleted store.size pri.store.size说明集群中还没有索引
- health:索引状态 green 集群完整;yellow 单点正常、集群不完整;red 单点不正常
- status:是否能使用
- index:索引名
- uuid:索引统一编号
- pri:主节点几个分片
- rep:从节点几个(副本数)
- docs.count:文档数
- docs.deleted:文档被删了多少
- store.size:整体占空间大小
- pri.store.size:主节点占空间大小
其他的_cat命令
| 命令 | 描述 |
|---|---|
| /_cat/allocation | 查看单节点的shard分配整体情况 |
| /_cat/shards | 查看所有shard的详细情况 |
| /_cat/shards/{index} | 查看指定分片的详细情况 |
| /_cat/master | 查看master节点信息 |
| /_cat/nodes | 查看所有节点信息 |
| /_cat/indices/{index} | 查看集群中指定index的详细信息 |
| /_cat/segments | 查看各index的segment详细信息,包括segment名,所属shard,内存(磁盘)占用大小,是否刷盘 |
| /_cat/segments/{index} | 查看指定index的segment详细信息 |
| /_cat/count | 查看当前集群的doc数量 |
| /_cat/count/{index} | 查看指定索引的doc数量 |
| /_cat/recovery | 查看集群内每个shard的修复状态 |
| /_cat/recovery/{index} | 查看指定索引shard的修复状态 |
| /_cat/pending_tasks | 查看当前集群的pending task |
| /_cat/aliases | 查看集群中所有alias信息,路由配置等 |
| /_cat/aliases/{alias} | 查看指定索引的alias信息 |
| /_cat/thread_pool | 查看集群各节点内部不同类型的threadpool的统计信息 |
| /_cat/plugins | 查看集群各个节点上的plugin信息 |
| /_cat/fielddata | 查看当前集群各个节点的fielddata内存使用情况 |
| /_cat/fielddata/{fields} | 查看指定field的内存使用情况,里面传field属性对应的值 |
| /_cat/nodeattrs | 查看单节点的自定义属性 |
| /_cat/repositories | 输出集群中注册快照存储库 |
| /_cat/templates | 输出当前正在存在的模板信息 |
创建索引
PUT /movie?pretty
?pretty表示格式化JSON响应
索引名称长度不超过255个字符,不可使用特殊字符,可使用下划线(_)、加号(+)、减号(-)但不可以以它们开头。
可以在创建索引时定义mapping等属性,search_analyzer属性默认与analyzer属性一致:
PUT /movie
{"mappings": {"properties": {"actorList": {"properties": {"gender": {"type": "long"},"name": {"type": "text","analyzer": "ik_max_word"}}},"doubanScore": {"type": "float"},"id": {"type": "long"},"name": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}
}
删除索引
DELETE /movie
修改索引
已经存在的mapping属性是无法修改的,只能做新增,例如下面修改分析器的操作就会失败:
POST /movie/_mappings
{"properties": {"name": {"type": "text","analyzer": "standard","search_analyzer": "standard"}}
}
会报与已存在mapper冲突的错误:
{"error": {"root_cause": [{"type": "illegal_argument_exception","reason": """Mapper for [name] conflicts with existing mapper:Cannot update parameter [analyzer] from [ik_max_word] to [standard]"""}],"type": "illegal_argument_exception","reason": """Mapper for [name] conflicts with existing mapper:Cannot update parameter [analyzer] from [ik_max_word] to [standard]"""},"status": 400
}
查看索引
GET /movie
查看索引自身信息,包括mappings、settings等,可以直接指定端点查询GET /movie/_mappings
创建文档
POST /movie/_doc/1
{"id": 100,"name": "流浪地球","doubanScore": 7.9,"actorList": [{"gender": 1,"name": "吴京"},{"gender": 1,"name": "吴孟达"}]
}
可以指定文档ID,不指定由系统随机生成ID串
批量操作文档
Elasticsearch支持使用_bulk端点批量操作文档,奇数行是操作描述,偶数行是文档数据,当索引不存在时会自动创建
- create 如果文档不存在就创建,但如果文档存在就返回错误
- index 如果文档不存在就创建,如果文档存在就更新
- update 更新一个文档,如果文档不存在就返回错误
- delete 删除一个文档,如果要删除的文档id不存在,就返回错误
POST /movie/_bulk
{"create":{"_id":1}}
{"id":100,"name":"流浪地球","doubanScore":7.9,"actorList":[{"gender":1,"name":"吴京"},{"gender":1,"name":"吴孟达"}]}
{"create":{"_id":2}}
{"id":200,"name":"流浪地球2","doubanScore":8.2,"actorList":[{"gender":1,"name":"吴京"},{"gender":1,"name":"沙溢"}]}
{"create":{"_id":3}}
{"id":300,"name":"满江红","doubanScore":7.4,"actorList":[{"gender":1,"name":"张译"}]}
也可以这样操作,姿势很多
POST /_bulk
{"create":{"_index":"movie","_id":1}}
{"id":100,"name":"流浪地球","doubanScore":7.9,"actorList":[{"gender":1,"name":"吴京"},{"gender":1,"name":"吴孟达"}]}
{"create":{"_index":"movie","_id":2}}
{"id":200,"name":"流浪地球2","doubanScore":8.2,"actorList":[{"gender":1,"name":"吴京"},{"gender":1,"name":"沙溢"}]}
{"create":{"_index":"movie","_id":3}}
{"id":300,"name":"满江红","doubanScore":7.4,"actorList":[{"gender":1,"name":"张译"}]}
当然也可以先创建索引再进行_bulk
删除文档
DELETE /movie/_doc/1
查询文档
GET /movie/_doc/1
全量更新文档
PUT /movie/_doc/1
{"id": 100,"name": "流浪地球","doubanScore": 8,"actorList": [{"gender": 1,"name": "吴京"},{"gender": 1,"name": "吴孟达"},{"gender": 0,"name": "李光洁"}]
}
局部更新文档
POST /movie/_update/1
{"doc": {"doubanScore": 8}
}
索引的搜索
GET /movie/_search
共有两种:
- URI Search
- 操作简便,方便通过命令行测试
- 但是仅包含部分查询语法
- Request Body Search
- es 最常用的方式,查询丰富。
- 提供的完备查询语法Query DSL(Domain Specific Language)
分词分析
帮助分析某个analyzer是如何分析和索引一段文字
POST _analyze
{"analyzer": "standard","text": "我们都是中国人"
}
分数说明
提供查询结果的分数说明
GET /movie/_explain/1
{"query": {"match": {"name": "流浪地球"}}
}
查询类型分析
通过profile属性,分析查询类型为PhraseQuery、TermQuery、BooleanQuery等类型中的哪一种
GET /movie/_search?q=name:(地球 红)
{"profile": true
}
相关文章:

Elasticsearch的RESTful Api使用
Elasticsearch的RESTful Api使用 文章目录Elasticsearch的RESTful Api使用查询集群健康情况查看所有索引其他的_cat命令创建索引删除索引修改索引查看索引创建文档批量操作文档删除文档查询文档全量更新文档局部更新文档索引的搜索分词分析分数说明查询类型分析查询集群健康情况…...

软著申请需要注意的
一、文档格式 (1)程序源代码和说明文档,源码前后30页,文档前后30页。 (2)软件源代码和说明书的页眉必须标明软件名称、版本号和页码,应当与申请表中相应内容完全一致 (3)…...

SpringBoot入门 - 添加Logback日志
SpringBoot开发中如何选用日志框架呢? 出于性能等原因,Logback 目前是springboot应用日志的标配; 当然有时候在生产环境中也会考虑和三方中间件采用统一处理方式。日志框架的基础在学习这块时需要一些日志框架的发展和基础,同时了…...

社会实践报告
中文摘要: 注重素质教育的今天,社会实践活动一直被视为高校培养德、智、体、美、劳全面发展的跨 世纪优秀人才的重要途径。团期社会实践活动是学校教育向课堂外的一种延伸,也是推进素质教育进程的重 手段。它有助于当代大学生接触社会,了解社…...

LeetCode 460. LFU 缓存 -- 哈希查询+双向链表
LFU 缓存 困难 634 相关企业 请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。 实现 LFUCache 类: LFUCache(int capacity) - 用数据结构的容量 capacity 初始化对象 int get(int key) - 如果键 key 存在于缓存中,则获取键…...

Dubbo 源码分析 – SPI 机制
1.简介 SPI 全称为 Service Provider Interface,是一种服务发现机制。SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口 加载实现类。正因此特性࿰…...
JDBC概述二(JDBC编程+案例展示)
一(JDBC的编程步骤) 1.加载数据库驱动 加载数据库驱动通常使用class类的静态方法forName()来实现,具体实现方式如下: Class.forName(“DriverName”),DriverName就是数…...

广度和深度优先搜索解析与示例代码
一,什么是搜索算法 算法是基于特定数据结构之上的,深度优先搜索算法和广度优先搜索算法都是基于“图”这种数据结构的。 树是图的一种特例(连通无环的图就是树)。 图上的搜索算法,最直接的理解就是,在图中找出从一个顶点出发,到另一个顶点的路径。具体方法有很多,两种…...
基于SLIC超像素的归一化分割算法
论文:基于SLIC超像素的归一化分割方法研究 归一化分割的缺点:单独使用时无法区分很接近的图像区域,实时性也差。 区域接近问题:描述图像间相互关系的权重函数的取值,体现图像间的信息特征,影响分割效果。…...

C语言刷题(4)——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容又到了我们的复习啦,那么还是刷题噢,话不多说,让我们进入C语言的世界吧 BC55 简单计算器 BC56 线段图案 BC57 正方形图案 BC58 直角三角形图案 BC59 翻转直角三角形图案 BC60 带空格…...
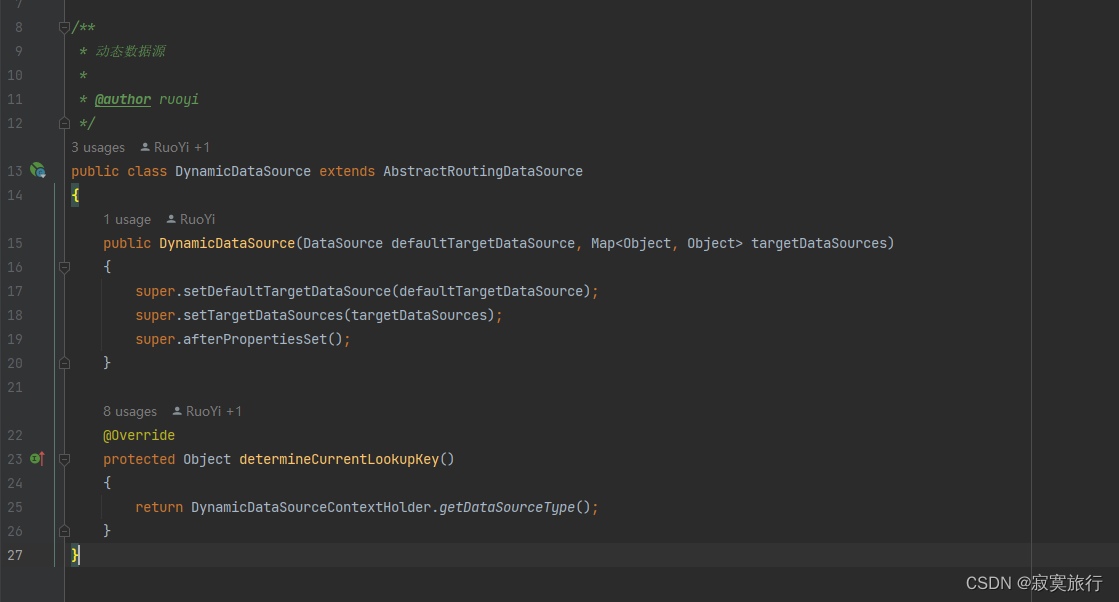
带你看懂RuoYi动态数据源切换
文章目录数据源是什么一、spring中是如何处理各种数据源的?1.开搞springboot2.创建一个测试类二、有了如上的理论,那么想想动态切换数据源吧参考若依的动态数据源配置总结数据源是什么 数据源,对于java来说,就是可用的数据库,那么我平时开发的springboot springclo…...

家有女儿必看:盲目的和青春期女儿较劲,不如掌握4个沟通技巧
导读:家有女儿必看:盲目的和青春期女儿较劲,不如掌握4个沟通技巧 各位点开这篇文章的朋友们,想必都是很高的颜值吧,我们真的是很有缘哦,小编每天都会给大家带来不一样的育儿资讯,如果对小编的文…...

【VC 7/8】vCenter Server 基于文件的备份和还原Ⅰ——基于文件的备份和还原的注意事项和限制
目录1.1 协议1.2 还原后配置说明1.3 Storage DRS1.4 分布式电源管理1.5 分布式虚拟交换机1.6 内容库1.7 虚拟机生命周期操作1.8 vSphere High Availability1.9 基于存储策略的管理1.10 其它注意事项虚拟存储区域网络修补关联博文[图片来源]:https://www.vmignite.co…...

【ROS学习笔记10】ROS中配置自定义Cpp头文件和导入自定义Python库
【ROS学习笔记10】ROS中配置自定义Cpp头文件和导入自定义Python库 文章目录【ROS学习笔记10】ROS中配置自定义Cpp头文件和导入自定义Python库一、ROS中的头文件和源文件1.1 自定义头文件调用1.2 自定义源文件调用二、Python模块的导入Reference写在前面,本系列笔记参…...

svn 分支(branch)和标签(tag)管理
版本控制的一大功能是可以隔离变化在某个开发线上,这个开发线就是分支(branch)。分支通常用于开发新功能,而不会影响主干的开发。也就是说分支上的代码的编译错误、bug不会对主干(trunk)产生影响。然后等分…...
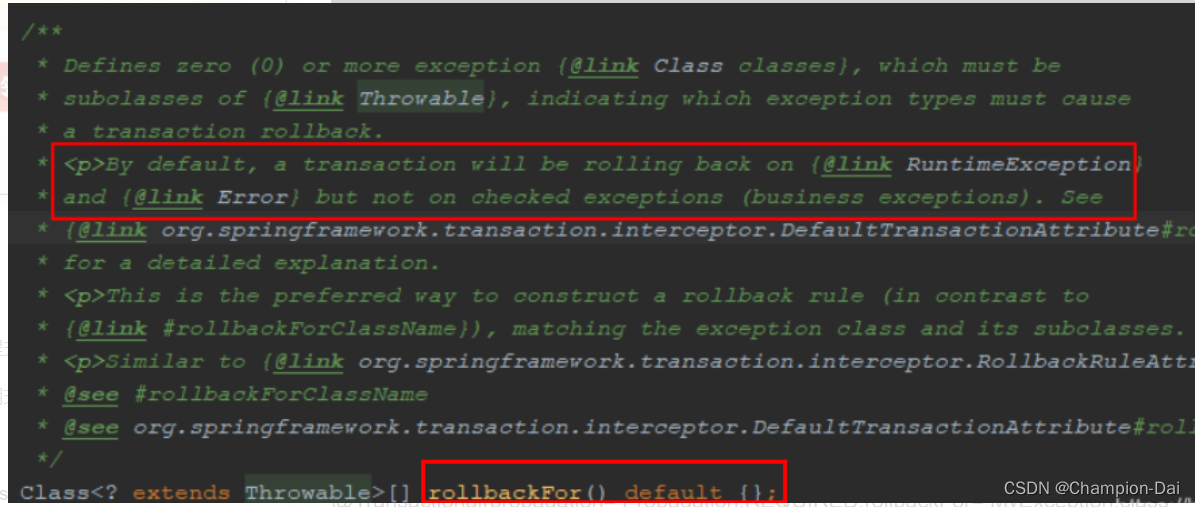
@Transactional详解
一、事务的概念 百度百科: 事务(Transaction),一般是指要做的或所做的事情。在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执 行单元(unit)。事务通常由高级数据库操纵语言或编程语言(如SQL&#x…...
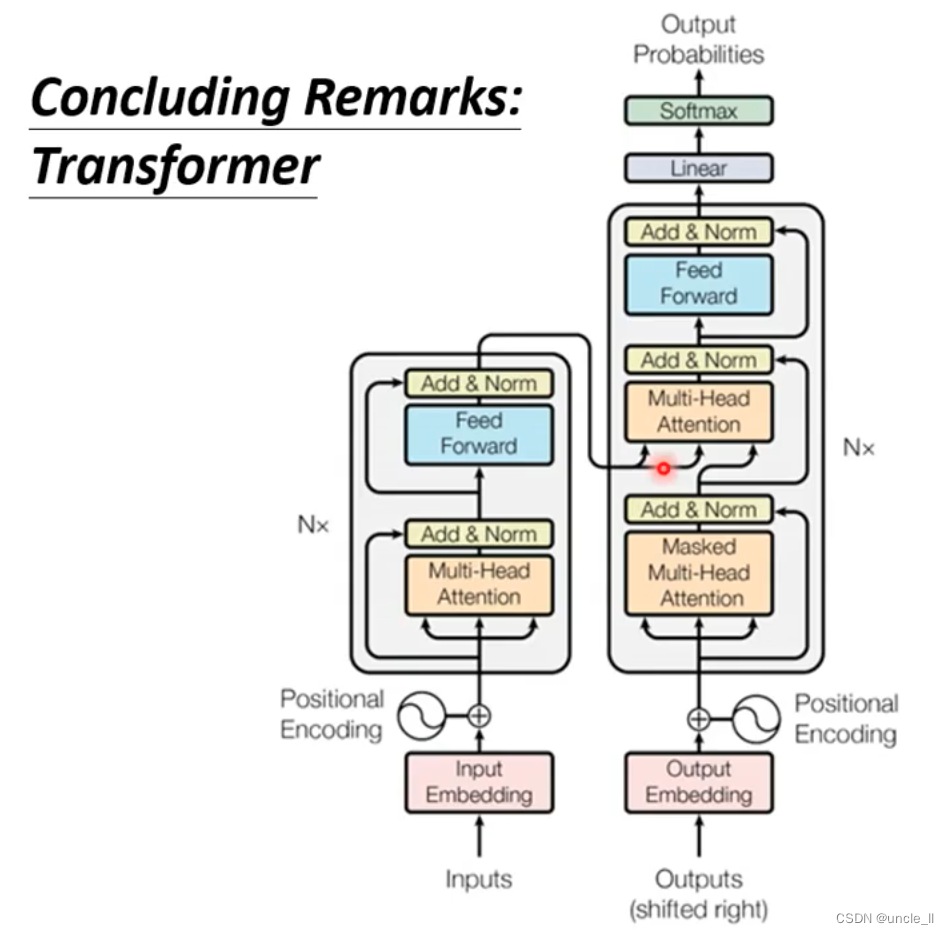
机器学习:Transformer
Transformer sequence-to-sequence(seq2seq) 很大语音没有文本,7000种中超半数没有文字。 遇到的问题: 遇到问题时候可以先不管它,先出一个baseline看看效果,后续再进行提升。 tts: 文本转语音,语音合成…...

pytorch-模型构建,参数访问,模型存取API接口,对比学习
多层感知机的简洁实现pytorch-多层感知机,最简单的深度学习模型,将非线性激活函数引入到模型中。_羞儿的博客-CSDN博客中含单隐藏层的多层感知机的实现方法。首先构造Sequential实例,然后依次添加两个全连接层。其中第一层的输出大小为256&am…...

javaEE 初阶 — 数据链路层中的以太网数据帧
文章目录以太网帧格式1. MAC 地址2. MAC 地址是如何与 IP 地址相互配合的3. 以太网帧格式中的类型MTU(了解)以太网帧格式 数据链路层主要考虑的是相邻的两个结点之间的传输。 这里最知名的协议就是 以太网。 一个以太网数据帧有三个部分组成。帧头载荷…...
泼辣修图Polarr5.11.4 版,让你的创意无限延伸
泼辣修图是一款非常实用的图片处理软件,它不仅拥有丰富的图片处理功能,而且还能够轻松地实现自定义操作。泼辣修图的操作界面非常简洁,功能也非常丰富,使用起来非常方便快捷。 泼辣修图拥有非常丰富的图片处理功能,包括…...

【实战篇】Nginx核心配置与性能优化全攻略
1. Nginx基础配置快速上手 第一次接触Nginx时,我被它简洁的配置文件结构惊艳到了。相比其他Web服务器动辄几百行的配置,Nginx的配置文件就像一份精心设计的菜谱,每个指令都恰到好处。先带大家看看最基本的配置结构: # 全局块 user…...

如何解决ViPER4Windows兼容性难题?5步打造Windows 10/11音效增强终极方案
如何解决ViPER4Windows兼容性难题?5步打造Windows 10/11音效增强终极方案 【免费下载链接】ViPER4Windows-Patcher Patches for fix ViPER4Windows issues on Windows-10/11. 项目地址: https://gitcode.com/gh_mirrors/vi/ViPER4Windows-Patcher 副标题&…...

为什么92%的车载Java应用在-40℃环境崩溃?:嵌入式JRE热稳定性加固实战手册
第一章:车载Java应用低温崩溃现象全景透视在-20℃至-30℃的严寒环境下,车载信息娱乐系统(IVI)中基于Android Framework构建的Java应用频繁出现ANR、SIGSEGV及ClassLoader初始化失败等非预期终止行为。此类崩溃并非由业务逻辑缺陷直…...

LangFlow问题解决:常见部署错误与连接Ollama配置详解
LangFlow问题解决:常见部署错误与连接Ollama配置详解 如果你正在尝试用LangFlow搭建自己的AI应用工作流,但卡在了部署和配置环节,这篇文章就是为你准备的。LangFlow作为一款低代码的可视化工具,理论上能让构建LangChain流水线变得…...

Photon光影包:颠覆级Minecraft视觉体验的沉浸式渲染方案
Photon光影包:颠覆级Minecraft视觉体验的沉浸式渲染方案 【免费下载链接】photon A gameplay-focused shader pack for Minecraft 项目地址: https://gitcode.com/gh_mirrors/photon3/photon 在像素化的方块世界中,如何突破视觉边界实现电影级画面…...

3步打造游戏性能优化神器:DLSS Swapper零基础掌握指南
3步打造游戏性能优化神器:DLSS Swapper零基础掌握指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为PC游戏玩家设计的DLSS版本管理工具,通过自动化版本切换、智能游戏扫…...
部署到ROS或Simulink?)
从仿真到实战:如何将你的MATLAB机械臂轨迹规划代码(3-5-3插值)部署到ROS或Simulink?
从仿真到实战:MATLAB机械臂轨迹规划代码的ROS与Simulink部署指南 当你完成了MATLAB中机械臂轨迹规划的算法开发,看着屏幕上平滑的位置、速度和加速度曲线,接下来面临的核心问题是如何将这些数据转化为真实机械臂的动作。本文将深入探讨两种主…...

5个实战技巧让Continue插件成为你的JetBrains AI编程搭档
5个实战技巧让Continue插件成为你的JetBrains AI编程搭档 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue 在当今AI驱动的开发时代…...

小白也能懂:雪女-斗罗大陆-造相Z-Turbo文生图模型使用详解
小白也能懂:雪女-斗罗大陆-造相Z-Turbo文生图模型使用详解 1. 模型介绍 1.1 什么是雪女-斗罗大陆-造相Z-Turbo 雪女-斗罗大陆-造相Z-Turbo是一款专门用于生成《斗罗大陆》风格图片的AI模型,特别擅长创作与"雪女"角色相关的精美图像。这个模…...

突破QQ音乐格式壁垒:QMCDecode全方位解密方案与跨场景应用指南
突破QQ音乐格式壁垒:QMCDecode全方位解密方案与跨场景应用指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录ÿ…...