HBase读取流程详解
读流程从头到尾可以分为如下4个步骤:Client-Server读取交互逻辑,Server端Scan框架体系,过滤淘汰不符合查询条件的HFile,从HFile中读取待查找Key。其中Client-Server交互逻辑主要介绍HBase客户端在整个scan请求的过程中是如何与服务器端进行交互的,理解这点对于使用HBase Scan API进行数据读取非常重要。了解Server端Scan框架体系,从宏观上介绍HBase RegionServer如何逐步处理一次scan请求。接下来的小节会对scan流程中的核心步骤进行更加深入的分析。
HBase读数据的流程更加复杂。主要基于两个方面的原因:一是因为HBase一次范围查询可能会涉及多个Region、多块缓存甚至多个数据存储文件;二是因为HBase中更新操作以及删除操作的实现都很简单,更新操作并没有更新原有数据,而是使用时间戳属性实现了多版本;删除操作也并没有真正删除原有数据,只是插入了一条标记为"deleted"标签的数据,而真正的数据删除发生在系统异步执行Major Compact的时候。很显然,这种实现思路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着套上了层层枷锁:读取过程需要根据版本进行过滤,对已经标记删除的数据也要进行过滤。
一、Client-Server读取交互逻辑
Client-Server通用交互逻辑::Client首先会从ZooKeeper中获取元数据hbase:meta表所在的RegionServer,然后根据待读写rowkey发送请求到元数据所在RegionServer,获取数据所在的目标RegionServer和Region(并将这部分元数据信息缓存到本地),最后将请求进行封装发送到目标RegionServer进行处理。
在通用交互逻辑的基础上,数据读取过程中Client与Server的交互有很多需要关注的点。从API的角度看,HBase数据读取可以分为get和scan两类,get请求通常根据给定rowkey查找一行记录,scan请求通常根据给定的startkey和stopkey查找多行满足条件的记录。但从技术实现的角度来看,get请求也是一种scan请求(最简单的scan请求,scan的条数为1)。从这个角度讲,所有读取操作都可以认为是一次scan操作。
注意:
HBase Client端与Server端的scan操作并没有设计为一次RPC请求,这是因为一次大规模的scan操作很有可能就是一次全表扫描,扫描结果非常之大,通过一次RPC将大量扫描结果返回客户端会带来至少两个非常严重的后果:
(1)大量数据传输会导致集群网络带宽等系统资源短时间被大量占用,严重影响集群中其他业务。
(2)客户端很可能因为内存无法缓存这些数据而导致客户端OOM。
实际上HBase会根据设置条件将一次大的scan操作拆分为多个RPC请求,每个RPC请求称为一次next请求,每次只返回规定数量的结果。
scan的客户端示例代码:
public static void scan() {HTable table=...; Scan scan=new Scan(); scan.withStartRow(startRow) // 设置检索起始row .withStopRow(stopRow) // 设置检索结束row .setFamilyMap(Map<byte[], Set<byte[]> familyMap>) // 设置检索的列簇和对应列簇下的列集合 .setTimeRange(minStamp, maxStamp) // 设置检索TimeRange .setMaxVersions(maxVersions) // 设置检索的最大版本号 .setFilter(filter) // 设置检索过滤器 ... scan.setMaxResultSize(10000); scan.setBatch(100); ResultScanner rs = table.getScanner(scan); for (Result r : rs) { for (KeyValue kv : r.raw()) { ...... } }
}
(1)for(Result r:rs)语句实际等价于Result r=rs.next()。每执行一次next()操作,客户端先会从本地缓存中检查是否有数据,如果有就直接返回给用户,如果没有就发起一次RPC请求到服务器端获取,获取成功之后缓存到本地。
(2)单次RPC请求的数据条数由参数caching设定,默认为Integer.MAX_VALUE。每次RPC请求获取的数据都会缓存到客户端,该值如果设置过大,可能会因为一次获取到的数据量太大导致服务器端/客户端内存OOM;而如果设置太小会导致一次大scan进行太多次RPC,网络成本高。
(3)对于很多特殊业务有可能一张表中设置了大量(几万甚至几十万)的列,这样一行数据的数据量就会非常大,为了防止返回一行数据但数据量很大的情况,客户端可以通过setBatch方法设置一次RPC请求的数据列数量。
(4)客户端还可以通过setMaxResultSize方法设置每次RPC请求返回的数据量大小(不是数据条数),默认是2G。
二、Server端Scan框架体系
一次scan可能会同时扫描一张表的多个Region,对于这种扫描,客户端会根据hbase:meta元数据将扫描的起始区间[startKey,stopKey)进行切分,切分成多个互相独立的查询子区间,每个子区间对应一个Region。比如当前表有3个Region,Region的起始区间分别为:[“a”,“c”),[“c”,“e”),[“e”,“g”),客户端设置scan的扫描区间为[“b”,“f”)。因为扫描区间明显跨越了多个Region,需要进行切分,按照Region区间切分后的子区间为[“b”,“c”),[“c”,“e”),[“e”,“f”)。
HBase中每个Region都是一个独立的存储引擎,因此客户端可以将每个子区间请求分别发送给对应的Region进行处理。下文会聚焦于单个Region处理scan请求的核心流程。
RegionServer接收到客户端的get/scan请求之后做了两件事情:首先构建scanner iterator体系;然后执行next函数获取KeyValue,并对其进行条件过滤。
1,构建Scanner Iterator体系
Scanner的核心体系包括三层Scanner:RegionScanner,StoreScanner,MemStoreScanner和StoreFileScanner。
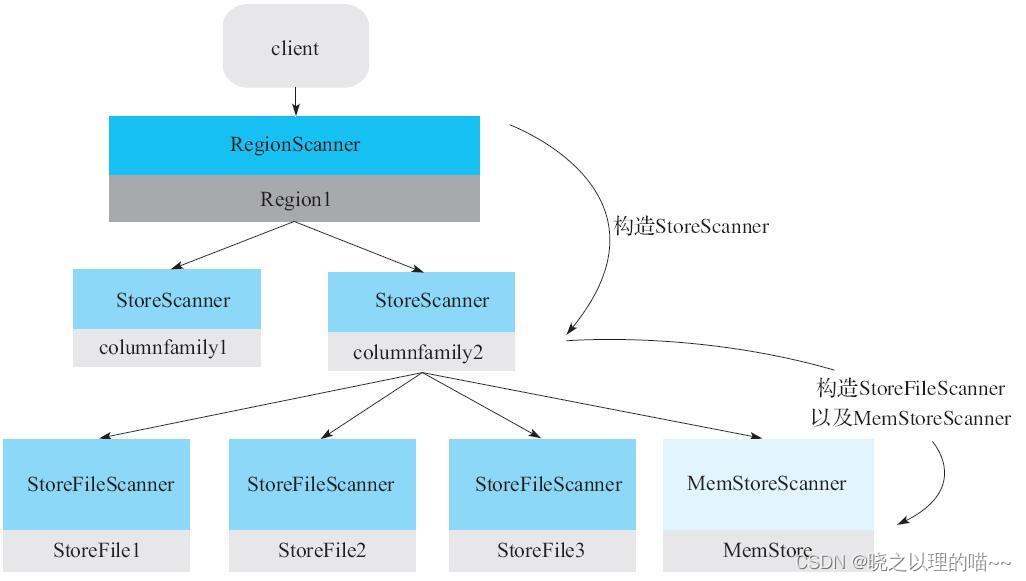
三者是层级的关系:
(1)一个RegionScanner由多个StoreScanner构成。一张表由多少个列簇组成,就有多少个StoreScanner,每个StoreScanner负责对应Store的数据查找。
(2)一个StoreScanner由MemStoreScanner和StoreFileScanner构成。每个Store的数据由内存中的MemStore和磁盘上的StoreFile文件组成。相对应的,StoreScanner会为当前该Store中每个HFile构造一个StoreFileScanner,用于实际执行对应文件的检索。同时,会为对应MemStore构造一个MemStoreScanner,用于执行该Store中MemStore的数据检索。
注意:RegionScanner以及StoreScanner并不负责实际查找操作,它们更多地承担组织调度任务,负责KeyValue最终查找操作的是StoreFileScanner和MemStoreScanner。
构造好三层Scanner体系之后准备工作并没有完成,还需要以下几个非常核心的关键步骤:
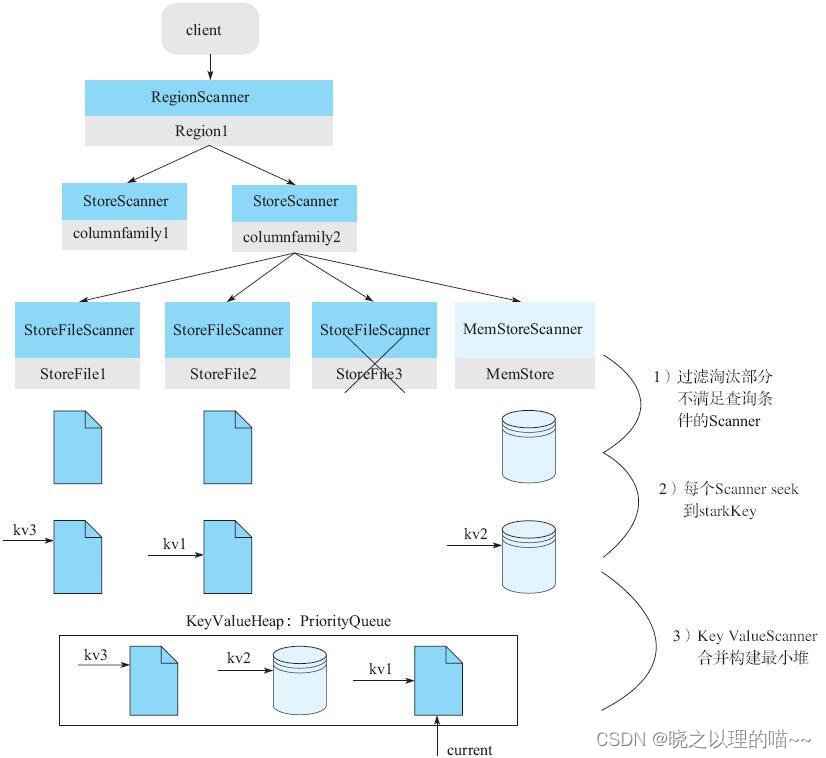
1)过滤淘汰部分不满足查询条件的Scanner。StoreScanner为每一个HFile构造一个对应的StoreFileScanner,需要注意的事实是,并不是每一个HFile都包含用户想要查找的KeyValue,相反,可以通过一些查询条件过滤掉很多肯定不存在待查找KeyValue的HFile。主要过滤策略有:Time Range过滤、Rowkey Range过滤以及布隆过滤器,具体的过滤细节详见6.3.3节。图6-11中StoreFile3检查未通过而被过滤淘汰。
2)每个Scanner seek到startKey。这个步骤在每个HFile文件中(或MemStore)中seek扫描起始点startKey。如果HFile中没有找到starkKey,则seek下一个KeyValue地址。HFile中具体的seek过程比较复杂。
3)KeyValueScanner合并构建最小堆。将该Store中的所有StoreFileScanner和MemStoreScanner合并形成一个heap(最小堆),所谓heap实际上是一个优先级队列。在队列中,按照Scanner排序规则将Scanner seek得到的KeyValue由小到大进行排序。最小堆管理Scanner可以保证取出来的KeyValue都是最小的,这样依次不断地pop就可以由小到大获取目标KeyValue集合,保证有序性。
2,执行next函数获取KeyValue并对其进行条件过滤
经过Scanner体系的构建,KeyValue此时已经可以由小到大依次经过KeyValueScanner获得,但这些KeyValue是否满足用户设定的TimeRange条件、版本号条件以及Filter条件还需要进一步的检查。
检查规则如下:
(1)检查该KeyValue的KeyType是否是Deleted/DeletedColumn/DeleteFamily等,如果是,则直接忽略该列所有其他版本,跳到下列(列簇)。
(2)检查该KeyValue的Timestamp是否在用户设定的Timestamp Range范围,如果不在该范围,忽略。
(3)检查该KeyValue是否满足用户设置的各种filter过滤器,如果不满足,忽略。
(4)检查该KeyValue是否满足用户查询中设定的版本数,比如用户只查询最新版本,则忽略该列的其他版本;反之,如果用户查询所有版本,则还需要查询该cell的其他版本。
三、过滤淘汰不符合查询条件的HFile
过滤StoreFile发生在KeyValueScanner合并构建最小堆,过滤手段主要有三种:根据KeyRange过滤,根据TimeRange过滤,根据布隆过滤器进行过滤。
(1)根据KeyRange过滤:因为StoreFile中所有KeyValue数据都是有序排列的,所以如果待检索row范围[startrow,stoprow]与文件起始key范围[firstkey,lastkey]没有交集,比如stoprow<firstkey或者startrow>lastkey,就可以过滤掉该StoreFile。
(2)根据TimeRange过滤:StoreFile中元数据有一个关于该File的TimeRange属性[miniTimestamp,maxTimestamp],如果待检索的TimeRange与该文件时间范围没有交集,就可以过滤掉该StoreFile;另外,如果该文件所有数据已经过期,也可以过滤淘汰。
(3)根据布隆过滤器进行过滤:StoreFile中布隆过滤器相关Data Block结构在第5章已经做过介绍,系统根据待检索的rowkey获取对应的Bloom Block并加载到内存(通常情况下,热点BloomBlock会常驻内存的),再用hash函数对待检索rowkey进行hash,根据hash后的结果在布隆过滤器数据中进行寻址,即可确定待检索rowkey是否一定不存在于该HFile。
四、从HFile中读取待查找Key

1,根据HFile索引树定位目标Block
HRegionServer打开HFile时会将所有HFile的Trailer部分和Load-on-open部分加载到内存,Load-on-open部分有个非常重要的Block——Root Index Block,即索引树的根节点。
BlockKey是整个Block的第一个rowkey,如Root Index Block中"a",“m”,“o”,"u"都为BlockKey。Block Offset表示该索引节点指向的Block在HFile的偏移量。
HFile索引树索引在数据量不大的时候只有最上面一层,随着数据量增大开始分裂为多层,最多三层。
一次查询的索引过程,基本流程可以表示为:
(1)用户输入rowkey为’fb’,在Root Index Block中通过二分查找定位到’fb’在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为Root Index Block常驻内存,所以这个过程很快。
(2)将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index’d’和’h’之间,接下来访问索引’d’指向的叶子节点。
(3)同理,将索引’d’指向的中间节点索引块加载到内存,通过二分查找定位找到fb在index’f’和’g’之间,最后需要访问索引’f’指向的Data Block节点。
(4)将索引’f’指向的Data Block加载到内存,通过遍历的方式找到对应KeyValue。
上述流程中,Intermediate Index Block、Leaf Index Block以及Data Block都需要加载到内存,所以一次查询的IO正常为3次。但是实际上HBase为Block提供了缓存机制,可以将频繁使用的Block缓存在内存中,以便进一步加快实际读取过程。
2,BlockCache中检索目标Block
BlockCache组件在第5章做过详细介绍,根据内存管理策略的不同经历了LRUBlockCache、SlabCache以及BucketCache等多个方案的发展,在内存管理优化、GC优化方面都有了很大的提升。
但无论哪个方案,从BlockCache中定位待查Block都非常简单。Block缓存到BlockCache之后会构建一个Map,Map的Key是BlockKey,Value是Block在内存中的地址。其中BlockKey由两部分构成——HFile名称以及Block在HFile中的偏移量。BlockKey很显然是全局唯一的。根据BlockKey可以获取该Block在BlockCache中内存位置,然后直接加载出该Block对象。如果在BlockCache中没有找到待查Block,就需要在HDFS文件中查找。
3,HDFS文件中检索目标Block
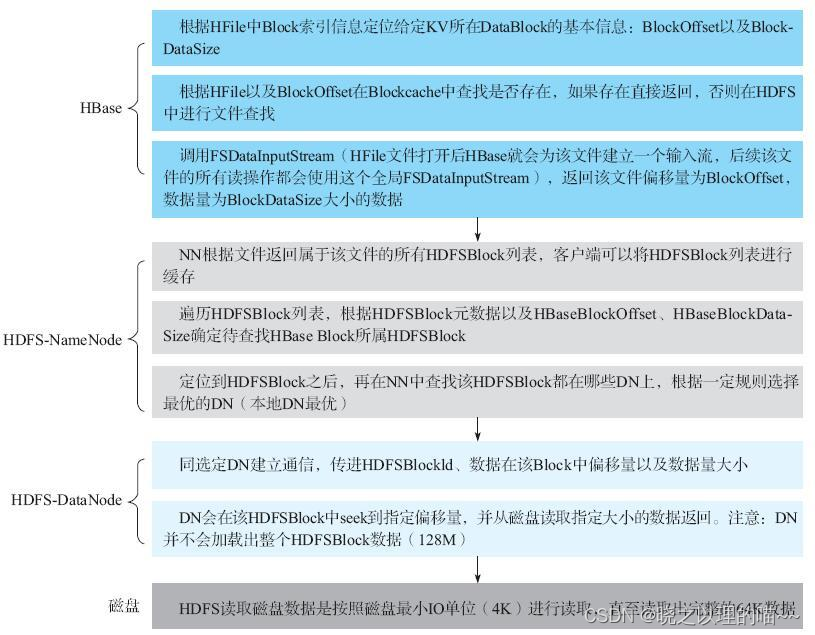
根据文件索引提供的Block Offset以及Block DataSize这两个元素可以在HDFS上读取到对应的Data Block内容(核心代码可以参见HFileBlock.java中内部类FSReaderImpl的readBlockData方法)。这个阶段HBase会下发命令给HDFS,HDFS执行真正的Data Block查找工作。
整个流程涉及4个组件:HBase、NameNode、DataNode以及磁盘。其中HBase模块做的事情上文已经做过了说明,需要特别说明的是FSDataInputStream这个输入流,HBase会在加载HFile的时候为每个HFile新建一个从HDFS读取数据的输入流——FSDataInputStream,之后所有对该HFile的读取操作都会使用这个文件级别的InputStream进行操作。
使用FSDataInputStream读取HFile中的数据块,命令下发到HDFS,首先会联系NameNode组件。NameNode组件会做两件事情:
(1)找到属于这个HFile的所有HDFSBlock列表,确认待查找数据在哪个HDFSBlock上。众所周知,HDFS会将一个给定文件切分为多个大小等于128M的Data Block,NameNode上会存储数据文件与这些HDFSBlock的对应关系。
(2)确认定位到的HDFSBlock在哪些DataNode上,选择一个最优DataNode返回给客户端。HDFS将文件切分成多个HDFSBlock之后,采取一定的策略按照三副本原则将其分布在集群的不同节点,实现数据的高可靠存储。HDFSBlock与DataNode的对应关系存储在NameNode。
NameNode告知HBase可以去特定DataNode上访问特定HDFSBlock,之后,HBase会再联系对应DataNode。DataNode首先找到指定HDFSBlock,seek到指定偏移量,并从磁盘读出指定大小的数据返回。
DataNode读取数据实际上是向磁盘发送读取指令,磁盘接收到读取指令之后会移动磁头到给定位置,读取出完整的64K数据返回。
4,从Block中读取待查找KeyValue
HFile Block由KeyValue(由小到大依次存储)构成,但这些KeyValue并不是固定长度的,只能遍历扫描查找。
文章来源:《HBase原理与实践》 作者:胡争;范欣欣
文章内容仅供学习交流,如有侵犯,联系删除哦!
相关文章:
HBase读取流程详解
读流程从头到尾可以分为如下4个步骤:Client-Server读取交互逻辑,Server端Scan框架体系,过滤淘汰不符合查询条件的HFile,从HFile中读取待查找Key。其中Client-Server交互逻辑主要介绍HBase客户端在整个scan请求的过程中是如何与服务…...

Redis学习(一):NoSQL概述
为什么要使用Nosql 现在是大数据时代,过大的数据一般的数据库无法进行分析处理了。 单机MySQL的年代 90年代,一个基本的网站访问量一般不会太大,单个数据库完全足够! 那个时候,更多的去使用静态网站,服务器…...

ESP32设备驱动-MCP23017并行IO扩展驱动
MCP23017并行IO扩展驱动 1、MCP23017介绍 MCP23017是一个用于 I2C 总线应用的 16 位通用并行 I/O 端口扩展器。 16 位 I/O 端口在功能上由两个 8 位端口(PORTA 和 PORTB)组成。 MCP23017 可配置为在 8 位或 16 位模式下工作。 其引脚排列如下: MCP23017 在 3.3v 下工作正常…...
RabbitMQ简介
0. 学习目标 能够说出什么是消息中间件能够安装RabbitMQ能够编写RabbitMQ的入门程序能够说出RabbitMQ的5种模式特征能够使用Spring整合RabbitMQ 1. 消息中间件概述 1.1. 什么是消息中间件 MQ全称为Message Queue,消息队列是应用程序和应用程序之间的通信方法。是…...

【项目设计】高并发内存池(五)[释放内存流程及调通]
🎇C学习历程:入门 博客主页:一起去看日落吗持续分享博主的C学习历程博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记&…...
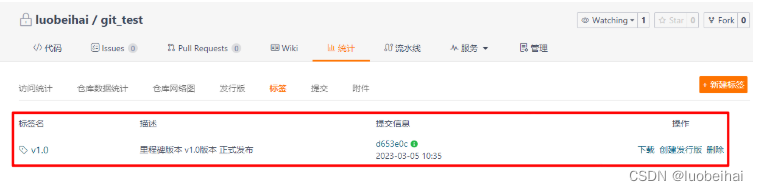
Git标签与版本发布
1. 什么是git标签 标签,就类似我们阅读时的书签,可以很轻易找到自己阅读到了哪里。 对于git来说,在使用git对项目进行版本管理的时候,当我们的项目开发到一定的阶段,需要发布一个版本。这时,我们就可以对…...

Python面向对象编程
文章目录1 作用域1.1 局部作用域2 类成员权限3 是否继承新式类4 多重继承5 虚拟子类6 内省【在运行时确定对象类型的能力】7 函数参数8 生成器1 作用域 1.1 局部作用域 1,当局部变量遮盖全局变量,使用globals()[变量名]来使用全局变量;2&am…...

【什么情况会导致 MySQL 索引失效?】
MySQL索引失效可能有多种原因,下面列举一些常见的情况: 数据库表数据量太小: 如果表的数据量非常小,则MySQL可能不会使用索引,因为它认为全表扫描的代价更小。 索引列上进行了函数操作: 如果在索引列上…...
--自问自答系列版本)
Java核心知识点整理之小碎片--每天一点点(坚持呀)--自问自答系列版本
1.int和Integer Integer是int的包装类;int是基本数据类型。 Integer变量必须实例化后才能使用;int变量不需要。 Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值…...
的使用方法)
js中new Map()的使用方法
1.map的方法及属性Map对象存有键值对,其中的键可以是任何数据类型。Map对象记得键的原始插入顺序。Map对象具有表示映射大小的属性。1.1 基本的Map() 方法MethodDescriptionnew Map()创建新的 Map 对象。set()为 Map 对象中的键设置值。get()获取 Map 对象中键的值。…...

synchronized从入门到踹门
synchronized是什么synchronized是Java关键字,为了维护高并发是出现的原子性问题。技术是把双刃剑,多线程并发给我带来了前所未有的速率,然而在享受快速编程的过程,也给我们带来了原子性问题。如下:public class Main …...

ubuntu-8-安装nfs服务共享目录
Ubuntu最新版本(Ubuntu22.04LTS)安装nfs服务器及使用教程 ubuntu16.04挂载_如何在Ubuntu 20.04上设置NFS挂载 Ubuntu 20.04 设置时区、配置NTP同步 timesyncd 代替 ntpd 服务器 10.0.2.11 客户端 10.0.2.121 NFS简介 (1)什么是NFS NFS就是Network File System的缩写…...
设计算法的常用思想)
算法练习(特辑)设计算法的常用思想
1、递推法 递推的思想是把一个复杂的庞大的计算过程转换为简单过程的多次重复,每一次推导的结果作为下一次推导的开始。 2、递归法 递归算法实际上是把问题转化成规模更小的同类子问题,先解决子问题,再通过相同的求解过程逐步解决更高层次…...
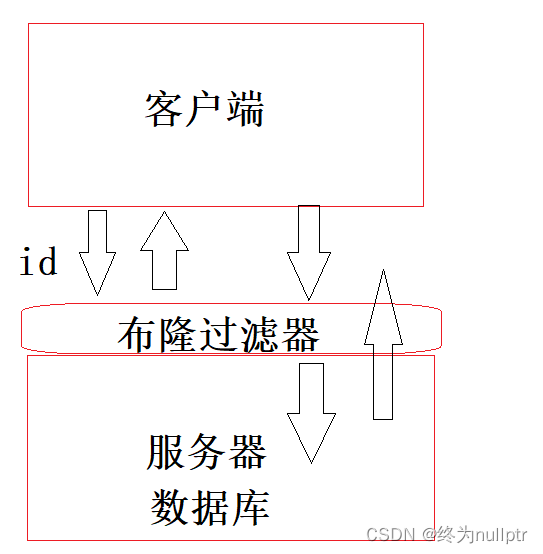
哈希->模拟实现+位图应用
致前行路上的人: 要努力,但不要着急,繁花锦簇,硕果累累都需要过程! 目录 1. unordered系列关联式容器 1.1 unordered_map 1.1.1概念介绍: 1.1.2 unordered_map的接口说明 1.2unordered_set 1.3常见面试题oj…...
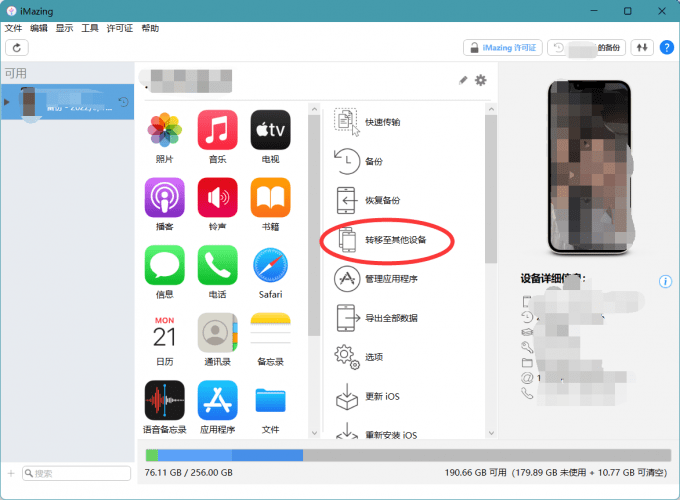
苹果手机想要传输数据到电脑怎么传输呢?
苹果手机想要传输数据到电脑怎么传输呢?尤其是传输数据到Windows系统,可能需要使用一些传输软件,那么常用的传输软件有哪些呢?下文将为大家推荐几款常用的苹果手机数据传输常用工具。近期苹果发布了iPhone14系列手机,如…...

Linux 练习四 (目录操作 + 文件操作)
文章目录1 基于文件指针的文件操作1.1 文件的创建,打开和关闭1.2 文件读写操作2 基于文件描述符的文件操作2.1 打开、创建和关闭文件2.2 文件读写2.3 改变文件大小2.4 文件映射2.5 文件定位2.6 获取文件信息2.7 复制文件描述符2.8 文件描述符和文件指针2.9 标准输入…...
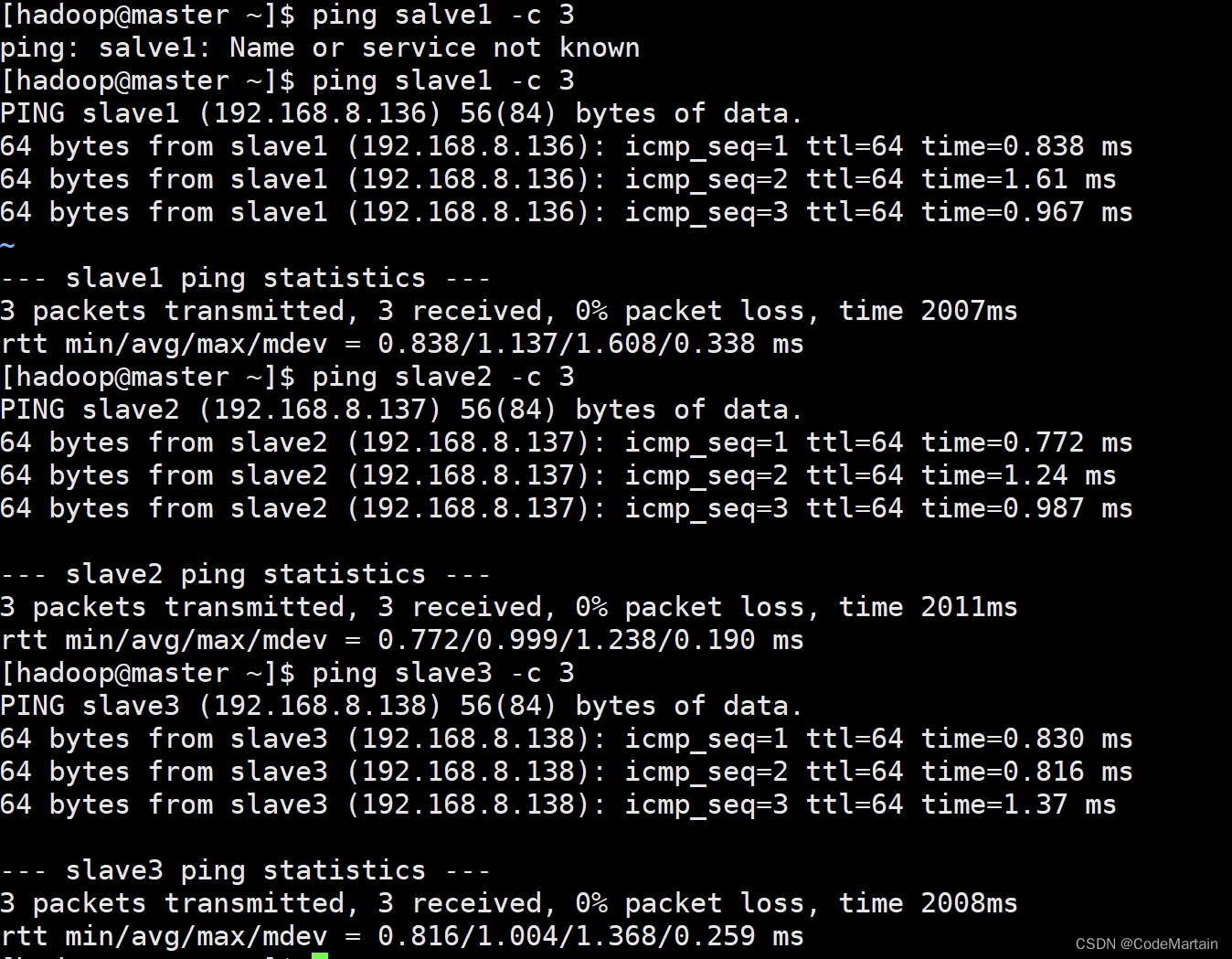
自学大数据第四天~hadoop集群的搭建
Hadoop集群安装配置 当hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,此时HDFS名称节点和数据节点位于不同的机器上; 数据就可以分布到多个节点,不同的数据节点上的数据计算可以并行执行了,这时候MR才能发挥其本该有的作用; 没那么多机器怎么办~~~~多几个虚拟…...

ULID和UUID
ULID:Universally Unique Lexicographically Sortable Identifier(通用唯一词典分类标识符)UUID:Universally Unique Identifier(通用唯一标识符)为什么不选择UUIDUUID 目前有 5 个版本:版本1&a…...

java基础面试10题
1.JVM、JRE 和 JDK 的关系 Jvm:java虚拟机,类似于一个小型的计算机,它能够将java程序编译后的.class 文件解释给相应平台的本地系统执行,从而实现跨平台。 jre:是运行java程序所需要的环境的集合,它包含了…...

Golang闭包问题及并发闭包问题
目录Golang闭包问题及并发闭包问题匿名函数闭包闭包可以不传入外部参数,仍然可以访问外部变量闭包提供数据隔离并发闭包为什么解决方法Golang闭包问题及并发闭包问题 参考原文链接:https://blog.csdn.net/qq_35976351/article/details/81986496 htt…...
)
Spring AI实战:5分钟搞定豆包TTS语音合成(附完整Java代码)
Spring AI实战:5分钟集成豆包TTS语音合成(附完整Java代码) 语音合成技术正在重塑人机交互的边界。作为Java开发者,你可能已经注意到Spring AI生态的快速崛起——它正成为企业级AI应用开发的新标准。本文将带你用最短时间完成豆包T…...

Wan2.1-UMT5与Python入门:零基础学会用AI生成你的第一个视频
Wan2.1-UMT5与Python入门:零基础学会用AI生成你的第一个视频 你是不是也刷到过那些由AI生成的酷炫短视频,心里痒痒的,觉得这技术真神奇?但一想到要学复杂的编程和模型部署,就觉得头大,感觉离自己很远。 别…...

Python程序设计期末考试高频大题精讲:二维列表数据处理实战与深度解析
Python程序设计期末考试高频大题精讲:二维列表数据处理实战与深度解析 摘要:本文以高校计算机科学与技术专业《Python程序设计》期末考试中一道典型大题——“统计学生捐款次数”为切入点,系统讲解二维列表(嵌套列表)的…...

TCA9548A I²C多路复用器原理与嵌入式实战指南
1. TCA9548A IC多路复用器技术解析与嵌入式系统集成实践 1.1 器件定位与工程价值 TCA9548A是德州仪器(TI)推出的低电压8通道IC总线开关,其核心价值在于解决嵌入式系统中IC总线地址冲突这一经典工程难题。在STM32、ESP32、Raspberry Pi等主流…...

多模态场景:头巾误判为厨师帽 — 问题分析与调优指南
多模态场景:头巾误判为厨师帽 — 问题分析与调优指南适用对象:使用 Qwen-VL 等多模态大模型做「厨师帽 / 头饰」相关识别时的面试问答、方案设计与落地调优参考。1. 问题本质:为什么会把头巾当成厨师帽 这通常不是「模型坏了」,而…...

SecGPT-14B开源大模型部署:CSDN平台内开箱即用,省去HuggingFace下载环节
SecGPT-14B开源大模型部署:CSDN平台内开箱即用,省去HuggingFace下载环节 想快速体验一个专注于网络安全问答的14B大模型,但又不想经历从HuggingFace下载几十GB模型文件的漫长等待和复杂配置?现在,在CSDN星图平台上&am…...

OpenClaw未来展望:Qwen3-14B与本地自动化的5个进化方向
OpenClaw未来展望:Qwen3-14B与本地自动化的5个进化方向 1. 从工具到伙伴:OpenClaw的现状与定位 去年冬天,当我第一次在本地MacBook上部署OpenClaw时,它还是个需要手动配置JSON文件才能调用本地模型的"半成品"。如今看…...

VBA数据库解决方案第二十九讲 如何批量修改数据库中的数据
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...

STM32智能剪枝机:嵌入式系统与传感器集成实践
1. 项目背景与需求分析作为一名从事嵌入式开发多年的工程师,我最近完成了一个基于STM32的智能绿化带剪枝机项目。这个项目的初衷源于我在城市公园散步时的观察:园艺工人手持笨重的剪枝工具,在烈日下长时间弯腰作业,不仅效率低下&a…...

电路原理与人生哲学的奇妙对应关系
1. 电路与人生的奇妙映射作为一名在电子行业摸爬滚打十多年的工程师,我常常惊叹于电路原理与人生百态之间的惊人相似。记得刚入行时,我的导师就说过:"读懂电路,就读懂了人生。"当时只觉得是句玩笑话,直到这些…...