链表——超详细
一、无头单向非循环链表
1.结构(两个部分):
typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;//数据域struct SListNode* next;//指针域
}SLNode;它只有一个数字域和一个指针域,里面数据域就是所存放的数据,类型是存放数据的类型,而指针域是为了找到下一个节点,存放的是下一个节点的地址,因此它的类型是一个结构体类型的指针,我们可以使用 typedef 对类型和结构体类型进行重命名,这里就体现一个好名字的重要性,变量命名的规范性是非常关键的,前面学习的时候,我命名十分随意,结果就是越写越混乱,过几天看的时候也不知道自己这个名字代表的是什么。
这里建议头结点的数据域中不要储存东西,很多人习惯里面存放链表的长度,可是我们已经使用 typedef 对类型进行重命名,就是为了方便改变其储存数据的类型,如果我们存放的数据不再是整型了,那自然是储存不了链表长度的,所以为了写出来的链表更具有普适性,还是不要在头结点中数据域中储存链表长度等数据。
还有要区分头结点和头指针,这两个东西完全就不是一个概念,我之前就把它们搞混了,还是很痛苦的。首先头结点是一个节点,本质上是一个结构体,区分数据域和指针域,头指针是一个指针,就别谈什么数据域和指针域了,它就是用来储存第一个节点的地址。这可以理解吧,你想想后面所有节点都是一个指一个,肯定需要一个头引导一下。
当然链表的每一个数据都是直接储存在一个结构体变量中,多个结构体变量共同组成一个链表,而我之前学习的顺序表它就是在一个结构体变量的基础上,通过成员申请指向动态申请的空间,顺序表中的数据并没有直接储存在结构体中,而是储存在动态申请开的空间里,所以一个顺序表只对应一个结构体变量。就是这样的结构差异导致 pList ==NULL 和 ps == NULL 所表达的含义是不同的,pList ==NULL 表示当前链表是一个空链表,当然空链表也是一个链表,只不过里面没有数据罢了,而 ps == NULL 则表示这个顺序表根本不存在,这里需要注意!!!,一个空顺序表的表示方式是:ps->size == 0 。
2.遍历链表数据:
void STLPrint(SLTNode* phead)
{SLTNode* cur = phead;while (cur != NULL){printf("%d->", cur->data);cur = cur->next;}printf("NULL\n");
}直接写一个函数,这里我们传递的是头指针,当决定用指针去遍历链表之后,接下来就该让这个指针动起来 cur = cur->next 就是通过不断把下一个节点的地址不断赋值给自己来实现遍历的,直到cur = NULL 的时候说明已经遍历完了整个链表。这里有个非常值得注意的问题:循环结束你条件的设置,我设置的是 cur != NULL ,那么需要思考的是为什么不是 cur -> next != NULL 呢!?让我们来观察这个循环,当cur -> next != NULL 时说明 cur 指向最后一个节点,并没有遍历结束。
3.创建新节点:
由于我们后面很多操作都需要创建新的节点,就把节点的创建单独封装了一个函数。
不难这就不展开说了。
SLTNode* BuySLTNode(SLTDataType x)//创建新节点
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc");return NULL;}newnode->data = x;newnode->next = NULL;return newnode;
}4.尾加:
void SLTPushBack(SLTNode** pphead, SLTDataType x)//尾加函数
{assert(pphead);SLTNode* newnode = BuySLTNode(x);if (*pphead == NULL){*pphead = newnode;}else{SLTNode* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;}
}尾加的第一步当然是先创建一个节点来储存数据,是通过函数来实现的,对于函数来说实参的改变不会影响实参,这里就涉及到传值和传址的区别了,毫无疑问是使用传地址来实现,也就是传递头指针的地址,不然创建的节点就是一个局部变量,离开作用域后就自动销毁了。我们还需要注意的是,当链表为空时,意味着链表只有一个节点,且该节点的地址是0x00000000。当我们能不能把创建的新节点连接到此节点的后面呢?答案是不可以的!!!因为0x00000000后面的地址空间是不允许我们随意访问的,它属于操作系统严格管控的区域。正确做法是:直接将新创建的节点当做头结点,这就意味着:需要把头指针中存放的地址修改成新创建节点的地址!
既然上面说到需要传递头指针的地址,地址的地址那形参自然就需要用一个二级指针来接收,这里记作 pphead 。注意:这个二级指针不能为空!!!,因为它存的可是头指针地址的地址啊,如果这个都为空,那就说明链表不存在,我们还是要区分链表不存在和空链表各自是如何表示的,所以我们在使用 pphead 时就要对它进行检查(使用 assert 进行断言)
这里代码的实现,需要先判断头指针是不是空的,就意味着链表只有一个节点,那如果我们需要插入数据,直接将新节点赋值给头指针指向的地址,这个不难理解,这一步也不能忘记,还是很必要的,如果不为空呢?我们就需要创建一个新的指针来遍历链表,循环结束条件就是当指针走到下一个就是空时就说明到尾部了,需要赋值了。好的非常通俗易懂。
5.头加:
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = BuySLTNode(x);newnode->next = *pphead;*pphead = newnode;
}这个和上面同理依然要使用二级指针来实现,但是这里不需要考虑空链表的情况,已经明白,就不多说了。
6.尾删:
void SLTPopBack(SLTNode** pphead)//尾删
{assert(pphead);assert(*pphead);//检查链表是否为空if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{SLTNode* prev = *pphead;SLTNode* tail = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);tail = NULL;prev->next = NULL;}
}才开始按自己思路写了一个,写完发现并没有我想的那么容易,它需要考虑链表是否为空,并且也需要使用二级指针来完成。尾删首先要遍历链表找到最后一个节点将其释放掉,还要找到倒数第二个节点,将它的指针域中存的地址改为 NULL 。所以定义两个指针让它们同时去遍历链表。需要注意的是空链表和只有一个节点的链表的情况,空链表无法进行尾删,而只有一个节点的链表,这意味着要改变头指针里面存放的地址,所以尾删也要传递二级指针。
7.头删:
void SLTPopFront(SLTNode** pphead)//头删
{assert(pphead);assert(*pphead);SLTNode* tail = *pphead;*pphead = (*pphead)->next;free(tail);tail = NULL;
}没什么好讲的,就是要注意链表是否为空,空链表无法进行删除,此外在进行头删的时候记得将原来的头结点释放掉,先保留,再释放。
8.单链表查找:
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)//单链表查找
{SLTNode* ptr = phead;while (ptr != NULL){if (ptr->data == x){return ptr;//返回数据存放地址}else{ptr = ptr->next;}}return NULL;//说明没找到(已经遍历结束)
}其实就是遍历一遍链表,但是只能返回第一次出现的地址。查找可以当做修改使用,我们找到节点地址之后就可以通过地址去修改数据域中储存的数据。
9.在 pos 位置之前插入:
oid SLTInsert(SLTNode** pphead,SLTNode*pos,SLTDataType x)//在 pos 位置之前插入
{assert(pphead);assert(pos);if (pos == *pphead)//如果pos就是头结点{SLTPushFront(pphead, x);}else{SLTNode* newnode = BuySLTNode(x);SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = newnode;newnode->next = pos;}
}需要注意的是 pos 是头结点的情况,此时就成头插了,需要改变头指针中存的地址,因此函数形参需要传递二级指针。
10.删除 pos 位置数据:
void SLTzErase(SLTNode** pphead, SLTNode* pos)//删除 pos 位置数据:
{assert(pphead);assert(*pphead);//空链表不能删assert(pos);if (pos == *pphead){SLTPopFront(pphead);//相当于头删}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;//其实没什么用,形参不改变实参}
}pos 可能是头结点的地址,因此形参要用二级指针,其他的没什么好说的。
11.在 pos 位置的后面插入:
void SLTInsertAfter(SLTNode* pos, SLTDataType x)//在 pos 位置的后面插入:
{assert(pos);SLTNode* newnode = BuySLTNode(x);SLTNode* tmp = pos->next;pos->next = newnode;newnode->next = tmp;
}这里需要注意赋值的顺序问题,有两种方法:
- 先让 newnode 的指针域储存 pos 后一个节点的地址,再让 pos 的指针域存 newnode 的地址。
- 借助中间变量,先把 pos 后面节点的地址保存起来,再让 pos 的指针域存 newnode 的地址,最后再让 newnode 的指针域存第一步中间变量中保存的地址(这个比较容易理解,正如上面代码所表示的)。
12.删除 pos 位置后面的数据:
void SLTEraseAfter(SLTNode* pos)//删除 pos 位置后面的数据:
{arrest(pos);assert(pos->next);//后面有数据才能删SLTNode* tmp = pos->next->next;//这里保存了 pos 后面的后面的节点的地址free(pos->next);pos->next = tmp;
}注意后面不能写成: pos->next = pos->next->next 这样写虽然也达到了删除 pos 后面节点的目的,但是没有真正意义上实现删除,因为每一个节点都是通过 malloc 在堆上申请的,不使用的时候要主动的去释放掉(free),把这块空间归还给操作系统,否则会导致内存泄漏。而上面那样写,就会导致 、pos 后面的节点丢失,无法进行释放,正确做法是在执行这条语句之前把 pos 后面节点的地址先保存起来。
在自己已经完整练习过几遍后,确保已经掌握。
二、双向链表:
1.双向链表的特点:
- 每次在插入或者删除某个节点时,需要处理四个节点的使用,而不是两个,实现起来有点困难。
- 相对于单链表,占用空间内存更大。
- 既可以从头遍历到尾,也可以从尾遍历到头。
2.结构(三个部分):
typedef int E;
typedef struct SLTNode
{struct Node* pre;//指针域E data;//数据域struct Node* next;//指针域
}Node;在学习完单链表后,理解双向链表容易多了,可以很容易的观察到它比单链表多一个指针域,struct Node* pre 是指向当前节点的直接前驱。后面两个不用多做说明了。
拓展:双向链表也可以进行首尾相接,构成双向循环链表,在创建链表时只需要在最后首尾相连即可。
3.创建双向链表:
Node* CreatNode(Node* head)//创建双向链表
{head = (Node*)malloc(sizeof(Node));if (head == NULL){perror("malloc");return NULL;}head->pre = NULL;head->next = NULL;head->data = rand() % MAX;return head;
}
Node* CreatList(Node* head, int length)
{if (length == 1)//这里length指需要创建的链表长度{return(head = CreatNode(head));}else{head = CreatNode(head);Node* list = head;for (int i = 1; i = length; i++){Node* body = (Node*)malloc(sizeof(Node));body->pre = NULL;body->next = NULL;body->data = rand() % MAX;list->next = body;body->pre = list;list = list->next;}}return head;
}同单链表相比,双链表仅是各节点多了一个用于指向直接前驱的指针域,因此可以类比学习,需要注意的是,与单链表不同,双向链表创建过程中,每创建一个新节点,都要与其前驱节点建立两次联系,分别是:
- 将新节点的 pre 指针指向直接前驱节点
- 将直接前驱节点的 next 指针指向新节点
这里我创建了两个函数,其实可以合并为一个创建函数,但是为了更容易理解,我把它分为两种情况,第一种情况是指仅仅为了创建头结点,基于单链表的学习,这里不多做阐述。最重要的是第二种情况,我函数参数引入了 length 这个变量,是指所需要创建链表的长度,我还是觉得挺新奇的,毕竟单链表的创建就只是一个节点一个节点的创建。让我们剖析一下这个代码的具体过程,length==1 的情况跳过,关于多节点的创建,讲究一个连续性,使用 for 循环来实现,然后就是建立节点与节点之间的联系,多看多打多理解。
4.插入节点:
Node* InsertList(Node* head,int add, E data)//在add位置前插入data节点
{Node* temp = (Node*)malloc(sizeof(Node));if (temp == NULL){perror("malloc");return NULL;}else{temp->data = data;temp->pre = NULL;temp->next = NULL;}if (add == 1){temp->next = head;head->pre = temp;head = temp;}else{Node* body = head;for (int i = 1; i < add; i++){body = body->next;}if (body->next == NULL){body->next = temp;temp->pre = body;}else{body->next->pre = temp;temp->next = body->next;body->next = temp;temp->pre = body;}}return head;
}当我学到这里的时候,发现这种方法格外新颖,和我单链表的学习方法出入太大,果断放弃,另择它法。
直接重学双向链表是带头节点的,当然依然不存储有效数据,具体原因在学习单链表的时候已经详细解释过了。
1.结构设计及其初始化:
typedef int LTDataType;
typedef struct ListNode
{struct ListNode* prev;//指针域(直接前驱)LTDataType data;//数据域struct ListNode* next;//指针域(直接后继)
}LTNode;
LTNode* LTlint()//初始化
{LTNode* phead = (LTNode*)malloc(sizeof(LTNode));phead->next = NULL;phead->prev = NULL;return phead;
}只能说这个版本正常多了,这里不需要多做解释,咱们继续看。
2.创建节点:
void BuyLTNode(LTDataType x)//创建节点
{LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));if (newnode == NULL){perror("malloc");return NULL;}newnode->next = NULL;newnode->data = x;newnode->prev = NULL;return newnode;
}3.尾插:
void LTPushBack(LTNode* phead, LTDataType x)//尾插
{assert(phead);LTNode* tail = phead->prev;LTNode* newnode = BuyLTNode(x);tail->next = newnode;newnode->prev = tail;newnode->next = phead;phead->prev = newnode;
}这个代码我真的思考了很久,它和单链表有个巨大的不同之处,是我所忽略的。在循环链表中我们让头结点的前驱是链表的最后一个节点!!!意识到这个问题之后,便可以不用循环遍历到尾部,也能实现尾插操作。
4.头插、尾删、头删、查找、pos位前插入、pos位删除:
void LTPushFront(LTNode* phead, LTDataType x)//头插
{assert(phead);LTNode* first = phead->next;LTNode* newnode = BuyLTNode(x);phead->next = newnode;newnode->prev = phead;newnode->next = first;first->prev = newnode;
}
void LTPopBack(LTNode* phead)//尾删
{assert(phead);assert(phead->next != phead);//防止只有一个节点LTNode* tail = phead->prev;LTNode* tailprev = tail->prev;free(tail);phead->prev = tailprev;tailprev->next = phead;
}
void LTPopFront(LTNode* phead)//头删
{assert(phead);assert(phead->next != phead);LTNode* first = phead->next;LTNode* firstnext = first->next;free(first);firstnext->prev = phead;phead->next = firstnext;
}
LTNode* LTFind(LTNode* phead, LTDataType x)//查找
{assert(phead);LTNode* cur = phead->next;while (cur != phead)//注意此处循环条件{if (cur->data == x){return cur;}cur = cur->next;}return NULL;
}
void LTInsert(LTNode* pos, LTDataType x)//在pos之前插入
{assert(pos);LTNode* newnode = BuyLTNode(x);LTNode* posprev = pos->prev;newnode->prev = posprev;posprev->next = newnode;pos->prev = newnode;
}
void LTErase(LTNode* pos)//在pos位删除
{assert(pos);LTNode* posprev = pos->prev;LTNode* posnext = pos->next;free(pos);posprev->next = posnext;posnext->prev = posprev;
}5.判断是否为空、打印、销毁:
bool LTEmpty(LTNode* phead)//判断是否为空(可以简化代码)
{assert(phead);return phead->next == phead;
}
void LTPrint(LTNode* phead)//打印
{assert(phead);printf("guard<==>");LTNode* cur = phead->next;while (cur != phead){printf("%d<==>", cur->data);cur = cur->next;}printf("\n");
}
void LTDestroy(LTNode* phead)//销毁
{assert(phead);LTNode* cur = phead->next;while (cur != phead){LTNode* next = cur->next;free(cur);cur = next;}free(phead);
}三、链表练习题:
1.单向链表: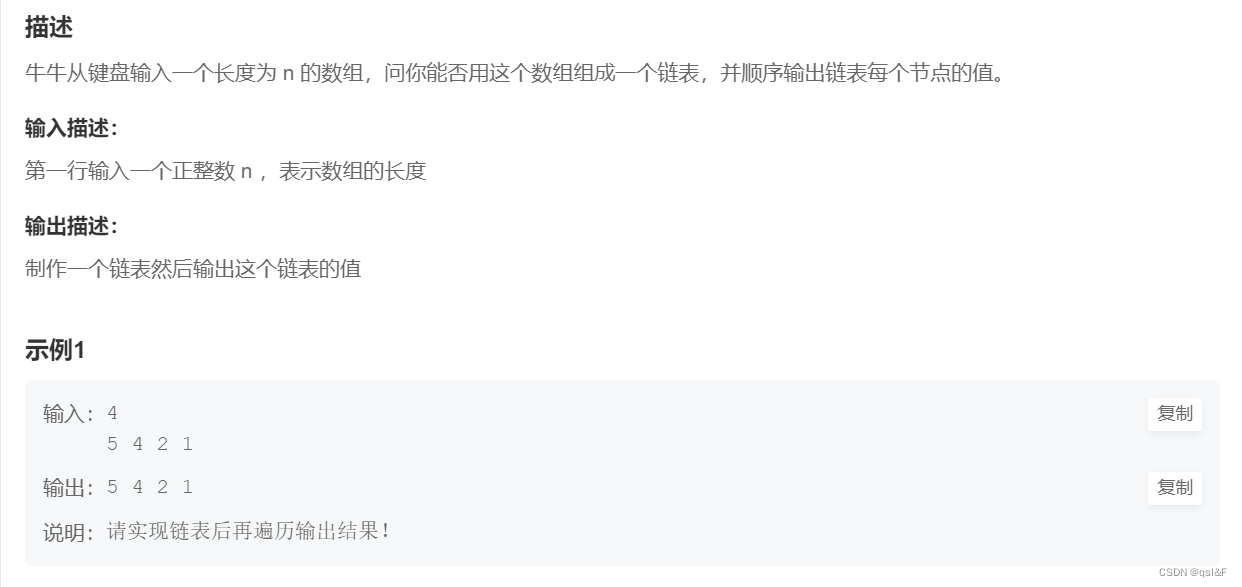
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;
SLTNode* SLTInit()
{SLTNode* phead = (SLTNode*)malloc(sizeof(SLTNode));assert(phead);phead->next = NULL;phead->data = 0;return phead;
}
void SLTPush(SLTNode** pphead, int x)
{assert(pphead);SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));assert(newnode);newnode->next = NULL;newnode->data = x;SLTNode* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;
}void SLTPrint(SLTNode* phead)
{assert(phead);assert(phead->next);SLTNode* cur = phead->next;while (cur != NULL){printf("%d ", cur->data);cur = cur->next;}
}
int main()
{int n = 0;scanf("%d", & n);//动态数组int* arr = (int*)malloc(sizeof(int) * n);SLTNode* head = SLTInit();for (int i = 0; i < n; i++){scanf("%d", &arr[i]);}for (int i = 0; i < n; i++){SLTPush(&head, arr[i]);}SLTPrint(head);return 0;
}刚开始第一次写出来的时候发生了几处错误:
- 第一:使用静态数组进行初始化操作,结果发现无法达到预期效果,在小方同学的提醒下知道了在这个情况下可以使用动态数组

- 第二:打印函数一直打印的是头结点(完全是粗心错误)。
2.交换链表: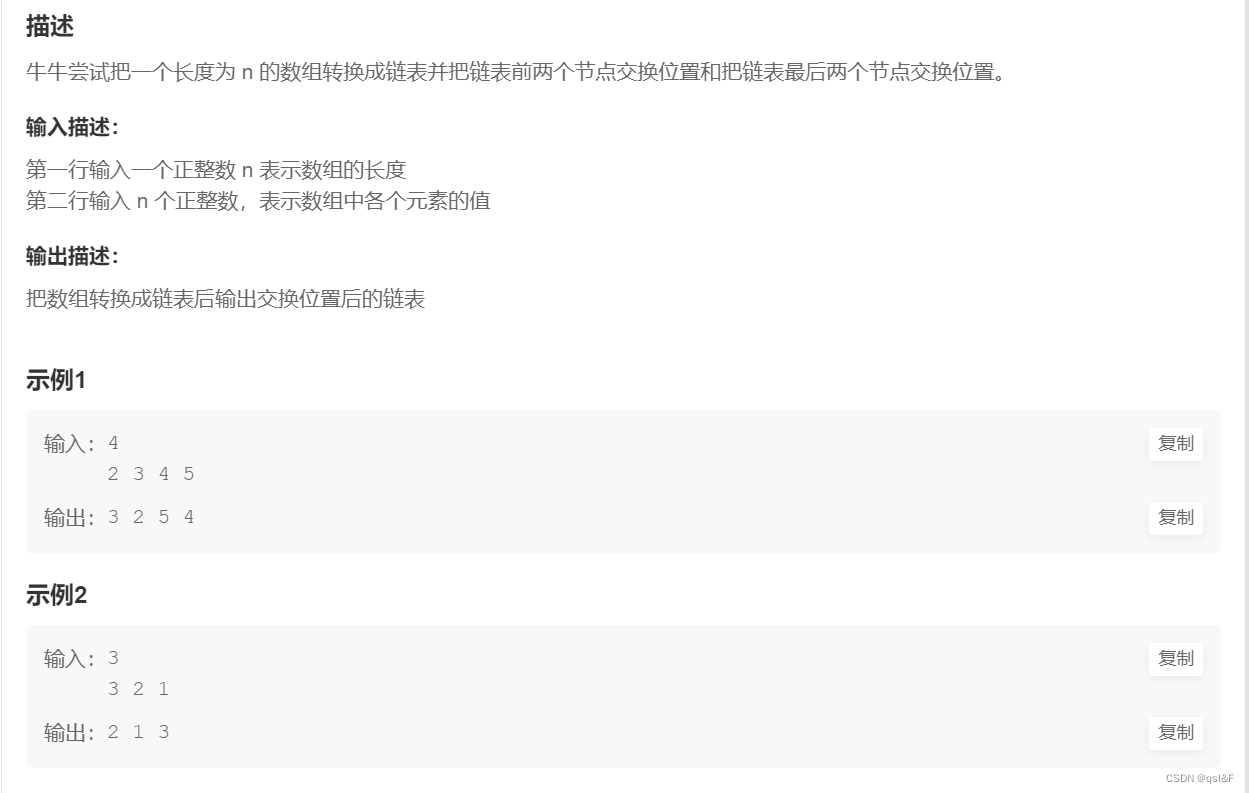
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;
SLTNode* Init()
{SLTNode* phead = (SLTNode*)malloc(sizeof(SLTNode));assert(phead);phead->data = 0;phead->next = NULL;return phead;
}
void SLTPush(SLTNode** pphead, int x)
{assert(pphead);SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));newnode->next = NULL;newnode->data = x;assert(newnode);SLTNode* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;
}
void SLTExchangeFront(SLTNode**pphead)
{SLTNode* cur = (*pphead)->next;SLTNode* prev = cur->next;int t = cur->data;cur->data = prev->data;prev->data = t;
}
void SLTExchangeBack(SLTNode** pphead)
{SLTNode* tail = *pphead;SLTNode* prev = *pphead;while (tail->next != NULL){prev = tail;tail = tail->next;}int t = tail->data;tail->data = prev->data;prev->data = t;
}
void SLTPrint(SLTNode* phead)
{assert(phead);assert(phead->next);SLTNode* cur = phead->next;while (cur != NULL){printf("%d ", cur->data);cur = cur->next;}
}
int main()
{int n = 0;scanf("%d", &n);int* arr = (int*)malloc(sizeof(int) * n);int i = 0;for (i = 0; i < n; i++){scanf("%d", &arr[i]);}SLTNode* head = Init();for (int i = 0; i < n; i++){SLTPush(&head, arr[i]);}SLTExchangeFront(&head);SLTExchangeBack(&head);SLTPrint(head);return 0;
}3.链表求和: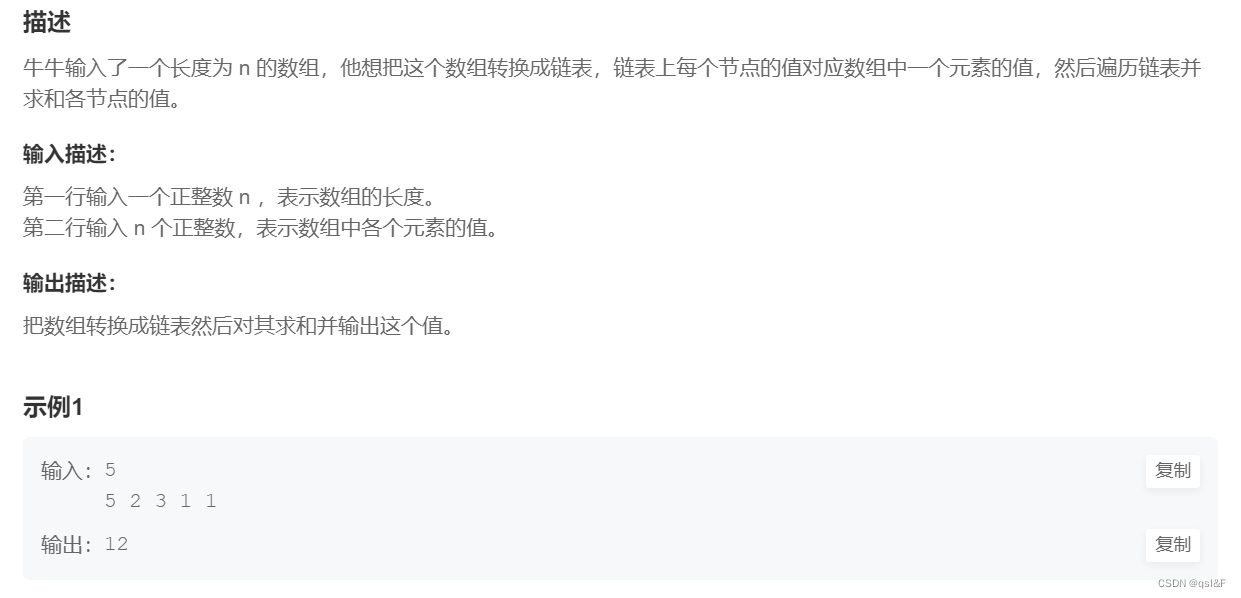
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;
SLTNode* Init()
{SLTNode* phead = (SLTNode*)malloc(sizeof(SLTNode));assert(phead);phead->data = 0;phead->next = NULL;return phead;
}
void SLTPush(SLTNode** pphead, int x)
{assert(pphead);SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));newnode->next = NULL;newnode->data = x;assert(newnode);SLTNode* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;
}
void SLTPrint(SLTNode* phead)
{assert(phead);assert(phead->next);int sum = 0;SLTNode* cur = phead->next;while (cur != NULL){sum += cur->data;cur = cur->next;}printf("%d", sum);
}
int main()
{int n = 0;scanf("%d", &n);int* arr = (int*)malloc(sizeof(int) * n);int i = 0;for (i = 0; i < n; i++){scanf("%d", &arr[i]);}SLTNode* head = Init();for (int i = 0; i < n; i++){SLTPush(&head, arr[i]);}SLTPrint(head);return 0;
}
4.双链表求和:
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef struct SListNode1
{int data;struct SListNode1* next;
}SLTNode1;
typedef struct SListNode2
{int data;struct SListNode2* next;
}SLTNode2;
SLTNode1* Init1()
{SLTNode1* phead = (SLTNode1*)malloc(sizeof(SLTNode1));assert(phead);phead->data = 0;phead->next = NULL;return phead;
}
SLTNode2* Init2()
{SLTNode2* phead = (SLTNode2*)malloc(sizeof(SLTNode2));assert(phead);phead->data = 0;phead->next = NULL;return phead;
}
void SLTPush1(SLTNode1** pphead, int x)
{assert(pphead);assert(*pphead);SLTNode1* newnode = (SLTNode1*)malloc(sizeof(SLTNode1));assert(newnode);newnode->next = NULL;newnode->data = x;SLTNode1* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;
}
void SLTPush2(SLTNode2** pphead, int x)
{assert(pphead);assert(*pphead);SLTNode2* newnode = (SLTNode1*)malloc(sizeof(SLTNode2));assert(newnode);newnode->next = NULL;newnode->data = x;SLTNode2* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;
}
void SLTPrint(SLTNode1* phead1,SLTNode2*phead2)
{assert(phead1->next);assert(phead2->next);SLTNode1* cur1 = phead1->next;SLTNode2* cur2 = phead2->next;while (cur1 != NULL){cur1->data = cur1->data + cur2->data;printf("%d ", cur1->data);cur1 = cur1->next;cur2 = cur2->next;}
}
int main()
{int n = 0;scanf("%d", &n);int* arr1 = (int*)malloc(sizeof(int) * n);int* arr2 = (int*)malloc(sizeof(int) * n);int i = 0;SLTNode1* head1 = Init1();SLTNode2* head2 = Init2();for (i = 0; i < n; i++){scanf("%d", &arr1[i]);}for (i = 0; i < n; i++){scanf("%d", &arr2[i]);}for (i = 0; i < n; i++){SLTPush1(&head1, arr1[i]);}for (i = 0; i < n; i++){SLTPush2(&head2, arr2[i]);}SLTPrint(head1, head2);return 0;
}5.链表删除:
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;
SLTNode* Init()
{SLTNode* phead = (SLTNode*)malloc(sizeof(SLTNode));assert(phead);phead->data = 0;phead->next = NULL;return phead;
}
void SLTPush(SLTNode** pphead, int x)
{assert(pphead);SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));newnode->next = NULL;newnode->data = x;assert(newnode);SLTNode* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;
}
SLTNode* SLTFind(SLTNode* phead, int x)
{assert(phead->next);SLTNode* ptr = phead->next;while (ptr != NULL){if (ptr->data == x){return ptr;}else{ptr = ptr->next;}}return NULL;
}
void SLTPopFront(SLTNode** pphead)
{assert(pphead);assert(*pphead);SLTNode* tail,*temp ;tail = (*pphead)->next;if (tail->next != NULL) {temp = tail->next;(*pphead)->next = temp;}free(tail);tail = NULL;
}
void SLTzErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead);assert(pos);assert(*pphead);if (pos == (*pphead)->next){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){if (prev->next == NULL)return;prev = prev->next;}if (pos->next != NULL)prev->next = pos->next;elseprev->next = NULL;free(pos);pos = NULL;}
}
void SLTPrint(SLTNode* phead)
{assert(phead);assert(phead->next);int sum = 0;SLTNode* cur = phead->next;while (cur != NULL){printf("%d ", cur->data);cur = cur->next;}
}
int main()
{int n = 0;int x = 0;scanf("%d", &n);scanf("%d", &x);int* arr = (int*)malloc(sizeof(int) * n);int i = 0;for (i = 0; i < n; i++){scanf("%d", &arr[i]);}SLTNode* head = Init();for (int i = 0; i < n; i++){SLTPush(&head, arr[i]);}for (i = 0; i < n; i++){SLTNode* pos = SLTFind(head, x);if (pos == NULL)break;SLTzErase(&head, pos);}SLTPrint(head);return 0;
}写这题的时候卡了一下,经过小方同学改错后,发现头删函数不完善,把头节点删了,而且还没有连接头节点和下一个节点,以后书写时需注意,以及循环遇空(NULL)需及时 break ,不然就会被 assert(pos)断言报错。
6.链表添加节点: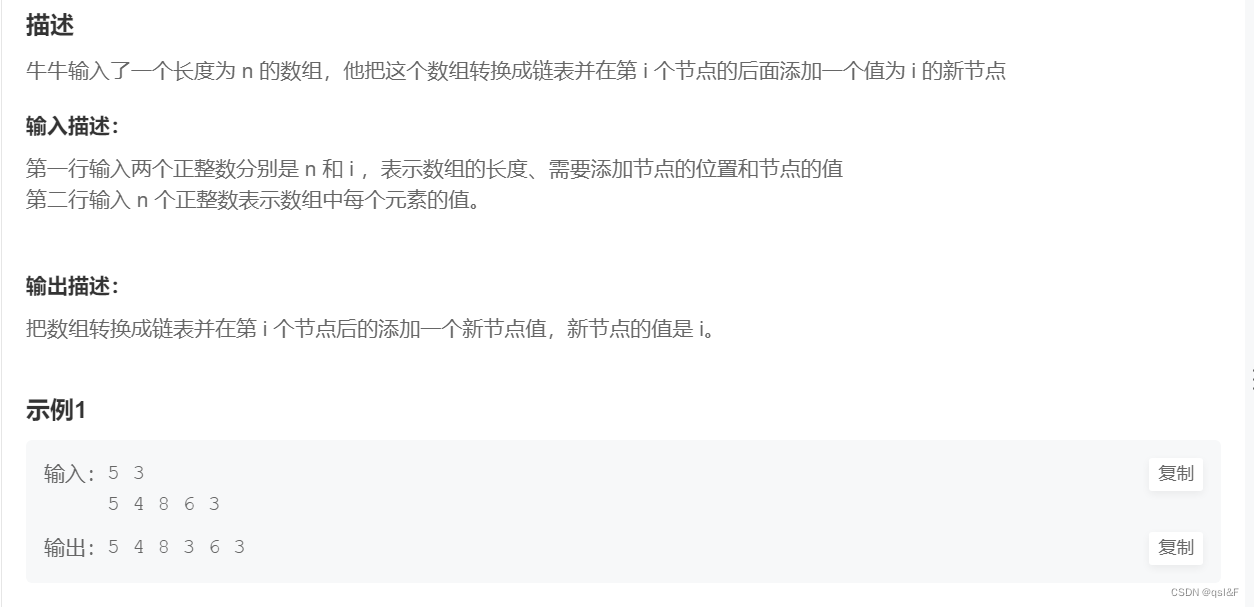
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;
SLTNode* SLTInit()
{SLTNode* phead = (SLTNode*)malloc(sizeof(SLTNode));assert(phead);phead->next = NULL;phead->data = 0;return phead;
}
void SLTPush(SLTNode** pphead, int x)
{assert(pphead);SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));assert(newnode);newnode->next = NULL;newnode->data = x;SLTNode* cur = *pphead;while (cur->next != NULL){cur = cur->next;}cur->next = newnode;
}void SLTPrint(SLTNode* phead)
{assert(phead);assert(phead->next);SLTNode* cur = phead->next;while (cur != NULL){printf("%d ", cur->data);cur = cur->next;}
}
void SLTAdd(SLTNode** pphead, int pos)
{assert(pphead);assert(pos);SLTNode* cur = *pphead;SLTNode* prev = *pphead;for (int i = 0; i < (pos+1); i++){prev = cur;cur = cur->next;}SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));assert(newnode);newnode->next = NULL;newnode->data = pos;newnode->next = cur;prev->next = newnode;
}
int main()
{int n = 0;scanf("%d", &n);//动态数组int i = 0;scanf("%d", &i);int* arr = (int*)malloc(sizeof(int) * n);SLTNode* head = SLTInit();for (int j = 0; j < n; j++){scanf("%d", &arr[j]);}for (int j = 0; j < n; j++){SLTPush(&head, arr[j]);}SLTAdd(&head, i);SLTPrint(head);return 0;
}
链表基础题目已完成,可以较为熟练使用链表来解决相关问题。
相关文章:
链表——超详细
一、无头单向非循环链表 1.结构(两个部分): typedef int SLTDataType; typedef struct SListNode {SLTDataType data;//数据域struct SListNode* next;//指针域 }SLNode; 它只有一个数字域和一个指针域,里面数据域就是所存放的…...
【刷题】 leetcode 面试题 08.05.递归乘法
递归乘法 1 题目描述2 思路一(返璞归真版)3 思路二(二进制乘法器版)4 思路三(变态版)Thanks♪(・ω・)ノ谢谢阅读下一篇文章见!!! 1 题目…...
C语言实现希尔排序算法(附带源代码)
希尔排序 希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的: 插入排序在对几乎已经排好序的数据操作时,效率高࿰…...
:取taxlist对象的子集)
R语言【taxlist】——subset():取taxlist对象的子集
Package taxlist version 0.2.4 Description taxlist对象的子集将通过逻辑操作或模式匹配来完成。子集可以引用包含在插槽taxonNames、taxonRelations或taxonTraits中的信息。 Usage ## S4 method for signature taxlist subset(x,subset,slot "names",keep_child…...

单片机学习笔记---定时器计数器(含寄存器)工作原理介绍(详解篇2)
目录 T1工作在方式2时 T0工作在方式3时 四种工作方式的总结 定时计数器对输入信号的要求 定时计数器对的编程的一个要求 关于初值计算的问题 4种工作方式的最大定时时间的大小 关于编程方式的问题 实例分析 实例1 实例2 T1工作在方式2时 51单片机,有两个…...

《动手学深度学习(PyTorch版)》笔记4.1
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...

OpenAI发布新模型!ChatGPT性能重磅提升,API大幅降价,GPT-4 「变懒」被修复
OpenAI 对ChatGPT进行了大更新:推出了新一代的嵌入模型,对GPT-4 Turbo模型进行了更新,并将很快对GPT-3.5 Turbo的API进行大幅降价,GPT-4「变懒」行为也被修复。 接下来二狗就带大家看看ChatGPT的这次详细更新。 推出新的嵌入模型…...
【C深度解剖】计算机数据下载和删除原理
简介:本系列博客为C深度解剖系列内容,以某个点为中心进行相关详细拓展 适宜人群:已大体了解C语法同学 作者留言:本博客相关内容如需转载请注明出处,本人学疏才浅,难免存在些许错误,望留言指正 作…...

ASTORS国土安全奖:ManageEngine AD360荣获银奖
美国安全今日(AST)的年度“ASTORS”国土安全奖计划是一个备受瞩目的活动,致力于突显国土安全领域的创新与进步。这一奖项旨在表彰在保护国家免受安全威胁方面做出卓越贡献的个人和组织。该计划汇聚了执法、公共安全和行业领袖,不仅…...

clang--cpplint--gitlint
clang_format clang_format是什么 代码格式化工具 clang_format 官网和官网教程 中文教程 下载 sudo apt install clang sudo apt install clang-format#查看下载是否成功 clang --version 代码的构建到提交的过程: cmake .. make make test make clang_f…...

Web开发8:前后端分离开发
在现代的 Web 开发中,前后端分离开发已经成为了一种常见的架构模式。它的优势在于前端和后端可以独立开发,互不干扰,同时也提供了更好的可扩展性和灵活性。本篇博客将介绍前后端分离开发的概念、优势以及如何实现。 什么是前后端分离开发&am…...
基于 java+springboot+mybatis电影售票网站管理系统前台+后台设计和实现
基于 javaspringbootmybatis电影售票网站管理系统前台后台设计和实现 🍅 作者主页 央顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承…...
】错误:*.onchip_flash_0:UFM 扇区不支持“隐藏”模式。请更新访问模式设置)
【INTEL(ALTERA)】错误:*.onchip_flash_0:UFM 扇区不支持“隐藏”模式。请更新访问模式设置
说明 由于英特尔 Quartus Prime Standard Edition 软件版本 22.1 存在一个问题,当您针对 10 FPGA Compact 变体英特尔 MAX在片上闪存英特尔 FPGA IP中选择单压缩映像配置模式时,可能会出现以下错误消息。 错误:*.onchip_flash_0:…...

备战蓝桥杯---数据结构与STL应用(基础3)
今天我们主要介绍的是pair,string,set,map pair:我们可以把它当作一个结构体: void solve(){pair<int int> a;//创建amake_pair(1,2);//添加元素cout<<a.first<<endl<<a.second<<endl;}//输出 当然,它也可以嵌套&#…...

「优选算法刷题」:只出现一次的数字Ⅲ
一、题目 给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。 你必须设计并实现线性时间复杂度的算法且仅使用常量额外空间来解决此问题。 示例 1: …...
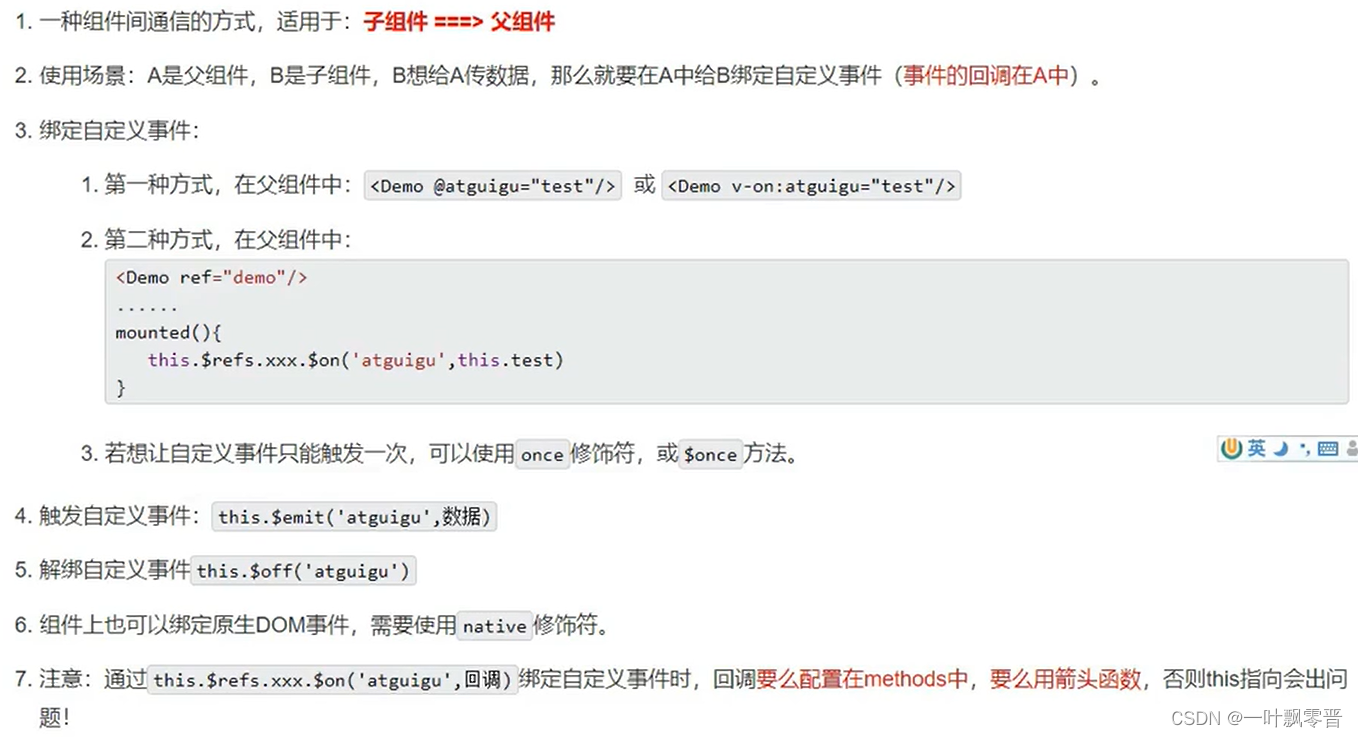
Vue-43、Vue中组件自定义事件
1、给学生绑定atguigu事件 2、在组件内触发事件 第二种写法 传多个参数。 解绑 解绑一个事件 解绑多个自定义事件 this.$off([xxx1,xxx2]);解绑所有事件 this.$off();总结...

GitHub 开启 2FA 双重身份验证的方法
为什么要开启 2FA 自2023年3月13日起,我们登录 GitHub 都会看到一个要求 Enable 2FA 的重要提示,具体如下: GitHub users are now required to enable two-factor authentication as an additional security measure. Your activity on GitHub includes you in this requi…...
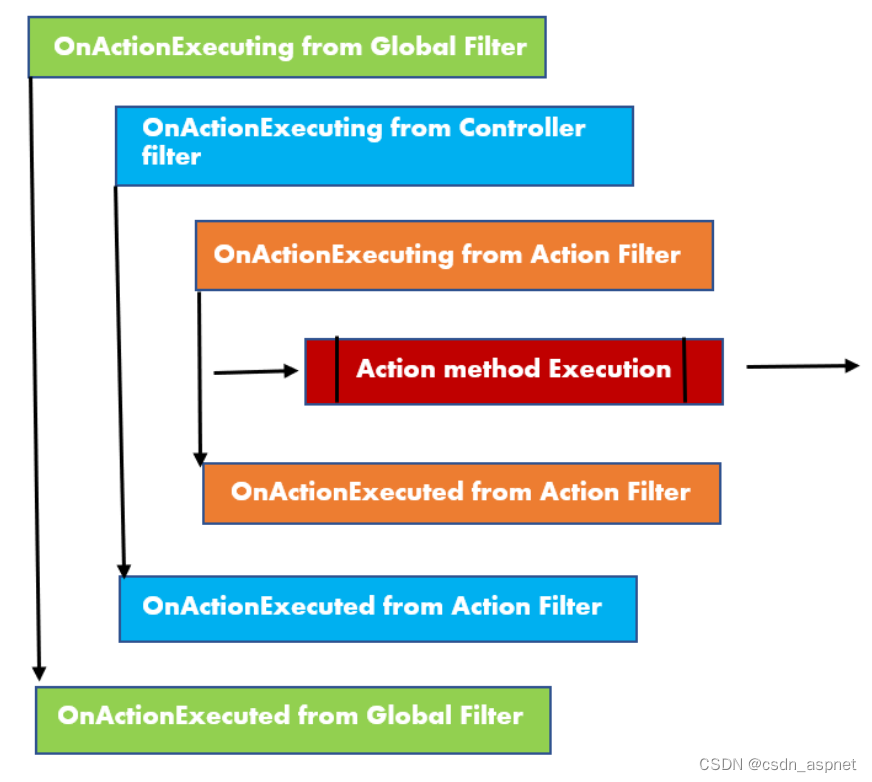
ASP.NET Core 过滤器 使用依赖项注入
过滤器是 ASP.NET Core 中的特殊组件,允许我们在请求管道的特定阶段控制请求的执行。这些过滤器在中间件执行后以及 MVC 中间件匹配路由并调用特定操作时发挥作用。 简而言之,过滤器提供了一种在操作级别自定义应用程序行为的方法。它们就像检查点&#…...

2024年的网创之路应该这样走才对
2024年的网创之路应该这样走才对 大家都知道这两年经济环境不好,钱不好挣,对于普通人,只有一条出路,就是学某项技能,然后死磕,不能提升某项技能的项目,打死也不做,因为多数项目都是…...

ssh异常报错:Did not receive identification string from
一、问题描述 某次外出在异地工作场所xshell炼乳远程服务器时,报错:Connection closed by foreign host. D,服务器查看secure日志或sshd服务状态会显示:id not receive identification string from client_ip; 二、分析处理 1&a…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...

关于我第九次博客作业
(1)Flex布局核心概念一、Flex 是什么Flex 是 CSS3 一维弹性布局,专治元素对齐、自适应、空间分配问题,布局更高效灵活。二、两大核心角色1. 父容器(Flex容器)设置 display: flex 即为弹性父盒子,负责统一规定子元素排列…...

AVR+ESP8266双核架构打造独立WiFi天气显示器:从硬件设计到软件实现
1. 项目概述:一个独立WiFi天气显示器的诞生几年前,我琢磨着在书桌上放一个能实时显示天气信息的小玩意儿,市面上成品要么功能单一,要么价格不菲,要么数据源依赖复杂的服务器。于是,我决定自己动手ÿ…...

Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑
Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾经因为复杂的视频编辑软件而头疼?想要一个免费、开源且…...
)
别再手动触发ADC了!用STM32CubeMX配置定时器触发+DMA搬运,实现精准采样(附F1/F4差异说明)
STM32CubeMX定时器触发ADCDMA全自动采样实战指南 在嵌入式数据采集系统中,ADC采样的精准度和效率直接影响整个系统的性能表现。传统的手动触发方式不仅占用CPU资源,还难以保证采样间隔的一致性。本文将深入解析如何利用STM32CubeMX配置定时器触发ADC配合…...

机器学习记忆化:平衡隐私、公平与鲁棒性的可信AI实践
1. 项目概述与核心挑战 在机器学习领域,我们常常追求一个“完美”的模型:它既能精准地识别出图片中的猫狗,又能流畅地生成人类般的文本,还能在医疗诊断中给出可靠的建议。为了实现这些目标,我们投入海量数据࿰…...

Unity背包拖拽实战:三坐标系映射与跨Panel交互原理
1. 这不是“拖一拖就完事”的UI小功能,而是Unity UI系统能力的实战压力测试 在Unity项目里,“背包装备拖拽”这六个字,新手常以为只是给Image加个DragHandler接口、写几行OnBeginDrag/OnDrag/OnEndDrag回调——结果上线前一周,策划…...