Redis五种数据类型及应用场景
 1、数据类型
1、数据类型
String(字符串,整数,浮点数):做简单的键值对缓存
List(列表):储存一些列表类型的数据结构
Hash(哈希):包含键值对的无序散列表,结构化的数据
Set(无序集合):交集,并集,差集的操作
Zset(有序集合)(Sorted sets):去重同时也可以排序
先通过一张图了解下Redis内部内存管理中是如何描述这些不同数据类型的:
首先Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
这里需要特殊说明一下vm字段,只有打开了Redis的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的。通过上图我们可以发现Redis使用redisObject来表示所有的key/value数据是比较浪费内存的,当然这些内存管理成本的付出主要也是为了给Redis不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用,我们随后会具体讨论。
一、string
string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。value其实不仅是String,也可以是数字。string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
常用命令:get、set、incr、decr、mget等。
应用场景:String是最常用的一种数据类型,普通的key/ value 存储都可以归为此类,即可以完全实现目前 Memcached 的功能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还提供了下面一些操作:
获取字符串长度
往字符串append内容
设置和获取字符串的某一段内容
设置及获取字符串的某一位(bit)
批量设置一系列字符串的内容
使用场景:常规key-value缓存应用。常规计数: 微博数, 粉丝数。 实现方式:String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
redis 127.0.0.1:6379> SET name "runoob"
"OK" redis 127.0.0.1:6379> GET name
"runoob"
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为 runoob。
**注意**:一个键最大能存储512MB。
二、Hash
Hash 是一个键值(key => value)对集合。Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。 常用命令:hget,hset,hgetall 等。 应用场景:我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
image
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
image
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:
image
也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题,很好的解决了问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。 使用场景:存储部分变更数据,如用户信息等。 实现方式:上面已经说到Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
redis> HSET myhash field1 "Hello" field2 "World"
"OK" redis> HGET myhash field1
"Hello" redis> HGET myhash field2
"World"
实例中我们使用了 Redis HMSET, HGET 命令,HMSET 设置了两个 field=>value 对, HGET 获取对应 field 对应的 value。每个 hash 可以存储 232 -1 键值对(40多亿)。
三、list
list 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
常用命令:lpush(添加左边元素),rpush,lpop(移除左边第一个元素),rpop,lrange(获取列表片段,LRANGE key start stop)等。
应用场景:Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
List 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用List结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列, 可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元素。
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。 获取越接近两端的元素速度越快,但通过索引访问时会比较慢。
使用场景: 消息队列系统:使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。比如:将Redis用作日志收集器,实际上还是一个队列,多个端点将日志信息写入Redis,然后一个worker统一将所有日志写到磁盘。
取最新N个数据的操作:记录前N个最新登陆的用户Id列表,超出的范围可以从数据库中获得。
复制代码
//把当前登录人添加到链表里
ret = r.lpush("login:last_login_times", uid) //保持链表只有N位
ret = redis.ltrim("login:last_login_times", 0, N-1) //获得前N个最新登陆的用户Id列表
last_login_list = r.lrange("login:last_login_times", 0, N-1)
复制代码
比如微博: 在Redis中我们的最新微博ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。我们的系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
复制代码
redis 127.0.0.1:6379> lpush runoob redis
(integer) 1 redis 127.0.0.1:6379> lpush runoob mongodb
(integer) 2 redis 127.0.0.1:6379> lpush runoob rabitmq
(integer) 3 redis 127.0.0.1:6379> lrange runoob 0 10
1) "rabitmq"
2) "mongodb"
3) "redis" redis 127.0.0.1:6379>
复制代码
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
四、 set
set 是string类型的无序集合。集合是通过hashtable实现的,概念和数学中个的集合基本类似,可以交集,并集,差集等等,set中的元素是没有顺序的。所以添加,删除,查找的复杂度都是O(1)。
*sadd 命令:*添加一个 string 元素到 key 对应的 set 集合中,成功返回1,如果元素已经在集合中返回 0,如果 key 对应的 set 不存在则返回错误。
常用命令:sadd,spop,smembers,sunion 等。
应用场景:Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Set 就是一个集合,集合的概念就是一堆不重复值的组合。利用Redis提供的Set数据结构,可以存储一些集合性的数据。
案例:在微博中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
实现方式: set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
使用场景: ①交集,并集,差集:(Set)
复制代码
//book表存储book名称
set book:1:name ”The Ruby Programming Language”
set book:2:name ”Ruby on rail”
set book:3:name ”Programming Erlang” //tag表使用集合来存储数据,因为集合擅长求交集、并集
sadd tag:ruby 1 sadd tag:ruby 2 sadd tag:web 2 sadd tag:erlang 3
//即属于ruby又属于web的书?
inter_list = redis.sinter("tag.web", "tag:ruby") //即属于ruby,但不属于web的书?
inter_list = redis.sdiff("tag.ruby", "tag:web") //属于ruby和属于web的书的合集?
inter_list = redis.sunion("tag.ruby", "tag:web")
复制代码
②获取某段时间所有数据去重值 这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
sadd key member
复制代码
redis 127.0.0.1:6379> sadd runoob redis
(integer) 1 redis 127.0.0.1:6379> sadd runoob mongodb
(integer) 1 redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 1 redis 127.0.0.1:6379> sadd runoob rabitmq
(integer) 0 redis 127.0.0.1:6379> smembers runoob
1) "redis"
2) "rabitmq"
3) "mongodb"
复制代码
**注意**: 以上实例中 rabitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。
五 、zset
zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。 *zadd 命令:*添加元素到集合,元素在集合中存在则更新对应score。 常用命令:zadd,zrange,zrem,zcard等
使用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。和Set相比,Sorted Set关联了一个double类型权重参数score,使得集合中的元素能够按score进行有序排列,redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。比如一个存储全班同学成绩的Sorted Set,其集合value可以是同学的学号,而score就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。另外还可以用Sorted Set来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
相关文章:
Redis五种数据类型及应用场景
1、数据类型 String(字符串,整数,浮点数):做简单的键值对缓存 List(列表):储存一些列表类型的数据结构 Hash(哈希):包含键值对的无序散列表,结构化的数据 Set(无序集合):交集,并集…...
测试环境搭建整套大数据系统(一:基础配置,修改hostname,hosts,免密)
一:使用服务器配置。 二:修改服务器名称hostname,hosts。 在 Linux 系统中,hostname 和 /etc/hosts 文件分别用于管理主机名和主机名解析。 在三台服务器上,分别执行以下命令。 vim /etc/hostnamexdso-hadoop-test-0…...
maven helper 解决jar包冲突方法
一 概要说明 1.1 说明 首先,解决idea中jar包冲突,使用maven的插件:maven helper插件,它能够给我们罗列出来同一个jar包的不同版本,以及他们的来源,但是对不同jar包中同名的类没有办法。 1.2 依赖顺序 …...
)
AppSrv-文件共享(23国赛真题)
2023全国职业院校技能大赛网络系统管理赛项–模块B:服务部署(WindowServer2022) 文章目录 AppSrv-文件共享题目配置步骤创建用户主目录共享文件夹:本地目录为d:\share\users\,允许所有域用户可读可写。在本目录下为所有用户添加一个以名称命名的文件夹,该文件夹将设置为所…...

AsyncLocal是如何实现在Thread直接传值的?
一:背景 1. 讲故事 这个问题的由来是在.NET高级调试训练营第十期分享ThreadStatic底层玩法的时候,有朋友提出了AsyncLocal是如何实现的,虽然做了口头上的表述,但总还是会不具体,所以觉得有必要用文字图表的方式来系统…...
Flask 入门1:一个简单的 Web 程序
1. 关于 Flask Flask诞生于2010年, Armin Ronacher的一个愚人节玩笑。不过现在已经是一个用python语言基于Werkzeug工具箱编写的轻量级web开发框架,它主要面向需求简单,项目周期短的小应用。 Flask本身相当于一个内核,其他几乎所…...
维护管理Harbor,docker容器的重启策略
维护管理Harbor 通过HarborWeb创建项目 在 Harbor 仓库中,任何镜像在被 push 到 regsitry 之前都必须有一个自己所属的项目。 单击“项目”,填写项目名称,项目级别若设置为"私有",则不勾选。如果设置为公共仓库&#…...
Qt6入门教程 14:QToolButton
目录 一.简介 二.常用接口 1.void setMenu(QMenu * menu) 2.void setPopupMode(ToolButtonPopupMode mode) 3.void setToolButtonStyle(Qt::ToolButtonStyle style) 4.void setArrowType(Qt::ArrowType type) 5.void setDefaultAction(QAction * action) 三.实战演练 1…...
3D数据转换器HOOPS Exchange如何获取模型的几何数据? 干货预警!
一、概述 前面讲解过模型在内存中的结构,现在回顾一下,当模型导入成功后,整个模型数据会以原生结构的 PRC 组装树形式存放到内存中。(申请 HOOPS Exchange 试用) PRC结构的主要类型包含四种,分别是…...

Coremail启动鸿蒙原生应用开发,打造全场景邮件办公新体验
1月18日,华为在深圳举行鸿蒙生态千帆启航仪式,Coremail出席仪式并与华为签署鸿蒙合作协议,宣布正式启动鸿蒙原生应用开发。作为首批拥抱鸿蒙的邮件领域伙伴,Coremail的加入标志着鸿蒙生态版图进一步完善。 Coremail是国内自建邮件…...

基于CVITEK_CV1821+SOI_Q03P的IPC方案
方案概述: 该方案基于主控平台CVITEK_CV1821和sensor SOI_Q03P,运用于智能监控IP摄像头,可用于户外或室内。采用了2304x1296的分辨率,30的帧率,支持HDR。作为3M的监控摄像头,通过ISP图像调校技术ÿ…...

chromedriver安装和环境变量配置
chromedriver 1、安装2、【重点】环境变量配置(1)包的复制:(2)系统环境变量配置 3、验证 1、安装 网上随便搜一篇chromedriver的安装文档即可。这里是一个快速链接 特别提醒:截止2024.1.30,chr…...

Linux浅学笔记03
目录 有关root的命令 用户和用户组 用户组管理:(以下需要root用户执行) 创建用户组: 删除用户组: 用户管理:(以下需要root用户执行) 创建用户: 删除用户: 查看用…...
【vue】图片加载骨架
一、前言 在网速较低或者网站的服务器宽带只有几MB的情况下,网页中的图片加载时,要么空白,要么像打印机一样一行一行地“扫描”出来,为了提升用户体验,可以给图片标签外加一层骨架。 无骨架 有骨架 二、详细设计 每张…...
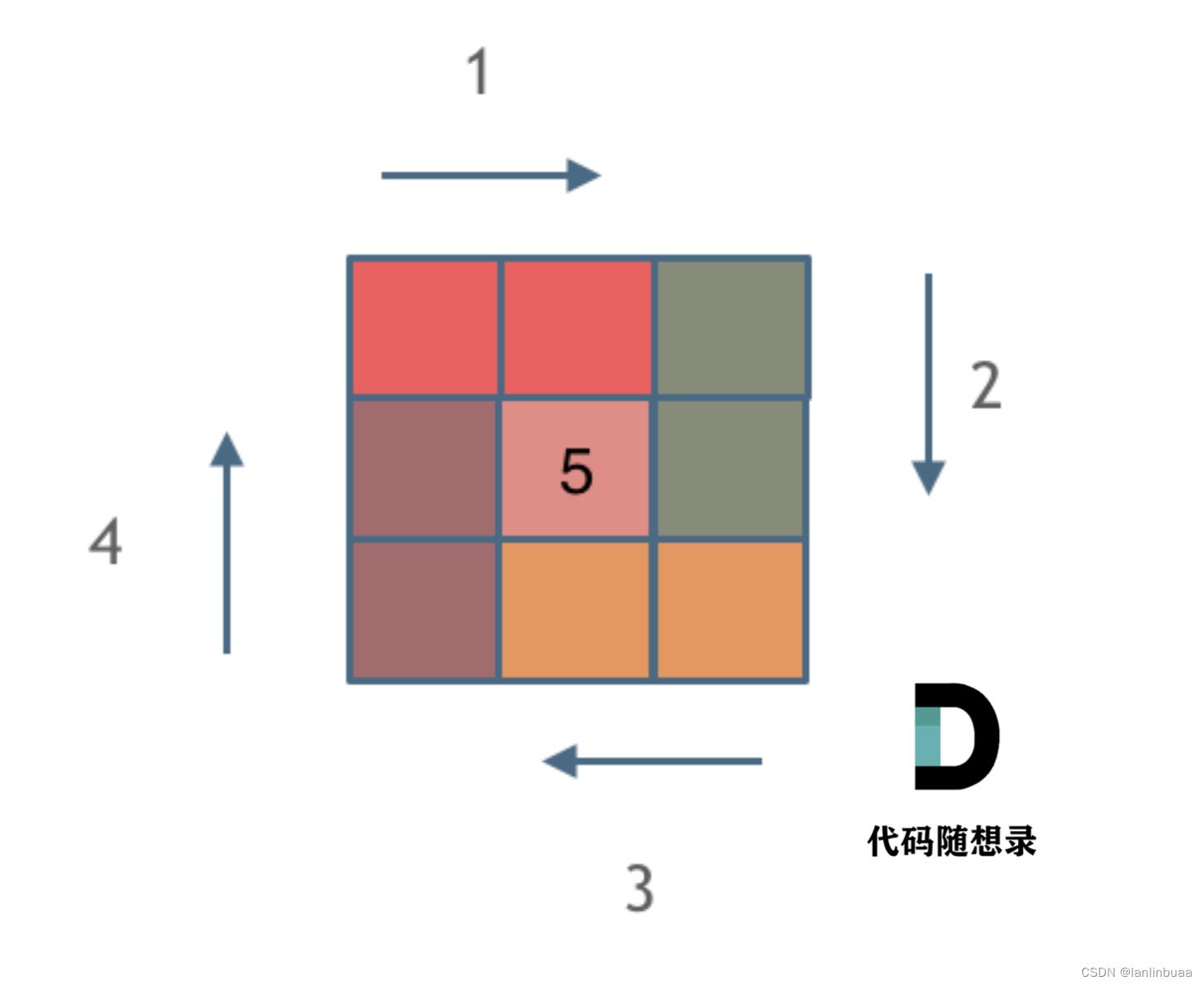
leetcode59. 螺旋矩阵 II
leetcode59. 螺旋矩阵 II 题目 思路 螺旋数组,一次螺旋4个方向(上行从左到右、右列从上到下、下行从右到左、左列从下到上),共执行(n//2)次螺旋。且对于n为奇数时,额外填充中心点nums[mid][mid] n 每一次螺旋圈下来…...

bash 5.2中文修订5
Grouping Commands 命令分组 Bash 提供两种方法将要执行的命令列表分组为一个单元。当命令被分组时,重定向可以应用于整个命令列表。例如,列表中所有命令的输出可以被重定向到单个流。 () 圆括号命令分组 ( list ) 将命令列表放在括号之间会强制 she…...

5GNR解调分析手持式频谱分析仪
2024年已经是5G网络全面普及的一年,手机也基本都升级了5G版本,那么同样的,5G的网络运行也是需要维护的。 我们知道,5G是新型的网络传输技术,如果一般的频谱分析仪是没有办法单独针对5G NR进行解析的。这个时候你就需要…...
互联网加竞赛 基于深度学习的人脸表情识别
文章目录 0 前言1 技术介绍1.1 技术概括1.2 目前表情识别实现技术 2 实现效果3 深度学习表情识别实现过程3.1 网络架构3.2 数据3.3 实现流程3.4 部分实现代码 4 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的人脸表情识别 该项目较…...

python-自动化篇-运维-监控-简单实例-道出如何使⽤Python进⾏网络监控?
如何使⽤Python进⾏⽹络监控? 使⽤Python进⾏⽹络监控可以帮助实时监视⽹络设备、流量和服务的状态,以便及时识别和解决问题。 以下是⼀般步骤,说明如何使⽤Python进⾏⽹络监控: 选择监控⼯具和库:选择适合⽹络监控需…...
SpringBoot 配置类解析
全局流程解析 配置类解析入口 postProcessBeanDefinitionRegistry逻辑 processConfigBeanDefinitions逻辑 执行逻辑解析 执行入口 ConfigurationClassPostProcessor.processConfigBeanDefinitions()方法中的do while循环体中 循环体逻辑 parse方法调用链 doProcessConfigurat…...

百度网盘下载速度太慢?Python脚本帮你获取高速直链
百度网盘下载速度太慢?Python脚本帮你获取高速直链 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的下载速度而苦恼吗?想要摆脱客…...

告别无效编程!Cursor + 高德地图实战,解锁AI开发效率密码
当GitHub Copilot还在逐行补全代码时,Cursor已经让开发者用"聊天"的方式写项目了。从Cursor的四大快捷键到AI幻觉的实战应对,从Vibe Coding的前沿理念到高德地图的AI落地实践,本文将带你深度理解AI编程的现在与未来。 目录 一、Cur…...

告别‘找茬’游戏:用Python复现ALCNet,让红外小目标检测又快又准
从理论到实践:用Python实现ALCNet红外小目标检测全流程红外图像中的小目标检测一直是计算机视觉领域的难点——目标可能只有几个像素大小,却要对抗复杂的背景噪声。传统方法依赖人工设计的特征,而ALCNet通过膨胀局部对比度度量和循环移位加速…...

SPTD:从训练动态中挖掘置信度信号,提升AI模型选择性预测能力
1. 项目概述:当模型学会说“我不知道”在医疗影像诊断、自动驾驶决策或者金融风控这些领域,一个AI模型的预测错误,代价可能是巨大的。我们通常希望模型不仅给出答案,还能告诉我们它对这个答案有多“确信”。这就是不确定性量化的核…...

C++上位机软件工程师面试记录
目录 (一) 1. Qt 常用多线程类有哪些? 2. Qt 多线程不重写 run() 如何使用? 3. TCP 粘包、半包问题如何处理? 4. TCP 与 UDP 有什么区别? 5. TCP 三次握手、四次挥手基本原理 6. Modbus RTU 和 Modbus TCP …...

从华为EulerOS到openEuler:一个国产操作系统的开源之路与社区生态
从华为EulerOS到openEuler:一个国产操作系统的开源之路与社区生态在开源软件的世界里,每一个成功项目的背后都有一段独特的故事。当华为决定将其内部使用的EulerOS操作系统开源为openEuler时,这不仅是一个技术决策,更是一次关于开…...

如何快速掌握Apache Camel:企业集成模式实战指南
如何快速掌握Apache Camel:企业集成模式实战指南 【免费下载链接】camelinaction2 :camel: This project hosts the source code for the examples of the Camel in Action 2nd ed book :closed_book: written by Claus Ibsen and Jonathan Anstey. 项目地址: htt…...
)
保姆级教程:用再生龙Clonezilla Live给Ubuntu系统做全盘备份与恢复(含BIOS设置避坑)
从零掌握Clonezilla:Ubuntu系统全盘备份与恢复实战指南当你的Ubuntu系统突然崩溃,或是需要快速部署多台相同配置的机器时,一个可靠的系统备份方案能让你从容应对。Clonezilla作为开源备份神器,其强大功能不输商业软件,…...

基于PSO的多目标优化匿名化模型MO-OBAM:平衡隐私保护与数据效用的实战指南
1. 项目概述:当数据共享遇上隐私红线,我们如何破局?在数据驱动的时代,无论是医疗研究中的患者电子病历、金融风控中的信用记录,还是商业分析中的用户行为数据,其共享与分析都蕴含着巨大的价值。然而&#x…...

UE5 CPU瓶颈定位实战:用ProfileCPU精准揪出Game线程卡顿根因
1. 这不是“点开就看”的性能分析,而是UE5里真正能救命的CPU瓶颈定位术在UE5项目做到中后期,你肯定经历过那种“明明没加多少新功能,帧率却从60掉到35,Editor卡得像PPT”的窒息时刻。打开Stat Unit,看到Game线程时间飙…...