CUDA编程- - GPU线程的理解 thread,block,grid - 学习记录
GPU线程的理解 thread,block,grid
- 一、从 cpu 多线程角度理解 gpu 多线程
- 1、cpu 多线程并行加速
- 2、gpu多线程并行加速
- 2.1、cpu 线程与 gpu 线程的理解(核函数)
- 2.1.1 、第一步:编写核函数
- 2.1.2、第二步:调用核函数(使用内核函数)
- 2.1.3、第三步:编写 CMakeLists & 编译代码
- 二、重要概念 & 与线程索引的直观理解
- 2.1、重要概念
- 2.2、dim3与启动内核
- 2.3、如何找到线程块的索引
- 2.4、如何找到绝对线程索引
- 三、参考代码(打印索引)
- 3.1、打印一维索引
- 3.2、打印二维索引
- 3.2、扩展应用 (获取图片坐标)
一、从 cpu 多线程角度理解 gpu 多线程
1、cpu 多线程并行加速
在 cpu 中,用 openmp 并行计算,有限的线程数对 128 进行分组运算。
#pragma omp parallel for
for(int i =0;i<128;i++)
{a[i]=b[i]*c[i];
}
2、gpu多线程并行加速
在 gpu 中,可以直接开启 128 个线程对其进行计算。下面步骤和代码是演示如何开启 128个线程并打印
2.1、cpu 线程与 gpu 线程的理解(核函数)
2.1.1 、第一步:编写核函数
__global__ void some_kernel_func(int *a, int *b, int *c)
{// 初始化线程IDint i = (blockIdx.x * blockDim.x) + threadIdx.x;// 对数组元素进行乘法运算a[i] = b[i] * c[i];// 打印打前处理的进程ID// 可以看到blockIdx并非是按照顺序启动的,这也说明线程块启动的随机性printf("blockIdx.x = %d,blockDimx.x = %d,threadIdx.x = %d\n", blockIdx.x, blockDim.x, threadIdx.x);
}
2.1.2、第二步:调用核函数(使用内核函数)
#)调用语法
kernel_function<<<num_blocks,num_threads>>>(param1,param2,...)
- num_blocks 线程块,至少保证一个线程块
- num_threads 执行内核函数的线程数量
#)tips:
1、 some_kernel_func<<<1,128>>>(a,b,c); 调用 some_kernel_func 1*128 次
2、 some_kernel_func<<<2,128>>>(a,b,c); 调用 some_kernel_func 2*128 次
3、如果将 num_blocks 从 1 改成 2 ,则表示 gpu 将启动两倍于之前的线程数量的线程,
在 blockIdx.x = 0 中,i = threadIdx.x
在 blockIdx.x = 1 中, blockDim.x 表示所要求每个线程块启动的线程数量,在这 = 128
2.1.3、第三步:编写 CMakeLists & 编译代码
CMakeLists.txt
cmake_minimum_required(VERSION 2.8 FATAL_ERROR)
project(demo)
add_definitions(-std=c++14)
find_package(CUDA REQUIRED)# add cuda
include_directories(${CUDA_INCLUDE_DIRS} )
message("CUDA_LIBRARIES:${CUDA_LIBRARIES}")
message("CUDA_INCLUDE_DIRS:${CUDA_INCLUDE_DIRS}")
cuda_add_executable(demo print_theardId.cu)# link
target_link_libraries (demo ${CUDA_LIBRARIES})
print_theardId.cu
#include <stdio.h>
#include <stdlib.h>#include <cuda.h>
#include <cuda_runtime.h>/*gpu 中的矩阵乘法*/
__global__ void some_kernel_func(int *a, int *b, int *c)
{// 初始化线程IDint i = (blockIdx.x * blockDim.x) + threadIdx.x;// 对数组元素进行乘法运算a[i] = b[i] * c[i];// 打印打前处理的进程ID// 可以看到blockIdx并非是按照顺序启动的,这也说明线程块启动的随机性printf("blockIdx.x = %d,blockDimx.x = %d,threadIdx.x = %d\n", blockIdx.x, blockDim.x, threadIdx.x);
}int main(void)
{// 初始化指针元素int *a, *b, *c;// 初始化GPU指针元素int *gpu_a, *gpu_b, *gpu_c;// 初始化数组大小int size = 128 * sizeof(int);// 为CPU指针元素分配内存a = (int *)malloc(size);b = (int *)malloc(size);c = (int *)malloc(size);// 为GPU指针元素分配内存cudaMalloc((void **)&gpu_a, size);cudaMalloc((void **)&gpu_b, size);cudaMalloc((void **)&gpu_c, size);// 初始化数组元素for (int i = 0; i < 128; i++){b[i] = i;c[i] = i;}// 将数组元素复制到GPU中cudaMemcpy(gpu_b, b, size, cudaMemcpyHostToDevice);cudaMemcpy(gpu_c, c, size, cudaMemcpyHostToDevice);// 执行GPU核函数some_kernel_func<<<4, 32>>>(gpu_a, gpu_b, gpu_c);// 将GPU中的结果复制到CPU中cudaMemcpy(a, gpu_a, size, cudaMemcpyDeviceToHost);// 释放GPU和CPU中的内存cudaFree(gpu_a);cudaFree(gpu_b);cudaFree(gpu_c);free(a);free(b);free(c);return 0;
}
mkdir build
cd build
cmake ..
make
./demo
部分结果:
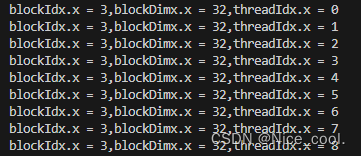
可以看到,
1、gpu 可以直接调用很多个线程,
2、线程数量的多少是由线程块,线程,线程网格等决定的,
3、在核函数中编写单个线程的使用代码,再调用核函数,便可简单的达到 cpu 中 openmp 的多线程方式
二、重要概念 & 与线程索引的直观理解
2.1、重要概念

gridDim.x – 线程网格X维度的线程块数目
gridDim.y – 线程网格Y维度的线程块数目
blockDim.x – 一个线程块X维度上的线程数量
blockDim.y – 一个线程块Y维度上的线程数量
theadIdx.x – 线程块X维度上的线程数量
theadIdx.y – 线程块Y维度上的线程数量
一般来说:
一个 kernel 对应一个 grid
一个 grid 可以有多个 block,一维~三维
一个 block 可以有多个 thread,一维~三维
2.2、dim3与启动内核
dim3 是CUDA中的特殊数据结构,可用来创建二维的线程块与线程网络
eg:4个线程块,128个线程
dim3 threads_rect(32,4) // 每个线程块在X方向开启32个线程,Y方向开启4个线程
dim3 blocks_rect(1,4) //在线程网格上,x方向1个线程块,Y方向4个线程
or
dim3 threads_square(16,8)
dim3 blocks_square(2,2)
以上两种方式线程数都是 32x4=128 , 16x8=128,只是线程块中线程的排布方式不一样
启动内核
1、 some_kernel_func<<<blocks_rect,threads_rect>>>(a,b,c);
2、 some_kernel_func<<<blocks_square,threads_square>>>(a,b,c);
2.3、如何找到线程块的索引
线程块的索引 x 线程块的大小 + 线程数量的起始点
参考核函数
// 定义ID查询函数
__global__ void what_is_my_id(unsigned int *const block,unsigned int *const thread,unsigned int *const warp,unsigned int *const calc_thread)
{/*线程ID是线程块的索引 x 线程块的大小 + 线程数量的起始点*/const unsigned int thread_idx = (blockIdx.x * blockDim.x) + threadIdx.x;block[thread_idx] = blockIdx.x;thread[thread_idx] = threadIdx.x;/*线程束 = 线程ID / 内置变量warpSize*/warp[thread_idx] = thread_idx / warpSize;calc_thread[thread_idx] = thread_idx;
}
来个.cu文件,体验一下这个核函数,// 编译方法同上
#include <stdio.h>
#include <stdlib.h>#include "cuda.h"
#include "cuda_runtime.h"// 定义ID查询函数
__global__ void what_is_my_id(unsigned int *const block,unsigned int *const thread,unsigned int *const warp,unsigned int *const calc_thread)
{/*线程ID是线程块的索引 x 线程块的大小 + 线程数量的起始点*/const unsigned int thread_idx = (blockIdx.x * blockDim.x) + threadIdx.x;block[thread_idx] = blockIdx.x;thread[thread_idx] = threadIdx.x;/*线程束 = 线程ID / 内置变量warpSize*/warp[thread_idx] = thread_idx / warpSize;calc_thread[thread_idx] = thread_idx;
}// 定义数组大小
#define ARRAY_SIZE 1024
// 定义数组字节大小
#define ARRAY_BYTES ARRAY_SIZE * sizeof(unsigned int)// 声明主机下参数
unsigned int cpu_block[ARRAY_SIZE];
unsigned int cpu_thread[ARRAY_SIZE];
unsigned int cpu_warp[ARRAY_SIZE];
unsigned int cpu_calc_thread[ARRAY_SIZE];// 定义主函数
int main(void)
{// 总线程数量为 2 x 64 = 128// 初始化线程块和线程数量const unsigned int num_blocks = 2;const unsigned int num_threads = 64;char ch;// 声明设备下参数unsigned int *gpu_block, *gpu_thread, *gpu_warp, *gpu_calc_thread;// 声明循环数量unsigned int i;// 为设备下参数分配内存cudaMalloc((void **)&gpu_block, ARRAY_BYTES);cudaMalloc((void **)&gpu_thread, ARRAY_BYTES);cudaMalloc((void **)&gpu_warp, ARRAY_BYTES);cudaMalloc((void **)&gpu_calc_thread, ARRAY_BYTES);// 调用核函数what_is_my_id<<<num_blocks, num_threads>>>(gpu_block, gpu_thread, gpu_warp, gpu_calc_thread);// 将设备下参数复制到主机下cudaMemcpy(cpu_block, gpu_block, ARRAY_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_thread, gpu_thread, ARRAY_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_warp, gpu_warp, ARRAY_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_calc_thread, gpu_calc_thread, ARRAY_BYTES, cudaMemcpyDeviceToHost);// 释放GPU内存cudaFree(gpu_block);cudaFree(gpu_thread);cudaFree(gpu_warp);cudaFree(gpu_calc_thread);// 循环打印结果for (i = 0; i < ARRAY_SIZE; i++){printf("Calculated Thread: %d - Block: %d - Warp: %d - Thread: %d\n", cpu_calc_thread[i], cpu_block[i], cpu_warp[i], cpu_thread[i]);}return 0;
}
2.4、如何找到绝对线程索引
thread_idx = ( (gridDim.x * blockDim.x ) * idy ) + idx;
绝对线程索引 = 当前行索引 * 每行线程总数 + x方向的偏移
参考核函数
/*定义线程id计算函数*/
__global__ void what_is_my_id_2d_A(unsigned int *const block_x,unsigned int *const block_y,unsigned int *const thread,unsigned int *const calc_thread,unsigned int *const x_thread,unsigned int *const y_thread,unsigned int *const grid_dimx,unsigned int *const block_dimx,unsigned int *const grid_dimy,unsigned int *const block_dimy)
{/*获得线程索引*/const unsigned int idx = (blockIdx.x * blockDim.x) + threadIdx.x;const unsigned int idy = (blockIdx.y * blockDim.y) + threadIdx.y;/*计算线程id计算公式:线程ID = ((网格维度x * 块维度x) * 线程idy) + 线程idx(作为x维度上的偏移)*/const unsigned int thread_idx = ((gridDim.x * blockDim.x) * idy) + idx;/*获取线程块的索引*/block_x[thread_idx] = blockIdx.x;block_y[thread_idx] = blockIdx.y;/*获取线程的索引*/thread[thread_idx] = threadIdx.x;/*计算线程id*/calc_thread[thread_idx] = thread_idx;/*获取线程的x维度索引*/x_thread[thread_idx] = idx;/*获取线程的y维度索引*/y_thread[thread_idx] = idy;/*获取网格维度的X,Y值*/grid_dimx[thread_idx] = gridDim.x;grid_dimy[thread_idx] = gridDim.y;/*获取block_dimy*/block_dimx[thread_idx] = blockDim.x;
}
来个.cu文件,体验一下这个核函数,// 编译方法同上
#include <stdio.h>
#include <stdlib.h>
#include <cuda.h>
#include <cuda_runtime.h>/*定义线程id计算函数*/
__global__ void what_is_my_id_2d_A(unsigned int *const block_x,unsigned int *const block_y,unsigned int *const thread,unsigned int *const calc_thread,unsigned int *const x_thread,unsigned int *const y_thread,unsigned int *const grid_dimx,unsigned int *const block_dimx,unsigned int *const grid_dimy,unsigned int *const block_dimy)
{/*获得线程索引*/const unsigned int idx = (blockIdx.x * blockDim.x) + threadIdx.x;const unsigned int idy = (blockIdx.y * blockDim.y) + threadIdx.y;/*计算线程id计算公式:线程ID = ((网格维度x * 块维度x) * 线程idy) + 线程idx(作为x维度上的偏移)*/const unsigned int thread_idx = ((gridDim.x * blockDim.x) * idy) + idx;/*获取线程块的索引*/block_x[thread_idx] = blockIdx.x;block_y[thread_idx] = blockIdx.y;/*获取线程的索引*/thread[thread_idx] = threadIdx.x;/*计算线程id*/calc_thread[thread_idx] = thread_idx;/*获取线程的x维度索引*/x_thread[thread_idx] = idx;/*获取线程的y维度索引*/y_thread[thread_idx] = idy;/*获取网格维度的X,Y值*/grid_dimx[thread_idx] = gridDim.x;grid_dimy[thread_idx] = gridDim.y;/*获取block_dimy*/block_dimx[thread_idx] = blockDim.x;
}/*定义矩阵宽度以及大小*/
#define ARRAY_SIZE_X 32
#define ARRAY_SIZE_Y 16
#define ARRAY_SIZE_IN_BYTES (ARRAY_SIZE_X * ARRAY_SIZE_Y * sizeof(unsigned int))/*声明CPU端上的各项参数内存*/
unsigned int *cpu_block_x[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_block_y[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_warp[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_calc_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_x_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_y_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_grid_dimx[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_grid_dimy[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_block_dimx[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_block_dimy[ARRAY_SIZE_Y][ARRAY_SIZE_X];int main(void)
{const dim3 thread_rect = (32, 4);/*注意这里的块的dim3值为1x4*/const dim3 block_rect = (1, 4);/*初始化矩形线程分布启动项*/const dim3 thread_square = (16, 8);/*注意这里的块的dim3值为2x2*/const dim3 block_square = (2, 2);/*定义一个临时指针用于打印信息*/char ch;/*定义GPU端上的各项参数内存*/unsigned int *gpu_block_x;unsigned int *gpu_block_y;unsigned int *gpu_thread;unsigned int *gpu_warp;unsigned int *gpu_calc_thread;unsigned int *gpu_x_thread;unsigned int *gpu_y_thread;unsigned int *gpu_grid_dimx;unsigned int *gpu_grid_dimy;unsigned int *gpu_block_dimx;/*分配GPU端上的各项参数内存*/cudaMalloc((void **)&gpu_block_x, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_block_y, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_thread, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_warp, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_calc_thread, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_x_thread, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_y_thread, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_grid_dimx, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_grid_dimy, ARRAY_SIZE_IN_BYTES);cudaMalloc((void **)&gpu_block_dimx, ARRAY_SIZE_IN_BYTES);/*调用核函数*/for (int kernel = 0; kernel < 2; kernel++){switch (kernel){case 0:/*执行矩形配置核函数*/what_is_my_id_2d_A<<<block_rect, thread_rect>>>(gpu_block_x, gpu_block_y, gpu_thread, gpu_warp, gpu_calc_thread, gpu_x_thread, gpu_y_thread, gpu_grid_dimx, gpu_grid_dimy, gpu_block_dimx);break;case 1:/*执行方形配置核函数*/what_is_my_id_2d_A<<<block_square, thread_square>>>(gpu_block_x, gpu_block_y, gpu_thread, gpu_warp, gpu_calc_thread, gpu_x_thread, gpu_y_thread, gpu_grid_dimx, gpu_grid_dimy, gpu_block_dimx);break;default:exit(1);break;}/*将GPU端上的各项参数内存拷贝到CPU端上*/cudaMemcpy(cpu_block_x, gpu_block_x, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_block_y, gpu_block_y, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_thread, gpu_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_warp, gpu_warp, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_calc_thread, gpu_calc_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_x_thread, gpu_x_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_y_thread, gpu_y_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_grid_dimx, gpu_grid_dimx, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_grid_dimy, gpu_grid_dimy, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);cudaMemcpy(cpu_block_dimx, gpu_block_dimx, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);printf("\n kernel %d\n", kernel);/*打印结果*/for (int y = 0; y < ARRAY_SIZE_Y; y++){for (int x = 0; x < ARRAY_SIZE_X; x++){printf("CT: %2u Bkx: %1u TID: %2u YTID: %2u XTID: %2u GDX: %1u BDX: %1u GDY: %1u BDY:%1U\n", cpu_calc_thread[y * ARRAY_SIZE_X + x], cpu_block_x[y * ARRAY_SIZE_X + x], cpu_thread[y * ARRAY_SIZE_X + x], cpu_y_thread[y * ARRAY_SIZE_X + x], cpu_x_thread[y * ARRAY_SIZE_X + x], cpu_grid_dimx[y * ARRAY_SIZE_X + x], cpu_block_dimx[y * ARRAY_SIZE_X + x], cpu_grid_dimy[y * ARRAY_SIZE_X + x], cpu_block_y[y * ARRAY_SIZE_X + x]);}/*每行打印完后按任意键继续*/ch = getchar();}printf("Press any key to continue\n");ch = getchar();}/*释放GPU端上的各项参数内存*/cudaFree(gpu_block_x);cudaFree(gpu_block_y);cudaFree(gpu_thread);cudaFree(gpu_warp);cudaFree(gpu_calc_thread);cudaFree(gpu_x_thread);cudaFree(gpu_y_thread);cudaFree(gpu_grid_dimx);cudaFree(gpu_grid_dimy);cudaFree(gpu_block_dimx);
}
其中有个代码片段
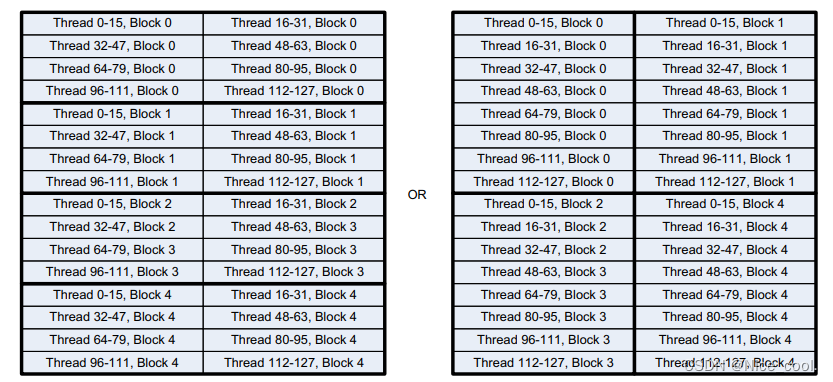
const dim3 thread_rect = (32, 4);/*注意这里的块的dim3值为1x4*/const dim3 block_rect = (1, 4);const dim3 thread_square = (16, 8);/*注意这里的块的dim3值为2x2*/const dim3 block_square = (2, 2);
如图理解,都是 2x2 / 1x4 = 四个线程块;每一块 32x4 / 16x8 =128个线程。这是两种不同的线程块布局方式。
但是一般会选择长方形的布局方式。
1、要以行的方式进行连续访问内存,而不是列的方式
2、同一个线程块可以通过共享内存进行通信
3、同一个线程束中的线程存储访问合并在一起了,长方形布局只需要一次访问操作就可以获得连续的内存数据 // 正方形要两次访问
三、参考代码(打印索引)
3.1、打印一维索引
场景:
一个数组有 8 个数据,要开 8 个线程去访问。
我们想切成 2 个block 访问,所以一个 blcok 就有 4 个线程
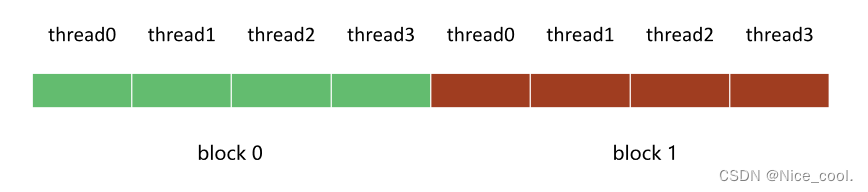
所以 线程设置如下:一个 block里面4个线程,一个grid里面2个block
一维索引的设置如下:
dim3 block(4);// 一个 block 里面 4 个线程dim3 grid(2);// 一个 grid 里面 2 个 block
#include <cuda_runtime.h>
#include <stdio.h>__global__ void print_idx_kernel(){printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",blockIdx.z, blockIdx.y, blockIdx.x,threadIdx.z, threadIdx.y, threadIdx.x);
}__global__ void print_dim_kernel(){printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",gridDim.z, gridDim.y, gridDim.x,blockDim.z, blockDim.y, blockDim.x);
}__global__ void print_thread_idx_per_block_kernel(){int index = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",blockIdx.z, blockIdx.y, blockIdx.x,index);
}__global__ void print_thread_idx_per_grid_kernel(){int bSize = blockDim.z * blockDim.y * blockDim.x;int bIndex = blockIdx.z * gridDim.x * gridDim.y + \blockIdx.y * gridDim.x + \blockIdx.x;int tIndex = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;int index = bIndex * bSize + tIndex;printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n", bIndex, tIndex, index);
}void print_one_dim(){int inputSize = 8;int blockDim = 4;int gridDim = inputSize / blockDim;dim3 block(blockDim);//4dim3 grid(gridDim);//2print_idx_kernel<<<grid, block>>>();//print_dim_kernel<<<grid, block>>>();//print_thread_idx_per_block_kernel<<<grid, block>>>();//print_thread_idx_per_grid_kernel<<<grid, block>>>();cudaDeviceSynchronize(); //用于同步
}int main() {print_one_dim();return 0;
}
核函数及其结果:
- 8个线程,8个输出;
- 索引都是从 z到y到x的;
1、线程块与线程
__global__ void print_idx_kernel(){printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",blockIdx.z, blockIdx.y, blockIdx.x,threadIdx.z, threadIdx.y, threadIdx.x);
}
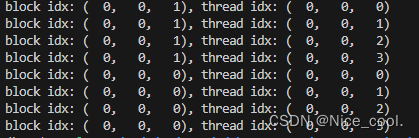
2、线程网格与线程块
__global__ void print_dim_kernel(){printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",gridDim.z, gridDim.y, gridDim.x,blockDim.z, blockDim.y, blockDim.x);
}
1x1x2=2
1x1x4=4
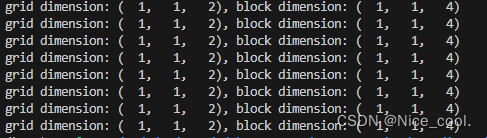
3、在 block 里面寻找每个线程的索引
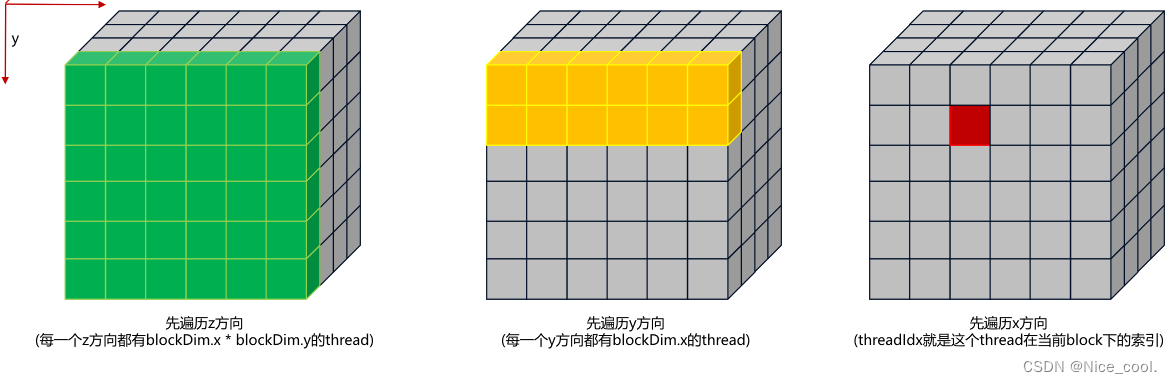
__global__ void print_thread_idx_per_block_kernel(){int index = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",blockIdx.z, blockIdx.y, blockIdx.x,index);
}
可以根据下面的图来理解访问顺序:
结果:
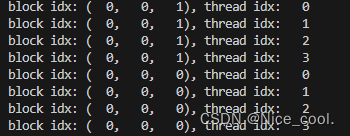
4、在 grid 里面寻找每个线程索引
__global__ void print_thread_idx_per_grid_kernel(){int bSize = blockDim.z * blockDim.y * blockDim.x; // block 的线程大小int bIndex = blockIdx.z * gridDim.x * gridDim.y + \blockIdx.y * gridDim.x + \blockIdx.x;int tIndex = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;int index = bIndex * bSize + tIndex;printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n", bIndex, tIndex, index);
}
可以根据下面的图来理解访问顺序:实际上就是从一堆方块里面找到那个红点
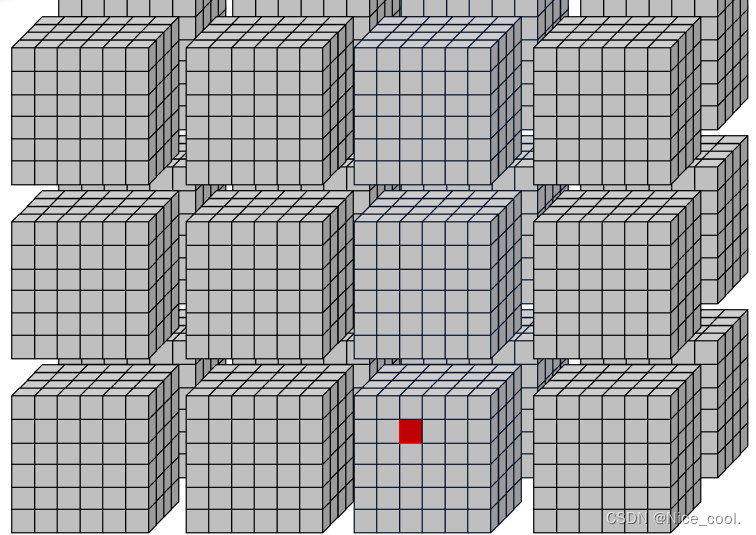
结果:(thread 从 0 ~ 7 )
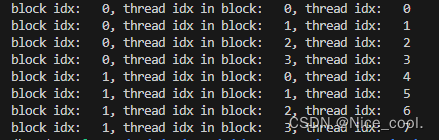
3.2、打印二维索引
#include <cuda_runtime.h>
#include <stdio.h>__global__ void print_idx_kernel(){printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",blockIdx.z, blockIdx.y, blockIdx.x,threadIdx.z, threadIdx.y, threadIdx.x);
}__global__ void print_dim_kernel(){printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",gridDim.z, gridDim.y, gridDim.x,blockDim.z, blockDim.y, blockDim.x);
}__global__ void print_thread_idx_per_block_kernel(){int index = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",blockIdx.z, blockIdx.y, blockIdx.x,index);
}__global__ void print_thread_idx_per_grid_kernel(){int bSize = blockDim.z * blockDim.y * blockDim.x;int bIndex = blockIdx.z * gridDim.x * gridDim.y + \blockIdx.y * gridDim.x + \blockIdx.x;int tIndex = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;int index = bIndex * bSize + tIndex;printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n", bIndex, tIndex, index);
}void print_two_dim(){int inputWidth = 4;int blockDim = 2;int gridDim = inputWidth / blockDim;dim3 block(blockDim, blockDim);// 2 , 2dim3 grid(gridDim, gridDim); //2,2print_idx_kernel<<<grid, block>>>();// print_dim_kernel<<<grid, block>>>();// print_thread_idx_per_block_kernel<<<grid, block>>>();//print_thread_idx_per_grid_kernel<<<grid, block>>>();cudaDeviceSynchronize();
}int main() {print_two_dim();return 0;
}
3.2、扩展应用 (获取图片坐标)
原理其实就是同上面(在 grid 里面寻找每个线程索引)一样,这里为了方便看,再次贴一次图。
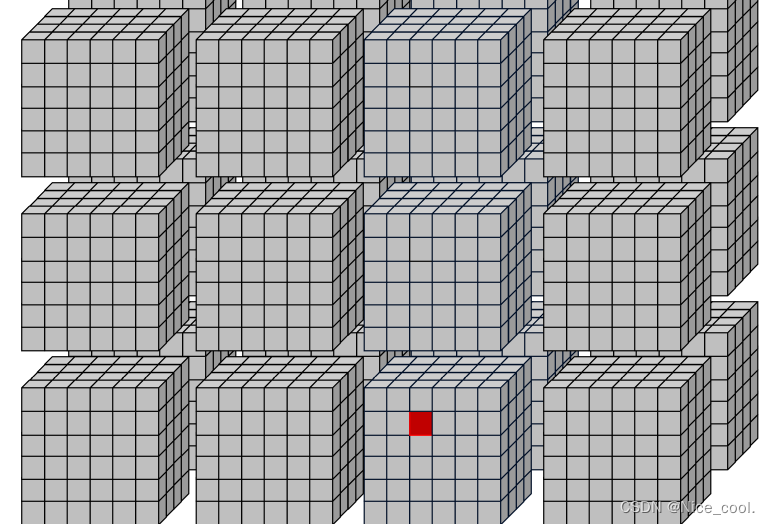
重写一个核函数,比之前的方便看
__global__ void print_cord_kernel(){int index = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",blockIdx.z, blockIdx.y, blockIdx.x,index, x, y);
}
完整的 .cu 文件如下:
#include <cuda_runtime.h>
#include <stdio.h>__global__ void print_cord_kernel(){int index = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",blockIdx.z, blockIdx.y, blockIdx.x,index, x, y);
}void print_cord(){int inputWidth = 4;int blockDim = 2;int gridDim = inputWidth / blockDim;dim3 block(blockDim, blockDim);dim3 grid(gridDim, gridDim);print_cord_kernel<<<grid, block>>>();cudaDeviceSynchronize();
}int main() {print_cord();return 0;
}
相关文章:
CUDA编程- - GPU线程的理解 thread,block,grid - 学习记录
GPU线程的理解 thread,block,grid 一、从 cpu 多线程角度理解 gpu 多线程1、cpu 多线程并行加速2、gpu多线程并行加速2.1、cpu 线程与 gpu 线程的理解(核函数)2.1.1 、第一步:编写核函数2.1.2、第二步:调用核函数(使用…...

yum 报错 ZLIB_1.2.3.3 not defined in file libz.so.1
这篇记录工作中发现的,库文件被修改导致 yum 无法正常使用的问题排查过程 问题描述 1)执行yum 报错说python2.7.5 结构异常,发现/usr/bin/yum 的解释器被修改过,恢复成/usr/bin/python即可 2)恢复后,发现…...
数字孪生智慧能源电力Web3D可视化云平台合集
前言 能源电力的经济发展是中国式现代化的强大动力,是经济社会发展的必要生产要素,电力成本变化直接关系到工业生产、交通运输、农业生产、居民生活等各个方面,合理、经济的能源成本能够促进社会用能服务水平提升、支撑区域产业发展…...
DataTable.Load(reader)注意事项
对于在C#中操作数据库查询,这样的代码很常见: using var cmd ExecuteCommand(sql); using var reader cmd.ExecuteReader(); DataTable dt new DataTable(); dt.Load(reader); ...一般的查询是没问题的,但是如果涉及主键列的查询…...
(23国赛真题))
DC-DNS(域名解析服务)(23国赛真题)
2023全国职业院校技能大赛网络系统管理赛项–模块B:服务部署(WindowServer2022) 文章目录 题目配置步骤安装及配置DNS服务。创建正向区域,添加必要的域名解析记录。配置TXT记录,配置域名反向PTR。无法解析的域名统一交由IspSrv进行解析验证配置chinaskills.com正向区域配置…...

日志之Loki详细讲解
文章目录 1 Loki1.1 引言1.2 Loki工作方式1.2.1 日志解析格式1.2.2 日志搜集架构模式1.2.3 Loki部署模式 1.3 服务端部署1.3.1 AllInOne部署模式1.3.1.1 k8s部署1.3.1.2 创建configmap1.3.1.3 创建持久化存储1.3.1.4 创建应用1.3.1.5 验证部署结果 1.3.2 裸机部署 1.4 Promtail…...

Mongodb投射中的$slice,正向反向跳过要搞清楚
在投射中,使用$操作符和$elemMatch返回数组中第一个符合查询条件的元素。而在投射中使用$slice, 能够返回指定数量的数组元素。 定义 投射中使用$slice命令,指定查询结果中返回数组元素的数量。 语法 db.collection.find(<query>,{<arrayFi…...
类和对象 第六部分 继承 第一部分:继承的语法
一.继承的概念 继承是面向对象的三大特性之一 有些类与类之间存在特殊的关系,例如下图: 我们可以发现,下级别的成员除了拥有上一级的共性,还有自己的特性,这个时候,我们可以讨论利用继承的技术,…...

githacker安装详细教程,linux添加环境变量详细教程(见标题三)
笔者是ctf小白,这两天也是遇到.git泄露的题目,需要工具来解决问题,在下载和使用的过程中也是遇到很多问题,写此篇记录经验,以供学习 在本篇标题三中有详细介绍了Linux系统添加环境变量的操作教程,以供学习 …...
2401Idea用GradleKotlin编译Java控制台中文出乱码解决
解决方法 解决方法1 在项目 build.gradle.kts 文件中加入 tasks.withType<JavaCompile> {options.encoding "UTF-8" } tasks.withType<JavaExec> {systemProperty("file.encoding", "utf-8") }经测试, 只加 tasks.withType<…...

Day39 62不同路径 63不同路径II 343整数拆分 96不同的二叉搜索树
62 不同路径 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 问总共有多少条不同的路径&#…...
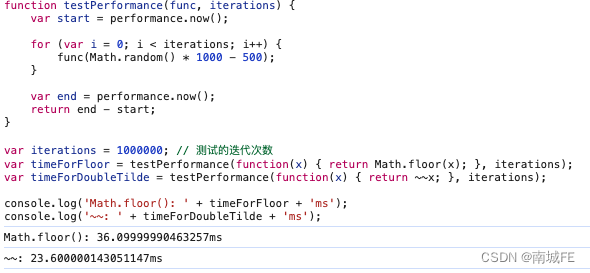
JavaScript 的 ~~ 运算和floor 的性能差异
在JavaScript中,~~(双波浪号)和Math.floor()都可以用于向下取整,但它们在行为和性能上有一些差异。要测试这两者之间的性能差异,你可以使用JavaScript的performance.now()方法来进行基准测试。 行为差异 Math.floor()…...
AtCoder Beginner Contest 338F - Negative Traveling Salesman【floyd+状态压缩dp】
原题链接:https://atcoder.jp/contests/abc338/tasks/abc338_f Time Limit: 6 sec / Memory Limit: 1024 MB Score: 500 points、 问题陈述 有一个有N个顶点和M条边的加权简单有向图。顶点的编号为 1 到 N,i/th 边的权重为 Wi,从顶点 U…...
UDP/TCP协议特点
1.前置知识 定义应用层协议 1.确定客户端和服务端要传递哪些信息 2.约定传输格式 网络上传输的一般是二进制数据/字符串 结构化数据转二进制/字符串 称为序列化 反之称之为反序列化 下面就是传输层了 在TCP/IP协议中,我们以 目的端口,目的IP 源端口 源IP 协议号这样一个五…...

编程笔记 html5cssjs 059 css多列
编程笔记 html5&css&js 059 css多列 一、CSS3 多列属性二、实例小结 CSS3 可以将文本内容设计成像报纸一样的多列布局. 一、CSS3 多列属性 下表列出了所有 CSS3 的多列属性: 属性 描述 column-count 指定元素应该被分割的列数。 column-fill 指定如何填充…...

Facebook的元宇宙探索:虚拟社交的新时代
近年来,科技的飞速发展推动着人类社交方式的翻天覆地的改变。在这场数字化革命的浪潮中,社交媒体巨头Facebook正积极探索并引领着一个被誉为“元宇宙”的全新领域,试图为用户打造更为真实、丰富的虚拟社交体验。 元宇宙的崛起 元宇宙这个概念…...

用React给XXL-JOB开发一个新皮肤(四):实现用户管理模块
目录 一. 简述二. 模块规划 2.1. 页面规划2.2. 模型实体定义 三. 模块实现 3.1. 用户分页搜索3.2. Modal 配置3.3. 创建用户表单3.4. 修改用户表单3.5. 删除 四. 结束语 一. 简述 上一篇文章我们实现登录页面和管理页面的 Layout 骨架,并对接登录和登出接口。这篇…...

某赛通电子文档安全管理系统 hiddenWatermark/uploadFile 文件上传漏洞复现
0x01 产品简介 某赛通电子文档安全管理系统(简称:CDG)是一款电子文档安全加密软件,该系统利用驱动层透明加密技术,通过对电子文档的加密保护,防止内部员工泄密和外部人员非法窃取企业核心重要数据资产,对电子文档进行全生命周期防护,系统具有透明加密、主动加密、智能…...

Redis五种数据类型及应用场景
1、数据类型 String(字符串,整数,浮点数):做简单的键值对缓存 List(列表):储存一些列表类型的数据结构 Hash(哈希):包含键值对的无序散列表,结构化的数据 Set(无序集合):交集,并集…...
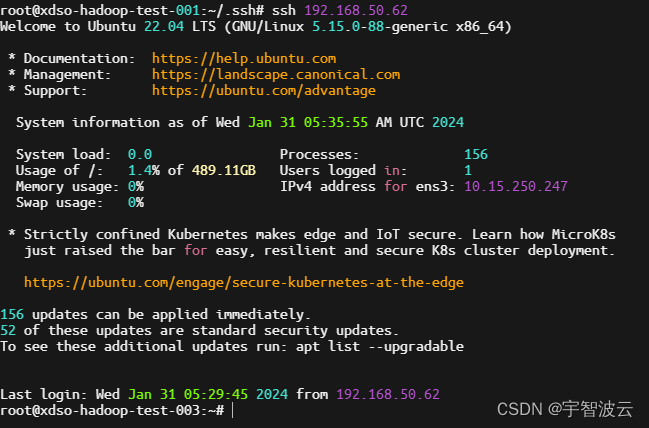
测试环境搭建整套大数据系统(一:基础配置,修改hostname,hosts,免密)
一:使用服务器配置。 二:修改服务器名称hostname,hosts。 在 Linux 系统中,hostname 和 /etc/hosts 文件分别用于管理主机名和主机名解析。 在三台服务器上,分别执行以下命令。 vim /etc/hostnamexdso-hadoop-test-0…...

JMeter深度实战:从HTTP接口测试到性能根因分析
1. 这不是“点点按钮就能出报告”的玩具,而是接口质量的显微镜很多人第一次打开JMeter,以为它就是个带图形界面的curl增强版——填个URL、点下“启动”,等几秒看个响应码,再导出个Excel就完事了。我刚接手电商中台接口测试时也这么…...
)
3D激光SLAM入门:点云曲率计算与LOAM边缘/平面特征提取(附代码)
专栏系列:3D激光SLAM从零到精通 | 难度:中级 | 预计阅读:25分钟 前置知识:Python编程,numpy基础,3D点云的基本概念 摘要 本文深入讲解3D激光SLAM中最基础也是最关键的一环——点云特征提取。我们将从LOAM论…...

基于ArUco标记的毫米波反射镜自主对准系统设计与实现
1. 项目概述在5G/6G通信时代,毫米波(mmWave)技术凭借其超大带宽和超低延迟特性,成为实现千兆级无线传输的关键技术。然而,毫米波信号在非视距(NLOS)环境中的快速衰减问题,一直是制约其实际部署的主要瓶颈。传统解决方案如可重构智…...

Tomcat路径规范化漏洞:CVE-2024系列信息泄露深度解析
1. 这三个CVE不是“远程代码执行”,但比很多RCE更值得你立刻放下手头工作去查Apache Tomcat 信息泄露漏洞CVE-2024-21733、CVE-2024-21733、CVE-2024-24549和CVE-2024-34750——光看编号就容易让人划走:又是一堆CVE,又得翻公告,又…...

AI Native 公司构建指南:从 Anthropic 创始人手册到工程实践
【摘要】系统解析 AI Native 公司的本质特征与技术架构,基于 Anthropic 2026 年《创始人行动手册》核心框架,结合 31 家精益 AI 团队的真实案例,提供从想法验证到规模化增长的完整工程落地路径,帮助技术创业者避开 AI 时代特有的创…...

1231546
123456...

如何在3分钟内精准定位Windows热键冲突:Hotkey Detective终极指南
如何在3分钟内精准定位Windows热键冲突:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

SketchUp STL插件:5分钟快速掌握3D打印模型转换的完整免费指南
SketchUp STL插件:5分钟快速掌握3D打印模型转换的完整免费指南 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl Sk…...

【AI Daily】AI日报 | 2026-05-24
今日一句话判断 今天 AI 工程最值得关注的是 AI 方向的基础设施化:开源80386微码实现发布、Making Deep Learning Go Brrrr from F、Lum1104/Understand-Anything 代表能力正在从模型层下沉到工具链和工作流。 行动建议 跟踪 开源80386微码实现发布,判…...

等保2.0三级Linux服务器合规基线重建实战指南
1. 为什么等保2.0整改不是“打补丁”,而是重装操作系统级的系统工程你刚接手一台跑了三年的CentOS 7服务器,业务跑得稳,监控没告警,运维日志里连个WARNING都少见——但等保测评报告第一页就写着:“操作系统未满足等保2…...