Decoupled Knowledge Distillation(CVPR 2022)原理与代码解析
paper:Decoupled Knowledge Distillation
code:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/DKD.py
背景
与基于响应logits-based的蒸馏方法相比,基于特征feature-based的蒸馏方法在各种任务上的表现更好,因此对基于响应的知识蒸馏的研究越来越少。然而,基于特征的方法的训练成本并不令人满意,因为在训练期间引入了额外的计算和存储占用(如网络模块和复杂的操作)来提取特征。基于响应的蒸馏所需的计算和存储都较小,但性能较差。直觉上来说,logit-based蒸馏方法应当达到与feature-based方法相当的性能,因为logits处与更深的层有更丰富的语义特征。作者猜测logit-based蒸馏的性能受到了未知原因的限制,导致表现不理想。
本文的创新点
本文作者深入研究了KD的作用机制,将分类预测拆分为两个层次:(1)对目标类和所有非目标类进行二分类预测。(2)对每个非目标类进行多分类预测。进而将原始的KD损失也拆分为两部分,一种是针对目标类的二分类蒸馏,另一种是针对非目标类的多分类蒸馏。并分别称为target classification knowledge distillation(TCKD)和non-target classification knowledge distillation(NCKD)。通过分别单独研究两部分对性能的影响,作者发现NCKD中包含了重要的知识,而原始KD对两部分耦合的方式抑制了NCKD的作用,也限制了平衡这两部分的灵活性。
为了解决这些问题,本文提出了一种新的logit蒸馏方法Decoupled Knowledge Distillation(DKD),将TCKD和NCKD进行解耦,使得它们之间的权重可调,从而解除了对NCKD的抑制,提升了蒸馏的性能。
方法介绍
Reformulating KD
Notions
对于一个属于第 \(t\) 类的样本,分类概率可以表示为 \(\mathbf{p}=[p_{1},p_{2},...,p_{t},...,p_{C}]\in \mathbb{R}^{1\times C}\),其中 \(p_{i}\) 是第 \(i\) 类的概率,\(C\) 是类别数。\(\mathbf{p}\) 中的每个元素都可以通过softmax函数得到
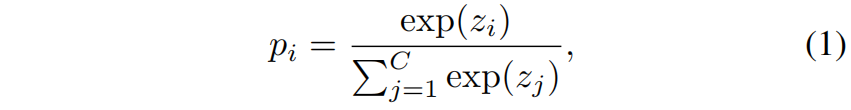
其中 \(z_{i}\) 表示第 \(i\) 类的logit。
为了将与目标类相关和无关的预测分开,定义 \(\mathbf{b}=[p_{t},p_{\setminus t}]\in \mathbb{R}^{1\times 2}\) 表示二分类概率,其中 \(p_{t}\) 表示目标类的概率,\(p_{\setminus t}\) 表示非目标类的概率(所有其它类的概率和),可按下式分别计算得到
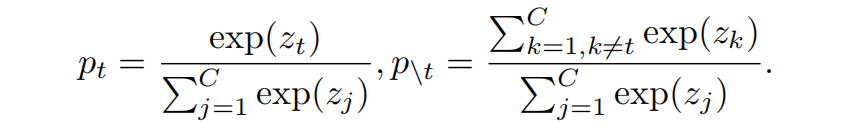
同时定义 \(\hat{\mathbf{p}}=[\hat{p}_{1},...,\hat{p}_{t-1},\hat{p}_{t+1},...,\hat{p}_{C}]\in \mathbb{R}^{1\times (C-1)}\) 来单独建模非目标类别的概率(即不考虑第 \(t\) 类),其中每个元素按下式得到
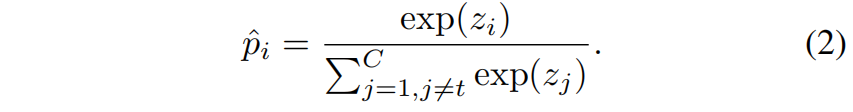
Reformulation
\(\mathcal{T}\) 和 \(\mathcal{S}\) 分别表示教师和学生网络,根据上面定义的二分类概率 \(\mathbf{b}\) 和非目标类的多分类概率 \(\hat{\mathbf{p}}\),原始KD中的KL散度损失函数可以重写成下面的形式
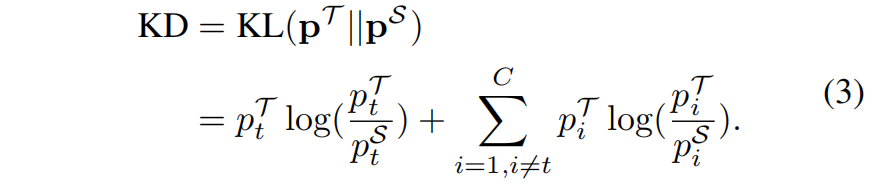
根据式(1)和(2),我们有 \(\hat{p}_{i}=p_{i}/p_{\setminus t}\),式(3)可以重写成如下
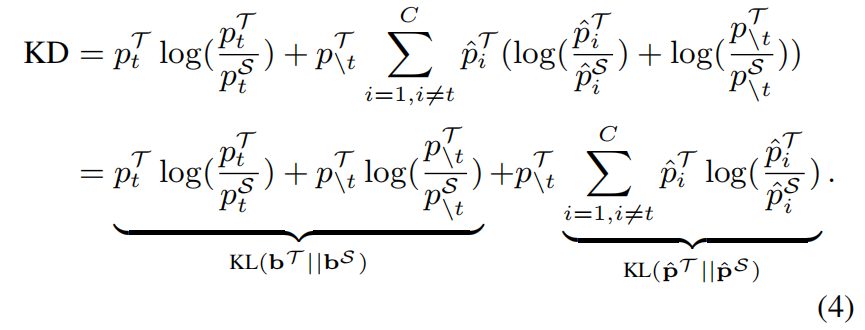
然后式(4)又可以重写成如下

这里根据式(1)(2)(3)推导式(4)(5)的具体过程如下


由式(5)可以看出,KD loss可以看作两项的加权和,其中第一项表示教师和学生网络对目标类别预测概率之间的相似性,因此称之为Target Class Knowledge Distillation(TCKD)。第二项表示教师和学生网络对非目标类别预测概率之间的相似性,称为Non-Target Class Knowledge Distillation(NCKD)。因此式(5)可以重写成如下
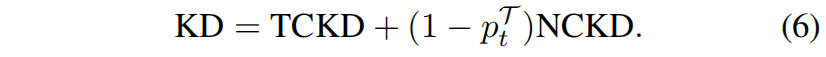
显然,NCKD和 \(p_{t}^{\mathcal{T}}\) 是耦合的。
Effects of TCKD and NCKD
Performance gain of each part
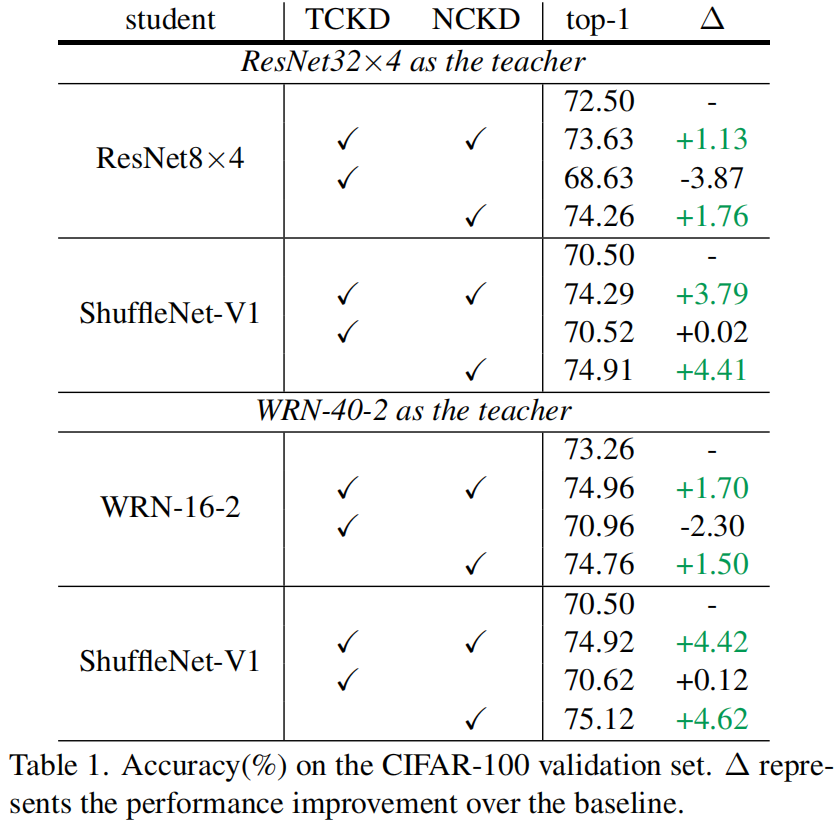
作者在CIFAR-100数据集上分别研究了TCKD和NCKD的影响,结果如下表所示,可以看出,单独使用TCKD对学生模型的提升非常小甚至还会降低精度,而单独使用NCKD可以得到与完整KD相似甚至更高的精度,由此可以看出相比于TCKD,NCKD对学生网络精度的提升更加重要。
TCKD transfers the knowledge concerning the “difficulty” of training samples.
根据式(5)推测TCKD可能将关于样本“难度”的知识传递给了学生网络,例如,相比于 \(p_{t}^{\mathcal{T}}=0.75\) 的样本 \(p_{t}^{\mathcal{T}}=0.99\) 的样本对学生网络来说是更容易学习的样本。由于TCKD传递了样本的难度知识,推测当训练样本更难时TCKD的有效性就会彰显出来,因为CIFAR-100的数据比较简单,TCKD包含的难度知识也相对较少,因此作者通过三个角度进行实验,来验证观点:训练样本越难,TCKD提供的难度知识就越有用。
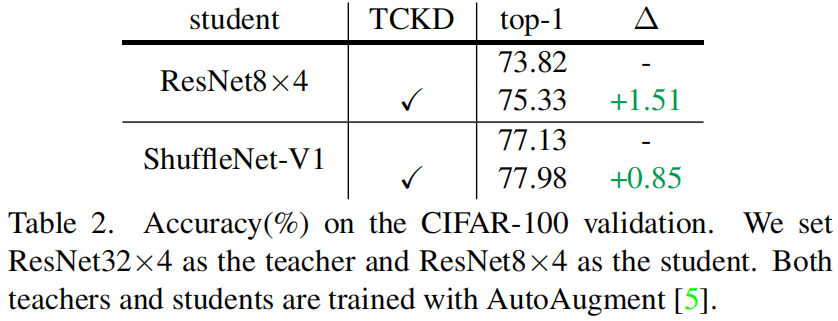
数据增强是一种增加训练样本难度很直接的方法,作者对CIFAR-100进行了AutoAugment增强,然后进行蒸馏的结果如下所示,可以看出进行数据增强后,TCKD对性能的提升更加明显。
噪声标签也会增加数据的训练难度,对数据添加噪声标签后结果如下所示,结果表明TCKD在噪声更大的训练数据上获得了更大的性能提升。
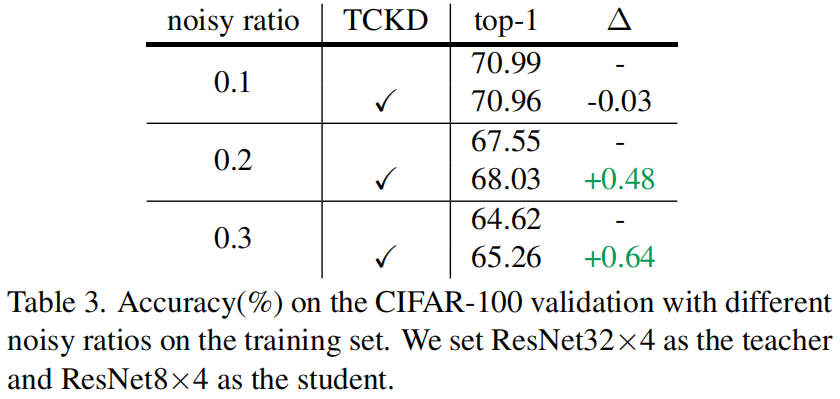
作者还考虑了更难的数据集比如ImageNet,在ImageNet上TCKD获得了0.32的性能提升。

通过上述实验,作者证明了TCKD在困难数据上的有效性,当在更困难的样本上进行蒸馏时,关于样本难度的知识更有用。
NCKD is the prominent reason why logit distillation works but is greatly suppressed.
从表(1)中可以看出单独使用NCKD时其性能和完整的KD相当甚至更好,这表明非目标类别的知识对logit蒸馏至关重要。但是从式(5)可以看出,NCKD和 \((1-p_{t}^{\mathcal{T}})\) 耦合,\(p_{t}^{\mathcal{T}}\) 表明教师对目标类别的置信度,因此置信度越高会导致NCKD的权重越小。作者认为教师模型对训练样本的置信度越高,它所能提供的知识应该越可靠越有价值,但实际上高置信度确抑制了损失的权重,因此作者将logit蒸馏性能不高的原因归结为原始的KD损失对NCKD的抑制。
作者设计了一个消融实验来验证预测准确即置信度高的样本确实比置信度低的样本包含更有用的知识。首先根据 \(p_{t}^{\mathcal{T}}\) 对训练样本进行排序,将其均分为两个子集,一个子集包含了 \(p_{t}^{\mathcal{T}}\) 前50%的样本,另一个子集包含 \(p_{t}^{\mathcal{T}}\) 后50%的样本。然后在每个子集上用NCKD训练学生网络来比较性能的增益。结果如下表所示,可以看出,对 \(p_{t}^{\mathcal{T}}\) 50%的样本使用NCKD获得了更好的性能,表明了预测准确的样本确实包含了更丰富的知识。

Decoupled Knowledge Distillation
针对上述问题,作者提出了解耦知识蒸馏Decoupled Knowledge Distillation(DKD),如下所示
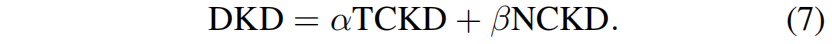
具体来说,引入了超参 \(\alpha\) 和 \(\beta\) 分别作为TCKD和NCKD的权重。
实验结果
下表是采用不同的 \(\alpha\) 和 \(\beta\) 时学生网络的精度,表1中 \(\alpha\) 固定为1.0,表2中 \(\beta\) 固定为8.0。从结果可以看出解耦 \((1-p_{t}^{\mathcal{T}})\) 和NCKD可以带来显著的性能提升(73.64% vs. 74.79%),解耦TCKD和NCKD的权重获得了进一步的性能提升(74.79% vs. 76.32%)。第二个表表明TCKD是不可或缺的,同时当 \(\alpha\) 在1.0附近波动时,TCKD的提升比较稳定没有太大的波动。

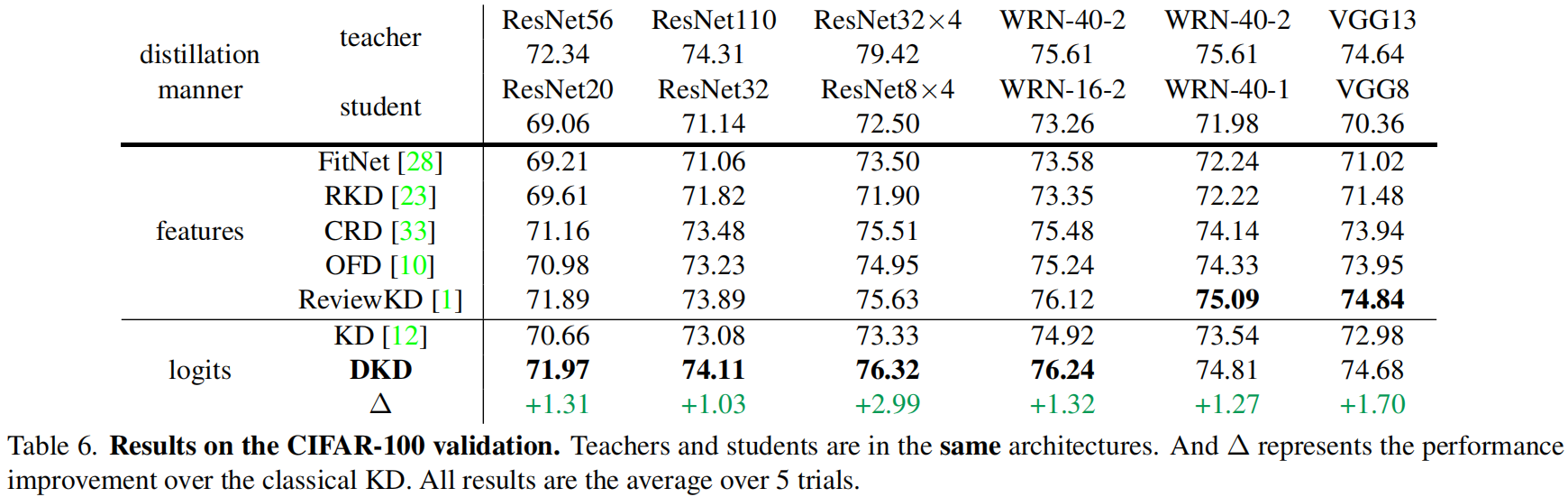
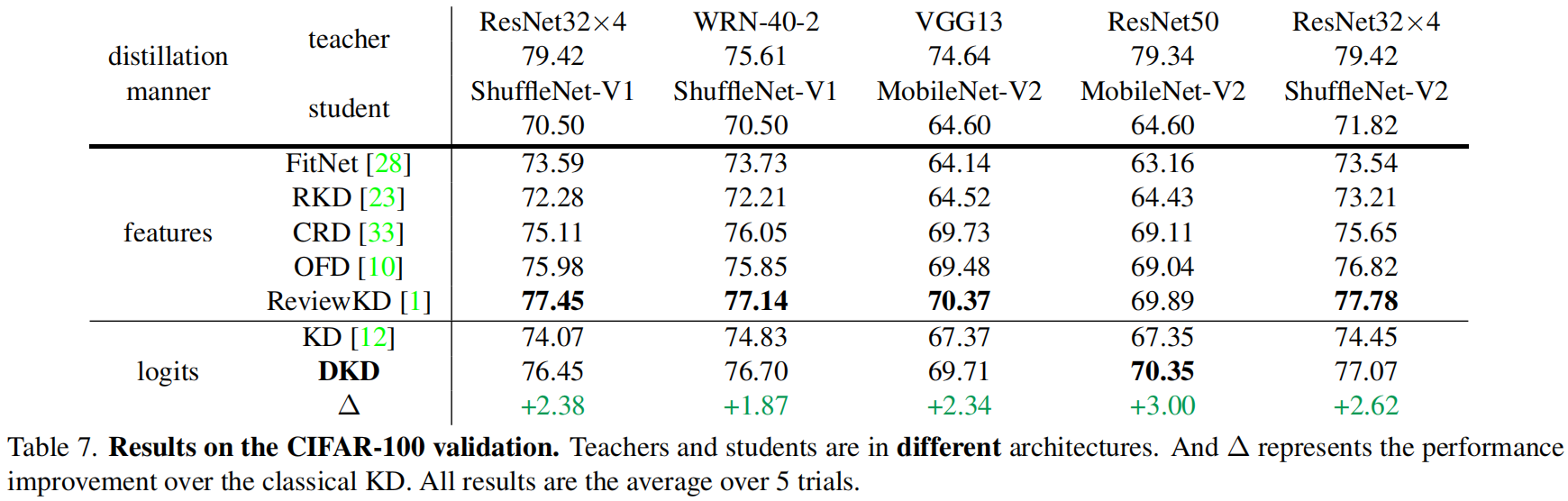
下表是在CIFAR-100验证集上的结果,其中 \(\alpha\) 固定为1,对于不同的教师模型 \(\beta\) 值不同,具体后面会讲。
下面是在ImageNet上的结果
Guidance for tuning \(\beta\)
作者认为NCKD在知识传递中的重要性与教师网络的信心有关,教师网络越有信息,NCKD的重要性就越大,\(\beta\) 值就应该越大。如果目标类的logit值远大于所有非目标类,那么可以认为教师非常有信心,\(\beta\) 值也应该设置的更大。因此作者假定 \(\beta\) 值与目标类和所有非目标类之间的logit差有关。目标类的logit用 \(z_{t}\) 表示,其中 \(t\) 表示目标类别,\(z_{max}\) 表示所有非目标类的logit的最大值即 \(z_{max}=max(\left \{ z_{i}|i\ne t \right \} )\)。
作者选用ShuffleNet-v1作为学生网络,比较了选用不同的教师网络和不同的 \(\beta\) 值的精度,并且给出了所有训练样本上 \(z_{t}-z_{max}\) 的均值,结果如下
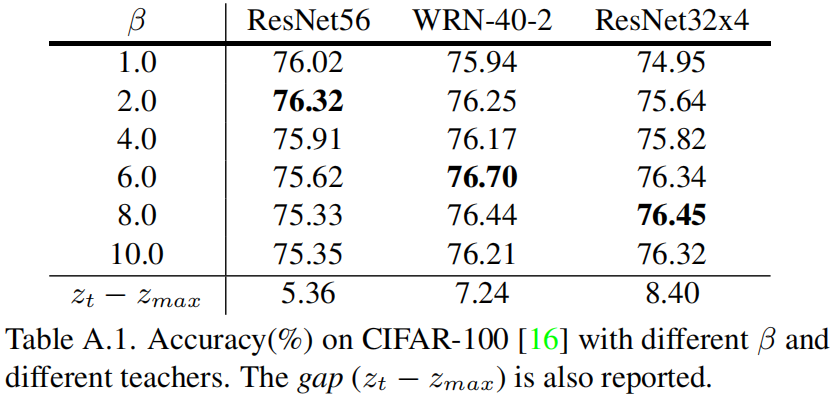
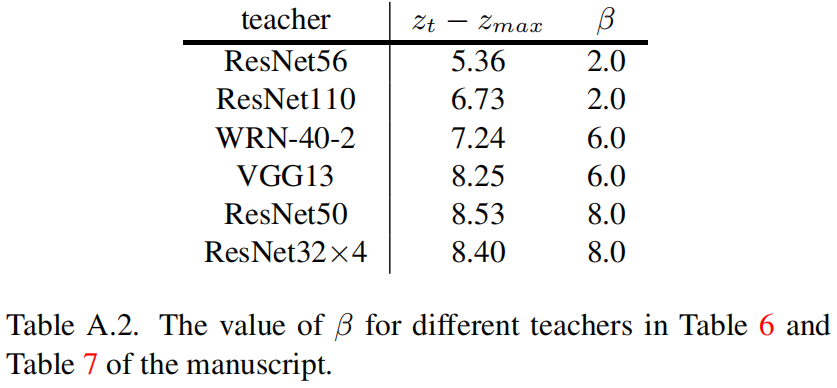
从结果可以看出最优的 \(\beta\) 值与 \(z_{t}-z_{max}\) 成正相关的关系。基于此,表6和表7中不同的教师网络对应的 \(\beta\) 值如下
代码解析
下面是官方实现,其中函数_get_gt_mask中tensor.scatter_()的用法具体见Torch.Tensor.scatter_( ) 用法解读_00000cj的博客-CSDN博客。在求nckd的输入pred_teacher_part2和log_pred_student_part2中都有一个- 1000.0 * gt_mask的操作,这里官方在issue里有解答https://github.com/megvii-research/mdistiller/issues/1,原本的应该是logits[1-gt_mask] / temperature计算所有非目标类别的softmax,因为这里index操作比较慢,因此改成logits/temperature - 1000 * gt_mask,gt_mask中非目标类别处全为0,因此相当于没减。目标类别的logit减去了1000,相当于softmax中分子和分母各加上 \(e^{-1000}\) 约等于0,等价于没加。
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom ._base import Distillerdef dkd_loss(logits_student, logits_teacher, target, alpha, beta, temperature):# (64,100),(64,100),(64),1,8,4gt_mask = _get_gt_mask(logits_student, target) # (64,100),除了每个样本对应target索引处为True, 其它都为Falseother_mask = _get_other_mask(logits_student, target)pred_student = F.softmax(logits_student / temperature, dim=1)pred_teacher = F.softmax(logits_teacher / temperature, dim=1)pred_student = cat_mask(pred_student, gt_mask, other_mask) # (64,2), 第一列是目标类别的logit, 第二列是所有非目标类别的logit的和pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask)log_pred_student = torch.log(pred_student)tckd_loss = (F.kl_div(log_pred_student, pred_teacher, size_average=False)* (temperature**2)/ target.shape[0])# https://github.com/megvii-research/mdistiller/issues/1# e^{-1000}非常小约等于0,等价于把这一项去掉了pred_teacher_part2 = F.softmax(logits_teacher / temperature - 1000.0 * gt_mask, dim=1)log_pred_student_part2 = F.log_softmax(logits_student / temperature - 1000.0 * gt_mask, dim=1)nckd_loss = (F.kl_div(log_pred_student_part2, pred_teacher_part2, size_average=False)* (temperature**2)/ target.shape[0])return alpha * tckd_loss + beta * nckd_lossdef _get_gt_mask(logits, target):target = target.reshape(-1)mask = torch.zeros_like(logits).scatter_(1, target.unsqueeze(1), 1).bool()return maskdef _get_other_mask(logits, target):target = target.reshape(-1)mask = torch.ones_like(logits).scatter_(1, target.unsqueeze(1), 0).bool()return maskdef cat_mask(t, mask1, mask2):t1 = (t * mask1).sum(dim=1, keepdims=True) # (64,1)t2 = (t * mask2).sum(1, keepdims=True) # (64,1)rt = torch.cat([t1, t2], dim=1) # (64,2)return rtclass DKD(Distiller):"""Decoupled Knowledge Distillation(CVPR 2022)"""def __init__(self, student, teacher, cfg):super(DKD, self).__init__(student, teacher)self.ce_loss_weight = cfg.DKD.CE_WEIGHTself.alpha = cfg.DKD.ALPHAself.beta = cfg.DKD.BETAself.temperature = cfg.DKD.Tself.warmup = cfg.DKD.WARMUPdef forward_train(self, image, target, **kwargs):logits_student, _ = self.student(image)with torch.no_grad():logits_teacher, _ = self.teacher(image)# lossesloss_ce = self.ce_loss_weight * F.cross_entropy(logits_student, target)loss_dkd = min(kwargs["epoch"] / self.warmup, 1.0) * dkd_loss(logits_student,logits_teacher,target,self.alpha,self.beta,self.temperature,)losses_dict = {"loss_ce": loss_ce,"loss_kd": loss_dkd,}return logits_student, losses_dict
相关文章:
Decoupled Knowledge Distillation(CVPR 2022)原理与代码解析
paper:Decoupled Knowledge Distillationcode:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/DKD.py背景与基于响应logits-based的蒸馏方法相比,基于特征feature-based的蒸馏方法在各种任务上的表现更好…...

IronWebScraper 2023.2.2 Crack
关于 .NET 的 IronWebScraper 用于从 HTML Web 应用程序中提取干净的结构化数据的 C# 框架。 IronWebScraper for .NET 是一个 C# 网络抓取库,它允许开发人员模拟和自动化人类浏览行为,以从 Web 应用程序中提取内容、文件和图像作为本机 .NET 对象。Iron…...

【2.1 golong中条件语句if】
1. 条件语句if 1.1.1. Go 语言条件语句: 条件语句需要开发者通过指定一个或多个条件,并通过测试条件是否为 true 来决定是否执行指定语句,并在条件为 false 的情况在执行另外的语句。 Go 语言提供了以下几种条件判断语句: 1.1…...
)
Scala编程(第四版)
Scala编程可伸缩的语言面向对象与函数式编程Scala优势Scala是兼容的可伸缩的语言 1、适合构建将java组件组装在一起的脚本 2、用于编写可复用组件,并讲这些组件构建成大型框架 Scala是一门综合面向对象和函数式编程概念的静态类型编程语言 面向对象与函数式编程 面…...
aws apigateway 基础概念和入门示例
参考资料 https://docs.aws.amazon.com/zh_cn/apigateway/latest/developerguide/getting-started.html apigateway基础理解 apigateway的核心概念 apigateway,基础服务用来管理接口的创建,部署和管理restapi,http资源和方法的集合&#…...
2023年“中银杯”安徽省职业院校技能大赛网络安全A模块全过程解析
A模块基础设施设置/安全加固(200分) 一、项目和任务描述: 假定你是某企业的网络安全工程师,对于企业的服务器系统,根据任务要求确保各服务正常运行,并通过综合运用登录和密码策略、流量完整性保护策略、事件监控策略、防火墙策略等多种安全策略来提升服务器系统的网络安全…...

【Python入门第二十四天】Python 迭代器
Python 迭代器 迭代器是一种对象,该对象包含值的可计数数字。 迭代器是可迭代的对象,这意味着您可以遍历所有值。 从技术上讲,在 Python 中,迭代器是实现迭代器协议的对象,它包含方法 iter() 和 next()。 迭代器 V…...
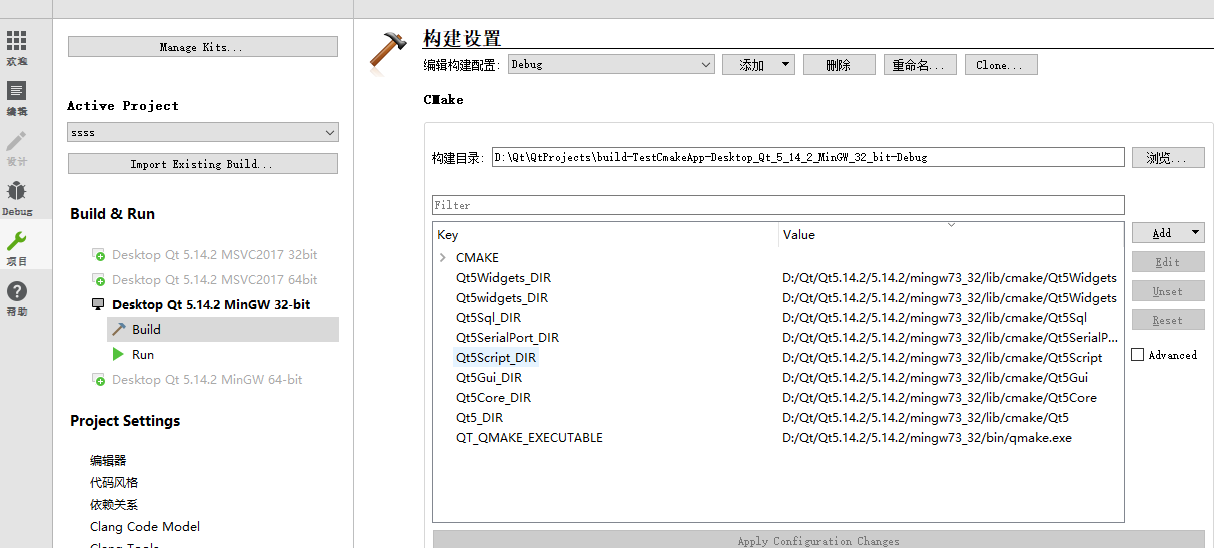
Qt扫盲-CMake 使用概述
CMake 使用概述一、概述二、创建Qt CMake 项目三、简单介绍1. 引入Qt的库2.Qt CMake 引入第三方库3. Qt CMake 项目目录四、使用案例一、概述 CMake是一个简化跨不同平台开发项目的构建过程的工具。对C来说其实就是生成一个文件,文件里面描述了,怎么组织…...

minGW-w64配置途径
文章目录1 GNU、GCC与minGW2 minGW当前下载方式3 minGW-w64配置途径Step1Step2Step31 GNU、GCC与minGW GNU这个名字是GNUs Not Unix的递归首字母缩写,它的发音为[gnoo],只有一个音节,发音很像"grew",但需要把其中的r音替…...
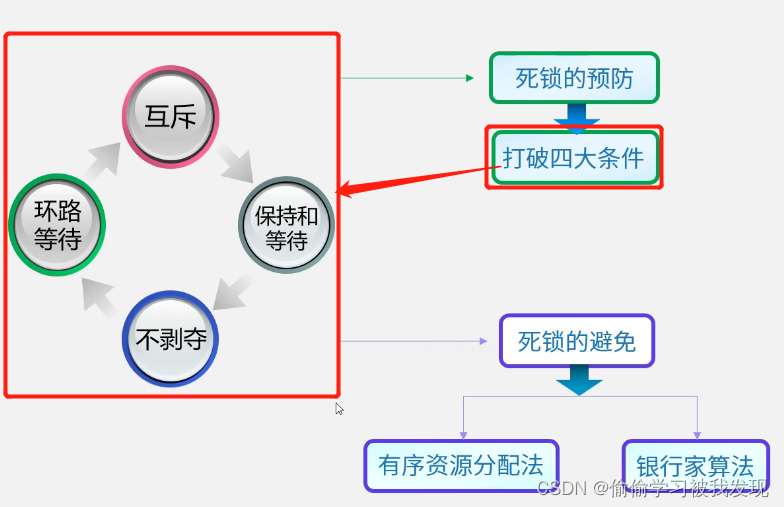
程序、进程、线程的基本概念、信号量的PV操作、前趋图的PV操作
程序、进程、线程的基本概念 进程控制块PCB的组织方式:顺序方式、链接方式、索引方式、Hash。 在JVM 中进程与线程关系 进程: 拥有资源的独立单位。可以被独立调度。可以分配资源。 线程: 可以被独立调度。同一进程中的多个线程,…...

设计测试用例
目录 测试用例的基本要素 测试用例的设计方法 功能需求测试分析 非功能需求测试分析 设计测试用例的具体方法 测试用例的基本要素 测试用例(Test Case)是为了实施测试而向被测试的系统提供的一组集合,这组集合包含:测试环境…...
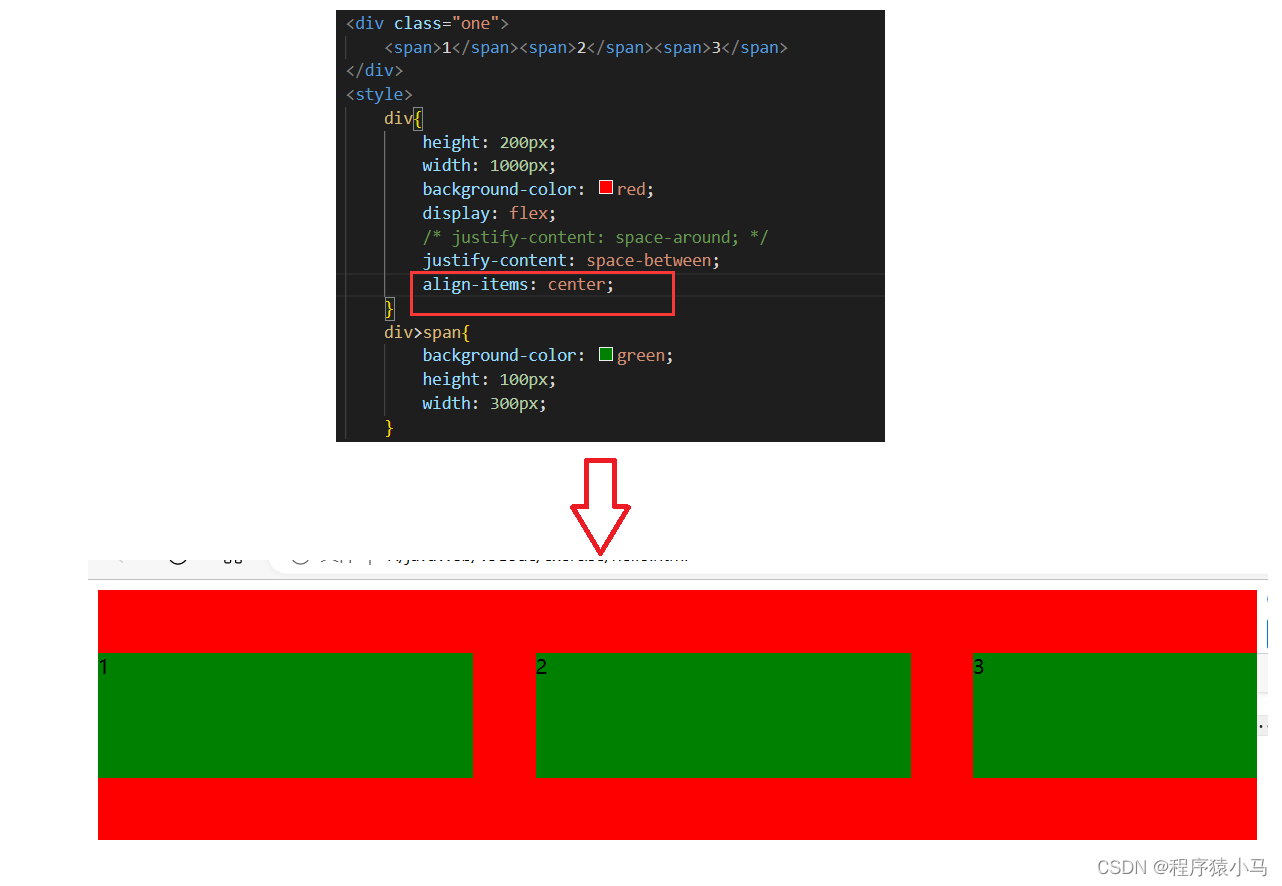
CSS 选择器以及CSS常用属性
目录 🐇今日良言:可以不光芒万丈,但不要停止发光 🐯一、写CSS的三种方法 🐯二、CSS选择器的常见用法 🐯三、CSS常用属性 🐇今日良言:可以不光芒万丈,但不要停止发光 🐯一、写CSS的三种方法 CSS的基本语…...
测试概念及模型
今日目标掌握测试用例包含的基本内容使用等价类方法设计出测试用例1. 软件测试分类(复习)1.1 按阶段划分单元测试测试:针对单个功能进行测试,如:登录、购物车等开发(更多的理解):针对…...

王道计算机组成原理课代表 - 考研计算机 第六章 总线 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对 计算机组成 知识点的理解的总结。希望对新一届的计算机考研人提供帮助!!! 关于对 “总线” 章节知识点总结的十分全面,涵括了《计算机组成原理》课程里的…...

【C++升级之路】第八篇:string类
🌟hello,各位读者大大们你们好呀🌟 🍭🍭系列专栏:【C学习与应用】 ✒️✒️本篇内容:简单介绍string类的概念、string类的常用接口、string类的模拟实现(各个常见接口的实现代码&…...

mysql性能优化_原理_课程大纲
1、MySQL在金融互联网行业的企业级安装部署 目录章节版本说明版本说明安装MySQL规范1 安装方式2 安装用户3 目录规范MySQL 5.7 安装部署1 操作系统配置2 创建用户3 创建目录4 安装5 配置文件6 安装依赖包7 配置环境变量8 初始化数据库9 重置密码MySQL8 安装MySQL8 安装源码安装…...

项目管理报告工具的功能
项目报告软件哪个好?Zoho Projects的项目管理报告工具为您提供整个组织的360可见性,获取所有项目的实时更新,使用强大的项目报告软件推动成功。Zoho Projects的项目报告软件允许团队整理和监控他们的资源和项目,以评估进度并避免对…...
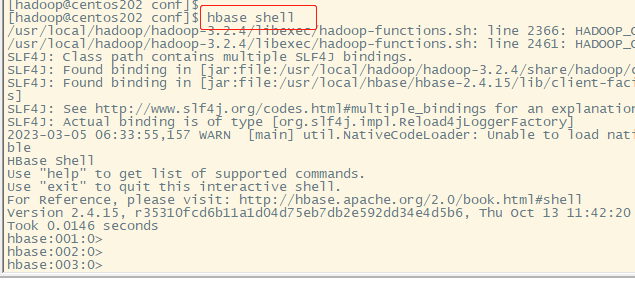
centos8上安装hbase
【README】1.本文部分内容转自:https://computingforgeeks.com/how-to-install-apache-hadoop-hbase-on-centos-7/2.本文是在单机上安装hbase (仅用于学习交流); 【1】更新系统因为 hadoop和hbase是动态的,为便于hbase…...
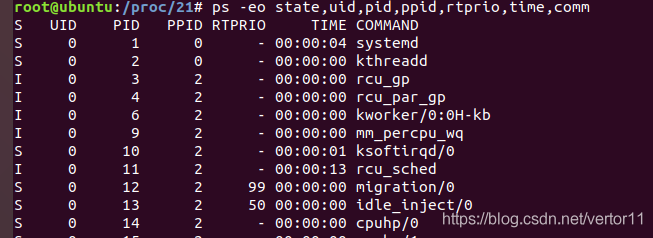
linux 进程及调度基础知识
引用Linux进程管理专题Linux进程管理与调度-之-目录导航Linux下0号进程的前世(init_task进程)今生(idle进程)----Linux进程的管理与调度(五)蜗窝科技-进程管理郭健: Linux进程调度技术的前世今生之“前世”郭健: Linux进程调度技术…...
Python计算分类问题的评价指标(准确率、精确度、召回率和F1值,Kappa指标)
机器学习的分类问题常用评论指标有:准确率、精确度、召回率和F1值,还有kappa指标 。 每次调包去找他们的计算代码很麻烦,所以这里一次性定义一个函数,直接计算所有的评价指标。 每次输入预测值和真实值就可以得到上面的指标值&a…...

三极管信号滤波原理与工程实践
1. 三极管在信号滤波中的独特应用作为一名嵌入式硬件工程师,我经常需要处理各种传感器信号。最近在无刷电机驱动项目中,遇到了霍尔信号毛刺干扰的问题。传统教科书上总是强调三极管的放大作用,但实际工程中,我发现三极管在信号滤波…...

时间/金额转换
公式:大头 总数值 / 限制(除数)剩余 总数值 % 限制(除数)例如要将95分钟拆成小时分钟的形式60分钟1小时,那么这60就是限制小时 95 / 60分钟 95 % 60...

从NTLM中继到域控接管:ADCS-ESC8漏洞实战解析
1. ADCS-ESC8漏洞概述 ADCS-ESC8是Active Directory证书服务(AD CS)中的一个高危漏洞,它允许攻击者通过NTLM中继攻击获取域控制器证书。这个漏洞的核心在于ADCS默认配置中的Web证书注册页面仅使用HTTP协议且支持NTLM认证,但未启用任何中继攻击防护措施。…...

ESXI系统安装全流程详解:从U盘启动到网络配置
1. 制作ESXI系统U盘启动盘 准备一个容量至少8GB的U盘,建议使用USB3.0接口的高速U盘,这样写入速度会快很多。我实测过,用USB2.0的U盘写入一个ESXI镜像可能需要20分钟,而USB3.0通常5分钟就能搞定。 首先需要下载两个关键文件&#x…...

Ubuntu 22.04上,用Cephadm 17.2.0搭建单节点Ceph集群的保姆级避坑指南
Ubuntu 22.04单节点Ceph集群实战:从零到生产级部署的17个关键细节 当你在Ubuntu 22.04上尝试用Cephadm搭建单节点Ceph集群时,是否遇到过这些场景:bootstrap卡在某个步骤超过半小时、OSD设备明明存在却显示"no available devices"、…...

Synthelix-Auto-Bot终极指南:10分钟掌握多钱包节点自动化管理
Synthelix-Auto-Bot终极指南:10分钟掌握多钱包节点自动化管理 【免费下载链接】Synthelix-Auto-Bot **Automated tool for managing Synthelix nodes across multiple wallets** 项目地址: https://gitcode.com/gh_mirrors/syn/Synthelix-Auto-Bot Synthelix…...

如何为Whisper ASR Webservice开发自定义引擎和插件
如何为Whisper ASR Webservice开发自定义引擎和插件 【免费下载链接】whisper-asr-webservice OpenAI Whisper ASR Webservice API 项目地址: https://gitcode.com/gh_mirrors/wh/whisper-asr-webservice Whisper ASR Webservice是一个基于OpenAI Whisper的语音识别服务…...

Comsol 脉冲激光诱导等离子体仿真模型:探索微观世界的奇妙之旅
Comsol脉冲激光诱导等离子体仿真模型 利用脉冲激光作为热源,在氩气环境中诱导产生等离子体,主要体现出等离子体的密度、等离子体温度等参数 可以为激光诱导等离子体提供准确的参考在科研与工程领域,对脉冲激光诱导等离子体的深入研究有着举足…...

解决Legado书源调试难题:从问题诊断到环境优化的完整指南
解决Legado书源调试难题:从问题诊断到环境优化的完整指南 【免费下载链接】legado Legado 3.0 Book Reader with powerful controls & full functions❤️阅读3.0, 阅读是一款可以自定义来源阅读网络内容的工具,为广大网络文学爱好者提供一种方便、快…...

PS插件加载失败?手把手教你用注册表修复PS2017-2022扩展未签署问题
PS插件加载失败?手把手教你用注册表修复PS2017-2022扩展未签署问题 当你在Photoshop中安装新插件时,突然弹出"扩展未经正确签署"的错误提示,这种挫败感我深有体会。作为一名长期与PS插件打交道的设计师,这个问题几乎成…...