KAFKA高可用架构涉及常用功能整理
KAFKA高可用架构涉及常用功能整理
- 1. kafka的高可用系统架构和相关组件
- 2. kafka的核心参数
- 2.1 常规配置
- 2.2 特殊优化配置
- 3. kafka常用命令
- 3.1 常用基础命令
- 3.1.1 创建topic
- 3.1.2 获取集群的topic列表
- 3.1.3 获取集群的topic详情
- 3.1.4 删除集群的topic
- 3.1.5 获取集群的消费组列表
- 3.1.6 获取集群的消费组详情
- 3.1.7 删除集群的消费组
- 3.1.8 获取集群的消费组消费延迟
- 3.2 常用运维命令
- 3.2.1 模拟数据消费
- 3.2.2 重置消费组
- 3.2.3 topic的partition扩、缩容、数据均衡
- 4. 事务性
- 4.1 数据写流程
- 4.1.1 相关概念
- 4.1.1 正常写入流程
- 4.1.2 当写入时broker宕机的处理方式
- 4.2 数据读流程
- 4.2.1 相关概念
- 4.2.2 正常消费流程
- 4.2.3 消费者rebalance说明
- 5. 日志复制流程
- 5.1. segment文件解析
- 5.1.1 偏移量索引
- 5.1.2 时间索引
- 5.2. kafka的日志复制流程
- 5.3. kafka的日志清理机制
- 5.3.1 日志删除
- 5.3.2 日志压缩
- 6. 疑问和思考
- 6.1 相关概念
- 6.2 如果消费者commit的时间过长,为什么会触发消费者的rebalance?
- 6.3 为什么要设计ISR?
- 6.4 Follower能否对外提供服务?
- 6.5 如何记录消费者的消费offset信息?
- 6. 参考文档
探讨kafka的系统架构以及以及整体常用的命令和系统分析,本文主要探讨高可用版本的kafka集群,并基于日常工作中的沉淀进行思考和整理。更多关于分布式系统的架构思考请参考文档关于常见分布式组件高可用设计原理的理解和思考
1. kafka的高可用系统架构和相关组件
kafka面对的使用场景是,大量数据的生产和消费,是面对大数据的消息中间件。这么巨大的业务体量,难以通过一台机器完成所有的数据写入、存储和请求,因此需要进行数据的分片,采用 分片模式 进行数据拆分,从而降低单台机器的压力,并能够提供大量的集群扩展能力。
按照 分片模式 的架构模式,在架构上需要拆分2种类型的角色
- 具备全局视角的元数据保存组件或者角色
- 实际的worker节点,具体负责业务的数据写入、存储和读写请求
在kafka的系统架构中,全局视角 并没有拆分出一个单独的组件进行完成,而是复用broker进程,通过broker进程中拆分出独立的模块controller,负责全局的元数据存储和数据视角。
-
kafka的 0.11.0以前的版本,对于分区和副本的状态的管理依赖于zookeeper的watcher和队列:每一个broker都会在zookeeper注册watcher,所以zookeeper就会出现大量的watcher, 如果宕机的broker上的partition很多比较多,会造成多个watcher触发,造成集群内大规模调整;每一个replica都要去再次zookeeper上注册监视器,当集群规模很大的时候,zookeeper负担很重。这种设计很容易出现脑裂和羊群效应以及zookeeper集群过载。
-
kafka的 0.11.0版本后改变了这种设计,使用controller,只有controller,Leader会向zookeeper上注册watcher,其他broker几乎不用监听zookeeper的状态变化。
kafka集群中多个broker,有一个会被选举为controller leader,负责管理整个集群中分区和副本的状态,比如partition的leader 副本故障,由controller 负责为该partition重新选举新的leader 副本;当检测到ISR列表发生变化,有controller通知集群中所有broker更新其MetadataCache信息;或者增加某个topic分区的时候也会由controller管理分区的重新分配工作。
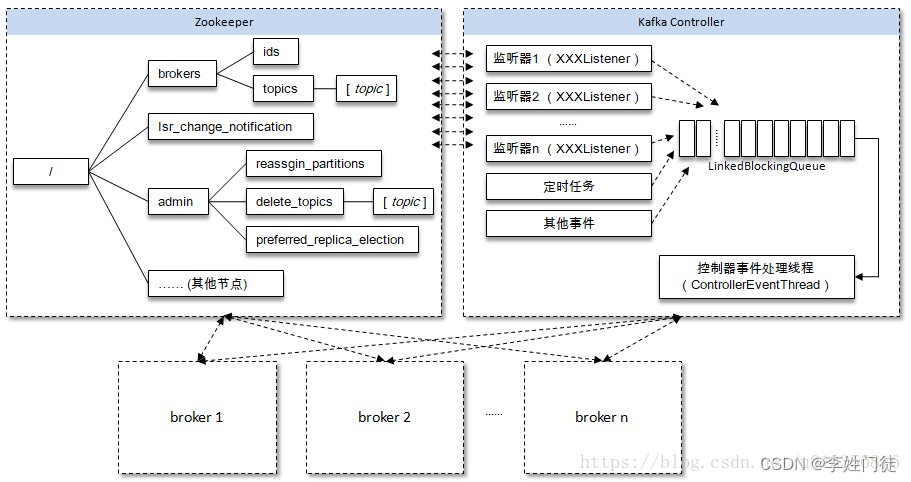
相关核心的组件和角色作用如下
| 组件 | 部署模式 | 组件作用 | 备注 |
|---|---|---|---|
| controller | 复用broker | 存储集群的元数据,具体集群数据的全局视角 | 负责管理整个集群中分区和副本的状态,多个broker通过选举选择一个controller Leader 进行工作 |
| broker | 多机部署 | 它负责接收、存储和管理消息数据 | 接收和存储消息数据:kafka broker接收来自producer发送的消息,并将这些消息存储在自己的磁盘上。 |
| zk | 多节点部署 | zk提供kafka的broker选主锁和消息通知,zkfc接受相关zk进行主从切换 | 通过Zab 协议来保证分布式事务的最终一致性 |
注:在 kafka 2.8.0 版本,移除了对 Zookeeper 的依赖,通过 KRaft 进行自己的集群管理,使用 kafka 内部的 Quorum 控制器来取代 ZooKeeper,因此用户第一次可在完全不需要 ZooKeeper 的情况下执行 kafka,这不只节省运算资源,并且也使得 kafka 效能更好,还可支持规模更大的集群。
2. kafka的核心参数
2.1 常规配置
server.properties配置
log.flush.interval.messages=92233720368547758
# kafka的监听地址
listeners=PLAINTEXT://0.0.0.0:9092
socket.request.max.bytes=104857600
broker.rack=50010001
log.retention.bytes=-1
compression.type=producer
zookeeper.connection.timeout.ms=6000
replica.lag.time.max.ms=10000
replica.fetch.max.bytes=1048576
log.cleaner.enable=true
log.dirs=/var/lib/kafka/data/topics
# kafka的topic保存时间,默认是7天,根据实际情况调整
log.retention.hours=168
log.segment.bytes=1073741824
offsets.topic.replication.factor=3
default.replication.factor=3
broker.id=0
socket.send.buffer.bytes=102400
# kafka的监听地址
advertised.listeners=PLAINTEXT://0.0.0.0:9092
# zk的链接地址
zookeeper.connect=xx.xx.xx.xx:2181/kafka
num.io.threads=8
socket.receive.buffer.bytes=102400
message.max.bytes=1000012
auto.create.topics.enable=false
log.flush.interval.ms=92233720368547758
min.insync.replicas=1
log.retention.check.interval.ms=300000
# topic默认的副本因子,总的副本数+1
num.replica.fetchers=1
num.partitions=1
num.network.threads=3
2.2 特殊优化配置
- 跟消费者相关,如果消费者超出相关心跳、拉取数据周期,会被判定消费者失效
# 消费者心跳配置,单位ms
session.timeout.ms=10000
# 消费者拉取数据周期,单位ms
max.poll.interval.ms=300000
3. kafka常用命令
3.1 常用基础命令
3.1.1 创建topic
# 获取zk地址
zk=$(cat config/server.properties | grep -v '^[[:space:]]*#' | grep zookeeper.connect= | awk -F',' '{print $NF}')
topic="xx"
# 检查所有的消费组状态
./kafka-topics.sh --create --zookeeper $zk --topic $topic --replication-factor 2 --partitions 8
3.1.2 获取集群的topic列表
# 获取zk地址
zk=$(cat config/server.properties | grep -v '^[[:space:]]*#' | grep zookeeper.connect= | awk -F',' '{print $NF}')
# 检查topic状态, 预期isr节点个数和副本数相等
bin/kafka-topics.sh --zookeeper $zk --list
3.1.3 获取集群的topic详情
# 获取zk地址
zk=$(cat config/server.properties | grep -v '^[[:space:]]*#' | grep zookeeper.connect= | awk -F',' '{print $NF}')
topic="test"
# 检查topic状态, 预期isr节点个数和副本数相等
bin/kafka-topics.sh --zookeeper $zk --describe --topic $topic# 检查所有的topic状态, 预期isr节点个数和副本数相等
bin/kafka-topics.sh --zookeeper $zk --describe
3.1.4 删除集群的topic
# 获取zk地址
zk=$(cat config/server.properties | grep -v '^[[:space:]]*#' | grep zookeeper.connect= | awk -F',' '{print $NF}')
topic="test"
# 删除相关的topic,但是需要kafka侧开启相关的配置才能支持
bin/kafka-topics.sh --zookeeper $zk --delete --topic $topic# 检查所有的topic状态, 预期isr节点个数和副本数相等
bin/kafka-topics.sh --zookeeper $zk
3.1.5 获取集群的消费组列表
# 获取zk地址
broker="127.0.0.1:9092"
# 检查所有的消费组状态
bin/kafka-consumer-groups.sh --bootstrap-server $broker --list
3.1.6 获取集群的消费组详情
# 获取zk地址
broker="127.0.0.1:9092"
group="xxx"
# 查看单个消费组的详情
bin/kafka-consumer-groups.sh --bootstrap-server $broker --describe --group $group
3.1.7 删除集群的消费组
# 获取zk地址
broker="127.0.0.1:9092"
group="xxx"
# 删除相关的消费组
bin/kafka-consumer-groups.sh --bootstrap-server $broker --describe --group $group --delete
3.1.8 获取集群的消费组消费延迟
# 获取zk地址
broker="127.0.0.1:9092"
# 检查所有的消费组状态
bin/kafka-consumer-groups.sh --bootstrap-server $broker --describe --group $group
3.2 常用运维命令
3.2.1 模拟数据消费
1, 控制台1生产消息
broker="127.0.0.1:9092"
topic="xxx"
#生产消息
./bin/kafka-console-producer.sh --broker-list $broker --topic $topic
2, 控制台2消费消息
broker="127.0.0.1:9092"
topic="xxx"
group="xxx"
# 从头开始消费
bin/kafka-console-consumer.sh --topic $topic --group $group --bootstrap-server $broker# 从尾部开始消费,必需要指定分区
bin/kafka-console-consumer.sh --bootstrap-server $broker --topic $topic --offset latest
3.2.2 重置消费组
broker="127.0.0.1:9092"
topic="xxx"
group="xxx"
# 重置消费组到最早的消费位点,该操作通常用于补数据
bin/kafka-consumer-groups.sh --bootstrap-server $broker --group $group --reset-offsets --topic $topic --to-earliest --execute# 重置消费组到最新的消费位点,该操作通常用于消费组无法完成数据消费,丢失所有的数据
bin/kafka-consumer-groups.sh --bootstrap-server $broker --group $group --reset-offsets --topic $topic --to-latest --execute# 重置消费组到某个时间点
datetime="2017-08-04T14:30:00.000"
bin/kafka-consumer-groups.sh --bootstrap-server $broker --group $group --reset-offsets --topic $topic --to-datetime $datetime --execute
3.2.3 topic的partition扩、缩容、数据均衡
zk=$(cat config/server.properties | grep -v '^[[:space:]]*#' | grep zookeeper.connect= | awk -F',' '{print $NF}')
broker="127.0.0.1:9092"
topic="xxx"
group="xxx"# 调整分区副本分布
#1.先写一个topic.json指定需要reassign的topic
cat topics.json
{"topics": [{"topic": "xx"}],"version": 1
} #2.生成推荐方案,执行下面命令会在控制台打印出推荐方案,将"Proposed partition reassignment configuration" 下方的json文件存储为topic.json, 可按需调整
./kafka-reassign-partitions.sh --zookeeper $zk --topics-to-move-json-file topics.json --generate --broker-list 0,1,2# 输出内容如下
{"version":1,"partitions":[{"topic":"xx","partition":1,"replicas":[2,3,0,4,1,5],"log_dirs":["any","any","any","any","any","any"]},{"topic":"xx","partition":0,"replicas":[5,2,3,0,4,1],"log_dirs":["any","any","any","any","any","any"]}]}#3.将控制台输出的内容,保存成replication-factor.json,并按照预期的结果编辑,编辑结果如下#如上1/2步骤也可以跳过,直接执行步骤3,按照格式调整副本数量,之后执行4/5/6步骤即可,可以按照预期的方式进行手动编辑如下配置文件,调整相关的topic的partion数量,以及每个partition所在的broker节点信息
cat replication-factor.json{"version":1,"partitions":[{"topic":"xx","partition":1,"replicas":[0,1],"log_dirs":["any","any"]},{"topic":"xx","partition":0,"replicas":[0,1],"log_dirs":["any","any"]}]}#4.使用replication-factor.json执行副本调整
bin/kafka-reassign-partitions.sh --zookeeper $zk --reassignment-json-file replication-factor.json --execute#5.使用replication-factor.json查询调整的进度,预期是最终所有的partiton completed successfully
bin/kafka-reassign-partitions.sh --zookeeper $zk --reassignment-json-file replication-factor.json --verify#7.检查topic的分区情况
bin/kafka-topics.sh --zookeeper $zk --describe --topic $topic
4. 事务性
4.1 数据写流程
4.1.1 相关概念
跟数据读写流程中涉及的相关概念,进行相关介绍
- broker: 消息处理节点,多个broker组成kafka集群。
- topic: 组成一个完整的消息队列
- partition: 一个topic拆分成多个partition,每个partion有多副本,分散在不同的broker,从而实现分布式和topic的扩展能力
- replica:partition 的副本,保障 partition 的高可用。
- producer: 产生信息的主体,可以是服务器日志信息等。
- consumer group:每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 的一个 consumer 消费,但可以被多个 consumer group 消费。
- consumer: 消费producer产生话题消息的主体。
4.1.1 正常写入流程
kafka的数据写流程,整体流程如下。
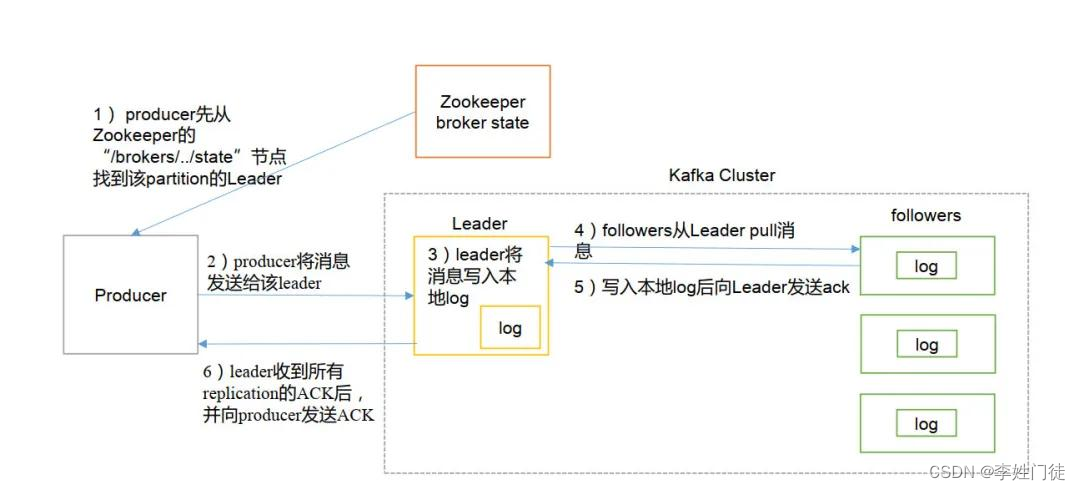
producer向kafka创建一条记录,记录中一个要指定对应的topic和value,key和partition可选。 先将数据进行序列化,然后按照topic和partition,放进对应的发送队列中。为了提升效率和数据写入吞吐,kafka producer都是批量请求,会积攒一批,然后一起发送,不是调send()就进行立刻进行网络发包。发送到partition分为两种情况
- 指定了key,按照key进行哈希,相同key去一个partition。
- 没有指定key,轮询来选partition
当选择好写入的topic和partition后,进行数据写入,整体流程如下
- producer 先从 zookeeper 的 "/kafka/kafka/brokers/topics/xxx/partitions/x/state"节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- ISR内的所有followers 从 leader 异步拉取消息,写入本地 log 后向 leader 发送 ACK
- leader返回向producer ACK
说明
request.required.acks 参数不同,返回模式不同:
- request.required.acks = 0 表示 producer 不等待来自 Leader 的 ACK 确认,直接发送下一条消息。在这种情况下,如果 Leader 分片所在服务器发生宕机,那么这些已经发送的数据会丢失。
- request.required.acks = 1 表示 producer 等待来自 Leader 的 ACK 确认,当收到确认后才发送下一条消息。在这种情况下,消息一定会被写入到 Leader 服务器,但并不保证 Follow 节点已经同步完成。所以如果在消息已经被写入 Leader 分片,但是还未同步到 Follower 节点,此时Leader 分片所在服务器宕机了,那么这条消息也就丢失了,无法被消费到。
- request.required.acks = -1 表示 producer 等待来自 Leader 和ISR内的所有Follower 的 ACK 确认之后,才发送下一条消息。在这种情况下,除非 Leader 节点和所有 Follower 节点都宕机了,否则不会发生消息的丢失。
zk中的topic对应的partition情况如下
4.1.2 当写入时broker宕机的处理方式
在写入过程时,producer将数据写入Leader副本后,Follower副本通过pull的方式从Leader异步拉取数据,因此在producer写入数据时,出现节点宕机时的表现如下
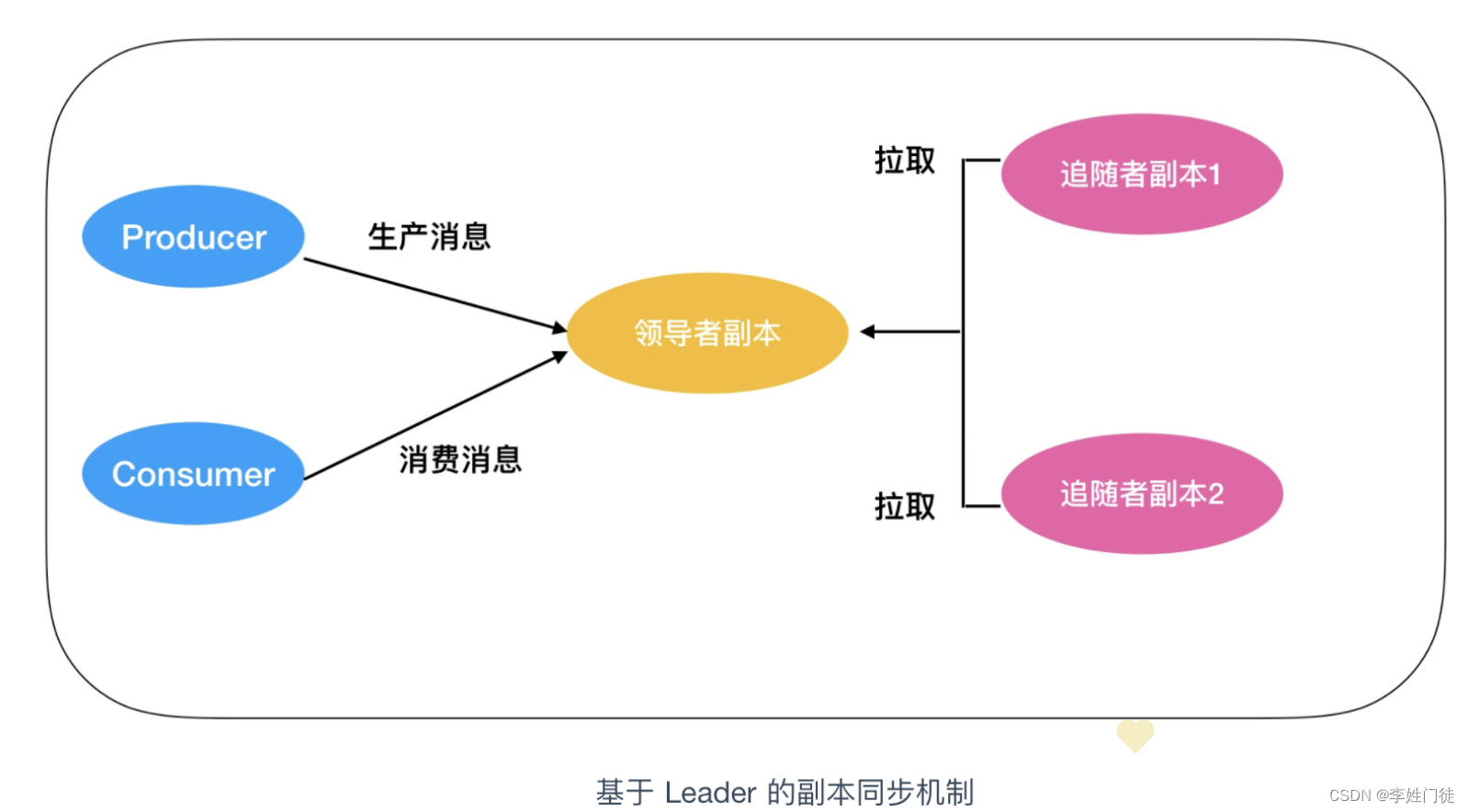
- 如果宕机的节点是Leader,producer不能把数据写入Leader副本,因此此时需要producer配置超时重试,等待partition从ISR中重新选择出Leader,producer将数据写入。
- 如果宕机的节点是Follower,宕机的Follower会被踢出ISR列表,producer写入数据给Leader不受影响,ISR内所有的Follower返回ACK确认后,表示数据已经完成写入,并返回给producer ACK,表示该数据已经写入完成。
4.2 数据读流程
4.2.1 相关概念
kafka的消费者使用pull流程,主动从topic-partition拉取数据。consumer加入到consumer group,触发partition的rebalance,给对应的consumer分配消费的partition(如果consumer数量 > partition数量,该consumer可能会分配到能够消费的partition),在parition进行rebalance期间,消费者无法读取消息,整个群组有一小段时间不可用
coordinator:辅助实现消费者组的初始化和分区的分配。
coordinator节点选择 = groupid的hashcode值 % 50( __consumer_offsets的分区数量)
4.2.2 正常消费流程
kafka的数据消费流程,整体流程如下。
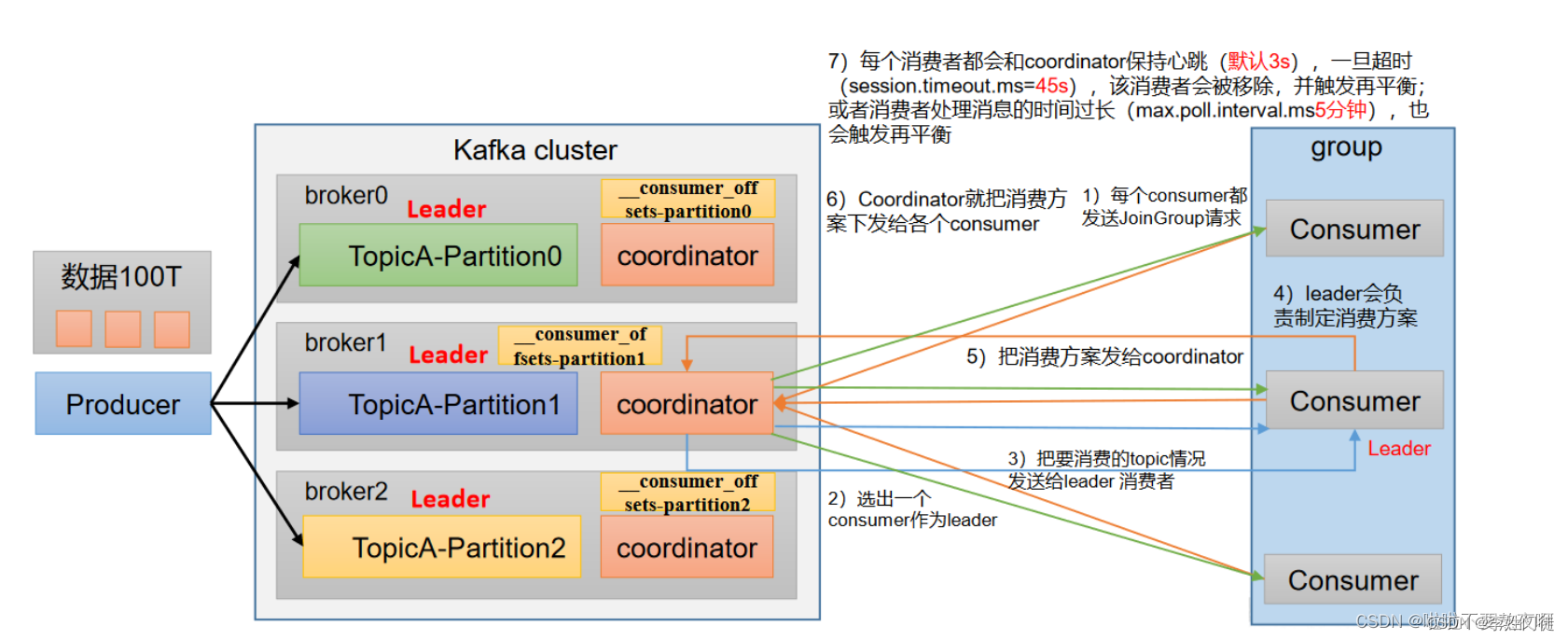
- 每个consumer都发送JoinGroup请求;
- 选出一个consumer作为leader;
- 把要消费的topic情况发送给leader 消费者;
- leader会负责制定消费方案;
- 把消费方案发给coordinator;
- coordinator就把消费方案下发给各个consumer;
- consumer 连接到 leader 对应的 broker
- consumer 将自己保存的 offset 发送给 leader
- leader 根据 offset 等信息定位到 segment(索引文件 .index 和日志文件 .log ),根据索引文件中的内容,定位到日志文件中该偏移量对应的开始位置读取相应长度的数据并返回给 consumer
参考segment文件解析
- consumer完成数据消费逻辑后,进行commit,该数据被消费完成
说明
- comsumer完成数据消费,并提交commit后,对应的消费offset就会被确认。如果consumer完成了commit,但是在后续的下游的处理过程中出现了逻辑异常,有可能会出现数据丢失。所以通常的做法是,consumer读取到了kafka的数据,并进行下游的逻辑处理,等到完整的逻辑处理完并sink到下游后,才提交commit,避免数据丢失。
- 在一个consumergroup中,一个parition最多只能给一个consumer消费,但是一个consumer可以消费多个parition,所以更多时候,parition的数量限制了consumer的数量,因此需要再业务上线时进行容量评估。
4.2.3 消费者rebalance说明
- kafka服务端会维护和检测consumer是否正常存活,每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;
- 如果消费者处理消息的时间过长(max.poll.interval.ms 5分钟),也会触发再平衡。因此在进行消费时需要注意,尽量避免数据的处理逻辑过于复杂,处理时间过长
- consumer加入或者离开consumer group也会触发再平衡,平衡期间对应的consumer group不能消费数据
5. 日志复制流程
5.1. segment文件解析
返回segment文件解析
kafka通过topic-partition副本机制拆分到多个broker节点,从而实现数据的分片,提供集群的扩展能力。每个partition数据又由多个segment分片组合而成。 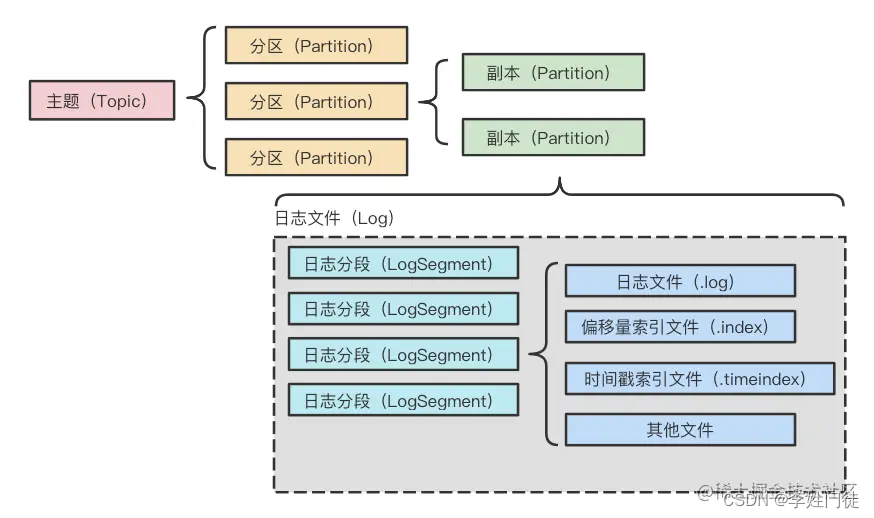 每个日志分段都有一个基准偏移量(baseOffset,20位数字),表示当前日志分段的第一条消息的offset。日志分段相关文件名就用基准偏移量进行命名,从而可以通过文件名的offset初步找到相关消息的数据位置,一定程度上可以实现索引的目的,比如: | 文件类别 | 作用 | |-------------------------|-----------------------------------| | .index | 消息的物理地址的偏移量索引文件 | | .timeindex | 映射时间戳和相对offset的时间戳索引文件 | | .log | 日志文件(消息存储文件) | | .snapshot | 对幂等型或者事务型producer所生成的快照文件 | | leader-epoch-checkpoint | 保存了每一任leader开始写入消息时的offset, 会定时更新 |kafka日志追加是顺序写入的,日志文件存在多种后缀,重点需要关注**.index,.timeindex和.log** 三种类型。每个Segment都有一个基准偏移量,用来表示当前Segment中的第一条消息的offset。
-rw-r--r--. 1 kafka kafka 245432 Feb 25 13:01 00000000000000000000.index
-rw-r--r--. 1 kafka kafka 909769306 Feb 25 11:31 00000000000000000000.log
-rw-r--r--. 1 kafka kafka 343392 Feb 25 13:01 00000000000000000000.timeindex
-rw-r--r--. 1 kafka kafka 10485760 Mar 1 08:56 00000000000001778276.index
-rw-r--r--. 1 kafka kafka 265569655 Mar 1 08:56 00000000000001778276.log
-rw-r--r--. 1 kafka kafka 10 Feb 25 13:01 00000000000001778276.snapshot
-rw-r--r--. 1 kafka kafka 10485756 Mar 1 08:56 00000000000001778276.timeindex.log文件中存储的是真正的数据,通过命令可以看到如下信息:
baseOffset: 0 lastOffset: 31 count: 32 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1636617435886 size: 4961 magic: 2 compresscodec: NONE crc: 3491097385 isvalid: true
baseOffset: 32 lastOffset: 35 count: 4 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 4961 CreateTime: 1636617435892 size: 674 magic: 2 compresscodec: NONE crc: 1015769393 isvalid: true
baseOffset: 36 lastOffset: 37 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 5635 CreateTime: 1636617435892 size: 367 magic: 2 compresscodec: NONE crc: 587346678 isvalid: true
baseOffset: 38 lastOffset: 41 count: 4 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 6002 CreateTime: 1636617435894 size: 676 magic: 2 compresscodec: NONE crc: 2973063088 isvalid: true
从以上内容可以看到的的消息是:baseOffset从0开始,到offset为31结束的消息段中存储了32条消息,时间戳是1636617435886,大小为4961K,压缩类型为NONE。
由此可以推断出kafka的2种类型的索引方式:偏移量索引(对应.index)和时间索引(对应.timeindex)。
5.1.1 偏移量索引
.index文件中的内容如下:
1 offset: 35 position: 4961
2 offset: 261 position: 24300
3 offset: 352 position: 40646
4 offset: 458 position: 54670
如果要查找offset为270的消息
- 首先会通过二分找到对应的segment
- 然后去对应的.index文件通过二分找到不大于270的最大索引项,也就是[offset: 261 position: 24300]
- 之后进行顺序扫描,通过二分法找到offset为261的那条,并记录物理偏移量
- 从.log文件中的物理偏移量为24300的位置开始顺序查找偏移量为270的消息。
5.1.2 时间索引
timeindex文件中的内容如下:
timestamp: 1636617435892 offset: 35
timestamp: 1636617435952 offset: 261
timestamp: 1636617435981 offset: 352
timestamp: 1636617435988 offset: 458
如果要查找timstamp为1636617435955开始的消息
- 首先将时间戳和每个.log文件中最大的时间戳largestTimeStamp进行逐一对比,直到找到不小于1636617435955所对应的segment
- .log文件的largestTimeStamp的计算是先查询该log文件所对应的时间戳文件,找到最后一条索引项,若最后一条索引项的时间戳字段大于0,则取该值,否则去取log的修改时间
- 找到log文件后,使用二分法定位,找到不大于1636617435955的最大索引项,也就是[timestamp: 1636617435952 offset: 261]
- 拿着偏移量是261的offset值去.index文件找到不大于261的最大索引项,也就是[offset: 261 position: 24300]
- 之后从偏移量为24300的位置开始顺序查找,找到timestamp不小于1636617435955的消息。
5.2. kafka的日志复制流程
ISR机制,整体流程如下
- producer 通知 ZooKeeper 识别Leader
- producer 向Leader写入消息
- Leader收到消息后会把消息写入到本地 log
- Follower会从Leader那里拉取消息
- Follower向本地写入 log
- Follower向Leader发送写入成功的消息
- Leader会收到Follower(部分或者所有)发送的消息,并根据producer的数据写入模式决定返回
- Leader根据producer的数据写入模式以及Follower完成写入的数量决定向producer返回写入成功的
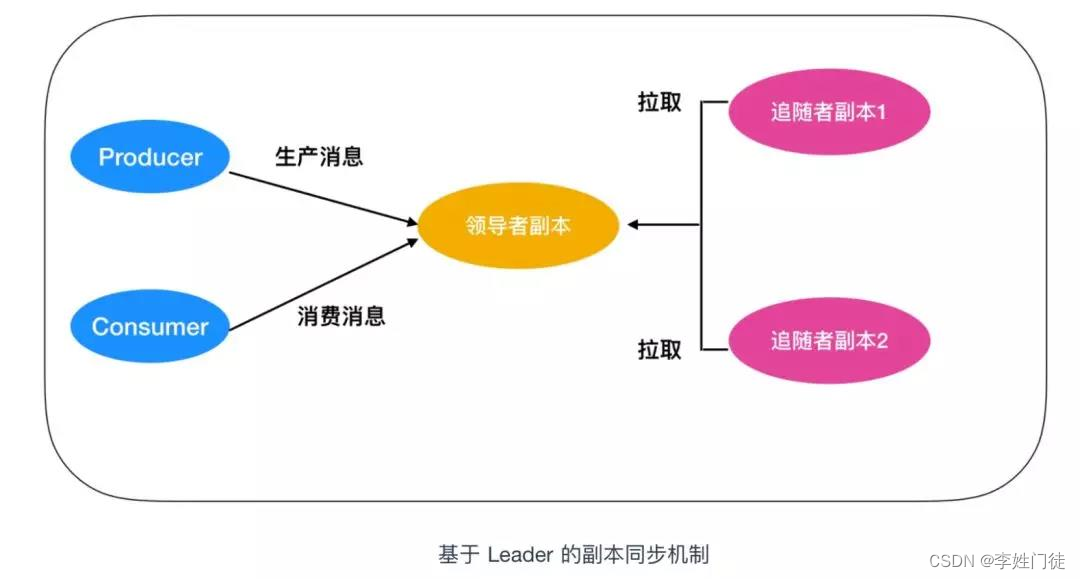
这幅图需要注意以下几点
- 所有的请求都必须发送到 Leader 副本所在的 broker 中,Follower 副本只是用作数据拉取,采用异步拉取的方式,并写入到自己的提交日志中,从而实现与 Leader 的同步
- 当 Leader 副本所在的 broker 宕机后,kafka 依托于 ZooKeeper 提供的监控功能能够实时感知到,并开启新一轮的选举,从追随者副本中选一个作为 Leader。如果宕机的 broker 重启完成后,该分区的副本会作为 Follower 重新加入。
5.3. kafka的日志清理机制
kafka提供了两种清理策略:日志删除和日志压缩,可以通过参数log.cleaner.policy进行配置,参数可选[compact, delete]。
5.3.1 日志删除
按照一定的策略,将不满足的数据进行删除。日志删除的配置如下:
| 配置 | 默认值 | 说明 |
|---|---|---|
| log.retention.check.interval.ms | 300000毫秒 | 日志清理器检查日志是否符合删除条件的频率(毫秒) |
| log.retention.bytes | -1 | 保留日志文件的最大值 |
| log.segment.bytes | 1073741824 | 单个日志文件的最大大小(KB) |
| log.retention.hours | 168小时 | 日志保留的时间(小时) |
| log.retention.minutes | 日志保留的时间(分钟) | |
| log.retention.ms | 日志保留的时间(毫秒) | |
| file.delete.delay.ms | 60000毫秒 | 从磁盘中删除的延迟时间(毫秒) |
5.3.2 日志压缩
针对每个消息的key进行整合,对于有相同key的不同的value值,只保留最后一个版本。也支持对单个的topic进行配置清理策略,参数cleaner.policy,压缩策略通过compression.type进行指定,可选值为[‘none’, ‘gzip’, ‘snappy’, ‘lz4’, ‘zstd’]。
6. 疑问和思考
6.1 相关概念
ISR( In-Sync Replicas): 就是 kafka 为某个分区维护的一组同步集合,即每个分区都有自己的一个 ISR 集合,处于 ISR 集合中的副本,意味着 follower 副本与 leader 副本保持同步状态,只有处于 ISR 集合中的副本才有资格被选举为 leader。一条 kafka 消息,只有被 ISR 中的副本都接收到,才被视为“已同步”状态。
HW (High Watermark)俗称高水位 : 它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
LEO (Log End Offset): 标识当前日志文件中下一条待写入的消息的offset。图中offset为9的位置即为当前日志文件的 LEO,LEO 的大小相当于当前日志分区中最后一条消息的offset值加1.分区 ISR 集合中的每个副本都会维护自身的 LEO ,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
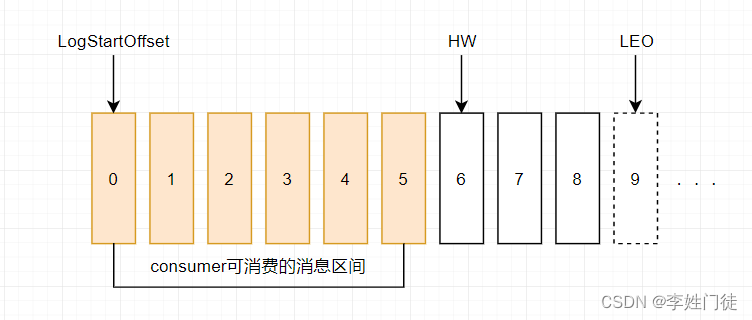
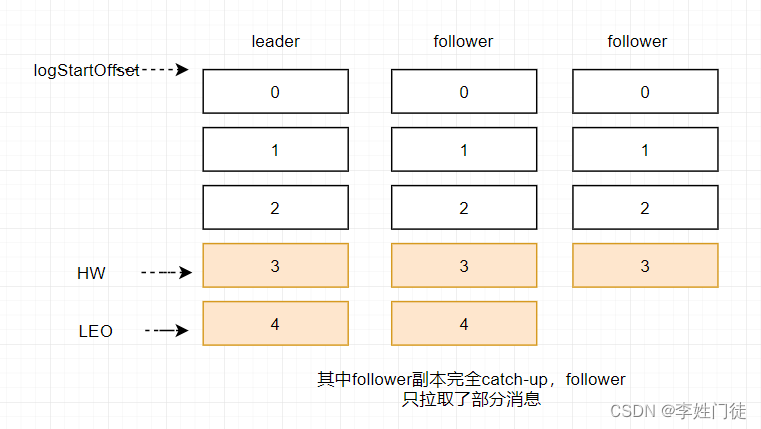
由于kafka的允许producer自定义数据的写入模式(request.required.acks 的3中模式),相同topic-partition的leader数据是领先的,ISR中的不同Follower拉取数据进度不同,因此数据程度是不一样的。
6.2 如果消费者commit的时间过长,为什么会触发消费者的rebalance?
kafka服务端会维护和检测consumer是否正常存活,每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理消息的时间过长(max.poll.interval.ms 5分钟),也会触发再平衡。因此在进行消费时需要注意,尽量避免数据的处理逻辑过于复杂,处理时间过长
6.3 为什么要设计ISR?
因为kafka为了追求更高的吞吐能力,partition副本之间的同步都是异步进行,因此在kafka的副本之间数据不一致是比较场景的行为。生产中难以避免,有些Follower节点的数据相对于Leader慢很多。如果不及时踢出异常节点或者慢节点,就会出现部分节点拖垮集群整体写入性能的情况,从而导致集群异常。ISR能够有效的规避这些节点,避免他们参与选举Leader、数据写入的ACK等,能够在数据写入的实时性和数据一致性上得到更好的保证。
ISR不是一成不变的每个partition的ISR是不断地进行动态调整的。如果Follower延时太久,那么leader会它移除,延时的时间由参数replica.log.max.messages和replica.log.time.max.ms决定。
6.4 Follower能否对外提供服务?
不能。
在kafka的设计模式中,单个partition的Leader数据才是最全、最完整的(只能消费到HW前的数据),消费者跟Leader通信获取拉取数据,能够得到最准确的数据事务,并且一致性能够得到保证。另外topic的partition是拆分在不同的broker上的,当kafka有多个topic-partition时,Leader的partition的相对均匀的分布在不同的broker,因此也能够分担压力。早起的kafka版本就是这样设计的
实际上,由于consumer只能消费到ISR中的HW以前的数据(已经完成commit),ISR中的Follower在HW前的数据是一致的,因此实际上也能够从consumer消费。后续的版本提供了follower replica fetch概念,实现了从follower拉取数据。
6.5 如何记录消费者的消费offset信息?
-
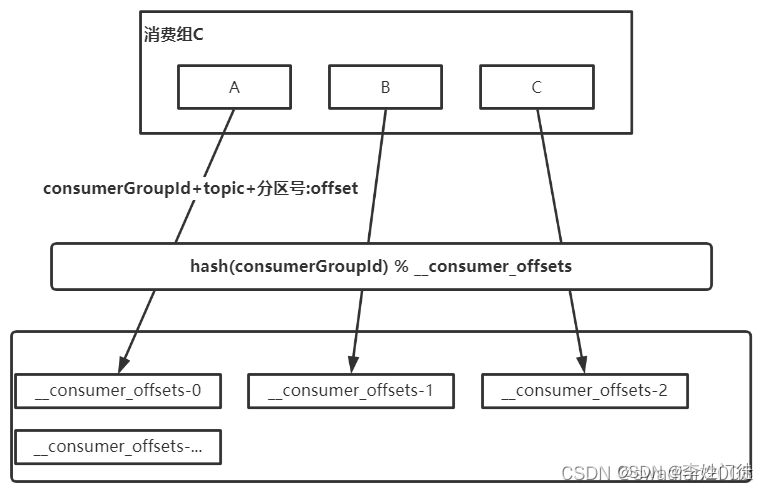
每个consumer会定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets,提交过去的时候,key是consumerGroupId+topic+分区号(指定消费组、消费的主题的分区),value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据。
-
__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
通过如下公式可以选出consumer消费的offset要提交到__consumer_offsets的对应的分区hash(consumerGroupId) % 50(__consumer_offsets的分区数)
6. 参考文档
- 一文讲清 Kafka 工作流程和存储机制
- kafka写入的过程
- Kafka 的这些原理你知道吗
- kafka系列 - 12 Kafka 消费者|消费方式|工作流程|消费者组原理|消费者组初始化和消费流程|消费者参数
- Kafka的日志存储
相关文章:
KAFKA高可用架构涉及常用功能整理
KAFKA高可用架构涉及常用功能整理 1. kafka的高可用系统架构和相关组件2. kafka的核心参数2.1 常规配置2.2 特殊优化配置 3. kafka常用命令3.1 常用基础命令3.1.1 创建topic3.1.2 获取集群的topic列表3.1.3 获取集群的topic详情3.1.4 删除集群的topic3.1.5 获取集群的消费组列表…...

3d模型上的材质怎么删除---模大狮模型网
在大多数3D软件中,可以通过以下步骤来删除3D模型上的材质: 选择要删除材质的模型:首先,从场景中选择包含目标材质的模型。可以使用选择工具或按名称查找模型。 进入编辑模式:将模型切换到编辑模式。这通常需要选择相应…...

leetcode hot100跳跃游戏Ⅱ
本题和上一题还是有不一样的地方,这个题中,我们需要记录我们跳跃的步数并尽可能的满足最小的跳跃步数到达终点。 那么我们还是采用覆盖范围的概念,但是我们需要两个,一个是在当前位置的覆盖范围,另一个是下一步的覆盖…...

大数据期望最大化(EM)算法:从理论到实战全解析
文章目录 大数据期望最大化(EM)算法:从理论到实战全解析一、引言概率模型与隐变量极大似然估计(MLE)Jensen不等式 二、基础数学原理条件概率与联合概率似然函数Kullback-Leibler散度贝叶斯推断 三、EM算法的核心思想期…...
【鸿蒙】大模型对话应用(二):对话界面设计与实现
Demo介绍 本demo对接阿里云和百度的大模型API,实现一个简单的对话应用。 DecEco Studio版本:DevEco Studio 3.1.1 Release HarmonyOS SDK版本:API9 关键点:ArkTS、ArkUI、UIAbility、网络http请求、列表布局、层叠布局 对话页…...

MySQL 导入数据
我们可以将已有的数据导入到MySQL数据库中,下面是几种方式: 1、mysql 命令导入 使用 mysql 命令导入语法格式为: mysql -u用户名 -p密码 < 要导入的数据库数据(shulanxt.sql) 实例: # mysql -uroot -p123456 < …...

探索数字经济:从基础到前沿的奇妙旅程
新一轮技术革命方兴未艾,特别是以人工智能、大数据、物联网等为代表的数字技术革命,催生了一系列新技术、新产业、新模式,深刻改变着世界经济面貌。数字经济已成为重组全球要素资源、重塑全球经济结构、改变全球竞争格局的关键力量。预估到20…...
】如何在 Windows 操作系统上设置 Design Space Explorer II 远程 SSH 场)
【INTEL(ALTERA)】如何在 Windows 操作系统上设置 Design Space Explorer II 远程 SSH 场
说明 从英特尔 Quartus Prime Pro Edition 软件 22.1 版本开始,您可以选择使用 Windows OpenSSH 服务器设置 Design Space Explorer II (DSE II)。 解决方法 1.让 DSE II 与 OpenSSH 协同工作的第一步是 安装 OpenSSH。应在远程主机上安装 Op…...

Python编程-使用urllib进行网络爬虫常用内容梳理
Python编程-使用urllib进行网络爬虫常用内容梳理 使用urllib库进行基础网络请求 使用request发起网络请求 from urllib import request from http.client import HTTPResponseresponse: HTTPResponse request.urlopen(url"http://pkc/vul/sqli/sqli_str.php") pr…...
01 Redis的特性+下载安装启动+Redis自动启动+客户端连接
1.1 NoSQL NoSQL(“non-relational”, “Not Only SQL”),泛指非关系型的数据库。 键值存储数据库 : 就像 Map 一样的 key-value 对。如Redis文档数据库 : NoSQL 与关系型数据的结合,最像关系…...

C++发起Https请求
Wininet库忽略Https证书 相信很多朋友使用C WINAPI开发的时候网络模块的时候遇到Https忽悠证书无效的情况下, 仍然希望获取结果下列代码便是忽略异常的Https CA证书,下面对原理进行简单的讲解首先, 需要设置Https忽略需要用到如下结果函数与参数Interne…...
哪款笔记软件支持电脑和手机互通数据?
上班族在日常工作中,随手记录工作笔记已成为司空见惯的场景。例如:从快节奏的会议记录到灵感迸发的创意;跟踪项目进展,记录每个阶段的成果、问题和下一步计划;记录、更新工作任务清单等,工作笔记承载了职场…...
部署PXE高效批量网络装机
部署PXE高效批量网络装机 因在Cisco3850核心交换机中已开启DHCP 服务,因此不需要在配置DHCP服务。如果您的网络环境中也已有DHCP服务,也不用再配置DHCP服务了,直接部署PXE相关服务即可。 找一台linux系统的服务器,这本次试验用的是…...
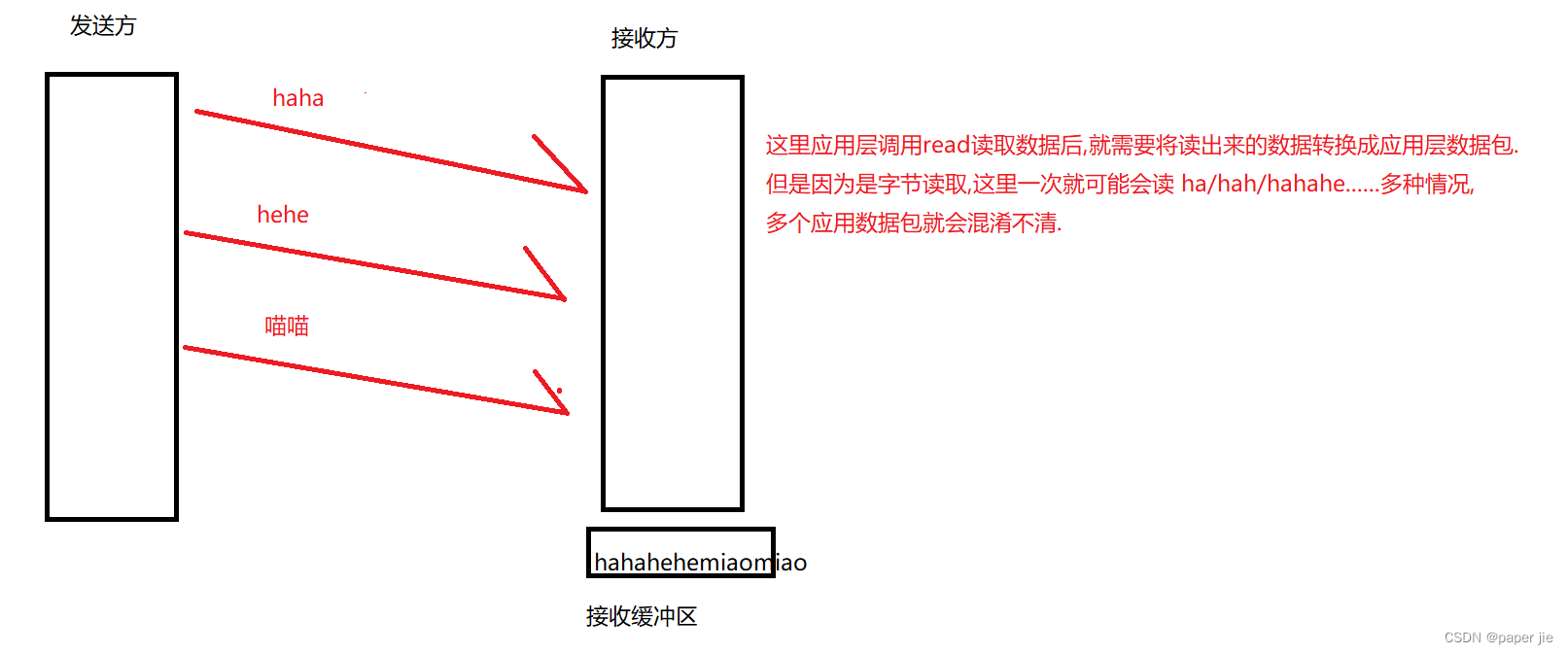
【JavaEE】UDP协议与TCP协议
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文于《JavaEE》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&…...

Leetcode—1828. 统计一个圆中点的数目【中等】
2024每日刷题(一零五) Leetcode—1828. 统计一个圆中点的数目 实现代码 class Solution { public:vector<int> countPoints(vector<vector<int>>& points, vector<vector<int>>& queries) {vector<int> a…...
)
新概念英语第二册(47)
New words and expressions】生词和短语(9) thirsty adj. 贪杯的 ghost n. 鬼魂 haunt v. (鬼)来访,闹鬼 block …...
抽象类(Java)、模板方法设计模式
一、概念 在Java中有abstract关键字,就是抽象的意思,可用来修饰类和成员方法。 用abstract来修饰类,那这个类就是抽象类;修饰方法,那这个方法就是抽象方法。 修饰符 abstract class 类名{修饰符 abstract 返回值类型…...

【Delphi】IDE 工具栏错乱恢复
由于经常会在4K和2K显示器上切换Delphi开发环境(IDE),导致IDE工具栏错乱,咋样设置都无法恢复,后来看到红鱼儿的博客,说是通过操作注册表的方法,能解决,试了一下,果真好用,非常感谢分…...
)
自动化报告的前奏|使用python-pptx操作PPT(一)
自动化报告先从python-pptx开始 文章目录 1 python-pptx的基础属性1.1 新建幻灯片1.1.1 幻灯片布局的样式1.1.2 修改pptx模版大小1.1.3 指定模版生成1.1.4 创建幻灯片背景1.1.5 创建幻灯片备注信息1.1.6 设置幻灯片标题1.2 一些ppt元素/组件1.2.1 特殊符号1.2.2 placeholders1.…...

2024美赛数学建模D题思路+代码
文章目录 1 赛题思路2 美赛比赛日期和时间3 赛题类型4 美赛常见数模问题5 建模资料 1 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 2 美赛比赛日期和时间 比赛开始时间:北京时间2024年2月2日(周五ÿ…...

告别ibus!Ubuntu 22.04 LTS下Fcitx5+搜狗输入法保姆级配置指南
Ubuntu 22.04 LTS 现代化输入方案:Fcitx5与搜狗输入法深度整合指南在Linux桌面环境中,输入法配置一直是中文用户面临的经典难题。Ubuntu 22.04 LTS作为长期支持版本,其默认的IBus框架对中文输入的支持始终差强人意。本文将带你探索更先进的解…...

3D层析SAR与AutoML融合:实现高精度森林树种自动识别
1. 项目概述:当3D雷达“透视”森林,机器学习如何识别每一棵树?在森林资源管理与生态研究中,准确识别树种一直是个既基础又棘手的难题。传统的野外调查方法,依赖人力跋山涉水,不仅成本高昂、效率低下&#x…...

混沌时间序列预测:轻量级方法为何完胜复杂深度学习模型?
1. 项目概述与核心洞察在时间序列预测这个领域,尤其是在处理像洛伦兹系统这样的低维混沌动力系统时,我们常常会陷入一个思维定式:模型越复杂、参数越多、计算量越大,预测效果就应该越好。这个想法很自然,毕竟深度学习在…...

洛谷 B4361:[GESP202506 四级] 排序
【题目来源】 https://www.luogu.com.cn/problem/B4361 【题目描述】 体育课上有 n 名同学排成一队,从前往后数第 i 位同学的身高为 hi,体重为 wi。目前排成的队伍看起来参差不齐,老师希望同学们能按照身高从高到低的顺序排队,…...

AI系列【仅供参考】:TRAE 支持自定义模型了,配置个 DeepSeek V4 试试
TRAE 支持自定义模型了,配置个 DeepSeek V4 试试TRAE 支持自定义模型了,配置个 DeepSeek V4 试试原因解决方案底下评论问题一:回答一:回答二:回答三:问题二:回答一:问题三࿱…...

终极指南:无需微软账户离线启用Windows Insider预览计划的完整方案
终极指南:无需微软账户离线启用Windows Insider预览计划的完整方案 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: http…...

解决Claude Code密钥被封与Token不足的替代接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code密钥被封与Token不足的替代接入方案 对于频繁使用Claude Code编程助手的开发者而言,开发流程中突然遇到…...

Triton+KServe构建高可用ML模型服务的七道关卡
1. 项目概述:这不是一次“部署”,而是一场从实验室到产线的系统性迁移“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题里藏着太多被轻描淡写却重若千钧的词。“Notebook”不是指纸质本子,而是Jupyter里…...

一键搞定B站视频下载:跨平台工具BilibiliDown完整使用指南
一键搞定B站视频下载:跨平台工具BilibiliDown完整使用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirro…...

告别RGB!用HSL颜色空间在STM32上做颜色识别,为什么更准?附OV7725实战代码与调参心得
HSL颜色空间在嵌入式视觉中的实战优势:基于STM32与OV7725的鲁棒识别方案 当我们在嵌入式设备上实现颜色识别时,光照变化总是最令人头疼的问题之一。早晨、中午和傍晚的光线差异,阴影的干扰,甚至是LED频闪带来的影响,都…...