Spark调优总结
下面是基于官方优化建议,加上自己的一些理解整理。官方地址:https://spark.apache.org/docs/2.4.8/tuning.html
任务并行度
Spark会根据每个文件的大小自动设置运行“map”任务的数量,而对于分布式的“reduce”操作,例如groupByKey和reduceByKey,它使用最大的父RDD分区数,我们也可以为这些算子提供其分区数的参数值或者设置spark.default.parallelism参数,推荐是CPU的2-3倍任务数。增加Reduce任务的并行度(sortByKey, groupByKey, reduceByKey, join, etc),减少每一个任务处理的数据集的规模,Spark可以200ms内完成一个任务的计算,因为spark支持重用executor的JVM,并且每个任务的消耗也很低,所以可以放心增加任务数。
默认的并行度:spark.default.parallelism
在SQL中动态修改分区数:SET spark.sql.shuffle.partitions = 2;
Map端过滤
- 利用广播变量把Driver的大对象广播到每一个executor端,构造一个静态表,实现map端join。
- 使用Map端预处理的算子,比如RDD的reduceByKey、aggregateByKey、foldByKey、combineByKey都是用了map side combine。而groupByKey却不能使用map side combine,因为即使groupByKey实现了map side combine也不会减少shuffle的数据量,最终还是需要将所有的map side数据插入到哈希表中,从而导致老年代中有更多的对象,甚至OutOfMemoryError。
当需要把结果收集到driver端时,先filter多余的行->再去除不需要的列->如果有必要再distinct->再collect
缓存和缓存级别
whether to use memory, or ExternalBlockStore,
whether to drop the RDD to disk if it falls out of memory or ExternalBlockStore,
whether to keep the data in memory in a serialized format,
and whether to replicate the RDD partitions on multiple nodes.
class StorageLevel private(private var _useDisk: Boolean,private var _useMemory: Boolean,private var _useOffHeap: Boolean,private var _deserialized: Boolean,private var _replication: Int = 1) extends Externalizableobject StorageLevel {val NONE = new StorageLevel(false, false, false, false)val DISK_ONLY = new StorageLevel(true, false, false, false)val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)val MEMORY_ONLY = new StorageLevel(false, true, false, true)val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
普通的cache等同于persist(Storage.MEMORY_ONLY),在内存不足时数据会被驱逐,下次使用时需要重算,所以建议使用persist(Storage.MEMORY_AND_DISK_SER)。
缓存数据压缩
SparkSQL使用spark.catalog.cacheTable(“tableName”)或者dataFrame.cache()可以使用内存中的列存储格式。SparkSQL只扫描请求的列并自动调节最小压缩和GC压力之间的平衡。
| spark.sql.inMemoryColumnarStorage.compressed | 默认true | When set to true Spark SQL will automatically select a compression codec for each column based on statistics of the data. |
| spark.sql.inMemoryColumnarStorage.batchSize | 默认10000 | Controls the size of batches for columnar caching. Larger batch sizes can improve memory utilization and compression, but risk OOMs when caching data. |
使用checkpoint截断logical plan
checkpoint两个应用:
- 对RDD做checkpoint切断做checkpoint RDD的依赖关系(在计划特别大的时候非常有用),将RDD数据保存到可靠存储(如HDFS)以便数据恢复;
- 是应用在spark streaming中,使用checkpoint用来保存DStreamGraph以及相关配置信息,以便在Driver崩溃重启的时候能够接着之前进度继续进行处理(如之前waiting batch的job会在重启后继续处理)。
在RDD上做checkpoint和在DF或者DS上做checkpoint有些区别,后两者会返回一个新的数据集。默认checkpoint是lazy的,但我们默认在DF或者DS上使用的是checkpoint(eager = true, reliableCheckpoint = true),会立即执行(其内部是通过调用ds的rdd的count方法实现)。checkpoint的过程:首先是拷贝现有的RDD,对新的RDD进行checkpoint(也就是存储到本地),然后生成一个新的DS返回,这样就切断了依赖。所以后续算子都会基于新的RDD计算,那么还有必要先对原有RDD缓存吗?另外注意,checkpoint到本地的rdd文件只能用于spark恢复,不能直接被后续的算子利用。
A RDD can be recovered from a checkpoint files using SparkContext.checkpointFile. You can use SparkSession.internalCreateDataFrame method to (re)create the DataFrame from the RDD of internal binary rows.
数据本地化级别(数据和代码的位置关系)
数据存储和计算分离可以方便系统的横向扩展,但当计算数据的时候往往需要把数据网路传输到计算节点带来网络耗时。所以Spark更喜欢存算不分离的方式。这就是数据本地化,有以下几个级别:
- PROCESS_LOCAL(相同JVM)
- NODE_LOCAL(同节点不同JVM)
- NO_PREF(没有偏好)
- RACK_LOCAL(同机架)
- ANY (网络上并且不同机架)
通常,为了高效,需要将序列化代码从一个地方传送到另一个地方比将数据块传送到另一个地方,因为代码的大小比数据小得多,这都是spark的任务调度来完成的。当数据和代码在不同的节点时,Spark通常所做的是等待一段时间,希望数据所处的executor有任务结束腾出资源从而调度新的任务。一旦超时到期,它就开始将数据从远处移动到空闲CPU,比如在同节点的不同executor间移动数据。每个级别之间的回退等待超时可以单独配置。
堆内内存优化
在spark1.6版本之前就是用的静态内存模型。静态模型就是把一个Executor分成三个部分,一部分是Storage内存区域,一部分是Execution区域,还有一部分是其他区域。在spark的configuration中默认的有以下参数控制。
(旧版)spark.storage.memoryFraction: 默认0.6,用于缓存和广播变量。
(旧版)spark.shuffle.memoryFraction: 默认0.2,用于Execution。
在spark2.0版本之后,spark新增加一种模型,就是统一动态模型。Spark内存结构分为:默认是(JVM的堆空间 - 300MB)*60%作为Spark的内存,40%用于存储Spark的用户数据结构和Spark的内部元数据。该比例由spark.memory.fraction参数控制。
Spark内存又默认五五分为execution内存和storage内存,execution内存用于Shuffle\joins\sorts\aggregations算子使用,而storage内存用于在集群间缓存和传播内部数据,storage内存是不会被占用的,通过spark.memory.storageFraction参数控制。
这种设计确保了几个理想的性能。 首先,不使用缓存的应用程序可以使用整个执行空间,从而避免不必要的磁盘溢出。 其次,使用缓存的应用程序可以保留最小的存储空间®,使其数据块不会被移除。
需要注意,因为动态占用机制,Spark UI上的storage memory是execution+storage的内存,另外还包含了堆外内存,即其值等于 (spark.executor.memory - 300M) * spark.memory.fraction + 堆外内存
堆外内存优化
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 1.6 引入了堆外(Off-heap)内存,即JVM之外,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。 这种模式不在 JVM 内申请内存,而是调用 Java 的 unsafe 相关 API 进行诸如 C 语言里面的 malloc() 直接向操作系统申请内存,由于这种方式不经过 JVM 内存管理,所以可以避免频繁的 GC,这种内存申请的缺点是必须自己编写内存申请和释放的逻辑。如果堆外内存被启动,堆外内存也会存在execution和storage内容,和On-heap中的execution和storage内存不同的是,前者不会被JVM的GC回收。
| spark.driver.memoryOverhead | driverMemory * 0.10, with minimum of 384 | The amount of off-heap memory to be allocated per driver in cluster mode, in MiB unless otherwise specified. This is memory that accounts for things like VM overheads, interned strings, other native overheads, etc. This tends to grow with the container size (typically 6-10%). This option is currently supported on YARN and Kubernetes. 相当于spark.memory.offHeap.enabled+spark.memory.offHeap.size,只是该参数用于告知YARN和K8S来分配内存,和spark.memory.offHeap.size同时使用时需要比其大。 |
| spark.executor.memoryOverhead | executorMemory * 0.10, with minimum of 384 | The amount of off-heap memory to be allocated per executor, in MiB unless otherwise specified. This is memory that accounts for things like VM overheads, interned strings, other native overheads, etc. This tends to grow with the executor size (typically 6-10%). This option is currently supported on YARN and Kubernetes. |
| spark.memory.offHeap.enabled | false | If true, Spark will attempt to use off-heap memory for certain operations. If off-heap memory use is enabled, then spark.memory.offHeap.size must be positive. |
| spark.memory.offHeap.size | 0 | The absolute amount of memory in bytes which can be used for off-heap allocation. This setting has no impact on heap memory usage, so if your executors’ total memory consumption must fit within some hard limit then be sure to shrink your JVM heap size accordingly. This must be set to a positive value when spark.memory.offHeap.enabled=true. |
Join Strategy Hints
BROADCAST, MERGE, SHUFFLE_HASH and SHUFFLE_REPLICATE_NL,
当使用BROADCAST hint在表t1上时,即使t1表的大小超过了spark.sql.autoBroadcastJoinThreshold,Spark也会也会优先考虑把t1作为build side。至于是broadcast hash join 或者broadcast nested loop join要取决于是否有等值连接条件。
当不同的join策略hint用于join两边时,Spark使用hint的优先级是BROADCAST>MERGE>SHUFFLE_HASH>SHUFFLE_REPLICATE_NL。当两端都指定BROADCAST hint或者SHUFFLE_HASH hint时,Spark将根据join的类型和表的大小来选择build side。注意,Spark不保证一定会使用指定的hint,因为某些join策略hint可能不支持所有join类型。
spark.table("src").join(spark.table("records").hint("broadcast"), "key").show()
Join Hints也可以用于SparkSQL
- BROADCAST的别名为BROADCASTJOIN 、MAPJOIN.
- MERGE,Suggests that Spark use shuffle sort merge join. The aliases for MERGE are SHUFFLE_MERGE and MERGEJOIN.
- SHUFFLE_HASH,Suggests that Spark use shuffle hash join. If both sides have the shuffle hash hints, Spark chooses the smaller side (based on stats) as the build side.Hash Join的第一步就是根据两表之中较小的那一个构建哈希表,这个小表就叫做build table,大表则称为probe table,因为需要拿小表形成的哈希表来"探测"它
SHUFFLE_REPLICATE_NL,Suggests that Spark use shuffle-and-replicate nested loop join. - Broadcast Join(大表和小表),被广播的表需要小于 spark.sql.autoBroadcastJoinThreshold 所配置的值,默认是10M (或者加了broadcast join的hint);基表不能被广播,比如 left outer join 时,只能广播右表。因为被广播的表首先被collect到driver段,然后被冗余分发到每个executor上,所以当表比较大时,采用broadcast join会对driver端和executor端造成较大的压力。
- Sort Merge Join(大表对大表),将两张表按照join keys进行了重新shuffle,保证join keys值相同的记录会被分在相应的分区。分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接。因为两个序列都是有序的,从头遍历,碰到key相同的就输出;如果不同,左边小就继续取左边,反之取右边(即用即取即丢)
Partitioning Hints
COALESCE, REPARTITION, and REPARTITION_BY_RANGE
SELECT /*+ COALESCE(3) */ * FROM t;
SELECT /*+ REPARTITION(3) */ * FROM t;
SELECT /*+ REPARTITION(c) */ * FROM t;
SELECT /*+ REPARTITION(3, c) */ * FROM t;
SELECT /*+ REPARTITION_BY_RANGE(c) */ * FROM t;
SELECT /*+ REPARTITION_BY_RANGE(3, c) */ * FROM t;
EXPLAIN EXTENDED SELECT /*+ REPARTITION(100), COALESCE(500), REPARTITION_BY_RANGE(3, c) */ * FROM t;
GC优化
堆和栈都是Java用来在RAM中存放数据的地方。
堆:
- Java的堆是一个运行时数据区,类的对象从堆中分配空间。这些对象通过new等指令建立,通过垃圾回收器来销毁。
- 堆的优势是可以动态地分配内存空间,需要多少内存空间不必事先告诉编译器,因为它是在运行时动态分配的。但缺点是,由于需要在运行时动态分配内存,所以存取速度较慢。
栈: - 栈中主要存放一些基本数据类型的变量(byte,short,int,long,float,double,boolean,char)和对象的引用。
- 栈的优势是,存取速度比堆快,栈数据可以共享(重用)。但是缺点时,栈空间中的数据大小和生存期必须是确定的,缺乏灵活性。栈主要存放一些基本类型的变量int, short, long, byte, float, double, boolean, char和对象句柄。对于局部变量,如果是基本类型,会把值直接存储在栈;如果是引用类型,比如String s = new String(“william”);会把其对象存储在堆,而把这个对象的引用(指针)存储在栈。
堆和栈的区别: - 最主要的区别就是堆内存用来存储Java中的对象,无论是成员变量,局部变量,还是类变量,它们指向的对象都存储在堆内存中。栈内存用来存储局部变量和方法调用。栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见,即栈内存可以理解成线程的私有内存。而堆内存中的对象对所有线程可见和访问。
- 如果是堆内存没有可用的空间存储生成的对象,JVM会抛出java.lang.OutOfMemoryError。如果栈内存没有可用的空间存储方法调用和局部变量,JVM会抛出java.lang.StackOverFlowError。
- 堆内存远大于栈的内存,如果你使用递归的话,那么你的栈很快就会充满,很可能发生StackOverFlowError问题。
- 我们通过-Xms选项可以设置堆的初始时的大小,-Xmx选项可以设置堆的最大值。通过-Xss选项设置栈内存的大小。
JVM的GC日志的主要参数包括如下几个:
- -XX:+PrintGC 输出GC日志
- -XX:+PrintGCDetails 输出GC的详细日志
- -XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
- -XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
- -XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
- -Xloggc:…/logs/gc.log 日志文件的输出路径
在较高的层次上,管理全GC发生的频率可以帮助减少开销,可以通过在作业的配置中设置spark.executor.extraJavaOptions来指定执行器的GC调优标志。通过在Java选项中添加-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps来实现,Spark会在executor端控制台日志中打印的消息。当您的程序存储的rdd有很大的“变动”时,JVM垃圾收集可能会成为一个问题。 (对于只读取一次RDD,然后在其上运行多次操作的程序来说,这通常不是问题。) 当Java需要清除旧对象来为新对象腾出空间时,它将需要跟踪所有Java对象并找到未使用的对象。 这里需要记住的要点是,垃圾收集的成本与Java对象的数量成比例,因此使用对象较少的数据结构(例如,使用int数组而不是LinkedList)会大大降低此成本。 一个更好的方法是以序列化的形式持久化对象,如上所述:现在每个RDD分区只有一个对象(一个字节数组)。 在尝试其他技术之前,如果GC存在问题,首先要尝试的是使用序列化缓存。
JAVA堆内部划分为年轻代和老年代,年轻代存储短生命周期的对象,而老年代存储长生命周期的对象。年轻一代被进一步划分为三个区域: Eden, Survivor1, Survivor2。GC的过程:当Eden满时,会在Eden上运行一个minor GC,并将来自Eden和Survivor1的活对象复制到Survivor2。交换Survivor区域。如果一个对象足够老或Survivor2已满,则将其移动到老年代。 最后,当老年代接近满时将调用一个完整的GC。
Runtime.getRuntime.maxMemory 是程序能够使用的最大内存,其值会比实际配置的执行器内存的值小。这是因为内存分配池的堆部分分为 Eden,Survivor 和 Tenured 三部分空间,而这里面一共包含了两个 Survivor 区域,而这两个 Survivor 区域在任何时候我们只能用到其中一个,所以我们可以使用下面的公式进行描述:
ExecutorMemory = Eden + 2 * Survivor + Tenured
Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured
Spark中GC调优的目标是确保只有长寿命的rdd存储在Old代中,而Young代的大小足以存储短寿命的对象。 这将有助于避免完整的gc收集任务执行期间创建的临时对象。 一些可能有用的步骤是:
- 通过收集GC统计信息来检查垃圾收集是否过多。 如果在任务完成之前多次调用全GC,则意味着没有足够的内存可用来执行任务。
- 如果minor collections太多而major gc不多,那么为Eden分配更多的内存会有所帮助。 您可以将Eden的大小设置为每个任务所需内存的高估值。 如果Eden的大小被确定为E,那么您可以使用选项-Xmn=4/3*E设置Young代的大小。 (扩大4/3也是为了考虑survivor 区域所使用的空间。-XX:SurvivorRatio的值默认为8,代表Survivor和Eden的比例为1:8,而两个Survivor:Eden就是2:8,所以Eden占整个年轻代的4/5。
- 在打印的GC统计中,如果OldGen接近满了,可以通过降低spark.memory.fraction来减少用于缓存的内存数量,因为降低数据缓存比降低任务执行速度要好。 或者考虑减少年轻代的大小。 这意味着如果您将-Xmn设置为上面的值则降低-Xmn,如果没有请尝试更改JVM的NewRatio参数的值。-XX:NewRatio的值默认为2,代表年轻代和老年代的比值是1:2,即老年代占堆内存的2/3。它应该足够大,以至于这个分数超过spark.memory.fraction。
- 尝试使用-XX:+UseG1GC的G1GC垃圾收集器。 在垃圾收集成为瓶颈的某些情况下,它可以提高性能。 注意,对于较大的执行器堆大小,使用-XX:G1HeapRegionSize增加G1区域大小可能很重要
- 例如,如果您的任务正在从HDFS读取数据,则可以通过从HDFS读取的数据块大小来估计任务占用的内存大小。 请注意,解压后的块的大小通常是块大小的2到3倍。 因此,如果我们希望有3或4个任务的工作空间,而HDFS的块大小是128MB,我们可以估计Eden的大小为43128MB。
mapPartition替换map
可以重复利用变量,减少重复定义变量对资源的消耗
相关文章:

Spark调优总结
下面是基于官方优化建议,加上自己的一些理解整理。官方地址:https://spark.apache.org/docs/2.4.8/tuning.html 任务并行度 Spark会根据每个文件的大小自动设置运行“map”任务的数量,而对于分布式的“reduce”操作,例如groupBy…...
4.创建和加入通道相关(network.sh脚本createChannel函数分析)[fabric2.2]
fabric的test-network例子有一个orderer组织、两个peer组织、每个组织一个节点,只有系统通道(system-channel),没有其他应用通道。我们可以使用./network.sh createChannel命令来创建一个名为mychannel的应用通道。 一、主要概念 …...
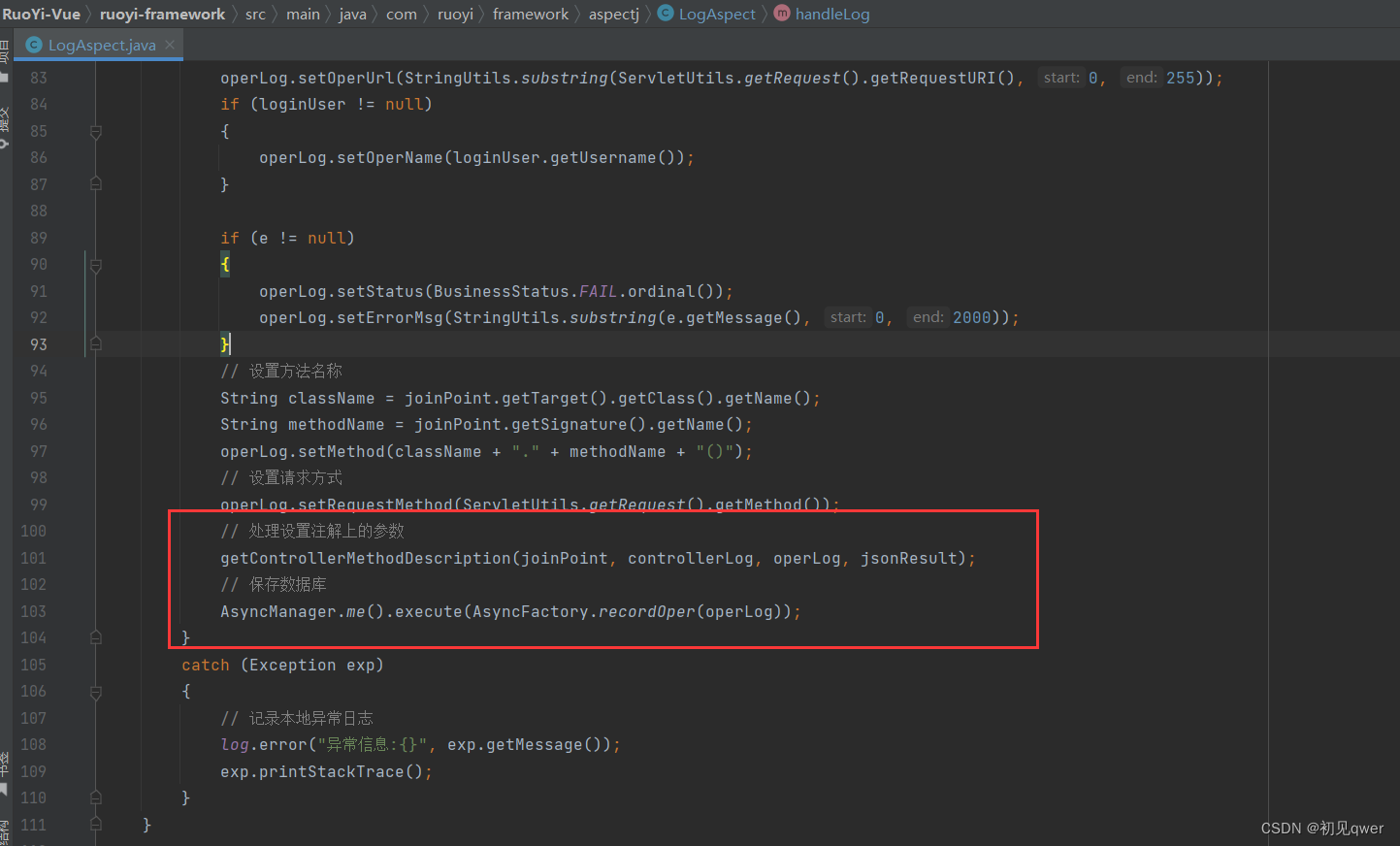
若依学习(前后端分离版)——自定义注解@Log(如何自定义注解,实现aop)
如何自定义注解 aop的基本知识与应用 若依对用户的一些更新删除等敏感操作操作进行了日志记录 注解定义和切面处理的项目位置 第一步:自定义注解log 定义了注解的相关信息。这里定义的属性可以在使用时加以定义 注解Target和Retention的作用 第二步切面逻辑…...

防止暴力破解ssh的四种方法
一. 方法介绍 防止暴力破解的四种方法: 1 密码要写的足够的复杂,通常建议将密码写16位,并且无连贯的数字或者字母;当然也可以固定一个时间修改一次密码,推荐是一个月修改一次会稳妥一些2 修改ssh的端口号,…...
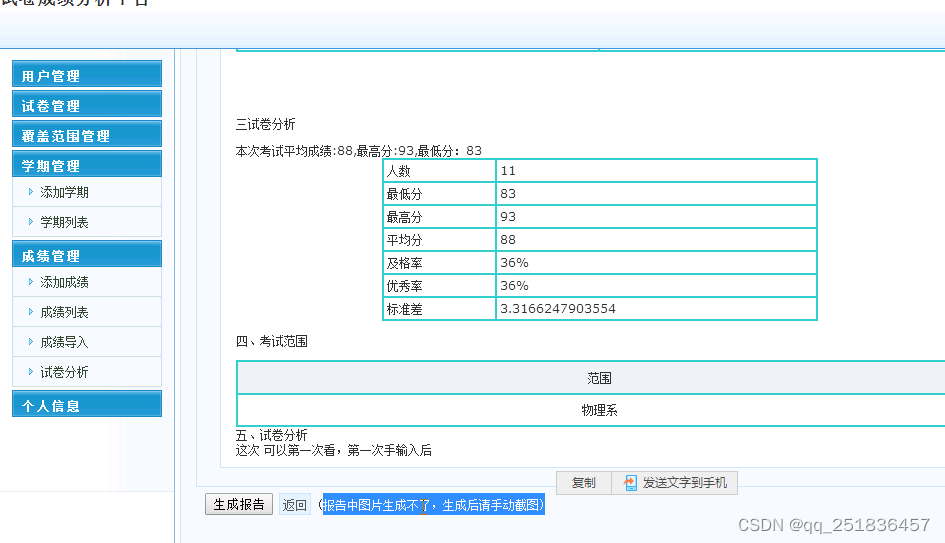
jsp试卷分析管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 JSP试卷分析管理系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql5.0&…...
可选链运算符(?.)与空值合并运算符(??)
1. 可选链运算符Optional chaining(?.) MDN定义 可选链运算符(?.)允许读取位于连接对象链深处的属性的值,而不必明确验证链中的每个引用是否有效。?. 运算符的功能类似于 . 链式运算符,不同之处在于,在引用为空 (n…...

JavaScript 闭包
JavaScript 变量可以是局部变量或全局变量。私有变量可以用到闭包。全局变量函数可以访问函数内部定义的变量,如:实例function myFunction() {var a 4;return a * a;}尝试一下 函数也可以访问函数外部定义的变量,如:实例var a 4…...

每日记录自己的Android项目(二)—Viewbinding,WebView,Navigation
今日想法今天是想把做一个跳转页面的时候调到H5页面去,但是这个页面我用app来承载,不要调到浏览器去。所以用到了下方三个东西。Viewbindingbuild.gradle配置首先在app模块的build.gradle里添加一下代码默认情况下,每一个布局xml文件都会生成…...

20230305英语学习
Climate Change Is Suffocating Large Parts of the Ocean 研究:气候变化正在使海洋“缺氧” One day more than a decade ago, Eric Prince was studying the tracks of tagged fish when he noticed something odd.Blue marlin off the southeastern United State…...
【Linux】手把手教你在CentOS上使用docker 安装MySQL8.0
文章目录前言一. docker的安装1.1 从阿里下载repo镜像1.2 安装docker1.3 启动docker并查看版本二. 使用docker安装MySQL8.02.1 拉取MySQL镜像2.2 创建容器2.3 操作MySQL容器2.4 远程登录测试总结前言 大家好,又见面了,我是沐风晓月,本文主要…...

论文解读:High Dynamic Range and Super-Resolution from Raw Image Bursts
论文解读:High Dynamic Range and Super-Resolution from Raw Image Bursts 今天介绍一篇发表于 2022 年 ACM Tranaction on Graphic 上的文章,这篇文章通过多帧曝光将 HDR 与 SR 放在一起解决,与一般的文章不同的地方在于,这篇文…...
国内的PMP考试通过率高达97%?
自认为是虚高,虽然国人在考试方面的确独树一帜的强,应该也没有这样夸张。 如果自学,大概是50%,如果有老师教,那大概是60%到80%,还是比较高的。 为什么自学那么低?除了自身的自制力的问题&…...

IOC(概念和原理)
文章目录1. IOC容器概念2. IOC底层原理3. IOC(接口)4. IOC操作Bean管理(概念)5. IOC操作Bean管理(基于xml方式)5.1 基于xml创建对象5.2 基于xml方式注入属性5.2.1 DI:依赖注入,就是注…...

操作系统 - 第二章
一、进程的定义、组成、组织、特征 一、进程的定义 从不同的角度,进程有不同的定义 1、进程是程序的一次执行过程; 2、进程是一个程序及其数据在处理机上顺序执行时所发生的活动; 3、进程是具有独立功能的程序在数据集合上运行的过程…...

进程控制~
进程控制 (创建、终止,等待,程序替换) 进程创建: pid_t fork();父子进程,数据独有,代码共享,各有各的地址 pit_t vfork();父进程阻塞,直到子进程exit退出或者程序替换之…...
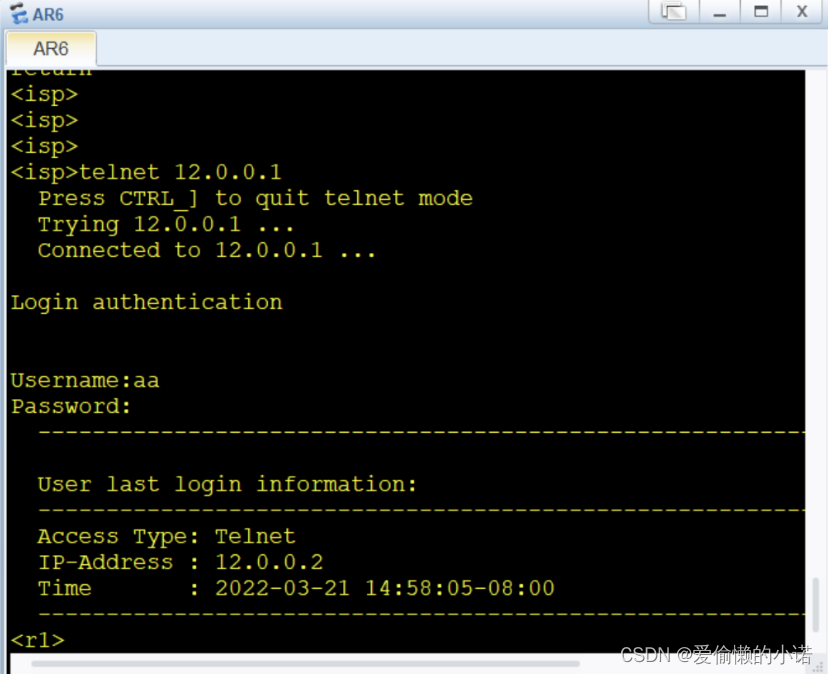
HCIP第一个实验
实验要求与实验拓扑子网划分分析将骨干链路看成一个整体,路由器后的2个环回地址先看成一个,最后再进行拆分。计算得出,一共需要划分为6个子网段,取三位。再将每一条网段,按照题目要求进行划分最后完成子网划分。子网划…...
)
阿里云轻量服务器--Docker--dubbo-admin安装(连接zookeeper nacos)
前言:当使用dubbo 作为微服务的接口调用,在dubbo 注册到zookeeper 或者nacos 中时 可以安装dubbo-admin 作为服务的监测; 1 Dubbo Admin 介绍: Dubbo 框架提供了丰富的服务治理功能如流量控制、动态配置、服务 Mock、服务测试等…...

树莓派Pico W无线WiFi开发板使用方法及MicroPython编程实践
树莓派Pico W开发板是树莓派基金会于2022年6月底推出的一款无线WiFi开发板,它支持C/C和MicroPython编程。本文介绍树莓派Pico W无线WiFi开发板的使用方法及MicroPython编程示例,包括树莓派Pico W开发板板载LED使用及控制编程示例,Pico W开发板…...
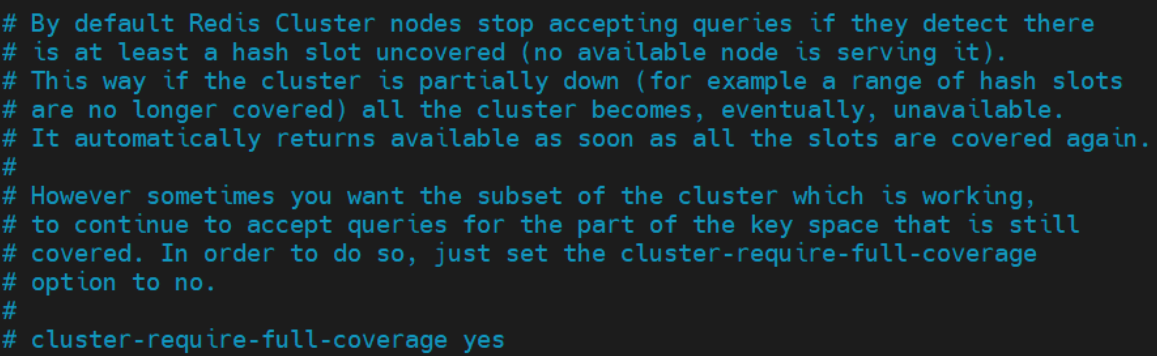
Redis学习【11】之分布式系统
文章目录一 数据分区算法1.1 顺序分区1.1.1 轮询分区算法1.1.2 时间片轮转分区算法1.1.3 数据块分区算法1.1.4 业务主题分区算法1.2 哈希分区1.2.1 节点取模分区算法1.2.2 一致性哈希分区算法1.2.3 虚拟槽分区算法二 分布式系统环境搭建与运行2.1 系统搭建2.1.1 系统架构2.1.2 …...

光速c数列的猜想:光猜
光速c数列的猜想:光猜 2023-03-05 10:26:30 猜测:不同的宇宙光速c并不同 分成等级数列c0,c1,c2,...cn... 地球所处宇宙的真空光速c为c1,其中c0或许假设为光在纯水中速度乎 亦有可能仅有六级对应六道。 宇宙外,容器外也,超过光速c1,为光速c2,可看到容器…...

Laya3D美术进阶:巧用Shader实现APP级游戏效果还原
1. 为什么选择Laya3D的Shader技术? 很多开发者第一次接触Laya3D时,都会有个疑问:为什么不用Unity直接开发?特别是在微信小游戏这个特定场景下,Laya3D的Shader技术到底能带来什么优势?我做了三年Laya小游戏…...

C++vector迭代器失效全解析
深入讲解 C vector 的迭代器失效在 C 中,std::vector 是一个动态数组,它支持随机访问和高效的元素操作。迭代器是 C 中用于遍历容器元素的重要工具,类似于指针。但使用 vector 时,某些操作可能导致迭代器失效(iterator…...

PyTorch 2.8深度学习镜像入门必看:RTX 4090D环境验证与快速上手步骤
PyTorch 2.8深度学习镜像入门必看:RTX 4090D环境验证与快速上手步骤 1. 镜像概述与核心优势 PyTorch 2.8深度学习镜像专为RTX 4090D显卡优化设计,提供开箱即用的深度学习开发环境。这个镜像最显著的特点是免去了复杂的环境配置过程,让开发者…...
到HDR图像合成的完整流程解析)
OpenCV实战:从相机响应函数(CRF)到HDR图像合成的完整流程解析
1. 相机响应函数(CRF)基础解析 第一次听说相机响应函数(CRF)时,我也是一头雾水。简单来说,CRF就是描述相机如何把真实世界的光线强度(L)转换成图像像素值(B)的数学关系。想象一下,你拿着手机对着同一个场景拍三张照片:一张很暗、一…...

intv_ai_mk11部署避坑指南:端口映射失败、响应延迟、乱码重复等问题解决方案
intv_ai_mk11部署避坑指南:端口映射失败、响应延迟、乱码重复等问题解决方案 1. 环境准备与快速部署 1.1 系统要求 操作系统:Ubuntu 20.04/22.04 LTSGPU:NVIDIA显卡(至少16GB显存)内存:32GB以上存储&…...

ISO/SAE 21434:2021 逐条审核判定表
A 章节号|B 条款|C 要求内容|D 符合性|E 证据 / 说明|F:不符合整改项符合性选项:符合 / 部分符合 / 不符合 / 不适用章节号条款审核要求内容符合性证据 / 备注整改项44.1建立网络安全生命周…...

内网外网互传文件慢怎么办?高速传输协议该如何选择?
企业日常办公中,内外网文件互传卡顿、中断、速度不达标的问题十分普遍,尤其在大文件与批量文件场景下,传统方式难以满足稳定高效的需求。选择合适的高速传输方案,直接影响跨网协作效率与数据安全,这也是多数运维与业务…...

深入理解Java AQS:抽象队列同步器的核心原理与实战指南
深入理解Java AQS:抽象队列同步器的核心原理与实战指南 【免费下载链接】JavaGuide Java 面试 & 后端通用面试指南,覆盖计算机基础、数据库、分布式、高并发、系统设计与 AI 应用开发 项目地址: https://gitcode.com/gh_mirrors/ja/JavaGuide …...

CANoe Trace中的Time列:从基础定义到高级时序分析实战
1. CANoe Trace中的Time列基础解析 第一次打开CANoe的Trace窗口时,那排密密麻麻的数据确实让人头皮发麻。但别担心,咱们先来搞定最左边那个看似简单却至关重要的Time列。这个时间戳就像车载网络的"心电图"记录仪,精确到微秒级别地记…...

如何高效保存B站视频?BiliTools全能下载解决方案让你无忧离线观看
如何高效保存B站视频?BiliTools全能下载解决方案让你无忧离线观看 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliT…...