Amazon Bedrock 的微调和持续预训练功能允许用户使用私有数据定制模型
今天我很高兴地宣布,您现在可以在 Amazon Bedrock 中使用自己的数据,安全并私密地定制基础模型(FMs),按照您所在领域、企业和用例的特定要求构建应用程序。借助定制模型,您可以创建独特的用户体验,体现企业的风格、观点和服务。
通过微调,您可以通过私有的特定任务标注训练数据集来提高模型的准确性,进一步使基础模型(FM)专业化。借助持续预训练,您可以在安全的托管环境中使用私有未经标注的数据和客户管理密钥来训练模型。持续预训练有助于模型丰富知识,增强适应性,从而超越原始训练,提高面向特定领域的针对性。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
下面我们来快速浏览一下这两种模型定制选项。您可以使用 Amazon Bedrock 控制台 或 API 创建微调和持续预训练任务。在控制台中,导航至 Amazon Bedrock,然后选择“定制模型”。
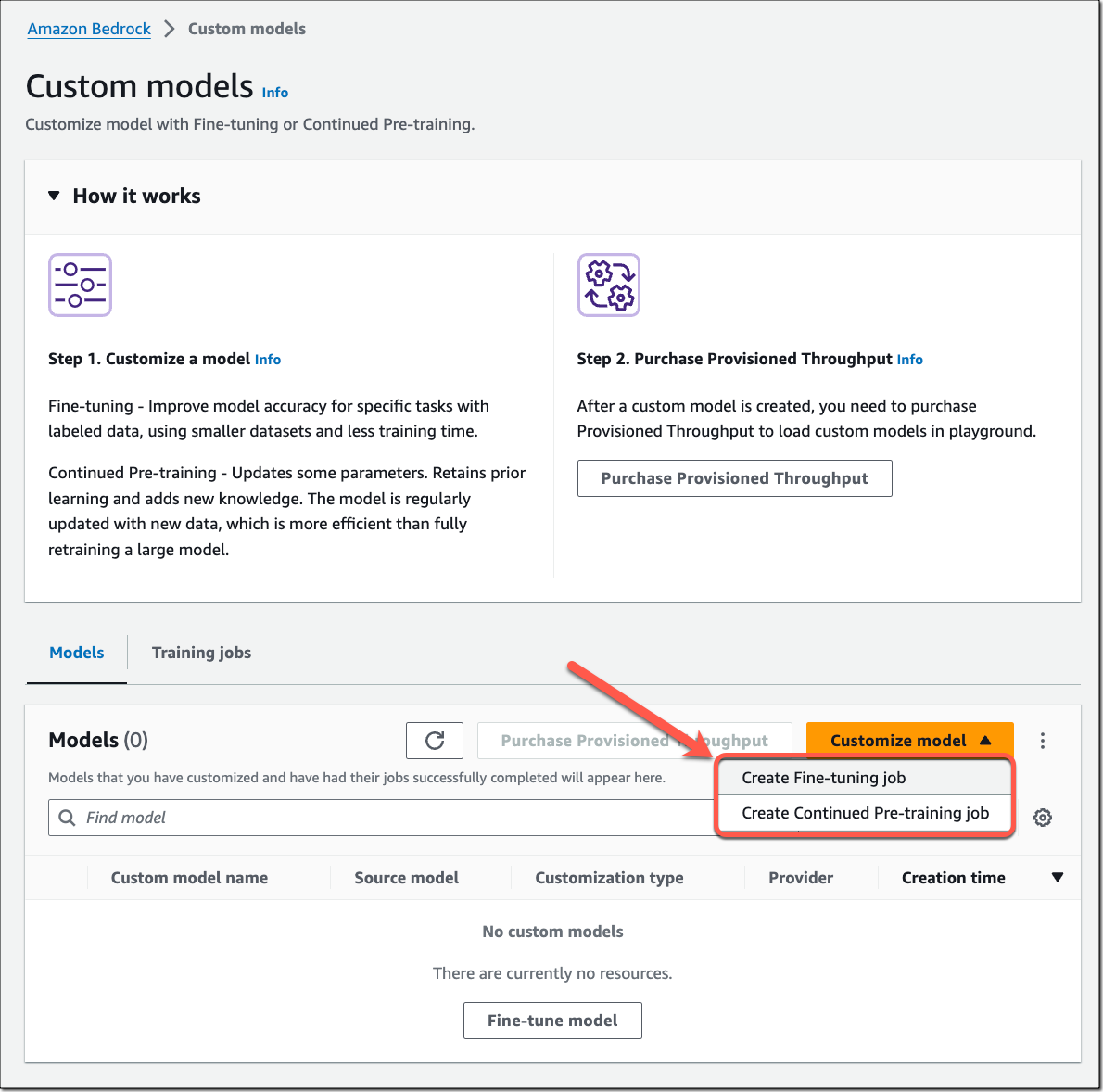
微调 Meta Llama 2、Cohere Command Light、以及 Amazon Titan FMs Amazon Bedrock 现在支持微调 Meta Llama 2、Cohere Command Light 以及 Amazon Titan 模型。要在控制台创建微调任务,选择 “自定义模型”,然后选择“创建微调任务”。
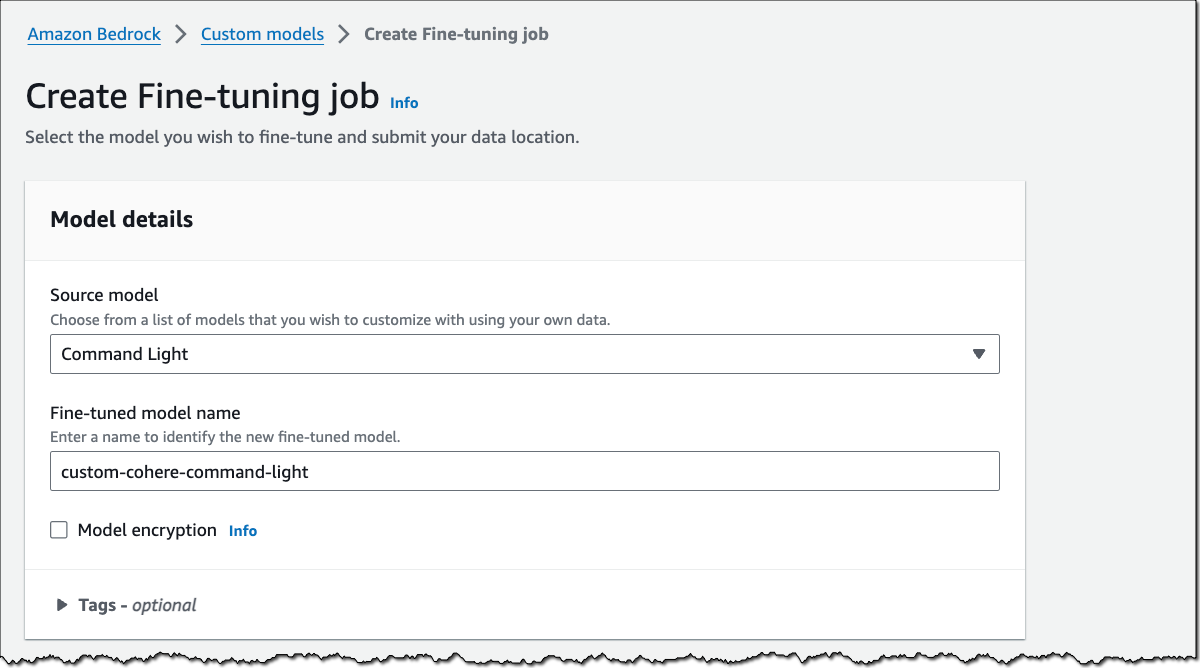
下面是关于使用 Amazon SDK for Python (Boto3) 的快速演示。我们对 Cohere Command Light 进行微调,以汇总对话。因为是演示,所以我使用了公开的 dialogsum 数据集,您也可以选择您所在企业的特定数据。
为了准备在 Amazon Bedrock 上进行微调,我将数据集转换为 JSON Lines 格式,并将其上传到 Amazon S3。每一行 JSON 都需要一个提示字段和一个完成字段。您最多可以指定 10,000 条训练数据记录,但只需几百个示例就能看到模型性能的提升。
{"completion": "Mr. Smith's getting a check-up, and Doctor Haw...", "prompt": Summarize the following conversation.\n\n#Pers..."}{"completion": "Mrs Parker takes Ricky for his vaccines. Dr. P...", "prompt": "Summarize the following conversation.\n\n#Pers..."}{"completion": "#Person1#'s looking for a set of keys and asks...", "prompt": "Summarize the following conversation.\n\n#Pers..."} 为方便起见,我编辑了提示和完成字段。
您可以使用以下命令列出支持微调的可用基础模型:
import boto3 bedrock = boto3.client(service_name="bedrock")bedrock_runtime = boto3.client(service_name="bedrock-runtime")for model in bedrock.list_foundation_models(byCustomizationType="FINE_TUNING")["modelSummaries"]:for key, value in model.items():print(key, ":", value)print("-----\n")接下来,我创建了一个模型定制任务。我指定了支持微调的 Cohere Command Light 模型 ID,将定制类型设为 FINE_TUNING,并指向训练数据的 Amazon S3 位置。如有必要,您还可以调整微调超参数。
# Select the foundation model you want to customizebase_model_id = "cohere.command-light-text-v14:7:4k"bedrock.create_model_customization_job(customizationType="FINE_TUNING",jobName=job_name,customModelName=model_name,roleArn=role,baseModelIdentifier=base_model_id,hyperParameters = {"epochCount": "1","batchSize": "8","learningRate": "0.00001",},trainingDataConfig={"s3Uri": "s3://path/to/train-summarization.jsonl"},outputDataConfig={"s3Uri": "s3://path/to/output"},)# Check for the job statusstatus = bedrock.get_model_customization_job(jobIdentifier=job_name)["status"]完成任务之后,您的自定义模型将收到一个唯一的模型 ID。Amazon Bedrock 将会安全地存储您的微调模型。要测试和部署您的模型,您需要购买 Provisioned Throughput。
我们来看看结果。我从数据集中选择一个示例,请求微调前的基本模型和微调后的自定义模型,总结出以下对话:
prompt = """Summarize the following conversation.\\n\\n#Person1#: Hello. My name is John Sandals, and I've got a reservation.\\n#Person2#: May I see some identification, sir, please?\\n#Person1#: Sure. Here you are.\\n#Person2#: Thank you so much. Have you got a credit card, Mr. Sandals?\\n#Person1#: I sure do. How about American Express?\\n#Person2#: Unfortunately, at the present time we take only MasterCard or VISA.\\n#Person1#: No American Express? Okay, here's my VISA.\\n#Person2#: Thank you, sir. You'll be in room 507, nonsmoking, with a queen-size bed. Do you approve, sir?\\n#Person1#: Yeah, that'll be fine.\\n#Person2#: That's great. This is your key, sir. If you need anything at all, anytime, just dial zero.\\n\\nSummary: """下面是微调前的基本模型响应:
#Person2# 帮助 John Sandals 完成预订。John 提供了他的信用卡信息,而 #Person2# 确认他们只接受万事达和 VISA 卡。John 将入住 507 号房间,如果他有任何需要,将由 #Person2# 提供服务。
下面是微调后的响应,更简短、更切题:
John Sandals 预订了一家酒店并办理了入住手续。#Person2# 拿走了他的信用卡并给了他一把钥匙。
持续预训练支持 Amazon Titan Text (预览版)
Amazon Bedrock 的持续预训练可用于 Amazon Titan Text 模型的公开预览版,包括 Titan Text Express 和 Titan Text Lite。要在控制台创建持续预训练任务,选择“自定义模型”,然后选择“创建持续预训练任务”。
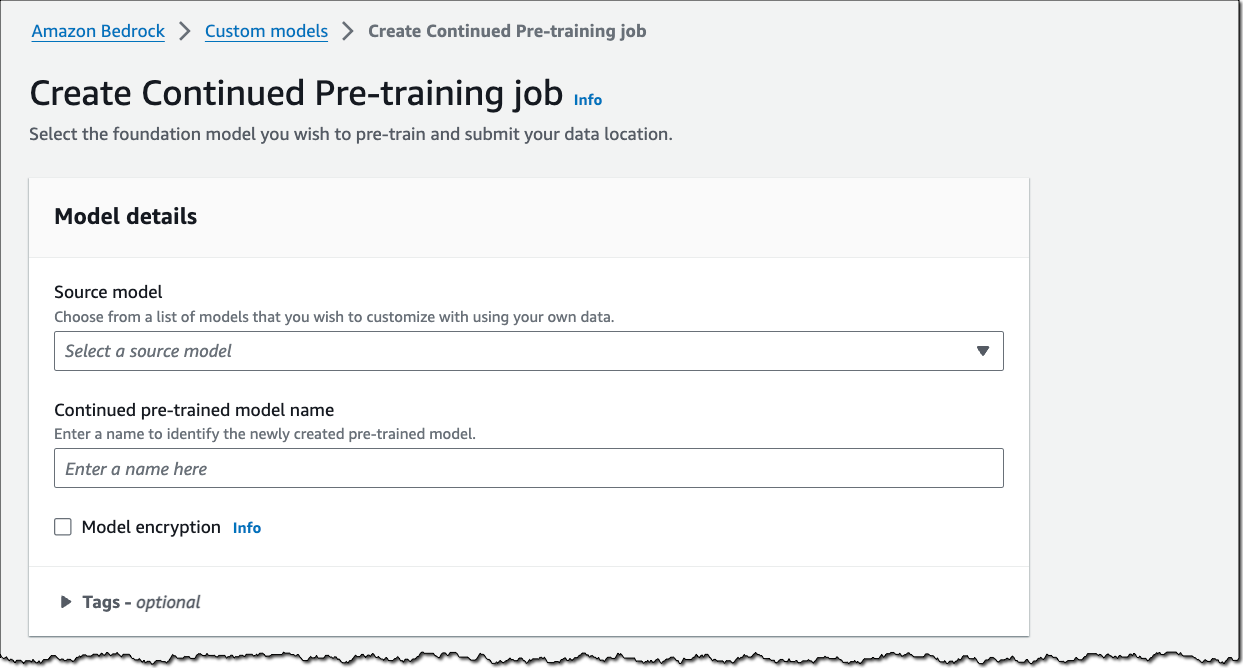
下面还是关于使用 boto3 的快速演示。假设您在一家投资公司工作,希望继续使用财务和分析师报告对模型进行预训练,使其更加了解金融行业术语。因为是演示,所以我选择了一组亚马逊股东信作为训练数据。
为了准备实施预训练,我将数据集转换为 JSON Lines 格式,并将其上传到 Amazon S3。我使用的是未加标注的数据,因此每一行 JSON 仅需提示字段。您最多可以指定 100,000 条训练数据记录,通常最少需要提供 10 亿个令牌才能看到积极效果。
{"input": "Dear shareholders: As I sit down to..."}{"input": "Over the last several months, we to..."}{"input": "work came from optimizing the conne..."}{"input": "of the Amazon shopping experience f..."}为方便起见,我编辑了输入字段。
然后,创建一个模型自定义任务,将定制类型设为指向数据的 CONTINUED_PRE_TRAINING。如有必要,您还可以调整持续预训练超参数。
# Select the foundation model you want to customizebase_model_id = "amazon.titan-text-express-v1"bedrock.create_model_customization_job(customizationType="CONTINUED_PRE_TRAINING",jobName=job_name,customModelName=model_name,roleArn=role,baseModelIdentifier=base_model_id,hyperParameters = {"epochCount": "10","batchSize": "8","learningRate": "0.00001",},trainingDataConfig={"s3Uri": "s3://path/to/train-continued-pretraining.jsonl"},outputDataConfig={"s3Uri": "s3://path/to/output"},)完成任务之后,您将收到一个唯一的模型 ID。还是由 Amazon Bedrock 安全地存储您的自定义模型。和微调一样,要测试和部署您的模型,您需要购买 Provisioned Throughput。
注意事项
下面是一些重要注意事项:
数据隐私和网络安全 —— 借助 Amazon Bedrock,您可以控制自己的数据,并且您的所有输入和自定义内容都是亚马逊云科技账户私有的。您的数据(例如提示、完成情况和微调模型)不会用于改进服务,也绝不会用来和第三方模型提供商共享。您的数据将保留在处理 API 调用的区域。所有数据在传输和静止状态中均进行了加密。您可以使用Amazon PrivateLink 在您的 VPC 和 Amazon Bedrock 之间创建私密连接。
计费 —— Amazon Bedrock 对模型定制、存储和推理收费。模型定制按处理的令牌数量收费,即训练数据集中的令牌数量乘以训练周期数。训练周期是指在微调过程中,对训练数据集的一次完整遍历。您需要每月为每个模型支付模型存储费用。推理是按照每个模型单位使用的预配置吞吐量按小时收费。有关详细定价信息,请参阅 Amazon Bedrock 定价。
定制模型和预配置吞吐量 —— Amazon Bedrock 允许您通过购买预配置吞吐量在自定义模型上运行推理。这种模式可以保证稳定的吞吐量水平,作为交换,您需要承诺使用期限。您可以指定满足应用程序性能需求所需的模型单元数量。在最初评估自定义模型时,您可以按小时购买预配置吞吐量,无需长期承诺。如果没有承诺使用期限,则每个预配置吞吐量仅限使用 1 个模型单元。每个账户最多可创建两个预配置吞吐量。
可用性
支持 Meta Llama 2、Cohere Command Light 和 Amazon Titan Text FM 的微调功能现已在美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)这两个亚马逊云科技区域推出。持续预培训现已在美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)这两个亚马逊云科技区域以公开预览版提供。更多信息,请访问 Amazon Bedrock开发人员体验页面,查阅《用户指南》。
立即开始使用 Amazon Bedrock 自定义您的基础模型!
文章来源:Amazon Bedrock 的微调和持续预训练功能允许用户使用私有数据定制模型
相关文章:
Amazon Bedrock 的微调和持续预训练功能允许用户使用私有数据定制模型
今天我很高兴地宣布,您现在可以在 Amazon Bedrock 中使用自己的数据,安全并私密地定制基础模型(FMs),按照您所在领域、企业和用例的特定要求构建应用程序。借助定制模型,您可以创建独特的用户体验ÿ…...
Pyecharts绘制多种炫酷气泡图
Pyecharts绘制多种炫酷气泡图 引言 数据可视化是数据分析中不可或缺的一环,而Pyecharts作为一款基于Echarts的Python图表库,提供了丰富的图表类型,其中气泡图是一种常用于展示三维数据的炫酷图表。本文将介绍如何使用Pyecharts绘制多种炫酷…...

C# 多线程(2)——线程同步
目录 1 线程不安全2 线程同步方式2.1 简单的阻塞方法2.2 锁2.2.1 Lock使用2.2.2 互斥体Mutex2.2.3 信号量Semaphore2.2.3 轻量级信号量SemaphoreSlim2.2.4 读写锁ReaderWriterLockSlim 2.3 信号同步2.3.1 AutoResetEvent2.3.1.1 AutoResetEvent实现双向信号 2.3.2 ManualResetE…...

Java设计模式【工厂模式】
Java设计模式【工厂模式】 前言 三种工厂模式:简单工厂模式、工厂方法模式、抽象工厂模式; 创建型设计模式封装对象的创建过程,将对象的创建和使用分离开,从而提高代码的可维护性和可扩展性 简单工厂模式 概述:将…...
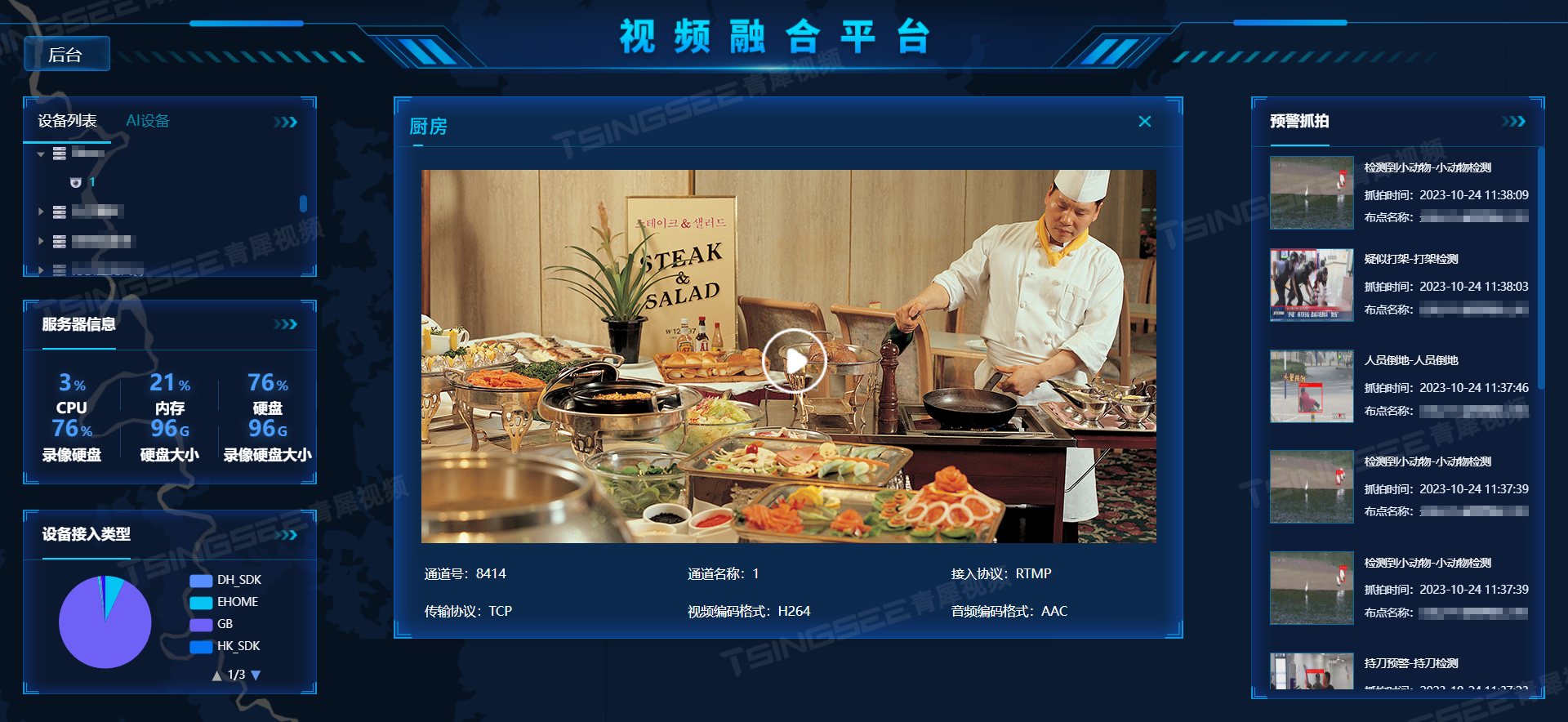
AI智能分析+明厨亮灶智慧管理平台助力“舌尖上的安全”
春节是中国最重要的传统节日之一,在春节期间,人们聚餐需求激增,餐饮业也迎来了高峰期。在这个时期,餐饮企业需要更加注重食品安全和卫生质量,以保证消费者的健康和权益,明厨亮灶智慧管理成为了餐饮业中备受…...
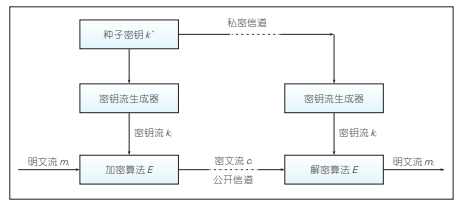
【现代密码学基础】详解完美安全与香农定理
目录 一. 介绍 二. 完美安全的密钥与消息空间 三. 完美安全的密钥长度 四. 最优的完美安全方案 五. 香农定理 (1)理论分析 (2)严格的正向证明 (3)严格的反向证明 六. 小结 一. 介绍 一次一密方案…...

Python 将文本转换成语音播放 pyttsx3
Python 将文本转换成语音播放 pyttsx3 目录 Python 将文本转换成语音播放 pyttsx3 1. 安装 2. 使用 3. 封装 Pyttsx3 是一个 Python 库,它提供了文本到语音(Text-to-Speech,TTS)转换的功能。这个库允许 Python 程序通过调用本…...
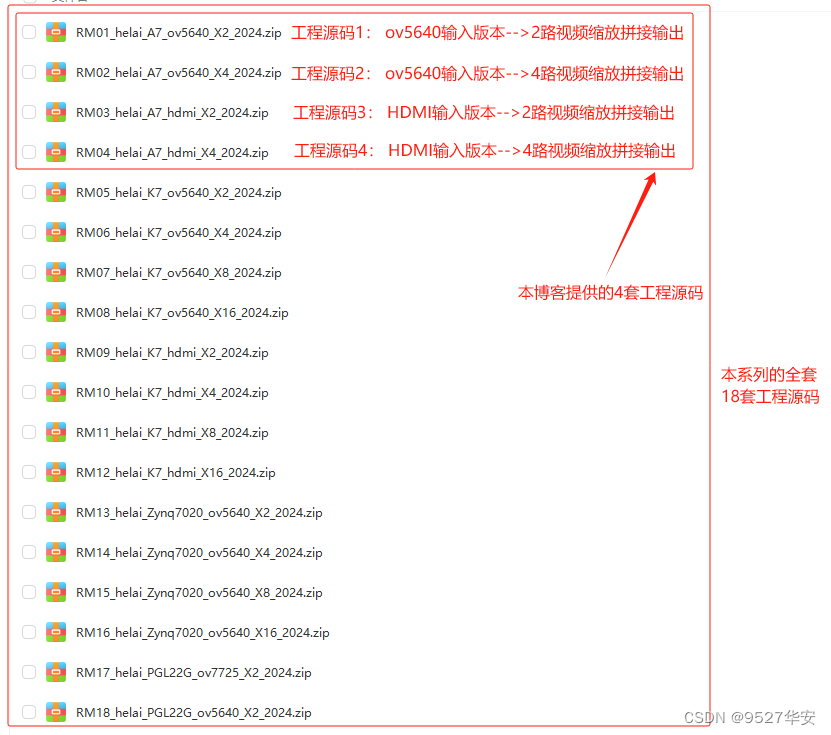
FPGA高端项目:Xilinx Artix7系列FPGA 多路视频缩放拼接 工程解决方案 提供4套工程源码+技术支持
目录 1、前言版本更新说明给读者的一封信FPGA就业高端项目培训计划免责声明 2、相关方案推荐我这里已有的FPGA图像缩放方案我已有的FPGA视频拼接叠加融合方案本方案的Xilinx Kintex7系列FPGA上的ov5640版本本方案的Xilinx Kintex7系列FPGA上的HDMI版本 3、设计思路框架设计框图…...

开源模型应用落地-业务优化篇(三)
一、前言 假如您跟随我的脚步,学习到上一篇的内容,到这里,相信细心的您,已经发现了,在上一篇中遗留的问题。那就是IM服务过载的时候,如何进行水平扩容? 因为在每个IM服务中,我们用JV…...

基于SpringBoot+Vue实现的物流快递仓库管理系统
基于SpringBootVue实现的物流快递仓库管理系统 文章目录 基于SpringBootVue实现的物流快递仓库管理系统系统介绍技术选型成果展示账号地址及其他说明源码获取 系统介绍 系统演示 关注视频号【全栈小白】,观看演示视频 基于SpringBootVue实现的物流快递仓库管理系…...

编程笔记 html5cssjs 072 JavaScrip BigInt数据类型
编程笔记 html5&css&js 072 JavaScrip BigInt数据类型 一、BigInt 数据类型二、BigInt 的创建和使用三、BigInt 操作与方法三、示例小结 JavaScript BigInt 数据类型是一种内置的数据类型,用于表示大于 Number.MAX_SAFE_INTEGER(即2^53 - 1&…...

matlab simulink 步进电机控制
1、内容简介 略 41-可以交流、咨询、答疑 2、内容说明 电动执行器定位控制在生产生活中具有广泛的应用,在使用搭载步进电机的电动执行器进行定位控制的时候,定位系统的定位精度和响应波形,会随着负载质量的变化而变化,这是由电…...
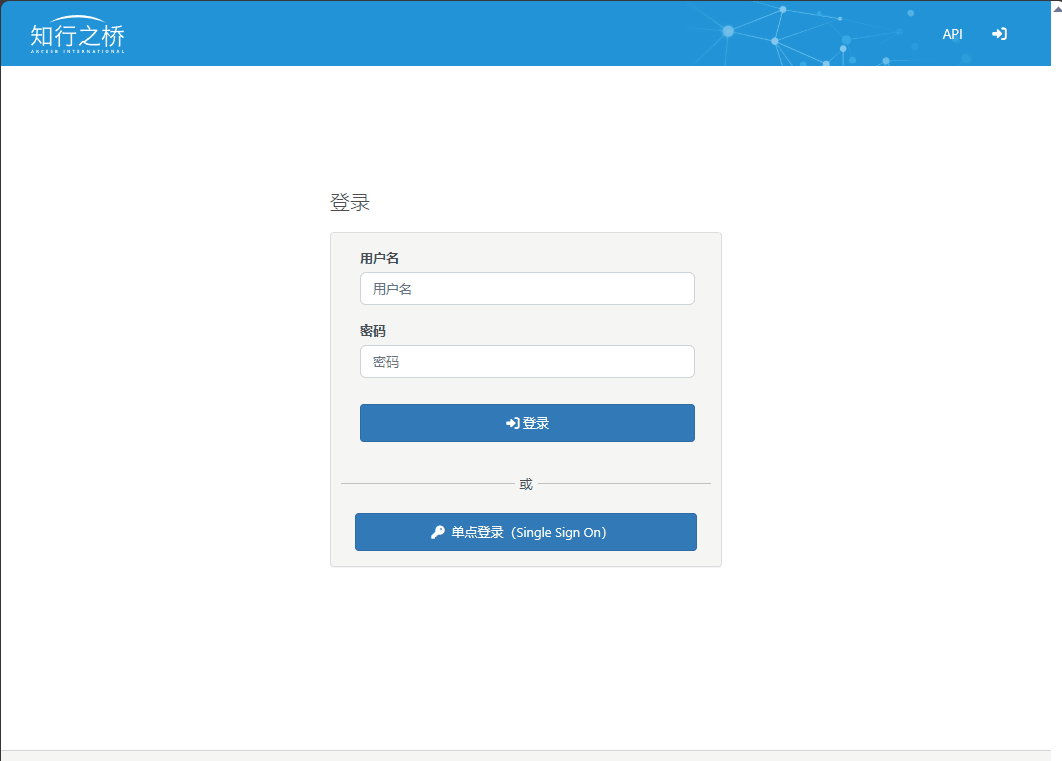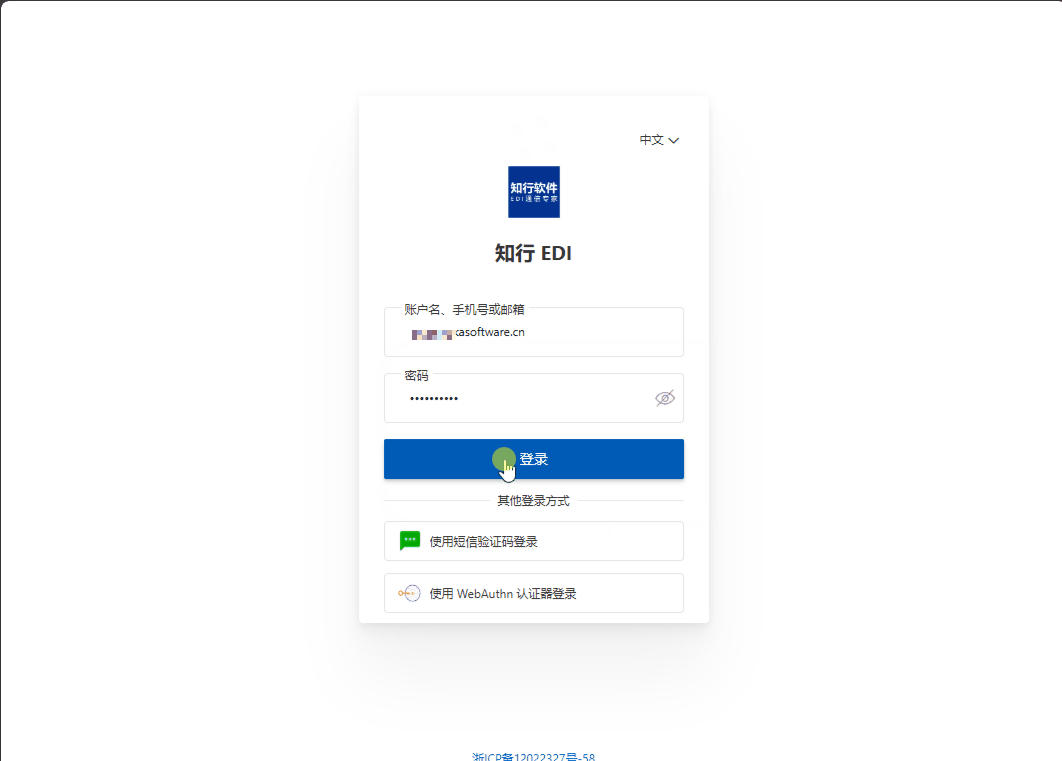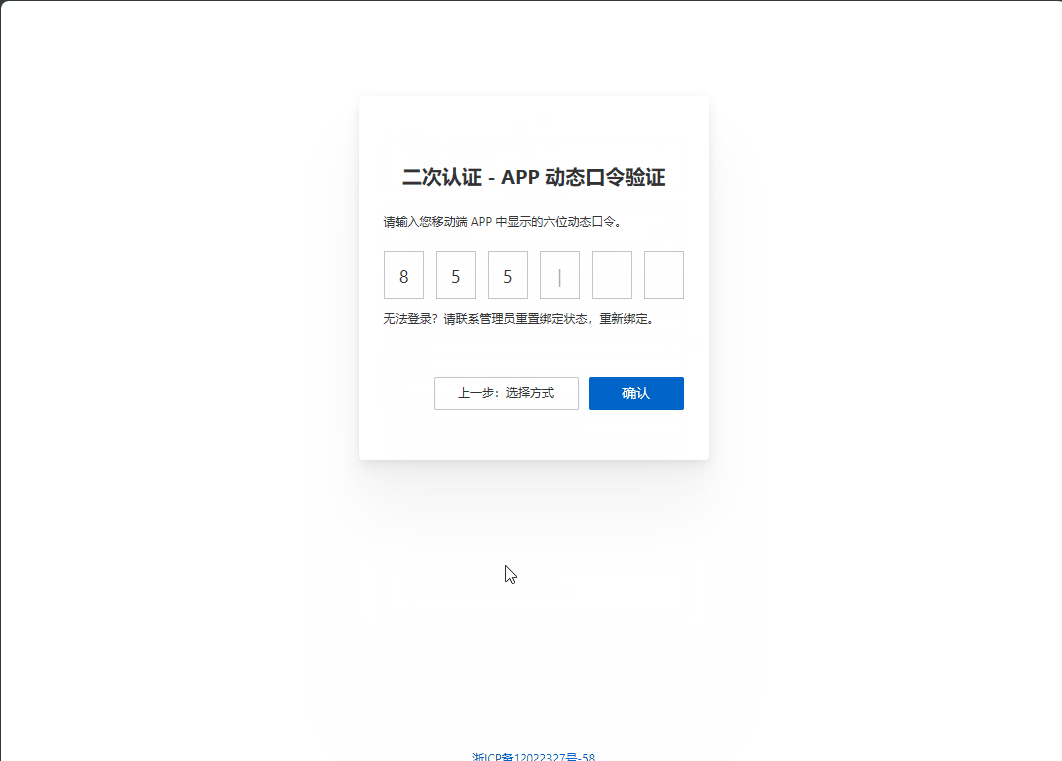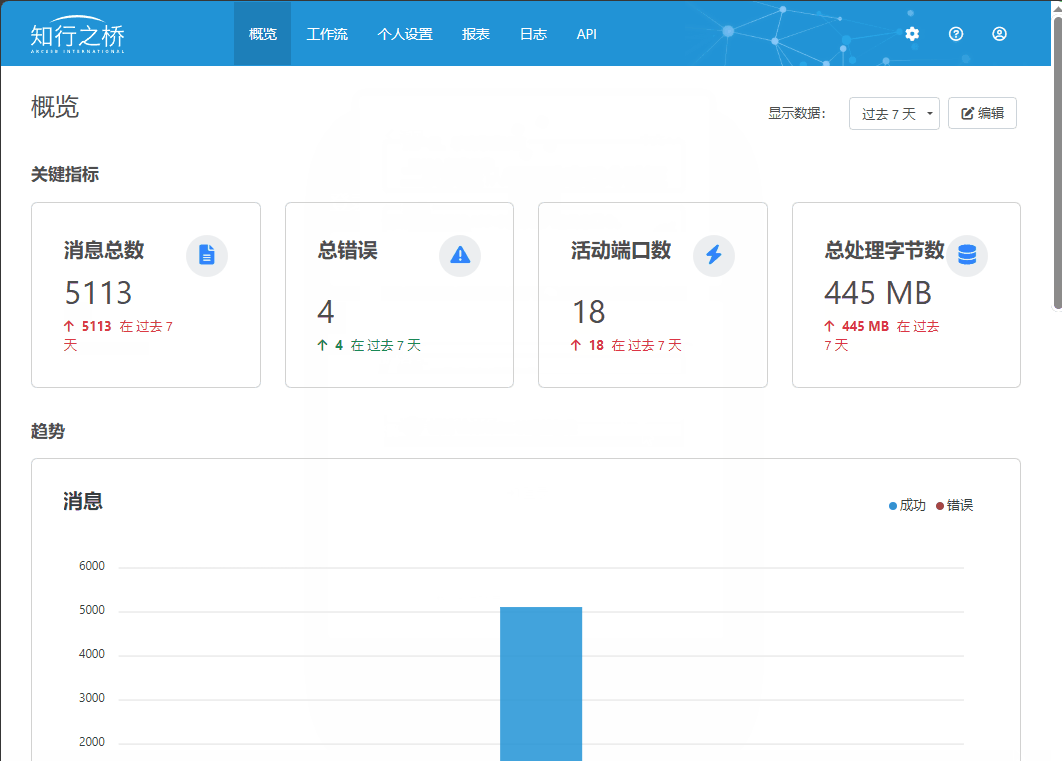
使用阿里云的IDaaS实现知行之桥EDI系统的单点登录
,在开始测试之前,需要确定用哪个信息作为“登陆用户的ID字段”。 这个字段用来在完成SSO登陆之后,用哪个信息将阿里云IDaaS的用户和知行之桥EDI系统的用户做对应。这里我们使用了 phonenumber 这个自定义属性。需要在阿里云做如下配置&#x…...
基于微服务的高考志愿智能辅助决策系统(附源码)
目录 一.引言 1、编写目的 2、系统功能概述 二.功能分析 三.微服务模块 1、微服务用户相关模块 (1)用户注册 (2)用户登录 (3)用户信息管理 (4)用户操作 2、微服务文件云存…...

LeetCode —— 137. 只出现一次的数字 II
😶🌫️😶🌫️😶🌫️😶🌫️Take your time ! 😶🌫️😶🌫️😶🌫️😶🌫️…...

pnpm、npm、yarn 包管理工具
1、npm 关键词:软件包管理器、命令行工具、一个社区和一个平台 npm(Node Package Manager)是一个用于Node.js环境的软件包管理器。它是一个命令行工具,用于安装、升级、删除和管理JavaScript软件包。npm最初是随同Node.js一起发布…...

微服务知识
1、概念 大型单体应用拆分成多个独立部署运行的微服务(解决并发问题) 2、特点 3、技术栈 4、微服务带来的问题 5、微服务的注册中心 服务注册与发现:微服务实例在启动时会向注册中心注册自己的信息…...

如何在微信搭建私域流量池?
A: ①给客户打标签 添加标签,多维度构建用户画像,精准发送消息。 ②群发信息 选择自定义时间,上传内容 (支持文字,图片) ,一键群发 。 ③建立专属素材库 将常用的话术、图片与文件录入至素材库,员工可随…...

MySQL原理(三)锁定机制(1)综述
一、介绍: 1、锁的本质 业务场景中存在共享资源,多个进程或线程需要竞争获取并处理共享资源,为了保证公平、可靠、结果正确等业务逻辑,要把并发执行的问题变为串行,串行时引入第三方锁当成谁有权限来操作共享资源的判…...

Qt知识点总结
将枚举类型转换为字符串 这里使用的在网络编程中,获取socket状态并显示的时候,遇到的一个问题 #include <QMetaEnum>// 将枚举类型转换为字符串 QMetaEnum metaEnum QMetaEnum::fromType<QAbstractSocket::SocketState>(); const char *c…...

不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变
不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变 💡 每次做 PPT 都在 Powerpoint 里拖来拖去,最后做出来还是那个味儿?Frontend Slides 让…...

AI答案优化效果可以靠哪些第三方数据验证?
先给结论:AI答案优化效果要做三层交叉验证AI 答案优化、GEO 服务的效果,不应只听服务商自述,也不适合只靠单张 AI 回答截图判断。更稳妥的做法,是用三层数据交叉验证:AI回答层数据:看品牌是否被提及、位置是…...

为你的大模型应用快速接入Taotoken,Python调用只需三步
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的大模型应用快速接入Taotoken,Python调用只需三步 对于希望在自己的应用中集成大模型能力的开发者而言࿰…...

避坑指南:Gurobi在MATLAB中配置成功后,为什么optimize函数求解结果不对?
Gurobi与MATLAB联合作战:当optimize函数结果异常时的全维度排错手册 当你终于完成了Gurobi的安装配置,看到yalmiptest显示"Found"时,那种成就感就像调试通过了第一个"Hello World"。但现实很快给你上了一课——optimize函…...

3D Slicer完整指南:免费医学影像可视化的终极解决方案
3D Slicer完整指南:免费医学影像可视化的终极解决方案 【免费下载链接】Slicer Multi-platform, free open source software for visualization and image computing. 项目地址: https://gitcode.com/gh_mirrors/sl/Slicer 3D Slicer是一款功能强大的跨平台医…...

如何用Playnite打造你的终极游戏库:统一管理Steam、Epic、GOG等20+平台游戏
如何用Playnite打造你的终极游戏库:统一管理Steam、Epic、GOG等20平台游戏 【免费下载链接】Playnite Video game library manager with support for wide range of 3rd party libraries and game emulation support, providing one unified interface for your gam…...

为什么92%的社交App在AI Agent接入后用户停留时长暴跌?——资深架构师亲授5层调优框架
更多请点击: https://kaifayun.com 第一章:为什么92%的社交App在AI Agent接入后用户停留时长暴跌? 当AI Agent以“智能助手”“聊天搭子”“情绪陪伴者”等名义大规模嵌入社交App时,产品团队普遍预期用户活跃度与停留时长将显著提…...

前端实战:CSS 实现经典对联式悬浮广告
一、效果介绍对联广告是网页中非常经典的广告布局,特点:左右两侧各一个广告栏,像对联一样悬挂页面上下滚动,广告固定不动、悬浮跟随屏幕中间是网站主体内容,互不遮挡、互不影响核心技术:CSS fixed 固定定位…...

Honey Select 2终极增强补丁:5分钟解锁完整汉化与去码功能
Honey Select 2终极增强补丁:5分钟解锁完整汉化与去码功能 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是《Honey Select 2》游戏的…...
避坑指南)
【能力进阶】测试工程师必须了解的 Tokenization(分词器)避坑指南
写作日期:2026年5月 适用读者:后端/算法测试工程师、AI产品测试、LLM应用QA 1 为什么测试工程师必须关注分词器? 2 竞品对比:同一句话,不同模型差出一个量级 2.1 「中文税」到底有多重 2.2 各模型中文分词效...