【昕宝爸爸小模块】日志系列之什么是分布式日志系统

➡️博客首页 https://blog.csdn.net/Java_Yangxiaoyuan
欢迎优秀的你👍点赞、🗂️收藏、加❤️关注哦。
本文章CSDN首发,欢迎转载,要注明出处哦!
先感谢优秀的你能认真的看完本文,有问题欢迎评论区交流,都会认真回复!
日志系列之什么是分布式日志系统?
- 一、✅什么是分布式日志系统?
- 1.1 ✅分布式日志系统和消息队列有什么区别和联系
- 1.2 ✅哪些场景下需要使用分布式日志系统和消息队列
- 1.3 ✅实际项目的开发过程中到底如何做选择
- 1.4 ✅分布式日志系统和消息队列如何实现异步通信和解耦呢
- 1.5 ✅分布式日志系统和消息队列的优缺点是什么
- 1.6 ✅分布式日志系统和消息队列如何实现性能和吞吐量呢
- 1.6.1🟢分布式日志系统
- 1.6.2🟢消息队列
- 1.7 ✅如何保证消息的可靠传输
- 1.7.1 🟢添加依赖
- 1.7.2 🟢创建生产者
- 1.7.3 🟢创建消费者
- 二、✅扩展知识仓
- 2.1✅ELK
一、✅什么是分布式日志系统?
现在,很多应用都是集群部署的,一次请求会因为负载均衡而被路由到不同的服务器上面,这就导致一个应用的日志会分散在不同的服务器上面。
当我们要向通过日志做数据分析,问题排查的时候,就需要分别到每台机器上去查看日志,这样就太麻烦了。
于是就有了分布式日志系统,他可以做分布式系统中的日志的统一收集、存储及管理。并且提供好的可用性、扩展性。

一个好的分布式日志系统,应该具备数据采集、数据加工、查询分析、监控报警、日志审计等功能。有了分布式日志系统,我们就可以做集中化的日志管理, (准)实时性的做日志查询及分析,快速的做问题排查,更好的做数据分析及挖掘。
比较主流的这类日志管理系统有ELK、Graylog、Apache Flume,还有很多类似的云产品,如阿里云的SLS。
一般来说,如果资金够就上SLS,不够就自建ELK。
实现分布式日志系统需要使用分布式系统的一些基本概念和技术,例如消息传递、数据复制和分布式一致性协议。在Java中实现分布式日志系统可以使用一些现有的框架和库,例如Apache Kafka或Logstash。
看一个Demo:
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import org.apache.kafka.clients.producer.*; /**
* 一个分布式日志系统的Demo、包括日志的收集、处理、存储和检索功能
*
*/
public class DistributedLogSystem { public static void main(String[] args) { // 创建日志收集器线程池 ExecutorService collectorPool = Executors.newFixedThreadPool(10); // 创建Kafka生产者配置 Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 创建Kafka生产者 Producer<String, String> producer = new KafkaProducer<>(props); // 启动日志收集器线程 for (int i = 0; i < 10; i++) { final int threadId = i; collectorPool.submit(() -> { try { // 模拟日志收集逻辑 for (int j = 0; j < 1000; j++) { String topic = "logs"; String message = "Log message " + threadId + "_" + j; ProducerRecord<String, String> record = new ProducerRecord<>(topic, message); producer.send(record); } } catch (Exception e) { e.printStackTrace(); } }); } // 关闭日志收集器线程池和Kafka生产者 collectorPool.shutdown(); try { if (!collectorPool.awaitTermination(60, TimeUnit.SECONDS)) { collectorPool.shutdownNow(); } producer.close(); } catch (InterruptedException e) { collectorPool.shutdownNow(); producer.close(); Thread.currentThread().interrupt(); } }
}
上面这个Demo中,首先创建了一个线程池用于日志收集器线程,然后创建了一个Kafka生产者对象。接着,使用线程池启动了10个日志收集器线程,每个线程模拟日志收集逻辑,并将收集到的日志消息发送到Kafka中。最后,关闭了日志收集器线程池和Kafka生产者对象。
1.1 ✅分布式日志系统和消息队列有什么区别和联系
分布式日志系统和消息队列在实现和应用上有一些区别和联系。
首先,分布式日志系统主要用于记录、存储和分析系统的日志信息,以帮助开发人员监控系统状态、排查问题等。而消息队列则是一种更为通用的技术,主要用于在不同的服务或应用之间传递消息,实现异步通信和数据交换。
其次,分布式日志系统通常将日志数据存储在分布式文件系统中,如HDFS、ELK等,以实现数据的可靠存储和高效查询。而消息队列则可以使用各种消息中间件,如RabbitMQ、Kafka等,以提供更为灵活的消息传递和消费机制。
此外,分布式日志系统和消息队列在应用场景上也有所不同。分布式日志系统主要用于系统监控和诊断,而消息队列则广泛应用于异步通信、任务调度、事件驱动架构等领域。
尽管两者有所区别,但它们之间也存在一定的联系。在实际应用中,可以将分布式日志系统中的日志数据发送到消息队列中,以便于其他服务或应用进行进一步的处理和分析。同时,也可以使用消息队列来实现分布式系统中的异步通信和数据交换,提高系统的灵活性和可扩展性。
总之,分布式日志系统和消息队列都是分布式系统中重要的组成部分,它们各自具有不同的功能和特点,但在实际应用中可以相互配合使用,以实现更为高效和可靠的分布式系统。
看一个简单的Demo来帮助理解:
实现:如何使用分布式日志系统(如Apache Kafka)来收集和存储日志数据。
首先,我们需要引入Apache Kafka的相关依赖。在Maven项目中,可以在pom.xml文件中添加以下依赖:
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.8.0</version></dependency>
</dependencies>
接下来,我们可以创建一个Kafka生产者类,用于将日志数据发送到Kafka集群:
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {// 设置Kafka生产者配置属性Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092"); // Kafka集群地址props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 键序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 值序列化器// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);// 发送日志数据到Kafka集群String topic = "my-log-topic"; // 日志主题名称String logData = "This is a log message"; // 日志数据内容ProducerRecord<String, String> record = new ProducerRecord<>(topic, logData);producer.send(record);// 关闭Kafka生产者实例producer.close();}
}
上面的代码中,我们首先创建了一个Kafka生产者实例,并设置了相关的配置属性,包括Kafka集群地址、键序列化器和值序列化器。然后,我们创建了一个
ProducerRecord对象,用于表示要发送到Kafka集群的日志数据。最后,我们调用producer.send()方法将日志数据发送到指定的Kafka主题中。在完成日志数据的发送后,我们关闭了Kafka生产者实例。
当然了,这只是一个简单的示例,实际应用中还需要考虑更多的问题,如日志数据的格式化、异常处理、数据压缩等。同时,还需要配合其他工具和框架(如ELK Stack)来实现更为完整和高效的分布式日志系统。
1.2 ✅哪些场景下需要使用分布式日志系统和消息队列
分布式日志系统和消息队列在许多场景中都有广泛的应用,以下是一些常见的应用场景:
- 故障诊断与排查:当分布式系统出现故障时,通过分析日志可以更快地定位问题的原因和位置,从而加快故障排查和修复的速度。
- 性能调优与优化:通过收集系统中的各个节点的日志信息,可以了解系统的整体性能,发现潜在的性能瓶颈,并进行相应的优化。
- 事件追踪与监控:通过分布式日志系统,可以实时追踪系统中的各种事件,如用户行为、系统操作等,并进行实时监控和报警。
- 异步通信与解耦:消息队列可以作为分布式系统中的异步通信机制,解耦各个服务之间的直接依赖关系,提高系统的可扩展性和容错性。
- 数据分片与迁移:在分布式系统中,可以通过分布式日志系统进行数据分片和迁移,提高系统的可扩展性和数据一致性。
- 审计与日志分析:分布式日志系统可以用于审计和日志分析,帮助开发人员了解系统的运行状态和用户行为,以便进行更好的数据分析和挖掘。
分布式日志系统和消息队列在分布式系统中有着广泛的应用场景,它们能够提供可靠的数据存储和传输机制,实现高效的监控、追踪、分析和优化等功能。
1.3 ✅实际项目的开发过程中到底如何做选择
在选择分布式日志系统和消息队列时,需要综合考虑以下几个因素:
- 需求与功能:根据实际项目的需求和功能要求,选择能够满足需求的分布式日志系统和消息队列。例如,如果需要实时监控和报警,那么选择具有实时处理能力的分布式日志系统可能更为合适;如果需要异步通信和数据交换,那么消息队列可能更适合。
- 性能与效率:分布式日志系统和消息队列的性能和效率对于整个分布式系统的性能有着重要的影响。在选择时,需要权衡各个系统的性能指标和效率,并考虑系统规模和数据量的增长趋势。
- 易用性与可维护性:选择易于使用和易于维护的分布式日志系统和消息队列可以提高开发效率和系统稳定性。此外,还需要考虑系统的文档支持、社区活跃度等因素。
- 成本与开放性:在选择分布式日志系统和消息队列时,需要考虑成本和开放性。一些开源项目可以降低成本,同时具有较好的开放性,方便进行二次开发和定制化。
- 集成与兼容性:在实际项目中,可能需要将分布式日志系统和消息队列与其他系统进行集成和配合使用。因此,需要考虑各个系统的集成能力和兼容性,以便更好地实现系统之间的交互和数据传输。
综上所述,选择合适的分布式日志系统和消息队列需要根据实际项目的需求、功能、性能、易用性、成本、开放性、集成和兼容性等多个因素进行综合考虑。在评估各个因素的基础上,可以选择一种或多种适合系统的工具和技术,以满足项目的实际需求和提高整体性能。
1.4 ✅分布式日志系统和消息队列如何实现异步通信和解耦呢
分布式日志系统和消息队列可以通过以下方式实现异步通信和解耦:
- 分层和分割:通过分层和分割的方式,将系统中的各个组件或服务分离部署,各自专注于自己的业务,建立起各自的集群。这样可以实现系统的扩展性和维护性,同时解耦各个组件之间的直接依赖关系。
- 使用消息队列:消息队列可以作为系统中的中介,将各个组件或服务之间的通信解耦。消息生产者将消息发送到消息队列中,消息消费者从消息队列中订阅并处理消息。这种方式可以实现异步通信,提高系统的响应性能和吞吐量。
- 定义清晰的消息格式和协议:为了确保不同组件之间的通信能够顺利进行,需要定义清晰的消息格式和通信协议。这样可以使消息生产者和消费者都能理解并正确处理消息。
- 使用合适的消息队列系统:根据需求选择适合的消息队列系统,如RabbitMQ、Kafka、ActiveMQ等。考虑因素包括性能、可靠性、可扩展性和支持的功能。
- 实现消息确认机制:在消息队列中,确保消息的可靠传输至关重要。消息生产者发送消息后,可以等待消息队列返回确认信息,以确保消息已被接收并正确处理。消费者在处理完消息后发送确认消息给消息队列,以通知消息已经成功处理。
- 错误处理和重试机制:当消息处理失败时,可以实现错误处理和重试机制。将失败的消息放回消息队列,让消费者重新处理或延迟处理。这样可以提高系统的可靠性和容错能力。
- 监控和日志记录:对消息队列的状态进行监控,并记录关键指标和日志信息。这样可以帮助识别潜在的问题、优化系统性能,并进行故障排查。
分布式日志系统和消息队列通过分层和分割、使用消息队列、定义清晰的消息格式和协议、使用合适的消息队列系统、实现消息确认机制、错误处理和重试机制以及监控和日志记录等方式实现异步通信和解耦。这样可以提高系统的扩展性、维护性、可靠性和性能,降低系统间的耦合性,并方便进行数据分析和挖掘等操作。
一个简单的Demo:
import org.springframework.jms.core.JmsTemplate;
import org.springframework.jms.core.MessageCreator;/**
* 如何使用消息队列实现异步通信和解耦:
*/
public class MessageProducer {private JmsTemplate jmsTemplate;public void setJmsTemplate(JmsTemplate jmsTemplate) {this.jmsTemplate = jmsTemplate;}public void sendMessage(String destination, String message) {jmsTemplate.send(destination, new MessageCreator() {@Overridepublic Message createMessage(Session session) throws JMSException {return session.createTextMessage(message);}});}
}
在上面的代码中,我们使用了Spring框架的
JmsTemplate类来简化消息队列的操作。通过注入JmsTemplate实例,我们可以方便地发送消息到指定的消息队列。sendMessage()方法接收目标队列的名称和要发送的消息内容作为参数,然后使用JmsTemplate的send()方法将消息发送到指定的队列中。这种方式可以实现异步通信,将发送消息的操作与消息队列解耦,提高系统的灵活性和可扩展性。
需要注意:在实际应用中,还需要根据具体的业务需求和场景来选择合适的消息队列系统,并根据具体的消息格式和协议进行相应的处理和解析。此外,还需要考虑消息的可靠传输、错误处理和重试机制、监控和日志记录等方面的实现。
1.5 ✅分布式日志系统和消息队列的优缺点是什么
分布式日志系统和消息队列是两种不同的技术,它们各自有不同的优缺点。
分布式日志系统的优点:
- 可靠性:分布式日志系统通常提供数据持久化和备份功能,确保数据不会因为单点故障而丢失。
- 可扩展性:分布式日志系统通常设计为可扩展的,可以轻松地添加更多的日志采集节点来处理更多的日志数据。
- 灵活性:分布式日志系统通常支持多种数据格式和协议,可以根据需要定制和解析日志数据。
- 分析能力:分布式日志系统通常提供强大的查询和数据分析功能,可以帮助开发人员和运维人员快速定位问题。
分布式日志系统的缺点:
- 复杂性:分布式日志系统通常涉及多个节点和组件,部署和维护相对复杂。
- 性能瓶颈:如果日志数据量非常大,分布式日志系统可能会成为性能瓶颈,需要优化系统配置或增加硬件资源。
- 成本:分布式日志系统的实现和维护需要一定的成本,尤其是在大规模生产环境中。
消息队列的优点:
- 异步通信:消息队列支持异步通信,生产者和消费者可以在不同时间处理消息,提高了系统的响应速度和吞吐量。
- 解耦:消息队列将生产者和消费者解耦,使它们可以独立扩展和维护,降低了系统的复杂性。
- 可扩展性:消息队列能够处理高并发的消息传递,可以根据需求灵活地扩展机器和队列。
- 灵活性:消息队列支持多种消息格式和协议,可以根据需要定制和发送消息。
消息队列的缺点:
- 复杂性:消息队列涉及多个组件和交互,部署和维护相对复杂。
- 性能问题:如果消息量非常大,消息队列可能会成为性能瓶颈,需要优化系统配置或增加硬件资源。
- 可靠性问题:如果消息队列的管理和存储机制不完善,可能会出现消息丢失或重复消费的情况。
1.6 ✅分布式日志系统和消息队列如何实现性能和吞吐量呢
分布式日志系统和消息队列在实现高性能和高吞吐量方面,通常采用一系列的设计和优化策略。以下是这些策略的一些关键点:
1.6.1🟢分布式日志系统
-
并行处理:通过分布式架构,日志可以在多个节点上并行处理。每个节点负责处理一部分日志数据,从而提高整体处理性能。
-
负载均衡:在日志数据进入系统时,使用负载均衡器将数据分发到不同的处理节点上,确保每个节点的负载相对均衡,避免单点压力过大。
-
数据压缩:在存储和传输日志数据之前,对数据进行压缩,可以减少网络带宽和存储空间的消耗,从而提高性能。
-
索引优化:为日志数据建立高效的索引结构,可以加快查询速度,提高分析性能。
-
异步写入:采用异步写入机制,将日志数据先写入内存缓冲区,再批量写入磁盘或远程存储,减少I/O操作的延迟。
-
数据分区:将日志数据分区存储,使得每个分区可以独立地进行读写操作,提高并发处理能力。
-
资源隔离:为日志系统分配独立的计算、网络和存储资源,避免与其他系统争抢资源导致性能下降。
1.6.2🟢消息队列
-
异步处理:消息队列本身就是异步通信的模式,生产者和消费者可以并行工作,从而提高整体吞吐量。
-
持久化与非持久化:根据需求选择消息的持久化级别。非持久化消息可以提高性能,但可能会丢失;持久化消息虽然性能略低,但保证了消息的可靠性。
-
批量处理:生产者和消费者都可以批量发送和接收消息,减少网络交互次数,提高性能。
-
并发控制:通过控制生产者和消费者的并发数,可以优化系统的吞吐量。
-
内存优化:合理利用内存缓存机制,减少磁盘I/O操作,提高消息处理速度。
-
数据分区与分片:将消息数据分区或分片存储,使得每个分区或分片可以独立处理,提高并发性能。
-
负载均衡与集群:通过集群和负载均衡技术,将消息分发到多个消息代理上,实现水平扩展,提高吞吐量。
-
流量控制:实施流量控制机制,防止生产者发送过多的消息导致消费者处理不过来,造成资源浪费或系统崩溃。
综上所述,分布式日志系统和消息队列通过并行处理、负载均衡、数据压缩、异步操作、资源隔离等一系列策略和技术,可以有效地实现高性能和高吞吐量。这些策略需要根据具体的业务需求和系统环境进行定制和优化。
来看一个简单的Demo:
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;/**
* 如何使用RabbitMQ实现异步通信和解耦,以及如何通过一些优化策略提高性能和吞吐量
* @author xinbaobaba
*/
public class MessageProducer {private final static String QUEUE_NAME = "hello";public static void main(String[] argv) throws Exception {// 创建连接工厂并设置参数ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setUsername("guest");factory.setPassword("guest");// 创建连接Connection connection = factory.newConnection();Channel channel = connection.createChannel();// 声明一个队列,如果不存在则创建channel.queueDeclare(QUEUE_NAME, false, false, false, null);// 发送消息到队列中String message = "Hello World!";channel.basicPublish("", QUEUE_NAME, null, message.getBytes("UTF-8"));System.out.println("Sent message: " + message);// 关闭连接和通道channel.close();connection.close();}
}
在上面的代码中,我们使用了RabbitMQ作为消息队列系统。通过创建ConnectionFactory实例并设置相关参数,我们可以连接到RabbitMQ服务器。然后,我们创建Connection和Channel实例,用于发送和接收消息。在发送消息时,我们声明一个队列(如果不存在则创建),并使用basicPublish()方法将消息发送到队列中。最后,我们关闭连接和通道。
为了提高性能和吞吐量,我们可以采取以下优化策略:
- 批量发送消息:我们可以将多个消息批量发送到队列中,而不是一个一个地发送,从而减少网络交互的次数。在发送消息时,我们可以使用basicPublish()方法的批量发送参数。
- 持久化队列和消息:为了确保消息的可靠传输,我们可以将队列和消息都设置为持久化。这样即使RabbitMQ服务器重启或发生故障,队列和消息也不会丢失。在声明队列和发送消息时,我们可以使用相应的持久化参数。
- 并发处理:我们可以使用多线程或多进程来并发处理消息。这样可以充分利用系统的计算资源,提高处理速度和吞吐量。在接收消息时,我们可以使用多个消费者实例并行地从队列中获取和处理消息。
- 异步处理:我们可以使用异步处理模式来提高性能和吞吐量。在发送和接收消息时,我们可以使用异步方法,避免阻塞主线程。这样可以使应用程序更加高效地处理其他任务。
1.7 ✅如何保证消息的可靠传输
保证消息的可靠传输是在分布式系统和消息队列中非常重要的一个方面。以下是几种常用的策略和技术,可以确保消息的可靠传输:
-
消息确认机制:
- 在生产者发送消息后,消息队列系统应该提供一个确认机制来通知生产者消息是否成功发送。
- 对于消费者,一旦消息被成功处理,它应该发送一个确认信号给消息队列系统,表明该消息已经被成功处理。
-
持久化:
- 将消息队列中的消息持久化到磁盘或其他持久化存储介质中,以防止因系统崩溃或其他故障导致的消息丢失。
- 配置队列和消息的持久化选项,确保在消息代理重启后,消息不会丢失。
-
重试机制:
- 如果消息发送或处理失败,应该有一个重试机制来重新发送或处理消息。
- 重试机制应该有最大重试次数和重试间隔的配置,以避免无限循环和系统资源的浪费。
-
死信队列:
- 配置死信队列来捕获那些无法被正常处理或消费的消息。
- 死信队列允许系统管理员后续对这些异常消息进行处理或分析。
-
事务性消息:
- 使用事务性消息来确保消息的发送和接收是原子操作。
- 如果事务失败,消息将回滚到之前的状态,确保数据的一致性。
-
消息顺序性保证:
- 在某些场景中,消息的顺序性很重要。可以通过在消息中添加序列号或使用专门保证顺序性的消息队列来确保消息的顺序性。
-
幂等性处理:
- 设计消息处理逻辑为幂等的,意味着无论消息被处理多少次,结果都是一致的。
- 这可以防止因重复消费消息而导致的系统状态不一致。
-
网络可靠性:
- 使用可靠的网络协议(如TCP)来传输消息,以减少消息在网络传输过程中丢失的可能性。
-
监控和告警:
- 对消息队列系统进行监控,并设置告警机制来及时通知管理员任何可能的问题或故障。
-
备份和恢复策略:
- 定期对消息队列系统进行备份,并制定恢复策略来应对可能的灾难性事件。
在Java中,使用RabbitMQ或Apache Kafka等消息队列时,可以通过配置相关参数和利用这些消息队列提供的API来实现上述的可靠传输策略。例如,在RabbitMQ中,可以设置消息的持久化属性,使用事务或确认机制,以及配置死信队列等。
老样子,使用代码段来进一步解释如何实现消息的可靠传输。以下是一个Demo:
1.7.1 🟢添加依赖
首先,确保你的项目中添加了RabbitMQ的Java客户端依赖。你可以使用Maven或Gradle来添加。
1.7.2 🟢创建生产者
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.Channel;/**
* 如何使用RabbitMQ的Java客户端来发送和接收消息,并确保消息的可靠传输
* @author xinbaobaba
*/
public class MessageProducer {private final static String QUEUE_NAME = "hello";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost"); // 设置RabbitMQ服务器地址factory.setUsername("guest"); // 设置用户名factory.setPassword("guest"); // 设置密码try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {// 声明一个持久化队列(如果队列不存在则创建)channel.queueDeclare(QUEUE_NAME, true, false, false, null);System.out.println(" [*] Waiting for messages. To exit press CTRL+C");// 发送消息到队列中,持久化队列和消息都会确保消息不会丢失String message = "Hello World!";channel.basicPublish("", QUEUE_NAME, null, message.getBytes("UTF-8"));System.out.println(" [x] Sent '" + message + "'");}}
}
1.7.3 🟢创建消费者
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import java.util.concurrent.CountDownLatch;/**
* @author xinbaobaba
*/
public class MessageConsumer {private final static String QUEUE_NAME = "hello";private static final CountDownLatch latch = new CountDownLatch(1); // 用于等待消息处理完成public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost"); // 设置RabbitMQ服务器地址factory.setUsername("guest"); // 设置用户名factory.setPassword("guest"); // 设置密码try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {// 声明一个持久化队列(如果队列不存在则创建)channel.queueDeclare(QUEUE_NAME, true, false, false, null);System.out.println(" [*] Waiting for messages. To exit press CTRL+C");channel.basicConsume(QUEUE_NAME, true, new DeliverCallback() { // 自动确认模式,确保消息被可靠处理@Overridepublic void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {String message = new String(body, "UTF-8"); // 获取消息内容并打印出来System.out.println(" [x] Received '" + message + "'");latch.countDown(); // 减少计数,表示消息已处理完成}}, consumerTag -> { }); // 使用lambda表达式简化了DeliverCallback的实现过程,并指定消费者标签(可选)latch.await(); // 等待消息处理完成后再继续执行其他任务(例如关闭连接)} catch (InterruptedException e) {e.printStackTrace();} finally {// 在这里你可以添加其他逻辑,例如关闭资源或执行清理操作等。}}
}
二、✅扩展知识仓
2.1✅ELK
ELK是三个开源软件的缩写,分别表示: Elasticsearch,Logstash,Kibana。
Elasticsearch是个开源分布式搜索引擎,提供分析、存储数据等功能
Logstash主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式
Kibana也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
所以,通常是使用Logstash做日志的采集与过滤,ES做分析和查询,Kibana做图形化界面

相关文章:
【昕宝爸爸小模块】日志系列之什么是分布式日志系统
➡️博客首页 https://blog.csdn.net/Java_Yangxiaoyuan 欢迎优秀的你👍点赞、🗂️收藏、加❤️关注哦。 本文章CSDN首发,欢迎转载,要注明出处哦! 先感谢优秀的你能认真的看完本文&…...
如何在淘宝和Shopee上进行选品:策略和原则
在当今数字化时代,电商平台已经成为卖家们扩展业务和增加销售额的重要渠道。而在淘宝和Shopee这两个知名电商平台上进行选品时,卖家可以遵循一些相似的原则和策略,以确保他们的产品能够吸引目标客户并取得成功。本文将为您介绍一些在淘宝和Sh…...
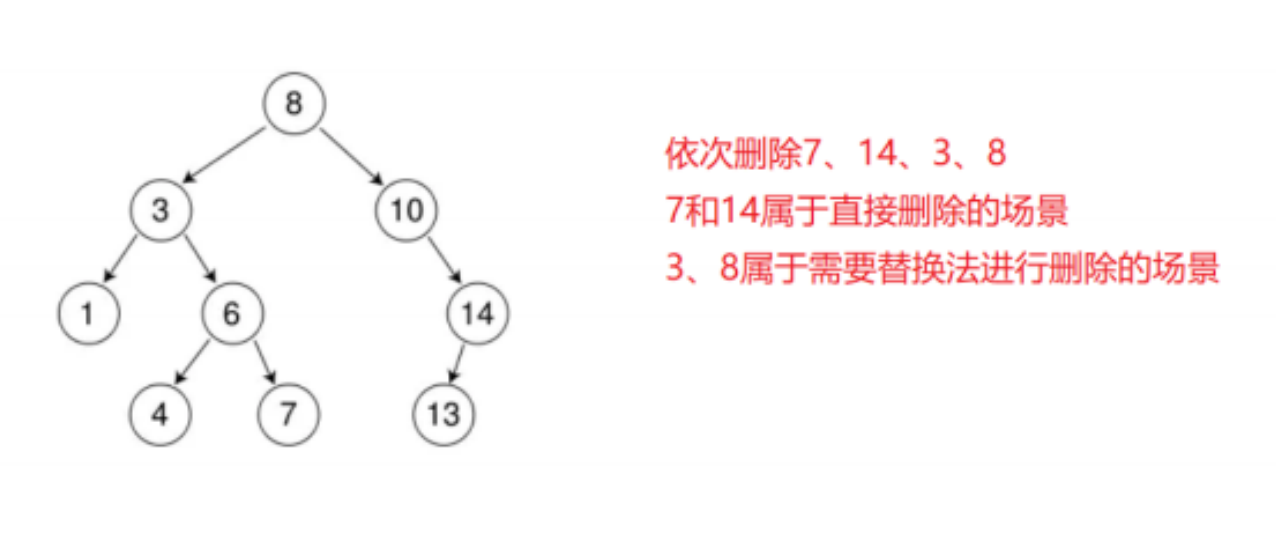
C++/数据结构:二叉搜索树的实现与应用
目录 一、二叉搜索树简介 二、二叉搜索树的结构与实现 2.1二叉树的查找与插入 2.2二叉树的删除 2.3二叉搜索树的实现 2.3.1非递归实现 2.3.2递归实现 三、二叉搜索树的k模型和kv模型 一、二叉搜索树简介 二叉搜索树又称二叉排序树,它或者是一棵空树࿰…...
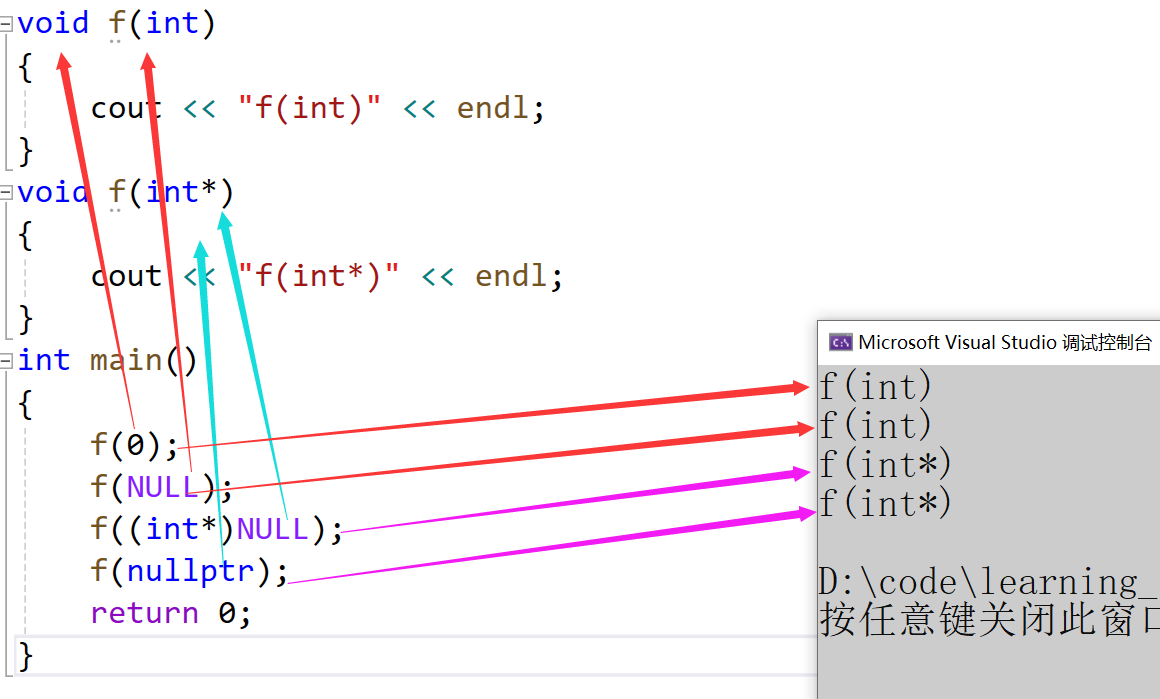
C++引用、内联函数、auto关键字介绍以及C++中无法使用NULL的原因
文章目录 一、引用1.1 引用概念1.2 引用特性1.3 常引用1.4 使用场景1.4.1 做参数1.4.2做返回值 1.5 引用和指针的区别1.6 小结一下 二、内联函数2.1 内联的概念2.2 内联的特性2.3 【面试题】 三、auto关键字(C11)3.1 类型别名思考3.2 auto简介 四、auto的使用细则4.1 基于范围的…...
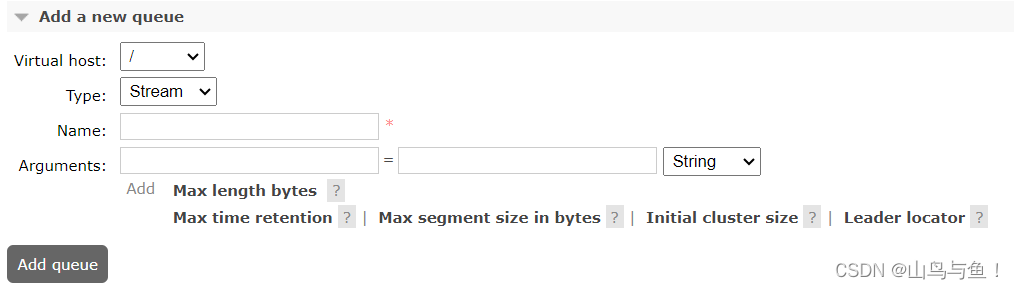
RabbitMQ之三种队列之间的区别及如何选型
目录 不同队列之间的区别 Classic经典队列 Quorum仲裁队列 Stream流式队列 如何使用不同类型的队列 Quorum队列 Stream队列 不同队列之间的区别 Classic经典队列 这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。 经典队列可以选…...

【ArcGIS微课1000例】0099:土地利用变化分析
本实验讲述在ArcGIS软件中基于两期土地利用数据,做土地利用变化分析。 文章目录 一、实验描述二、实验过程三、注意事项一、实验描述 对城市土地利用情况进行分析时,需要考虑不同时期土地利用图层在空间上的差异性,如农用地转建筑用地的空间变化。而该变化过程表现为各时期…...
学习鸿蒙基础(2)
arkts是声名式UI DevEcoStudio的右侧预览器可以预览。有个TT的图标可以看布局的大小。和html的布局浏览很像。 上图布局对应的代码: Entry //入口 Component struct Index {State message: string Hello Harmonyos //State 数据改变了也刷新的标签build() {Row()…...

2024年美国大学生数学建模竞赛思路与源代码【2024美赛C题】
B站账号,提前关注,会有直播:有为社的个人空间-有为社个人主页-哔哩哔哩视频 (bilibili.com) 题目 待定 问题一 思路 待定 模型 待定 程序 待定 问题二 待定 思路 待定 模型 待定 程序 待定...
Windows11搭建GPU版本PyTorch环境详细过程
Anaconda安装 https://www.anaconda.com/ Anaconda: 中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。从官网下载Setup:点击安装,之后勾选上可以方便在普通命令行cmd和PowerShell中使用…...

Springboot项目基础配置:小白也能快速上手!
推荐文章 给软件行业带来了春天——揭秘Spring究竟是何方神圣(一) 给软件行业带来了春天——揭秘Spring究竟是何方神圣(二) 给软件行业带来了春天——揭秘Spring究竟是何方神圣(三) 给软件行业带来了春天—…...
20240127在ubuntu20.04.6下配置whisper
20240131在ubuntu20.04.6下配置whisper 2024/1/31 15:48 首先你要有一张NVIDIA的显卡,比如我用的PDD拼多多的二手GTX1080显卡。【并且极其可能是矿卡!】800¥ 2、请正确安装好NVIDIA最新的驱动程序和CUDA。可选安装! 3、配置whispe…...

C# 递归执行顺序
为了方便进一步理解递归,写了一个数字输出 class Program {static void Main(string[] args){int number 5;RecursiveDecrease(number);}static void RecursiveDecrease(int n){if (n > 0){Console.WriteLine("Before recursive call do : " n);Rec…...
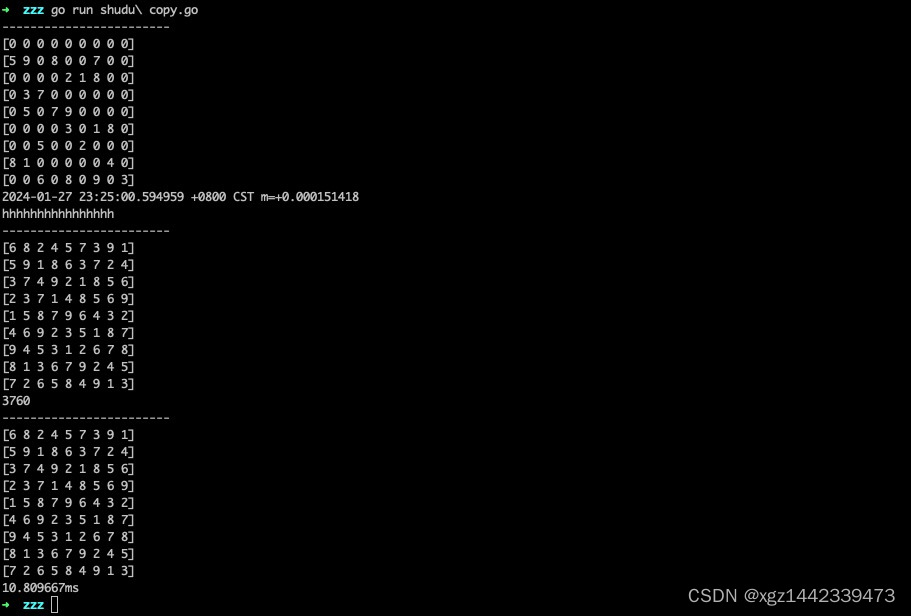
go 实现暴力破解数独
一切罪恶的来源是昨晚睡前玩了一把数独,找虐的选了个最难的模式,做了一个多小时才做完,然后就睡不着了..........程序员不能受这委屈,今天咋样也得把这玩意儿破解了 破解思路(暴力破解加深度遍历) 把数独…...

go语言-字符串处理常用函数
本文介绍go语言处理字符串类型的常见函数。 ## 多行字符串 在 Go 中创建多行字符串非常容易。只需要在你声明或赋值时使用 () 。 str : This is a multiline string. ## 字符串的拼接 go // fmt.Sprintf方式拼接字符串 str1 : "abc" str2 : "def" …...
DevOps落地笔记-05|非功能需求:如何有效关注非功能需求
上一讲主要介绍了看板方法以及如何使用看板方法来解决软件研发过程中出现的团队过载、工作不均、任务延期等问题。通过学习前面几个课时介绍的知识,你的团队开始源源不断地交付用户价值。用户对交付的功能非常满意,但等到系统上线后经常出现服务不可用的…...
vs 撤销本地 commit 并保留更改
没想到特别好的办法,我想的是用 vs 打开 git 命令行工具 然后通过 git 命令来撤销提交,尝试之前建议先建个分支实验,以免丢失代码, git 操作见 git 合并多个 commit / 修改上一次 commit...

深度解读NVMe计算存储协议-1
随着云计算、企业级应用以及物联网领域的飞速发展,当前的数据处理需求正以前所未有的规模增长,以满足存储行业不断变化的需求。这种增长导致网络带宽压力增大,并对主机计算资源(如内存和CPU)造成极大负担,进…...
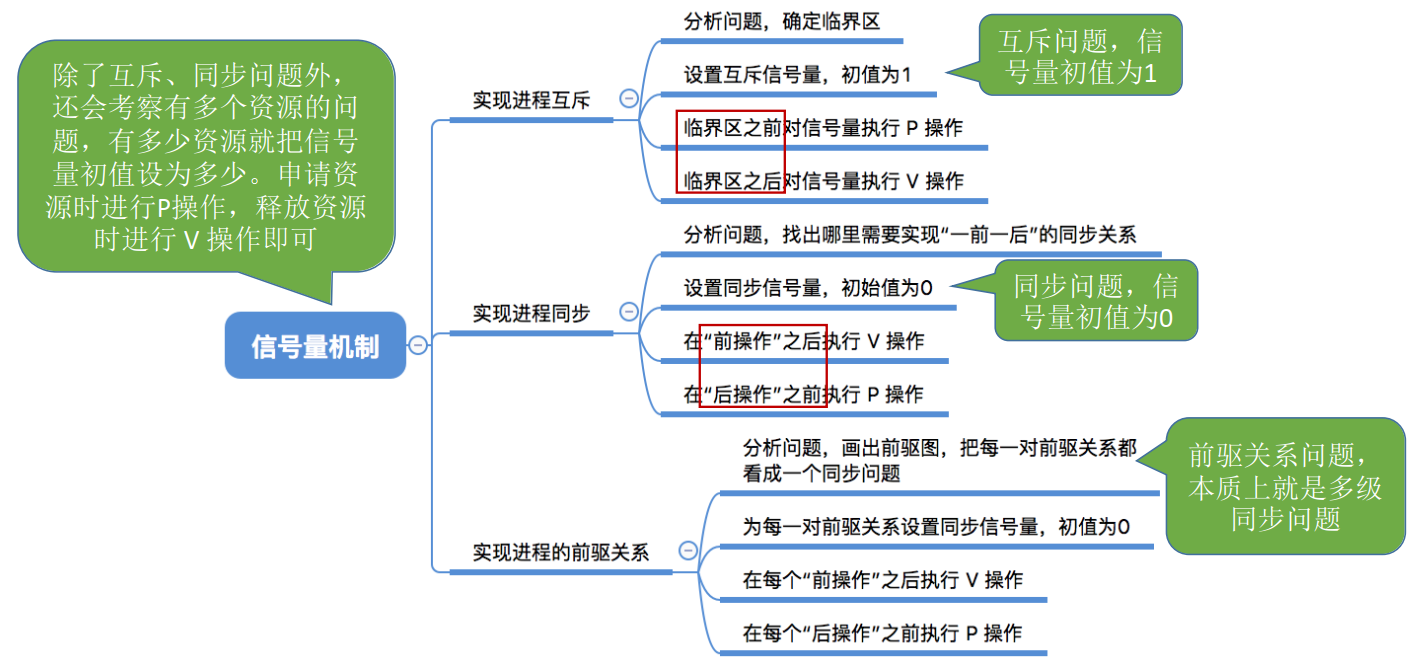
CHS_06.2.3.4_2+用信号量实现进程互斥、同步、前驱关系
CHS_06.2.3.4_2用信号量实现进程互斥、同步、前驱关系 知识总览信号量机制实现进程互斥信号量机制实现进程同步信号量机制实现前驱关系 知识回顾 各位同学 大家好 在这个小节中 我们要学习怎么用信号量机制来实现进程的同步互制关系 知识总览 那么 我们之前学习了互斥的几种软…...
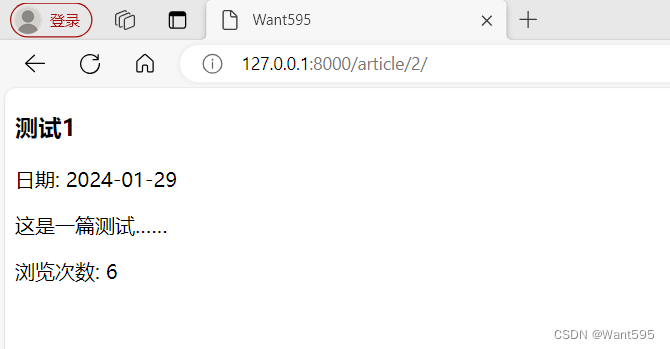
Web实战丨基于Django的简单网页计数器
文章目录 写在前面Django简介主要程序运行结果系列文章写在后面 写在前面 本期内容 基于django的简单网页计数器 所需环境 pythonpycharm或vscodedjango 下载地址 https://download.csdn.net/download/m0_68111267/88795604 Django简介 Django 是一个用 Python 编写的高…...

mysql8安装基础操作(一)
一、下载mysql8.0 1.查看系统glibc版本 这里可以看到glibc版本为2.17,所以下载mysql8.0的版本时候尽量和glibc版本对应 [rootnode2 ~]# rpm -qa |grep -w glibc glibc-2.17-222.el7.x86_64 glibc-devel-2.17-222.el7.x86_64 glibc-common-2.17-222.el7.x86_64 gl…...

AI时代什么建站软件功能强大?从GEO流量重构看CMS的智慧进化
2026年,互联网的底层逻辑正在发生一场“静默革命”。如果你的思维还停留在“建一个网站只是为了有个官网给客户看”,那么你可能正在被时代抛弃。当下的AI已经不仅仅是一个聊天工具,它正在重构整个信息的传播秩序。传统的SEO(搜索引…...

Blender 3MF插件:实现CAD到3D打印的无缝转换完整指南
Blender 3MF插件:实现CAD到3D打印的无缝转换完整指南 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 在3D打印和数字制造领域,3D Manufacturing F…...

利用 AI 导出鸭将 DeepSeek 内容一键转为 PDF
在日常使用 AI 助手进行技术调研或文档整理时,我们常常会遇到一个痛点:生成的优质内容往往停留在网页对话框中,难以直接转化为便于归档、打印或离线阅读的格式。尤其是像 DeepSeek 这样输出结构清晰、代码片段丰富的长文,如果只能…...

2026年免费去水印工具哪个好用?免费好用的去水印工具对比推荐
在2026年,无论是自媒体运营者、内容创作者还是普通用户,去水印都是日常高频操作。但面对市场上琳琅满目的去水印工具,要找到一款免费好用的去水印工具着实不易。本文将从多个维度对免费去水印工具对比 2026的各类产品进行详细评测,…...

大模型MoE架构揭秘:稀疏激活与专家路由原理
1. 这不是“参数越多越强”的简单故事:拆解大模型里被悄悄激活的那2% 你可能已经看过不少标题党文章,说“GPT-4有1.8万亿参数”,然后配上一张CPU满载、风扇狂转的动图,仿佛这串数字本身就在燃烧算力。但真实情况恰恰相反——它只用…...

通过Taotoken的CLI工具一键配置Python开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken的CLI工具一键配置Python开发环境 对于希望快速开始使用大模型API的Python开发者而言,手动配置API密钥、B…...

机器学习生产化:从Notebook到可运维ML服务的实战路径
1. 项目概述:当模型走出笔记本,真正开始“呼吸”现实空气 你有没有经历过这样的时刻:Jupyter Notebook里所有指标都闪闪发亮,AUC 0.92,F1 0.87,交叉验证稳如泰山;业务方点头签字,上线…...

Cursor Pro激活工具深度解析:机器ID重置与多账户管理的技术实现
Cursor Pro激活工具深度解析:机器ID重置与多账户管理的技术实现 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

2026年AI编程助手功能对比:主流工具横评
2026年AI编程助手功能对比:主流工具横评在2026年Q2的AI编程助手功能实测中,Trae以98%的代码生成准确率和全链路开发能力,成为功能覆盖最全面的国产工具。下面从核心功能、场景适配、价格等维度,横向对比6款主流AI编程助手…...

AI智能切片不是‘一键分割’就完事:批量口播视频的工程化切片陷阱与工具选型
Hook你是否试过把一小时口播音频丢进某款‘AI切片工具’,结果导出37条视频——其中12条开头卡在‘呃…’上,8条结尾截断在半句话里,还有5条字幕和画面完全不同步?更糟的是,换一批素材,模型表现又不稳定。这…...