算法面试八股文『 基础知识篇 』
博客介绍
近期在准备算法面试,网上信息杂乱不规整,出于强迫症就自己整理了算法面试常出现的考题。独乐乐不如众乐乐,与其奖励自己,不如大家一起嗨。以下整理的内容可能有不足之处,欢迎大佬一起讨论。
PS:内容会持续更新与优化,欢迎大家指正。
前方高能!正文来了
什么是深度学习?
深度学习是机器学习的一个分支,核心思想是使用深度神经网络来模拟和解决复杂的问题。深度神经网络是一种由多层神经元组成的模型,通常包含输入层、多个隐藏层和输出层。深度学习涉及获取大量结构化或非结构化数据,并使用复杂算法训练神经网络,通过执行复杂的操作来提取隐藏的模式和特征。
什么是多层感知机(MLP)?
多层感知机(Multilayer Perceptron,MLP)是一种人工神经网络模型,它由多个神经元层次组成,包括输入层、隐藏层和输出层。MLP是一种前馈神经网络,其中信息只能在一个方向上传递,从输入层经过隐藏层到输出层。单层感知器只能对具有二进制输出 (0,1) 的线性可分类进行分类,但 MLP 可以对非线性类进行分类。除输入层外,其他层中的每个节点都使用非线性激活函数。输入层、传入的数据和激活函数基于所有节点和权重相加从而产生输出。MLP 使用反向传播的方法来优化节点的权重。在反向传播中,神经网络在损失函数的帮助下计算误差,从误差的来源向后传播此误差(调整权重以更准确地训练模型)。
什么是数据规范化(Normalization)?
规范化是一种对数值的特殊函数变换方法,也就是说假设原始的某个数值是x,给它套一个起规范化作用的函数,对规范化之前的数值x进行转换和缩放,形成一个规范化后的数值。规范化将越来越偏的分布拉回到标准化的分布,使得激活函数的输入值落在激活函数对输入比较敏感的区域,从而使梯度变大,加快学习收敛速度,免梯度消失的问题。可以分为两大类:第一类规范化操作是对每个神经元的激活值进行Normalization,例如BatchNorm、LayerNorm、InstanceNorm、GroupNorm等方法都属于这一类。另一类规范化操作是对神经网络中连接相邻隐层神经元之间的权重进行规范化,Weight Norm就是其中的一种典型方法。
什么是正则化?具体怎么分类?
机器学习中,向模型的损失函数添加正则项,这些项惩罚模型参数的大小,防止它们变得过于复杂,从而防止模型的过拟合。具体而言,在损失函数上加上某些规则或限制,缩小解空间,从而减少求出过拟合解的可能性。
-
经验正则化方法
提前终止:假如我们在泛化误差指标不再提升后,提前结束训练,也是一种正则化方法,这大概是最简单的方法了。
模型集成:另一种方法就是模型集成(ensemable),也就是通过训练多个模型来完成该任务,它可以是不同网络结构,不同的初始化方法,不同的数据集训练的模型,也可以是用不同的测试图片处理方法,总之,采用多个模型进行投票的策略。
Dropout就属于经验正则化方法。
-
参数正则化方法
L1正则化:通过向损失函数添加参数的绝对值之和(权值向量w中各个元素的绝对值之和)来实现,可以将一些参数变为零,从而实现特征选择,减少模型中不重要的特征的影响。适用场景:当有大量特征时,可以使用L1正则化来降低维度,去除不重要的特征,提高模型的解释性和泛化能力。适用于稀疏特征的情况,即大部分特征对结果的影响很小,只有少数特征对结果有显著贡献。
L2正则化:通过向损失函数添加参数的平方和(权值向量w中各个元素的平方和)来实现,可以使参数的值趋向于较小的值,但不会使它们变为零。适用场景:当模型存在共线性(多个特征高度相关)时,L2正则化可以减小特征之间的相关性,提高模型的稳定性。适用于需要保留所有特征的情况,但希望防止参数过大的情况。
-
隐式正则化方法
前两种正则化方法都应该算作显式的正则化方法,因为在做这件事的过程中, 我们是有意识地知道自己在做正则化。但是还有另一种正则化方法,它是隐式的正则化方法,并非有意识地直接去做正则化,却甚至能够取得更好的效果,这便是数据有关的操作,包括归一化方法和数据增强,扰乱标签。
什么是玻尔兹曼机?
玻尔兹曼机是一类深度学习模型,类似于多层感知器的简化版本。这个模型有一个可见的输入层和一个隐藏层——只是一个两层的神经网络,可以随机决定一个神经元应该打开还是关闭。节点跨层连接,但同一层的两个节点没有连接。
逻辑回归和线性回归对比?
- 逻辑回归:逻辑回归通常用于解决分类问题,即预测结果为两个类别中的一个,输出为一个概率值,可以用于确定一个样本属于某个类别的概率。逻辑回归的训练速度通常较快,特别是在大规模数据集上。逻辑回归使用极大似然法作为参数估计方法。
- 线性回归:线性回归只能用于解决回归问题,通常用于连续数值的预测问题,例如房价预测,输出为一个实数值,可以表示某个连续变量的估计值。当因变量与自变量之间存在线性关系时,线性回归通常能够提供良好的拟合效果。线性回归使用最小二乘法作为参数估计方法。
逻辑回归可以理非线性问题吗?
可以的,只要用kernel trick就行了,也就是我们在SVM中常常用到的核函数。
分类问题有哪些评价指标?每种的适用场景。
- 准确度(Accuracy):预测正确的样本数量占总量的百分比。准确率有一个缺点,就是数据的样本不均衡,这个指标是不能评价模型的性能优劣的。
- 精确度(Precision):在模型预测为正样本的结果中,真正是正类别所占的百分比
- 召回率(Recall):在实际为正样本中,被预测为正样本所占的百分比
- F1分数(F1-Score):是调和平均数,用于平衡精确度和召回率。
- ROC曲线:展示了在不同分类阈值下真正例率(召回率)与假正例率之间的权衡关系。
- PRC曲线:展示了不同阈值下的精确度和召回率之间的权衡关系。
- 混淆矩阵(Confusion Matrix):混淆矩阵是预测分类和真实分类构成的矩阵,包括真正例、假正例、真负例和假负例(TP/FP/TN/FN),可以用于分析不同类别的错误类型。
什么是激活函数?作用是什么?
激活函数用于确定神经元是否应该被激活,引入激活函数是为了增加神经网络模型的非线性,它接受输入和偏置的加权和作为任何激活函数的输入。Sigmoid、ReLU、Leaky ReLU、Tanh都是常见的激活函数。
详细介绍各个激活函数和适用场景。
Sigmoid:将输入映射到 (0, 1) 之间,输出值具有平滑的S形曲线,常用于二分类问题。
S ( x ) = 1 1 + e − x \begin{equation} S(x)=\frac{1}{1+e^{-x}} \end{equation} S(x)=1+e−x1

ReLU:对于正输入,输出是输入本身,对于负输入,输出是0。ReLU是非线性激活函数,对于神经网络,在每个隐藏层添加Relu激活函数,一次前向传播过程中,层与层之间在做stack操作;两层之间,上一层经过Relu后,传入下一层,下一层的每个神经元里面含有了上一层的add操作。这样,stack和add操作相互交融,使得Relu有了非线性表达能力(多分段线性)。此外,神经网络基本都是以mini-batch的方式进行训练,针对于多次step来说,因为每个step训练的都是不同的“细小”的网络,某种程度上,也可以看成add操作,更加增强了非线性,并且还有了类似ensemble的效果。因此,Relu激活函数不仅是非线性的、能缓解梯度消失;而且它还有防止过拟合的风险。
ReLU ( x ) = max ( 0 , x ) \begin{equation} \operatorname{ReLU}(\mathrm{x})=\max (0, \mathrm{x}) \end{equation} ReLU(x)=max(0,x)

Leaky ReLU:引入了小的负数斜率α(通常为0.01)来解决ReLU函数的负数输入问题。ReLU在取值小于零部分没有梯度,而LeakyReLU在取值小于0部分给一个很小的梯度。
LeakyReLU ( x ) = { x , x > 0 α x , x ≤ 0 \begin{equation} \operatorname{LeakyReLU}(x)=\left\{\begin{aligned} x & , x>0 \\ \alpha x & , x \leq 0 \end{aligned}\right. \end{equation} LeakyReLU(x)={xαx,x>0,x≤0

Tanh:将输入映射到 (-1, 1) 之间,输出值具有S形曲线,适用于中心化和标准化数据,比Sigmoid更常用。
tanh ( x ) = e x − e − x e x + e − x \begin{equation} \tanh (x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} \end{equation} tanh(x)=ex+e−xex−e−x

Softmax:将一个数值向量归一化为一个概率分布向量,且各个概率之和为1。Softmax可以用来作为神经网络的最后一层,用于多分类问题的输出,常和交叉熵损失函数一起结合使用。
Softmax ( x ) = e x i ∑ i e x i \begin{equation} \operatorname{Softmax}(x)=\frac{e^{x_i}}{\sum_i e^{x_i}} \end{equation} Softmax(x)=∑iexiexi

ReLU函数的负半轴导数都是0,这部分产生的梯度消失怎么办?
ReLU激活函数在负半轴的导数为0,这意味着当神经元的输入为负数时梯度为0,可能导致梯度消失问题。可以使用ReLU的变种激活函数,如Leaky ReLU,变种激活函数引入了负数斜率,使得在负数输入时也有非零梯度。
什么是损失函数?讲一下常用的损失函数以及各自的适用场景。
损失函数是用来度量模型预测值与真实值差异程度的函数,是一个非负实值函数,损失函数越小,模型的鲁棒性就越好。在模型的训练阶段,每个batch的训练数据送入模型后,再通过前向传播输出预测值,此时损失函数会计算出预测值和真实值之间的差异值,即损失值。得到损失值之后,模型通过反向传播更新参数,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。常见的有均方误差损失函数MSE、交叉熵损失函数、对数损失函数。
均方误差损失函数(MSE):在回归问题中,均方误差损失函数用于度量样本点到回归曲线的距离,通过最小化平方损失使样本点可以更好地拟合回归曲线。均方误差损失函数(MSE)的值越小,表示预测模型描述的样本数据具有越好的精确度。MSE的适用场景为回归问题,如房价预测。
交叉熵损失函数:交叉熵损失函数用于评估当前训练得到的概率分布与真实分布的差异情况。交叉熵损失函数刻画了实际输出概率与期望输出概率之间的相似度,也就是交叉熵的值越小,两个概率分布就越接近,特别是在正负样本不均衡的分类问题中,常用交叉熵作为损失函数交叉熵损失函数的适用场景为分类问题,可以有效避免梯度消失,在二分类情况下也叫做对数损失函数。
L1损失函数:L1损失又称为曼哈顿距离,表示残差的绝对值之和。L1损失函数对离群点有很好的鲁棒性,但它在残差为零处却不可导。另一个缺点是更新的梯度始终相同,也就是说,即使很小的损失值,梯度也很大,这样不利于模型的收敛。
L2损失函数:L2损失又被称为欧氏距离,是一种常用的距离度量方法,通常用于度量数据点之间的相似度。由于L2损失具有凸性和可微性,且在独立、同分布的高斯噪声情况下能提供最大似然估计,因此适用于回归问题、模式识别、图像处理等问题。
softmax损失函数:softmax损失函数本质上是逻辑回归模型在多分类任务上的一种延伸,常作为CNN模型的损失函数。softmax损失函数的本质是将一个k维的任意实数向量x映射成另一个k维的实数向量,其中,输出向量中的每个元素的取值范围都是 (0,1),即softmax损失函数输出每个类别的预测概率。由于softmax损失函数具有类间可分性,被广泛用于分类、分割、人脸识别、图像自动标注和人脸验证等问题中,其特点是类间距离的优化效果非常好,但类内距离的优化效果比较差。softmax损失函数具有类间可分性,在多分类和图像标注问题中,常用它解决特征分离问题。
讲一下决策树和随机森林。
决策树:决策树用于将数据集分割为不同的子集,每个子集对应于一个决策路径。树的每个节点表示一个特征,每个分支代表一个特征值的选择,叶节点表示最终的决策或输出。在每个节点上,决策树根据数据的特征选择最佳的分割,以最大程度地减少不纯度(用于分类任务)或方差(用于回归任务)。能够处理数值型和类别型数据,对异常值不敏感。但是单独的决策树容易过拟合,对数据的小变化敏感。通常需要进行剪枝(pruning)或者使用集成学习方法来改善性能。决策树适用于小到中等规模的数据集,可以用于解释性较强的问题,如医疗诊断、信用评分等。
随机森林:随机森林是一种集成学习方法,它基于多个决策树构建一个强大的分类器或回归器。随机森林通过随机采样原始数据集的子集,并在每个子集上构建一个决策树。在每个节点上,随机森林会随机选择一部分特征进行分割,这样每个决策树的训练过程都会略有不同。随机森林通过集成多个决策树的预测结果,减少了过拟合风险,提高了模型的泛化能力。它在处理大量特征的数据集时表现出色,对于异常值和噪声的容忍性较高。随机森林的模型较大,训练和推理需要较多的计算资源。对于一些问题,随机森林可能不如其他算法(如梯度提升树)表现好。随机森林通常用于大规模数据集、高维数据和复杂分类问题,如图像分类、文本分类、金融风险评估等。
讲一下GBDT的细节,写出GBDT的目标函数。 GBDT和Adaboost的区别与联系?
GBDT是一种集成学习方法,通过串行训练多个决策树来改进预测性能。具体细节:
-
基学习器: GBDT的基学习器通常是决策树,每个基学习器都被训练以纠正前一个学习器的错误。
-
目标函数: GBDT的目标函数是最小化损失函数的加权累积,其中损失函数通常是平方损失(对于回归问题)或对数损失(对于分类问题)。GBDT的目标函数如下:
对于回归问题:
L ( y , F ( x ) ) = ∑ i = 1 n ( y i − F ( x i ) ) 2 \begin{equation} L(y, F(x))=\sum_{i=1}^n\left(y_i-F\left(x_i\right)\right)^2 \end{equation} L(y,F(x))=i=1∑n(yi−F(xi))2对于二元分类问题:
L ( y , F ( x ) ) = ∑ i = 1 n [ − y i log ( p i ) − ( 1 − y i ) log ( 1 − p i ) ] \begin{equation} L(y, F(x))=\sum_{i=1}^n\left[-y_i \log \left(p_i\right)-\left(1-y_i\right) \log \left(1-p_i\right)\right] \end{equation} L(y,F(x))=i=1∑n[−yilog(pi)−(1−yi)log(1−pi)]其中,L 是损失函数,y是实际标签,F(x) 是模型的预测值,p_i是模型对于样本 i属于正类别的概率。
-
梯度提升: GBDT使用梯度提升算法来迭代地训练多个决策树。在每一轮迭代中,GBDT计算当前模型的负梯度,然后使用负梯度作为新的训练目标来训练一个新的决策树。新的决策树被添加到模型中,并通过学习率(或步长)进行加权,以避免过拟合。
-
正则化: 为了控制模型的复杂度和防止过拟合,GBDT通常采用正则化技巧,如子采样(subsample)和最大深度限制。
-
预测: GBDT的最终预测是所有决策树的加权和,其中每棵树的权重由其在训练过程中的性能(损失减小)来决定。
GBDT和Adaboost都是集成学习方法,同异对比如下:
相似之处:
-
都是串行集成方法,通过组合多个弱学习器来构建强学习器。
-
都使用了加权策略,每个学习器都有一个权重,用于组合最终的预测结果。
-
都可以用于分类和回归问题。
区别:
- AdaBoost用错分数据点来识别问题,通过调整错分数据点的权重来改进模型。Gradient Boosting通过负梯度来识别问题,通过计算负梯度来改进模型。
- Adaboost 与 GBDT 的本质区别在于 boosting 策略的不同。Adaboost强调Adaptive(自适应),通过不断修改样本权重(增大分错样本权重,降低分对样本权重),不断加入弱分类器进行boosting,我理解为每一步都在寻找函数空间的最优解。GBDT 则是在确定损失函数后,本轮 cart 树的拟合目标就是沿着损失函数相对于前一轮组合树模型的负梯度方向进行拟合,也就是希望最快速度地最小化预测值与真实值之间的差异,使用函数空间的梯度下降逼近最优解。
讲一下SVM。SVM与LR有什么联系?
支持向量机(SVM):
-
工作原理: SVM是一种监督学习算法,其目标是找到一个最优的超平面,将不同类别的数据分开,同时使分类边界的间隔最大化。SVM可以用于二元分类问题,也可以扩展到多类分类问题。
-
损失函数: SVM的损失函数基于间隔最大化原则,通常使用了合页损失(Hinge Loss)作为其损失函数。Hinge Loss的目标是确保正确分类的样本距离分类边界足够远,以增加分类的稳定性。
-
正则化: SVM通常采用L2正则化,以防止过拟合。正则化项的强度由超参数C来控制,C越小,正则化越强,允许一些训练样本出现在分类边界之内。
-
核技巧: SVM可以使用核函数来处理非线性分类问题,将数据映射到高维空间中进行线性划分。
逻辑回归(LR):
-
工作原理: 逻辑回归是一种基于概率的分类算法,通过将输入特征的线性组合通过sigmoid函数映射到[0,1]之间的概率值,来进行分类。
-
损失函数: 逻辑回归使用对数损失(Log Loss)作为其损失函数,该损失函数用于衡量模型的预测概率与真实标签之间的差异。
-
正则化: 逻辑回归也可以采用正则化,通常使用L1或L2正则化来控制模型的复杂度。
联系和区别:
-
相似之处:
SVM和LR都是用于二元分类的算法,可以扩展到多类分类。
两者都可以使用正则化来控制模型的复杂度。
SVM和LR都可用于线性分类问题,但SVM通过核技巧可以处理非线性分类问题。
-
区别:
SVM的目标是找到一个最大间隔的超平面,以最大化分类边界的间隔,而LR的目标是最小化对数损失,以最大程度地拟合训练数据。
SVM使用Hinge Loss作为损失函数,而LR使用对数损失。
SVM的决策边界是由支持向量(样本)确定的,而LR的决策边界是根据概率确定的。
SVM在训练时更倾向于选择少数的支持向量,而LR会使用所有的训练样本。
讲一下PCA的步骤以及PCA和SVD的区别和联系。
主成分分析(PCA)是一种用于降维和特征提取的线性数据分析技术。
PCA的步骤:
-
数据中心化: 首先,对原始数据进行中心化处理,即将每个特征的均值减去相应特征的均值,以确保数据的均值为零。
-
计算协方差矩阵: 接下来,计算数据的协方差矩阵。协方差矩阵描述了数据特征之间的关联性和方差。
-
特征值分解: 对协方差矩阵进行特征值分解。特征值分解得到特征值和对应的特征向量,其中特征值表示了数据中的方差,而特征向量表示了主成分的方向。
-
选择主成分: 根据特征值的大小,选择最重要的前k个主成分,其中k通常是一个小于原始特征数量的正整数。
-
投影数据: 使用选定的主成分,将数据投影到新的低维子空间中。投影可以通过矩阵乘法来实现,新的数据点的坐标是原始数据点在主成分上的投影。
PCA与SVD的区别和联系:
-
区别:
数学基础: PCA是一种基于协方差矩阵的特征值分解方法,而SVD是一种矩阵分解方法,可以应用于不仅仅是数据降维,还可以用于矩阵分解等任务。
应用领域: PCA通常应用于数据降维、特征提取和可视化,而SVD广泛用于矩阵分解、降噪和推荐系统等领域。
-
联系:
在PCA的步骤中,特征值分解是关键的一步,它与SVD密切相关。具体来说,对协方差矩阵进行特征值分解实际上等价于对数据矩阵进行SVD分解。PCA中的特征向量对应于SVD中的右奇异向量。
在某些情况下,SVD可以用于直接执行PCA,而无需计算协方差矩阵。这可以提高计算效率,尤其是对于大型数据集。
讲一下ensemble。
集成学习(Ensemble Learning)是一种机器学习方法,旨在通过组合多个基本学习器的预测结果来提高模型的性能和鲁棒性。集成学习通过将多个模型组合在一起,可以在一定程度上减小单个模型的偏差和方差,从而提高整体性能。
基本概念:
-
基本学习器: 集成学习的基础是一组基本学习器,通常是弱学习器(模型性能略优于随机猜测)。这些基本学习器可以是不同的算法,也可以是同一算法的不同实例。
-
集成方法: 集成学习通过将多个基本学习器的预测结果进行组合,产生最终的集成预测。集成方法可以分为两大类:Bagging和Boosting。
Bagging: Bagging方法通过随机有放回地从训练数据中采样多个子集,然后在每个子集上训练一个基本学习器。最后,Bagging将多个基本学习器的预测结果进行平均或投票来得到最终预测。著名的Bagging算法包括随机森林(Random Forest)。
Boosting: Boosting方法通过迭代训练多个基本学习器,每个学习器都尝试修正前一个学习器的错误。Boosting方法通常会给予前一个学习器分类错误的样本更高的权重,以便下一个学习器能够更关注这些难以分类的样本。著名的Boosting算法包括Adaboost、Gradient Boosting、XGBoost等。
集成学习的优势:
- 提高性能: 集成学习通常能够提高模型的性能,尤其是在复杂任务和大数据集上。
- 减小过拟合: 通过组合多个模型的预测,可以减小过拟合风险,提高模型的泛化能力。
- 增强鲁棒性: 集成学习可以提高模型对噪声和异常值的鲁棒性,使模型更稳健。
偏差和方差的区别。ensemble的方法中哪些是降低偏差,哪些是降低方差?
偏差(Bias):
- 偏差是模型对真实关系的错误偏离,它表示了模型的拟合能力。
- 高偏差的模型通常对训练数据和测试数据都表现不佳,模型欠拟合(Underfitting)。
- 偏差过高可能表示模型过于简单,无法捕捉数据中的复杂关系。
方差(Variance):
- 方差是模型对训练数据的敏感度,它表示了模型的波动性。
- 高方差的模型在训练数据上表现很好,但在测试数据上可能表现不佳,模型容易过拟合(Overfitting)。
- 方差过高可能表示模型过于复杂,试图拟合训练数据中的噪声。
降低偏差和方差的方法:
-
Bagging方法(如随机森林):
Bagging方法通过训练多个基本学习器,并将它们的预测结果进行平均或投票,从而降低模型的方差。
随机森林是一种Bagging方法,通过构建多棵决策树,并对它们的结果进行组合,降低了方差。
-
Boosting方法(如Adaboost、Gradient Boosting):
Boosting方法通过迭代训练多个基本学习器,每个学习器尝试修正前一个学习器的错误,从而降低模型的偏差。
通过增加对错误分类样本的关注,Boosting方法提高了模型的拟合能力。
-
模型正则化:
正则化技术如L1和L2正则化可以帮助降低模型的复杂度,从而降低方差,并一定程度上降低偏差。
-
特征工程:
选择合适的特征和特征预处理方法可以改善模型的性能,降低偏差和方差。
什么是梯度下降?
梯度下降(Gradient Descent)是一种优化算法,用于调整模型参数以减小损失函数的值。梯度下降的核心思想是通过计算损失函数相对于模型参数的梯度(导数),然后沿着梯度的反方向逐步更新模型参数,这一步需要选择一个学习率(learning rate)来控制参数更新的步长,直到达到损失函数的局部或全局最小值。
反向传播是什么?
反向传播是一种监督学习中的优化算法,用于调整神经网络的权重和偏置,以最小化模型的损失函数。反向传播算法通过计算损失函数相对于每个模型参数的梯度,然后根据梯度的方向来更新参数,以逐渐降低损失函数的值,从而提高模型的性能。
主要思想是:
- 将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
- 由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
- 在反向传播的过程中,根据误差调整各种参数的值,不断迭代上述过程,直至收敛。
前馈神经网络(FNN)和循环神经网络(RNN)有什么区别?
- 结构区别: FNN是一种最简单的神经网络类型,由一系列前向连接的神经层组成,各层之间的连接是单向的,信息仅在一个方向上传播(输入层→隐藏层→输出层)。RNN是一种具有循环连接的神经网络,允许信息在神经网络中沿时间步传播。RNN的主要特点是隐藏层中的神经元可以接收来自前一个时间步的输出作为输入,因此可以处理序列数据,如文本、时间序列等。
- 应用区别:FNN通常用于处理静态数据,如图像分类、物体识别、语音识别等任务,它们对于输入数据之间的顺序没有明确的依赖关系,每个输入样本都是独立处理的。RNN主要用于处理序列数据,它们适用于具有时间或序列性质的数据,如NLP中的文本分析、语音合成、股票预测、机器翻译等任务。RNN通过循环连接在处理序列数据时可以捕捉数据中的时间相关性和上下文信息。
- 问题区别: FNN通常更容易训练和收敛,因为没有循环连接引入梯度消失或梯度爆炸等问题,但在处理长期依赖性或时间序列数据时表现不佳。RNN在处理时间序列数据和短期依赖性上表现出色,但在处理长期依赖性时可能受到梯度消失或梯度爆炸问题的影响。为了解决这个问题,出现了各种RNN的改进和变种,如长短时记忆网络(LSTM)和门控循环单元(GRU)。
什么是超参数?
超参数是在开始学习过程之前设置值的参数,但与模型的权重和偏置不同,超参数不是通过训练数据来学习的,而是在训练模型之前需要手动选择或调整的参数。一般我们将可以根据模型自身的算法通过数据迭代自动学习出的变量称为参数,而超参数的设置可以影响到这些参数是如何训练,所以称其为超参数。常见的有学习率lr、迭代次数epoch、批大小batch size、网络层数、正则化参数、激活函数、dropout率等。
学习率是什么?设置得太低或太高会发生什么?
学习率控制了梯度下降算法中参数更新的步长或速度,决定了在每次迭代中应该沿着梯度的反方向更新模型参数的程度。当学习率太低时,模型训练的收敛非常缓慢,因为只对权重进行最小的更新,需要多次更新才能达到最小值。如果非常小可能最终的梯度可能不会跳出局部最小值,导致训练的结果并不是最优解。如果学习率设置得太高,模型的训练不稳定,由于权重的急剧更新,可能导致模型无法收敛,损失函数发散。
什么是Dropout和Batch Normalization(批归一化BN)?
Dropout 是一种正则化技术,通过在训练过程中随机丢弃(禁用)神经网络中的一些神经元,来减少过拟合的风险。在每次训练迭代中,以一定的概率随机选择部分神经元,将它们的输出设置为零,从而使网络不依赖于某些局部特征。
Batch Normalization通过在每个batch数据上进行归一化,从而稳定训练过程并加速收敛。BN会在每个隐藏层上进行归一化,使其均值接近零并方差接近一,同时保留了网络中的非线性激活函数,有助于防止梯度消失或梯度爆炸问题。
从bagging和正则化的角度怎么理解dropout?
从Bagging的角度:
Bagging是一种集成学习方法,通过在原始数据集上多次进行有放回抽样,训练多个独立的模型(基学习器),然后通过对它们的预测进行平均或投票来提高模型的泛化性能。Dropout在每次训练迭代中随机选择一部分神经元,并将其临时关闭(将其输出置为零),而不参与前向传播和反向传播。这相当于在每次迭代中训练了一个不同的子网络,每个子网络只看到完整网络的一部分。这就类似于Bagging中的有放回抽样,每个子网络对数据的处理都是独立的,因此Dropout有助于模型的泛化,减少了过拟合风险。
从正则化的角度:
从正则化的角度来看,Dropout是一种强制模型学习更健壮特征的方法。通过在训练过程中随机关闭神经元,Dropout迫使模型不能过分依赖于某些特定的神经元,从而防止了神经元之间的共适应(co-adaptation)。这有助于减小模型对噪声数据的敏感性,提高泛化性能。此外,Dropout还可以被视为一种模型平均方法,因为在每次迭代中都会训练一个不同的子网络。这些子网络的组合可以被看作是对模型参数的一种平均估计,有助于减小参数之间的方差,进而提高模型的稳定性和泛化性能。
批量梯度下降(BGD)和随机梯度下降(SGD)的区别是什么?
BGD使用整个训练数据集来计算梯度和更新参数。在每次迭代中,它对所有训练样本进行梯度计算和参数更新。SGD在每次迭代中仅使用单个训练样本来计算梯度和更新参数。它在每次迭代中随机选择一个样本并进行更新。由于使用整个数据集,BGD的参数更新频率较低,每次迭代需要大量计算,但通常能够更稳定地收敛。SGD的参数更新频率非常高,因为它在每次迭代中只使用一个样本,因此收敛速度可能更快,但会引入更多的噪声和不稳定性。
什么是过拟合和欠拟合?如何解决?
过拟合是指模型在训练集上表现很好,但在验证集和测试集表现不好,即模型的泛化能力很差。当模型过度学习了训练数据中的细微差异和噪声,导致对新数据的预测不准确,就会发生过拟合。训练数据太少、样本噪音干扰过大、模型复杂度过高都会产生过拟合。欠拟合是指模型在训练集、验证集和测试集上均表现不佳的情况,通常发生在训练模型的数据较少且质量不佳的情况下。解决欠拟合:①增加样本数量;②增加模型参数,提高模型复杂度;③增加循环次数;④查看是否是学习率过高导致模型无法收敛。解决过拟合:①清洗数据;②减少模型参数,降低模型复杂度;③增加惩罚因子(正则化),保留所有的特征,但是减少参数的大小。
CNN中常见的层有哪些?
- 卷积层(Convolutional Layer):CNN的核心组成部分,使用卷积操作来从输入图像中提取特征,通过滑动卷积核(过滤器)在图像上进行卷积操作,生成特征图。每个卷积核可以捕捉不同的特征,如边缘、纹理等。
- 池化层(Pooling Layer): 用于减小特征图的尺寸,降低计算复杂度,并增加模型的平移不变性。常见的池化操作包括最大池化和平均池化,它们分别选择最大值或平均值来汇总局部区域的信息。
- 激活层(Activation Layer): 引入非线性,通过应用激活函数(如ReLU、Sigmoid、Tanh等)来激活卷积层或全连接层的输出,有助于模型学习非线性特征。
- 全连接层(Fully Connected Layer):将前一层的所有神经元与当前层的每个神经元相连接。在CNN的最后几层通常包括全连接层,用于进行分类或回归任务。
- 批归一化层(Batch Normalization Layer): 批归一化层用于加速训练,提高模型的稳定性,有助于防止梯度消失问题。它在每个卷积层或全连接层的输出上进行归一化,通常在激活函数之前应用。
- 卷积转置层(Convolutional Transpose Layer,也称为反卷积层): 用于上采样或反卷积操作,可以将特征图的尺寸扩展到更大的空间尺寸。
- 残差块(Residual Block): 残差块是一种特殊的层结构,用于构建深度残差网络(ResNet)。它包括跳跃连接,有助于解决深层网络中的梯度消失问题,使得可以训练非常深的模型。
CNN的“池化”是什么?它是如何运作的?
“池化”(pooling)是一种用于减小特征图尺寸并提取最重要特征的操作,通过对输入的局部区域进行汇总操作,减少特征图的维度,同时保留关键信息,有助于降低计算复杂度,减轻过拟合,并提高模型的平移不变性。Pooling的本质就是特征选择+信息过滤的过程,模型通过损失一部分信息实现与计算性能的妥协。常用的有最大池化和平均池化。
为什么max pooling要更常用?哪些情况下,average pooling比max pooling更合适?
一般来说max pooling的效果更好,虽然max pooling和average pooling都对数据做了下采样,但是max pooling保留了每个池化窗口内的最大值,从而更好地保留了图像中的显著特征,更像是做了特征选择,选出了分类辨识度更好的特征,且提供了非线性。 pooling的主要作用一方面是去掉冗余信息,一方面要保留feature map的特征信息,在分类问题中,我们需要知道的是这张图像有什么object,而不大关心这个object位置在哪,在这种情况下显然max pooling比average pooling更合适。在网络比较深的地方,特征已经稀疏了,从一块区域里选出最大的,比起这片区域的平均值来,更能把稀疏的特征传递下去。
average pooling更强调对整体特征信息进行一层下采样,在减少参数维度的贡献上更大一点,更多的体现在信息的完整传递这个维度上,在一个很大很有代表性的模型中,比如说DenseNet中的模块之间的连接大多采用average pooling,在减少维度的同时,更有利信息传递到下一个模块进行特征提取。average pooling在全局平均池化操作中应用也比较广,在ResNet和Inception结构中最后一层都使用了平均池化。有的时候在模型接近分类器的末端使用全局平均池化还可以代替Flatten操作,使输入数据变成一位向量。
LSTM中每个gate的作用是什么?为什么跟RNN相比,LSTM可以防止梯度消失?
以下是LSTM中的各个门控单元(gate)的作用:
-
输入门:
作用:决定哪些信息应该被添加到细胞状态中。
计算方式:通过输入数据和前一个隐藏状态来计算一个介于0和1之间的值,表示有多少信息应该被添加。
-
遗忘门:
作用:决定哪些信息应该从细胞状态中被遗忘。
计算方式:通过输入数据和前一个隐藏状态来计算一个介于0和1之间的值,表示有多少细胞状态中的信息应该被遗忘。
-
细胞状态更新:
作用:根据输入门的输出、遗忘门的输出和前一个细胞状态,来更新当前时间步的细胞状态。
计算方式:使用输入门的输出来决定添加多少新信息,使用遗忘门的输出来决定要从细胞状态中删除多少旧信息。
-
输出门:
作用:根据细胞状态和当前时间步的输入数据,决定当前时间步的隐藏状态。
计算方式:通过输入数据、前一个隐藏状态和细胞状态来计算一个介于0和1之间的值,表示有多少细胞状态的信息应该被输出到隐藏状态中。
相比于RNN,LSTM有以下特点:
-
遗忘门:LSTM的遗忘门允许网络选择性地遗忘先前的信息,这有助于处理长序列中的长期依赖。在传统RNN中,信息的传递方式更加简单,容易导致梯度消失或爆炸问题。
-
输入门:LSTM的输入门允许网络选择性地添加新信息到细胞状态中,这有助于捕捉当前输入的重要信息。这与传统RNN不同,传统RNN通常无法选择性地接受或拒绝输入信息。
-
细胞状态:LSTM的细胞状态充当了一个信息传输通道,信息可以在不同时间步之间流动,而不会受到过多的变换或遗忘。这有助于维护长期依赖性。
LSTM是什么?它是如何工作的?
LSTM(长短时记忆网络,Long Short-Term Memory)是RNN的变种,用于处理序列数据,特别是对于长序列和处理长期依赖性非常有效。LSTM设计的目的是解决传统RNN在处理长序列时产生的梯度消失和梯度爆炸问题,通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息,而不像普通的RNN那样只有一种记忆叠加方式。用最简洁的话讲就是,网络决定要记住/忘记什么→有选择地更新单元状态值→网络决定当前状态的哪一部分可以输出。

什么是梯度消失和梯度爆炸?
- 梯度消失: 梯度消失指的是在反向传播过程中,梯度逐渐变得非常小,接近于零。当梯度变得非常小时,权重更新几乎没有影响,导致网络的参数没有有效地更新。这通常发生在深度神经网络中,特别是在使用sigmoid或tanh等饱和性激活函数时,因为这些函数的导数在输入接近极端值时接近于零。梯度消失导致模型无法学习长期依赖性和复杂的特征,限制了网络的深度。
- 梯度弥散: 梯度弥散是梯度消失的一种特例,指的是梯度在反向传播过程中逐渐变得非常大,导致权重更新变得非常大,网络参数不稳定,甚至无法收敛。这通常发生在深度神经网络中,特别是在使用权重矩阵初始化不当、网络结构较深、梯度传播距离较长的情况下。梯度弥散会导致训练过程变得不稳定,甚至模型无法训练。
- 梯度爆炸: 梯度爆炸是梯度弥散的反面,指的是在反向传播过程中,梯度逐渐变得非常大,导致权重更新变得非常大,网络参数不稳定,甚至溢出到数值范围之外。这通常发生在深度神经网络中,特别是在使用权重矩阵初始化不当、网络结构较深、梯度传播距离较长的情况下。梯度爆炸会导致训练过程不稳定,权重值迅速增加,可能导致数值溢出或数值不稳定的情况。
CNN和RNN的梯度消失是一样的吗?
**CNN中的梯度消失:**在CNN中,梯度消失通常是由于网络层的深度引起的。当CNN变得非常深时,梯度可能会在反向传播过程中逐渐减小,导致底层的权重更新非常缓慢,甚至停滞。这在深层卷积网络中尤为明显,因为每个卷积层都引入了非线性激活函数(如ReLU),可能会导致梯度的缩小。为了解决这个问题,通常采用一些技巧,如BN和残差连接来缓解梯度消失问题。
**RNN中的梯度消失:**在RNN中,梯度消失通常与时间步数有关。RNN模型会在每个时间步重复应用相同的权重,这可能导致梯度在时间上传播时指数级减小。长序列中的信息可能在远处时间步上丢失,这被称为梯度消失问题。为了解决这个问题,引入了LSTM和GRU等结构,它们通过门控机制来控制信息的流动,从而更好地捕捉长期依赖性,避免梯度消失问题。
Epoch、Batch和Iteration的区别是什么?
- Epoch(迭代轮数):一个 epoch 表示训练集在神经网络上的一次正向传播和反向传播。在一个 epoch 中,整个训练集被输入到网络中,所有样本都用于计算损失函数和更新模型参数。训练通常需要多个 epoch 来确保模型充分学习数据的特征和模式。
- Batch(批次):由于不能一次性将整个数据集传递给神经网络,所以将数据集分批进行处理,每一批称为一个batch。
- Iteration(迭代):如果有10000张图像作为数据,batch size为200。那么一个epoch 应该运行50次iteration(10000除以50)。
batch size对收敛速度的影响。
大的batchsize减少训练时间,提高稳定性。这是肯定的,同样的epoch数目,大的batchsize需要的batch数目减少了,所以可以减少训练时间,目前已经有多篇公开论文在1小时内训练完ImageNet数据集。另一方面,大的batch size梯度的计算更加稳定,因为模型训练曲线会更加平滑。在微调的时候,大的batch size可能会取得更好的结果。
大的batchsize导致模型泛化能力下降。在一定范围内,增加batchsize有助于收敛的稳定性,但是随着batchsize的增加,模型的性能会下降。大的batchsize性能下降是因为训练时间不够长,本质上并不少batchsize的问题,在同样的epochs下的参数更新变少了,因此需要更长的迭代次数。batchsize在变得很大(超过一个临界点)时,会降低模型的泛化能力。在此临界点之下,模型的性能变换随batch size通常没有学习率敏感。
大的batchsize收敛到sharp minimum,而小的batchsize收敛到flat minimum,后者具有更好的泛化能力。两者的区别就在于变化的趋势,一个快一个慢,如下图,造成这个现象的主要原因是小的batchsize带来的噪声有助于逃离sharp minimum。

CNN做卷积运算的复杂度是怎样的?如果一个CNN网络的输入channel数目和卷积核数目都减半,总的计算量变为原来的多少?
卷积运算的复杂度:
-
输入图像的大小:如果输入图像的大小为 H × W H \times W H×W(高度 x 宽度),则输入图像的总像素数目为 H × W H \times W H×W。
-
卷积核的大小:卷积核的大小通常表示为 K h × K w K_h \times K_w Kh×Kw,其中 K h K_h Kh 表示卷积核的高度, K w K_w Kw 表示卷积核的宽度。
-
输入通道数目:如果输入图像有 C in C_{\text{in}} Cin 个通道,表示每个像素点具有 C in C_{\text{in}} Cin 个特征。
-
卷积核的数目:如果使用了 C out C_{\text{out}} Cout 个卷积核,那么每个卷积核将生成一个输出通道。
-
步幅(stride):步幅决定了卷积核在输入图像上滑动的距离,通常为 S S S。
-
填充(padding):填充可以增加输出特征图的大小,通常使用填充来控制卷积核的滑动。
卷积运算的复杂度可以计算为:
复杂度 = H × W × K h × K w × C in × C out S 2 \begin{equation} \text { 复杂度 }=\frac{H \times W \times K_h \times K_w \times C_{\text {in }} \times C_{\text {out }}}{S^2} \end{equation} 复杂度 =S2H×W×Kh×Kw×Cin ×Cout
如果没有填充,填充大小为0,步幅为1,那么复杂度可以简化为:
复杂度 = H × W × K h × K w × C in × C out \begin{equation} \text { 复杂度 }=H \times W \times K_h \times K_w \times C_{\text {in }} \times C_{\text {out }} \end{equation} 复杂度 =H×W×Kh×Kw×Cin ×Cout
减半输入通道数目和卷积核数目的影响:
如果输入通道数目和卷积核数目都减半,那么总的计算量将减少为原来的多少?
假设原始的计算量为
C in × C out × 复杂度 C_{\text{in}} \times C_{\text{out}} \times \text{复杂度} Cin×Cout×复杂度
如果将输入通道数目和卷积核数目都减半,那么新的计算量为:
1 2 × 1 2 × C i n × C o u t × 复杂度 = 1 4 × C i n × C o u t × 复杂度 \begin{equation} \frac{1}{2} \times \frac{1}{2} \times C_{\mathrm{in}} \times C_{\mathrm{out}} \times \text { 复杂度 }=\frac{1}{4} \times C_{\mathrm{in}} \times C_{\mathrm{out}} \times \text { 复杂度 } \end{equation} 21×21×Cin×Cout× 复杂度 =41×Cin×Cout× 复杂度
data augmentation有哪些技巧?
数据增强(Data Augmentation)是一种在训练深度学习模型时扩展训练数据集的技术,它通过对原始数据进行一系列变换来生成新的训练样本,从而增加数据的多样性,有助于提高模型的泛化性能。常见技巧:
-
随机裁剪:从原始图像中随机选择一个区域,调整其大小以获得新的图像,使模型对不同物体位置的变化更具鲁棒性。
-
随机翻转:随机对图像进行水平翻转或垂直翻转,以生成镜像图像,从而增加数据的多样性,提高模型的旋转不变性。
-
随机旋转:对图像进行随机旋转一定角度,以模拟不同拍摄角度或角度变化,使模型对旋转变换具有鲁棒性。
-
色彩扰动:随机改变图像的亮度、对比度、饱和度和色调等颜色属性,以生成具有不同颜色变化的图像。
-
添加噪声:向图像中添加随机噪声,如高斯噪声或椒盐噪声,以提高模型对噪声的鲁棒性。
-
缩放:随机缩放图像的尺寸,可以将图像放大或缩小,以模拟不同大小的物体或图像分辨率。
-
变形:对图像进行随机形变,如拉伸、扭曲或弯曲,以模拟不同形状变化的情况。
-
随机剪切:在图像中随机选择一个区域,并对该区域进行剪切,以生成不同部分的图像,增加多样性。
-
混合数据:将两个或多个图像混合在一起,生成新的图像,同时混合标签,以增加数据的多样性。
-
自动增强:使用自动增强算法来确定一组增强操作和参数,以最大程度地提高数据的多样性。
介绍优化方法sgd、momentum、rmsprop、adam,并说出区别和联系。
-
SGD(随机梯度下降):
SGD是最基本的优化方法,在每个训练步骤中仅使用一个随机选择的样本进行权重更新。SGD具有高度随机性,因为每个样本都可以导致权重的变化;同时可能会收敛较慢,因为它在训练过程中可能会出现震荡。
-
Momentum(动量优化):
Momentum加入了惯性,使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
-
RMSprop:
RMSprop采用移动平均的方式来调整学习率,对每个参数的学习率进行适应性调整。改变了二阶动量计算方法,即用窗口滑动加权平均值计算二阶动量。
-
Adam(自适应矩估计优化):
Adam集成了SGD的一阶动量和RMSProp的二阶动量,不仅具有动量项,还具有自适应学习率调整。
如果训练的神经网络不收敛,可能有哪些原因?
- 没有对数据进行归一化
- 忘记检查输入和输出
- 没有对数据进行预处理
- 没有对数据正则化
- 使用过大的样本
- 使用不正确的学习率
- 在输出层使用错误的激活函数
- 网络中包含坏梯度
- 初始化权重错误
- 过深的网络
- 隐藏单元数量错误
- 网络设计不合理(任务-网络不匹配)
怎么理解卷积核? 1x1的卷积核有什么作用?
卷积核也称为滤波器,在CNN中是用于从输入数据中提取特征的小型矩阵或过滤器。卷积核在卷积层中滑动或卷积于输入数据,将其与卷积核的权重进行点乘运算,并将结果累加,从而生成输出特征图。
卷积核通常具有以下特点:
- 尺寸:卷积核的大小通常是正方形,如3x3、5x5等,但也可以是矩形。
- 深度:卷积核的深度必须与输入数据的通道数相匹配,以便进行逐通道的卷积运算。
- 权重参数:卷积核的每个元素都是模型需要学习的权重参数,用于从输入数据中提取特征。
1x1卷积核的作用包括:
- 通过控制卷积核个数实现升维/降维,从而减少模型参数和计算量
- 用于不同channel上特征的融合
- 1x1的卷积相当于全连接层的计算过程,并且加入了非线性激活函数,从而增加了网络的非线性,使得网络可以表达更加复杂的特征。
23、3x3卷积核和5x5卷积核相比的优点?
两个3x3的卷积核的感受野比5x5的卷积核的感受野大,在保持相同感受野的同时,用3x3的卷积核可以提升网络的深度,可以很明显的减少计算量。
CNN在图像中的广泛应用的原因 ?
- 局部连接
- 权值共享:减小参数量
- 池化操作:增大感受野
- 多层次结构:可以提取low-level以及high-level的信息
CNN不适用的场景。
- 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
- 数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
深度学习框架中的张量是什么意思?
张量(Tensor)是一种多维数组数据结构,是深度学习计算的基本数据单元。张量可以看作是高维数组,可以包含标量(0维张量,也就是单个数字)、向量(1维张量,如一维数组)、矩阵(2维张量,如二维数组)以及更高维的数据。
还有一件事
以上的内容会持续更新,兄弟们可以多多关注~ 后续还会更新手推系列(softmax/BN/BP等)、模型分析系列、大模型系列。算法的内容多且晦涩,我尽量整理成相对容易理解记忆的形式,先不谈能不能吃透,起码可以应对面试。
相关文章:
算法面试八股文『 基础知识篇 』
博客介绍 近期在准备算法面试,网上信息杂乱不规整,出于强迫症就自己整理了算法面试常出现的考题。独乐乐不如众乐乐,与其奖励自己,不如大家一起嗨。以下整理的内容可能有不足之处,欢迎大佬一起讨论。 PS:…...
docker-学习-4
docker学习第四天 docker学习第四天1. 回顾1.1. 容器的网络类型1.2. 容器的本质1.3. 数据的持久化1.4. 看有哪些卷1.5. 看卷的详细信息 2. 如何做多台宿主机里的多个容器之间的数据共享2.1. 概念2.2. 搭NFS服务器实现多个容器之间的数据共享的详细步骤2.3. 如果是多台机器&…...
el-upload子组件上传多张图片(上传为files或base64url)
场景: 在表单页,有图片需要上传,表单的操作行按钮中有上传按钮,点击上传按钮。 弹出el-dialog进行图片的上传,可以上传多张图片。 由于多个表单页都有上传多张图片的操作,因此将上传多图的el-upload定义…...

2024美赛数学建模C题思路源码——网球选手的动量
这题挺有意思,没具体看比赛情况,打过比赛的人应该都知道险胜局(第二局、第五局逆转局)最影响心态的,导致第3、5局输了 模型结果需要证明这样的现象 赛题目的 赛题目的:分析网球球员的表现 问题一.球员在比赛特定时间表现力 问题分析 excel数据:每个时间段有16场比赛,…...

金三银四_程序员怎么写简历_写简历网站
你们在制作简历时,是不是基本只关注两件事:简历模板,还有基本信息的填写。 当你再次坐下来更新你的简历时,可能会发现自己不自觉地选择了那个“看起来最好看的模板”,填写基本信息,却没有深入思考如何使简历更具吸引力。这其实是一个普遍现象:许多求职者仍停留在传统简历…...

echarts条形图添加滚动条
效果展示: 测试数据: taskList:[{majorDeptName:测试,finishCount:54,notFinishCount:21}, {majorDeptName:测试,finishCount:54,notFinishCount:21}, {majorDeptName:测试,finishCount:54,notFinishCount:21}, {majorDeptName:测试,finishCount:54,notFinishCount:21}, {maj…...

Java 使用Soap方式调用WebService接口
pom文件依赖 <dependencies><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.13.0</version></dependency><!-- https://mvnrepository.com/artif…...

2024美赛数学建模所有题目思路分析
美赛思路已更新,关注后可以获取更多思路。并且领取资料 C题思路 首先,我们要理解势头是什么。简单来说,势头是一方在比赛中因一系列事件而获得的动力或优势。在网球中,这可能意味着连续赢得几个球,或是在比赛的某个关…...

Docker容器引擎(5)
目录 一.docker-compose docker-compose的三大概念: yaml文件格式: json文件格式: docker-compose 配置模板文件常用的字段: 二.Docker Compose 环境安装: 查看版本: 准备好nginx 的dockerfile的文…...
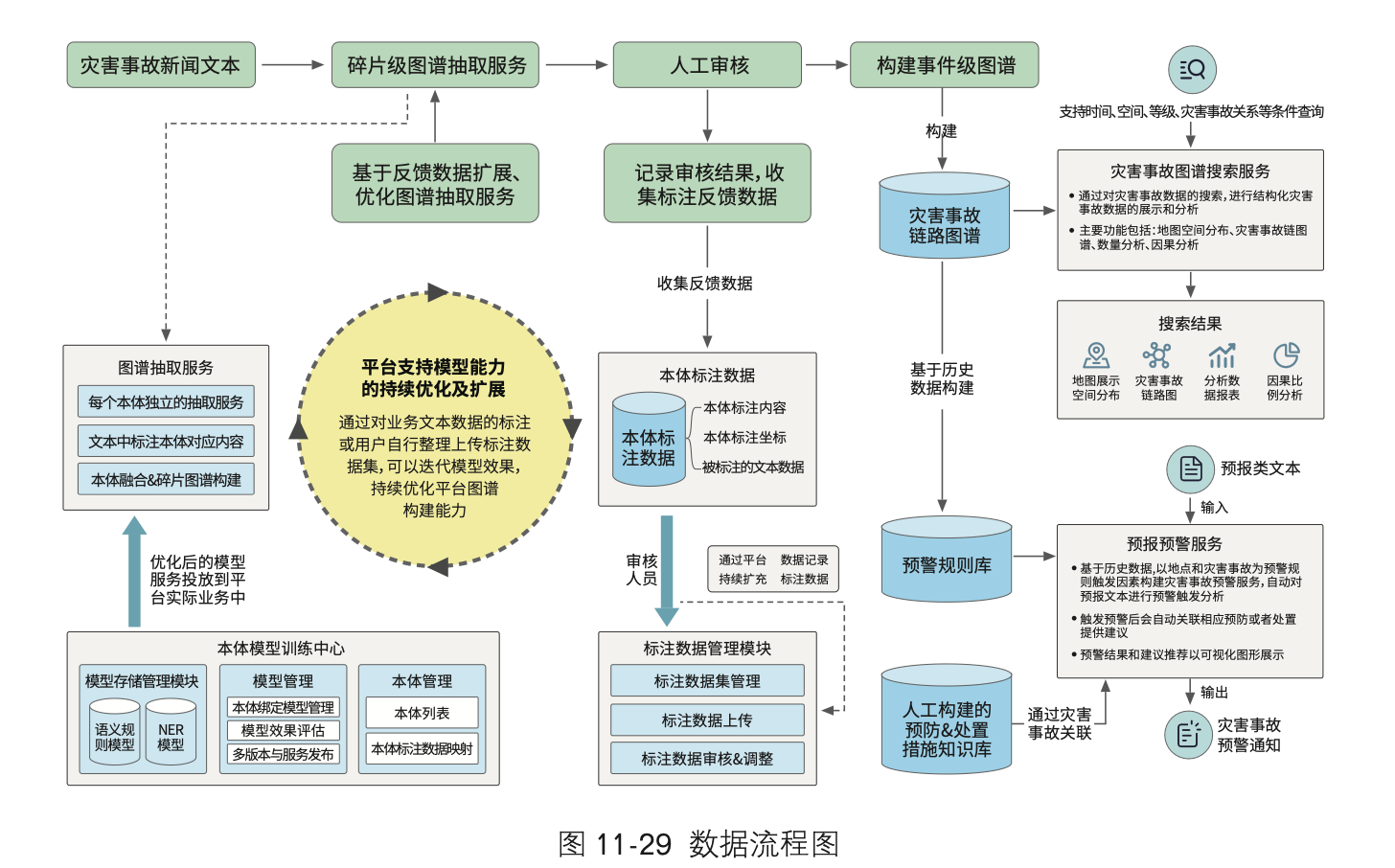
百分点科技:《数据科学技术: 文本分析和知识图谱》
科技进步带来的便利已经渗透到工作生活的方方面面,ChatGPT的出现更是掀起了新一波的智能化浪潮,推动更多智能应用的涌现。这背后离不开一个朴素的逻辑,即对数据的收集、治理、建模、分析和应用,这便是数据科学所重点研究的对象——…...
LabVIEW传感器通用实验平台
LabVIEW传感器通用实验平台 介绍了基于LabVIEW的传感器实验平台的开发。该平台利用LabVIEW图形化编程语言和多参量数据采集卡,提供了一个交互性好、可扩充性强、使用灵活方便的传感器技术实验环境。 系统由硬件和软件两部分组成。硬件部分主要包括多通道数据采集卡…...
向日葵企业“云策略”升级 支持Android 被控策略设置
此前,贝锐向日葵推出了适配PC企业客户端的云策略功能,这一功能支持管理平台统一修改设备设置,上万设备实时下发实时生效,很好的解决了当远程控制方案部署后,想要灵活调整配置需要逐台手工操作的痛点,大幅提…...

51单片机通过级联74HC595实现倒计时秒表Protues仿真设计
一、设计背景 近年来随着科技的飞速发展,单片机的应用正在不断的走向深入。本文阐述了51单片机通过级联74HC595实现倒计时秒表设计,倒计时精度达0.05s,解决了传统的由于倒计时精度不够造成的误差和不公平性,是各种体育竞赛的必备设…...

深信服技术认证“SCCA-C”划重点:深信服云计算关键技术
为帮助大家更加系统化地学习云计算知识,高效通过云计算工程师认证,深信服特推出“SCCA-C认证备考秘笈”,共十期内容。“考试重点”内容框架,帮助大家快速get重点知识。 划重点来啦 *点击图片放大展示 深信服云计算认证(…...

Redis stream特性了解
在发布订阅中我们了解到发布订阅模式存在的无法持久化保存消息和对于离线重连的客户端不能读取历史消息的缺陷,以下就来了解一下stream是如何解决这个问题的 steam是类似于仅添加log的数据结构,提供了以下基本命令 XADD: 添加新条目到stream # 语法xadd…...

苍穹外卖项目可以写的简历和如何优化简历
文章目录 重点写中规写添加自己个性的项目面试会问道的问题 我是一名双非大二计算机本科生,希望我的分享对你有帮助,点赞关注不迷路。 简历编写一直是很多人求职人的心病,我自己上学期有一门课程是去校内企业面试,当时我就感受出…...

C++:智能指针
C在用引用取缔掉指针的同时,模板的引入带给了指针新的发挥空间 智能指针简单的来说就是带有不同特性和内存管理的指针模板 unique_ptr 1.不能有多个对象指向一块内存 2.对象释放时内部指针指向地址也随之释放 3.对象内数据只能通过接口更改绑定 4.对象只能接收右值…...
用户界面(UI)、用户体验(UE)和用户体验(UX)的差异
对一个应用程序而言,UX/UE (user experience) 设计和 UI (user interface) 设计非常重要。UX设计包括可视化布局、信息结构、可用性、图形、互动等多个方面。UI设计也属于UX范畴。正是因为三者在一定程度上具有重叠的工作内容,很多从业多年的设计师都分不…...
react 之 UseReducer
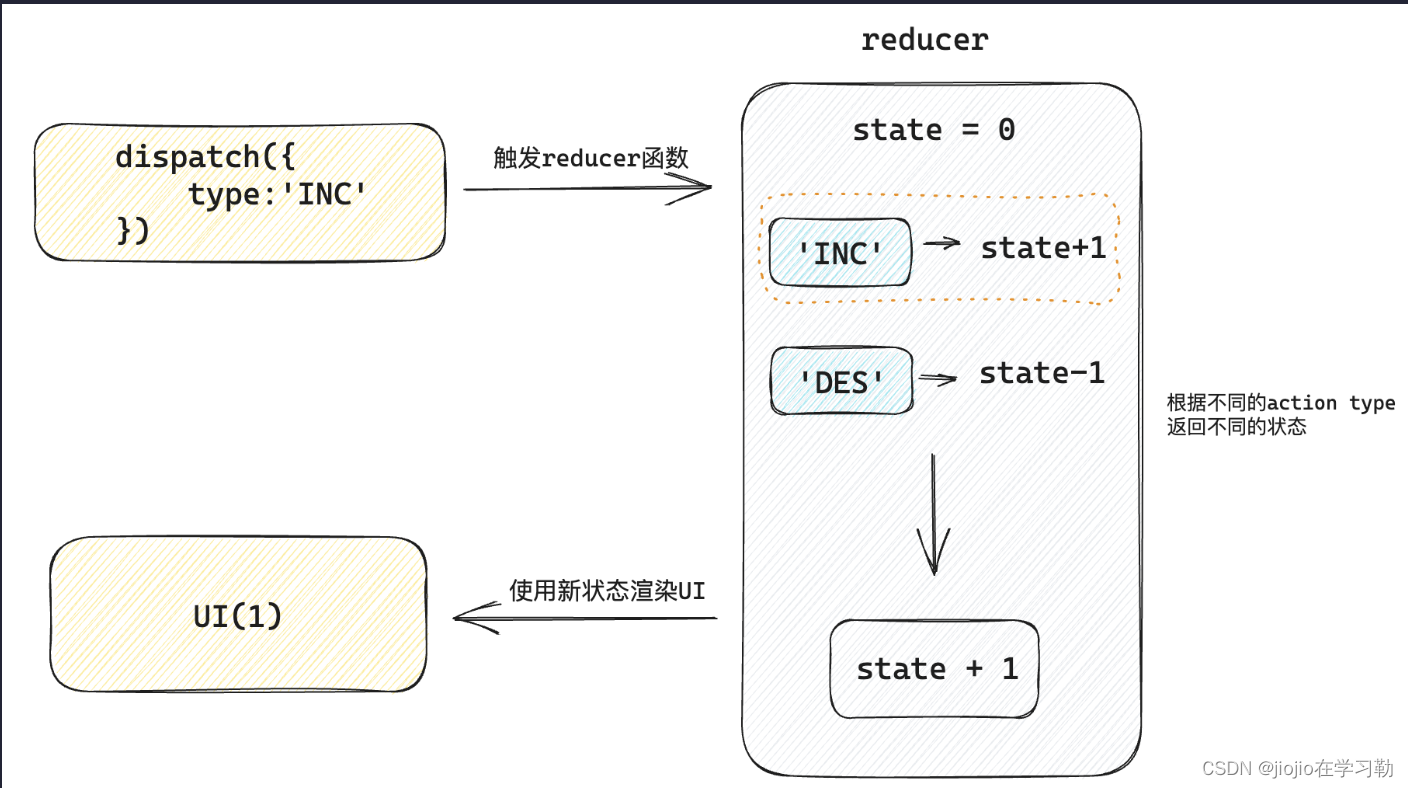
UseReducer作用: 让 React 管理多个相对关联的状态数据 import { useReducer } from react// 1. 定义reducer函数,根据不同的action返回不同的新状态 function reducer(state, action) {switch (action.type) {case INC:return state 1case DEC:return state - 1de…...

C++:this隐藏参数
你是否有一个问题:C中成员函数中究竟是如何访问成员变量的? 其实了解后回答起来这个问题很简单,通过一个不受限的隐藏参数this,this是类的指针,通过它可以访问到类内的各种成员。 明白了这个问题就很好理解ÿ…...

snnTorch NIR导出功能详解:实现跨框架模型转换
snnTorch NIR导出功能详解:实现跨框架模型转换 【免费下载链接】snntorch Deep and online learning with spiking neural networks in Python 项目地址: https://gitcode.com/gh_mirrors/sn/snntorch snnTorch是一个基于Python的脉冲神经网络(SN…...

为什么 AI 多智能体系统最终都会遇到“混乱边界”?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

AI编程工具 Codex 入门教程,带你7分钟上手 Codex !
大家好,我是程序员小灰。前一段时间,Anthropic旗下的AI编程工具 Claude Code 火了,小灰也为大家制作了Claude Code 相关的视频教程,得到了很多读者的肯定。尽管Claude Code很强大,但存在一个致命的问题,就是…...
掌握AI视频制作:Pixelle-Video智能创作平台实战指南
掌握AI视频制作:Pixelle-Video智能创作平台实战指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 你是否曾经梦想过拥有一…...

端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践
端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践 【免费下载链接】wekws Production First and Production Ready End-to-End Keyword Spotting Toolkit 项目地址: https://gitcode.com/gh_mirrors/we/wekws 在物联网设备普及的今天&#x…...

软件测试的“测开分离”趋势,是机遇还是陷阱
一、测开分离:软件测试行业的新变局在软件测试行业的发展历程中,角色的边界一直在悄然演变。从早期手工测试独挑大梁,到自动化测试兴起后测试人员开始涉足简单代码编写,再到如今测试开发工程师岗位的独立,测试与开发的…...

在OpenClaw项目中集成Taotoken实现Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw项目中集成Taotoken实现Agent工作流 对于使用OpenClaw框架构建AI Agent的开发者而言,一个稳定、便捷的模型服…...

UMA Unity角色系统深度解析:运行时人体编译器架构与跨平台实践
1. 为什么UMA不是“装上就能用”的Avatar系统——从三个典型失败案例说起我第一次在项目里引入Unity Multipurpose Avatar(UMA)时,信心满满地拖进Package Manager,点完Import,打开Demo场景,结果角色模型直接…...

3个实战技巧:用GitHub社区徽章系统打造你的开发者影响力
3个实战技巧:用GitHub社区徽章系统打造你的开发者影响力 【免费下载链接】community Public feedback discussions for: GitHub Mobile, GitHub Discussions, GitHub Codespaces, GitHub Sponsors, GitHub Issues and more! 项目地址: https://gitcode.com/gh_mir…...

在Node.js服务中集成Taotoken实现多模型智能对话
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现多模型智能对话 应用场景类,描述一个Node.js后端服务需要集成大模型能力的场景&#…...