【Spark实践6】特征转换FeatureTransformers实践Scala版--补充算子
本节介绍了用于处理特征的算法,大致可以分为以下几组:
- 提取(Extraction):从“原始”数据中提取特征。
- 转换(Transformation):缩放、转换或修改特征。
- 选择(Selection):从更大的特征集中选择一个子集。
- 局部敏感哈希(Locality Sensitive Hashing, LSH):这类算法结合了特征转换的方面与其他算法。
Feature Transformers
IndexToString
对应于StringIndexer,IndexToString将一个标签索引列映射回一个包含原始字符串标签的列。一个常见的用例是使用StringIndexer从标签生成索引,用这些索引训练模型,并使用IndexToString从预测的索引列检索原始标签。然而,你可以自由提供你自己的标签。
示例
基于StringIndexer的例子,假设我们有以下包含列id和categoryIndex的DataFrame:
| id | categoryIndex |
|---|---|
| 0 | 0.0 |
| 1 | 2.0 |
| 2 | 1.0 |
| 3 | 0.0 |
| 4 | 0.0 |
| 5 | 1.0 |
应用IndexToString,以categoryIndex作为输入列,originalCategory作为输出列,我们能够检索我们的原始标签(它们将从列的元数据中推断出来):
| id | categoryIndex | originalCategory |
|---|---|---|
| 0 | 0.0 | a |
| 1 | 2.0 | b |
| 2 | 1.0 | c |
| 3 | 0.0 | a |
| 4 | 0.0 | a |
| 5 | 1.0 | c |
import org.apache.spark.ml.attribute.Attribute
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}
import org.apache.spark.sql.SparkSessionobject IndexToStringExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("IndexToStringExample").getOrCreate()val df = spark.createDataFrame(Seq((0, "a"),(1, "b"),(2, "c"),(3, "a"),(4, "a"),(5, "c"))).toDF("id", "category")val indexer = new StringIndexer().setInputCol("category").setOutputCol("categoryIndex").fit(df)val indexed = indexer.transform(df)println(s"Transformed string column '${indexer.getInputCol}' " +s"to indexed column '${indexer.getOutputCol}'")indexed.show()val inputColSchema = indexed.schema(indexer.getOutputCol)println(s"StringIndexer will store labels in output column metadata: " +s"${Attribute.fromStructField(inputColSchema).toString}\n")val converter = new IndexToString().setInputCol("categoryIndex").setOutputCol("originalCategory")val converted = converter.transform(indexed)println(s"Transformed indexed column '${converter.getInputCol}' back to original string " +s"column '${converter.getOutputCol}' using labels in metadata")converted.select("id", "categoryIndex", "originalCategory").show()spark.stop()}
}
OneHotEncoder
One-hot encoding 将一个表示为标签索引的分类特征映射到一个二进制向量中,该向量最多只有一个值为1,表示在所有特征值中存在某个特定的特征值。这种编码允许期望连续特征的算法,如逻辑回归,使用分类特征。对于字符串类型的输入数据,通常首先使用StringIndexer对分类特征进行编码。
OneHotEncoder可以转换多个列,为每个输入列返回一个独热编码的输出向量列。通常使用VectorAssembler将这些向量合并成一个单一的特征向量。
OneHotEncoder支持handleInvalid参数,以选择在转换数据时如何处理无效输入。可用的选项包括’keep’(任何无效输入都被分配到一个额外的分类索引)和’error’(抛出一个错误)。
import org.apache.spark.ml.feature.OneHotEncoder
import org.apache.spark.sql.SparkSessionobject OneHotEncoderExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("OneHotEncoderExample").getOrCreate()val df = spark.createDataFrame(Seq((0.0, 1.0),(1.0, 0.0),(2.0, 1.0),(0.0, 2.0),(0.0, 1.0),(2.0, 0.0))).toDF("categoryIndex1", "categoryIndex2")val encoder = new OneHotEncoder().setInputCols(Array("categoryIndex1", "categoryIndex2")).setOutputCols(Array("categoryVec1", "categoryVec2"))val model = encoder.fit(df)val encoded = model.transform(df)encoded.show()spark.stop()}
}VectorIndexer
VectorIndexer帮助在向量数据集中索引分类特征。它既可以自动决定哪些特征是分类的,也可以将原始值转换为类别索引。具体来说,它执行以下操作:
接受一个类型为Vector的输入列和一个参数maxCategories。
根据不同值的数量决定哪些特征应该被视为分类特征,其中最多具有maxCategories的特征被声明为分类特征。
为每个分类特征计算基于0的类别索引。
索引分类特征并将原始特征值转换为索引。
索引分类特征允许算法如决策树和树集合等正确处理分类特征,从而提高性能。
示例
在下面的示例中,我们读入一个标记点的数据集,然后使用VectorIndexer决定哪些特征应该被视为分类特征。我们将分类特征值转换为它们的索引。然后可以将这些转换后的数据传递给处理分类特征的算法,如DecisionTreeRegressor。
import org.apache.spark.ml.feature.VectorIndexer
import org.apache.spark.sql.SparkSessionobject VectorIndexerExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("VectorIndexerExample").getOrCreate()val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")val indexer = new VectorIndexer().setInputCol("features").setOutputCol("indexed").setMaxCategories(10)val indexerModel = indexer.fit(data)val categoricalFeatures: Set[Int] = indexerModel.categoryMaps.keys.toSetprintln(s"Chose ${categoricalFeatures.size} " +s"categorical features: ${categoricalFeatures.mkString(", ")}")val indexedData = indexerModel.transform(data)indexedData.show()spark.stop()}
}
Interaction
Interaction是一个转换器,它接受向量或双精度值列,并生成一个单独的向量列,包含来自每个输入列的一个值的所有组合的乘积。
例如,如果你有两个向量类型的列,每个列有3个维度作为输入列,那么你将得到一个9维的向量作为输出列。
示例
假设我们有以下带有列“id1”、“vec1”和“vec2”的DataFrame:
| id1 | vec1 | vec2 |
|---|---|---|
| 1 | [1.0,2.0,3.0] | [8.0,4.0,5.0] |
| 2 | [4.0,3.0,8.0] | [7.0,9.0,8.0] |
| 3 | [6.0,1.0,9.0] | [2.0,3.0,6.0] |
| 4 | [10.0,8.0,6.0] | [9.0,4.0,5.0] |
| 5 | [9.0,2.0,7.0] | [10.0,7.0,3.0] |
| 6 | [1.0,1.0,4.0] | [2.0,8.0,4.0] |
应用Interaction到这些输入列后,输出列interactedCol将包含:
| id1 | vec1 | vec2 | interactedCol |
|---|---|---|---|
| 1 | [1.0,2.0,3.0] | [8.0,4.0,5.0] | [8.0,4.0,5.0,16.0,8.0,10.0,24.0,12.0,15.0] |
| 2 | [4.0,3.0,8.0] | [7.0,9.0,8.0] | [56.0,72.0,64.0,42.0,54.0,48.0,112.0,144.0,128.0] |
| 3 | [6.0,1.0,9.0] | [2.0,3.0,6.0] | [36.0,54.0,108.0,6.0,9.0,18.0,54.0,81.0,162.0] |
| 4 | [10.0,8.0,6.0] | [9.0,4.0,5.0] | [360.0,160.0,200.0,288.0,128.0,160.0,216.0,96.0,120.0] |
| 5 | [9.0,2.0,7.0] | [10.0,7.0,3.0] | [450.0,315.0,135.0,100.0,70.0,30.0,350.0,245.0,105.0] |
| 6 | [1.0,1.0,4.0] | [2.0,8.0,4.0] | [12.0,48.0,24.0,12.0,48.0,24.0,48.0,192.0,96.0] |
import org.apache.spark.ml.feature.{Interaction, VectorAssembler}
import org.apache.spark.sql.SparkSessionobject InteractionExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("InteractionExample").getOrCreate()val df = spark.createDataFrame(Seq((1, 1, 2, 3, 8, 4, 5),(2, 4, 3, 8, 7, 9, 8),(3, 6, 1, 9, 2, 3, 6),(4, 10, 8, 6, 9, 4, 5),(5, 9, 2, 7, 10, 7, 3),(6, 1, 1, 4, 2, 8, 4))).toDF("id1", "id2", "id3", "id4", "id5", "id6", "id7")val assembler1 = new VectorAssembler().setInputCols(Array("id2", "id3", "id4")).setOutputCol("vec1")val assembled1 = assembler1.transform(df)val assembler2 = new VectorAssembler().setInputCols(Array("id5", "id6", "id7")).setOutputCol("vec2")val assembled2 = assembler2.transform(assembled1).select("id1", "vec1", "vec2")val interaction = new Interaction().setInputCols(Array("id1", "vec1", "vec2")).setOutputCol("interactedCol")val interacted = interaction.transform(assembled2)interacted.show(truncate = false)spark.stop()}
}
Normalizer
Normalizer是一个转换器,它可以转换包含向量行的数据集,将每个向量规范化为单位范数。它接受参数p,该参数指定用于规范化的p-范数。(默认情况下,p=2。)这种规范化可以帮助标准化输入数据并改善学习算法的行为。
示例
以下示例演示了如何加载libsvm格式的数据集,然后将每行规范化为单位L1范数和单位L∞范数。
import org.apache.spark.ml.feature.Normalizer
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSessionobject NormalizerExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("NormalizerExample").getOrCreate()val dataFrame = spark.createDataFrame(Seq((0, Vectors.dense(1.0, 0.5, -1.0)),(1, Vectors.dense(2.0, 1.0, 1.0)),(2, Vectors.dense(4.0, 10.0, 2.0)))).toDF("id", "features")val normalizer = new Normalizer().setInputCol("features").setOutputCol("normFeatures").setP(1.0)val l1NormData = normalizer.transform(dataFrame)println("Normalized using L^1 norm")l1NormData.show()val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity)println("Normalized using L^inf norm")lInfNormData.show()spark.stop()}
}
StandardScaler
StandardScaler是一个转换器,用于转换包含向量行的数据集,规范化每个特征以具有单位标准差和/或零均值。它接受以下参数:
withStd:默认为True。将数据缩放到单位标准差。
withMean:默认为False。在缩放之前将数据中心化到均值。这将生成一个密集的输出,因此在应用于稀疏输入时要小心。
StandardScaler是一个估计器,可以在数据集上进行拟合,以产生StandardScalerModel;这相当于计算摘要统计信息。然后模型可以转换数据集中的一个向量列,使其特征具有单位标准差和/或零均值。
请注意,如果一个特征的标准差为零,那么该特征在向量中将返回默认的0.0值。
示例
以下示例演示了如何加载一个libsvm格式的数据集,然后规范化每个特征以具有单位标准差。
import org.apache.spark.ml.feature.StandardScaler
import org.apache.spark.sql.SparkSessionobject StandardScalerExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("StandardScalerExample").getOrCreate()val dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")val scaler = new StandardScaler().setInputCol("features").setOutputCol("scaledFeatures").setWithStd(true).setWithMean(false)// Compute summary statistics by fitting the StandardScaler.val scalerModel = scaler.fit(dataFrame)// Normalize each feature to have unit standard deviation.val scaledData = scalerModel.transform(dataFrame)scaledData.show()spark.stop()}
}
以下简单介绍以下,就不粘贴代码实例了,如果有需要,请评论区留言,我发你项目
RobustScaler
RobustScaler是一个转换器,它转换包含向量行的数据集,去除中位数并根据特定的分位数范围(默认为IQR:四分位距,即第一四分位数与第三四分位数之间的范围)来缩放数据。它的行为与StandardScaler相似,但是使用中位数和分位数范围代替均值和标准差,这使得它对异常值具有鲁棒性。它接受以下参数:
- lower:默认为0.25。用于计算分位数范围的下四分位数,由所有特征共享。
- upper:默认为0.75。用于计算分位数范围的上四分位数,由所有特征共享。
- withScaling:默认为True。将数据缩放到分位数范围。
- withCentering:默认为False。在缩放之前用中位数中心化数据。这将生成一个密集的输出,因此在应用于稀疏输入时要小心。
- RobustScaler是一个估计器,可以在数据集上进行拟合,以产生RobustScalerModel;这相当于计算分位数统计信息。然后模型可以转换数据集中的一个向量列,使其特征具有单位分位数范围和/或零中位数。
请注意,如果一个特征的分位数范围为零,那么该特征在向量中将返回默认的0.0值。
MinMaxScaler
MinMaxScaler是一个转换器,它将包含向量行的数据集的每个特征重新缩放到特定范围(通常是[0, 1])。它接受以下参数:
- min:默认为0.0。转换后的下界,由所有特征共享。
- max:默认为1.0。转换后的上界,由所有特征共享。
- MinMaxScaler在数据集上计算摘要统计,并产生一个MinMaxScalerModel。然后,该模型可以单独转换每个特征,使其位于给定范围内。
特征E的重新缩放值按以下方式计算:
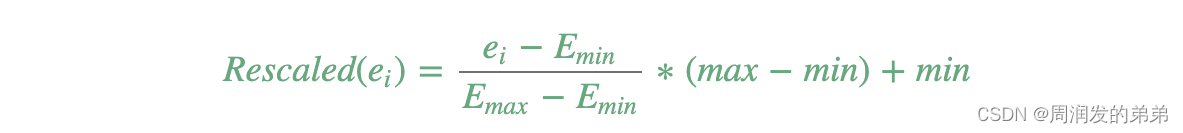
MaxAbsScaler
MaxAbsScaler是一种转换器,它通过每个特征中的最大绝对值将包含向量行的数据集的每个特征重新缩放到范围[-1, 1]。它不会平移/居中数据,因此不会破坏任何稀疏性。
MaxAbsScaler在数据集上计算摘要统计,并产生一个MaxAbsScalerModel。然后,该模型可以单独将每个特征转换到范围[-1, 1]内。
Bucketizer
Bucketizer是一种转换器,它将连续特征的列转换为特征桶的列,其中桶由用户指定。它接受一个参数:
splits:用于将连续特征映射到桶的参数。有n+1个分割点时,就有n个桶。由分割点x,y定义的桶包含范围[x,y)内的值,除了最后一个桶,它还包括y。分割点应该是严格递增的。必须明确提供-inf和inf的值以覆盖所有Double值;否则,未指定分割点范围外的值将被视为错误。分割点的两个示例是Array(Double.NegativeInfinity, 0.0, 1.0, Double.PositiveInfinity)和Array(0.0, 1.0, 2.0)。
请注意,如果您不知道目标列的上下界限,您应该添加Double.NegativeInfinity和Double.PositiveInfinity作为分割点的边界,以防止潜在的Bucketizer边界异常。
还要注意,您提供的分割点必须是严格递增的顺序,即s0 < s1 < s2 < … < sn。
更多细节可以在Bucketizer的API文档中找到。
ElementwiseProduct
ElementwiseProduct 通过元素间的乘法,将每个输入向量乘以一个给定的“权重”向量。换言之,它通过一个标量乘数来缩放数据集的每一列。这代表了输入向量v与变换向量w之间的哈达马德积(Hadamard product),以产生一个结果向量。
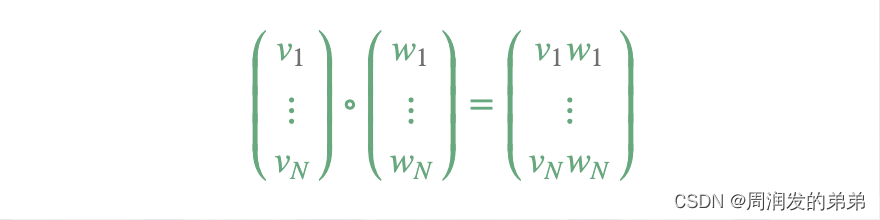
SQLTransformer
SQLTransformer 实现了由 SQL 语句定义的转换。目前,我们只支持类似 “SELECT … FROM THIS …” 的 SQL 语法,其中 “THIS” 代表输入数据集的底层表格。SELECT 子句指定了在输出中显示的字段、常量和表达式,可以是 Spark SQL 支持的任何 SELECT 子句。用户还可以使用 Spark SQL 内置函数和用户定义的函数(UDFs)对这些选定的列进行操作。例如,SQLTransformer 支持如下语句:
- SELECT a, a + b AS a_b FROM THIS
- SELECT a, SQRT(b) AS b_sqrt FROM THIS WHERE a > 5
- SELECT a, b, SUM© AS c_sum FROM THIS GROUP BY a, b
示例
假设我们有以下带有列 id、v1 和 v2 的 DataFrame:
| id | v1 | v2 |
|---|---|---|
| 0 | 1.0 | 3.0 |
| 2 | 2.0 | 5.0 |
这是使用语句 “SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM THIS” 的 SQLTransformer 的输出:
| id | v1 | v2 | v3 | v4 |
|---|---|---|---|---|
| 0 | 1.0 | 3.0 | 4.0 | 3.0 |
| 2 | 2.0 | 5.0 | 7.0 | 10.0 |
VectorAssembler
VectorAssembler 是一个转换器,它将给定的列列表组合成一个单独的向量列。它对于将原始特征和由不同特征转换器生成的特征组合成一个单一的特征向量非常有用,以便训练像逻辑回归和决策树这样的机器学习模型。VectorAssembler 接受以下输入列类型:所有数值类型、布尔类型和向量类型。在每一行中,输入列的值将按指定的顺序连接成一个向量。
VectorSizeHint
有时候,明确指定VectorType列的向量大小是有用的。例如,VectorAssembler 使用其输入列的大小信息来生成其输出列的大小信息和元数据。虽然在某些情况下可以通过检查列的内容来获取这些信息,在流数据框架中,直到流启动之前,内容是不可用的。VectorSizeHint 允许用户明确指定列的向量大小,这样 VectorAssembler 或可能需要知道向量大小的其他转换器就可以使用该列作为输入。
要使用 VectorSizeHint,用户必须设置 inputCol 和 size 参数。将此转换器应用于数据框将产生一个具有更新的元数据的新数据框,为 inputCol 指定了向量大小。对结果数据框进行的下游操作可以使用元数据来获取这个大小。
VectorSizeHint 还可以接受一个可选的 handleInvalid 参数,该参数控制当向量列包含空值或错误大小的向量时的行为。默认情况下,handleInvalid 被设置为“error”,表示应该抛出异常。这个参数也可以设置为“skip”,表示应该从结果数据框中过滤掉包含无效值的行,或者“optimistic”,表示不应该检查列中的无效值,并且应该保留所有行。请注意,使用“optimistic”可能会导致结果数据框处于不一致的状态,这意味着 VectorSizeHint 应用于的列的元数据与该列的内容不匹配。用户应当注意避免这种不一致状态。
QuantileDiscretizer
QuantileDiscretizer 将带有连续特征的列转换为带有分箱类别特征的列。分箱的数量由 numBuckets 参数设置。使用的桶数可能会小于这个值,例如,如果输入的不同值太少,不足以创建足够的不同分位数。
NaN 值:在 QuantileDiscretizer 拟合过程中,NaN 值将从列中移除。这将产生一个 Bucketizer 模型用于预测。在转换过程中,当 Bucketizer 在数据集中发现 NaN 值时,会引发错误,但用户也可以通过设置 handleInvalid 来选择保留或移除数据集中的 NaN 值。如果用户选择保留 NaN 值,这些值将被特殊处理并放入它们自己的桶中,例如,如果使用了 4 个桶,那么非 NaN 数据将被放入 buckets[0-3],但 NaN 将被计入一个特殊的 bucket[4]。
算法:分箱范围的选择使用了一个近似算法(有关详细描述,请参见 approxQuantile 的文档)。可以用 relativeError 参数控制近似的精度。当设置为零时,将计算精确的分位数(注意:计算精确分位数是一个昂贵的操作)。分箱的下界和上界将是 -Infinity 和 +Infinity,涵盖所有实数值。
Examples
Assume that we have a DataFrame with the columns id, hour:
| id | hour |
|---|---|
| 0 | 18.0 |
| ---- | ------ |
| 1 | 19.0 |
| ---- | ------ |
| 2 | 8.0 |
| ---- | ------ |
| 3 | 5.0 |
| ---- | ------ |
| 4 | 2.2 |
| 小时是一种连续特征,具有 Double 类型。我们想要将连续特征转换为分类特征。给定 numBuckets = 3,我们应该得到以下 DataFrame: |
| id | hour | result |
|---|---|---|
| 0 | 18.0 | 2.0 |
| ---- | ------ | ------ |
| 1 | 19.0 | 2.0 |
| ---- | ------ | ------ |
| 2 | 8.0 | 1.0 |
| ---- | ------ | ------ |
| 3 | 5.0 | 1.0 |
| ---- | ------ | ------ |
| 4 | 2.2 | 0.0 |
Imputer
Imputer 估计器通过使用所在列的均值、中位数或众数来完成数据集中的缺失值。输入列应为数值类型。目前 Imputer 不支持分类特征,并且可能为包含分类特征的列创建不正确的值。Imputer 可以填充除了‘NaN’之外的自定义值,通过 .setMissingValue(custom_value) 来实现。例如,.setMissingValue(0) 将会填充所有出现的(0)。
请注意,输入列中的所有 null 值都被视为缺失值,因此也会被填充。
示例
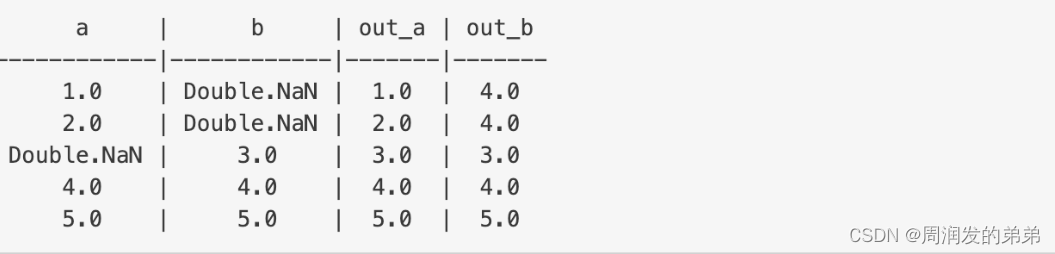
假设我们有一个带有列 a 和 b 的 DataFrame:

在这个例子中,Imputer 将替换所有出现的 Double.NaN(缺失值的默认值)为从相应列的其他值计算出的均值(默认的填充策略)。在这个例子中,列 a 和 b 的替代值分别是 3.0 和 4.0。转换后,输出列中的缺失值将被相关列的替代值所替换。
相关文章:
【Spark实践6】特征转换FeatureTransformers实践Scala版--补充算子
本节介绍了用于处理特征的算法,大致可以分为以下几组: 提取(Extraction):从“原始”数据中提取特征。转换(Transformation):缩放、转换或修改特征。选择(Selection&…...

【知识点】设计模式
创建型 单例模式 Singleton:确保一个类只有一个实例,并提供该实例的全局访问点 使用一个私有构造方法、一个私有静态变量以及一个公有静态方法来实现。私有构造方法确保了不能通过构造方法来创建对象实例,只能通过公有静态方法返回唯一的私…...
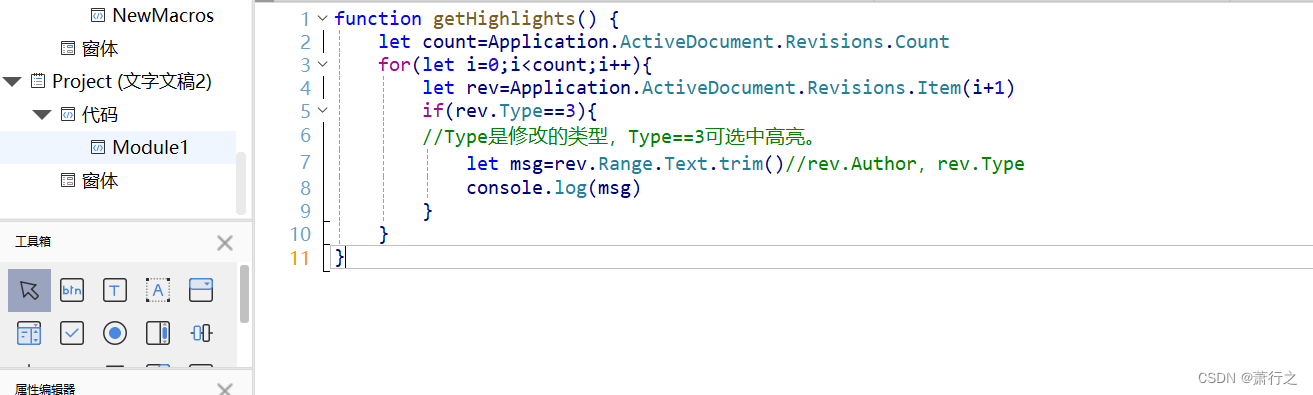
WPS WORD 宏导出高亮文本
WPS手机版可以直接导出高亮文本,但只能导出手机编辑的部分,如果同时在电脑上编辑过,电脑上高亮的无法导出,因为作者不一样。 但WPS电脑版没有这个功能,只能通过宏编程实现。 这里利用了审阅模式,在文字高亮…...

python 基础知识点(蓝桥杯python科目个人复习计划32)
今日复习内容:基础算法中的位运算 1.简介 位运算就是对二进制进行操作的运算方式,分为与运算,或运算,异或运算,取反,左移和右移。 (1)与运算 xyx&y000010100111 (2)或运算 …...
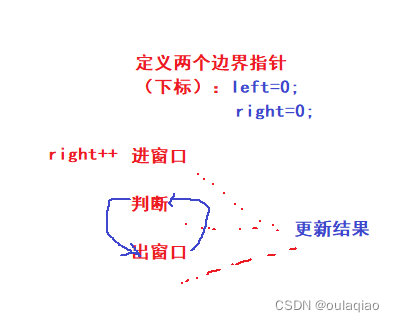
(算法二)滑动窗口
滑动窗口:既一块区域进行滑动,且不回退 往往解决的是一段连续空间中满足条件的最长或者最短子数组(串) 是由暴力解法(优化)——>不回退的滑动窗口解法 长度最小的子数组 无重复字符的最长子数组 此类题…...

【Go语言成长之路】Hello Go
文章目录 Hello Go一、建立工程目录二、开启代码追踪三、编写代码四、测试代码 Hello Go 一、建立工程目录 pzspzs-ubuntu22:~$ mkdir go_study/hello -p pzspzs-ubuntu22:~$ cd go_study/hello 在hello目录下,我们会编写属于自己的第一个Go demo例子࿰…...
大数据应用开发3-Scala笔记1
一、编程框架 Scala语言是在JVM上运行的,兼容Java语法 区分大小写 - Scala是大小写敏感的,这意味着标识Hello 和 hello在Scala中会有不同的含义。 类名 - 对于所有的类名的第一个字母要大写。 如果需要使用几个单词来构成一个类的名称,每个…...

android 网络拦截器统一处理请求参数和返回值加解密实现
前言 项目中遇到参数加密和返回结果加密的业务 这里写一下实现 一来加深记忆 二来为以后参考铺垫 需求 项目在开发中涉及到 登陆 发验证码 认证 等前期准备接口 这些接口需要单独处理 比如不加密 或者有其他的业务需求 剩下的是登陆成功以后的业务需求接口 针对入参和返回值…...
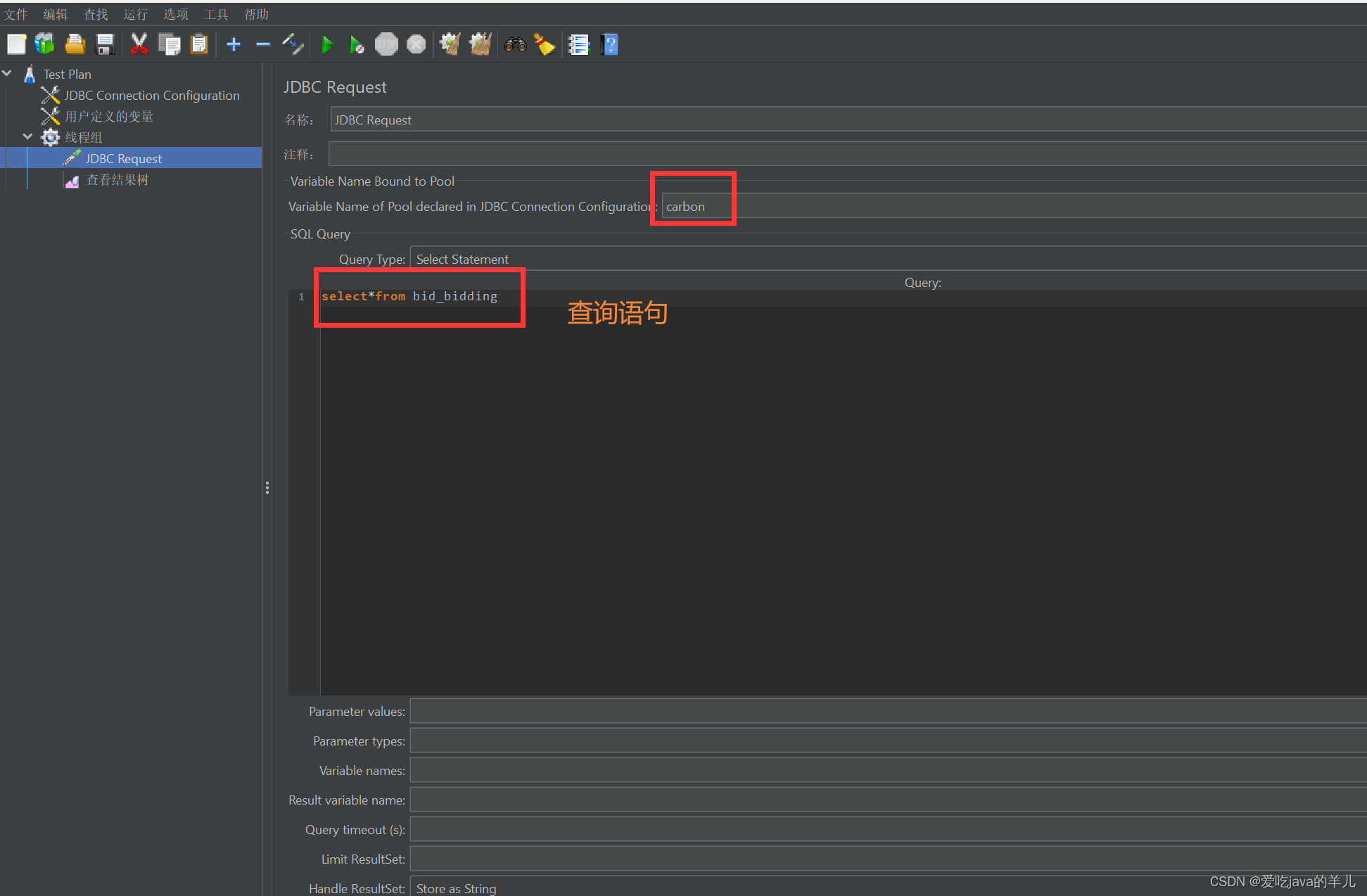
Jmeter直连mysql数据库教程
mysql数据库能够通过Navicat等远程连接工具连接 下载驱动并加入jmeter 1.mysql驱动下载地址:MySQL :: Download MySQL Connector/J (Archived Versions) 找到对应的驱动下载:如下图: 把驱动jar包加入jmeter 配置jmeter连接mysql数据库…...
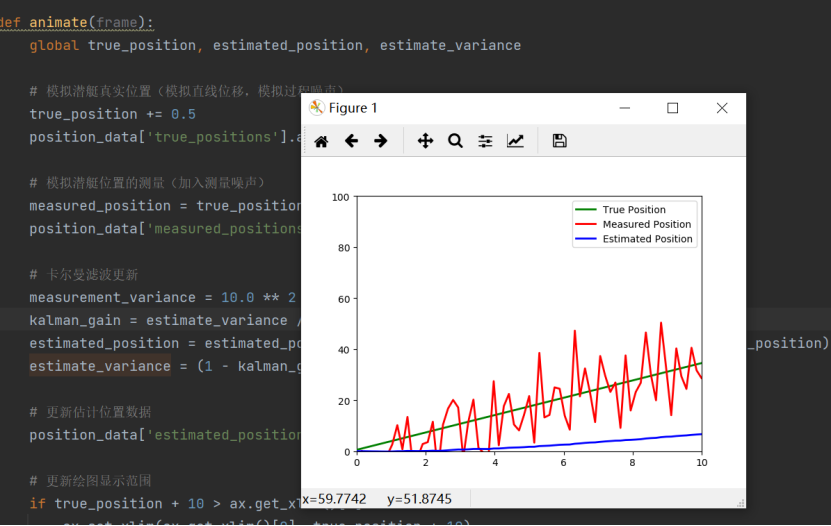
2024美赛数学建模B题思路分析 - 搜索潜水器
1 赛题 问题B:搜索潜水器 总部位于希腊的小型海上巡航潜艇(MCMS)公司,制造能够将人类运送到海洋最深处的潜水器。潜水器被移动到该位置,并不受主船的束缚。MCMS现在希望用他们的潜水器带游客在爱奥尼亚海底探险&…...

Tomcat在Java web的应用
Tomcat在Java web的应用 本来这篇博客顺应之前的内容,应该是需要写Tomcat的简介、基本使用、配置和部署项目、Web的项目结构、创建MavenWeb、idea本地集成以及Tomcat的Maven插件的笔记内容,但是总觉得没必要,因为这些内容网上肯定很多了&…...
Python爬虫某云免费音乐——多线程批量下载
重点一:每首音乐的下载地址 重点二:如何判断是免费音乐 重点三:如何用线程下载并保存 重点四:如何规避运行错误导致子线程死掉 重点五:如何管理子线程合理运行 需要全部代码的私信或者VX:Kmwcx1109 运行效果&…...

Python实现TCP和UDP通信
目录 一:TCP 二:UDP 一:TCP 在Python中实现TCP通信可以通过使用内置的socket模块来完成。以下是一个简单的示例,展示了如何使用Python的socket模块创建一个TCP客户端和服务器。 TCP服务器 import socket def start_server(): s…...
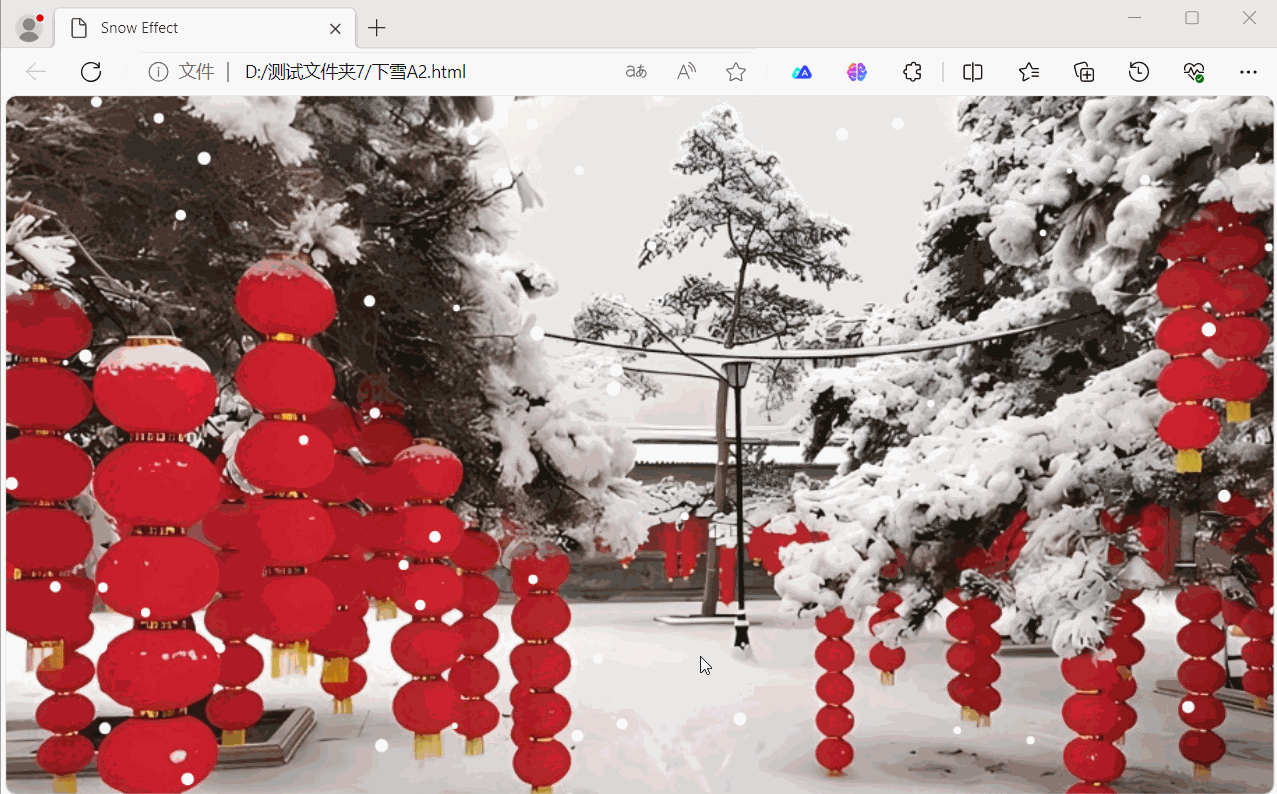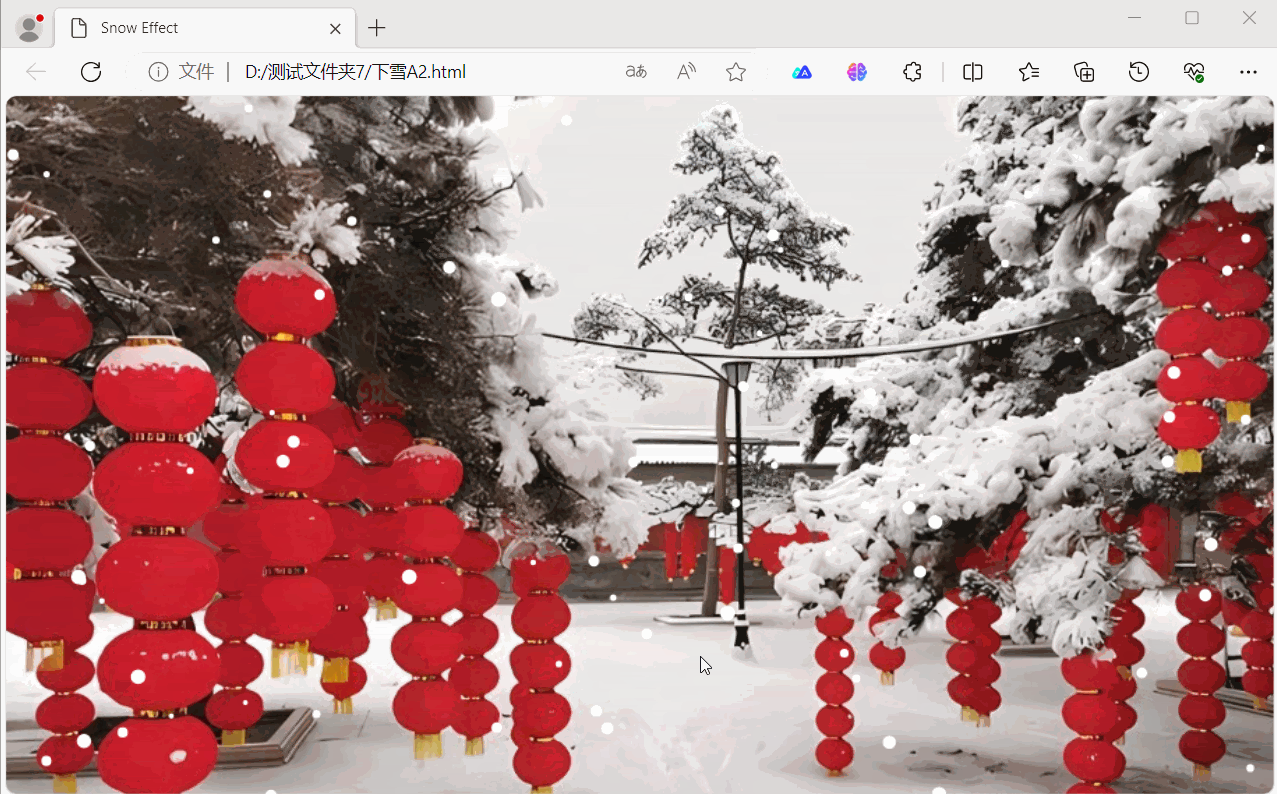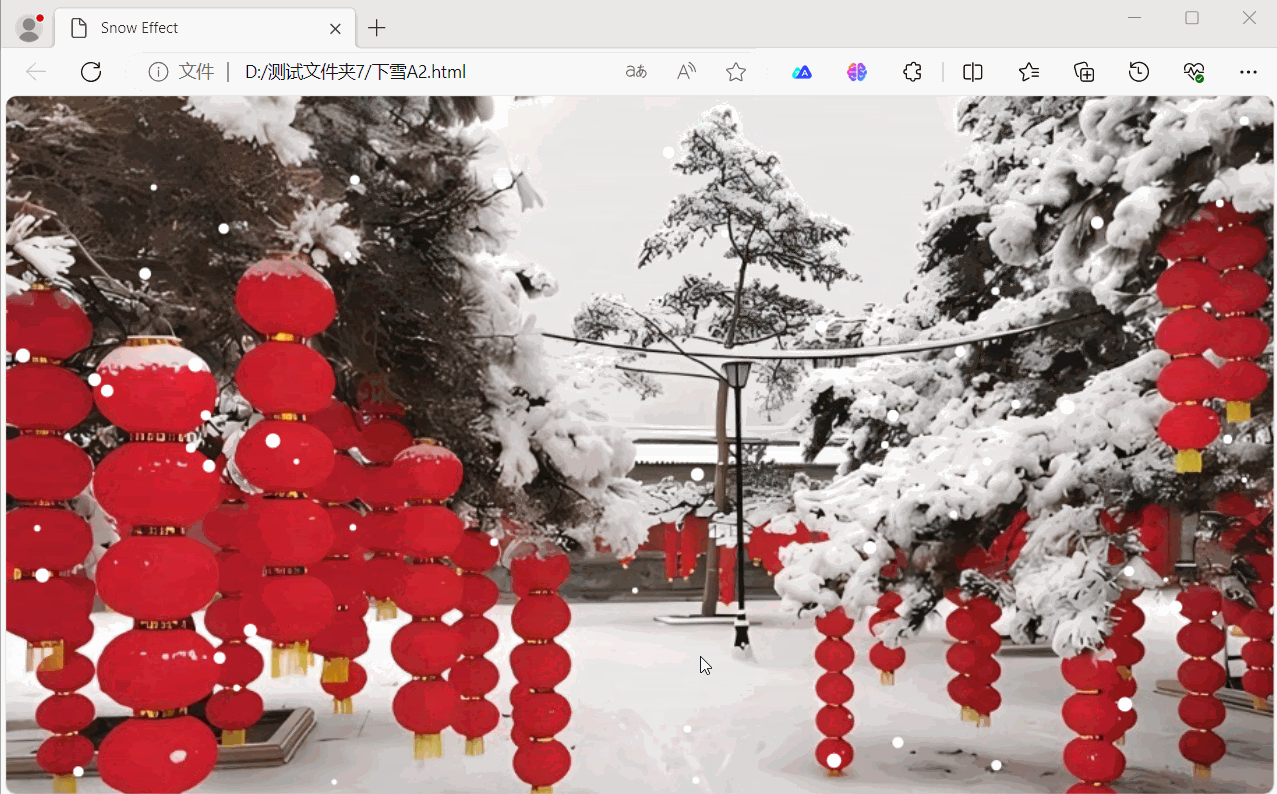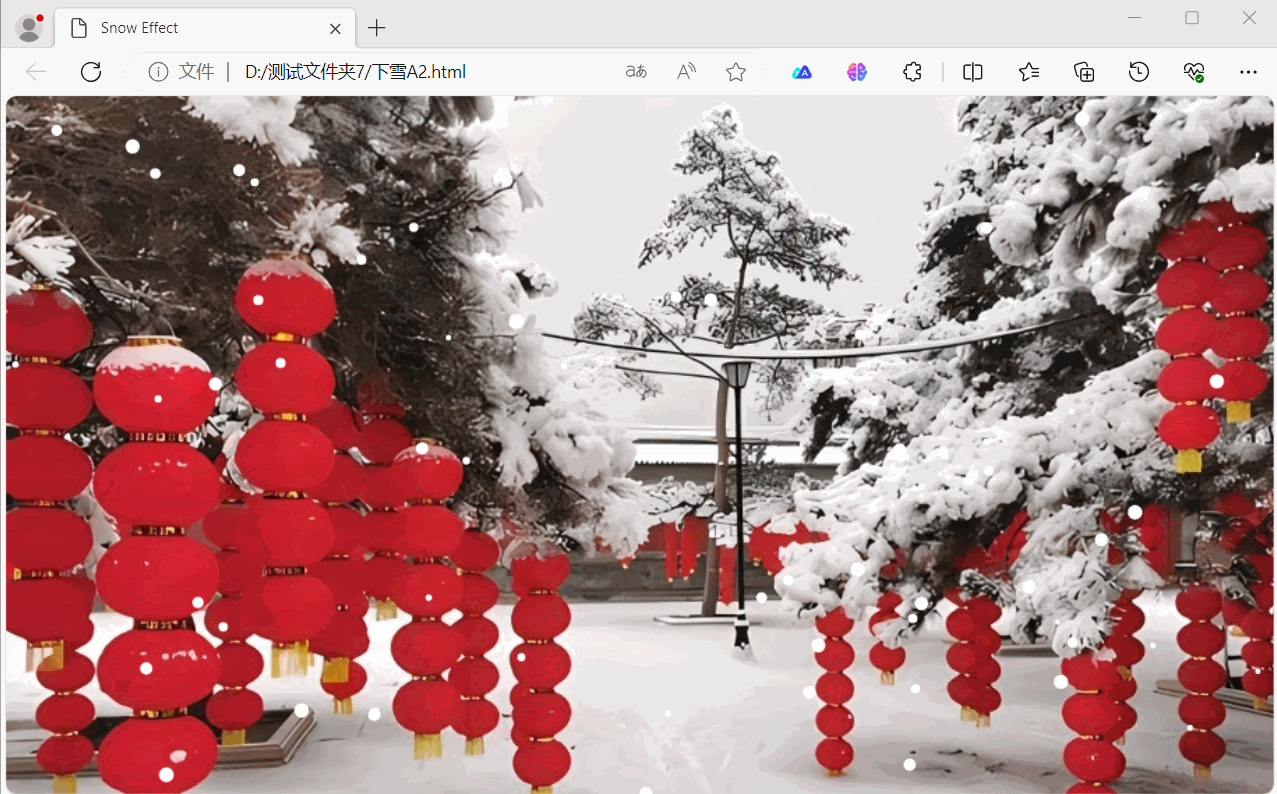
用HTML5 + JavaScript实现下雪效果
用HTML5 JavaScript实现下雪效果 下面是用HTML5 JavaScript实现下雪效果示例,展示了如何使用 HTML5 的 <canvas> 元素以及 JavaScript 来创建下雪效果。效果如下: 源码如下: <!DOCTYPE html> <html lang"en">…...

PDF操作——批量删除末页
一、说明 由于PDF末页为空白页或者是免责声明需要删除,涉及的文件比较多,因此写了一小段代码进行处理。 二、完整架构流程 这个代码的整体架构流程可以分为以下几个步骤: 导入所需的库:首先,代码导入了PyPDF2和os两…...
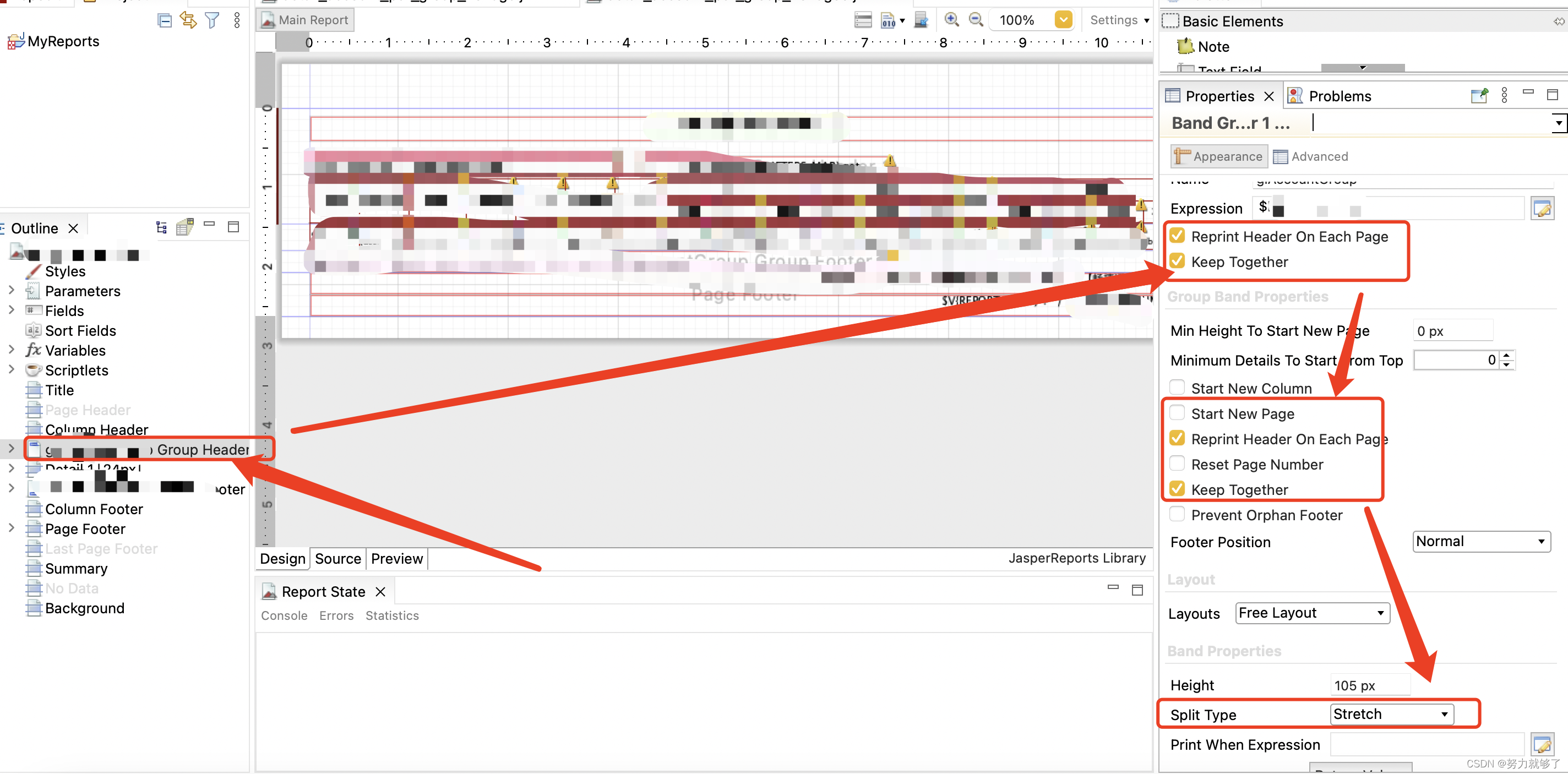
Jasperreport 生成 PDF之省纸模式
省纸模式顾名思义就是节省纸张,使用 Jasper 去生成 PDF 的时候如果进行分组打印的时候,一页 A4 纸只会打印一组数据。这种情况下,如果每组数据特别少,只有几行,一页 A4 纸张根本用不了,就会另起一页继续打印…...
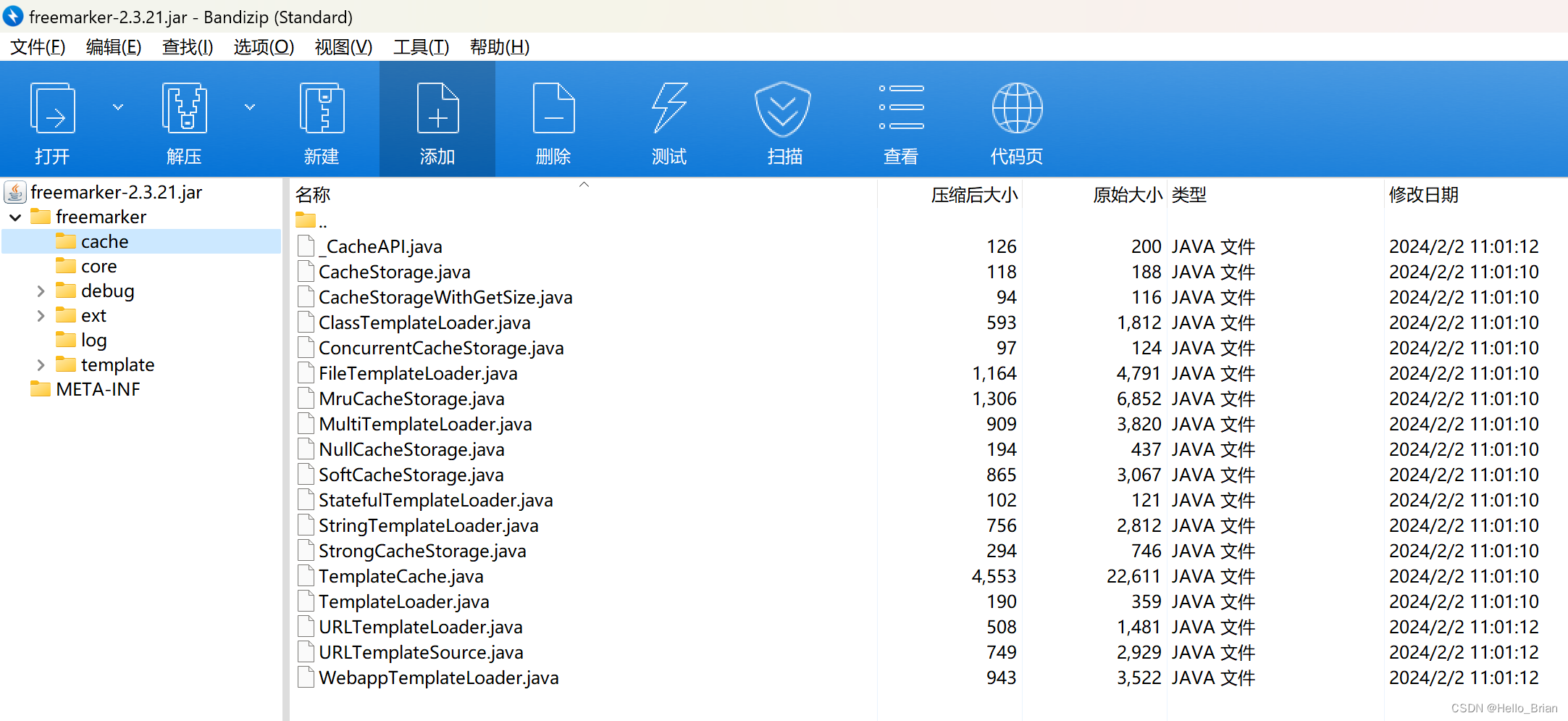
IDEA反编译Jar包
反编译步骤 使用IDEA安装decompiler插件 找到decompiler插件文件夹所在位置(IDEA安装路径/plugins/java-decompiler/lib ),将需要反编译的jar包放到decompiler插件文件夹下,并创建一个空的文件夹,用来存放反编译后的…...

MySQL 备份恢复
1.1 MySQL日志管理 在数据库保存数据时,有时候不可避免会出现数据丢失或者被破坏,这样情况下,我们必须保证数据的安全性和完整性,就需要使用日志来查看或者恢复数据了。 数据库中数据丢失或被破坏可能原因: 误删除数…...

UbuntuServer22.04LTS在线安装MySQL8.x
UbuntuServer22.04LTS在线安装MySQL8.x 文章目录 UbuntuServer22.04LTS在线安装MySQL8.x1. 安装1. 官网2. 在线安装3. 修改密码及设置远程登录4. 其他配置参考 2. 启动和停止1. 查看运行状态2. 开机自启3. 查看默认服务器配置命令 3. 登录 1. 安装 1. 官网 官网安装文档&#…...

GmSSL - GmSSL的编译、安装和命令行基本指令
文章目录 Pre下载源代码(zip)编译与安装SM4加密解密SM3摘要SM2签名及验签SM2加密及解密生成SM2根证书rootcakey.pem及CA证书cakey.pem使用CA证书签发签名证书和加密证书将签名证书和ca证书合并为服务端证书certs.pem,并验证查看证书内容: Pre Java - 一…...

Win11Debloat:重构Windows 11系统体验的开源优化工具
Win11Debloat:重构Windows 11系统体验的开源优化工具 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and cus…...

Axure RP本地化指南:从零开始的界面优化与效率提升方案
Axure RP本地化指南:从零开始的界面优化与效率提升方案 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 作为产品设计…...

3大战略优势:如何通过Axure本地化解决方案提升团队设计效率与协作效能
3大战略优势:如何通过Axure本地化解决方案提升团队设计效率与协作效能 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

Wan2.1模型实测:用TurboDiffusion快速生成电商产品展示视频
Wan2.1模型实测:用TurboDiffusion快速生成电商产品展示视频 1. 引言:当电商遇上秒级视频生成 想象一下这个场景:你是一家电商公司的运营,明天就要上架一款新产品,需要制作10个不同风格、不同角度的产品展示视频。按照…...

OpenClaw镜像体验:Qwen2.5-VL-7B图文模型10分钟快速上手
OpenClaw镜像体验:Qwen2.5-VL-7B图文模型10分钟快速上手 1. 为什么选择云镜像体验OpenClaw 第一次接触OpenClaw时,我花了整整一个下午在本地环境折腾依赖项——从Python版本冲突到CUDA驱动不兼容,最后连基础服务都没跑起来。直到发现星图平…...
告别枯燥界面!GEMMA-3: PIXEL STATION像素风AI工作站,让图像分析像玩游戏
告别枯燥界面!GEMMA-3: PIXEL STATION像素风AI工作站,让图像分析像玩游戏 1. 引言:当AI遇上复古游戏美学 在传统AI工具普遍采用单调技术界面的今天,GEMMA-3: PIXEL STATION带来了一场视觉革命。这款创新工作站将Google最先进的多…...

微信聊天记录永久保存的3种方法:WeChatMsg完整指南与实战技巧
微信聊天记录永久保存的3种方法:WeChatMsg完整指南与实战技巧 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/w…...

DoL-Lyra整合包:三步打造你的专属Degrees of Lewdity游戏体验
DoL-Lyra整合包:三步打造你的专属Degrees of Lewdity游戏体验 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS 你是否厌倦了在Degrees of Lewdity英文原版游戏中费力查找词典?…...
与事件(Event)驱动模型》)
3.4《深入浅出:轮询(Polling)与事件(Event)驱动模型》
001、开篇:从“忙等”到“响应”——理解轮询与事件的核心差异 深夜两点,示波器的波形已经乱成一团麻。我盯着屏幕,手里攥着逻辑分析仪的探头,试图找出那个丢失的传感器数据包。代码里明明写着“等待设备就绪”,但CPU使用率却飙到了98%。同事凑过来看了一眼,指着那个whi…...
)
Ubuntu 20.04下用Python3搞定Mininet可视化编辑器Miniedit(附报错修复指南)
Ubuntu 20.04下Python3运行Miniedit的完整解决方案 在Linux网络仿真领域,Mininet凭借其轻量级和高度可定制的特性,成为众多开发者和研究人员的首选工具。而Miniedit作为Mininet的可视化前端,本应让拓扑创建变得简单直观,但在Pytho…...