Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2
1. 使用入口
- DistributedOptimizer类定义在
megatron/optimizer/distrib_optimizer.py文件中。创建的入口是在megatron/optimizer/__init__.py文件中的get_megatron_optimizer函数中。根据传入的args.use_distributed_optimizer参数来判断是用DistributedOptimizer还是Float16OptimizerWithFloat16Params。
def get_megatron_optimizer(model,no_weight_decay_cond=None,scale_lr_cond=None,lr_mult=1.0):...# Megatron optimizer.opt_ty = DistributedOptimizer \if args.use_distributed_optimizer else \Float16OptimizerWithFloat16Paramsreturn opt_ty(optimizer,args.clip_grad,args.log_num_zeros_in_grad,params_have_main_grad,args.use_contiguous_buffers_in_local_ddp,args.fp16,args.bf16,args.params_dtype,grad_scaler,model)
- 相关的Optimizer的使用参考【Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1】
2. 初始化init源码说明
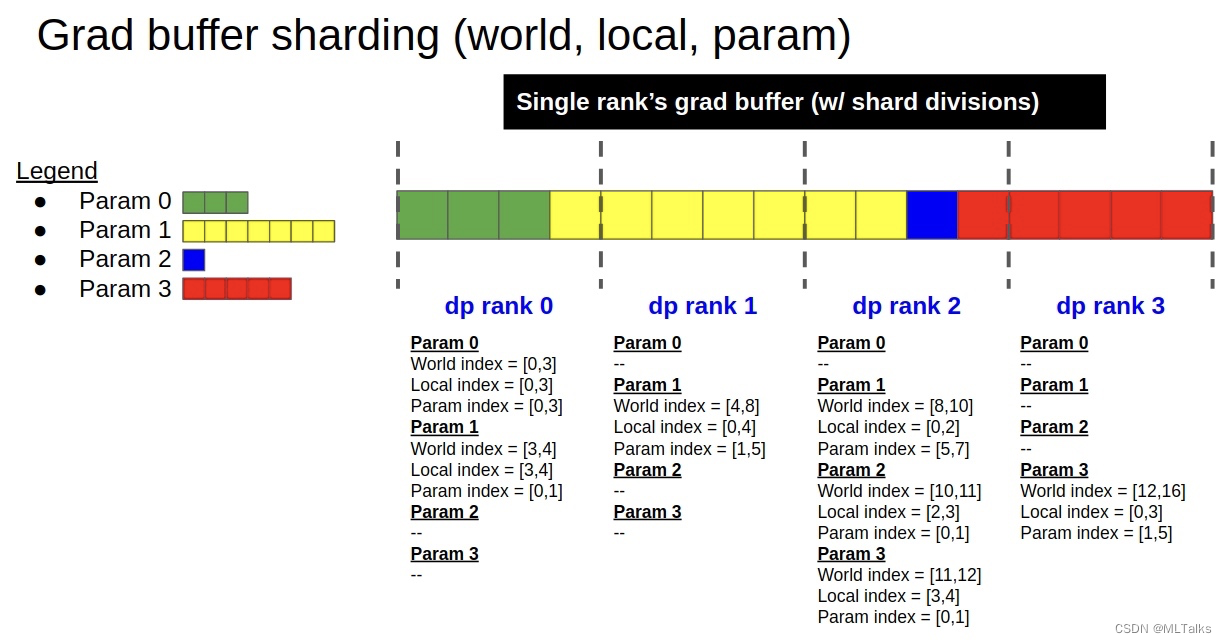
- 初始化的过程很大程度对应的上图grad buffer分片的实现,对应init函数如下:
def __init__(self, optimizer, clip_grad, log_num_zeros_in_grad,params_have_main_grad, use_contiguous_buffers_in_local_ddp,fp16, bf16, params_dtype, grad_scaler, models):
- init时会通过
build_model_gbuf_range_map函数先创建grad buffer的范围映射,也就是对应图中的world_index/local_index/param_index三个。这里的self.models是一个list类型,对于使用了interleave流水线方式的训练来说,这里的self.models中会保存多份model, 其余情况list中只有一个元素。
# Model grad buffer ranges.self.model_gbuf_ranges = []for model_index, model in enumerate(self.models):self.model_gbuf_ranges.append(self.build_model_gbuf_range_map(model))
build_model_gbuf_range_map会依次按grad buffer中类型来进行range的初始化build_model_gbuf_range。这里定义了一个单独的Range类。
@classmethoddef build_model_gbuf_range_map(cls, model):"""Create param-to-grad-buffer mappings, for grad buffer data typeswithin a specific virtual model."""return {dtype : cls.build_model_gbuf_range(model, dtype)for dtype in model._grad_buffers}class Range:"""A range represents a start and end points for indexing a shardfrom a full tensor."""def __init__(self, start, end):self.start = startself.end = endself.size = end - startdef normalize(self, start = 0):return Range(start, start + self.size)def __str__(self):return "%d,%d [%d]" % (self.start, self.end, self.size)def __len__(self):return self.end - self.start
build_model_gbuf_range初始化range的流程如下:- 获取DP的rank,计算单个Grad buffer切片的大小
- 保存当前rank的world range和local range, 分别对应world index和local index
- 计算param的range范围,对应param index
- 返回当前rank的相关range范围
@classmethoddef build_model_gbuf_range(cls, model, dtype):# 获取DP的rankdata_parallel_rank = mpu.get_data_parallel_rank()data_parallel_world_size = mpu.get_data_parallel_world_size()# 计算单个Grad buffer切片的大小grad_buffer = model._grad_buffers[dtype]gbuf_size = grad_buffer.numelmax_gbuf_range_size = int(math.ceil(gbuf_size / data_parallel_world_size))# 跟据DDP的rank总数,分别计算每个rank对应的全局rangegbuf_world_all_ranges = []for r in range(data_parallel_world_size):gbuf_world_start = r * max_gbuf_range_sizegbuf_world_end = min(gbuf_size, gbuf_world_start+max_gbuf_range_size)gbuf_world_range = Range(gbuf_world_start, gbuf_world_end)gbuf_world_all_ranges.append(gbuf_world_range)# 保存当前rank的world range和local range# Local DP's ranges.gbuf_world_range = gbuf_world_all_ranges[data_parallel_rank]gbuf_local_range = gbuf_world_range.normalize()# 计算param的range范围param_range_map = cls.build_model_gbuf_param_range_map(model,dtype,gbuf_world_range)# Group into dict.data = {"local" : gbuf_local_range,"world" : gbuf_world_range,"world_all" : gbuf_world_all_ranges,"param_map" : param_range_map,"max_range_size" : max_gbuf_range_size,}return data
- 接着会根据当前rank相关的Range内容
self.model_gbuf_ranges调用build_model_param_gbuf_map函数,主要作用是创建model_gbuf_ranges的逆映射,保存param->(modex_index, type)的映射。
class DistributedOptimizer(MixedPrecisionOptimizer):def __init__(...):...self.model_param_gbuf_map = \self.build_model_param_gbuf_map(self.model_gbuf_ranges)...def build_model_param_gbuf_map(cls, model_gbuf_ranges):"""Create a reverse of the model_gbuf_ranges, for referencing inopposite direction."""param_gbuf_map = {}for model_index, model_gbuf_range_map in enumerate(model_gbuf_ranges):for dtype, gbuf_range_map in model_gbuf_range_map.items():for param, param_range_map in gbuf_range_map["param_map"].items():param_gbuf_map[param] = (model_index, dtype)return param_gbuf_map
- 在
self.build_model_param_gbuf_map之后是初始化Optimizer对应的local group range,Optimizer原本有param_groups包括多个参数组,这里build_optimizer_group_ranges为了创建param参数到group_index的map映射,也就是<model_parameter:group_index>;self.build_model_param_gbuf_map最后对每个group_range中增加新的orig_group和orig_group_idx两个key,原来group_range初始化的时候只有params一个key
class DistributedOptimizer(MixedPrecisionOptimizer):def __init__(...):...# Optimizer ranges.self.model_param_group_index_map, self.opt_group_ranges = \self.build_optimizer_group_ranges(self.optimizer.param_groups,self.model_gbuf_ranges)...def build_optimizer_group_ranges(cls, param_groups, model_gbuf_ranges):# 获取param_groups中组的个数num_groups = len(param_groups)# 创建全局的参数到group_index的map映射,也就是<model_parameter:group_index>world_param_group_map = {}for group_index, group in enumerate(param_groups):for param in group["params"]:assert param.requires_gradworld_param_group_map[param] = group_index# 创建当前rank的local_param_group_map, local_param_group_map是param与(group_index, group_params_len)的映射, local_param_group_map虽然返回了但后面没用local_param_group_map = {}group_ranges = [ {"params": []} for _ in param_groups ]for model_gbuf_range_map in model_gbuf_ranges:for dtype, gbuf_range_map in model_gbuf_range_map.items():for param in gbuf_range_map["param_map"]:group_index = world_param_group_map[param]group_range = group_ranges[group_index]group_range["params"].append(param)local_param_group_map[param] = \(group_index, len(group_range["params"]) - 1)# Squeeze zero-size group ranges.for group_index, group_range in enumerate(group_ranges):group_range["orig_group"] = param_groups[group_index]group_range["orig_group_idx"] = param_groups[group_index]return local_param_group_map, group_ranges
- 在初始化Optimizer之后,是通过创建
self.build_model_and_main_param_groups创建optimizer step要用到的main parameter groups, 这里的group一方面是要进行reduce和gather通信操作,另一方面是被优化器用于梯度的更新操作。
class DistributedOptimizer(MixedPrecisionOptimizer):def __init__(...):...# Allocate main param shards.(self.model_float16_groups,self.model_fp32_groups,self.shard_float16_groups,self.shard_fp32_groups,self.shard_fp32_from_float16_groups,) = self.build_model_and_main_param_groups(self.model_gbuf_ranges,self.model_param_gbuf_map,self.opt_group_ranges)...self.build_model_and_main_param_groups的实现主要是关于fp32/fp16/bf16三种类型训练时优化器内的显存分配。
@classmethoddef build_model_and_main_param_groups(cls,model_gbuf_ranges,param_gbuf_map,opt_group_ranges):...# 保存原本fp16类型parammodel_float16_groups = []# 保存原本fp32类型parammodel_fp32_groups = []# 保存原本fp16类型param的切片shard_float16_groups = []# 保存原本fp32类型param的切片shard_fp32_groups = []# 保存原本fp16类型param的fp32类型param的副本shard_fp32_from_float16_groups = []# 分配每个group的param参数切片for group_index, group_range in enumerate(opt_group_ranges):for model_param in group_range["params"]:if model_param.type() in ['torch.cuda.HalfTensor','torch.cuda.BFloat16Tensor']:# 如果是fp16/bf16类型参数,clone为fp32类型的切片.shard_model_param = model_param.detach().view(-1) \[param_range.start:param_range.end]shard_main_param = shard_model_param.clone().float()...# 添加到group中model_float16_params_this_group.append(model_param)shard_float16_params_this_group.append(shard_model_param)shard_fp32_from_float16_params_this_group.append(shard_main_param)elif model_param.type() == 'torch.cuda.FloatTensor':# 如果是fp32类型参数,不进行clone,直接引用shard_model_param = model_param.view(-1) \[param_range.start:param_range.end]model_fp32_params_this_group.append(model_param)shard_fp32_params_this_group.append(shard_model_param)...# 更新优化器的参数group_range["orig_group"]["params"] = [*shard_fp32_params_this_group,*shard_fp32_from_float16_params_this_group,]return (model_float16_groups,model_fp32_groups,shard_float16_groups,shard_fp32_groups,shard_fp32_from_float16_groups,)
- 在Optimizer init中,接下来是初始化self.param_buffers,这里的self.param_buffers是DDP模型的grad buffer的view示图,跟grad buffer共享存储,但是用自己的数据类型;最后更新优化器的param_groups。
class DistributedOptimizer(MixedPrecisionOptimizer):def __init__(...):...# 初始化self.param_buffersself.param_buffers = []for model_index, model in enumerate(self.models):current_param_buffers = {}for dtype, grad_buffer in model._grad_buffers.items():# 获取存储,这里是兼容的写法.try:storage = grad_buffer.data.storage()._untyped()except:storage = grad_buffer.data.storage().untyped()# 基于grad_buffer的storage创建param_buffer类型,这里的params_dtype是参数类型; 这里的torch.tensor没有autograd的历史。param_buffer = torch.tensor(storage,dtype = params_dtype,device = grad_buffer.data.device)param_buffer = param_buffer[:grad_buffer.numel_padded]# 这里的dtype是grad_buffer的类型current_param_buffers[dtype] = param_bufferself.param_buffers.append(current_param_buffers)# 最后更新优化器的param_groupsself.optimizer.param_groups = \[ g["orig_group"] for g in self.opt_group_ranges ]self.optimizer.load_state_dict(self.optimizer.state_dict())
3. 参考
- Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2
- Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1
- NVIDIA/Megatron-LM
相关文章:
Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2
1. 使用入口 DistributedOptimizer类定义在megatron/optimizer/distrib_optimizer.py文件中。创建的入口是在megatron/optimizer/__init__.py文件中的get_megatron_optimizer函数中。根据传入的args.use_distributed_optimizer参数来判断是用DistributedOptimizer还是Float16O…...
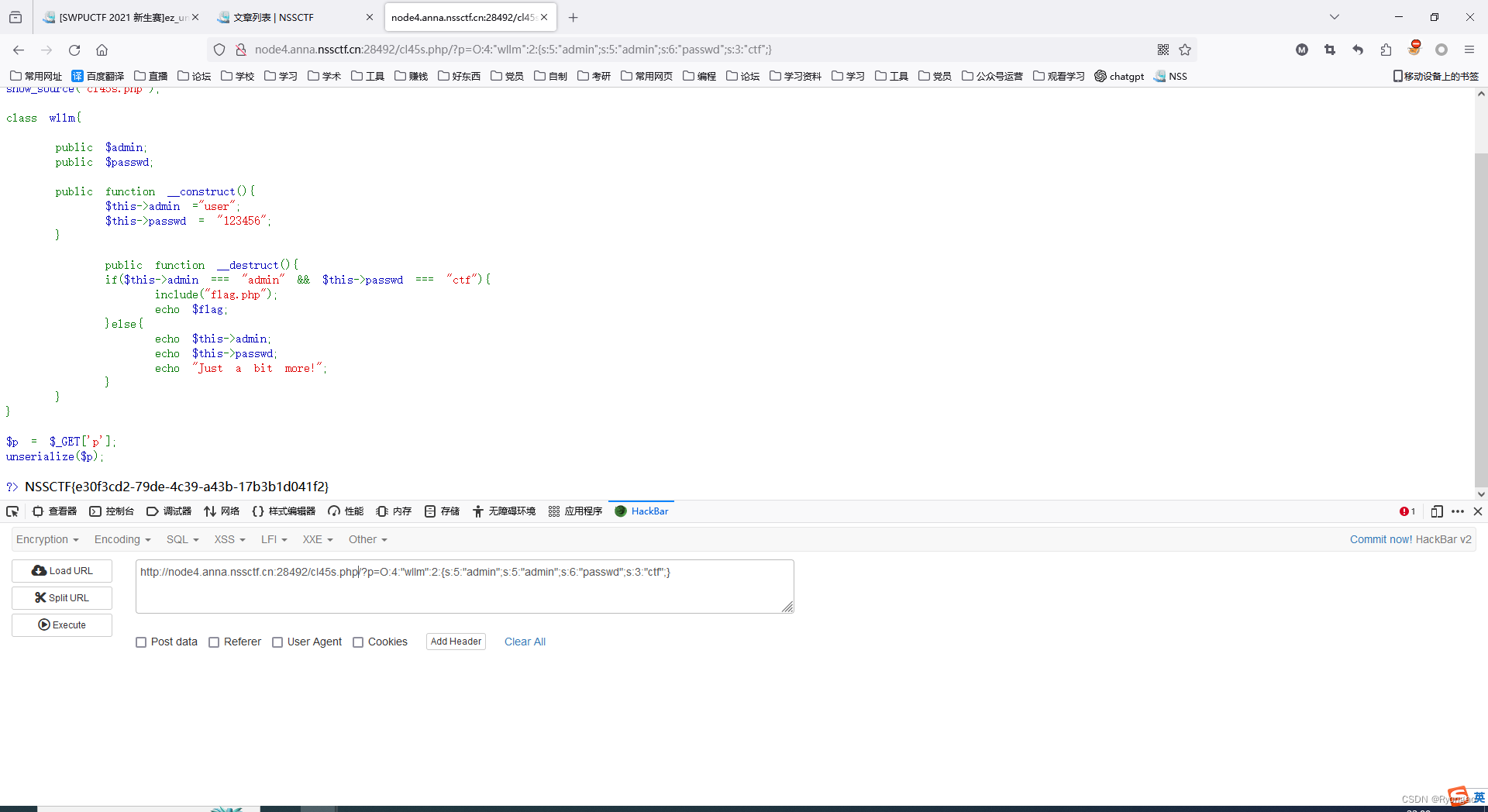
[SWPUCTF 2021 新生赛]ez_unserialize
根据下面的user_agent和Disallow可以判断这个是在robots.txt 我们看的出来这是一个反序列化需要我们adminadmin passwdctf construct 构造方法,当一个对象被创建时调用此方法,不过unserialize()时却不会被调用 destruct 析构方法,PHP将在对象…...

android tv开发-1,leanback 2
目录 presenter太多,如何理清关系 动画与点击 tv的登录与设置 搜索功能 带二级菜单的页面 presenter太多,如何理清关系 leanback里面已经定义好了adapter与presenter,直接继承它就可以了 private DefaultObjectAdapter mVideoAdapter; private VideoCardPresenter mCardP…...

Spring Boot注解
Spring Boot提供了许多常用的注解,用于简化开发过程和配置管理。以下是一些常用的Spring Boot注解: SpringBootApplication: 标记一个类为Spring Boot应用程序的入口点,同时也是一个组合注解,包括了Configuration、EnableAutoConf…...
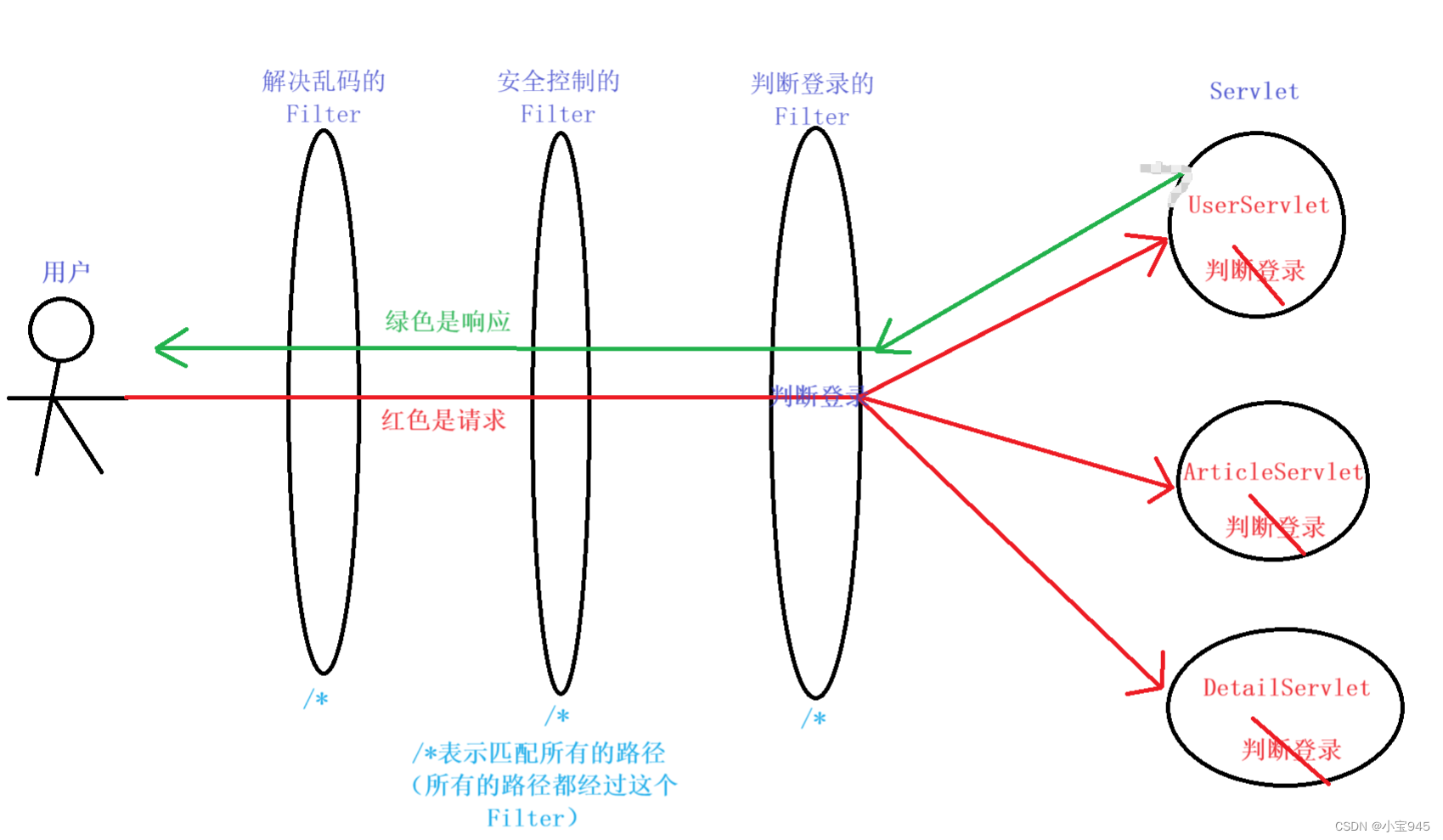
JavaWeb中的Filter(过滤器)和 Listener(监听器)
提示:这两个东西听起来似乎很难,实际上是非常简单的,按照要求写就行了,一定不要被新名词给吓到了。 JavaWeb中的Filter(过滤器) 一、Filter(过滤器)1.如何编写 Filter2.Filter 中的细…...

mybatis查询修改mysql的json字段
前言: mysql5.7版本之后支持json字段类型,推荐mysql8版本,适用于属性不确定的个性化字段,比如: 身份信息{“职业”,“学生”,“兴趣”:“打乒乓球”,“特长”:“跳高,书法”}; 图片信息{“日期”:“2023-12-12 22:12”…...

实时聊天系统
这个系统可以用于网站的即时通讯,比如客服系统、在线社区等。这个功能不仅对用户友好,而且也是检验技术实现能力的一个很好的案例。 ### 功能概述 该系统允许用户在网站上实时发送和接收消息。为了保持实时性,我们将使用PHP进行服务器端的逻…...
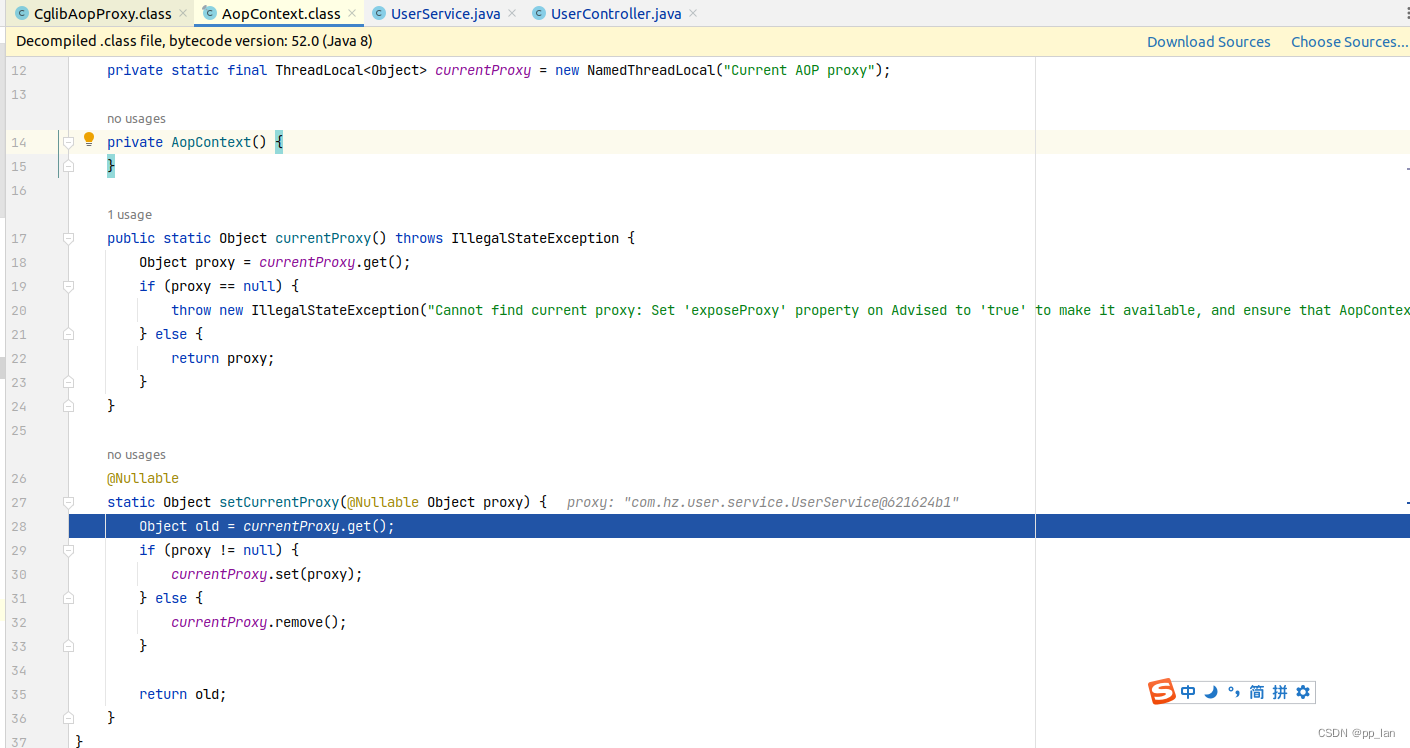
Spring-mvc、Spring-boot中如何在调用同类方法时触发AOP
1. 问题描述 Spring-mvc和Spring-boot中aop可以实现代理的功能,我们可以借此实现事务和日志记录或者限流等多种操作。但是,如果你在一个方法中调用其同类下的其他方法的时候不会触发AOP。本文主要说明其原因及解决办法和实现原理。 2. 原因 AIOP的本质是…...

幻兽帕鲁服务器自动重启备份-python
幻兽帕鲁服务器自动重启备份-python 1. 前置知识点2. 目录结构3. 代码内容4. 原理解释5. 额外备注 基于python编写的服务器全自动管理工具,能够实现自动定时备份存档,以及在检测到服务器崩溃之后自动重新启动,并且整合了对于frp端口转发工具的…...
C# Onnx yolov8 水表读数检测
目录 效果 模型信息 项目 代码 训练数据 下载 C# Onnx yolov8 水表读数检测 效果 模型信息 Model Properties ------------------------- date:2024-01-31T10:18:10.141465 author:Ultralytics task:detect license:AGPL-…...
负载均衡下webshell连接
目录 一、什么是负载均衡 分类 负载均衡算法 分类介绍 分类 均衡技术 主要应用 安装docker-compose 2.1上传的文件丢失 2.2 命令执行时的漂移 2.3 大工具投放失败 2.4 内网穿透工具失效 3.一些解决方案 总结 一、什么是负载均衡 负载均衡(Load Balanc…...

Spring面试大全-基础知识01
1.什么是Spring Spring框架是用于构建企业级Java的开源框架,他通过依赖注入和IOC容器帮我我们管理对象;支持AOP,将非业务功能(日志,事务等)从我们业务代码中分离出来,提高了代码的可维护性&…...
Transformer实战-系列教程4:Vision Transformer 源码解读2
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 4、Embbeding类 self.embeddings Embeddings(config, img_sizeimg_size) class Embeddings(nn.…...
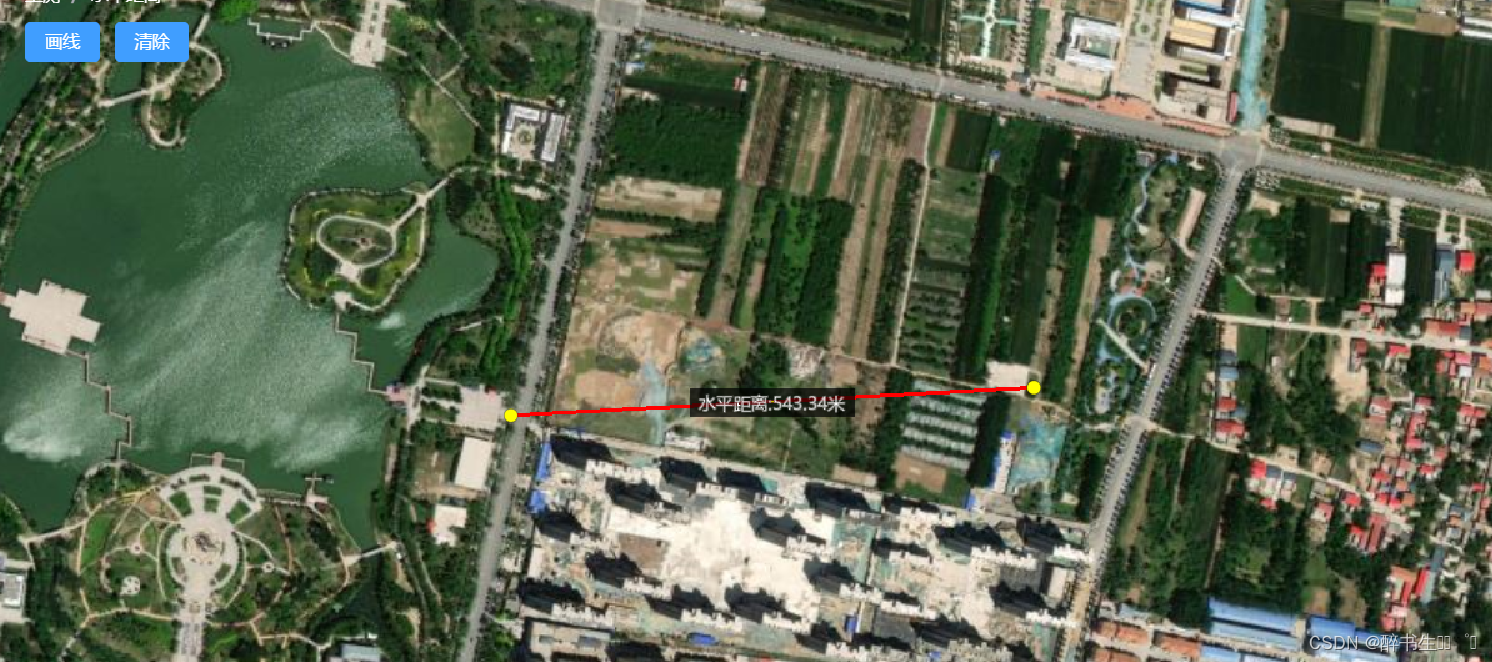
cesium-水平测距
cesium测量两点间的距离 <template><div id"cesiumContainer" style"height: 100vh;"></div><div id"toolbar" style"position: fixed;top:20px;left:220px;"><el-breadcrumb><el-breadcrumb-item&…...

【Android-Compose】手势检测实现按下、单击、双击、长按事件,以及避免频繁单击事件的简单方法
目录: 1 不需要双击事件 规避频繁单击事件2 需要双击事件(常规写法)3 后记:不建议使用上面的代码自定义按钮 1 不需要双击事件 规避频繁单击事件 var firstClickTime by remember { mutableStateOf(System.currentTimeMillis()…...
)
AUTOSAR汽车电子嵌入式编程精讲300篇-基于神经网络的CAN总线负载率优化(续)
目录 3.3 SA 算法 3.3.1 SA 算法原理 3.3.2 基于 SA 算法 CAN 总线负载率优化分析...

python爬虫6—高性能异步爬虫
如果有多个URL等待我们爬取,我们通常是一次只能爬取一个,爬取效率低,异步爬虫可以提高爬取效率,可以一次多多个URL同时同时发起请求 异步爬虫方式: 一、多线程、多进程(不建议):可以…...
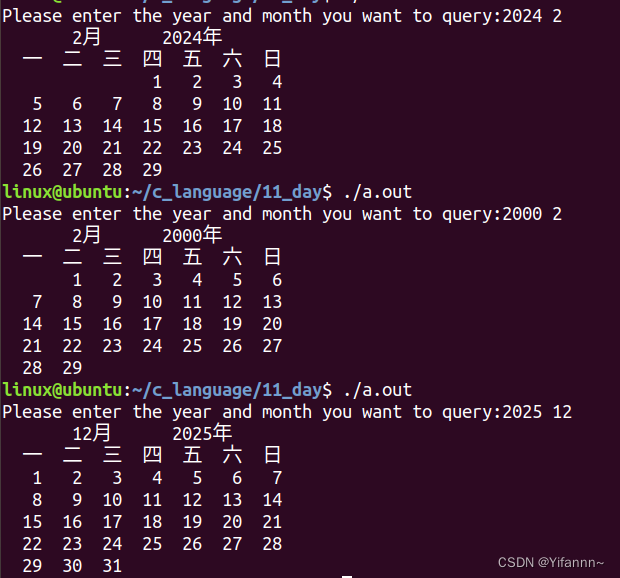
日历功能——C语言
实现日历功能,输入年份月份,输出日历 #include<stdio.h>int leap_year(int year) {if(year % 4 0 && year % 100 ! 0 || year % 400 0){return 1;}else{return 0;} }int determine_year_month_day(int *day,int month,int year) {if(mo…...

GPIO中断
1.EXTI简介 EXTI是External Interrupt的缩写,指外部中断。在嵌入式系统中,外部中断是一种用于处理外部事件的机制。当外部事件发生时(比如按下按钮、传感器信号变化等),外部中断可以立即打断正在执行的程序࿰…...
springboot完成一个线上图片存放地址+实现前后端上传图片+回显
1.路径 注意路径 2.代码:(那个imagePath没什么用,懒的删了),注意你的本地文件夹要有图片,才可以在线上地址中打开查看 package com.xxx.common.config;import org.springframework.beans.factory.annotat…...

单向链表的创建、插入、删除、遍历
文章目录单向链表:从创建到操作全解析 📝1. 单向链表的基本概念 🧠2. 实现单向链表 🛠️2.1 定义节点类2.2 创建链表3. 插入操作 ➕3.1 在头部插入3.2 在尾部插入3.3 在特定位置插入4. 删除操作 ❌4.1 删除头部节点4.2 删除特定值…...

程序员必看!高质量免费源码网推荐
在数字化浪潮席卷全球的今天,代码已成为驱动创新的核心动力。无论是初创企业快速搭建商业平台,还是开发者优化项目架构,高质量的源码资源都能显著缩短研发周期、降低开发成本。然而,面对网络上鱼龙混杂的源码平台,如何…...

扶摇速记:眼前流水,曲折前向
英语单词 went,意为【走】或走【去】,它是动词 go 的过去式。 went v. (go过去式) 去,走 我们可以这样去理解,其中 -t,表动词,是构词语法形式,含义主要来自wen-,而went 或 wen-的首字…...

LLM强化学习从入门到精通:Composition-RL全解析,收藏这篇就够了!
🎯 为什么我们需要Composition-RL? 想象一下:你正在备考数学竞赛,一开始做的都是基础题。随着练习增多,你能轻松答对所有基础题,但这些简单题已经无法帮你进步了——你需要更难的题目来提升能力。 这正是…...

OpenClaw+Qwen3.5-9B低成本自动化:自建模型比API省80%
OpenClawQwen3.5-9B低成本自动化:自建模型比API省80% 1. 为什么我要研究OpenClaw的成本问题 上个月我尝试用OpenClaw自动化处理积压的3000多份PDF文件,结果被商用API的账单吓了一跳——单次归档任务的token消耗折算下来居然要12美元。这让我开始思考&a…...

PLY格式驱动3D视觉检测革命,常规可见光相机在工业视觉检测中的应用。
PLY格式在机器视觉3D检测中的应用 PLY(Polygon File Format)是一种广泛用于存储3D点云数据的文件格式,支持顶点、面片、颜色、法向量等属性的灵活存储。其ASCII和二进制两种编码方式兼顾了可读性与效率,成为3D视觉领域的通用交换格…...

Slowloris安装与部署:从源码到生产环境的完整流程
Slowloris安装与部署:从源码到生产环境的完整流程 【免费下载链接】slowloris Low bandwidth DoS tool. Slowloris rewrite in Python. 项目地址: https://gitcode.com/gh_mirrors/sl/slowloris Slowloris是一款基于Python的低带宽DoS(拒绝服务&a…...

OpenClaw浏览器自动化:千问3.5-35B-A3B-FP8驱动智能爬虫实践
OpenClaw浏览器自动化:千问3.5-35B-A3B-FP8驱动智能爬虫实践 1. 为什么需要AI驱动的浏览器自动化 去年我接手了一个数据采集项目,目标是从几十个电商平台抓取商品信息和用户评价。传统爬虫在遇到验证码、动态加载内容时频繁失效,而人工操作…...

【 Postman 使用教程】
一、接口测试介绍 1. 接口分类: 内部接口:系统内部各功能模块之间的接口(测试比较详细)外部接口:系统与外部系统之间的接口(测试基本功能) 2. 接口测试的重点: 测试接口数据交换是否…...

嵌入式系统可靠性设计:内存保护与硬件检测实践
1. 嵌入式系统可靠性设计概述在工业控制、医疗设备和汽车电子等关键领域,嵌入式系统的可靠性直接关系到人身安全和财产安全。作为一名有十年嵌入式开发经验的工程师,我见过太多因可靠性设计不足导致的现场故障。这些故障往往不是由复杂算法错误引起&…...