为什么说TiDB在线扩容对业务几乎没有影响
作者: 数据源的TiDB学习之路 原文来源: https://tidb.net/blog/e82b2c5f
当前的数据库种类繁多,墨天轮当前统计的所有国产数据库已经有 290个 ,其中属于关系型数据库的有 166个 。关系型数据库从部署架构上又可以分为集中式(典型代表为达梦DM8、金仓KES)、分库分表(典型代表为中兴GoldenDB、腾讯TDSQL)以及原生分布式架构(典型代表为PingCAP TiDB、阿里OceanBase)。
昨天和别人交流PingCAP TiDB时,这位同学对“**TiDB在线扩容对业务几乎没有影响”**这一点表示不太理解,惊讶TiDB到底是怎么做到的。。细聊下来,发现这位同学是一位主要负责集中式和早期分布式架构数据库的DBA人员,比较熟悉Oracle、Greenplum。于是我有点理解他的惊讶了,因为Oracle和Greenplum我也是有一点点经验,本文简单针对一般分布式数据库和TiDB在扩容机制上谈一点个人的理解。
一. 一般分布式数据库在线扩容是怎么做的?
集中式数据库因为其架构本身的限制,一般来说想要实现在线扩容是比较困难的,这里暂且不予讨论,我们主要了解一下一般分布式数据库的扩容是如何进行的。不管是Greenplum这种MPP数据库,还是其它的分库分表数据库,为了实现数据的均衡分布,通常需要在表上定义相关的分布键。通过分布键,再结合哈希算法,可以把数据哈希散列到不同的数据节点中,类似于 hash(key)% N(key代表分布键,N代表数据节点编号) 。举个例子,假如一个分布式数据库有3个数据节点,表的分布键为ID(ID是一个递增序列),那么基于哈希算法散列后数据的分布大致如下图所示:
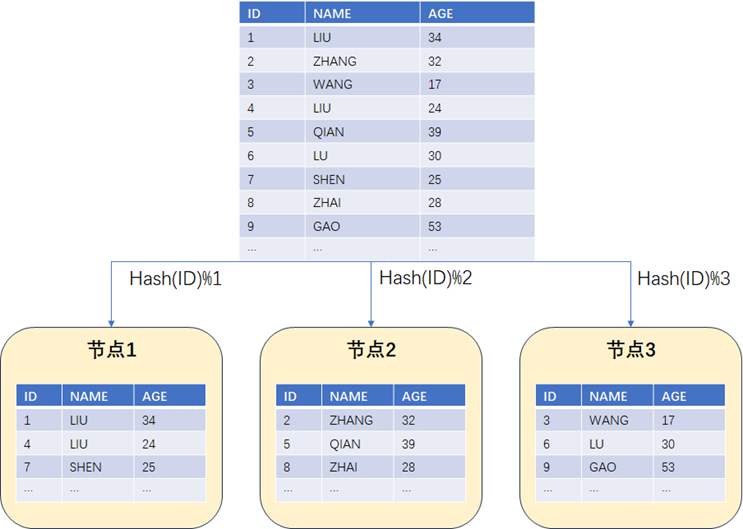
现在我们需要扩容一个节点,从原来的3节点扩容到4节点。为了保证原来哈希散列结果的一致性数据需要重新平衡,平衡后的数据分布应该如下面图中所示。可以发现,这个时候大部分的数据基本都搬迁了一遍。先不说数据的迁移是否对业务造成阻塞,光是这现有的大面积数据均衡足以导致整个系统的IO消耗极高, 严重影响整个系统的可用性 。
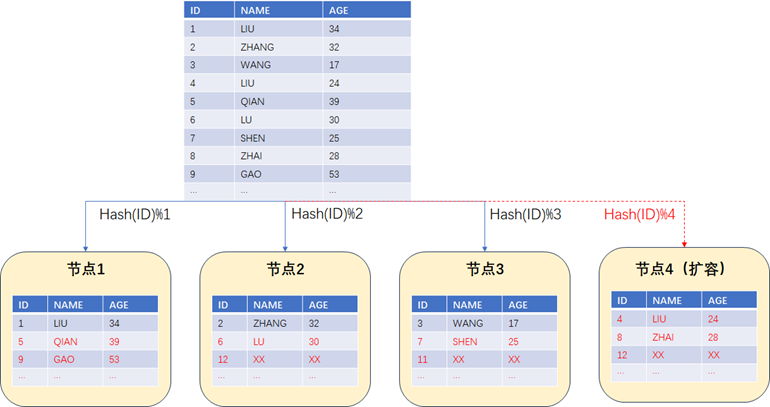
Greenplum在官方文档中还明确指出“ 正在被重新分布的表或者分区会被锁定并且不可读写。 当其重新分布完成后,常规操作才会继续。 ”可以明确的说,Greenplum早期版本里面根本就不支持所谓的“**在线”**扩容。
时代在进步,数据库技术也在进步。为了尽可能实现在线扩容的能力,Greenplum数据库包括其他的分库分表数据库开始引入一些新的算法来优化此事。 一致性哈希算法 开始被普遍应用,它与传统哈希算法最主要的不同是 不再使用节点编号来进行散列 ,而是使用2^32这样一个固定值做取模运算。一致性哈希算法将表中的数据和节点编号映射到一个圆环上,当增加节点时影响的数据范围只是圆环上的一小段数据范围。比如下图中增加节点4,影响的数据只有节点1到节点4之间的这部分数据。
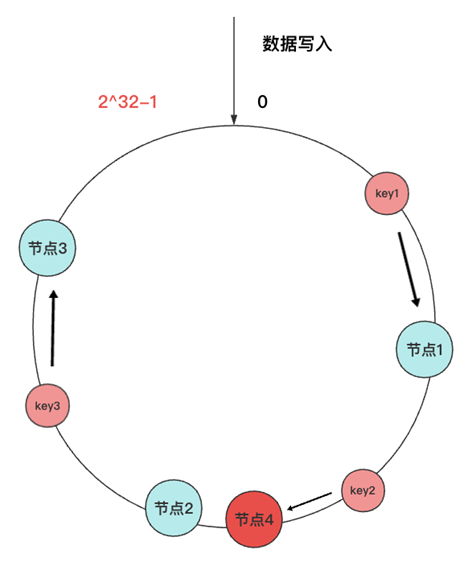
一致性哈希算法解决了数据重分布时大量数据搬迁的问题,减少了数据搬迁时的网络IO和磁盘IO。不过要真正实现不影响业务,还需要改进数据重分布内部的机制,比如 重分布时锁表等 问题。
二. TiDB的扩容是怎么做的以及为什么它几乎不影响业务?
TiDB的扩容机制离不开TiDB整体的架构实现。作为一个存算分离的原生分布式架构,TiDB集群主要由三大模块构成:用于集群元数据管理及集群调度的PD、用于接收外部请求并解析编译执行SQL的计算引擎TiDB Server以及用于数据存储以及多副本数据一致性保证的存储引擎TiKV/TiFlash。
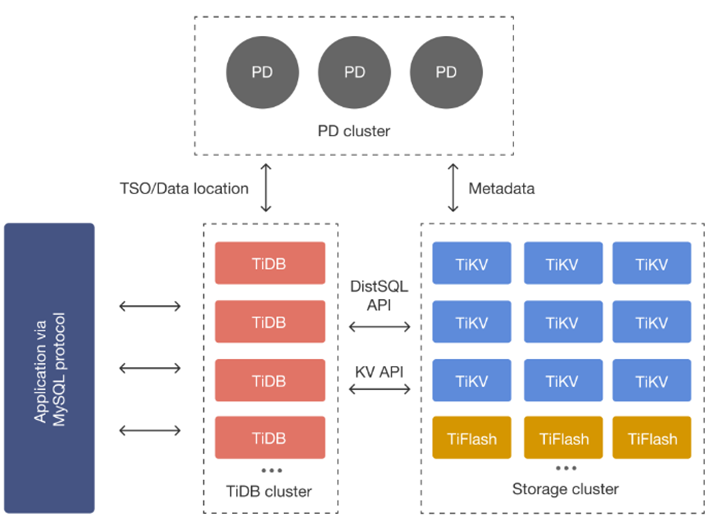
基于存算分离的架构,TiDB可以单独进行计算层扩容和存储层扩容。计算层的扩容相对简单,因为TiDB Server本身是 无状态 的。TiDB Server节点 不持久化数据 ,每个节点也是 完全对等 的,当TiDB Server计算资源不够了,只需要增加TiDB Server节点,然后修改上层的负载均衡组件将客户端连接均衡分发到新的TiDB Server节点即可(目前大多数负载均衡组件都支持动态修改配置)。因此, 计算节点的扩容完全不会影响现有的业务。
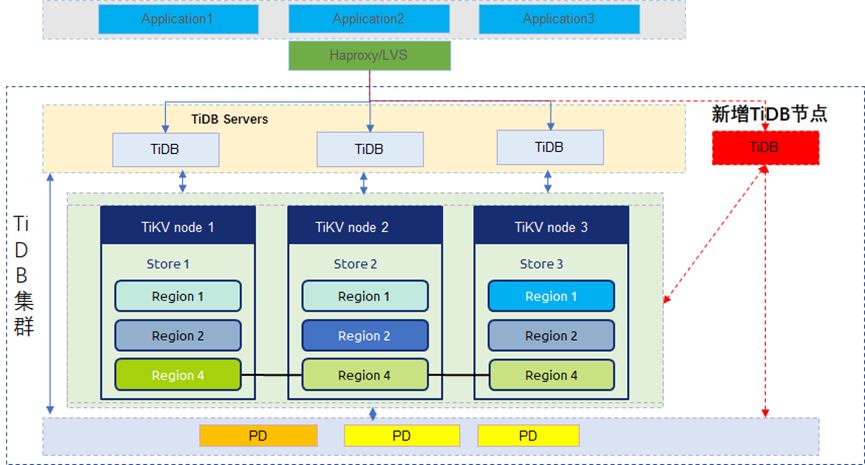
针对存储节点,TiKV的扩容与一般分布式数据库的扩容机制是完全不同的,这主要因为TiKV是一种 基于Multi Raft协议的分布式存储引擎 ,而不是像Greenplum或分库分表那种底层是多个MySQL或PG的单机数据库。
假如某集群要从3个TiKV节点扩容到4个TiKV节点,扩容步骤大致可以概括如下:
1. **扩容TiKV节点。**集群增加一个TiKV 4节点,此时TiKV 4上没有任何Region。PD节点识别到新的TiKV节点启动负载调度机制,计算哪些Region需要迁移到TiKV4。
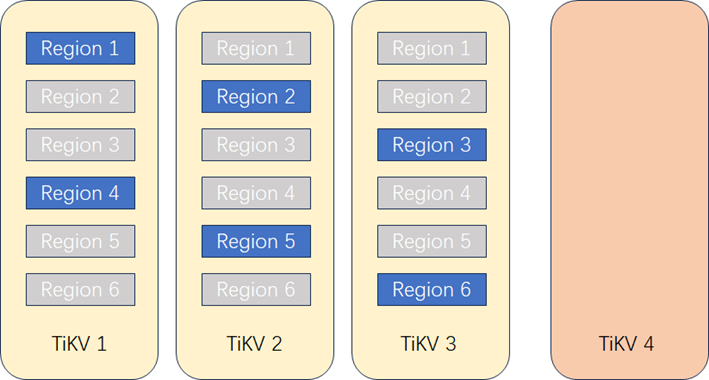
2. **调度算法确定迁移Region。**PD节点根据调度机制,确定将哪些Region副本迁移到TiKV 4上(假如开始3个节点上各有6个Region,平均到4个节点后每个节点的Region数为18/4=4~5个副本)。PD对TiKV1~3上Region对应的Leader副本发起复制指令。
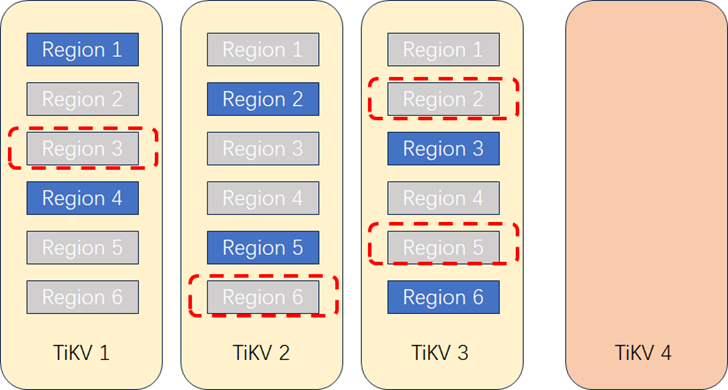
**3. 复制Region到新节点。**在TiKV上创建要复制的Region的副本,通过Raft机制开始复制数据。此过程中应用读写访问不受影响,不过因复制过程产生的IO消耗可能会对性能产生一点影响,不过TiDB本身提供了流控,可以动态调整复制的速度。
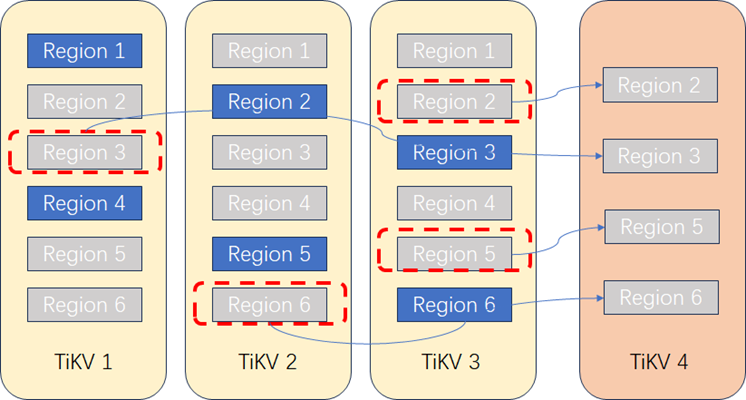
**4. 删除多余Region。**Region复制完成且数据一致后,PD将发起删除原有副本指令,保证每个Region的副本只有3个。
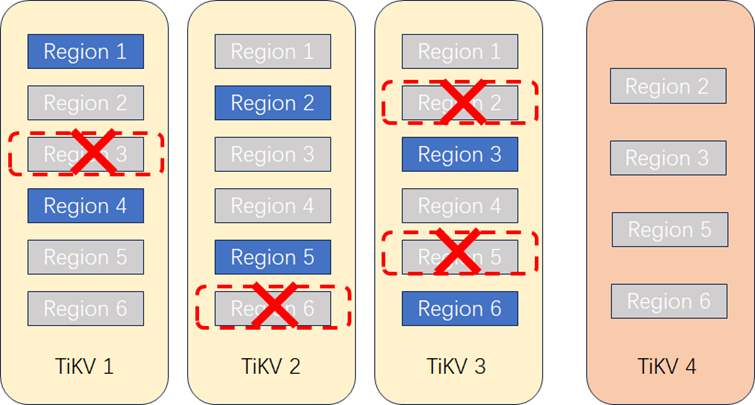
**5. Leader重新均衡。**PD根据调度机制,需要均衡Leader副本,将一部分Region的Leader切换到新增节点TiKV 4上,保证Leader的均衡。Leader切换完成后,读写业务将自动路由到TiKV 4上实现业务负载均衡。
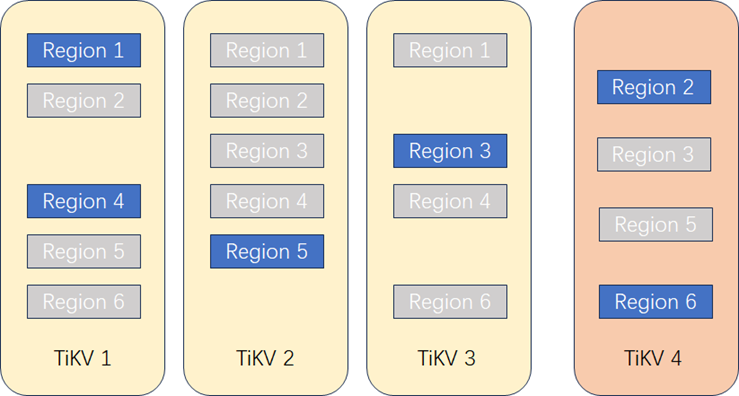
上述步骤简单理解下来就是说,TiKV的扩容是一种 先生成副本再迁移Leader 的一个过程,扩容对业务有影响的地方主要在于生成副本产生的IO消耗以及Leader切换的影响。对于前者,数据库有流控机制可以保证对业务几乎没有影响;对于后者,一方面Leader的切换本身时间非常短,另一方面当TiDB意识到Region迁移后也能够通过内部重试保证前端业务的正常执行。因此, 存储节点的扩容也几乎不会影响现有的业务。
相关文章:
为什么说TiDB在线扩容对业务几乎没有影响
作者: 数据源的TiDB学习之路 原文来源: https://tidb.net/blog/e82b2c5f 当前的数据库种类繁多,墨天轮当前统计的所有国产数据库已经有 290个 ,其中属于关系型数据库的有 166个 。关系型数据库从部署架构上又可以分为集中式…...
STM32--SPI通信协议(2)W25Q64简介
一、W25Q64简介 1、W25Qxx中的xx是不同的数字,表示了这个芯片不同的存储容量; 2、存储器分为易失性与非易失性,主要区别是存储的数据是否是掉电不丢失: 易失性存储器:SRAM、DRAM; 非易失性存储器ÿ…...

svn安装与搭建
1、svn搭建 # yum install subversion -y //安装 # svnserve --version //查看版本 2、创建仓库目录repo # mkdir -p /opt/svn/repo //创建目录 # svnadmin create /opt/svn/repo/ //创建新仓库 # ls !$ …...

什么是缓存击穿、缓存穿透、缓存雪崩?
缓存雪崩 缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。 解决方案 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。一般并发量不是特别多的时…...
springboot153相亲网站
简介 【毕设源码推荐 javaweb 项目】基于springbootvue 的 适用于计算机类毕业设计,课程设计参考与学习用途。仅供学习参考, 不得用于商业或者非法用途,否则,一切后果请用户自负。 看运行截图看 第五章 第四章 获取资料方式 **项…...
CMake生成osg的FFMPEG插件及Windows下不生成VS工程问题解决
在Windows下,如何利用CMake生成osg的FFMPEG插件,请参考如下博文,同生成jpeg插件类似: osg第三方插件的编译方法(以jpeg插件来讲解)。 如下为生成FFMPEG时必要的设置: 注意: 一定要…...

代码随想录算法训练营Day25 | 216.组合总和III、17.电话号码的字母组合
216.组合总和III 与77.组合差不多,就返回条件中收集结果步骤多了一步判断,同时剪枝策略多了一种 vector<vector<int>> ans; vector<int> path; int sum 0;void backtracking(int num, int& k, int& n) {if (path.size() k…...
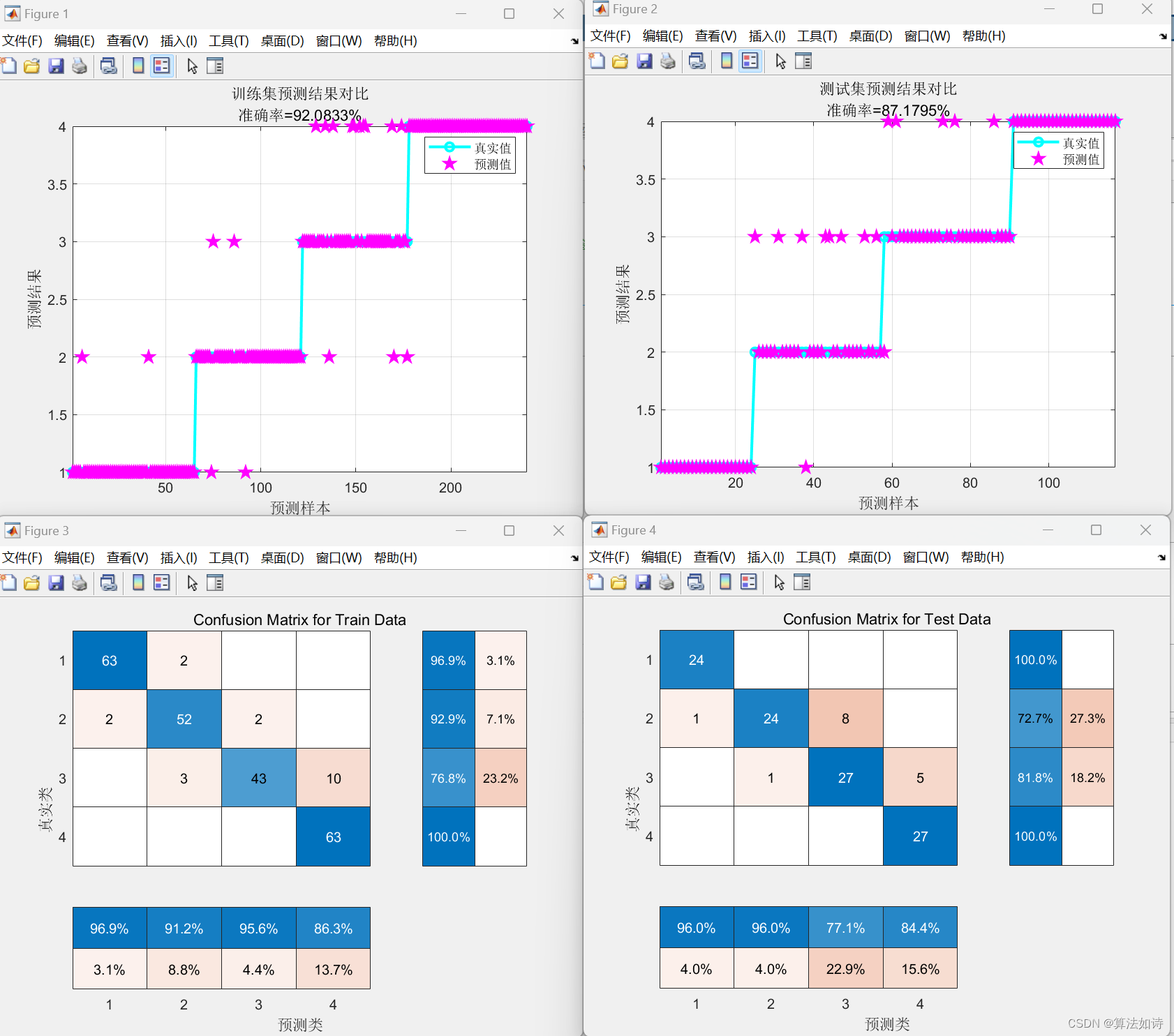
故障诊断 | 一文解决,SVM支持向量机的故障诊断(Matlab)
效果一览 文章概述 故障诊断 | 一文解决,SVM支持向量机的故障诊断(Matlab) 支持向量机(Support Vector Machine,SVM)是一种常用的监督学习算法,用于分类和回归分析。SVM的主要目标是找到一个最优的超平面(或者在非线性情况下是一个最优的超曲面),将不同类别的样本分开…...
)
12.1 Web开发_DOMBOM:JS关联CSS(❤❤)
12.1 Web开发_DOM&BOM 1. DOM&BOM2. DOM:文档对象模型2.1 获取页面元素1. getElementById2. getElementsByClassName3. querySelector3. 事件3.1 事件三要素3.2 绑定事件的三种方式1. 标签on2. 对象.on事件3. addEventListener3.3 常用事件...

scoped样式隔离原理
在 Vue 中,作用域样式(Scoped Styles)是通过以下原理实现的: 1、唯一选择器: 当 Vue 编译单文件组件时,在样式中使用 scoped 特性或 module 特性时,Vue 会为每个样式选择器生成一个唯一的属性…...
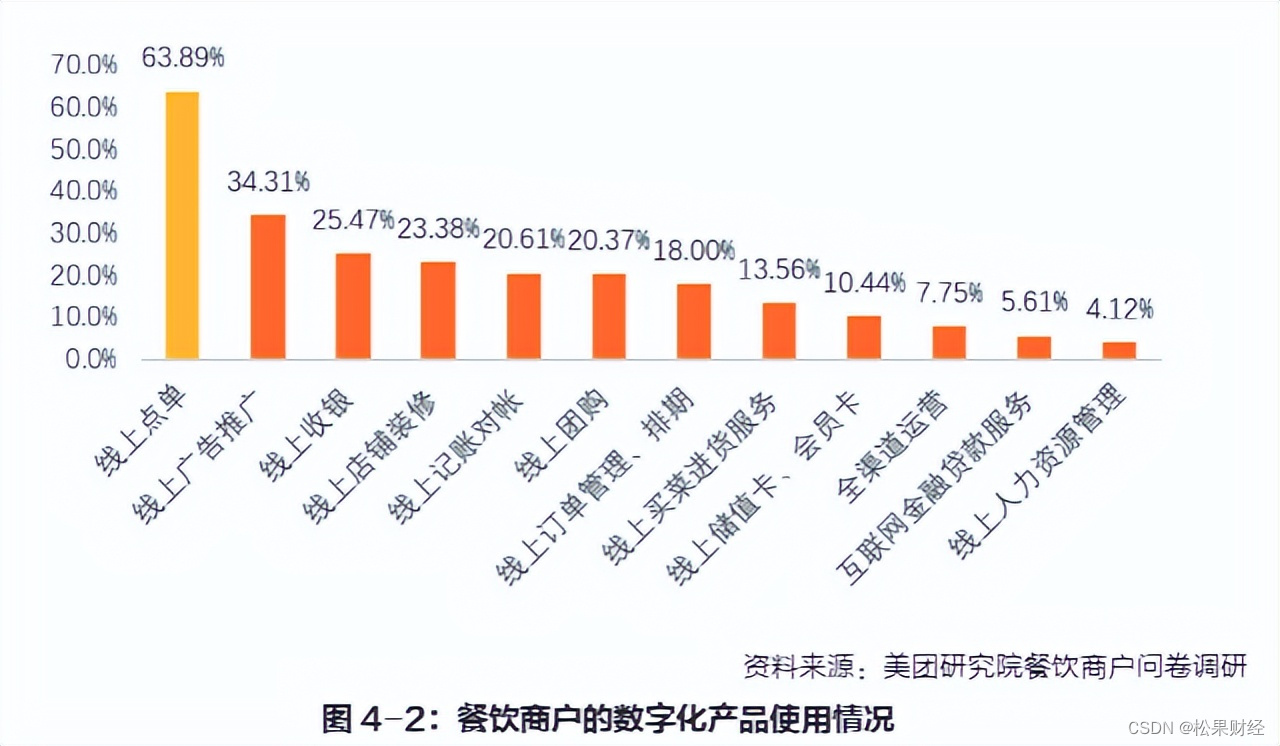
降价不是杀手锏,和府捞面打起“养生牌”
餐饮,“走进来”易,“走上去”难。 作为一个低门槛的创业赛道,每年都有数以万计怀着掘金梦的创业者涌入餐饮业。但是,每年也有无数个理由让餐饮经营者黯然离场。根据辰智大数据预测,2023全年餐饮开店率35.5%ÿ…...

在WORD中设置公式居中编号右对齐设置方式
1 软件环境 Office Microsoft Office LTSC 专业增强版2021 2 最终效果 3 操作步骤 编辑公式;光标定位到公式的最后(不是行的最后);输入#编号光标定位在公式最后(不是行的最后),按Enter键回车…...
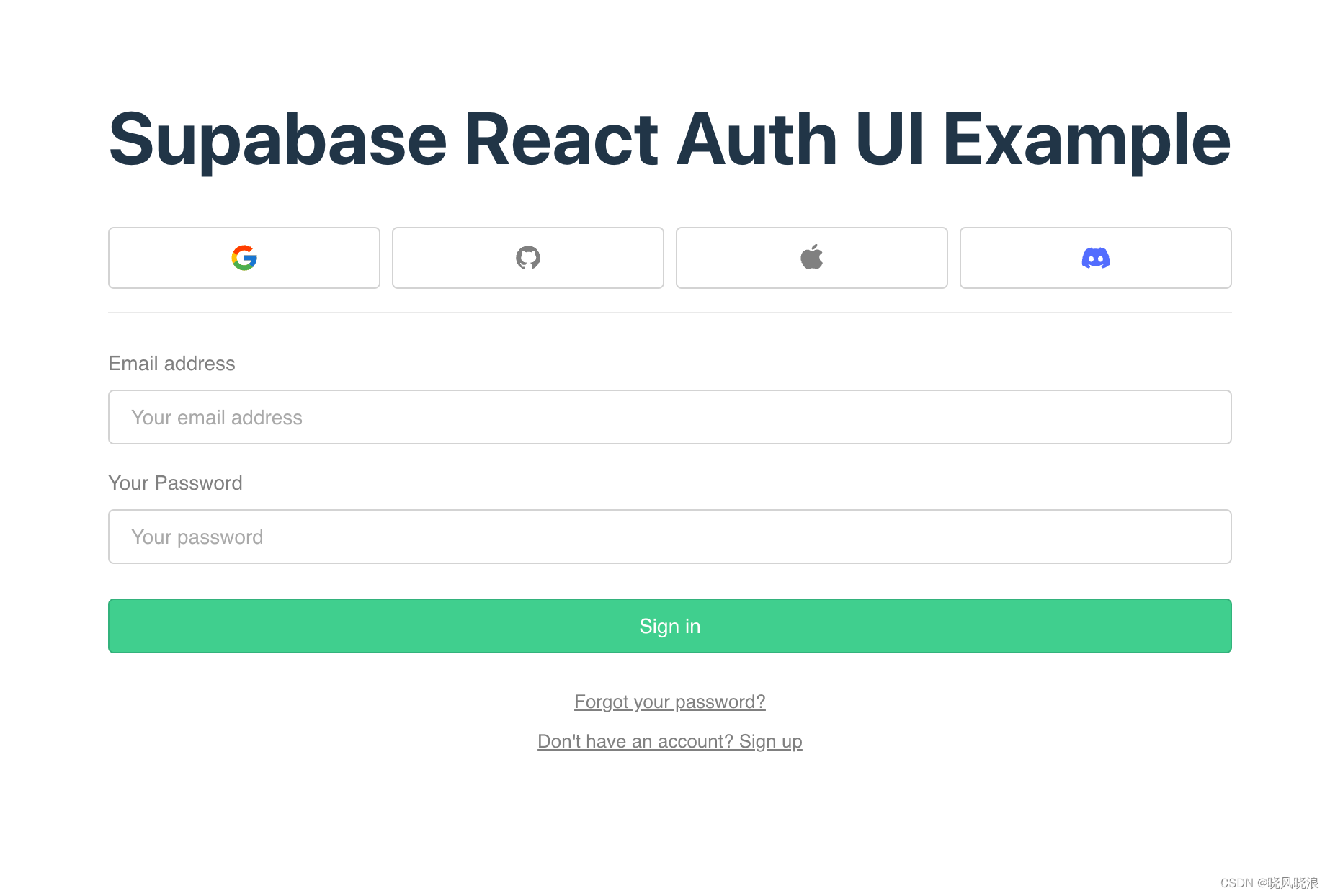
如何使用 Supabase Auth 在您的应用程序中设置身份验证
在本文中,您将学习基本的关键概念,这些概念将帮助您掌握身份验证和授权的工作原理。 您将首先了解什么是身份验证和授权,然后了解如何使用 Supabase auth 在应用程序中实现身份验证。 (本文内容参考:java567.com&…...
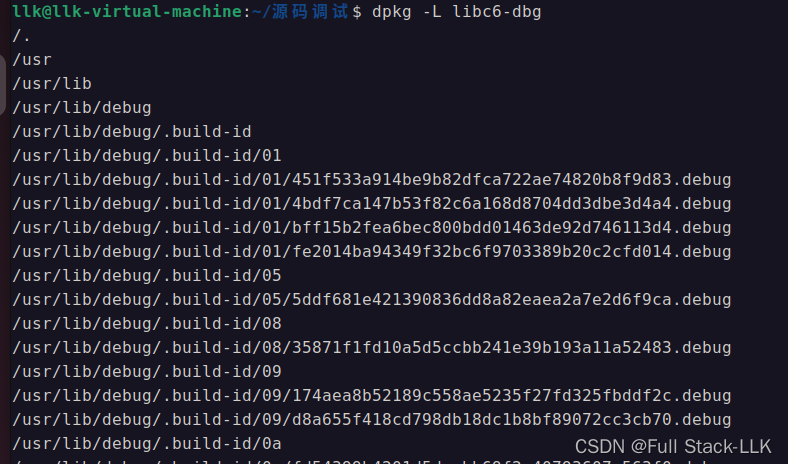
带libc源码gdb动态调试(导入glibc库使得可执行文件动态调试时可看见调用库函数源码)
文章目录 参考部分查看源码是否编译时有-g调试信息和符号表在 gdb 中加载 debug 文件/符号表将 debug 文件放入 ".debug" 文件夹通过 gdb 命令 set debug-file-directory directories GCC的gcc和g区别指定gcc/g,glibc的版本进行编译指定gcc/g的版本指定gl…...

初级通信工程师-通信动力与环境
1、 动力与环境的组成和基本要求 ● 动力与环境的组成: 通信电源系统、机房空调系统、动力环境集中监控管理系统与能耗监测管理系统和接地系统与防雷系统。 ● 网络通信设备对动力与环境的基本要求: 网络通信设备对动力与环境最根本的要求,…...
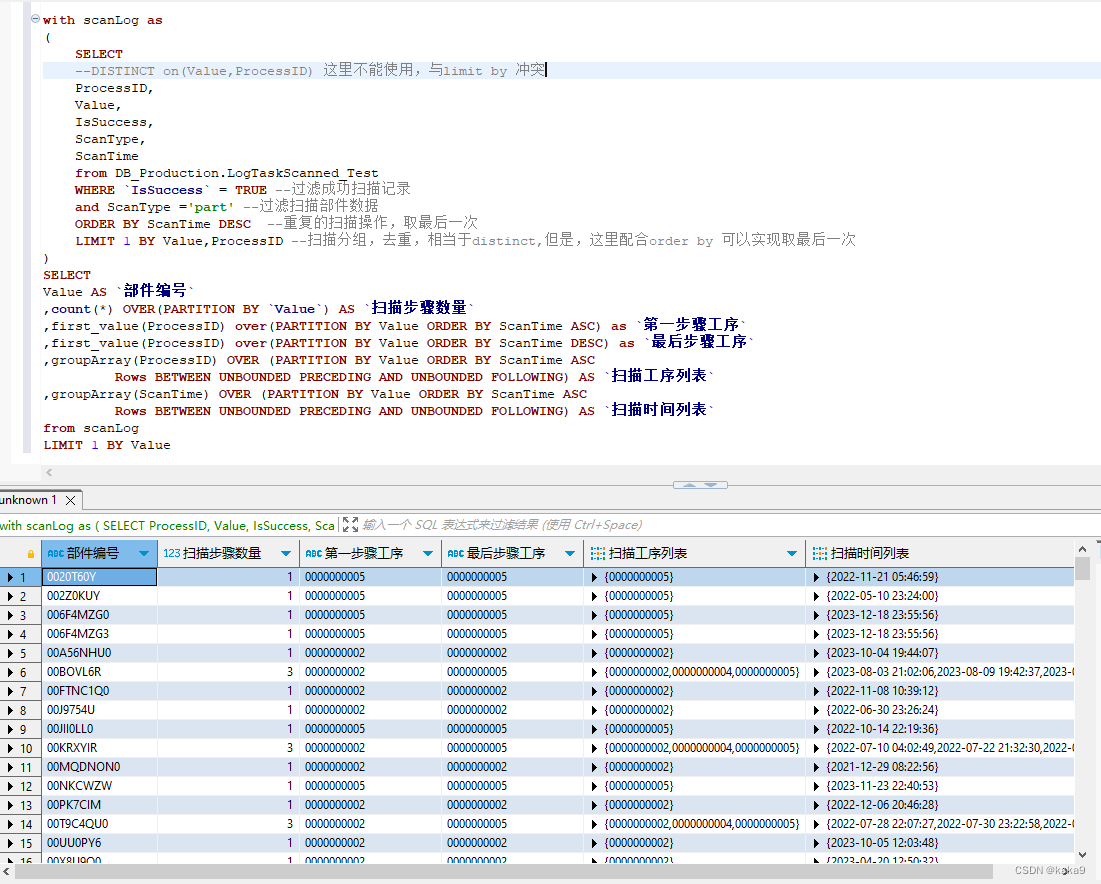
clickhouse在MES中的应用-跟踪扫描
开发的MES,往往都要做生产执行跟踪扫描,这样会产生大量的扫描数据,用关系型数据库,很容易造成查询冲突的问题。 生产跟踪扫描就发生的密度是非常高的,每个零部件的加工过程,都要被记录下来,特别…...

适用于嵌入式单片机的压缩算法
1. 简介 因为MCU的内存和算力的限制,那些对内存消耗大或算力需求大的压缩算法就不适合在MCU中使用。适用于MCU的压缩算法主要有:RLE、LZ77、Huffman、LZO、DEFLATE、LZ4。 2. 算法 2.1. RLE RLE(Run Length Encoding),也称为行程编码&…...
软件工程(最简式总结)
目录 第一章:概述 1.软件危机的表现原因 2.常见的软件开发方法包括: 3.软件工程基本原则 4.软件工程三要素 5.设计模式的分类 6.针对变换型数据流设计步骤 7.针对事务型数据流设计步骤 第二章:软件过程 1.软件生命周期 2.软件过程模型 &…...
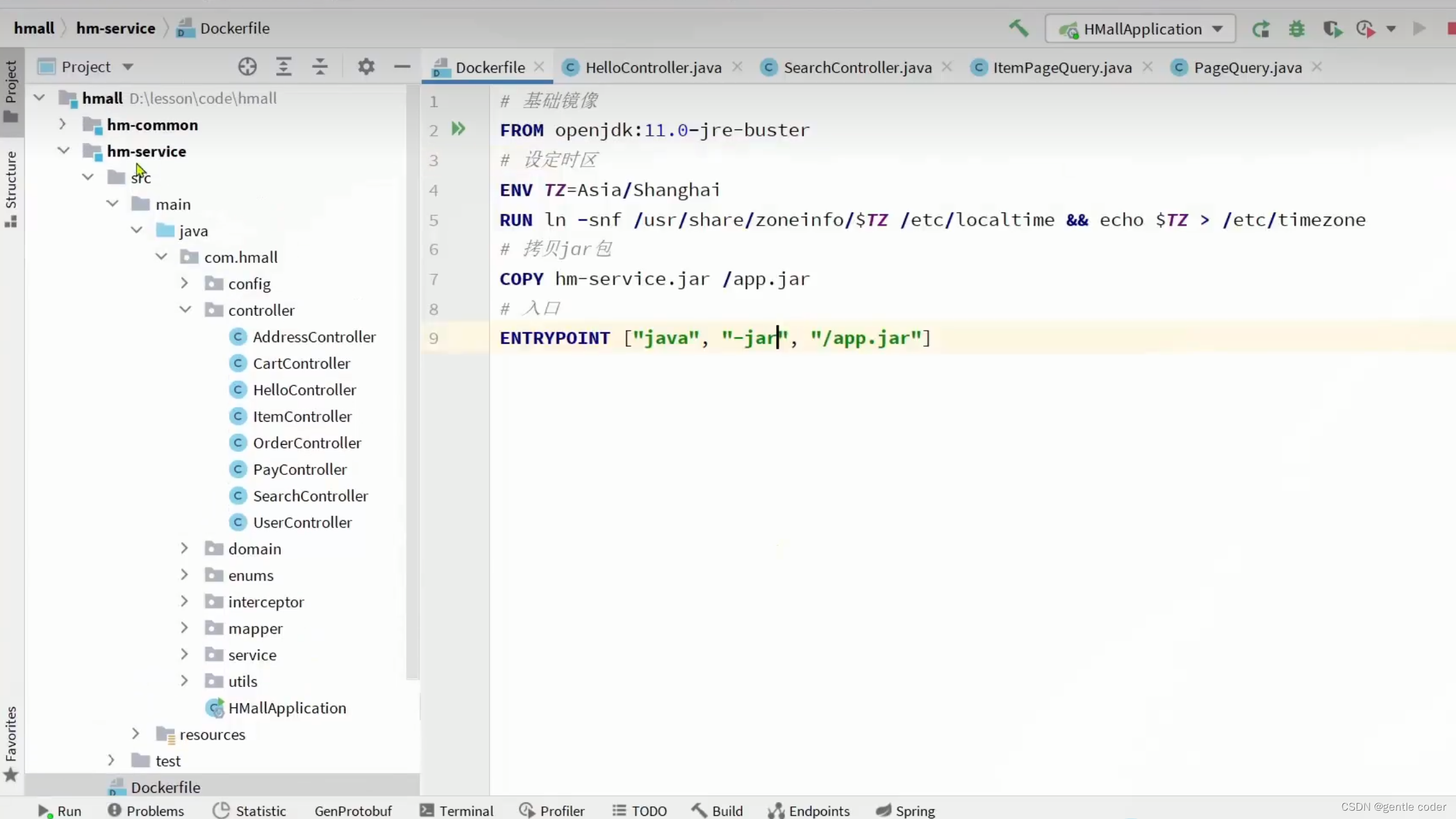
Docker基础(持续更新中)
# 第1步,去DockerHub查看nginx镜像仓库及相关信息# 第2步,拉取Nginx镜像 docker pull nginx# 第3步,查看镜像 docker images # 结果如下: REPOSITORY TAG IMAGE ID CREATED SIZE nginx latest 60…...
Vue工程引入Element-ui
npm 安装ELement-ui npm i element-ui -S 于package.json中发现有“element-ui”版本号即可 引入 Element 在 main.js 中写入以下内容: import element-ui/lib/theme-chalk/index.css; import ElementUI from element-ui;Vue.use(ElementUI);之后根据自己的需求设计…...

BaiduNetdiskPlugin-macOS:解决百度网盘下载速度限制的实用优化方案
BaiduNetdiskPlugin-macOS:解决百度网盘下载速度限制的实用优化方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 在macOS环境下使用百度…...

终极指南:如何快速为设计添加地图填充效果 - Sketch Map Generator 插件完全解析
终极指南:如何快速为设计添加地图填充效果 - Sketch Map Generator 插件完全解析 【免费下载链接】sketch-map-generator Sketch plugin to fill a shape with a map generated from a given location using Google Maps and Mapbox 项目地址: https://gitcode.co…...

BGE-Large-Zh效果可视化:向量维度投影图+相似度分布直方图双模展示
BGE-Large-Zh效果可视化:向量维度投影图相似度分布直方图双模展示 1. 项目概述 BGE-Large-Zh是一款专为中文语义理解设计的本地化向量化工具,基于BAAI的bge-large-zh-v1.5模型开发。这个工具能够将中文文本转换为1024维的语义向量,并通过计…...

突破硬件壁垒:开源驱动技术如何解锁跨系统硬件潜能
突破硬件壁垒:开源驱动技术如何解锁跨系统硬件潜能 【免费下载链接】DFRDisplayKm Windows infrastructure support for Apple DFR (Touch Bar) 项目地址: https://gitcode.com/gh_mirrors/df/DFRDisplayKm 副标题:从驱动开发到功能实现——让专属…...

IronPython 3扩展开发指南:构建自定义模块与SQLite集成
IronPython 3扩展开发指南:构建自定义模块与SQLite集成 【免费下载链接】ironpython3 Implementation of Python 3.x for .NET Framework that is built on top of the Dynamic Language Runtime. 项目地址: https://gitcode.com/gh_mirrors/ir/ironpython3 …...

霍里思特获2亿融资,矿业分选新势力崛起?
硬氪消息,矿石AI智能分选设备企业霍里思特完成近2亿元C轮融资,由招商局资本领投。该公司技术实力强,产品优势明显,市场表现佳,未来发展值得关注。融资情况与用途霍里思特完成近2亿元C轮融资,由招商局资本领…...

用SystemVerilog约束玩点花的:模拟CPU负载、网络包生成与游戏道具掉落
用SystemVerilog约束玩点花的:模拟CPU负载、网络包生成与游戏道具掉落 在硬件验证领域之外,SystemVerilog的约束随机化机制其实是一把被低估的瑞士军刀。想象一下,你能否用芯片验证的工具来设计一个游戏道具系统?或者用它来生成逼…...

从“画个女孩”到“绝世圣女”:圣女司幼幽-造相Z-Turbo提示词进阶指南
从“画个女孩”到“绝世圣女”:圣女司幼幽-造相Z-Turbo提示词进阶指南 1. 理解圣女司幼幽-造相Z-Turbo模型特性 1.1 模型定位与核心优势 圣女司幼幽-造相Z-Turbo是基于Z-Image-Turbo的LoRA微调版本,专门针对"牧神记"中的圣女司幼幽角色进行…...

Spire.Doc转PDF授权限制解析与解决方案
1. Spire.Doc转PDF的三页限制是怎么回事 第一次用Spire.Doc转换PDF时,我盯着生成的3页文档愣了半天——明明50页的Word文件,怎么输出就只剩个开头了?后来查文档才发现,这是未授权版本的硬性限制。就像试用版软件经常会有功能阉割&…...

5分钟搞定OpenClaw+百川2-13B:WebUI v1.0极简配置指南
5分钟搞定OpenClaw百川2-13B:WebUI v1.0极简配置指南 1. 为什么选择这个组合? 上周我在调试一个本地自动化助手时,发现OpenClaw默认对接的云端模型响应速度不稳定,于是决定尝试本地部署百川2-13B量化版。这个组合带来的最直接好…...