今日arXiv最热NLP大模型论文:微软提出SliceGPT,删除25%模型参数,性能几乎无损
引言:探索大型语言模型的高效压缩方法
随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,它们对计算和内存资源的巨大需求成为了一个不容忽视的问题。为了缓解这些资源限制,研究者们提出了多种模型压缩方法,其中剪枝(pruning)技术因其在后训练阶段应用的潜力而备受关注。然而,现有的剪枝技术面临着需要额外数据结构支持和在当前硬件上受限的加速效果等挑战。在这篇博客中,我们将探讨一种新的剪枝方案——SliceGPT,它通过删除权重矩阵的行和列来压缩大型模型,同时保持了模型的性能。
论文标题:
SLICEGPT: COMPRESS LARGE LANGUAGE MODELS BY DELETING ROWS AND COLUMNS
论文机构:
ETH Zurich, Microsoft Research
论文链接:
https://arxiv.org/pdf/2401.15024.pdf
项目地址:
https://github.com/microsoft/TransformerCompression
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!
SliceGPT的核心思想是利用变换器网络中的计算不变性,通过对每个权重矩阵应用正交矩阵变换,使得模型的计算结果保持不变。这种方法不仅减少了模型的参数数量,还降低了嵌入维度,从而减少了网络之间传递的信号量。通过大量实验,研究者们证明了SliceGPT能够在保持高达99%的零样本任务性能的同时,剪掉高达25%的模型参数。更重要的是,这种压缩方法无需额外的代码优化,就能在现有的硬件上实现更快的运行速度,这为未来减少预训练模型的内存和计算需求提供了新的视角。
SliceGPT方法概述:如何通过删除权重矩阵的行和列来压缩模型
SliceGPT是一种新颖的模型压缩方法,它通过删除权重矩阵的行和列来减少大型语言模型的参数数量。这种方法的核心思想是通过对模型的权重矩阵进行“切片”操作,即去除整行或整列,从而实现对模型的压缩。与其他剪枝方法不同,SliceGPT不仅仅是将权重矩阵中的某些元素设为零,而是完全移除掉权重矩阵的一部分。
在SliceGPT中,首先对网络进行单次变换,使得预测保持不变,然后再进行切片操作。这种变换保证了即使在切片后,模型的预测性能也只会受到很小的影响。通过这种方法,可以在不牺牲太多性能的前提下,显著减少模型的参数数量。例如,在LLAMA-2 70B、OPT 66B和Phi-2模型上的实验表明,SliceGPT能够在保持99%、99%和90%的零样本任务性能的同时,移除多达25%的模型参数。
SliceGPT的另一个优势是,压缩后的模型可以在更少的GPU上运行,并且运行速度更快,无需额外的代码优化。例如,在24GB的消费级GPU上,LLAMA-2 70B模型的推理计算量减少到了稠密模型的64%;在40GB的A100 GPU上,减少到了66%。
1. 切片前的准备:
在进行切片之前,需要对网络进行一次变换,以确保变换后的网络可以保持预测的不变性。这一步骤至关重要,因为它确保了在切片操作之后,模型的性能不会受到太大影响。
2. 切片操作:
切片操作涉及到移除权重矩阵的行和列。具体来说,就是在变换后的权重矩阵中,移除那些对模型性能贡献较小的行和列。这样,权重矩阵变得更小,网络的嵌入维度也随之减少。
3. 实验验证:
通过在不同的模型和任务上进行实验,SliceGPT证明了其在压缩模型方面的有效性。实验结果显示,即使在移除了大量参数的情况下,模型仍能保持较高的性能。
计算不变性的发现:理解RMSNorm操作如何使得变换保持不变
SliceGPT方法的成功部分归功于对变换网络中的计算不变性的发现。具体来说,研究者们发现,可以在变换器网络的每个权重矩阵上应用正交矩阵变换,而不改变模型的输出。这种计算不变性是通过RMSNorm操作实现的,该操作在网络的不同块之间执行,并保持变换的不变性。
正交矩阵和RMSNorm:
正交矩阵Q满足Q^TQ = QQ^T = I的关系,其中I是单位矩阵。正交矩阵的一个重要性质是,它不会改变向量的范数。RMSNorm操作通过将输入矩阵X的每一行除以其范数来实现规范化。由于正交变换不改变向量的范数,因此在RMSNorm之前和之后应用正交矩阵Q和Q^T不会改变网络的输出。
计算不变性的证明:
在RMSNorm连接的变换器网络中,如果在RMSNorm之前插入带有正交矩阵Q的线性层,在RMSNorm之后插入Q^T,则网络保持不变。这是因为信号矩阵的每一行都被Q乘以,规范化后再乘以Q^T,从而保持了网络的计算不变性。这一发现是SliceGPT能够成功压缩模型的关键。
通过这种计算不变性,SliceGPT能够在保持模型性能的同时,显著减少模型的参数数量和计算需求。这一发现不仅对于SliceGPT方法至关重要,也为未来减少预训练模型的内存和计算需求提供了新的思路。
实现模型压缩
在深度学习和自然语言处理领域,大型语言模型(LLMs)因其出色的性能而备受青睐。然而,这些模型通常参数量巨大,需要消耗大量的计算和内存资源。为了解决这一问题,研究者们提出了多种模型压缩技术,其中SliceGPT是一种新颖的后训练稀疏化方案,它通过替换权重矩阵为更小的矩阵来降低网络的嵌入维度,从而实现模型的压缩。
1. SliceGPT的PCA方法
SliceGPT的核心思想是利用计算不变性(computational invariance),即在不改变模型输出的前提下,对权重矩阵进行正交变换。具体来说,SliceGPT首先通过主成分分析(PCA)计算出每个权重矩阵的正交矩阵Q。这一步骤的目的是将信号矩阵投影到其主成分上。在这个过程中,研究者们发现不同网络块的信号并不对齐,因此需要在每个块应用不同的正交矩阵Qℓ。
2. 模型压缩过程
在计算出正交矩阵Qℓ后,SliceGPT通过删除权重矩阵的行或列来减小模型大小。这一过程称为“切片”(slicing)。由于PCA的目标是计算出一个低维表示Z,并进行近似重构,SliceGPT将这一思想应用到信号矩阵X之间,通过删除矩阵的次要主成分来实现压缩。具体来说,SliceGPT删除了Win的行和Wout及Wembd的列,并且还删除了插入到残差连接中的矩阵Q⊤ℓ−1Qℓ的行和列。
通过这种方法,SliceGPT成功地压缩了包括LLAMA-2 70B、OPT 66B和Phi-2在内的多个模型,最多减少了30%的参数量,同时保持了超过90%的密集模型性能。
实验设置
1. 使用的模型
在实验中,研究者们使用了OPT、LLAMA-2和Phi-2模型家族进行评估。这些模型是基于Transformer架构的大型语言模型,具有数十亿的参数量。实验排除了OPT 175B模型,因为它的性能不如较小的LLAMA-2模型。
2. 任务
实验涵盖了语言生成和流行的零样本任务。零样本任务包括PIQA、WinoGrande、HellaSwag、ARC-e和ARC-c等知名任务。
3. GPU类型
为了全面展示SliceGPT带来的速度提升,实验使用了多种GPU类型,包括Quadro RTX6000(24GB内存)作为消费级GPU的代表,以及40GB A100和80GB H100作为数据中心级别的基准。通过这些不同的GPU,研究者们能够评估SliceGPT在不同硬件条件下的性能和效率。
实验结果表明,SliceGPT不仅能够在单个GPU上快速完成模型压缩,而且在不同的GPU上都展现出了显著的速度和性能提升。
实验结果分析
1. 语言生成任务的性能表现
在语言生成任务中,SliceGPT的性能通过WikiText-2数据集进行评估。实验结果显示,应用SliceGPT到OPT模型与LLAMA-2模型时,随着模型大小的增加,SliceGPT的性能也随之提升。与SparseGPT采用的2:4稀疏比例相比,SliceGPT在25%的切片水平上表现更优。例如,在LLAMA-2模型上,SliceGPT的表现超过了SparseGPT 2:4。对于OPT模型,30%切片的模型在除了2.7B之外的所有模型大小上都优于2:4稀疏比例。
2. 零样本任务的性能表现
在零样本任务中,SliceGPT在五个知名任务上进行了评估:PIQA、WinoGrande、HellaSwag、ARC-e和ARC-c。实验结果表明,Phi-2模型的切片版本与LLAMA-2 7B模型的切片版本性能相当。最大的OPT和LLAMA-2模型可以非常有效地压缩,即使移除了30%的66B OPT模型的参数,性能损失也只有几个百分点。
3. 通过吞吐量和推理时间评估模型效率
在吞吐量方面,与稠密模型相比,SliceGPT在80GB H100 GPU上对25%和50%切片的模型进行了评估。实验发现,25%切片的模型在吞吐量上比稠密模型提高了高达1.55倍。在50%切片的情况下,最大的模型只需要一个GPU而不是两个,吞吐量显著提高:分别为3.13倍和1.87倍。这意味着对于固定数量的GPU,这些模型达到了稠密模型的6.26倍和3.75倍吞吐量。
在推理时间方面,SliceGPT压缩模型的端到端运行时间也得到了研究。在Quadro RTX6000和A100 GPU上,使用25%切片的模型在生成单个令牌的时间上分别比稠密模型快了16-17%和11-13%。在两种情况下,都减少了使用的GPU数量,相对于部署稠密模型,提供了能源和成本节约。例如,对于LLAMA-2 70B,使用RTX6000 GPU的计算需求从1764 GPUms减少到1075 GPUms。
恢复微调(RFT)的效果:探讨RFT对压缩模型性能的影响
恢复微调(RFT)是在切片后对模型进行少量微调,以恢复因切片而损失的性能。实验中,对切片后的LLAMA-2和Phi-2模型应用了RFT,使用LoRA方法进行微调。微调后,Phi-2模型在仅使用WikiText-2数据集时无法恢复从切片中损失的准确率,但使用Alpaca数据集后,能够恢复几个百分点的准确率。例如,25%切片并进行RFT后的Phi-2模型的平均准确率为65.2%,而稠密模型为72.2%。切片模型大约有2.2B参数,并保留了2.8B模型90.3%的准确率。这表明即使是小型语言模型也可以从训练后的剪枝中受益。
结论与未来工作
在本文中,我们介绍了SliceGPT,这是一种新的大型语言模型(LLM)的后训练稀疏化方案。SliceGPT通过替换每个权重矩阵为一个更小的(稠密)矩阵,从而减少了网络的嵌入维度。通过广泛的实验,我们证明了SliceGPT能够在保持高性能的同时,显著减少模型参数的数量。例如,在LLAMA-2 70B、OPT 66B 和 Phi-2 模型上,我们能够去除高达25%的模型参数,同时保持了99%、99% 和 90%的零样本任务性能。此外,我们的切片模型能够在更少的GPU上运行,并且运行速度更快,无需任何额外的代码优化。
1. 计算不变性的发现: 我们提出了计算不变性的概念,并展示了如何在不改变模型输出的情况下,对变换器网络中的每个权重矩阵应用正交矩阵变换。
2. 切片转换的应用: 我们利用这一发现,对变换器架构的每个块进行编辑,将信号矩阵投影到其主成分上,并移除变换后权重矩阵的行或列以减小模型大小。
3. 实验验证: 我们在OPT、LLAMA-2和Phi-2模型上进行了多项实验,展示了SliceGPT在压缩这些模型方面的能力,压缩比可达30%,并在下游任务上保持了超过90%的密集模型性能。
未来的研究方向可能包括:
-
参数更少的密集LMs性能: 我们发现,参数更少但密集的LMs在性能上优于参数少于13B的剪枝LMs。我们预计,随着研究的深入,这种情况不会持续太久。我们的剪枝模型虽然参数更多,但允许在GPU内存中加载更大的批量大小,并且没有稀疏结构的开销。结合这两种方法可能会获得最佳效果。
-
计算Q的其他方法: 探索其他计算Q的方法可能会改善结果。
-
降低推理时间和GPU数量: 为了进一步减少推理时间和所需的GPU数量,可以使用量化和结构性剪枝等补充方法。
我们希望我们对计算不变性的观察能够帮助未来的研究在提高深度学习模型的效率方面取得进展,并可能激发新的理论洞见。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!

相关文章:
今日arXiv最热NLP大模型论文:微软提出SliceGPT,删除25%模型参数,性能几乎无损
引言:探索大型语言模型的高效压缩方法 随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,它们对计算和内存资源的巨大需求成为了一个不容忽视的问题。为了缓解这些资源限制,研究者们提出了多种模型压缩方法&#…...
 写一个属于自己的 ChatGPT 新版 WebUI)
ChatGPT实战100例 - (13) 写一个属于自己的 ChatGPT 新版 WebUI
文章目录 ChatGPT实战100例 - (13) 写一个属于自己的 ChatGPT 新版 WebUI一、ChatGPT(OpenAI)的新版API调用1.1 环境变量配置与调用1.2 新版api调用1.3 命令行流式输出二、Gradio制作自己的聊天WebUI2.1 流式WebUI2.2 样式调整三、总结参考ChatGPT实战100例 - (13) 写一个属于自…...

【计算机学院寒假社会实践】——服务走进社区,共绘幸福蓝图
为深入贯彻落实志愿者服务精神,扎实推进志愿者服务质量,2024年1月28日,曲阜师范大学计算机学院“青年扎根基层,服务走进社区”社会实践队队员周兴睿在孙宇老师的指导下,来到山东省滨州市陈集街道社区开展了为期一天的“…...
[python] 过年燃放烟花
目录 新年祝福语 一、作品展示 二、作品所用资源 三、代码与资源说明 四、代码库 五、完整代码 六、总结 新年祝福语 岁月总是悄然流转,让人感叹时间的飞逝,转眼间又快到了中国传统的新年(龙年)。 回首过去…...
数据结构与算法:图论(邻接表板子+BFS宽搜、DFS深搜+拓扑排序板子+最小生成树MST的Prim算法、Kruskal算法、Dijkstra算法)
前言 图的难点主要在于图的表达形式非常多,即数据结构实现的形式很多。算法本身不是很难理解。所以建议精通一种数据结构后遇到相关题写个转换数据结构的接口,再套自己的板子。 邻接表板子(图的定义和生成) public class Graph…...

Python之PySpark简单应用
文章目录 一、介绍1.准备工作2. 创建SparkSession对象:3. 读取数据:4. 数据处理与分析:5. 停止SparkSession: 二、示例1.读取解析csv数据2.解析计算序列数据map\flatmap 三、问题总结1.代码问题2.配置问题 一、介绍 PySpark是Apa…...
降维(Dimensionality Reduction)
一、动机一:数据压缩 这节我将开始谈论第二种类型的无监督学习问题,称为降维。有几个原因使我们可能想要做降维,其一是数据压缩,它不仅允许我们压缩数据使用较少的计算机内存或磁盘空间,而且它可以加快我们的学习算法。…...
怎样调用浏览器插件(如metamask小狐狸钱包))
web应用(网页)怎样调用浏览器插件(如metamask小狐狸钱包)
下边是与gpt的对话,代码可以在浏览器控制台验证 一,在网页上点击一个连接按钮 然后小狐狸钱包就打开了,是怎么实现的呢 当你在网页上点击一个连接按钮,然后自动打开MetaMask(通常被称为“小狐狸钱包”,一种…...
2024美赛数学建模C题完整论文教学(含十几个处理后数据表格及python代码)
大家好呀,从发布赛题一直到现在,总算完成了数学建模美赛本次C题目Momentum in Tennis完整的成品论文。 本论文可以保证原创,保证高质量。绝不是随便引用一大堆模型和代码复制粘贴进来完全没有应用糊弄人的垃圾半成品论文。 C论文共49页&…...
Matplotlib绘制炫酷柱状图的艺术与技巧【第60篇—python:Matplotlib绘制柱状图】
文章目录 Matplotlib绘制炫酷柱状图的艺术与技巧1. 簇状柱状图2. 堆积柱状图3. 横向柱状图4. 百分比柱状图5. 3D柱状图6. 堆积横向柱状图7. 多系列百分比柱状图8. 3D堆积柱状图9. 带有误差线的柱状图10. 分组百分比柱状图11. 水平堆积柱状图12. 多面板柱状图13. 自定义颜色和样…...

window 挂载linux 网盘
背景:因为很多情况下,作为开发人员,我们都希望用Linux的编译环境,但是可以用windows下各种IDE来写code; linux 服务器安装NFS服务 说明:NFS 服务就是让不同的计算机可以在不同的操作系统之间共享文件,采用的就是服务端/客户端的架构,在NFS服务器上将目录设置为输出目录(…...

windows10忘记密码的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
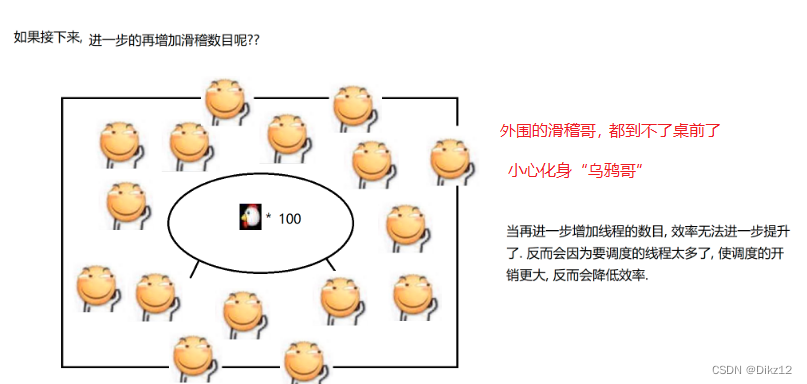
进程和线程的区别详解
🎥 个人主页:Dikz12📕格言:那些在暗处执拗生长的花,终有一日会馥郁传香欢迎大家👍点赞✍评论⭐收藏 目录 进程 进程在系统中是如何管理的 进一步认识PCB 线程 能否一直增加线程数目来提高效率 进程和线程…...

(基于xml配置Aop)学习Spring的第十五天
一 . Spring Aop编程简介 再详细点 , 如下 二 . 基于xml配置Aop 解决proxy相关问题 解决问题开始用xml配置AOP 导入pom坐标 <dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId><version>1.9.6</vers…...

Centos7环境安装PHP8
一、安装必要的模块 yum install -y bzip2-devel libcurl-devel libxml2-devel sqlite-devel oniguruma oniguruma-devel libxml2 libxml2-devel bzip2 bzip2-devel libcurl libcurl-devel libjpeg libjpeg-devel zstd libzstd-devel curl libcurl-devel libpng libpng-devel …...
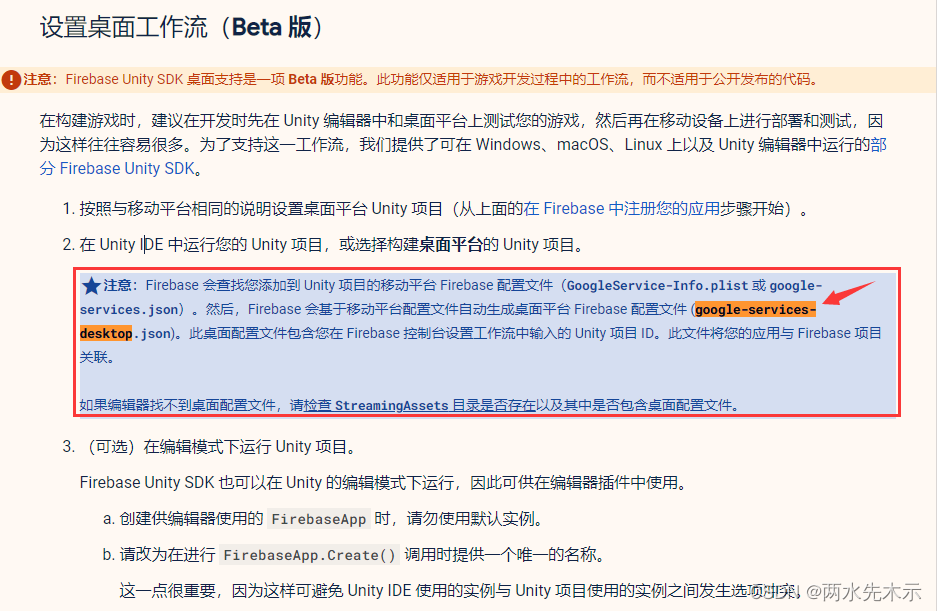
No matching client found for package name ‘com.unity3d.player‘
2024年2月5日更新 必须使用Unity方式接入Unity项目!一句话解决所有问题。(真的别玩Android方式) 大致这问题出现原因是我在Unity采用了Android方式接入Firebase,而Android接入实际上和Unity接入方式有配置上的不一样,我…...
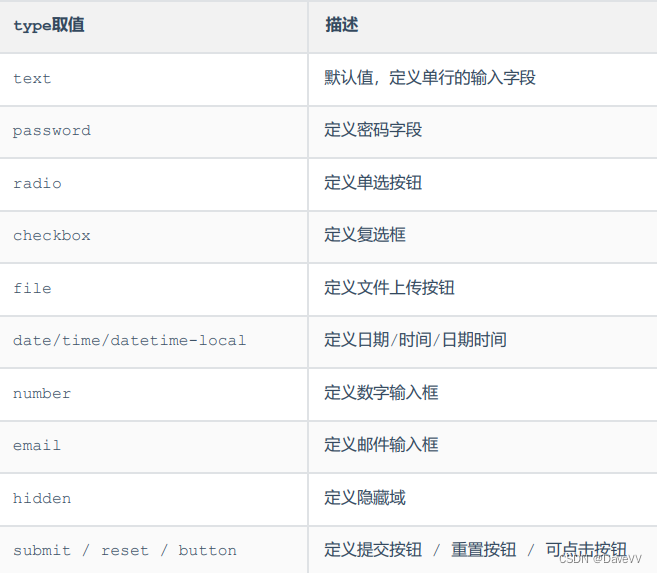
JavaWeb之HTML-CSS --黑马笔记
什么是HTML ? 标记语言:由标签构成的语言。 注意:HTML标签都是预定义好的,HTML代码直接在浏览器中运行,HTML标签由浏览器解析。 什么是CSS ? 开发工具 VS Code --安装文档和安装包都在网盘中 链接:https://p…...
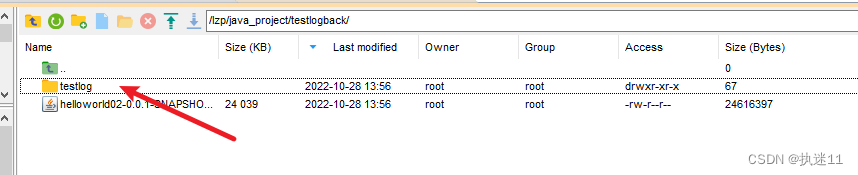
logback日志配置
springboot默认使用logback 无需额外添加pom依赖 1.指定日志文件路径 当前项目路径 testlog文件夹下 linux会在项目jar包同级目录 <property name"log.path" value"./testlog" /> 如果是下面这样配置的话 window会保存在当前项目所在盘的home文件夹…...
SpringBoot集成Flowable工作流
文章目录 一、了解Flowable1. 什么是Flowable2. Flowable基本流程3. Flowable主要几张表介绍 二、SpringBoot集成Flowable1. 在idea中安装Flowable插件2. SpringBoot集成Flowable3. SpringBoot集成Flowable前端页面 三、创建流程模版(以请假为例) 提示:以下是本篇文…...

try-with-resources 语法详解
目录 一、介绍 二、用法对比 三、优势 四、原理分析 一、介绍 在Java 7中,引入了一项重要的语法糖——try-with-resources,这项特性的目的是为了更有效地处理资源的管理。资源指的是需要在代码执行完毕后手动关闭的对象,比如文件流、网络…...

洪城寻缘角
洪城寻缘角 南昌人的免费寻缘平台 不必再奔波相亲角,不必被收费套路困扰 洪城寻缘角,全功能永久免费 无需注册即可登记,一键发布个人资料 支持多条件精准筛选,快速匹配同频有缘人 覆盖南昌全城单身,真实、高效、安心…...

前端CSS样式详细笔记
文章目录一、CSS基础概念1. 什么是CSS2. CSS三大核心特性3. CSS基本语法结构二、CSS引入方式三、CSS选择器详解1. 基础选择器2. 组合选择器3. 属性选择器4. 伪类与伪元素四、选择器优先级规则1. 优先级计算方法2. 优先级实战示例3. 优先级注意事项五、CSS盒模型1. 盒模型组成2.…...
部署到ROS或Simulink?)
从仿真到实战:如何将你的MATLAB机械臂轨迹规划代码(3-5-3插值)部署到ROS或Simulink?
从仿真到实战:MATLAB机械臂轨迹规划代码的ROS与Simulink部署指南 当你完成了MATLAB中机械臂轨迹规划的算法开发,看着屏幕上平滑的位置、速度和加速度曲线,接下来面临的核心问题是如何将这些数据转化为真实机械臂的动作。本文将深入探讨两种主…...

【花雕学编程】代码泄露之后:深度剖析Claude开源对开发者生态的冲击与机遇
导语:2026年3月31日,Anthropic 旗下 Claude Code CLI 客户端源码意外泄露,1906个源文件、51.2万行TypeScript代码被开发者备份至 GitHub 仓库 instructkr/claude-code,标注为“仅供研究”。这场看似偶然的打包失误,并非…...

不用手动设置滤波参数,程序自动根据信号特征,匹配滤波参数,零基础也能抗干扰。
在智能仪器的世界里,我们经常面临一个尴尬的局面:实验室里算法跑得飞起,一到现场就被噪声淹没。今天,我将结合《智能仪器设计》中的自适应信号处理理念,带你手撸一个“傻瓜式”自适应滤波器。这个工具的目标很明确&…...

Redis可视化管理解决方案:AnotherRedisDesktopManager实战指南
Redis可视化管理解决方案:AnotherRedisDesktopManager实战指南 【免费下载链接】AnotherRedisDesktopManager 🚀🚀🚀A faster, better and more stable Redis desktop manager [GUI client], compatible with Linux, Windows, Mac…...
)
深度学习篇---全局平均池化(Global Average Pooling, GAP)
全局平均池化是深度学习中一个优雅而强大的操作,它通过极简的设计解决了全连接层参数量爆炸的问题,同时增强了模型的泛化能力。 一、什么是全局平均池化? 1. 基本定义 全局平均池化是对每个特征通道的所有空间位置取平均值,将三…...

UI-Grid终极样式定制指南:10个LESS变量和主题系统使用技巧
UI-Grid终极样式定制指南:10个LESS变量和主题系统使用技巧 【免费下载链接】ui-grid UI Grid: an Angular Data Grid 项目地址: https://gitcode.com/gh_mirrors/ui/ui-grid UI-Grid作为Angular数据表格的强大解决方案,提供了灵活的样式定制系统。…...

DeepSeek-Coder-V2-Lite-Instruct社区案例集:开发者如何用AI改变编程方式
DeepSeek-Coder-V2-Lite-Instruct社区案例集:开发者如何用AI改变编程方式 【免费下载链接】DeepSeek-Coder-V2-Lite-Instruct 开源代码智能利器——DeepSeek-Coder-V2,性能比肩GPT4-Turbo,全面支持338种编程语言,128K超长上下文&a…...

OpenClaw小龙虾初体验【安装学习】
文章目录一、前言二、安装三、360安全龙虾四、腾讯龙虾4.1 文件移动4.2 应用分析4.3 Docker失败原因一、前言 最近小龙虾很火,不禁能说还能做,本质就类似木马,获取电脑权限,不禁能操作各应用还能联动外接设备。 那肯定要学习一下…...