PyTorch识别验证码
## 一、生成测试集数据
pip install captcha
common.py
import random
import time
captcha_array = list("0123456789abcdefghijklmnopqrstuvwxyz")
captcha_size = 4from captcha.image import ImageCaptchaif __name__ == '__main__':for i in range(10):image = ImageCaptcha()image_text = "".join(random.sample(captcha_array, captcha_size))image_path = "./datasets/train/{}_{}.png".format(image_text, int(time.time()))image.write(image_text, image_path)生成验证码
二、one-hot编码将类别变量转换为机器学习算法易于利用的一种形式的过程。
one_hot.py
import common
import torch
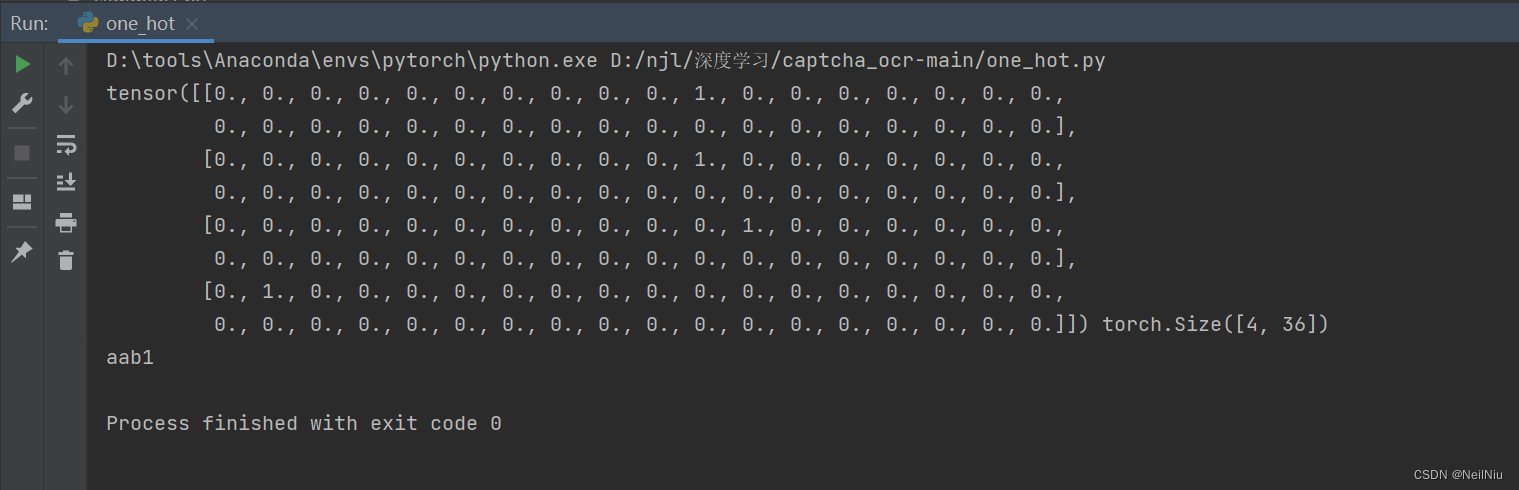
import torch.nn.functional as Fdef text2vec(text):# 将文本转换为变量vectors = torch.zeros((common.captcha_size, common.captcha_array.__len__()))# vectors[0,0] = 1# vectors[1,3] = 1# vectors[2,4] = 1# vectors[3, 1] = 1for i in range(len(text)):vectors[i, common.captcha_array.index(text[i])] = 1return vectorsdef vectotext(vec):vec=torch.argmax(vec, dim=1)text_label=""for v in vec:text_label+=common.captcha_array[v]return text_labelif __name__ == '__main__':vec=text2vec("aab1")print(vec, vec.shape)print(vectotext(vec))
三、 然后继续添加
my_datasets.py
import osfrom PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import one_hotclass mydatasets(Dataset):def __init__(self,root_dir):super(mydatasets, self).__init__()self.list_image_path=[ os.path.join(root_dir,image_name) for image_name in os.listdir(root_dir)]self.transforms=transforms.Compose([transforms.Resize((60,160)),transforms.ToTensor(),transforms.Grayscale()])def __getitem__(self, index):image_path = self.list_image_path[index]img_ = Image.open(image_path)image_name=image_path.split("\\")[-1]img_tesor=self.transforms(img_)img_lable=image_name.split("_")[0]img_lable=one_hot.text2vec(img_lable)img_lable=img_lable.view(1,-1)[0]return img_tesor,img_labledef __len__(self):return self.list_image_path.__len__()if __name__ == '__main__':d=mydatasets("datasets/train")img,label=d[0]writer=SummaryWriter("logs")writer.add_image("img",img,1)print(img.shape)writer.close()dataLoader 加载dataset
就是数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出,就是做一个数据的初始化。
四、训练
五、CNN卷积神经网络
model.py
import torch
from torch import nn
import common
class mymodel(nn.Module):def __init__(self):super(mymodel, self).__init__()self.layer1 = nn.Sequential(# 卷积层nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, padding=1),# 激活层nn.ReLU(),# 池化层nn.MaxPool2d(kernel_size=2) #[6, 64, 30, 80])self.layer2 = nn.Sequential(# 卷积层nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),# 激活层nn.ReLU(),# 池化层nn.MaxPool2d(2) #[6, 128, 15, 40])self.layer3 = nn.Sequential(# 卷积层nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),# 激活层nn.ReLU(),# 池化层nn.MaxPool2d(2) # [6, 256, 7, 20])self.layer4 = nn.Sequential(# 卷积层nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1),# 激活层nn.ReLU(),# 池化层nn.MaxPool2d(2) # [6, 512, 3, 10])# self.layer5 = nn.Sequential(# nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),# nn.ReLU(),# nn.MaxPool2d(2) # [6, 512, 1, 5]# )self.layer6 = nn.Sequential(# 展平nn.Flatten(), #[6, 2560] [64, 15360]# 线性层nn.Linear(in_features=15360, out_features=4096),# 防止过拟合nn.Dropout(0.2), # drop 20% of the neuron# 激活曾nn.ReLU(),# 线性层nn.Linear(in_features=4096, out_features=common.captcha_size*common.captcha_array.__len__()))def forward(self,x):x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)#x = x.view(1,-1)[0]#[983040]x = self.layer6(x)# x = x.view(x.size(0), -1)return x;if __name__ == '__main__':data = torch.ones(64, 1, 60, 160)model = mymodel()x = model(data)print(x.shape)

六、训练
train.py
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from my_datasets import mydatasets
from model import mymodelif __name__ == '__main__':train_datas = mydatasets("datasets/train")test_data = mydatasets("datasets/test")train_dataloader = DataLoader(train_datas, batch_size=64, shuffle=True)test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)# m = mymodel().cuda() 没有GPUm = mymodel()# MultiLabelSoftMarginLoss 多标签交叉熵损失函数# 优化器 Adam 一般要求学习率比较小# 先将梯度归零 zero_grad# 反向传播计算 backward# loss_fn = nn.MultiLabelSoftMarginLoss().cuda() 没有GPUloss_fn = nn.MultiLabelSoftMarginLoss()optimizer = torch.optim.Adam(m.parameters(), lr=0.001)w = SummaryWriter("logs")total_step = 0for i in range(10):# print("外层训练次数{}".format(i))for i,(imgs, targets) in enumerate(train_dataloader):# imgs = imgs.cuda() 没有GPU# targets = targets.cuda() 没有GPUoutputs = m(imgs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()if i%10 == 0:total_step += 1print("训练{}次,loss:{}".format(total_step*10, loss.item()))w.add_scalar("loss", loss, total_step)w.close()torch.save(m, "model.pth")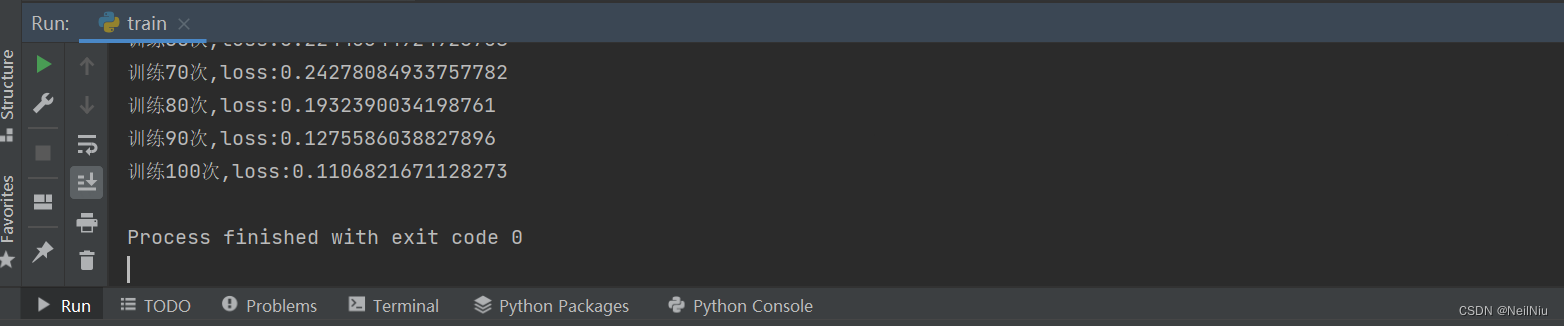
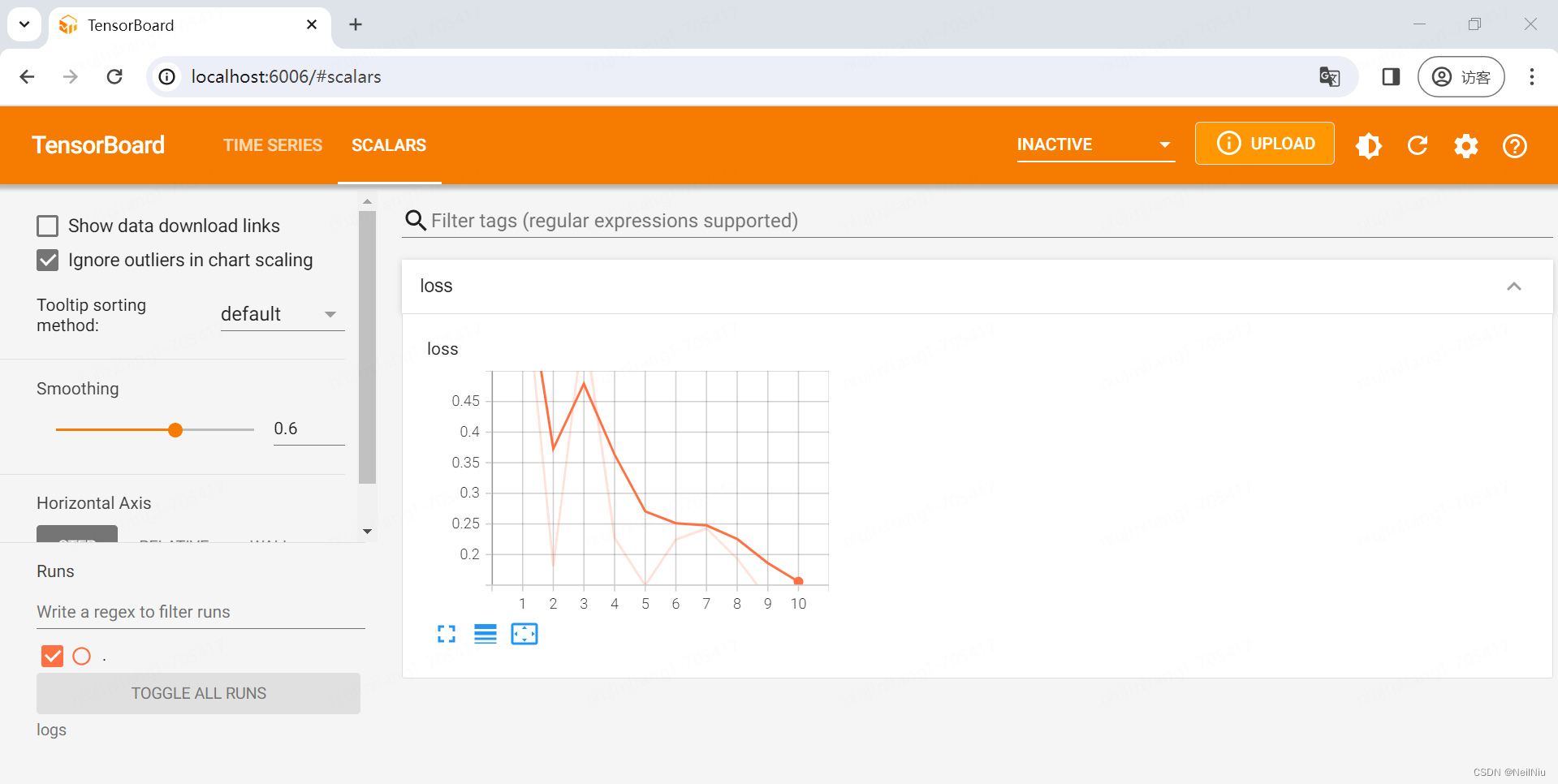
tensorboard --logdir=logs
使用tensorboard 查看损失率,接近零了。
七、图片预测
model.train() 和 model.eval()一般在模型训练和评价的时候会加上这两句,主要是针对由于model在训练时和评价时Batch Normalization 和Dropout方法模式不同,例如model指定t因此,在使用PyTorch进行训练和测试时一定注意要把rain/eval
predict.py
from PIL import Image
from torch.utils.data import DataLoader
import one_hot
import model
import torch
import common
import my_datasets
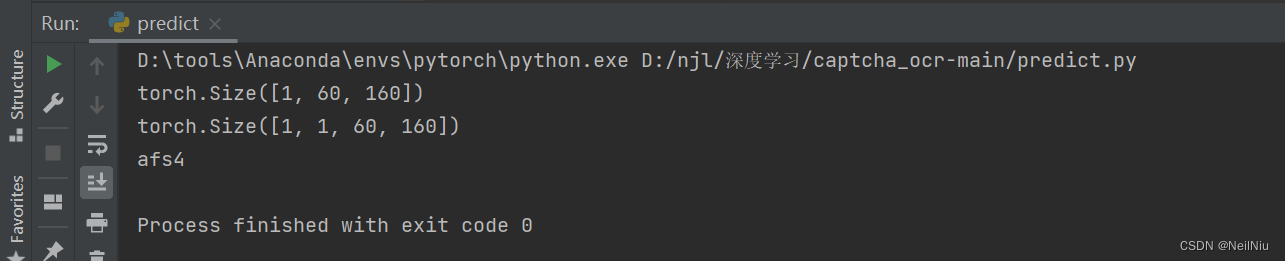
from torchvision import transformsdef test_pred():# m = torch.load("model.pth").cuda() 没有GPUm = torch.load("model.pth")m.eval()test_data = my_datasets.mydatasets("datasets/test")test_dataloader = DataLoader(test_data, batch_size=1, shuffle=False)test_length = test_data.__len__()correct = 0for i, (imgs, lables) in enumerate(test_dataloader):# imgs = imgs.cuda() 没有GPU# lables = lables.cuda() 没有GPUlables = lables.view(-1, common.captcha_array.__len__())lables_text = one_hot.vectotext(lables)predict_outputs = m(imgs)predict_outputs = predict_outputs.view(-1, common.captcha_array.__len__())predict_labels = one_hot.vectotext(predict_outputs)if predict_labels == lables_text:correct += 1print("预测正确:正确值:{},预测值:{}".format(lables_text, predict_labels))else:print("预测失败:正确值:{},预测值:{}".format(lables_text, predict_labels))# m(imgs)print("正确率{}".format(correct / test_length * 100))def pred_pic(pic_path):img = Image.open(pic_path)tersor_img = transforms.Compose([transforms.Grayscale(),transforms.Resize((60, 160)),transforms.ToTensor()])# img = tersor_img(img).cuda() 没有GPUimg = tersor_img(img)print(img.shape)img = torch.reshape(img, (-1, 1, 60, 160))print(img.shape)# m = torch.load("model.pth").cuda() 没有GPUm = torch.load("model.pth")outputs = m(img)outputs = outputs.view(-1, len(common.captcha_array))outputs_lable = one_hot.vectotext(outputs)print(outputs_lable)if __name__ == '__main__':# test_pred()pred_pic("./datasets/test/5ogl_1705418909.png")
预测值是一样的,需要找一些真实的验证码图片
相关文章:
PyTorch识别验证码
## 一、生成测试集数据pip install captcha common.py import random import time captcha_array list("0123456789abcdefghijklmnopqrstuvwxyz") captcha_size 4from captcha.image import ImageCaptchaif __name__ __main__:for i in range(10):image ImageC…...
手把手教你开发Python桌面应用-PyQt6图书管理系统-图书类别信息表格数据显示以及搜索实现
锋哥原创的PyQt6图书管理系统视频教程: PyQt6图书管理系统视频教程 Python桌面开发 Python入门级项目实战 (无废话版) 火爆连载更新中~_哔哩哔哩_bilibiliPyQt6图书管理系统视频教程 Python桌面开发 Python入门级项目实战 (无废话版) 火爆连载更新中~共计24条视频&…...

【HarmonyOS】鸿蒙开发之自定义组件——第3.7章
自定义构建函数 (适合内部页面的封装,更加合适)(构建页面) 案例: 自定义组件文件 Index.ets //全局自定义构建函数写法 Builder function item1(){Row({space:10}){Text("我是自定义构建函数")} }Component export struct Index{build(){Column(){item…...

初探unity中的ECS
ECS是一种软件架构模式,就像MVC一样。ECS最早在游戏《守望先锋》中提及到的相关链接。ECS具体是指实体(entity)、 组件(component)和系统(system): 实体:实体是一个ID&a…...

力扣:131. 分割回文串
回溯解法思路: 1.先声明一个集合来接受全部的回文子串组合,在声明一个集合来接收单个回文子串的组合。 2.写一个回溯函数,里面有终止条件和遍历全部组合的for循环来进行遍历全部的组合,终止条件为开始索引等于字符串的长度时&am…...

2024美赛数学建模B题思路源码
赛题目的 赛题目的: 问题描述: 解题的关键: 问题一. 问题分析 要开发一个模型来预测潜水器随时间的位置,我们需要考虑以下几个关键因素: 海洋环境因素:当前和预测的洋流、海水密度(可能会随…...
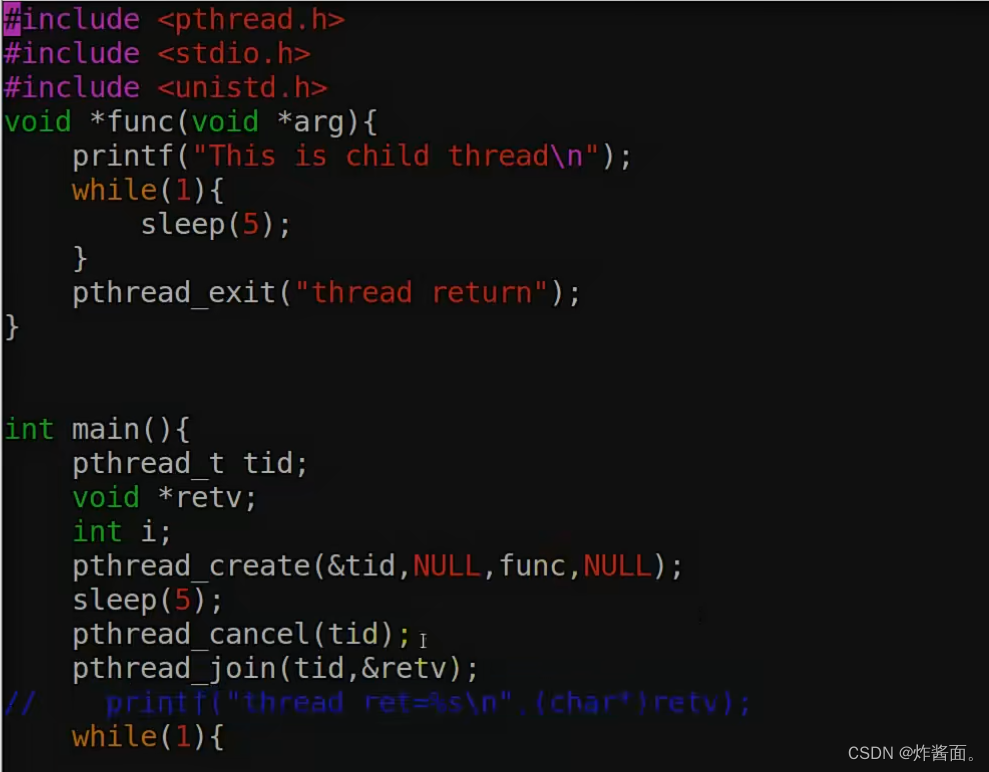
线程的取消和互斥
线程的取消 int pthread_cancel(pthread_t thread); 注意:线程的取消要有取消点才可以,不是说取消就取消,线程的取消点主要是阻塞的系统调用(前面sleep就是一个阻塞的系统调用) 如果没有取消点,手动设置一个 把上图中sleep函数替换成这个一样可以取消 void pth…...

机器学习之DeepSequence软件使用学习1
简介 DeepSequence 是一个生成性的、无监督的生物序列潜变量模型。给定一个多重序列比对作为输入,它可以用来预测可获得的突变,提取监督式学习的定量特征,并生成满足明显约束的新序列文库。它将序列中的高阶依赖性建模为残差子集之间约束的非…...
【Kotlin】Kotlin环境搭建
1 前言 Kotlin 是一种现代但已经成熟的编程语言,由 JetBrains 公司于 2011 年设计和开发,并在 2012 年开源,在 2016 年发布 v1.0 版本。在 2017 年,Google 宣布 Kotlin 正式成为 Android 开发语言,这进一步推动了 Kotl…...

langgraph学习--创建基本的agent执行器
本文介绍如何使用langgraph创建一个基本的Agent执行器,主要包括下面几个步骤: 1、定义工具 2、创建langchain Agent(由LLM、tools、prompt三部分组成) 3、定义图形状态 传统的LangChain代理的状态有几个属性: (1&#…...
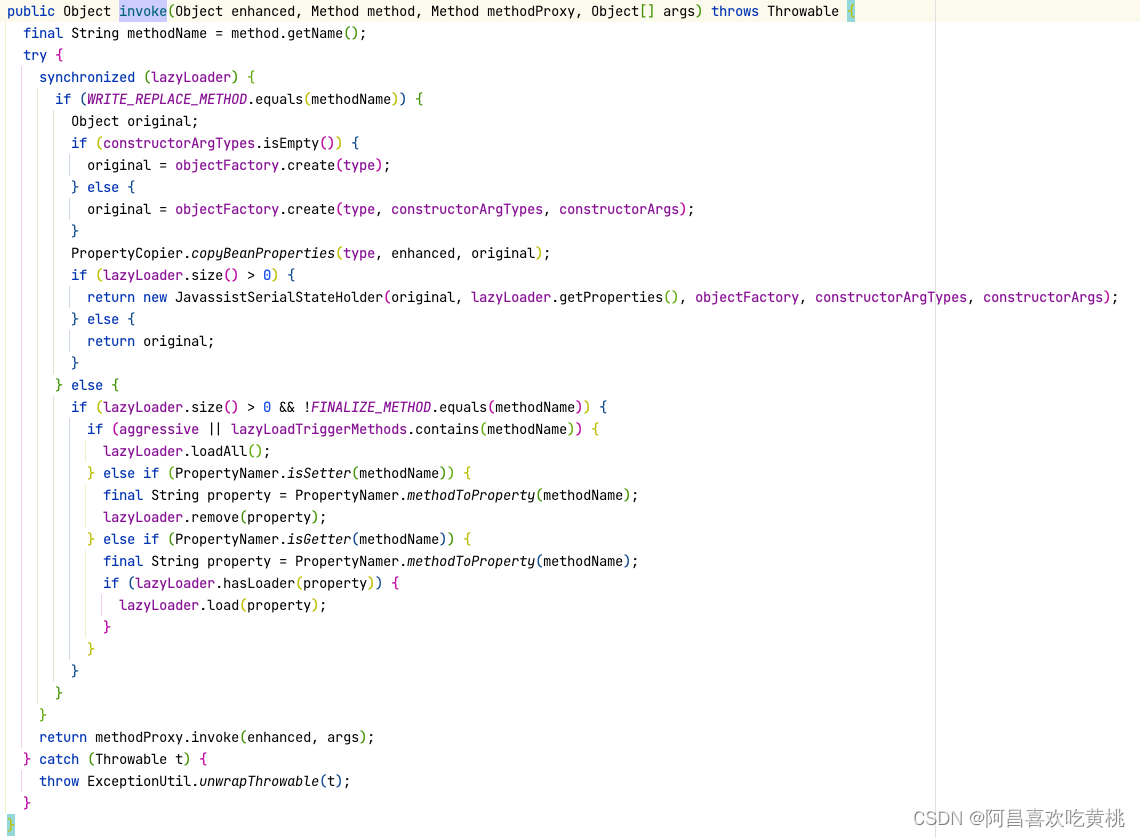
Mybatis中的sql-xml延迟加载机制
Mybatis中的sql-xml延迟加载机制 hi,我是阿昌,今天记录一下关于Mybatis中的sql-xml延迟加载机制 一、前言 首先mybatis技术本身就不多介绍,说延迟加载机制之前,那要先知道2个概念: 主查询对象关联对象 假设咱们现…...

【Linux系统学习】1.初识Linux
初识Linux 操作系统概述 初识Linux 虚拟机介绍 VMware WorkStation安装 1.操作系统概述 了解操作系统的作用 了解常见的操作系统 1.1 硬件和软件 计算机由哪两个主要部分组成? 硬件:计算机系统中由电子,机械和光电元件等组成的各种物理装置的…...

政安晨:政安晨:机器学习快速入门(三){pandas与scikit-learn} {模型验证及欠拟合与过拟合}
这一篇中,咱们使用Pandas与Scikit-liarn工具进行一下模型验证,之后再顺势了解一些过拟合与欠拟合,这是您逐渐深入机器学习的开始! 模型验证 评估您的模型性能,以便测试和比较其他选择。 在上一篇中,您已经…...

分享65个节日PPT,总有一款适合您
分享65个节日PPT,总有一款适合您 65个节日PPT下载链接:https://pan.baidu.com/s/1hc1M5gfYK8eDxQVsK8O9xQ?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集整理更不易。知…...
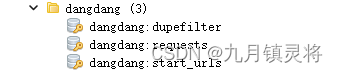
架构学习(二):原生scrapy如何接入scrapy-redis,初步入局分布式
原生scrapy如何接入scrapy-redis,实现初步入局分布式 前言scrpy-redis分布式碎语 实现流程扩展结束 前言 scrpy-redis分布式 下图是scrpy-redis官方提供的架构图,按我理解,与原生scrapy的差异主要是把名单队列服务器化,也是存储…...
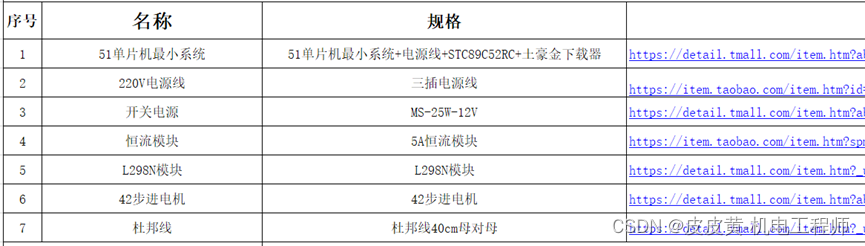
第1节、电路连接【51单片机+L298N步进电机系列】
↑↑↑点击上方【目录】,查看本系列全部文章 摘要:本节介绍如何搭建一个51单片机L298N步进电机控制电路,所用材料均为常见的模块,简单高效的方式搭建起硬件环境。 一、硬件清单 ①51单片机模块 ②恒流模块 ③开关电源 ④L298N模…...

API接口文档怎么写?
API接口文档模板 本文档更新时间:2022-12-07 本文档更新说明:提供了接口文档模板,后续如果有接口文档编写相关工作,可以参考该模板。 接口名称: XX帐号基础信息批量获取接口 【接口名称,见名知意】 接口…...
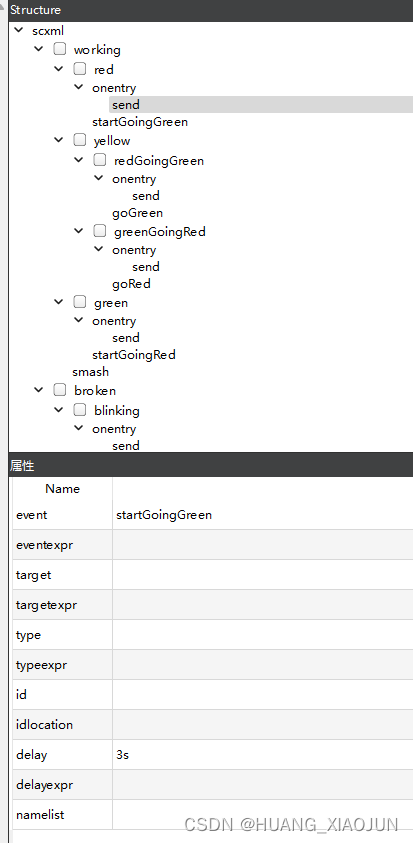
Qt 范例阅读: QStateMachine状态机框架 和 SCXML 引擎简单记录(方便后续有需求能想到这两个东西)
一、QStateMachine 简单应用: 实现按钮的文本切换 QStateMachine machine; //定义状态机(头文件定义)QState *off new QState(); //添加off 状态off->assignProperty(ui->pushButton_2, "text", "Off"); //绑定该…...
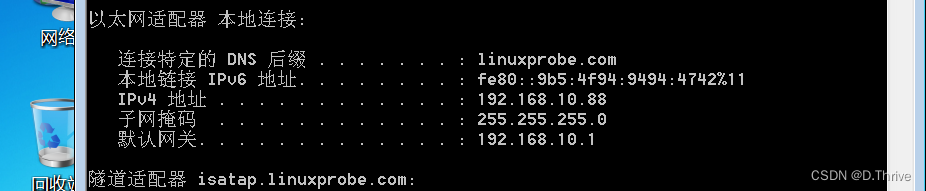
Linux实验记录:使用DHCP动态管理主机地址
前言: 本文是一篇关于Linux系统初学者的实验记录。 参考书籍:《Linux就该这么学》 实验环境: VmwareWorkStation 17——虚拟机软件 RedHatEnterpriseLinux[RHEL]8——红帽操作系统 备注: 动态主机配置协议(DHCP&…...

Qt应用软件【协议篇】MQTT协议介绍
文章目录 MQTT简介QT中MQTT的源码什么是 MQTT?MQTT 的工作原理MQTT 的工作流程MQTT 的应用场景智能家居工业物联网(IIoT)车联网环境监测医疗健康物流与供应链智能能源公共安全基于传输层TCP协议上的MQTT应用层协议...

企业微信考勤自动化解决方案:基于EasyWeChat的实战指南
企业微信考勤自动化解决方案:基于EasyWeChat的实战指南 【免费下载链接】easywechat 📦 一个 PHP 微信 SDK 项目地址: https://gitcode.com/gh_mirrors/ea/easywechat 在数字化办公普及的今天,企业考勤管理面临着数据采集繁琐、统计分…...
Pixel Dream Workshop 快速上手:Python 零基础入门到生成第一幅AI画作
Pixel Dream Workshop 快速上手:Python 零基础入门到生成第一幅AI画作 1. 前言:为什么选择Pixel Dream Workshop 如果你对AI绘画感兴趣但苦于没有编程基础,这篇教程就是为你量身定制的。Pixel Dream Workshop是一个对新手极其友好的AI绘画工…...

如何永久保存微信聊天记录?WeChatMsg终极指南让你重获数据掌控权
如何永久保存微信聊天记录?WeChatMsg终极指南让你重获数据掌控权 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendin…...

从零构建uWSGI-Nginx-Flask-Docker镜像的5个核心步骤
从零构建uWSGI-Nginx-Flask-Docker镜像的5个核心步骤 【免费下载链接】uwsgi-nginx-flask-docker Docker image with uWSGI and Nginx for Flask applications in Python running in a single container. Optionally with Alpine Linux. 项目地址: https://gitcode.com/gh_mi…...

Llama-3.2V-11B-cot快速部署:Docker镜像开箱即用,5分钟启动视觉CoT服务
Llama-3.2V-11B-cot快速部署:Docker镜像开箱即用,5分钟启动视觉CoT服务 1. 项目概述 Llama-3.2V-11B-cot是一个支持系统性推理的视觉语言模型,基于LLaVA-CoT论文实现。这个模型能够理解图像内容并进行逐步推理,最终给出合理的结…...

告别低效:用快马ai一键生成can总线数据分析与统计脚本
在汽车电子和嵌入式系统开发中,CAN总线数据的分析是个高频需求。无论是调试车载网络问题,还是优化通信性能,都离不开对海量CAN帧数据的处理。但手动写解析脚本不仅耗时,还容易遗漏关键细节。最近我发现用InsCode(快马)平台的AI辅助…...
保姆级教程)
告别龟速下载!Win10/Win11下为CDO配置国内镜像源(Ubuntu 18.04 LTS)保姆级教程
告别龟速下载!Win10/Win11下为CDO配置国内镜像源(Ubuntu 18.04 LTS)保姆级教程 如果你曾在Windows系统下通过WSL安装Ubuntu并尝试下载CDO,大概率经历过每秒几KB的绝望下载速度。这不是你的网络问题——默认的国外软件源对国内用户…...

Stable-Diffusion-v1-5-archive多风格生成效果:复古海报/科技感UI/手绘插画实拍
Stable Diffusion v1.5 Archive多风格生成效果:复古海报/科技感UI/手绘插画实拍 1. 模型介绍与核心能力 Stable Diffusion v1.5 Archive是经典SD1.5文生图模型的归档版本,作为AI图像生成领域的"常青树",它依然保持着强大的通用图…...

基于python宠物医院药品管理系统的设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商功能模块设计技术实现要点扩展功能建议项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块设计 药品信息管理模块 实现药品基础信息的…...

3步搭建JNPF工作流:新手也能玩转全流程类型
接触过不少刚入门低代码的开发和企业数字化人员,一提搭建工作流就犯怵:分不清流程类型适配场景,摸不透决策流的规则配置,搞不定自由流的灵活流转,最后要么搭出的流程适配性差,要么冗余臃肿跑不通。 其实基于…...