kafka-splunk数据通路实践
目的: 鉴于目前网络上没有完整的kafka数据投递至splunk教程,通过本文操作步骤,您将实现kafka数据投递至splunk日志系统
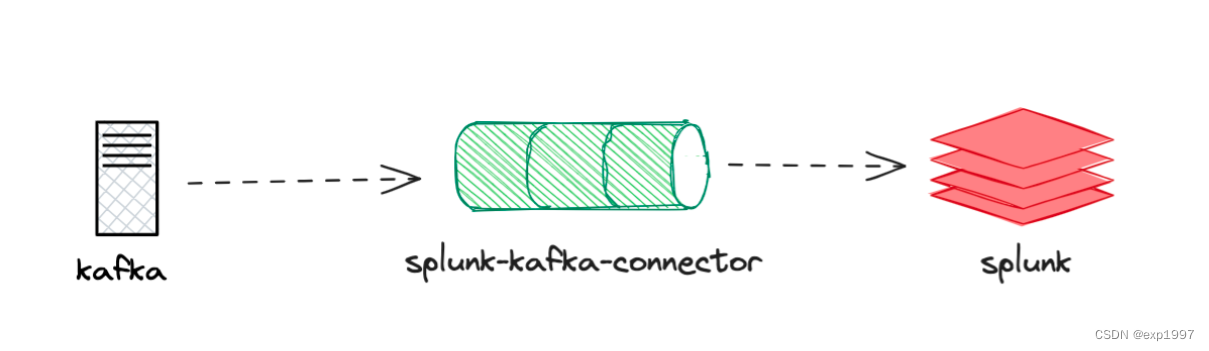
实现思路:
- 创建kafka集群
- 部署splunk,设置HTTP事件收集器
- 部署connector服务
- 创建connector任务,将kafka主题消息通过connector投递到splunk
测试环境:
- 测试使用的操作系统为centos7.5_x86_64
- 文章提供了两种部署方式,分别是单机部署和容器化部署
- 单机部署使用的主机来自腾讯云-cvm产品(腾讯云CVM),1台4c8g(如果条件允许,建议使用3台2c4g主机,分别部署kafka、connector、splunk,钱包有限,这里只是教程,不讲究这些)
- 上述云主机,已安装JDK8及以上版本
- 容器化部署使用的k8s集群来自腾讯云TKE,可以一键部署k8s集群,欢迎体验~
一、部署splunk
●splunk是一款收费软件,如果每天的数据量少于500M,可以使用Splunk提供的免费License,但不能用安全,分布式等高级功能。
部署步骤如下:
部署方式1:容器部署:
- 安装并启动docker(k8s集群节点可免除此步骤):
yum install docker -y
systemctl start docker
- 获取splunk镜像:
# https://hub.docker.com/r/splunk/splunk/tags
docker pull splunk/splunk
- 【非必须,3和4选一个】启动splunk容器,设置为自动接受lic,设置密码:
docker run -d -p 8000:8000 -e "SPLUNK_START_ARGS=--accept-license" -e "SPLUNK_PASSWORD=你的密码" -p 8088:8088 --name splunk splunk/splunk:latest
- 【非必须,3和4选一个】在k8s中以工作负载方式部署splunk,这将为你创建一个splunk-ns命名空间,并创建deployment类型的工作负载部署splunk,以及一个LB类型的service,请根据你的需要修改命名空间、镜像、密码、端口:
vi splunk-deployment.yaml
apiVersion: v1
kind: Namespace
metadata:name: splunk-ns---apiVersion: apps/v1
kind: Deployment
metadata:name: splunknamespace: splunk-ns
spec:replicas: 1selector:matchLabels:app: splunktemplate:metadata:labels:app: splunkspec:containers:- name: splunkimage: splunk/splunk:latestports:- containerPort: 8000- containerPort: 8088env:- name: SPLUNK_START_ARGSvalue: "--accept-license"- name: SPLUNK_PASSWORDvalue: "你的密码"volumeMounts:- name: splunk-datamountPath: /opt/splunk/varvolumes:- name: splunk-dataemptyDir: {}---apiVersion: v1
kind: Service
metadata:name: splunknamespace: splunk-ns
spec:selector:app: splunkports:- name: httpport: 8000targetPort: 8000- name: mgmtport: 8088targetPort: 8088type: LoadBalancer
- 打开浏览器,访问splunk的地址:8000,预期可以看到splunk的页面。用户名/密码:admin/你的密码

部署方式2:单机部署:
- 注册账号并获取splunk下载链接:https://www.splunk.com/en_us/download/splunk-enterprise.html ⚠️
- 解压缩
# 解压到/opt
tar -zxvf splunk-8.0.8-xxzx-Linux-x86_64.tgz -C /opt
- 启动splunk,接受许可
cd /opt/splunk/bin/
./splunk start --accept-license //启动,并自动接收许可
- 输入自定义用户名、密码
其他命令参考:
./splunk start //启动splunk
./splunk restart //重启splunk
./splunk status //查看splunk状态
./splunk version //查看splunk版
#卸载
./splunk disable boot-start //关闭自启动
./splunk stop //停止splunk
/opt/splunk/bin/rm–rf/opt/splunk //移除splunk安装目录
- splunk安装之后,默认开启Splunk Web端口8000。我们访问8000端口
●ps:Splunkd端口8089为管理端口
至此,splunk部署成功
二、配置Splunk HTTP 事件收集器
-
在splunk中配置HTTP 事件收集器:
a. 进入splunk web页面,点击右上角【设置】-【数据输入】
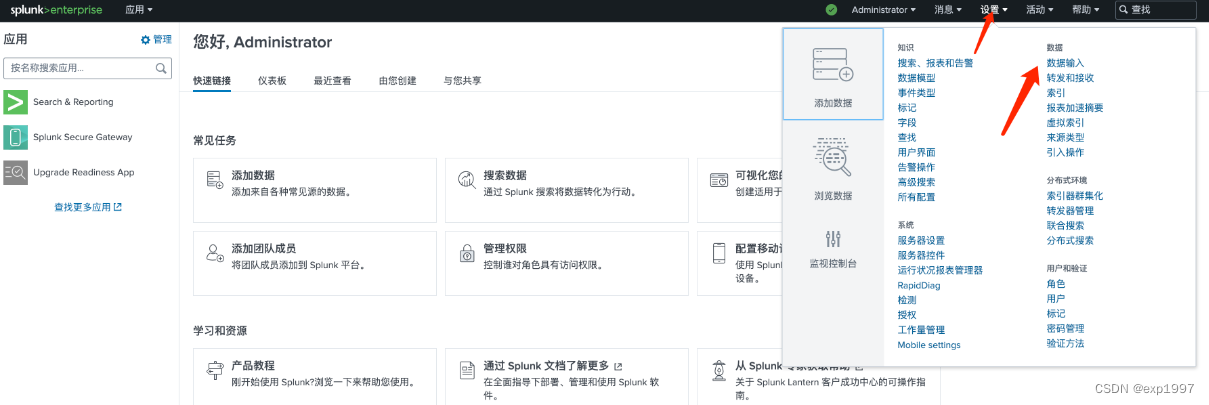
b. 选择HTTP事件收集器,点击【全局设置】,启用标记,HTTP端口为8088,点击【保存】
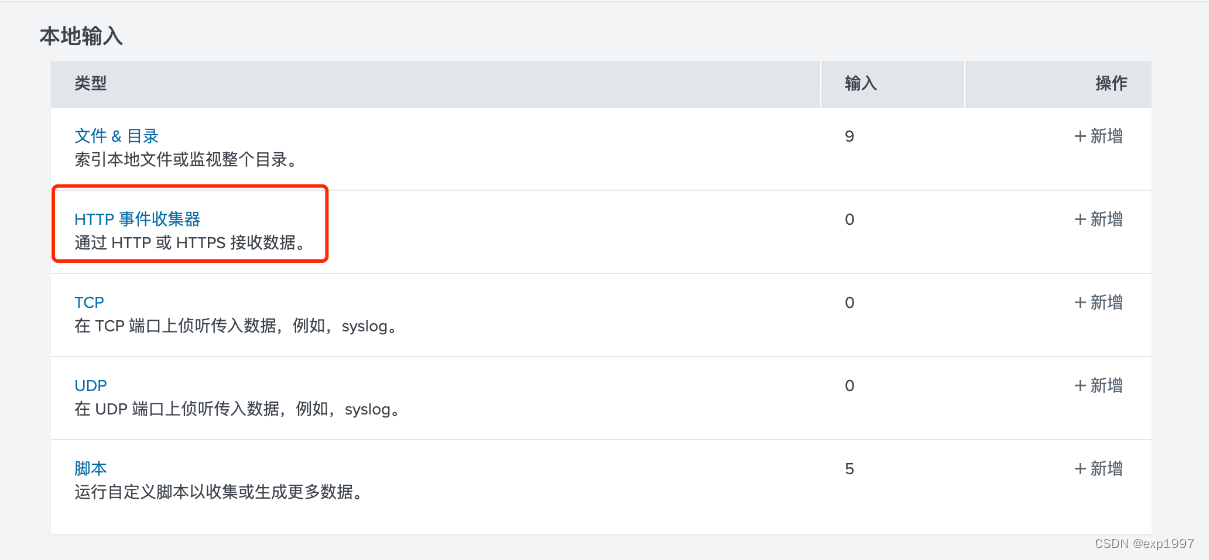
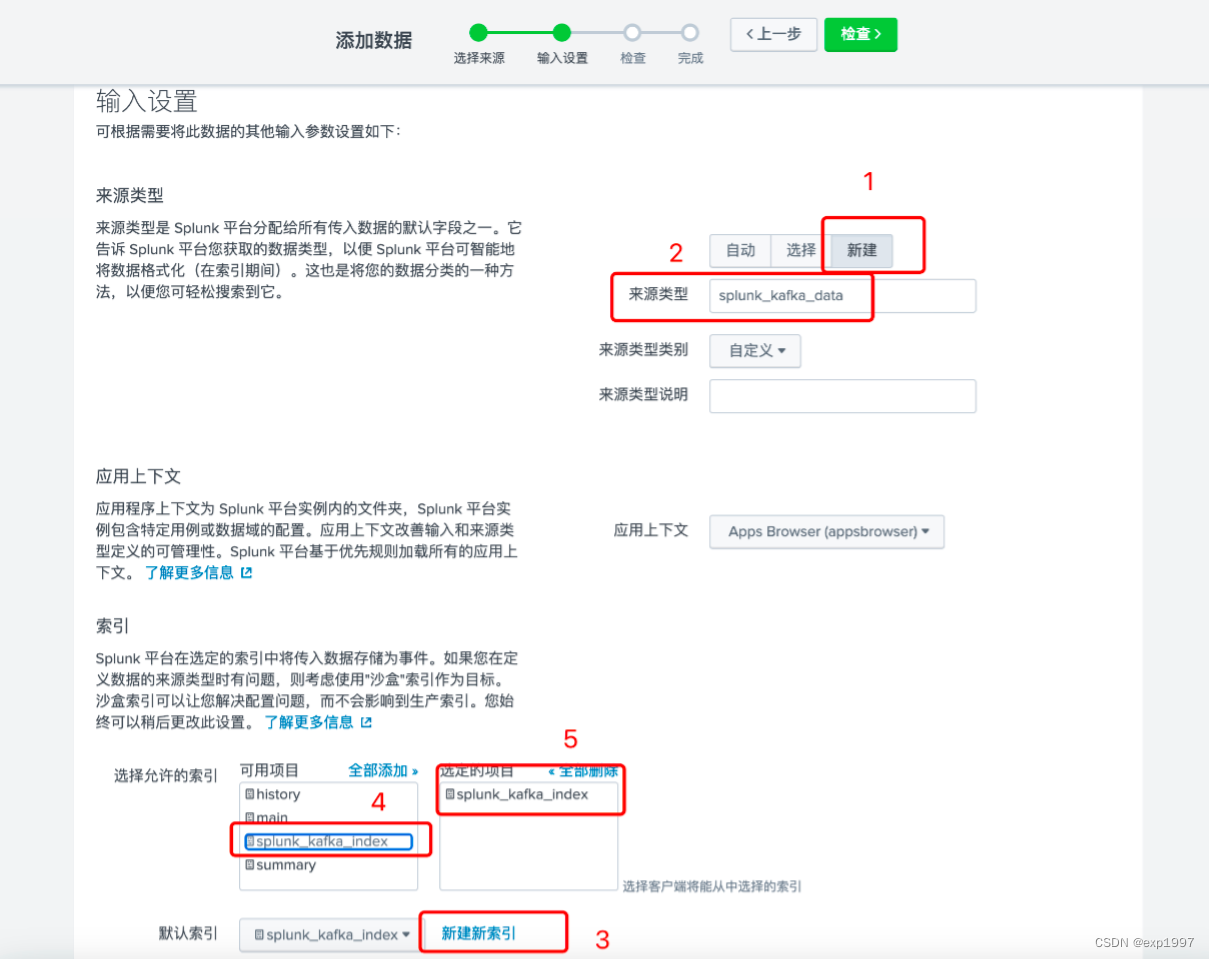
c. 点击右上角【新建标记】,新建HTTP事件收集器,填写:填写名称:splunk_kafka_connect_token,点击【下一步】;
新建来源类型“splunk_kafka_data”,新建索引“splunk_kafka_index”,点击【检查】;
提交;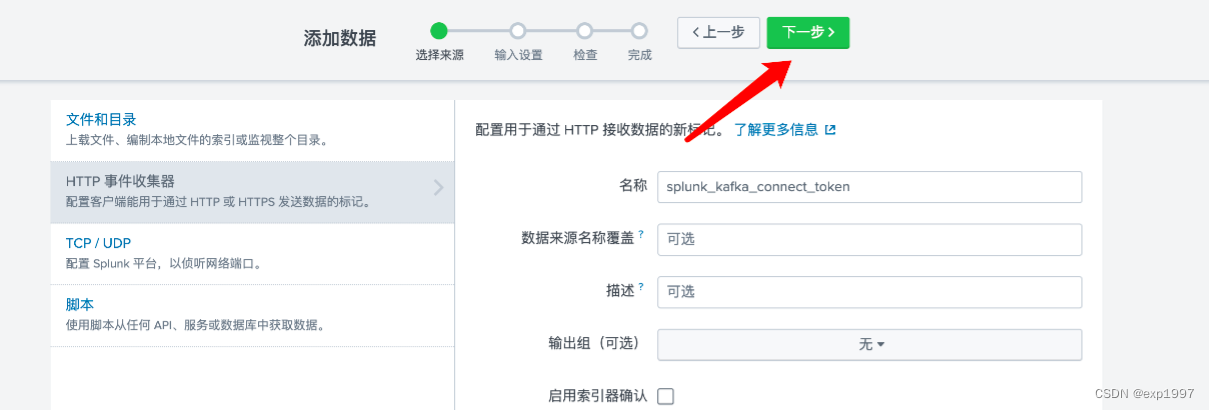
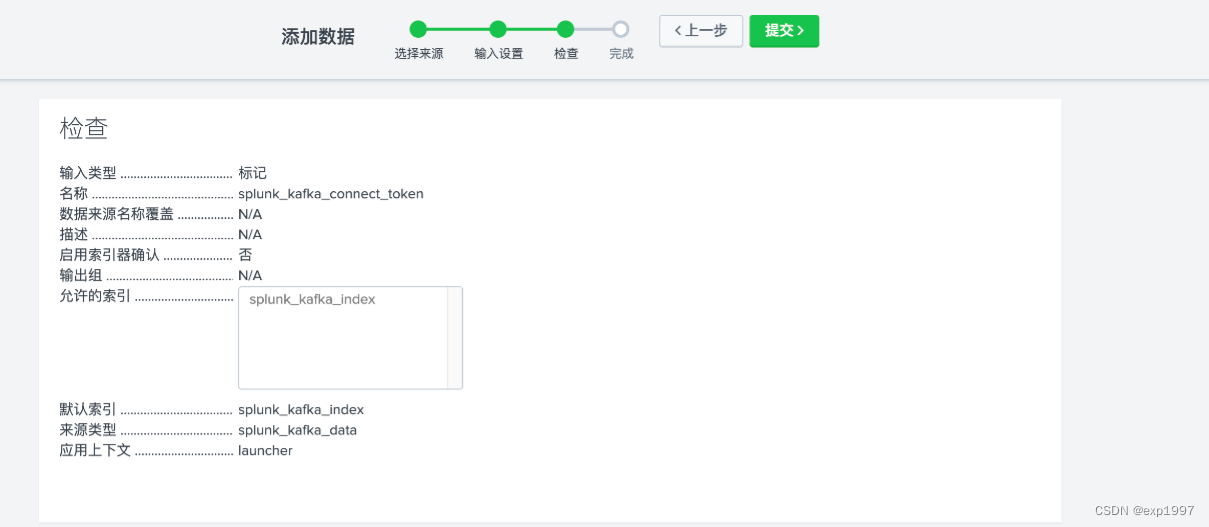
-
随后,在设置-数据输入-HTTP事件收集器页面,将得到一个token,记录此token

三、启动kafka并生产消息
- 启动kafka实例
a. 安装jdk
yum install java -y
b. 下载kafka:https://kafka.apache.org/downloads,以2.12版本为例
c.解压
tar -zxvf kafka_2.12-3.6.1.tgz
d.启动zookeeper
cd kafka_2.12-3.6.1/
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
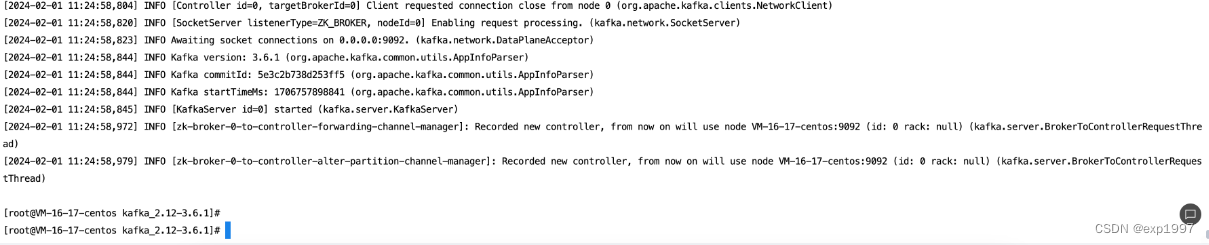
e.启动kafka
./bin/kafka-server-start.sh config/server.properties &
f.创建topic,假设叫topic0
./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic0

g.使用生产者发送若干条消息
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic0

h.消费
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic topic0
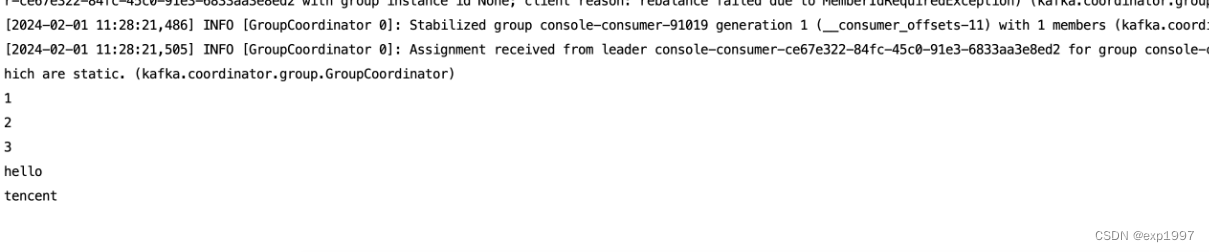
至此,kafka启动成功
三、使用splunk for kafka connector实现splunk与kafka数据通路
- github上下载splunk for kafka connector的latest jar,下载地址:https://github.com/splunk/kafka-connect-splunk,在执行以下操作前请仔细阅读github上的redame,因为随着版本更新,配置或许会改变
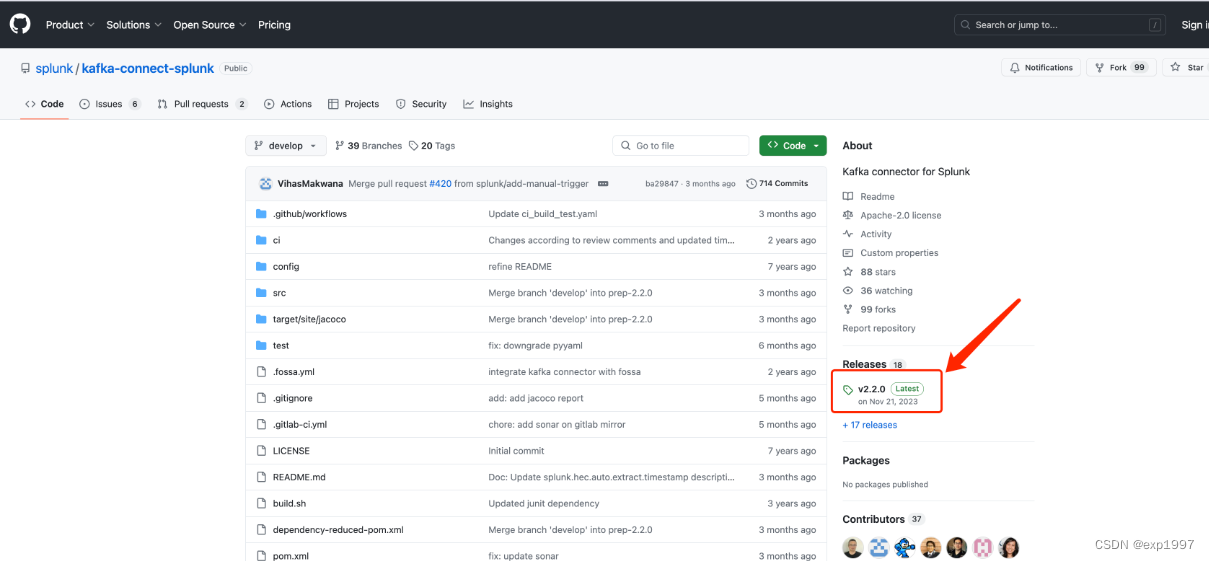
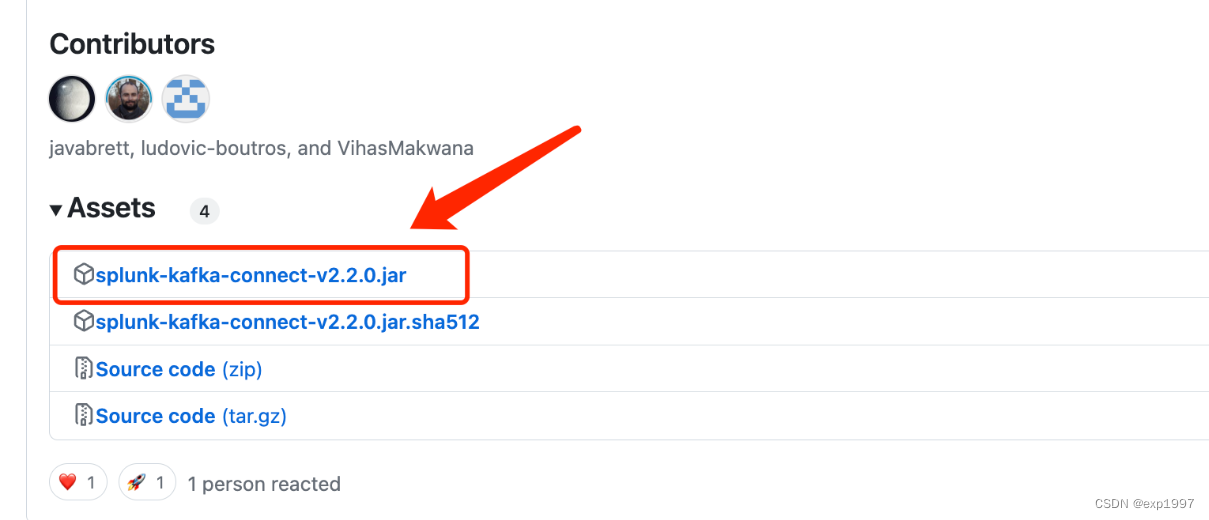
- 配置splunk for kafka connector
a.此步骤将完成kafka connector服务。返回带有kafka sdk的主机(注意,这里我只有一台测试机,但是如果你是多台主机分别部署kafka、connector的背景下,这里返回的不是kafka集群主机,我们要创建connector服务,kafka sdk是带有connector的配置的),编辑kafka_2.12-3.6.1/config/connect-distributed.properties
参数说明:
注意:rest.advertised.host.name和rest.advertised.port在不同的kafka版本中参数名不同,以connect-distributed.properties原文档参数为准;StringConverter表示日志格式为string,若日志为其他格式,请参考官方文档
# 将10.0.0.0:19000替换为你的kafka地址
bootstrap.servers=10.0.0.0:19000
group.id=test-splunk-kafka-connector
# 假设消息是string类型,格式不对splunk就不能解析日志
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
# 换为connector的地址
rest.advertised.host.name=10.1.1.1
rest.advertised.port=8083
#指定splunk-kafka-connector.jar所在目录
plugin.path=/usr/local/bin/
- 启动conncetor:
cd kafka_2.12-3.6.1/
./bin/connect-distributed.sh config/connect-distributed.properties
- 验证splunk connector:
# curl http://「connector ip」:8083/connector-plugins
curl http://10.1.1.1:8083/connector-plugins
预期出现这个字段,表示splunk connector已经启动了:{“class”:“com.splunk.kafka.connect.SplunkSinkConnector”,“type”:“sink”,“version”:“v2.2.0”}

- 创建connector任务,替换10.1.1.1为您的kafka connector地址10.0.0.0为您的splunk地址,token为splunk事件收集器的token,topics替换为您的kafka topic
curl 10.1.1.1:8083/connectors -X POST -H "Content-Type: application/json" -d'{"name": "splunk-kafka-connect-task","config": {"connector.class": "com.splunk.kafka.connect.SplunkSinkConnector","tasks.max": "3","topics": "topic0","splunk.indexes": "splunk_kafka_index","splunk.hec.uri":"https://10.0.0.0:8088","splunk.hec.token": "b4594xxxxxx","splunk.hec.ack.enabled" : "false","splunk.hec.raw" : "false","splunk.hec.json.event.enrichment" : "org=fin,bu=south-east-us","splunk.hec.ssl.validate.certs": "false","splunk.hec.track.data" : "true"}
}'预期返回:

- 进入splunk 主页-search&reporting
在搜索栏填写:index="splunk_kafka_index"验证index中的数据,预期能查看到我们生产的消息
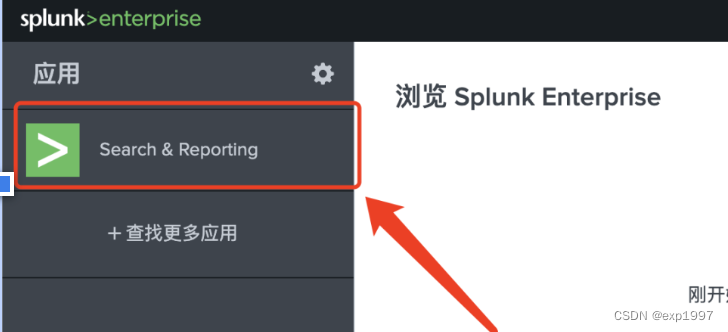

至此,kafka-splunk已打通
相关文章:
kafka-splunk数据通路实践
目的: 鉴于目前网络上没有完整的kafka数据投递至splunk教程,通过本文操作步骤,您将实现kafka数据投递至splunk日志系统 实现思路: 创建kafka集群部署splunk,设置HTTP事件收集器部署connector服务创建connector任务&a…...
C语言第十九弹---指针(三)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 指针 1、数组名的理解 2、使用指针访问数组 3、⼀维数组传参的本质 4、冒泡排序 5、二级指针 6、指针数组 7、指针数组模拟二维数组 总结 1、数组名的理解…...

TCP/IP LWIP FPGA 笔记
参考资料: 正点原子 LwIP 之 网络接口 netif(ethernetif.c、netif.c)-CSDN博客 IPv4/IPv6、DHCP、网关、路由_ipv6有网关的概念吗-CSDN博客 TCP/IP TCP/IP 协议中文名为传输控制协议/因特网互联协议,又名网络通讯协议…...

2024年海外优青项目申报指南
国家自然科学基金优秀青年科学基金(海外)项目(简称“海外优青项目”),一直备受海外优秀青年学者(包括博士后研究人员)关注,被看作是回国发展最为重要的资助项目之一。知识人网小编现…...

threejs之常用贴图
在三维图形和游戏开发中,高光贴图、凹凸贴图、法线贴图和环境光遮蔽贴图是常用的技术,用于增加虚拟物体表面的细节和真实感,而无需增加更多的几何体。这些技术可以帮助开发者和艺术家创造出既详细又性能高效的场景。 高光贴图(Sp…...

Unity类银河恶魔城学习记录3-1 EnemyStateMachine源代码 P47
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili Enemy.cs using System.Collections; using System.Collections.Generic;…...

使用webstorm调试vue 2 项目
学习目标: 使用webstorm调试vue 2 项目 笔者环境: npm 6.14.12 webstorm 2023.1 vue 2 学习内容: 例如: 正常启动npm 项目 配置javaScruot dubug 配置你的项目地址就好 使用dubug运行你配置的调式页 问题 如果进入了js页无…...
深度学习缝模块怎么描述创新点?(附写作模板+涨点论文)
深度学习缝了别的模块怎么描述创新点、怎么讲故事写成一篇优质论文? 简单框架:描述自己这个领域,该领域出现了什么问题,你用了什么方法解决,你的方法有了多大的性能提升。 其中,重点讲清楚这两点…...

html,css,js速成
准备:vscode配好c,python,vue环境,并下载live server插件。 1. html hypertext markup language(超文本标记语言) 1. 基础语法 一个html元素由开始标签,填充文本,结束标签构成。 常见标签说明<b>…...
)
《Docker极简教程》--Docker基础--基础知识(一)
在这篇文章中我们先大致的了解以下Docker的基本概念,在后续的文章中我们会详细的讲解这些概念以及使用。 一、容器(Container) 1.1 容器的定义和特点 容器的定义 容器是一种轻量级、可移植的软件打包技术,用于打包应用及其依赖项和运行环境,…...
Web html和css
目录 1 前言2 HTML2.1 元素(Element)2.1.1 块级元素和内联(行级)元素2.1.2 空元素 2.2 html页面的文档结构2.3 常见标签使用2.3.1 注释2.3.2 标题2.3.3 段落2.3.4 列表2.3.5 超链接2.3.6 图片2.3.7 内联(行级)标签2.3.8 换行 2.4 属性2.4.1 布尔属性 2.5 实体引用2.6 空格2.7 D…...

Three.js学习6:透视相机和正交相机
一、相机 相机 camera,可以理解为摄像机。在拍影视剧的时候,最终用户看到的画面都是相机拍出来的内容。 Three.js 里,相机 camera 里的内容就是用户能看到的内容。从这个角度来看,相机其实就是用户的视野,就像用户的眼…...
❤ React18 环境搭建项目与运行(地址已经放Gitee开源)
❤ React项目搭建与运行 环境介绍 node v20.11.0 react 18.2 react-dom 18.2.0一、React环境搭建 第一种普通cra搭建 1、检查本地环境 node版本 18.17.0 检查node和npm环境 node -v npm -v 2、安装yarn npm install -g yarn yarn --version 3、创建一个新的React项目…...
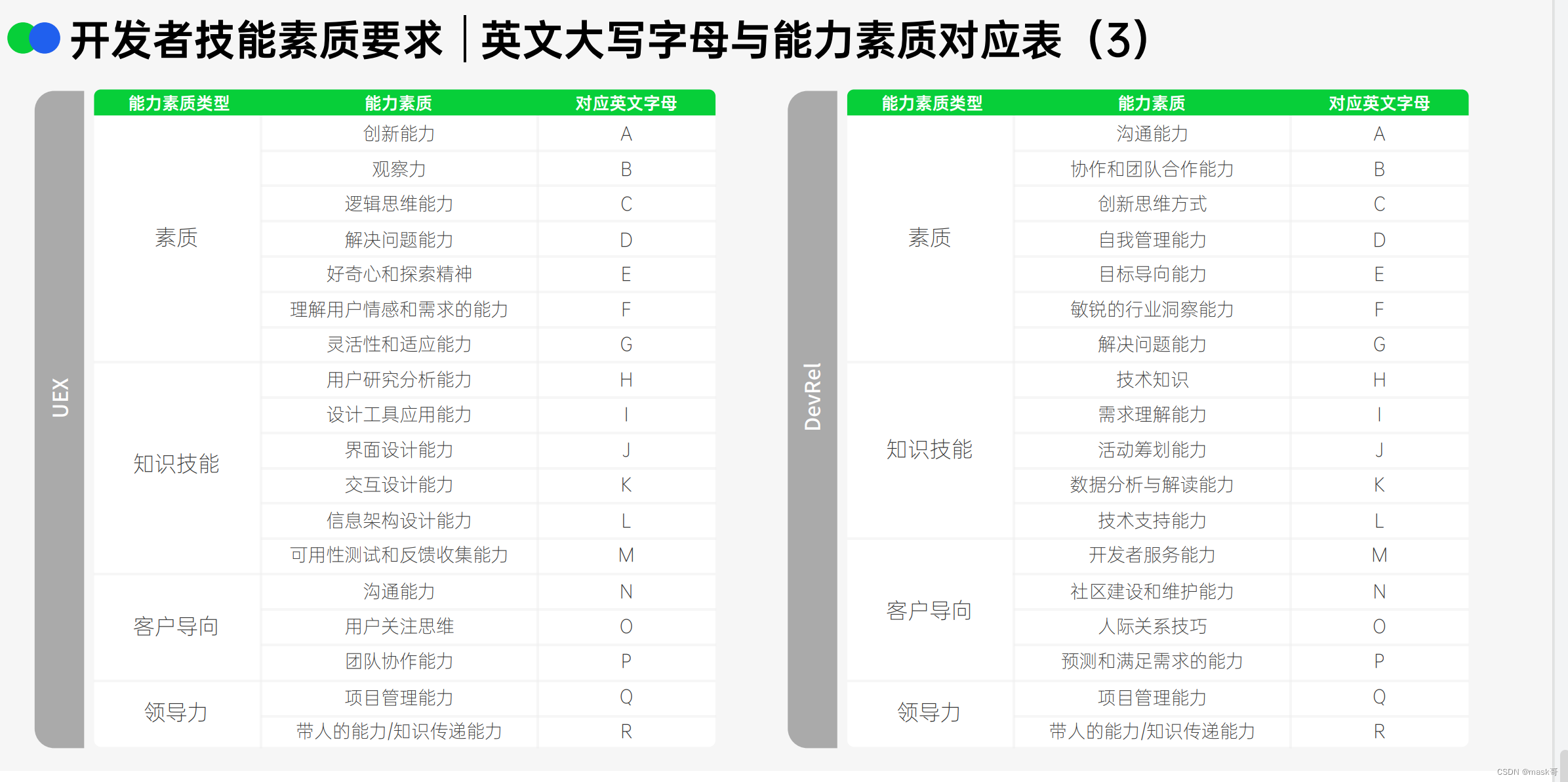
2024 RTE行业(实时互动行业)人才发展学习总结
解决方案 人才画像 开发者人才素质要求: 具备多个领域的技术知识注重团队合作,具备协作能力以用户为导向的用户体验意识具备创新思维和解决问题的能力需快速响应行业变化和持续的学习能力具备项目管理能力 学习和吸收新知识的渠道 RTE人才分类...

92.网游逆向分析与插件开发-游戏窗口化助手-显示游戏数据到小助手UI
内容参考于:易道云信息技术研究院VIP课 上一个内容:游戏窗口化助手的UI设计-CSDN博客 码云地址(游戏窗口化助手 分支):https://gitee.com/dye_your_fingers/sro_-ex.git 码云版本号:e8116af3a7b0186adba…...

Stable Diffusion 模型下载:majicMIX fantasy 麦橘幻想
文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十 下载地址 模型介绍 非常推荐的一个非常绚丽、充满幻想的大模型,由国人“Merjic”发布,下载量颇高。这个模型风格炸裂,远距离脸部需要inpaint以达成…...

docker compose安装minio
要使docker-compose管理的容器(如MinIO)在系统启动时自动启动,你需要使用Docker的重启策略。在你的docker-compose.yml文件中为MinIO服务添加restart策略即可实现这一目标。restart: always指令确保了在容器退出时总是重新启动容器࿰…...
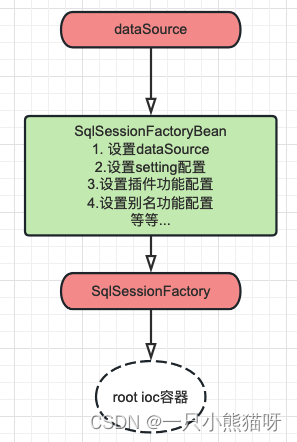
二、SSM 整合配置实战
本章概要 依赖整合和添加控制层配置编写(SpringMVC 整合)业务配置编写(AOP/TX 整合)持久层配置编写(MyBatis 整合)容器初始化配置类整合测试 2.1 依赖整合和添加 数据库准备 数据库脚本 CREATE DATABASE mybatis-example;USE mybatis-example;CREATE TABLE t_emp(emp_id INT…...

『运维备忘录』之 Yum 命令详解
运维人员不仅要熟悉操作系统、服务器、网络等只是,甚至对于开发相关的也要有所了解。很多运维工作者可能一时半会记不住那么多命令、代码、方法、原理或者用法等等。这里我将结合自身工作,持续给大家更新运维工作所需要接触到的知识点,希望大…...

CSS中可继承与不可继承属性有哪些
一、无继承性的属性 1.display:规定元素应该生成的框的类型 属性值作用none元素不显示,并且会从文档流中移除。block块类型。默认宽度为父元素宽度,可设置宽高,换行显示。inline行内元素类型。默认宽度为内容宽度,不…...

ImageSearch:5分钟掌握本地千万级图片搜索的终极指南
ImageSearch:5分钟掌握本地千万级图片搜索的终极指南 【免费下载链接】ImageSearch 基于.NET8的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 你是否曾在电脑里堆积如山的照片…...

别怕C++!手把手拆解TinyML测试框架:用micro_test.h给你的嵌入式AI代码加个‘保险丝’
嵌入式AI开发者的测试实战指南:用micro_test.h构建TinyML质量防线 在资源受限的微控制器上开发AI应用时,一个被反复验证的真理是:没有自动化测试的代码就像没有安全网的走钢丝。当你的神经网络模型需要在仅有几KB内存的设备上运行时ÿ…...

如何使用usearch构建精准视频内容推荐系统:基于观看历史的向量匹配方案
如何使用usearch构建精准视频内容推荐系统:基于观看历史的向量匹配方案 【免费下载链接】usearch Fast Open-Source Search & Clustering engine for Vectors & Arbitrary Objects in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoL…...
)
图解Linux内核DRM框架:从用户态ioctl到plane更新的完整数据流(以4.14版本为例)
图解Linux内核DRM框架:从用户态ioctl到plane更新的完整数据流(以4.14版本为例) 在图形显示技术领域,Linux内核的DRM(Direct Rendering Manager)框架扮演着核心角色。本文将聚焦于DRM_IOCTL_MODE_SETPLANE这…...

vue基于springboot的目的地旅游预订网站
目录同行可拿货,招校园代理 ,本人源头供货商功能模块划分技术实现要点扩展功能建议性能优化方向项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块划分 用户模块 用户注册与登录…...

Qwen3-VL-8B系统资源管理:监控与清理GPU显存和C盘空间
Qwen3-VL-8B系统资源管理:监控与清理GPU显存和C盘空间 长期运行像Qwen3-VL-8B这样的大模型服务,就像养了一头“数字大象”——它能力强大,但胃口也不小,尤其能吃GPU显存和硬盘空间。很多朋友刚开始部署时一切顺利,但跑…...

Android Studio中文插件:3分钟极速汉化,告别英文开发障碍
Android Studio中文插件:3分钟极速汉化,告别英文开发障碍 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack …...

ssm+java2026年毕设体育赛事管理系统App【源码+论文】
本系统(程序源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。系统程序文件列表开题报告内容一、选题背景关于赛事管理问题的研究,现有研究主要以大型综合性体育赛事(如奥运会、亚运会)的信息化管理…...

Element UI表格样式改造避坑指南:透明化后文字看不清、边框错位怎么办?
Element UI表格透明化实战:解决文字模糊与样式错位的专业方案 当我们在Vue项目中采用Element UI的el-table组件实现透明化效果时,经常会遇到一些棘手的样式问题。本文将深入分析四个典型场景的成因,并提供经过实战检验的解决方案。 1. 透明背…...

终极音乐解锁方案:在浏览器中实现加密音乐文件高效转换完整指南
终极音乐解锁方案:在浏览器中实现加密音乐文件高效转换完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...