时间序列(Time-Series)MultiWaveletCorrelation.py代码解析
#这两行导入了PyTorch和NumPy库,分别用于深度学习和数值计算
import torch
import numpy as np
#这两行导入了PyTorch的神经网络模块和函数模块。
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from typing import List, Tuple
import math
from functools import partial
from torch import nn, einsum, diagonal
from math import log2, ceil
import pdb
from sympy import Poly, legendre, Symbol, chebyshevt
from scipy.special import eval_legendre
#这个函数计算Legendre多项式的导数。
def legendreDer(k, x):
def _legendre(k, x):
return (2 * k + 1) * eval_legendre(k, x)
#初始化输出值为0。
out = 0
#开启循环,以步长为-2遍历奇数或偶数Legendre级数。
for i in np.arange(k - 1, -1, -2):
#将Legendre多项式的结果累加到输出中。
out += _legendre(i, x)
return out
#这个函数定义了多项式基函数,并应用上下限进行裁剪
def phi_(phi_c, x, lb=0, ub=1):
#创建一个掩码,用于指示x值是否在定义的区间外。
mask = np.logical_or(x < lb, x > ub) * 1.0
#如果x在定义的区间内,则返回多项式的值;如果在区间外,则返回0
return np.polynomial.polynomial.Polynomial(phi_c)(x) * (1 - mask)
#这个函数计算多项式基函数和关于基base的检验函数。
def get_phi_psi(k, base):
x = Symbol('x')
phi_coeff = np.zeros((k, k))
phi_2x_coeff = np.zeros((k, k))
#以下代码计算Legendre和切比雪夫(Chebyshev)多项式,并且它们的系数。这些多项式用于构建多小波基。
if base == 'legendre':
for ki in range(k):
coeff_ = Poly(legendre(ki, 2 * x - 1), x).all_coeffs()
phi_coeff[ki, :ki + 1] = np.flip(np.sqrt(2 * ki + 1) * np.array(coeff_).astype(np.float64))
coeff_ = Poly(legendre(ki, 4 * x - 1), x).all_coeffs()
phi_2x_coeff[ki, :ki + 1] = np.flip(np.sqrt(2) * np.sqrt(2 * ki + 1) * np.array(coeff_).astype(np.float64))
psi1_coeff = np.zeros((k, k))
psi2_coeff = np.zeros((k, k))
for ki in range(k):
psi1_coeff[ki, :] = phi_2x_coeff[ki, :]
for i in range(k):
a = phi_2x_coeff[ki, :ki + 1]
b = phi_coeff[i, :i + 1]
prod_ = np.convolve(a, b)
prod_[np.abs(prod_) < 1e-8] = 0
proj_ = (prod_ * 1 / (np.arange(len(prod_)) + 1) * np.power(0.5, 1 + np.arange(len(prod_)))).sum()
psi1_coeff[ki, :] -= proj_ * phi_coeff[i, :]
psi2_coeff[ki, :] -= proj_ * phi_coeff[i, :]
for j in range(ki):
a = phi_2x_coeff[ki, :ki + 1]
b = psi1_coeff[j, :]
prod_ = np.convolve(a, b)
prod_[np.abs(prod_) < 1e-8] = 0
proj_ = (prod_ * 1 / (np.arange(len(prod_)) + 1) * np.power(0.5, 1 + np.arange(len(prod_)))).sum()
psi1_coeff[ki, :] -= proj_ * psi1_coeff[j, :]
psi2_coeff[ki, :] -= proj_ * psi2_coeff[j, :]
a = psi1_coeff[ki, :]
prod_ = np.convolve(a, a)
prod_[np.abs(prod_) < 1e-8] = 0
norm1 = (prod_ * 1 / (np.arange(len(prod_)) + 1) * np.power(0.5, 1 + np.arange(len(prod_)))).sum()
a = psi2_coeff[ki, :]
prod_ = np.convolve(a, a)
prod_[np.abs(prod_) < 1e-8] = 0
norm2 = (prod_ * 1 / (np.arange(len(prod_)) + 1) * (1 - np.power(0.5, 1 + np.arange(len(prod_))))).sum()
norm_ = np.sqrt(norm1 + norm2)
psi1_coeff[ki, :] /= norm_
psi2_coeff[ki, :] /= norm_
psi1_coeff[np.abs(psi1_coeff) < 1e-8] = 0
psi2_coeff[np.abs(psi2_coeff) < 1e-8] = 0
phi = [np.poly1d(np.flip(phi_coeff[i, :])) for i in range(k)]
psi1 = [np.poly1d(np.flip(psi1_coeff[i, :])) for i in range(k)]
psi2 = [np.poly1d(np.flip(psi2_coeff[i, :])) for i in range(k)]
elif base == 'chebyshev':
for ki in range(k):
if ki == 0:
phi_coeff[ki, :ki + 1] = np.sqrt(2 / np.pi)
phi_2x_coeff[ki, :ki + 1] = np.sqrt(2 / np.pi) * np.sqrt(2)
else:
coeff_ = Poly(chebyshevt(ki, 2 * x - 1), x).all_coeffs()
phi_coeff[ki, :ki + 1] = np.flip(2 / np.sqrt(np.pi) * np.array(coeff_).astype(np.float64))
coeff_ = Poly(chebyshevt(ki, 4 * x - 1), x).all_coeffs()
phi_2x_coeff[ki, :ki + 1] = np.flip(
np.sqrt(2) * 2 / np.sqrt(np.pi) * np.array(coeff_).astype(np.float64))
phi = [partial(phi_, phi_coeff[i, :]) for i in range(k)]
x = Symbol('x')
kUse = 2 * k
roots = Poly(chebyshevt(kUse, 2 * x - 1)).all_roots()
x_m = np.array([rt.evalf(20) for rt in roots]).astype(np.float64)
# x_m[x_m==0.5] = 0.5 + 1e-8 # add small noise to avoid the case of 0.5 belonging to both phi(2x) and phi(2x-1)
# not needed for our purpose here, we use even k always to avoid
wm = np.pi / kUse / 2
psi1_coeff = np.zeros((k, k))
psi2_coeff = np.zeros((k, k))
psi1 = [[] for _ in range(k)]
psi2 = [[] for _ in range(k)]
for ki in range(k):
psi1_coeff[ki, :] = phi_2x_coeff[ki, :]
for i in range(k):
proj_ = (wm * phi[i](x_m) * np.sqrt(2) * phi[ki](2 * x_m)).sum()
psi1_coeff[ki, :] -= proj_ * phi_coeff[i, :]
psi2_coeff[ki, :] -= proj_ * phi_coeff[i, :]
for j in range(ki):
proj_ = (wm * psi1[j](x_m) * np.sqrt(2) * phi[ki](2 * x_m)).sum()
psi1_coeff[ki, :] -= proj_ * psi1_coeff[j, :]
psi2_coeff[ki, :] -= proj_ * psi2_coeff[j, :]
psi1[ki] = partial(phi_, psi1_coeff[ki, :], lb=0, ub=0.5)
psi2[ki] = partial(phi_, psi2_coeff[ki, :], lb=0.5, ub=1)
norm1 = (wm * psi1[ki](x_m) * psi1[ki](x_m)).sum()
norm2 = (wm * psi2[ki](x_m) * psi2[ki](x_m)).sum()
norm_ = np.sqrt(norm1 + norm2)
psi1_coeff[ki, :] /= norm_
psi2_coeff[ki, :] /= norm_
psi1_coeff[np.abs(psi1_coeff) < 1e-8] = 0
psi2_coeff[np.abs(psi2_coeff) < 1e-8] = 0
psi1[ki] = partial(phi_, psi1_coeff[ki, :], lb=0, ub=0.5 + 1e-16)
psi2[ki] = partial(phi_, psi2_coeff[ki, :], lb=0.5 + 1e-16, ub=1)
return phi, psi1, psi2
def get_filter(base, k):
def psi(psi1, psi2, i, inp):
mask = (inp <= 0.5) * 1.0
return psi1[i](inp) * mask + psi2[i](inp) * (1 - mask)
if base not in ['legendre', 'chebyshev']:
raise Exception('Base not supported')
x = Symbol('x')
H0 = np.zeros((k, k))
H1 = np.zeros((k, k))
G0 = np.zeros((k, k))
G1 = np.zeros((k, k))
PHI0 = np.zeros((k, k))
PHI1 = np.zeros((k, k))
phi, psi1, psi2 = get_phi_psi(k, base)
if base == 'legendre':
roots = Poly(legendre(k, 2 * x - 1)).all_roots()
x_m = np.array([rt.evalf(20) for rt in roots]).astype(np.float64)
wm = 1 / k / legendreDer(k, 2 * x_m - 1) / eval_legendre(k - 1, 2 * x_m - 1)
for ki in range(k):
for kpi in range(k):
H0[ki, kpi] = 1 / np.sqrt(2) * (wm * phi[ki](x_m / 2) * phi[kpi](x_m)).sum()
G0[ki, kpi] = 1 / np.sqrt(2) * (wm * psi(psi1, psi2, ki, x_m / 2) * phi[kpi](x_m)).sum()
H1[ki, kpi] = 1 / np.sqrt(2) * (wm * phi[ki]((x_m + 1) / 2) * phi[kpi](x_m)).sum()
G1[ki, kpi] = 1 / np.sqrt(2) * (wm * psi(psi1, psi2, ki, (x_m + 1) / 2) * phi[kpi](x_m)).sum()
PHI0 = np.eye(k)
PHI1 = np.eye(k)
elif base == 'chebyshev':
x = Symbol('x')
kUse = 2 * k
roots = Poly(chebyshevt(kUse, 2 * x - 1)).all_roots()
x_m = np.array([rt.evalf(20) for rt in roots]).astype(np.float64)
# x_m[x_m==0.5] = 0.5 + 1e-8 # add small noise to avoid the case of 0.5 belonging to both phi(2x) and phi(2x-1)
# not needed for our purpose here, we use even k always to avoid
wm = np.pi / kUse / 2
for ki in range(k):
for kpi in range(k):
H0[ki, kpi] = 1 / np.sqrt(2) * (wm * phi[ki](x_m / 2) * phi[kpi](x_m)).sum()
G0[ki, kpi] = 1 / np.sqrt(2) * (wm * psi(psi1, psi2, ki, x_m / 2) * phi[kpi](x_m)).sum()
H1[ki, kpi] = 1 / np.sqrt(2) * (wm * phi[ki]((x_m + 1) / 2) * phi[kpi](x_m)).sum()
G1[ki, kpi] = 1 / np.sqrt(2) * (wm * psi(psi1, psi2, ki, (x_m + 1) / 2) * phi[kpi](x_m)).sum()
PHI0[ki, kpi] = (wm * phi[ki](2 * x_m) * phi[kpi](2 * x_m)).sum() * 2
PHI1[ki, kpi] = (wm * phi[ki](2 * x_m - 1) * phi[kpi](2 * x_m - 1)).sum() * 2
PHI0[np.abs(PHI0) < 1e-8] = 0
PHI1[np.abs(PHI1) < 1e-8] = 0
H0[np.abs(H0) < 1e-8] = 0
H1[np.abs(H1) < 1e-8] = 0
G0[np.abs(G0) < 1e-8] = 0
G1[np.abs(G1) < 1e-8] = 0
return H0, H1, G0, G1, PHI0, PHI1
#定义了一个基于多小波变换的神经网络模块。这个类执行多小波变换,用于深度学习模型中的特征变换。
class MultiWaveletTransform(nn.Module):
"""
1D multiwavelet block.
"""
def __init__(self, ich=1, k=8, alpha=16, c=128,
nCZ=1, L=0, base='legendre', attention_dropout=0.1):
super(MultiWaveletTransform, self).__init__()
print('base', base)
self.k = k
self.c = c
self.L = L
self.nCZ = nCZ
self.Lk0 = nn.Linear(ich, c * k)
self.Lk1 = nn.Linear(c * k, ich)
self.ich = ich
self.MWT_CZ = nn.ModuleList(MWT_CZ1d(k, alpha, L, c, base) for i in range(nCZ))
def forward(self, queries, keys, values, attn_mask):
B, L, H, E = queries.shape
_, S, _, D = values.shape
if L > S:
zeros = torch.zeros_like(queries[:, :(L - S), :]).float()
values = torch.cat([values, zeros], dim=1)
keys = torch.cat([keys, zeros], dim=1)
else:
values = values[:, :L, :, :]
keys = keys[:, :L, :, :]
values = values.view(B, L, -1)
V = self.Lk0(values).view(B, L, self.c, -1)
for i in range(self.nCZ):
V = self.MWT_CZ[i](V)
if i < self.nCZ - 1:
V = F.relu(V)
V = self.Lk1(V.view(B, L, -1))
V = V.view(B, L, -1, D)
return (V.contiguous(), None)
#定义了一个基于多小波变换的交叉注意力模块。这个类结合了交叉注意力和多小波变换,用于捕捉序列间的关系。
class MultiWaveletCross(nn.Module):
"""
1D Multiwavelet Cross Attention layer.
"""
def __init__(self, in_channels, out_channels, seq_len_q, seq_len_kv, modes, c=64,
k=8, ich=512,
L=0,
base='legendre',
mode_select_method='random',
initializer=None, activation='tanh',
**kwargs):
super(MultiWaveletCross, self).__init__()
print('base', base)
self.c = c
self.k = k
self.L = L
H0, H1, G0, G1, PHI0, PHI1 = get_filter(base, k)
H0r = H0 @ PHI0
G0r = G0 @ PHI0
H1r = H1 @ PHI1
G1r = G1 @ PHI1
H0r[np.abs(H0r) < 1e-8] = 0
H1r[np.abs(H1r) < 1e-8] = 0
G0r[np.abs(G0r) < 1e-8] = 0
G1r[np.abs(G1r) < 1e-8] = 0
self.max_item = 3
self.attn1 = FourierCrossAttentionW(in_channels=in_channels, out_channels=out_channels, seq_len_q=seq_len_q,
seq_len_kv=seq_len_kv, modes=modes, activation=activation,
mode_select_method=mode_select_method)
self.attn2 = FourierCrossAttentionW(in_channels=in_channels, out_channels=out_channels, seq_len_q=seq_len_q,
seq_len_kv=seq_len_kv, modes=modes, activation=activation,
mode_select_method=mode_select_method)
self.attn3 = FourierCrossAttentionW(in_channels=in_channels, out_channels=out_channels, seq_len_q=seq_len_q,
seq_len_kv=seq_len_kv, modes=modes, activation=activation,
mode_select_method=mode_select_method)
self.attn4 = FourierCrossAttentionW(in_channels=in_channels, out_channels=out_channels, seq_len_q=seq_len_q,
seq_len_kv=seq_len_kv, modes=modes, activation=activation,
mode_select_method=mode_select_method)
self.T0 = nn.Linear(k, k)
self.register_buffer('ec_s', torch.Tensor(
np.concatenate((H0.T, H1.T), axis=0)))
self.register_buffer('ec_d', torch.Tensor(
np.concatenate((G0.T, G1.T), axis=0)))
self.register_buffer('rc_e', torch.Tensor(
np.concatenate((H0r, G0r), axis=0)))
self.register_buffer('rc_o', torch.Tensor(
np.concatenate((H1r, G1r), axis=0)))
self.Lk = nn.Linear(ich, c * k)
self.Lq = nn.Linear(ich, c * k)
self.Lv = nn.Linear(ich, c * k)
self.out = nn.Linear(c * k, ich)
self.modes1 = modes
def forward(self, q, k, v, mask=None):
B, N, H, E = q.shape # (B, N, H, E) torch.Size([3, 768, 8, 2])
_, S, _, _ = k.shape # (B, S, H, E) torch.Size([3, 96, 8, 2])
q = q.view(q.shape[0], q.shape[1], -1)
k = k.view(k.shape[0], k.shape[1], -1)
v = v.view(v.shape[0], v.shape[1], -1)
q = self.Lq(q)
q = q.view(q.shape[0], q.shape[1], self.c, self.k)
k = self.Lk(k)
k = k.view(k.shape[0], k.shape[1], self.c, self.k)
v = self.Lv(v)
v = v.view(v.shape[0], v.shape[1], self.c, self.k)
if N > S:
zeros = torch.zeros_like(q[:, :(N - S), :]).float()
v = torch.cat([v, zeros], dim=1)
k = torch.cat([k, zeros], dim=1)
else:
v = v[:, :N, :, :]
k = k[:, :N, :, :]
ns = math.floor(np.log2(N))
nl = pow(2, math.ceil(np.log2(N)))
extra_q = q[:, 0:nl - N, :, :]
extra_k = k[:, 0:nl - N, :, :]
extra_v = v[:, 0:nl - N, :, :]
q = torch.cat([q, extra_q], 1)
k = torch.cat([k, extra_k], 1)
v = torch.cat([v, extra_v], 1)
Ud_q = torch.jit.annotate(List[Tuple[Tensor]], [])
Ud_k = torch.jit.annotate(List[Tuple[Tensor]], [])
Ud_v = torch.jit.annotate(List[Tuple[Tensor]], [])
Us_q = torch.jit.annotate(List[Tensor], [])
Us_k = torch.jit.annotate(List[Tensor], [])
Us_v = torch.jit.annotate(List[Tensor], [])
Ud = torch.jit.annotate(List[Tensor], [])
Us = torch.jit.annotate(List[Tensor], [])
# decompose
for i in range(ns - self.L):
# print('q shape',q.shape)
d, q = self.wavelet_transform(q)
Ud_q += [tuple([d, q])]
Us_q += [d]
for i in range(ns - self.L):
d, k = self.wavelet_transform(k)
Ud_k += [tuple([d, k])]
Us_k += [d]
for i in range(ns - self.L):
d, v = self.wavelet_transform(v)
Ud_v += [tuple([d, v])]
Us_v += [d]
for i in range(ns - self.L):
dk, sk = Ud_k[i], Us_k[i]
dq, sq = Ud_q[i], Us_q[i]
dv, sv = Ud_v[i], Us_v[i]
Ud += [self.attn1(dq[0], dk[0], dv[0], mask)[0] + self.attn2(dq[1], dk[1], dv[1], mask)[0]]
Us += [self.attn3(sq, sk, sv, mask)[0]]
v = self.attn4(q, k, v, mask)[0]
# reconstruct
for i in range(ns - 1 - self.L, -1, -1):
v = v + Us[i]
v = torch.cat((v, Ud[i]), -1)
v = self.evenOdd(v)
v = self.out(v[:, :N, :, :].contiguous().view(B, N, -1))
return (v.contiguous(), None)
def wavelet_transform(self, x):
xa = torch.cat([x[:, ::2, :, :],
x[:, 1::2, :, :],
], -1)
d = torch.matmul(xa, self.ec_d)
s = torch.matmul(xa, self.ec_s)
return d, s
def evenOdd(self, x):
B, N, c, ich = x.shape # (B, N, c, k)
assert ich == 2 * self.k
x_e = torch.matmul(x, self.rc_e)
x_o = torch.matmul(x, self.rc_o)
x = torch.zeros(B, N * 2, c, self.k,
device=x.device)
x[..., ::2, :, :] = x_e
x[..., 1::2, :, :] = x_o
return x
#定义了一个基于傅里叶变换的交叉注意力模块。这个类执行交叉注意力操作,在傅里叶域内增强序列间的特征表示。
class FourierCrossAttentionW(nn.Module):
def __init__(self, in_channels, out_channels, seq_len_q, seq_len_kv, modes=16, activation='tanh',
mode_select_method='random'):
super(FourierCrossAttentionW, self).__init__()
print('corss fourier correlation used!')
self.in_channels = in_channels
self.out_channels = out_channels
self.modes1 = modes
self.activation = activation
def compl_mul1d(self, order, x, weights):
x_flag = True
w_flag = True
if not torch.is_complex(x):
x_flag = False
x = torch.complex(x, torch.zeros_like(x).to(x.device))
if not torch.is_complex(weights):
w_flag = False
weights = torch.complex(weights, torch.zeros_like(weights).to(weights.device))
if x_flag or w_flag:
return torch.complex(torch.einsum(order, x.real, weights.real) - torch.einsum(order, x.imag, weights.imag),
torch.einsum(order, x.real, weights.imag) + torch.einsum(order, x.imag, weights.real))
else:
return torch.einsum(order, x.real, weights.real)
def forward(self, q, k, v, mask):
B, L, E, H = q.shape
xq = q.permute(0, 3, 2, 1) # size = [B, H, E, L] torch.Size([3, 8, 64, 512])
xk = k.permute(0, 3, 2, 1)
xv = v.permute(0, 3, 2, 1)
self.index_q = list(range(0, min(int(L // 2), self.modes1)))
self.index_k_v = list(range(0, min(int(xv.shape[3] // 2), self.modes1)))
# Compute Fourier coefficients
xq_ft_ = torch.zeros(B, H, E, len(self.index_q), device=xq.device, dtype=torch.cfloat)
xq_ft = torch.fft.rfft(xq, dim=-1)
for i, j in enumerate(self.index_q):
xq_ft_[:, :, :, i] = xq_ft[:, :, :, j]
xk_ft_ = torch.zeros(B, H, E, len(self.index_k_v), device=xq.device, dtype=torch.cfloat)
xk_ft = torch.fft.rfft(xk, dim=-1)
for i, j in enumerate(self.index_k_v):
xk_ft_[:, :, :, i] = xk_ft[:, :, :, j]
xqk_ft = (self.compl_mul1d("bhex,bhey->bhxy", xq_ft_, xk_ft_))
if self.activation == 'tanh':
xqk_ft = torch.complex(xqk_ft.real.tanh(), xqk_ft.imag.tanh())
elif self.activation == 'softmax':
xqk_ft = torch.softmax(abs(xqk_ft), dim=-1)
xqk_ft = torch.complex(xqk_ft, torch.zeros_like(xqk_ft))
else:
raise Exception('{} actiation function is not implemented'.format(self.activation))
xqkv_ft = self.compl_mul1d("bhxy,bhey->bhex", xqk_ft, xk_ft_)
xqkvw = xqkv_ft
out_ft = torch.zeros(B, H, E, L // 2 + 1, device=xq.device, dtype=torch.cfloat)
for i, j in enumerate(self.index_q):
out_ft[:, :, :, j] = xqkvw[:, :, :, i]
out = torch.fft.irfft(out_ft / self.in_channels / self.out_channels, n=xq.size(-1)).permute(0, 3, 2, 1)
# size = [B, L, H, E]
return (out, None)
#定义了一个执行稀疏核傅里叶变换的神经网络模块。这个类使用参数化的稀疏核在傅里叶域内执行特征变换。
class sparseKernelFT1d(nn.Module):
def __init__(self,
k, alpha, c=1,
nl=1,
initializer=None,
**kwargs):
super(sparseKernelFT1d, self).__init__()
self.modes1 = alpha
self.scale = (1 / (c * k * c * k))
self.weights1 = nn.Parameter(self.scale * torch.rand(c * k, c * k, self.modes1, dtype=torch.float))
self.weights2 = nn.Parameter(self.scale * torch.rand(c * k, c * k, self.modes1, dtype=torch.float))
self.weights1.requires_grad = True
self.weights2.requires_grad = True
self.k = k
def compl_mul1d(self, order, x, weights):
x_flag = True
w_flag = True
if not torch.is_complex(x):
x_flag = False
x = torch.complex(x, torch.zeros_like(x).to(x.device))
if not torch.is_complex(weights):
w_flag = False
weights = torch.complex(weights, torch.zeros_like(weights).to(weights.device))
if x_flag or w_flag:
return torch.complex(torch.einsum(order, x.real, weights.real) - torch.einsum(order, x.imag, weights.imag),
torch.einsum(order, x.real, weights.imag) + torch.einsum(order, x.imag, weights.real))
else:
return torch.einsum(order, x.real, weights.real)
def forward(self, x):
B, N, c, k = x.shape # (B, N, c, k)
x = x.view(B, N, -1)
x = x.permute(0, 2, 1)
x_fft = torch.fft.rfft(x)
# Multiply relevant Fourier modes
l = min(self.modes1, N // 2 + 1)
out_ft = torch.zeros(B, c * k, N // 2 + 1, device=x.device, dtype=torch.cfloat)
out_ft[:, :, :l] = self.compl_mul1d("bix,iox->box", x_fft[:, :, :l],
torch.complex(self.weights1, self.weights2)[:, :, :l])
x = torch.fft.irfft(out_ft, n=N)
x = x.permute(0, 2, 1).view(B, N, c, k)
return x
# ##
#定义了一个执行多小波变换卷积操作的神经网络模块。这个类结合了多小波变换和卷积操作,用于深度学习模型中的特征提取。
class MWT_CZ1d(nn.Module):
def __init__(self,
k=3, alpha=64,
L=0, c=1,
base='legendre',
initializer=None,
**kwargs):
super(MWT_CZ1d, self).__init__()
self.k = k
self.L = L
H0, H1, G0, G1, PHI0, PHI1 = get_filter(base, k)
H0r = H0 @ PHI0
G0r = G0 @ PHI0
H1r = H1 @ PHI1
G1r = G1 @ PHI1
H0r[np.abs(H0r) < 1e-8] = 0
H1r[np.abs(H1r) < 1e-8] = 0
G0r[np.abs(G0r) < 1e-8] = 0
G1r[np.abs(G1r) < 1e-8] = 0
self.max_item = 3
self.A = sparseKernelFT1d(k, alpha, c)
self.B = sparseKernelFT1d(k, alpha, c)
self.C = sparseKernelFT1d(k, alpha, c)
self.T0 = nn.Linear(k, k)
self.register_buffer('ec_s', torch.Tensor(
np.concatenate((H0.T, H1.T), axis=0)))
self.register_buffer('ec_d', torch.Tensor(
np.concatenate((G0.T, G1.T), axis=0)))
self.register_buffer('rc_e', torch.Tensor(
np.concatenate((H0r, G0r), axis=0)))
self.register_buffer('rc_o', torch.Tensor(
np.concatenate((H1r, G1r), axis=0)))
def forward(self, x):
B, N, c, k = x.shape # (B, N, k)
ns = math.floor(np.log2(N))
nl = pow(2, math.ceil(np.log2(N)))
extra_x = x[:, 0:nl - N, :, :]
x = torch.cat([x, extra_x], 1)
Ud = torch.jit.annotate(List[Tensor], [])
Us = torch.jit.annotate(List[Tensor], [])
for i in range(ns - self.L):
d, x = self.wavelet_transform(x)
Ud += [self.A(d) + self.B(x)]
Us += [self.C(d)]
x = self.T0(x) # coarsest scale transform
# reconstruct
for i in range(ns - 1 - self.L, -1, -1):
x = x + Us[i]
x = torch.cat((x, Ud[i]), -1)
x = self.evenOdd(x)
x = x[:, :N, :, :]
return x
def wavelet_transform(self, x):
xa = torch.cat([x[:, ::2, :, :],
x[:, 1::2, :, :],
], -1)
d = torch.matmul(xa, self.ec_d)
s = torch.matmul(xa, self.ec_s)
return d, s
def evenOdd(self, x):
B, N, c, ich = x.shape # (B, N, c, k)
assert ich == 2 * self.k
x_e = torch.matmul(x, self.rc_e)
x_o = torch.matmul(x, self.rc_o)
x = torch.zeros(B, N * 2, c, self.k,
device=x.device)
x[..., ::2, :, :] = x_e
x[..., 1::2, :, :] = x_o
return x
相关文章:
MultiWaveletCorrelation.py代码解析)
时间序列(Time-Series)MultiWaveletCorrelation.py代码解析
#这两行导入了PyTorch和NumPy库,分别用于深度学习和数值计算 import torch import numpy as np #这两行导入了PyTorch的神经网络模块和函数模块。 import torch.nn as nn import torch.nn.functional as F from torch import Tensor from typing import List, Tuple…...

C++的缺省参数和函数重载
目录 1.缺省参数 1.1缺省参数的概念 1.2缺省参数的分类 1.3缺省参数使用场景 2.函数重载 2.1函数重载的概念 2.2构成函数重载 1.缺省参数 1.1缺省参数的概念 概念:缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没…...
)
nginx upstream server主动健康检测模块ngx_http_upstream_check_module 使用和源码分析(上)
目录 1. 缘起2. 配置指令2.1 check2.2 check_keepalive_requests2.3 check_http_send2.4 check_http_expect_alive2.5 check_shm_size2.6 check_status3. 加载健康检测模块3.1 模块的编译3.2 模块的配置4. 测试验证5. 思考与问题6. 源码分析1. 缘起 众所周知,nginx原生的upst…...

第01课:自动驾驶概述
文章目录 1、无人驾驶行业概述什么是无人驾驶智慧出行大趋势无人驾驶能解决什么问题行业趋势无人驾驶的发展历程探索阶段(2004年以前)发展阶段(2004年-2016年)成熟阶段(2016年以后) 2、无人驾驶技术路径无人…...
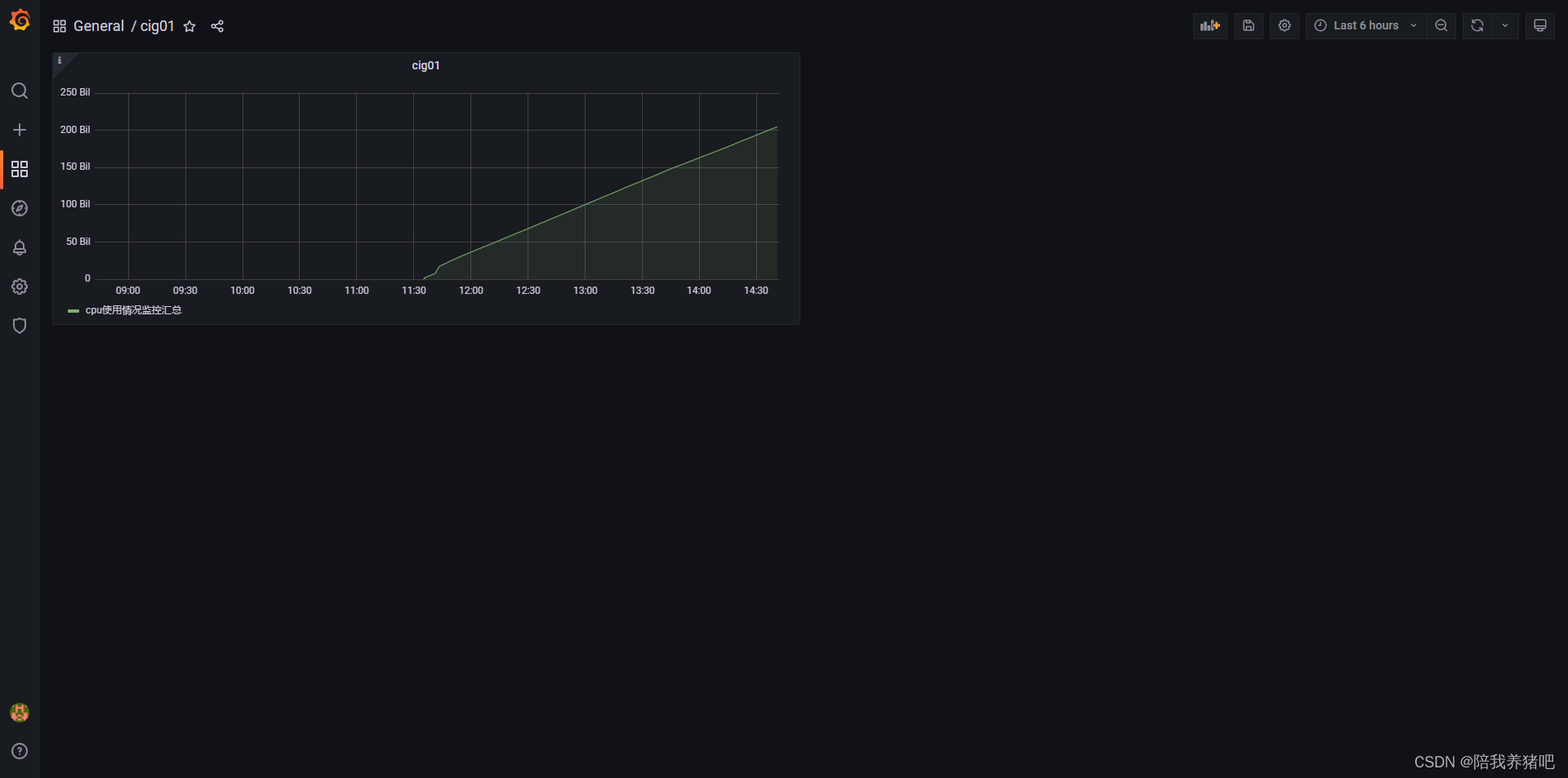
Docker进阶篇-CIG重量级监控系统
一、简介 通过docker stats命令可以很方便的查看当前宿主机上所有容器的CPU、内存、网络流量等数 据,可以满足一些小型应用。 但是docker stats统计结果只能是当前宿主机的全部容器,数据资料是实时的,没有地方存储、 没有健康指标过线预警…...
鸿蒙踩坑合集
各位网络中的小伙们,关于鸿蒙的踩坑陆陆续续收集中,本文章会持续更新,希望对您有所帮助 1、预览视图无法正常加载 重新编译项目,点击刷新按钮,控制台提示Build task failed. Open the Run window to view details. 解…...
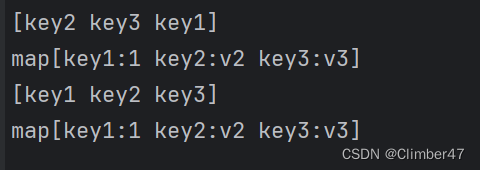
Golang-Map有序输出——使用orderedmap库实现
前言 工作中遇到一个问题:需要导出一个MySQL表格,表格内容由sql查询得来。但现在发现,所导出的表格中,各列的顺序不确定。多次导出, 每一次的序列顺序也是不定的。 因此确定是后端,Map使用相关导致的问题。…...
基础数学问题整理
最近刷了一些关于基础数学问题的题目,大致是关于组合数、分解质因数还有一些思维题,题目来自洛谷的【数学1】基础数学问题 - 题单 - 洛谷,很多思路还是之前没有见过的,都是简单到一般难度的题目(橙、题、绿题ÿ…...
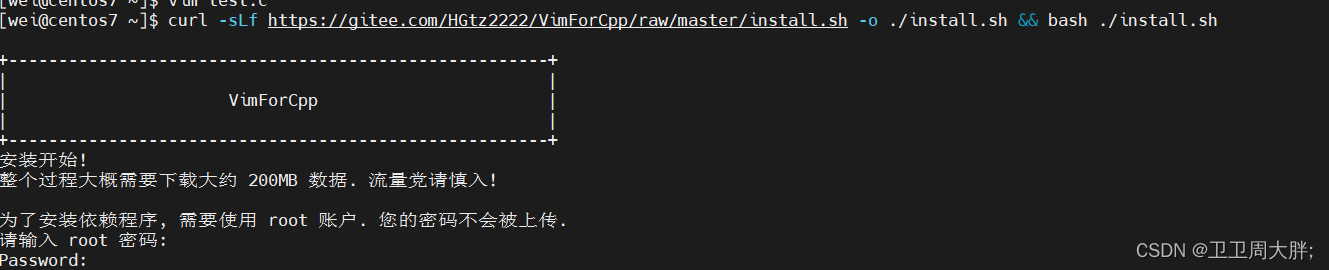
【Linux】环境基础开发工具的使用(一)
前言:在此之前我们学习了一些Linux的权限,今天我们进一步学习Linux下开发工具的使用。 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:Linux的深度刨析 👈 💯代码仓库:卫卫周大胖的学习日记…...
))
突破编程_C++_面试(基础知识(5))
面试题9:什么是内存地址 内存地址是指计算机内存中存储变量或对象的地址。内存空间大小就是寻址能力,即能访问到多少个地址,比如 32 位机器内存空间大小就是 2^32 4294967296,也就是 4 GB 。每个变量或对象在内存中都有一个唯一…...

十分钟掌握Go语言==运算符与reflect.DeepEqual函数处理interface{}值的比较规则
在 Go 语言中,interface{} 类型是一种特殊的接口类型,它表示任意类型的值。你可以使用 运算符来检测任意两个 interface{} 类型值的相等性,比较的规则和一般的接口类型一样,需要满足以下条件: 两个 interface{} 值的…...

Unity3d Shader篇(一)— 顶点漫反射着色器解析
文章目录 前言一、顶点漫反射着色器是什么?1. 顶点漫反射着色器的工作原理 二、编写顶点漫反射着色器1. 定义属性2. 创建 SubShader3. 编写着色器程序段4. 完成顶点着色器5. 完成片段着色器 三、效果四、总结 前言 在 Unity 中,Shader 可以用来实现各种…...

WordPress主题YIA的文章页评论内容为什么没有显示出来?
有些WordPress站长使用YIA主题后,在YIA主题设置的“基本”中没有开启“一键关闭评论功能”,而且文章也是允许评论的,但是评论框却不显示,最关键的是文章原本就有的评论内容也不显示,这是为什么呢? 根据YIA主…...
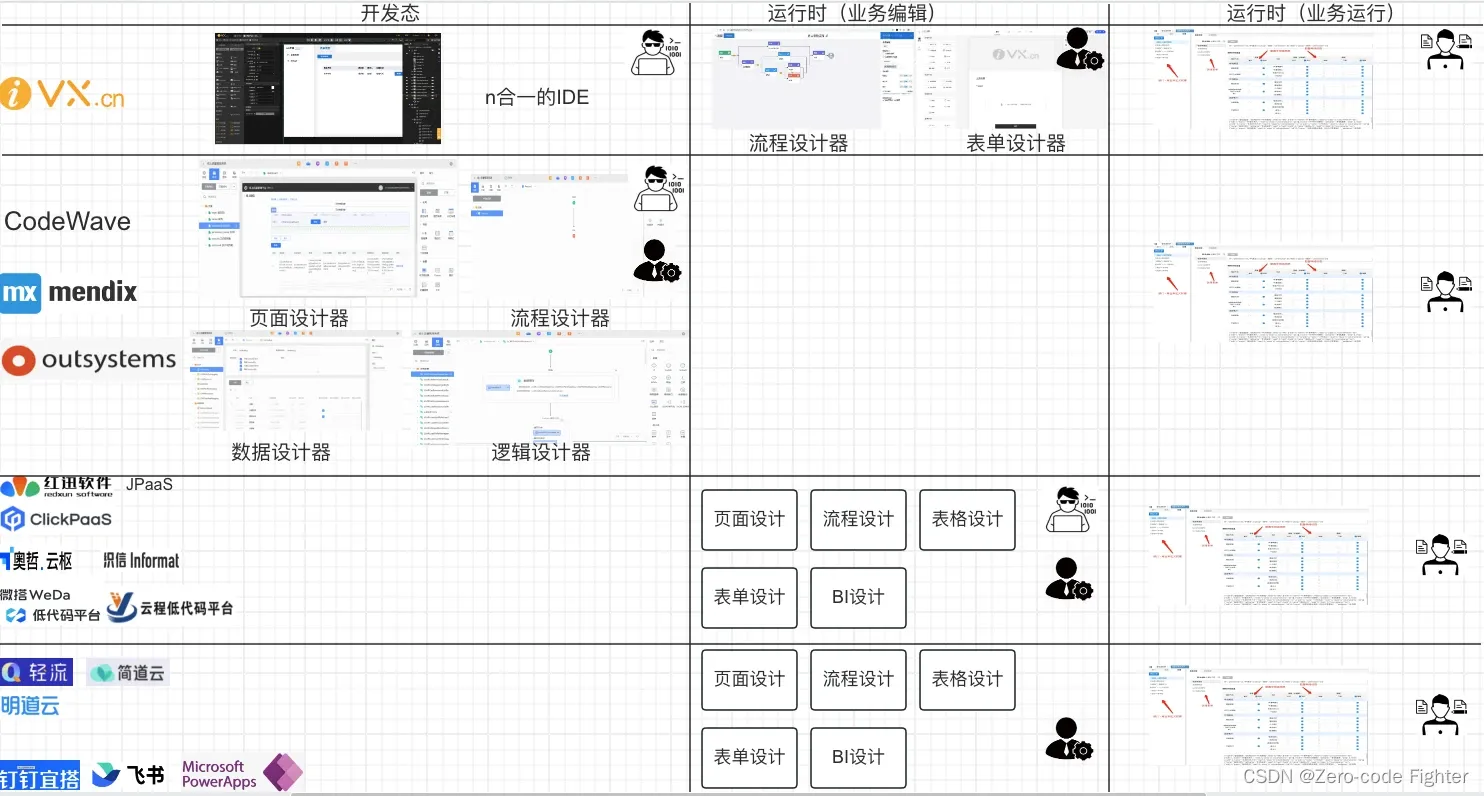
选择低代码应该注意什么?如何选择?
我查看了几乎所有的介绍低代码的总结和分析报告,几乎都没有把低代码最底层的产品逻辑说清楚。今天我尝试不用复杂的技术名词,也不用代码,把这个事儿给大家说明白,低代码到底怎么回事儿!(人云亦云那些&#…...
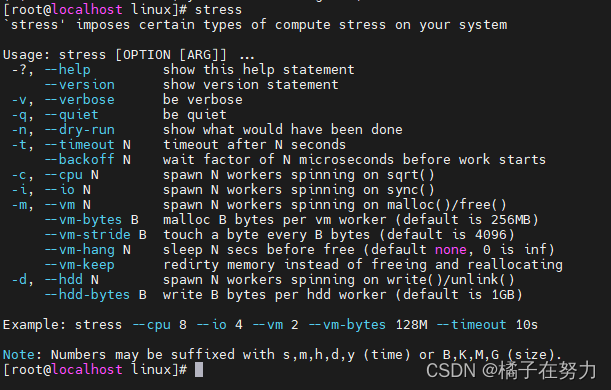
橘子学linux调优之工具包的安装
今天在公司无聊的弄服务器,想着有些常用的工具包安装一下,这里就简单记录一下。 一、sysstat的安装和使用 1、安装 我是通过源码的方式安装的,这样的好处在于可以自由选择你的版本,很直观。 直接去github上找到sysstat的地址&a…...

函数的连续与间断【高数笔记】
【连续】 分类,分几个?每类特点? 连续条件,是同时满足还是只需其一? 【间断】 分类,分几个大类,又分几个小类?每类特点? 间断条件,是同时满足还是只需其一&am…...

游戏如何选择服务器
选择游戏服务器是一个综合性的过程,涉及到的因素包括但不限于游戏类型和规模、硬件配置、网络质量、安全性、服务商的声誉以及地理分布等。以下是一些具体的指导原则: 游戏类型和规模:根据游戏的具体需求来选择合适的服务器。例如࿰…...

ubuntu20安装mysql8
1.安装 sudo apt update sudo apt install mysql-server-8.0 -y2.查看运行状态 yantaoubuntu20:~$ sudo systemctl status mysql ● mysql.service - MySQL Community ServerLoaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset:>Active: active …...
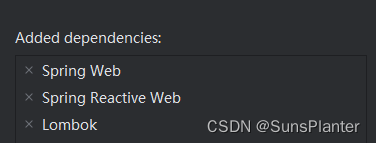
07 SB3之@HttpExchange(TBD)
HttpExchange是SpringBoot3的新特性. Spring Boot3 提供了新的 HTTP 的访问能力,封装了Http底层细节. 通过接口简化 HTTP远程访问,类似 Feign 功能。 SpringBoot 中定义接口提供 HTTP 服务 --> 框架生成的代理对象实现此接口 --> 框架生成的代理…...

Redis数据淘汰策略
Redis作为一种高性能的键值存储数据库,通常用于缓存和提高数据检索速度。然而,由于内存资源有限,当内存不足以容纳所有数据时,Redis就需要采取一些策略来删除部分数据,以确保新的数据能够被写入。这就引入了数据淘汰策…...

群晖ARPL界面IP显示正常但Synology Assistant搜不到?试试这5个排查步骤
群晖ARPL界面IP显示正常但Synology Assistant搜不到的深度排查指南 当你兴奋地完成黑群晖的ARPL引导安装,在启动界面看到系统已经成功获取IP地址,却突然发现Synology Assistant工具死活搜不到这个IP时,那种从云端跌入谷底的感觉我太熟悉了。这…...

零门槛视频创作:OpenCut高效替代方案全解析
零门槛视频创作:OpenCut高效替代方案全解析 【免费下载链接】OpenCut The open-source CapCut alternative 项目地址: https://gitcode.com/gh_mirrors/ap/OpenCut 在数字内容创作爆炸的时代,视频编辑工具的选择直接影响创作效率与作品质量。Open…...

八位行波进位加法器设计全攻略:从理论到Quartus II实现
八位行波进位加法器设计全攻略:从理论到Quartus II实现 在数字电路设计中,加法器是最基础也是最重要的运算单元之一。无论是简单的计算器还是复杂的CPU,都离不开高效可靠的加法器设计。八位行波进位加法器作为入门级但实用性极强的设计案例&a…...
)
Zotero效率翻倍!Zutilo插件保姆级配置指南(附我常用的10个快捷键方案)
Zotero效率革命:用Zutilo插件打造键盘流文献工作流 每天面对数百篇文献,你是否厌倦了在鼠标和键盘间反复切换?科研老手都知道,真正的效率提升往往来自那些能减少手指移动距离的微小优化。Zutilo正是Zotero生态中那个被严重低估的…...

面试回答第十五问:类加载
类加载简介 类加载是JVM能够识别类信息,分配空间创建对象实例的基础。 类加载一共分为五阶段,分别是加载,验证,准备,解析,初始化五阶段。这不是顺序,不是加载之后才能验证,验证之后才…...
)
Shell脚本新手必看:6种方法彻底解决Undefined Variable报错(附代码示例)
Shell脚本变量报错终极指南:从根源解决Undefined Variable问题 在Linux系统管理和自动化运维中,Shell脚本是不可或缺的工具。但许多初学者在编写脚本时,经常会遇到"Undefined Variable"这类看似简单却令人头疼的报错。这种错误不仅…...

VisualVM安全监控指南:敏感数据保护与权限管理
VisualVM安全监控指南:敏感数据保护与权限管理 【免费下载链接】visualvm VisualVM is an All-in-One Java Troubleshooting Tool 项目地址: https://gitcode.com/gh_mirrors/vi/visualvm VisualVM作为一款强大的Java应用性能监控与故障诊断工具,…...

EVA-02一键部署教程:Python爬虫数据智能处理实战
EVA-02一键部署教程:Python爬虫数据智能处理实战 你是不是也遇到过这种情况?用Python爬虫辛辛苦苦抓了一堆网页数据,结果发现里面全是乱七八糟的HTML标签和广告信息,真正有用的内容被埋得严严实实。手动写规则去提取吧࿰…...

4步打造高效能开源路由器:OpenWrt固件安装指南
4步打造高效能开源路由器:OpenWrt固件安装指南 【免费下载链接】openwrt openwrt编译更新库X86-R2C-R2S-R4S-R5S-N1-小米MI系列等多机型全部适配OTA自动升级 项目地址: https://gitcode.com/GitHub_Trending/openwrt5/openwrt OpenWrt固件安装是提升R5S设备性…...

[双重嵌入架构]:实现高精度人脸生成的AI解决方案
[双重嵌入架构]:实现高精度人脸生成的AI解决方案 【免费下载链接】IP-Adapter-FaceID 项目地址: https://ai.gitcode.com/hf_mirrors/h94/IP-Adapter-FaceID 1. 技术原理:双重嵌入架构的创新突破 1.1 并行特征处理机制 IP-Adapter-FaceID Plus…...