泛型、Trait 和生命周期(上)
目录
1、提取函数来减少重复
2、在函数定义中使用泛型
3、结构体定义中的泛型
4、枚举定义中的泛型
5、方法定义中的泛型
6、泛型代码的性能
每一门编程语言都有高效处理重复概念的工具。在 Rust 中其工具之一就是 泛型(generics)。泛型是具体类型或其他属性的抽象替代。我们可以表达泛型的属性,比如它们的行为或如何与其他泛型相关联,而不需要在编写和编译代码时知道它们在这里实际上代表什么。
首先,我们将回顾一下提取函数以减少代码重复的机制。接下来,我们将使用相同的技术,从两个仅参数类型不同的函数中创建一个泛型函数。我们也会讲到结构体和枚举定义中的泛型。
之后,我们讨论 trait,这是一个定义泛型行为的方法。trait 可以与泛型结合来将泛型限制为只接受拥有特定行为的类型,而不是任意类型。
最后介绍 生命周期(lifetimes),它是一类允许我们向编译器提供引用如何相互关联的泛型。Rust 的生命周期功能允许在很多场景下借用值的同时仍然使编译器能够检查这些引用的有效性。
1、提取函数来减少重复
让我们从下面这个这个寻找列表中最大值的小程序开始,如下所示:
fn main() {let number_list = vec![34, 50, 25, 100, 65]; // 定义一个列表let mut largest = &number_list[0]; // 定义一个可变变量largest,默认取列表的第一个值for number in &number_list {if number > largest { // 遍历如果值大于上面定义第一个值,则对应的值覆盖原来的值largest = number;}}println!("The largest number is {}", largest); // 100
}为了消除重复,我们要创建一层抽象,定义一个处理任意整型列表作为参数的函数。这个方案使得代码更简洁,并且表现了寻找任意列表中最大值这一概念。
fn largest(list: &[i32]) -> &i32 {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];let result = largest(&number_list);println!("The largest number is {}", result);
}
largest 函数有一个参数 list,它代表会传递给函数的任何具体的 i32值的 slice。函数定义中的 list 代表任何 &[i32]。当调用 largest 函数时,其代码实际上运行于我们传递的特定值上。
2、在函数定义中使用泛型
当使用泛型定义函数时,本来在函数签名中指定参数和返回值的类型的地方,会改用泛型来表示。采用这种技术,使得代码适应性更强,从而为函数的调用者提供更多的功能,同时也避免了代码的重复。
回到 largest 函数,以下示例中展示了两个函数,它们的功能都是寻找 slice 中最大值。接着我们使用泛型将其合并为一个函数。
fn largest_i32(list: &[i32]) -> &i32 {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn largest_char(list: &[char]) -> &char {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest_i32(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest_char(&char_list);println!("The largest char is {}", result);
}
为了参数化这个新函数中的这些类型,我们需要为类型参数命名,道理和给函数的形参起名一样。任何标识符都可以作为类型参数的名字。这里选用 T,因为传统上来说,Rust 的类型参数名字都比较短,通常仅为一个字母,同时,Rust 类型名的命名规范是首字母大写驼峰式命名法(UpperCamelCase)。T 作为 “type” 的缩写是大部分 Rust 程序员的首选。
如果要在函数体中使用参数,就必须在函数签名中声明它的名字,好让编译器知道这个名字指代的是什么。同理,当在函数签名中使用一个类型参数时,必须在使用它之前就声明它。为了定义泛型版本的 largest 函数,类型参数声明位于函数名称与参数列表中间的尖括号 <> 中,像这样:
fn largest<T>(list: &[T]) -> &T {可以这样理解这个定义:函数 largest 有泛型类型 T。它有个参数 list,其类型是元素为 T 的 slice。largest 函数会返回一个与 T 相同类型的引用。
在以下示例中,largest 函数在它的签名中使用了泛型,统一了两个实现。该示例也展示了如何调用 largest 函数,把 i32 值的 slice 或 char 值的 slice 传给它。请注意这些代码还不能编译!
fn largest<T>(list: &[T]) -> &T {let mut largest = &list[0];for item in list {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest(&char_list);println!("The largest char is {}", result);
}运行以上代码,会报以下错误。

帮助说明中提到了 std::cmp::PartialOrd,这是一个 trait。下一部分会讲到 trait。不过简单来说,这个错误表明 largest 的函数体不能适用于 T 的所有可能的类型。因为在函数体需要比较 T 类型的值,不过它只能用于我们知道如何排序的类型。为了开启比较功能,标准库中定义的 std::cmp::PartialOrd trait 可以实现类型的比较功能(查看附录 C 获取该 trait 的更多信息)。依照帮助说明中的建议,我们限制 T 只对实现了 PartialOrd 的类型有效后代码就可以编译了,因为标准库为 i32 和 char 实现了 PartialOrd。
3、结构体定义中的泛型
同样也可以用 <> 语法来定义结构体,它包含一个或多个泛型参数类型字段。下列示例定义了一个可以存放任何类型的 x 和 y 坐标值的结构体 Point:
struct Point<T> {x: T,y: T,
}fn main() {let integer = Point { x: 5, y: 10 };let float = Point { x: 1.0, y: 4.0 };
}其语法类似于函数定义中使用泛型。首先,必须在结构体名称后面的尖括号中声明泛型参数的名称。接着在结构体定义中可以指定具体数据类型的位置使用泛型类型。
注意 Point<T> 的定义中只使用了一个泛型类型,这个定义表明结构体 Point<T> 对于一些类型 T 是泛型的,而且字段 x 和 y 都是 相同类型的,无论它具体是何类型。如果尝试创建一个有不同类型值的 Point<T> 的实例,在以下示例代码中是不能编译的。
struct Point<T> {x: T,y: T,
}fn main() {let wont_work = Point { x: 5, y: 4.0 };
}在这个例子中,当把整型值 5 赋值给 x 时,就告诉了编译器这个 Point<T> 实例中的泛型 T 全是整型。接着指定 y 为浮点值 4.0,因为它y被定义为与 x 相同类型,所以将会得到一个像这样的类型不匹配错误:
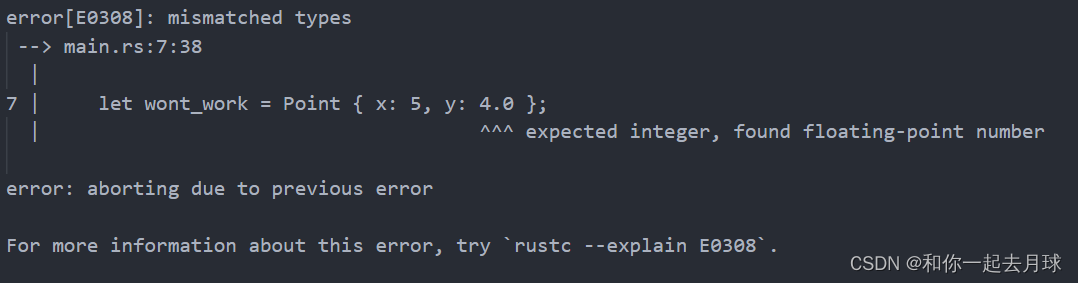
如果想要定义一个 x 和 y 可以有不同类型且仍然是泛型的 Point 结构体,我们可以使用多个泛型类型参数。在以下示例,我们修改 Point 的定义为拥有两个泛型类型 T 和 U。其中字段 x 是 T 类型的,而字段 y 是 U 类型的:
struct Point<T, U> {x: T,y: U,
}fn main() {let both_integer = Point { x: 5, y: 10 };let both_float = Point { x: 1.0, y: 4.0 };let integer_and_float = Point { x: 5, y: 4.0 };
}4、枚举定义中的泛型
和结构体类似,枚举也可以在成员中存放泛型数据类型。第六章我们曾用过标准库提供的 Option<T> 枚举,这里再回顾一下:
enum Option<T> {Some(T),None,
}现在这个定义应该更容易理解了。如你所见 Option<T> 是一个拥有泛型 T 的枚举,它有两个成员:Some,它存放了一个类型 T 的值,和不存在任何值的None。通过 Option<T> 枚举可以表达有一个可能的值的抽象概念,同时因为 Option<T> 是泛型的,无论这个可能的值是什么类型都可以使用这个抽象。
枚举也可以拥有多个泛型类型。
enum Result<T, E> {Ok(T),Err(E),
}Result 枚举有两个泛型类型,T 和 E。Result 有两个成员:Ok,它存放一个类型 T 的值,而 Err 则存放一个类型 E 的值。这个定义使得 Result 枚举能很方便的表达任何可能成功(返回 T 类型的值)也可能失败(返回 E 类型的值)的操作。
5、方法定义中的泛型
在为结构体和枚举实现方法时(像第五章那样),一样也可以用泛型。
struct Point<T> {x: T,y: T,
}impl<T> Point<T> {fn x(&self) -> &T {&self.x}
}fn main() {let p = Point { x: 5, y: 10 };println!("p.x = {}", p.x());
}这里在 Point<T> 上定义了一个叫做 x 的方法来返回字段 x 中数据的引用:
注意必须在 impl 后面声明 T,这样就可以在 Point<T> 上实现的方法中使用 T 了。通过在 impl 之后声明泛型 T,Rust 就知道 Point 的尖括号中的类型是泛型而不是具体类型。我们可以为泛型参数选择一个与结构体定义中声明的泛型参数所不同的名称,不过依照惯例使用了相同的名称。在声明泛型类型参数的 impl 中编写的方法将会定义在该类型的任何实例上,无论最终替换泛型类型参数的是何具体类型。
定义方法时也可以为泛型指定限制(constraint)。例如,可以选择为 Point<f32> 实例实现方法,而不是为泛型 Point 实例。示例 10-10 展示了一个没有在 impl 之后(的尖括号)声明泛型的例子,这里使用了一个具体类型,f32:
impl Point<f32> {fn distance_from_origin(&self) -> f32 {(self.x.powi(2) + self.y.powi(2)).sqrt()}
}这段代码意味着 Point<f32> 类型会有一个方法 distance_from_origin,而其他 T 不是 f32 类型的 Point<T> 实例则没有定义此方法。这个方法计算点实例与坐标 (0.0, 0.0) 之间的距离,并使用了只能用于浮点型的数学运算符。
结构体定义中的泛型类型参数并不总是与结构体方法签名中使用的泛型是同一类型。示例 10-11 中为 Point 结构体使用了泛型类型 X1 和 Y1,为 mixup 方法签名使用了 X2 和 Y2 来使得示例更加清楚。这个方法用 self 的 Point 类型的 x 值(类型 X1)和参数的 Point 类型的 y 值(类型 Y2)来创建一个新 Point 类型的实例:
struct Point<X1, Y1> {x: X1,y: Y1,
}impl<X1, Y1> Point<X1, Y1> {fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {Point {x: self.x,y: other.y,}}
}fn main() {let p1 = Point { x: 5, y: 10.4 };let p2 = Point { x: "Hello", y: 'c' };let p3 = p1.mixup(p2);println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}在 main 函数中,定义了一个有 i32 类型的 x(其值为 5)和 f64 的 y(其值为 10.4)的 Point。p2 则是一个有着字符串 slice 类型的 x(其值为 "Hello")和 char 类型的 y(其值为c)的 Point。在 p1 上以 p2 作为参数调用 mixup 会返回一个 p3,它会有一个 i32 类型的 x,因为 x 来自 p1,并拥有一个 char 类型的 y,因为 y 来自 p2。println! 会打印出 p3.x = 5, p3.y = c。
6、泛型代码的性能
Rust 通过在编译时进行泛型代码的 单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
在这个过程中,编译器所做的工作正好与示例 10-5 中我们创建泛型函数的步骤相反。编译器寻找所有泛型代码被调用的位置并使用泛型代码针对具体类型生成代码。
让我们看看这如何用于标准库中的 Option 枚举:
let integer = Some(5);
let float = Some(5.0);当 Rust 编译这些代码的时候,它会进行单态化。编译器会读取传递给 Option<T> 的值并发现有两种 Option<T>:一个对应 i32 另一个对应 f64。为此,它会将泛型定义 Option<T> 展开为两个针对 i32 和 f64 的定义,接着将泛型定义替换为这两个具体的定义。
编译器生成的单态化版本的代码看起来像这样(编译器会使用不同于如下假想的名字):
enum Option_i32 {Some(i32),None,
}enum Option_f64 {Some(f64),None,
}fn main() {let integer = Option_i32::Some(5);let float = Option_f64::Some(5.0);
}泛型 Option<T> 被编译器替换为了具体的定义。因为 Rust 会将每种情况下的泛型代码编译为具体类型,使用泛型没有运行时开销。当代码运行时,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。
相关文章:
泛型、Trait 和生命周期(上)
目录 1、提取函数来减少重复 2、在函数定义中使用泛型 3、结构体定义中的泛型 4、枚举定义中的泛型 5、方法定义中的泛型 6、泛型代码的性能 每一门编程语言都有高效处理重复概念的工具。在 Rust 中其工具之一就是 泛型(generics)。泛型是具体类型…...

<网络安全>《18 数据安全交换系统》
1 概念 企业为了保护核心数据安全,都会采取一些措施,比如做网络隔离划分,分成了不同的安全级别网络,或者安全域,接下来就是需要建设跨网络、跨安全域的安全数据交换系统,将安全保障与数据交换功能有机整合…...
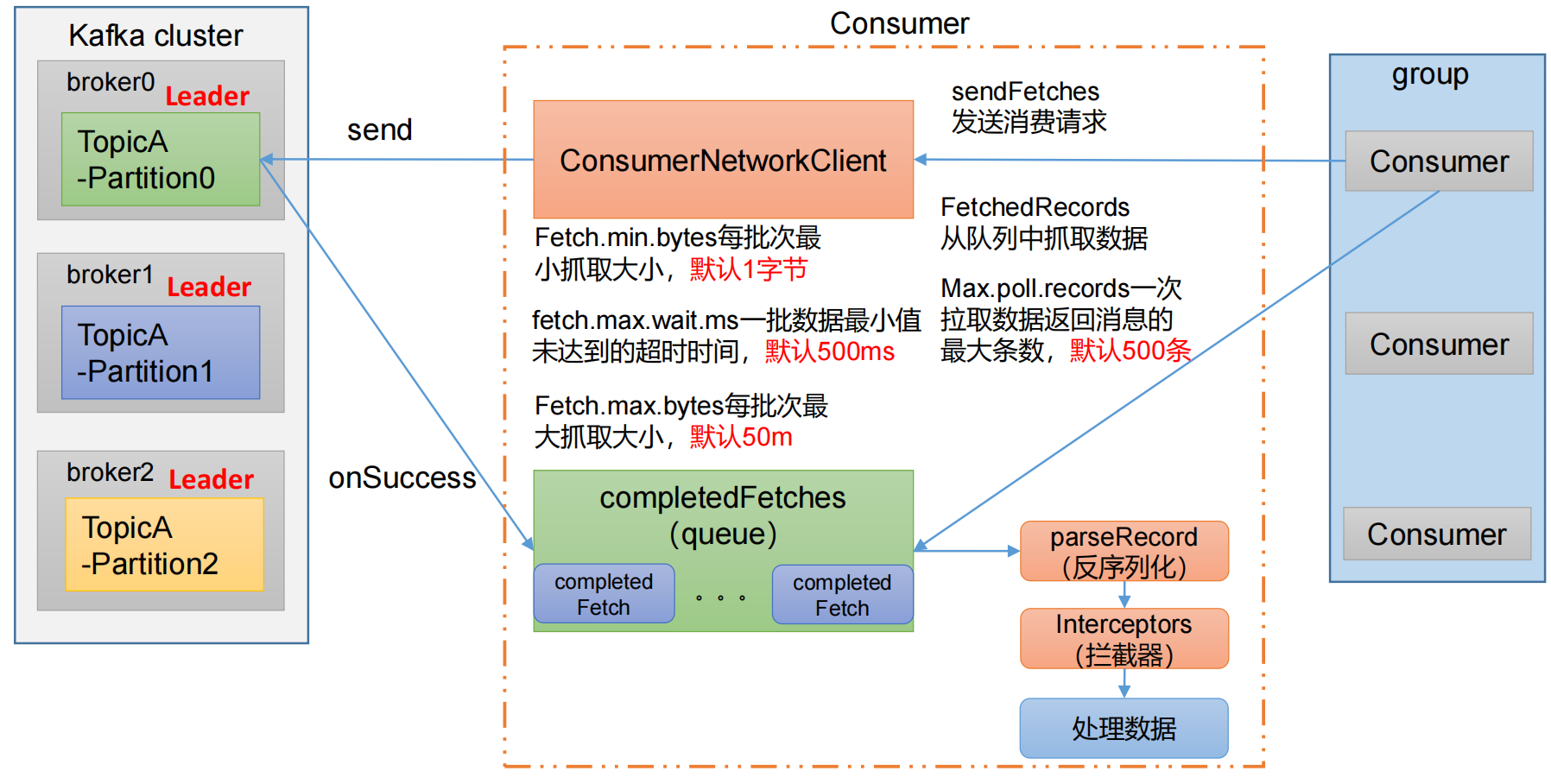
Kafka 生产调优
Kafka生产调优 文章目录 Kafka生产调优一、Kafka 硬件配置选择场景说明服务器台数选择磁盘选择内存选择CPU选择 二、Kafka Broker调优Broker 核心参数配置服役新节点/退役旧节点增加副本因子调整分区副本存储 三、Kafka 生产者调优生产者如何提高吞吐量数据可靠性数据去重数据乱…...
springboot162基于SpringBoot的体育馆管理系统的设计与实现
体育馆管理系统 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本体育馆管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕…...

Interpolator:在Android中方便使用一些常见的CubicBezier贝塞尔曲线动画效果
说明 方便在Android中使用Interpolator一些常见的CubicBezier贝塞尔曲线动画效果。 示意图如下 import android.view.animation.Interpolator import androidx.core.view.animation.PathInterpolatorCompat/*** 参考* android https://yisibl.github.io/cubic-bezier* 实现常…...
Nacos安装,服务注册,负载均衡配置,权重配置以及环境隔离
1. 安装 首先从官网下载 nacos 安装包,注意是下载 nacos-server Nacos官网 | Nacos 官方社区 | Nacos 下载 | Nacos 下载完毕后,解压找到文件夹bin,文本打开startup.cmd 修改配置如下 然后双击 startup.cmd 启动 nacos服务,默认…...

Vue3导出数据为txt文件
在Vue3中,可以通过使用Blob对象以及URL.createObjectURL()方法导出txt文档。 首先,你需要在Vue组件中创建一个方法来生成txt文档的内容。 //res.value.code 数据源 //type:格式设置 //form.name是下载文件的自定义名字 const downLoad ()&…...

Simulink中getConfigSet用法
目录 语法 说明 示例 获取配置集 getConfigSet的功能是从模型中获取配置集或配置引用。 语法 myConfigObj getConfigSet(model, configObjName) 说明 myConfigObj getConfigSet(model, configObjName) 返回关联到 model 并命名为 configObjName 的配置集或配置引用。 …...

【Algorithms 4】算法(第4版)学习笔记 05 - 2.2 归并排序
文章目录 前言参考目录学习笔记1:归并排序的简单演示1.1:基本思路1.2:归并排序的 demo 演示1.3:代码实现2:自顶向下的归并排序2.1:比较次数与访问次数的证明2.2:代码优化2.3:优化后代…...

mybatis mapper sql include用法实现sql块复用
一、总SQL <select id"getxxxMonitorData"resultType"com.xxx.module.system.dal.dataobject.xxx.xxxDO"><include refid"getxxxMonitorDataBaseSql"></include><include refid"whereContent"></include&…...
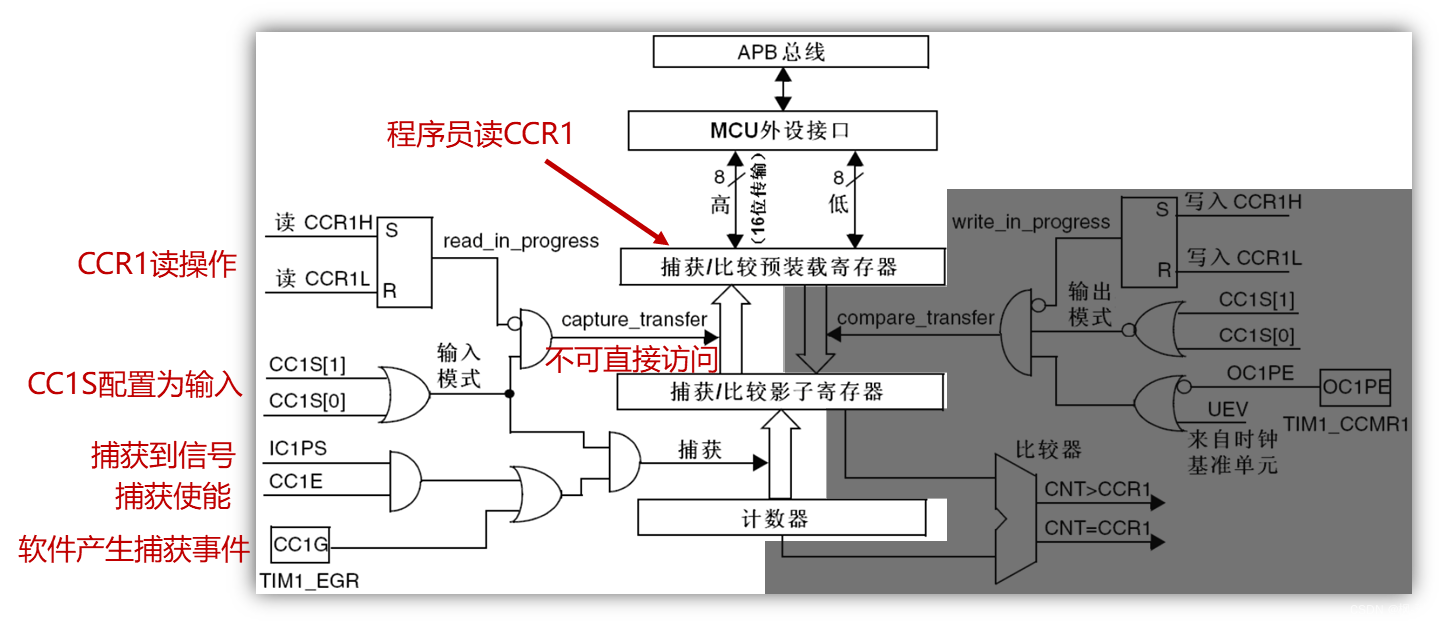
正点原子--STM32通用定时器学习笔记(2)
1. 通用定时器输入捕获部分框图介绍 捕获/比较通道的输入部分(通道1) 采样频率:控制寄存器 1(TIMx_CR1)的CKD[1:0] ⬇⬇⬇滤波方式选择: 捕获/ 比较模式寄存器 1(TIMx_CCMR1)的输入捕获部分⬇⬇…...

Flask实现异步调用sqlalchemy的模型类
事情是这样的,我这边需要在一次请求里面,搞一个异步不阻碍的任务,来执行耗时的操作。 一开始,我准备写的代码是这样的: from flask import Flask import time from concurrent.futures import ThreadPoolExecutorexec…...

Pocket2Mol + Generation of Atom Positions生成原子位置的方法有什么?联合概率是什么?
联合概率: 联合概率是统计学中的一个概念,用于描述两个或多个随机事件同时发生的概率。当我们谈论多个变量的联合概率时,我们是在探讨这些变量同时取特定值的概率。 让我们简化一下概念: 假设你有一个骰子(六面&…...

区分手机小程序以及电脑小程序;左滑、导航键返回拦截
1、区分电脑小程序和手机小程序 //区分电脑小程序、手机小程序(目标:手机小程序) // #ifdef MP-WEIXIN uni.getSystemInfo({success: (res) > {// windows | mac为pc端// android | ios为手机端// console.log(getSystemInfo,, res.plat…...

Web APIs 2 事件
Web APIs 2 事件 事件监听案例:广告关闭案例:随机问答 事件监听版本事件类型案例:轮播图完整焦点事件键盘事件输入事件案例:评论字数统计 事件对象获取事件对象事件对象常用属性案例:评论回车发布 环境对象this回调函数…...

网易腾讯面试题精选----90道设计模式面试题及答案
介绍 设计模式是软件开发的重要组成部分,为常见设计问题提供经过验证的解决方案。就设计模式面试候选人可以帮助衡量他们对软件架构的理解、解决问题的能力以及编写可维护和可扩展代码的能力。以下是一些常见的设计模式面试问题和答案,可帮助评估候选人在该领域的知识和专业知…...

程序员的数字化工作台:理解不关机背后的逻辑与需求
目录 程序员为什么不喜欢关电脑? 电脑对程序员的重要性: 工作流程与需求: 数据安全与备份: 即时性与响应: 个人习惯等方面: 程序员为什么不喜欢关电脑? 电脑对程序员的重要性:…...

Java Socket Server TCP服务端向指定客户端发送消息
实现思路 首先需要知道java里如何创建一个Socket服务器端。 //创建一个服务器端对象ServerSocket server new ServerSocket(); //绑定启动的ip和端口号server.bind(new InetSocketAddress("127.0.0.1",8082));//启动成功后,调用accept()方法阻塞…...
java日志框架总结(五、logback日志框架)
一、logback概述 Logback是由log4j创始人设计的又一个开源日志组件。 Logback当前分成三个模块: 1、logback-core, 2、logback- classic 3、logback-access。 1)logback-core是其它两个模块的基础模块。 2)logback-…...

android下library打包aar并上传到maven,嵌入版的app
android嵌入版 准备工作简化代码到三方app上传maven自动打包上面已经完成了library到三方app的流程 这几天在研究android下怎么把自己的项目当作一个library给到另一个app做嵌入使用,把这些记录下来,方便以后参考 准备工作 1.需要了解一些gradle 命令打…...
实战:从原理到代码实现与性能对比)
Treap(树堆)实战:从原理到代码实现与性能对比
1. 什么是Treap:当二叉搜索树遇上堆 第一次听说Treap这个数据结构时,我正被红黑树的旋转操作折磨得焦头烂额。直到某天在算法竞赛讨论区看到有人用20行代码实现了一个"魔法平衡树",才真正打开了新世界的大门。Treap这个名字本身就揭…...

终极指南:如何在浏览器中快速将HTML转换为Word文档
终极指南:如何在浏览器中快速将HTML转换为Word文档 【免费下载链接】html-docx-js Converts HTML documents to DOCX in the browser 项目地址: https://gitcode.com/gh_mirrors/ht/html-docx-js 你是否需要将网页内容导出为可编辑的Word文档?htm…...

BURSTER 8645-5005 扭矩传感器
BURSTER 8645-5005(德国波斯特)是一款非接触式、磁致伸缩原理、高精度动态旋转扭矩传感器,量程 5 N・m,内置放大器,专为连续旋转工况下的动态扭矩测量设计一、型号与量程型号:BURSTER 8645-5005系列&#x…...
)
用Python和ROS 2 Humble手把手教你写一个简易机械臂仿真器(附完整代码)
用Python和ROS 2 Humble构建2自由度机械臂仿真器:从零实现运动学与轨迹可视化 在机器人开发中,机械臂的运动控制一直是核心难点。传统实体设备的高成本和复杂调试流程让许多开发者望而却步。本文将带你用Python和ROS 2 Humble构建一个完整的2自由度机械臂…...

终极指南:深度解析ExplorerBlurMica如何用3大核心技术重塑Windows文件资源管理器透明美化体验
终极指南:深度解析ExplorerBlurMica如何用3大核心技术重塑Windows文件资源管理器透明美化体验 【免费下载链接】ExplorerBlurMica Add background Blur effect or Acrylic (Mica for win11) effect to explorer for win10 and win11 项目地址: https://gitcode.co…...

ZYNQ7010核心板硬件设计实战——从原理图到PCB的工程化思考
1. 从零开始构建ZYNQ7010核心板 第一次接触ZYNQ7010这种集成了ARM处理器和FPGA的SoC芯片时,我既兴奋又忐忑。这种混合架构的芯片确实强大,但随之而来的硬件设计复杂度也让人头疼。特别是当看到官方推荐的8层甚至12层PCB方案时,作为个人开发者…...

ReAct让AI像人一样“边想边做”,轻松搞定复杂问题!
写在前面 欢迎回到我们的智能体架构系列。上一期我们聊了工具调用,让智能体“长出了手”,能去外部世界获取信息。但很快我们就发现,光有手还不够。面对“谁是《沙丘》制片公司的CEO,以及该公司最近一部电影的预算?”这…...

MeterSphere接口测试保姆级教程:从环境配置到自动化编排,手把手带你避开那些新手必踩的坑
MeterSphere接口测试实战指南:从零搭建到高效编排的核心技巧 第一次打开MeterSphere的界面时,那些密密麻麻的菜单项和专业术语确实容易让人望而生畏。作为过来人,我完全理解新手面对接口测试工具时的困惑——"全局变量到底该在哪里设置&…...

Java面试-test
test...

Windows 11 零基础搞定 Coze Studio 本地部署:Docker 配置 + 豆包模型实战
Windows 11 零基础搞定 Coze Studio 本地部署:Docker 配置 豆包模型实战 1. 环境准备与Docker安装 对于Windows 11用户来说,Docker是运行Coze Studio的基础环境。与Linux或macOS不同,Windows平台需要特别注意虚拟化支持和镜像源配置。 硬…...