Kafka 生产调优
Kafka生产调优
文章目录
- Kafka生产调优
- 一、Kafka 硬件配置选择
- 场景说明
- 服务器台数选择
- 磁盘选择
- 内存选择
- CPU选择
- 二、Kafka Broker调优
- Broker 核心参数配置
- 服役新节点/退役旧节点
- 增加副本因子
- 调整分区副本存储
- 三、Kafka 生产者调优
- 生产者如何提高吞吐量
- 数据可靠性
- 数据去重
- 数据乱序
- 四、Kafka 消费者调优
- 消费者重要参数🚩
- 消费者再平衡
- 指定offset进行消费
- 指定时间进行消费
- 消费者如何提高吞吐量
- 五、Kafka总体调优
- 如何提升吞吐量🚩
- 数据精准一次
- 合理设置分区数
- 单条日志大于 1m的问题
- 集群压力测试
- Kafka Producer 压力测试
- Kafka Consumer 压力测试
一、Kafka 硬件配置选择
场景说明
100 万日活,每人每天 100 条日志,每天总共的日志条数是 100 万 * 100 条 = 1 亿条。
1 亿 / 24 小时 / 60 分 / 60 秒 = 1150 条/每秒钟。
每条日志大小:0.5k ~ 2k(约1k)。
1150 条/每秒钟 * 1k ≈ 1m/s 。
高峰期每秒钟:1150 条 * 20 倍 = 23000 条。
所以高峰每秒数据量:20MB/s。
服务器台数选择
服务器台数= 2 * (生产者峰值生产速率 * 副本 / 100) + 1
= 2 * (20m/s * 2 / 100) + 1
= 3 台
磁盘选择
kafka 底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多。建议选择普通的机械硬盘。
每天总数据量:1 亿条 * 1k ≈ 100g
100g * 副本 2 * 保存时间 3 天 / 0.7 ≈ 1T
建议三台服务器硬盘总大小,大于等于 1T。
内存选择
Kafka 内存组成:堆内存 + 页缓存
1)Kafka 堆内存建议每个节点:10g ~ 15g(在 kafka-server-start.sh 中修改)
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx10G -Xms10G"
fi
2)页缓存:页缓存是 Linux 系统服务器的内存。我们只需要保证 1 个 segment(1g)中25%的数据在内存中就好。
每个节点页缓存大小 =(分区数 * 1g * 25%)/ 节点数。例如 10 个分区,页缓存大小=(10 * 1g * 25%)/ 3 ≈ 1g
建议服务器内存大于等于 11G。
CPU选择
- num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的 50%。
- num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的 50%的 1/3。
- num.network.threads = 3 数据传输线程数,这个参数占总核数的 50%的 2/3。
建议 32 个 cpu core。
二、Kafka Broker调优
Broker 核心参数配置

| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认30s。 |
| auto.leader.rebalance.enable | 默认是 true。 自动 Leader Partition 平衡。 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 |
| log.retention.hours | Kafka 中数据保存的时间,默认 7 天。 |
| log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟。 |
| log.retention.bytes | 默认等于-1,表示无穷大(也表示关闭)。超过设置的所有日志总大小,删除最早的 segment。 |
| log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策 |
| num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。 |
| num.replica.fetchers | 默认是 1。副本拉取线程数,这个参数占总核数的 50%的 1/3 |
| num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 。 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改, 交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。 |
服役新节点/退役旧节点
(1)创建一个要均衡的主题。
$ vim topics-to-move.json
{"topics": [{"topic": "first"}],"version": 1
}
(2)生成一个负载均衡的计划。
$ bin/kafka-reassign-partitions.sh --bootstrap-server node102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中),由步骤2生成的👆
$ vim increase-replication-factor.json
(4)执行副本存储计划。
$ bin/kafka-reassign-partitions.sh --bootstrap-server node102:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
$ bin/kafka-reassign-partitions.sh --bootstrap-server node102:9092 --reassignment-json-file increase-replication-factor.json --verify
增加副本因子
1)创建测试 topic(3分区、1副本)
$ bin/kafka-topics.sh --bootstrap-server node102:9092 --create --partitions 3 --replication-factor 1 --
topic four
2)手动增加副本存储(3分区、3副本),创建副本存储计划,所有副本都指定存储在 broker0、broker1、broker2 中
vim increase-replication-factor.json{"version":1,"partitions":[{"topic":"four","partition":0,"replicas":[0,1,2]},{"topic":"four","partition":1,"replicas":[0,1,2]},{"topic":"four","partition":2,"replicas":[0,1,2]}
]}
3)执行副本存储计划。
$ bin/kafka-reassign-partitions.sh --bootstrap-server node102:9092 --reassignment-json-file increase-replication-factor.json --execute
调整分区副本存储
(1)创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)。
vim increase-replication-factor.json{"version":1,"partitions":[{"topic":"three","partition":0,"replicas":[0,1]},{"topic":"three","partition":1,"replicas":[0,1]},{"topic":"three","partition":2,"replicas":[1,0]},{"topic":"three","partition":3,"replicas":[1,0]}]
}
(2)执行副本存储计划。
$ bin/kafka-reassign-partitions.sh --bootstrap-server node102:9092 --reassignment-json-file increase-replication-factor.json --execute
(3)验证副本存储计划
$ bin/kafka-reassign-partitions.sh --bootstrap-server node102:9092 --reassignment-json-file increase-replication-factor.json --verify
三、Kafka 生产者调优

生产者如何提高吞吐量
| 参数名称 | 描述 |
|---|---|
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。 |
| batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可 缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传 以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。 支持压缩类型:none、gzip、snappy、lz4 和 zstd。 |
数据可靠性
| 参数名称 | 描述 |
|---|---|
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列 里面的所有节点收齐数据后应答。默认值是-1 |
至少一次 = ACK 级别设置为-1 + 分区副本大于等于 2 + ISR 里应答的最小副本数量大于等于 2
数据去重
| 参数名称 | 描述 |
|---|---|
| enable.idempotence | 是否开启幂等性,默认 true,表示开启幂等性。 |
Kafka 的事务一共有如下 5 个 API
// 1 初始化事务
void initTransactions();// 2 开启事务
void beginTransaction() throws ProducerFencedException;// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws
ProducerFencedException;// 4 提交事务
void commitTransaction() throws ProducerFencedException;// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
数据乱序
| 参数名称 | 描述 |
|---|---|
| enable.idempotence | 是否开启幂等性,默认 true,表示开启幂等性。 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5,开启幂等性 要保证该值是 1-5 的数字。 |
四、Kafka 消费者调优
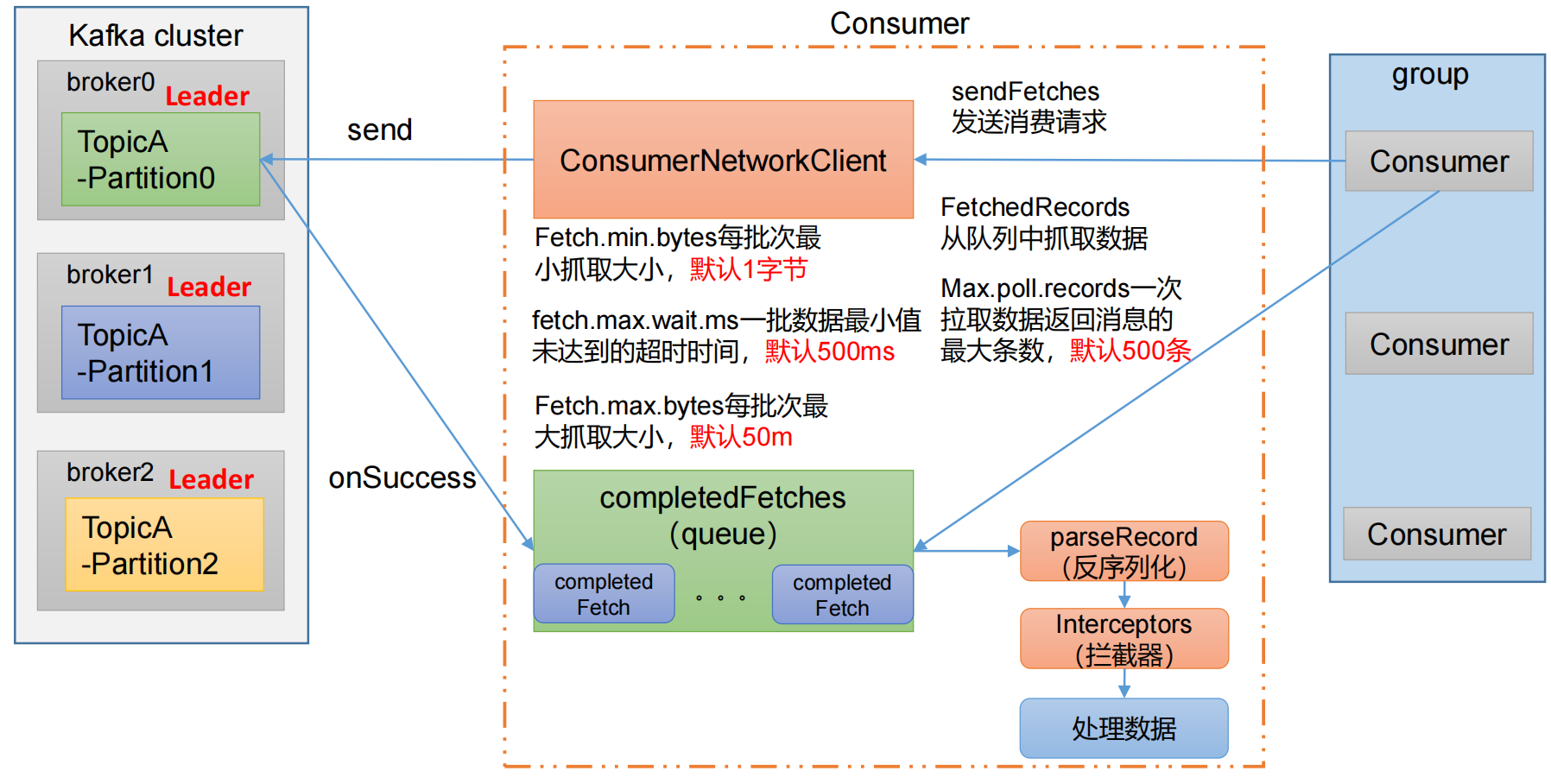
消费者重要参数🚩
| 参数 | 描述 |
|---|---|
| bootstrap.servers | 向 Kafka 集群建立初始连接用到的 host/port 列表。 |
| key.deserializer 和 value.deserializer | 指定接收消息的 key 和 value 的反序列化类型。一定要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 自动提交offset开关,默认值为 true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 消费者偏移量向Kafka提交的频率,默认5s。(如果设置自动提交offset时才生效) |
| auto.offset.reset | 当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3。 |
| ☘️session.timeout.ms | Kafka consumer 和 coordinator 之间连接超时时间,默认 45s。 超过该值,该消费者被移除,消费者组执行再平衡。 |
| ☘️max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| 🚩fetch.min.bytes | 消费者获取服务器端一批消息最小的字节数。 默认 1 个字节 |
| 🚩fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| 🚩fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| 🚩max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。 |
消费者再平衡
| 参数名称 | 描述 |
|---|---|
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于 session.timeout.ms,也不应该高于 session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。 超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| partition.assignment.strategy | 消费者分区分配策略 , 默 认 策 略 是 Range + CooperativeSticky。Kafka 可以同时使用多个分区分配策略。 可以选择的策略包括:Range、RoundRobin、Sticky、CooperativeSticky |
指定offset进行消费
public class CustomConsumerByHandSync {public static void main(String[] args) {// 1. 创建 kafka 消费者配置类Properties properties = new Properties();// 2. 添加配置参数// 添加连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");// 配置消费者组 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 是否自动提交 offsetproperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);//3. 创建 kafka 消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);// 2 订阅一个主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);//🚩 获取消费者分区信息,并指定offset进行消费Set<TopicPartition> assignment= new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}// 遍历所有分区,并指定 offset 从 1700 的位置开始消费for (TopicPartition tp: assignment) {kafkaConsumer.seek(tp, 1700);}// 消费数据while (true){// 读取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 输出消息for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.value());}}}
}
指定时间进行消费
在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。例如要求按照时间消费前一天的数据,怎么处理?
public class CustomConsumerByHandSync {public static void main(String[] args) {// 1. 创建 kafka 消费者配置类Properties properties = new Properties();// 2. 添加配置参数// 添加连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");// 配置消费者组 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 是否自动提交 offsetproperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);//3. 创建 kafka 消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);// 2 订阅一个主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);//🚩 获取消费者分区信息,并指定offset进行消费Set<TopicPartition> assignment= new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}HashMap<TopicPartition, Long> timestampToSearch = new HashMap<>(); // 封装集合存储,每个分区对应一天前的数据for (TopicPartition topicPartition : assignment) {timestampToSearch.put(topicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000);}// 获取从 1 天前开始消费的每个分区的 offsetMap<TopicPartition, OffsetAndTimestamp> offsets = kafkaConsumer.offsetsForTimes(timestampToSearch);// 遍历每个分区,对每个分区设置消费时间。for (TopicPartition topicPartition : assignment) {OffsetAndTimestamp offsetAndTimestamp = offsets.get(topicPartition);// 根据时间指定开始消费的位置if (offsetAndTimestamp != null){kafkaConsumer.seek(topicPartition, offsetAndTimestamp.offset());}}// 消费数据while (true){// 读取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 输出消息for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.value());}}}
}
消费者如何提高吞吐量
增加分区数:
$ bin/kafka-topics.sh --bootstrap-server node102:9092 --alter --topic first --partitions 3
| 参数名称 | 描述 |
|---|---|
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config) or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。 |
五、Kafka总体调优
如何提升吞吐量🚩
1)提升生产吞吐量
- buffer.memory:发送消息的缓冲区大小,默认值是 32m,可以增加到 64m。
- batch.size:默认是 16k。如果 batch 设置太小,会导致频繁网络请求,吞吐量下降;如果 batch 太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时
- linger.ms,这个值默认是 0,意思就是消息必须立即被发送。一般设置一个 5~100毫秒。如果 linger.ms 设置的太小,会导致频繁网络请求,吞吐量下降;如果 linger.ms 太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- compression.type:默认是 none,不压缩,但是也可以使用 lz4 压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大 producer 端的 CPU 开销。
2)增加分区
3)消费者提高吞吐量
- 调整 fetch.max.bytes 大小,默认是 50m。
- 调整 max.poll.records 大小,默认是 500 条。
4)增加下游消费者处理能力
数据精准一次
1)生产者角度
- acks 设置为-1 (acks=-1)
- 幂等性(enable.idempotence = true) + 事务
2)broker 服务端角度
- 分区副本大于等于 2 (–replication-factor 2)
- ISR 里应答的最小副本数量大于等于 2 (min.insync.replicas = 2)
3)消费者
- 事务 + 手动提交 offset (enable.auto.commit = false)
- 消费者输出的目的地必须支持事务(MySQL、Kafka)
合理设置分区数
(1)创建一个只有 1 个分区的 topic。
(2)测试这个 topic 的 producer 吞吐量和 consumer 吞吐量。
(3)假设他们的值分别是 Tp 和 Tc,单位可以是 MB/s。
(4)然后假设总的目标吞吐量是 Tt,那么分区数 = Tt / min(Tp,Tc)。
例如:producer 吞吐量 = 20m/s;consumer 吞吐量 = 50m/s,期望吞吐量 100m/s;
分区数 = 100 / 20 = 5 分区
分区数一般设置为:3-10 个
分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数。
单条日志大于 1m的问题
| 参数名称 | 描述 |
|---|---|
| message.max.bytes | 默认 1m,broker 端接收每个批次消息最大值 |
| max.request.size | 默认 1m,生产者发往 broker 每个请求消息最大值。针对 topic级别设置消息体的大小 |
| replica.fetch.max.bytes | 默认 1m,副本同步数据,每个批次消息最大值 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对 最大值。一批次的大小受 message.max.bytes (broker config) or max.message.bytes (topic config)影响 |
集群压力测试
用 Kafka 官方自带的脚本,对 Kafka 进行压测
- 生产者压测:kafka-producer-perf-test.sh
- 消费者压测:kafka-consumer-perf-test.sh
Kafka Producer 压力测试
(1)创建一个 test topic,设置为 3 个分区 3 个副本
$ bin/kafka-topics.sh --bootstrap-server node102:9092 --create --replication-factor 3 --partitions 3 --topic test
(2)在/opt/module/kafka/bin 目录下面有这两个文件。我们来测试一下
$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=node102:9092,node103:9092,node104:9092 batch.size=16384 linger.ms=0
测试参数说明:
- record-size 是一条信息有多大,单位是字节,本次测试设置为 1k。
- num-records 是总共发送多少条信息,本次测试设置为 100 万条。
- throughput 是每秒多少条信息,设成-1,表示不限流,尽可能快的生产数据,可测出生产者最大吞吐量。本次设置为每秒钟 1 万条。
- producer-props 后面可以配置生产者相关参数,batch.size 配置为 16k
调优参数:
更改不同的值进行压测
| 参数名称 | 描述 |
|---|---|
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。 |
| batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可 缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传 以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。 支持压缩类型:none、gzip、snappy、lz4 和 zstd。 |
Kafka Consumer 压力测试
(1)修改/opt/module/kafka/config/consumer.properties 文件中的一次拉取条数为 500
max.poll.records=500
(2)消费 100 万条日志进行压测
$ bin/kafka-consumer-perf-test.sh --bootstrap-server node102:9092,node103:9092,hadoop104:9092 --topic test --messages 1000000 --consumer.config config/consumer.properties
参数说明:
- –bootstrap-server 指定 Kafka 集群地址
- –topic 指定 topic 的名称
- –messages 总共要消费的消息个数。本次实验 100 万条
调优参数优化:(在consumer.properties中进行修改)
- 修改一次拉取的数量:max.poll.records=2000
- 调整文件中的拉取一批数据大小 100m:fetch.max.bytes=104857600
相关文章:
Kafka 生产调优
Kafka生产调优 文章目录 Kafka生产调优一、Kafka 硬件配置选择场景说明服务器台数选择磁盘选择内存选择CPU选择 二、Kafka Broker调优Broker 核心参数配置服役新节点/退役旧节点增加副本因子调整分区副本存储 三、Kafka 生产者调优生产者如何提高吞吐量数据可靠性数据去重数据乱…...
springboot162基于SpringBoot的体育馆管理系统的设计与实现
体育馆管理系统 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本体育馆管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕…...

Interpolator:在Android中方便使用一些常见的CubicBezier贝塞尔曲线动画效果
说明 方便在Android中使用Interpolator一些常见的CubicBezier贝塞尔曲线动画效果。 示意图如下 import android.view.animation.Interpolator import androidx.core.view.animation.PathInterpolatorCompat/*** 参考* android https://yisibl.github.io/cubic-bezier* 实现常…...
Nacos安装,服务注册,负载均衡配置,权重配置以及环境隔离
1. 安装 首先从官网下载 nacos 安装包,注意是下载 nacos-server Nacos官网 | Nacos 官方社区 | Nacos 下载 | Nacos 下载完毕后,解压找到文件夹bin,文本打开startup.cmd 修改配置如下 然后双击 startup.cmd 启动 nacos服务,默认…...

Vue3导出数据为txt文件
在Vue3中,可以通过使用Blob对象以及URL.createObjectURL()方法导出txt文档。 首先,你需要在Vue组件中创建一个方法来生成txt文档的内容。 //res.value.code 数据源 //type:格式设置 //form.name是下载文件的自定义名字 const downLoad ()&…...

Simulink中getConfigSet用法
目录 语法 说明 示例 获取配置集 getConfigSet的功能是从模型中获取配置集或配置引用。 语法 myConfigObj getConfigSet(model, configObjName) 说明 myConfigObj getConfigSet(model, configObjName) 返回关联到 model 并命名为 configObjName 的配置集或配置引用。 …...

【Algorithms 4】算法(第4版)学习笔记 05 - 2.2 归并排序
文章目录 前言参考目录学习笔记1:归并排序的简单演示1.1:基本思路1.2:归并排序的 demo 演示1.3:代码实现2:自顶向下的归并排序2.1:比较次数与访问次数的证明2.2:代码优化2.3:优化后代…...

mybatis mapper sql include用法实现sql块复用
一、总SQL <select id"getxxxMonitorData"resultType"com.xxx.module.system.dal.dataobject.xxx.xxxDO"><include refid"getxxxMonitorDataBaseSql"></include><include refid"whereContent"></include&…...
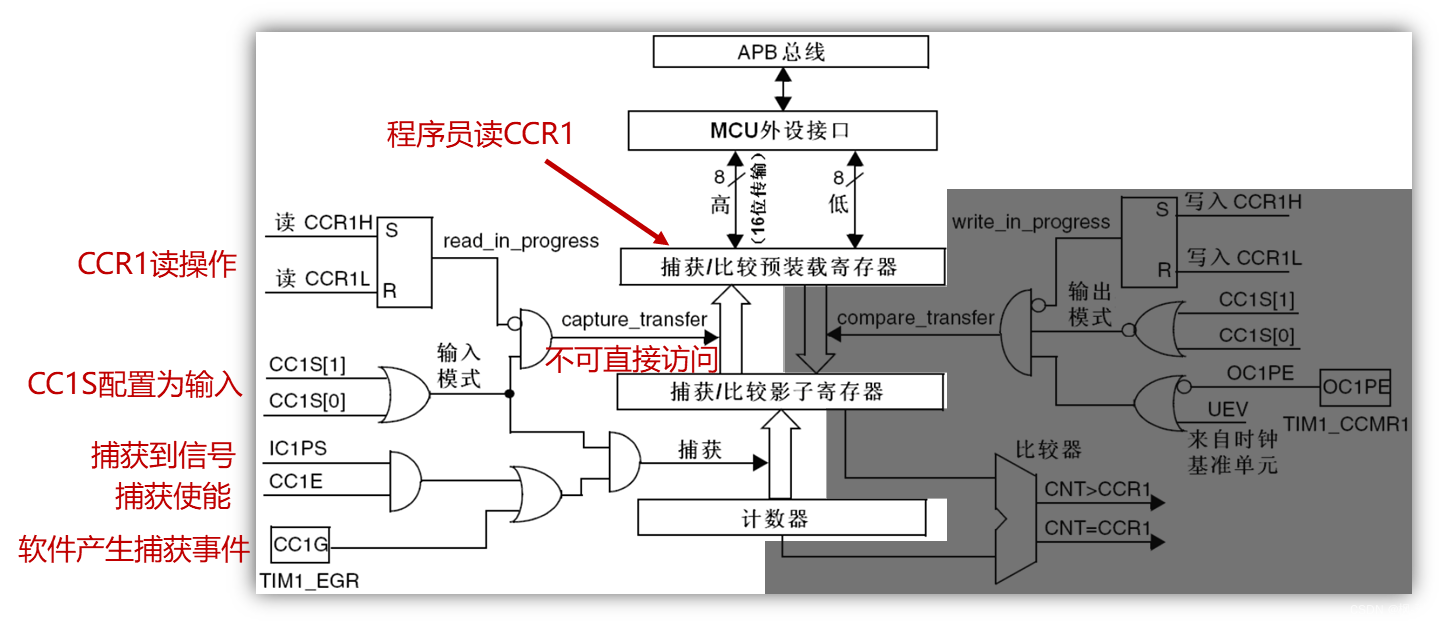
正点原子--STM32通用定时器学习笔记(2)
1. 通用定时器输入捕获部分框图介绍 捕获/比较通道的输入部分(通道1) 采样频率:控制寄存器 1(TIMx_CR1)的CKD[1:0] ⬇⬇⬇滤波方式选择: 捕获/ 比较模式寄存器 1(TIMx_CCMR1)的输入捕获部分⬇⬇…...

Flask实现异步调用sqlalchemy的模型类
事情是这样的,我这边需要在一次请求里面,搞一个异步不阻碍的任务,来执行耗时的操作。 一开始,我准备写的代码是这样的: from flask import Flask import time from concurrent.futures import ThreadPoolExecutorexec…...

Pocket2Mol + Generation of Atom Positions生成原子位置的方法有什么?联合概率是什么?
联合概率: 联合概率是统计学中的一个概念,用于描述两个或多个随机事件同时发生的概率。当我们谈论多个变量的联合概率时,我们是在探讨这些变量同时取特定值的概率。 让我们简化一下概念: 假设你有一个骰子(六面&…...

区分手机小程序以及电脑小程序;左滑、导航键返回拦截
1、区分电脑小程序和手机小程序 //区分电脑小程序、手机小程序(目标:手机小程序) // #ifdef MP-WEIXIN uni.getSystemInfo({success: (res) > {// windows | mac为pc端// android | ios为手机端// console.log(getSystemInfo,, res.plat…...

Web APIs 2 事件
Web APIs 2 事件 事件监听案例:广告关闭案例:随机问答 事件监听版本事件类型案例:轮播图完整焦点事件键盘事件输入事件案例:评论字数统计 事件对象获取事件对象事件对象常用属性案例:评论回车发布 环境对象this回调函数…...

网易腾讯面试题精选----90道设计模式面试题及答案
介绍 设计模式是软件开发的重要组成部分,为常见设计问题提供经过验证的解决方案。就设计模式面试候选人可以帮助衡量他们对软件架构的理解、解决问题的能力以及编写可维护和可扩展代码的能力。以下是一些常见的设计模式面试问题和答案,可帮助评估候选人在该领域的知识和专业知…...

程序员的数字化工作台:理解不关机背后的逻辑与需求
目录 程序员为什么不喜欢关电脑? 电脑对程序员的重要性: 工作流程与需求: 数据安全与备份: 即时性与响应: 个人习惯等方面: 程序员为什么不喜欢关电脑? 电脑对程序员的重要性:…...

Java Socket Server TCP服务端向指定客户端发送消息
实现思路 首先需要知道java里如何创建一个Socket服务器端。 //创建一个服务器端对象ServerSocket server new ServerSocket(); //绑定启动的ip和端口号server.bind(new InetSocketAddress("127.0.0.1",8082));//启动成功后,调用accept()方法阻塞…...
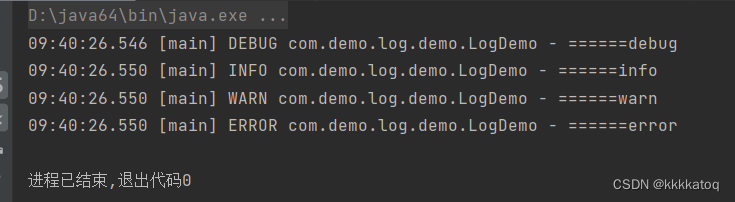
java日志框架总结(五、logback日志框架)
一、logback概述 Logback是由log4j创始人设计的又一个开源日志组件。 Logback当前分成三个模块: 1、logback-core, 2、logback- classic 3、logback-access。 1)logback-core是其它两个模块的基础模块。 2)logback-…...

android下library打包aar并上传到maven,嵌入版的app
android嵌入版 准备工作简化代码到三方app上传maven自动打包上面已经完成了library到三方app的流程 这几天在研究android下怎么把自己的项目当作一个library给到另一个app做嵌入使用,把这些记录下来,方便以后参考 准备工作 1.需要了解一些gradle 命令打…...

Xampp中Xdebug的安装使用
工欲善其事,必先利其器 XDebug简介 XDebug 是一个用于 PHP 的调试和性能分析工具。它提供了一系列功能,帮助开发者在开发和调试 PHP 应用程序时更加高效。 以下是 XDebug 的一些主要特性和功能: 调试功能: 断点调试:…...

金融行业的软件测试分析
随着金融行业的业务不断增加,金融交易模式的不断变化,金融机构对信息化的要求也越来越高,高质量的金融软件对于金融机构来说显得尤为重要。如何保证金融行业软件的质量,对金融行业软件的测试人员来说,也提出了更高的要…...

FICO批量修改资产字段AR31:替代规则失效的排查与修复
1. 替代规则失效的典型场景 最近在SAP FICO模块实施过程中,遇到一个挺有意思的问题。财务部门需要对大批量资产进行成本中心调整,要求按照不同使用日期切换不同的成本中心。听起来是个很常规的需求对吧?我们按照标准流程在GGB1配置了替代规则…...

Steam Achievement Manager完全指南:开源工具解决Steam游戏成就高效管理难题
Steam Achievement Manager完全指南:开源工具解决Steam游戏成就高效管理难题 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievemen…...

解锁开源卡牌游戏的自定义潜能:探索无名杀的无限创造空间
解锁开源卡牌游戏的自定义潜能:探索无名杀的无限创造空间 【免费下载链接】noname 项目地址: https://gitcode.com/GitHub_Trending/no/noname 在卡牌游戏的世界里,你是否曾梦想过创造属于自己的武将角色?设计独一无二的卡牌技能&…...

Comsol瓦斯抽采:深入探索复杂的地下奥秘
comsol瓦斯抽采 该案例涉及不同抽采数学模型理论 不同渗透率模型、有效应力分布媒体变形情况、瓦斯抽采量瓦斯压力分布 涵盖不同地应力工况对比 有数个详细视频 视频涉及理论分析及推导、模型建立及案例操作过程在煤矿开采领域,瓦斯抽采是一项至关重要的技术&#x…...

Excel中利用VBA批量检测URL链接状态
1. 为什么需要批量检测URL链接状态 在日常工作中,我们经常会遇到需要处理大量URL链接的情况。比如做数据分析时收集的网站列表、电商平台的商品链接、或者是内容管理系统中的文章地址。这些链接中难免会有失效的情况,可能是网站改版、页面删除࿰…...

OptiScaler全攻略:多技术融合实现跨硬件游戏画质增强的创新方案
OptiScaler全攻略:多技术融合实现跨硬件游戏画质增强的创新方案 【免费下载链接】OptiScaler DLSS replacement for AMD/Intel/Nvidia cards with multiple upscalers (XeSS/FSR2/DLSS) 项目地址: https://gitcode.com/GitHub_Trending/op/OptiScaler OptiSc…...

Pyenv vs Miniconda vs Anaconda:Python环境管理工具链深度解析
1. Python环境管理工具全景概览 刚接触Python开发时,我最头疼的就是环境配置问题。同一个项目在不同电脑上跑出不同结果,安装包时各种依赖报错,这些经历让我深刻认识到环境管理工具的重要性。目前主流的Pyenv、Miniconda和Anaconda就像三种不…...

【PyO3/Rust-Python测试权威框架】:Rust生态下Python扩展的零信任CI流水线设计
第一章:Python 扩展模块测试Python 扩展模块(如用 C/C、Rust 或 Cython 编写的模块)在提升性能的同时,也引入了跨语言交互的复杂性。对其开展系统性测试,是保障功能正确性、内存安全性和 ABI 兼容性的关键环节。测试环…...

为什么顶尖AI团队已弃用Triton+TVM?Cuvil编译器在边缘端低延迟推理中的3大不可替代优势
第一章:Cuvil编译器在Python AI推理中的核心定位与演进逻辑Cuvil编译器并非传统意义上的通用语言编译器,而是专为Python生态中AI模型推理场景深度定制的中间表示(IR)驱动型编译框架。它直面PyTorch/TensorFlow动态图执行开销大、J…...

FlowState Lab参数调优实战:如何获得理想的模拟精度与速度
FlowState Lab参数调优实战:如何获得理想的模拟精度与速度 1. 为什么参数调优如此重要 在工程仿真领域,我们常常面临一个经典难题:精度与速度的权衡。FlowState Lab作为一款强大的流体动力学仿真工具,其参数设置直接影响着模拟结…...