kafka排除zookeeper使用kraft的最新部署方案
kafka在新版本中已经可以不使用zookeeper进行服务部署,排除zookeeper的部署方案可以节省一些服务资源,这里使用 kafka_2.13-3.6.1.tgz 版本进行服务部署。
测试部署分为三个服务器:
| 服务器名称 | 服务器IP地址 |
|---|---|
| test01 | 192.168.56.101 |
| test02 | 192.168.56.102 |
| test03 | 192.168.56.103 |
- 将下载的安装包分别上传到三个服务器并解压安装包:
[root@localhost ~]# tar -zvxf kafka_2.13-3.6.1.tgz
[root@localhost ~]# cd kafka_2.13-3.6.1
[root@localhost kafka_2.13-3.6.1]# pwd
/root/kafka_2.13-3.6.1
[root@localhost kafka_2.13-3.6.1]# ls
bin config libs LICENSE licenses NOTICE site-docs
[root@localhost kafka_2.13-3.6.1]#
- 修改配置文件,这里需要在三个服务器上面分别进行修改,需要调整修改几个地方如下:
[root@localhost kafka_2.13-3.6.1]# vim ./config/kraft/server.properties# 设置角色对应的节点ID,节点ID在集群内不能重复
node.id=1
# kraft中集群节点是有角色划分的,分为broker和controller,测试环境就不去做区分,所有节点都有两种角色
process.roles=broker,controller
# 指定controller仲裁节点列表
controller.quorum.voters=1@192.168.56.101:9093,2@192.168.56.102:9093,3@192.168.56.103:9093
# 指定数据存储目录
log.dirs=/root/kafka_2.13-3.6.1/datas
# 服务监听地址
listeners=PLAINTEXT://192.168.56.101:9092,CONTROLLER://192.168.56.101:9093
# 对外提供服务的地址和端口号,如果不设置将使用listeners配置的地址
advertised.listeners=PLAINTEXT://192.168.56.101:9092
完成上面的配置后,就可以进行服务器的启动了,首次启动服务器步骤如下:
- 生成集群ID,集群id生成使用下面的命令,这个命令只需要在一台服务器上面执行即可,记录生成的这个ID:
[root@localhost kafka_2.13-3.6.1]# ./bin/kafka-storage.sh random-uuid
nJID7Q7dT62E_ehtbO3RaA
- 分别在几台服务器上面使用集群ID格式化目录:
[root@localhost kafka_2.13-3.6.1]# ./bin/kafka-storage.sh format -t nJID7Q7dT62E_ehtbO3RaA -c ./config/kraft/server.properties
Formatting /root/kafka_2.13-3.6.1/datas with metadata.version 3.6-IV2.
上面命令执行完成后,配置的数据目录将会生成两个文件,其中 bootstrap.checkpoint 是一个二进制文件,meta.properties 是元数据文件:
[root@localhost kafka_2.13-3.6.1]# ls datas/
bootstrap.checkpoint meta.properties
[root@localhost kafka_2.13-3.6.1]#
[root@localhost kafka_2.13-3.6.1]# cat datas/meta.properties
#
#Sat Feb 03 17:26:43 CST 2024
cluster.id=nJID7Q7dT62E_ehtbO3RaA
node.id=1
version=1
- 数据目录格式化完成后就可以启动服务,在启动服务时需要指定配置文件,同时可以通过参数来决定是前台启动服务还是后台启动:
# 后台启动:
$ ./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
# 前台启动:
$ ./bin/kafka-server-start.sh ./config/kraft/server.properties
完成上面这些一个kafka集群就已经搭建成功了,不使用zookeeper使得服务搭建非常简单,目前这个版本还支持使用zookeeper方式的安装。
# 启动zookeeper服务
$ bin/zookeeper-server-start.sh config/zookeeper.properties# 启动kafka服务
$ bin/kafka-server-start.sh config/server.properties
但还是建议使用kraft方式启动,毕竟可以省去zookeeper服务的维护,节省一部分资源。
# 以下所有命令都是以test-topic主题为示例,test-group消费者组为示例# 1. 创建主题:(test-topic 主题名;replication-factor 副本数量,副本是包含leader的,如果某个topic有副本,该值至少要配置为2)
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --create --topic test-topic --partitions 3 --replication-factor 2# 2. 查看主题:
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --describe --topic test-topic# 3. 删除主题:
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --delete --topic test-topic# 4. 列出主题列表
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 --list# 5. 调整分区数量
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.56.101:9092 -alter --partitions 4 --topic test-topic# 6. 查看消费者组信息
$ ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092 --list# 7. 查看某个消费者组消费情况
$ ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092 --group test-group --describe# 8. 在控制台向某个主题写入数据:
$ ./bin/kafka-console-producer.sh --broker-list 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --topic test-topic# 9. 在控制台消费某个主题数据
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --topic test-topic# 10. 指定消费10条数据
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.101:9092 --topic test-topic --max-messages 10# 在控制台消费数据时还可以添加参数:
# 最早数据开始消费:--from beginning
# 删除offsets并重新开始消费:--delete-consumer-offsets --from beginning
# 指定消费者组相关信息:--consumer.config ./config/consumer.properties------
# 下面这些是不怎么常用的命令,没有验证过作为记录供参考:# 更改主题配置信息:
./bin/kafka-configs.sh --bootstrap-server 192.168.56.101:9092 --entity-type topics --entity-name test-topic --alter --add-config max.message.bytes=128000# 查看主题配置信息:
./bin/kafka-configs.sh --bootstrap-server 192.168.56.101:9092 --entity-type topics --entity-name test-topic --describe# 删除配置:
./bin/kafka-configs.sh --bootstrap-server 192.168.56.101:9092 --entity-type topics --entity-name test-topic --alter --delete-config max.message.bytes# 将test topic的消费组的0分区的偏移量设置为最新
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --group test-group --topic test-topic:0 --reset-offsets --to-earliest –execute# 将test topic的消费组的0和1分区的偏移量设置为最旧
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --group test-group --topic test-topic:0,1 --reset-offsets --to-latest –execute# 将test topic的消费组的所有分区的偏移量设置为1000
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --group test-group --topic test-topic --reset-offsets --to-offset 1 –execute# --reset-offsets后可以跟的其他用法:--to-current:把位移调整到分区当前位移
# --reset-offsets后可以跟的其他用法:--shift-by N: 把位移调整到当前位移 + N处,注意N可以是负数,表示向前移动
# --reset-offsets后可以跟的其他用法:--to-datetime <datetime>:把位移调整到大于给定时间的最早位移处,datetime格式是yyyy-MM-ddTHH:mm:ss.xxx,比如2017-08-04T00:00:00.000
相关文章:

kafka排除zookeeper使用kraft的最新部署方案
kafka在新版本中已经可以不使用zookeeper进行服务部署,排除zookeeper的部署方案可以节省一些服务资源,这里使用 kafka_2.13-3.6.1.tgz 版本进行服务部署。 测试部署分为三个服务器: 服务器名称服务器IP地址test01192.168.56.101test02192.1…...
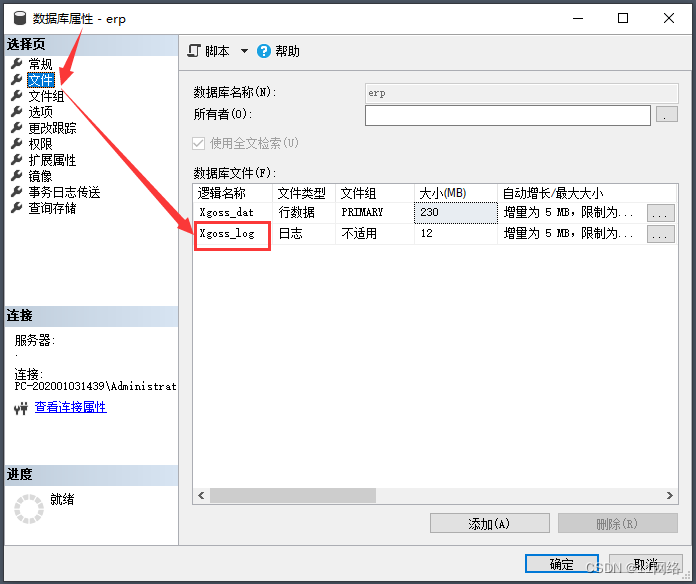
SQL Server数据库日志查看若已满需要清理的三种解决方案
首先查看获取实例中每个数据库日志文件大小及使用情况,根据数据库日志占用百分比来清理 DBCC SQLPERF(LOGSPACE) 第一种解决方案: 在数据库上点击右键 → 选择 属性 → 选择 文件,然后增加数据库日志文件的文件大小。 第二种解决方案 手动…...
人工智能 | 深度学习的进展
深度学习的进展 深度学习是人工智能领域的一个重要分支,它利用神经网络模拟人类大脑的学习过程,通过大量数据训练模型,使其能够自动提取特征、识别模式、进行分类和预测等任务。近年来,深度学习在多个领域取得了显著的进展&#…...

玩转Java8新特性
背景 说到Java8新特性,大家可能都耳濡目染了,代码中经常使用遍历stream流用到不同的api了,但是大家有没有想过自己也自定义个函数式接口呢,目前Java8自带的四个函数式接口,比如Function、Supplier等 stream流中也使用…...
EasyRecovery2024永久免费版电脑数据恢复软件下载
EasyRecovery数据恢复软件是一款非常好用且功能全面的工具,它能帮助用户恢复各种丢失或误删除的数据。以下是关于EasyRecovery的详细功能介绍以及下载步骤: EasyRecovery-mac最新版本下载:https://wm.makeding.com/iclk/?zoneid50201 EasyRecovery-win…...

QQ音乐新版客户端的音乐无法解密?来看看解决方法!音乐解锁工具Web+批处理版本合集,附常见问题及解决方法!
一、软件简介 一般会员制音乐软件(如某抑云,某鹅,某狗音乐)的歌曲下载后都是加密格式,加密格式的音乐只能在特定的播放器中才能播放,在其他音乐播放器和设备中则无法识别和播放。音乐解锁工具的作用就是将…...

2023年12月CCF-GESP编程能力等级认证C++编程一级真题解析
一、单选题(共15题,共30分) 第1题 以下C++不可以作为变量的名称的是( )。 A:CCF GESP B:ccfGESP C:CCFgesp D:CCF_GESP 答案:A 第2题 C++表达式 10 - 3 * (2 + 1) % 10 的值是( )。 A:0 B:1 C:2 D:3 答案:B 第3题 假设现在是上午十点,求出N小时(正整数…...

如何决定K8S Pod的剔除优先级
在Kubernetes(k8s)中,当节点资源面临压力时,如何决定Pod的优先级是一个关键问题。在Kubernetes 1.8版本之后,引入了基于Pod优先级的调度策略,即Pod Priority Preemption。这种策略允许在资源不足的情况下&a…...

【JavaScript】数据类型
文章目录 1. 数字(Number)2. 字符串(String)3. 布尔(Boolean)4. 对象(Object)5. 数组(Array)6. Undefined 和 Null7. typeof 操作符总结 在 JavaScript 中&am…...

JAVA:单例模式提高性能和安全性的优化技巧
1、简述 单例模式是一种常用的设计模式,用于确保一个类只有一个实例,并提供全局访问点。在 Java 中,单例模式的优化不仅可以提高性能,还可以增强安全性和可维护性。本文将介绍一些关键的技巧和最佳实践,帮助你优化单例…...
如何在 Ubuntu 上安装 ONLYOFFICE 文档 8.0
通过使用社区版,您有能力在您自己的服务器上部署 ONLYOFFICE 文档,从而使在线编辑器与 ONLYOFFICE 协作平台或其他热门系统进行无缝集成。 ONLYOFFICE 文档是什么 ONLYOFFICE 文档是一款全面的在线办公工具,提供了文本文档…...

什么是大模型
目录 让你了解什么是大模型什么是大模型?大模型的应用场景常见的大模型技术实例分析:深度学习语言模型GPT-3 让你了解什么是大模型 大模型(Big Model)是指在机器学习和人工智能领域中处理大规模数据和复杂模型的一种方法或技术。…...
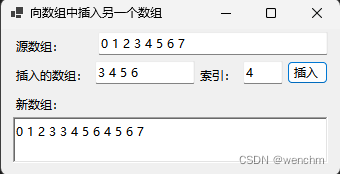
C#在既有数组中插入另一个数组:Array.Copy方法 vs 自定义插入方法
目录 一、使用的方法 1.使用Array.Copy方法 2.Copy(Array, Int32, Array, Int32, Int32) 3. 使用自定义的方法 二、实例 1.示例1:使用Array.Copy方法 2.示例2:使用自定义的方法 一、使用的方法 1.使用Array.Copy方法 首先定义了一个名为InsertAr…...

上位机图像处理和嵌入式模块部署(linux开发板的选择)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 很多图像算法是通过上位机来完成的,比如说工业视觉当中的halcon,一般都是要运行在windows平台上面,并且需要高性…...

2024情人节送女朋友什么礼物?精准送礼看这个就对啦!男生必看!
爱情是生活中最美好的情感之一,而情人节则是表达这份感情的最佳时刻。在2024年的情人节来临之际,作为男生的你是否已经为心爱的她准备了一份特别的礼物呢?如果你还在犹豫不决,那么这篇文章就是为你准备的!我们将会从女…...
)
查询每张表占用磁盘空间大小(达梦数据库)
查询每张表占用磁盘空间大小 环境介绍 环境介绍 在迁移准备工作中,为了更好评估迁移时间,可以统计大表数量与大表的实际大小,为迁移规划做准备 --查看用户下面每张表占用的磁盘空间SELECT T.OWNER,T.SEGMENT_NAME,T.SEGMENT_TYPE,T.TABLESPACE_NAME,T.BYTES,T.BYTES/1024 BYT…...

Vue3——创建一个应用
文章目录 创建应用实例挂载应用没有模板的组件的挂载 应用配置多个应用实例 其实使用脚手架创建的vue项目的main.js文件中已经为我们配置好 vue应用的创建。 import { createApp } from vue import App from ./App.vue const app createApp(App) app.mount(#app)创建应用实例…...
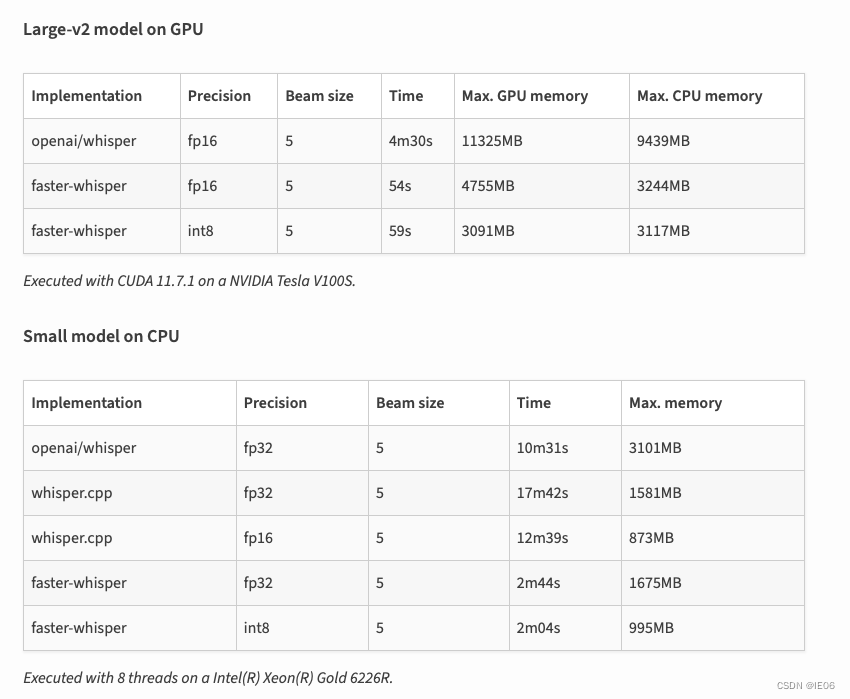
深度学习系列56:使用whisper进行语音转文字
1. openai-whisper 这应该是最快的使用方式了。安装pip install -U openai-whisper,接着安装ffmpeg,随后就可以使用了。模型清单如下: 第一种方式,使用命令行: whisper japanese.wav --language Japanese --model…...

【Web - 框架 - Vue】随笔 - 通过`CDN`的方式使用`VUE 2.0`和`Element UI`
通过CDN的方式使用VUE 2.0和Element UI VUE 网址 https://cdn.bootcdn.net/ajax/libs/vue/2.7.16/vue.js源码 https://download.csdn.net/download/HIGK_365/88815507测试 代码 <!DOCTYPE html> <html lang"en"> <head><meta charset&quo…...
备忘录模式)
设计模式(行为型模式)备忘录模式
目录 一、简介二、备忘录模式2.1、备忘录2.2、原发器2.3、备忘录模式 三、优点与缺点 一、简介 备忘录模式(Memento Pattern)是一种行为设计模式,旨在捕获一个对象的内部状态,并在不破坏对象封装的前提下将其保存,以便…...
)
POV-RAY入门指南 - 从零开始掌握光线追踪(1)
1. 初识POV-Ray:光线追踪的艺术 第一次打开POV-Ray时,我被它生成的金属球反射效果震撼到了——桌面上那个虚拟球体竟然能精确反射出周围环境的每处细节,连窗框的倒影都清晰可见。这种基于物理的光线追踪技术,正是好莱坞大片特效的…...
小信号建模之旅)
单台三相模块化多电平(MMC)小信号建模之旅
单台三相模块化多电平(mmc)小信号建模 内含功率外环、环流抑制、电流内环、PLL等控制部分完整建模在电力电子领域,三相模块化多电平(MMC)变换器因其诸多优点而备受关注。今天咱就唠唠单台MMC的小信号建模,这…...

Lychee Rerank MM惊艳效果:工业图纸图像与技术文档段落的跨模态重排序
Lychee Rerank MM惊艳效果:工业图纸图像与技术文档段落的跨模态重排序 1. 引言:当图纸遇见文字的多模态匹配革命 想象一下这样的场景:你手头有一张复杂的工业设备图纸,需要从海量技术文档中找到与之最匹配的说明段落。传统的关键…...

OpenClaw配置备份指南:Qwen3.5-9B环境快速迁移与恢复方法
OpenClaw配置备份指南:Qwen3.5-9B环境快速迁移与恢复方法 1. 为什么需要备份OpenClaw配置? 上周我的主力开发机突然硬盘故障,导致辛苦配置了两个月的OpenClaw环境全部丢失。最痛苦的不是重装软件,而是那些精心调试的模型参数、技…...

HyperDroid深度体验:安卓秒变Win11桌面的秘密武器
1. HyperDroid初体验:当安卓遇上Win11的奇妙化学反应 第一次打开HyperDroid时,我的手机屏幕瞬间变成了熟悉的Windows 11界面,那种感觉就像把电脑桌面装进了口袋。任务栏、开始菜单、甚至窗口的圆角设计都完美复刻,连动态磁贴的亚克…...

如何用VideoCaptioner将AI字幕准确率从83%提升到98%?完整免费教程
如何用VideoCaptioner将AI字幕准确率从83%提升到98%?完整免费教程 【免费下载链接】VideoCaptioner 🎬 卡卡字幕助手 | VideoCaptioner - 基于 LLM 的智能字幕助手,无需GPU一键高质量字幕视频合成!视频字幕生成、断句、校正、字幕…...
)
告别pip install langchain!用uv一步搞定LangChain 1.x环境(附pyproject.toml配置)
用uv重构LangChain开发环境:从依赖管理到生产级配置实战 如果你还在用pip install langchain搭建开发环境,可能已经落后于现代Python开发的效率标准了。当项目依赖逐渐复杂,特别是需要处理像LangChain这样包含多个可选组件(如open…...
上海同济大学上海交通大学医学院等团队:HiST:通过多尺度融合深度学习利用组织学图像重建肿瘤空间转录组)
Adv Sci(IF=14.1)上海同济大学上海交通大学医学院等团队:HiST:通过多尺度融合深度学习利用组织学图像重建肿瘤空间转录组
01文献学习今天分享的文献是由上海同济大学、上海交通大学医学院等团队于2026年3月在《Advanced Science》(中科院1区top。IF14.1)上发表的研究”HiST: Histological Images Reconstruct Tumor Spatial Transcriptomics via MultiScale Fusion Deep Lear…...

别再死记公式!一张图带你理清随机过程家族:从泊松、马尔可夫到维纳过程
随机过程家族图谱:用生活场景破解泊松、马尔可夫与维纳过程 想象一下午后的咖啡馆,顾客推门的间隔时间、咖啡师制作饮品的速度、甚至窗外飘落的樱花轨迹——这些看似无关的现象,背后都藏着随机过程的精妙规律。对于学习《随机过程》的同学们来…...

如何构建可靠的HTML5解析测试框架:全面指南与最佳实践
如何构建可靠的HTML5解析测试框架:全面指南与最佳实践 【免费下载链接】gumbo-parser An HTML5 parsing library in pure C99 项目地址: https://gitcode.com/gh_mirrors/gum/gumbo-parser HTML5解析器是现代Web开发的核心组件,而构建一个可靠的测…...