完全让ChatGPT写一个风格迁移的例子,不改动任何代码
⭐️ 前言
小编让ChatGPT写一个风格迁移的例子,注意注意,代码无任何改动,直接运行,输出结果。

额。。。。这不是风格转换后的结果图。
⭐️ 风格迁移基本原理
风格迁移是一种计算机视觉领域的图像处理技术,它的目标是将一张图像的内容与另一张图像的艺术风格相结合,创造出一张新的图像。这一技术通过深度学习的方法,结合卷积神经网络(CNN)和损失函数,实现了在内容和风格之间进行有效迁移。

下面详细探讨风格迁移的原理:
1. 内容表示:
内容图像: 风格迁移的源,提供图像的内容信息。
内容表示: 使用预训练的卷积神经网络,通常选择网络中的某一层,提取内容图像的特征表示。
2. 风格表示:
风格图像: 风格迁移的目标,提供所需的艺术风格。
风格表示: 同样使用卷积神经网络,选择多个层次的特征表示,以捕捉图像的不同尺度和层次的艺术风格。

5. 优化过程:
通过调整生成图像的像素值,以最小化总体损失函数,来生成最终的风格迁移图像。这通常通过梯度下降等优化算法来实现。

代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms
from PIL import Image
import numpy as np# 加载预训练的VGG模型
def load_vgg_model():vgg = models.vgg19(pretrained=True).featuresfor param in vgg.parameters():param.requires_grad_(False)return vgg# 图像预处理
def load_image(image_path, transform=None, max_size=None, shape=None):image = Image.open(image_path).convert('RGB')if max_size:scale = max_size / max(image.size)size = tuple(int(x * scale) for x in image.size)image = image.resize(size)if shape:image = image.resize(shape)if transform:image = transform(image).unsqueeze(0)return image# 图像后处理
def convert_image(tensor):image = tensor.to("cpu").clone().detach()image = image.numpy().squeeze()image = image.transpose(1,2,0)image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))image = image.clip(0, 1)return image# 定义风格迁移网络
class StyleTransferNet(nn.Module):def __init__(self, content_layers, style_layers):super(StyleTransferNet, self).__init__()self.vgg = load_vgg_model()self.content_layers = content_layersself.style_layers = style_layersdef forward(self, x):content_outputs = []style_outputs = []for i, layer in enumerate(self.vgg):x = layer(x)if i in self.content_layers:content_outputs.append(x)if i in self.style_layers:style_outputs.append(x)return content_outputs, style_outputs# 损失函数
def content_loss(target, generated):return torch.mean((target - generated)**2)def gram_matrix(tensor):_, d, h, w = tensor.size()tensor = tensor.view(d, h * w)gram = torch.mm(tensor, tensor.t())return gramdef style_loss(target, generated):target_gram = gram_matrix(target)generated_gram = gram_matrix(generated)return torch.mean((target_gram - generated_gram)**2)def total_variation_loss(image):return torch.sum(torch.abs(image[:, :, :, :-1] - image[:, :, :, 1:])) + \torch.sum(torch.abs(image[:, :, :-1, :] - image[:, :, 1:, :]))# 风格迁移主函数
def style_transfer(content_path, style_path, output_path, num_steps=10000, content_weight=1, style_weight=1e6, tv_weight=1e-6):device = torch.device("cuda" if torch.cuda.is_available() else "cpu")content_image = load_image(content_path, transform, max_size=400)style_image = load_image(style_path, transform, shape=[content_image.size(2), content_image.size(3)])content_image = content_image.to(device)style_image = style_image.to(device)model = StyleTransferNet(content_layers, style_layers).to(device).eval()# 优化器optimizer = optim.Adam([content_image.requires_grad_(), style_image.requires_grad_()], lr=0.01)for step in range(num_steps):optimizer.zero_grad()content_outputs, style_outputs = model(content_image)content_loss_value = 0for target, generated in zip(content_outputs, model(content_image)[0]):content_loss_value += content_loss(target, generated)style_loss_value = 0for target, generated in zip(style_outputs, model(style_image)[1]):style_loss_value += style_loss(target, generated)tv_loss_value = total_variation_loss(content_image)total_loss = content_weight * content_loss_value + style_weight * style_loss_value + tv_weight * tv_loss_valuetotal_loss.backward()optimizer.step()if step % 50 == 0 or step == num_steps - 1:print(f"Step {step}/{num_steps}, Total Loss: {total_loss.item()}")# 保存生成的图像output_image = convert_image(content_image)Image.fromarray((output_image * 255).astype(np.uint8)).save(output_path)# 主程序
content_image_path = "./content.jpg"
style_image_path = "./style.jpg"
output_image_path = "./image.jpg"transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])content_layers = [21]
style_layers = [0, 5, 10, 19, 28]style_transfer(content_image_path, style_image_path, output_image_path)输入的图片是这两张


输出的图片是这样(运行了10000轮):

风格是有了,调整一些参数,结果会有不同。
风格迁移技术的核心思想是通过深度学习网络将图像的内容和风格进行数学建模,然后通过优化损失函数来生成具有目标风格的图像。这使得艺术风格的迁移成为可能,为图像处理领域带来了新的可能性。
笔者水平有限,若有不对的地方欢迎评论指正!
相关文章:
完全让ChatGPT写一个风格迁移的例子,不改动任何代码
⭐️ 前言 小编让ChatGPT写一个风格迁移的例子,注意注意,代码无任何改动,直接运行,输出结果。 额。。。。这不是风格转换后的结果图。 ⭐️ 风格迁移基本原理 风格迁移是一种计算机视觉领域的图像处理技术,它的目标…...

查看jar包编译的jdk版本
解压jar包 jar xf xxx.jar 查看对象 javap -v Myclassname javap -v KafkaProducer.class |grep version -C 3 J2SE 8.0 52(0x33 hex) J2SE 7.0 51(0x32 hex) J2SE 6.0 50 (0x32 hex) J2SE 5.0 49 (0x31 hex) JDK 1.4 48 (0x30 hex) JDK 1.3 47 (0x2F hex) JDK 1.2 46 …...

未来之梦:畅想人工智能操控手机的辉煌时代
引言: 在当今数字化快速发展的时代,人工智能技术正日益深入我们的生活。其中,手机作为人们日常生活不可或缺的一部分,其未来将如何受到人工智能技术的影响,引发了广泛的关注和研究。本文将深入探讨人工智能操控手机的…...
产品经理--分享在项目中产品与研发之间会遇到的问题 在面试这一岗位时,面试官常问的问题之一,且分享两大原则来回答面试官这一问题
目录 一.STAR原则 1.1 简介 1.2 如何使用 1.3 举例说明 二.PDCA原则 2.1 简介 2.2 如何使用 2.3 运用场景 2.4 举例说明 三.产品与研发的沟通痛点 3.1 沟通痛点的原因 3.2 分享案例 前言 本篇会详细阐明作为一个产品经理会在项目遇到的问题,如:产…...

node环境打包js,webpack和rollup两个打包工具打包,能支持vue
引言 项目中经常用到共用的js,这里就需要用到共用js打包,这篇文章讲解两种打包方式,webpack打包和rollup打包两种方式 1、webpack打包js 1.1 在根目录创建 webpack.config.js,配置如下 const path require(path); module.expo…...
)
图数据库 之 Neo4j - 图数据库基础(2)
图数据库是一种专门用于存储、管理和查询图数据的数据库。与传统的关系型数据库不同,图数据库以图的形式存储数据,其中节点表示实体,边表示实体之间的关系。这种图数据模型非常适合表示复杂的关系和连接。 图数据库的定义和特点 图数据库是一…...
20240202在Ubuntu20.04.6下配置环境变量之后让nvcc --version显示正常
20240202在Ubuntu20.04.6下配置环境变量之后让nvcc --version显示正常 2024/2/2 20:19 在Ubuntu20.04.6下编译whiper.cpp的显卡模式的时候,报告nvcc异常了! 百度:nvcc -v nvidia-cuda-toolkit rootrootrootroot-X99-Turbo:~/whisper.cpp$ WH…...

数字孪生网络攻防模拟与城市安全演练
在数字化浪潮的推动下,网络攻防模拟和城市安全演练成为维护社会稳定的不可或缺的环节。基于数字孪生技术我们能够在虚拟环境中进行高度真实的网络攻防模拟,为安全专业人员提供实战经验,从而提升应对网络威胁的能力。同时,在城市安…...
【简单,动态规划或递归】)
LeetCode、62.不同路径的数目(一)【简单,动态规划或递归】
文章目录 前言LeetCode、62.不同路径的数目(一)【简单,动态规划或递归】题目描述与分类思路思路1:动态规划思路2:递归实现简洁写法补充:2024.1.30 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、…...

re:从0开始的CSS学习之路 4. 长度单位
1. 长度单位 像素px:一个像素就是屏幕中一个不可分割的点。我们应用的屏幕实际上是由一个个的像素点构成的。 不同显示器的像素点大小也不同,在屏幕尺寸相同的情况下,像素越小,显示效果越清晰。 大部分浏览器默认字体大小是16px …...

golang开源定时任务调度框架
golang开源定时任务调度框架 Go语言中有很多开源的定时任务调度框架,以下几个是比较流行常用的: golang开源定时任务框架介绍 cron 一个基于Cron表达式的定时任务库,可以精确到秒级。它提供了简单易用的API来定义和管理定时任务ÿ…...

GridModel事件集合——yonBIP低代码
我们接着看表格相关的事件,用友的文档打不开,真的是天大的404,客观请看这个开发文档网址,找不到了,你说holy 不咯?http://tinper.org/mdf/(如果有哪位小伙伴知道这个地址是不是迁移了的话&#…...
苹果macbook电脑删除数据恢复该怎么做?Mac电脑误删文件的恢复方法
苹果电脑删除数据恢复该怎么做?Mac电脑误删文件的恢复方法 如何在Mac上恢复误删除的文件?在日常使用Mac电脑时,无论是工作还是娱乐,我们都会创建和处理大量的文件。然而,有时候可能会不小心删除一些重要的文件&#x…...

2024年R2移动式压力容器充装证模拟考试题库及R2移动式压力容器充装理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年R2移动式压力容器充装证模拟考试题库及R2移动式压力容器充装理论考试试题是由安全生产模拟考试一点通提供,R2移动式压力容器充装证模拟考试题库是根据R2移动式压力容器充装最新版教材,R2…...
云开发超多功能工具箱组合微信小程序源码/附带流量主
这是一款云开发超多功能工具箱组合微信小程序源码附带流量主功能,小程序内包含了40余个功能,堪称全能工具箱了,大致功能如下: 证件照制作 | 垃圾分类查询 | 个性签名制作 二维码生成丨文字九宫格 | 手持弹幕丨照片压缩 | 照片编…...

挑战杯 python+深度学习+opencv实现植物识别算法系统
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习的植物识别算法研究与实现 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:4分工作量:4分创新点:4分 🧿 更多…...
pytest的常用插件和Allure测试报告
pytest常用插件 pytest-html插件 安装: pip install pytest-html -U 用途: 生成html的测试报告 用法: 在.ini配置文件里面添加 addopts --htmlreport.html --self-contained-html 效果: 执行结果中存在html测试报告路…...
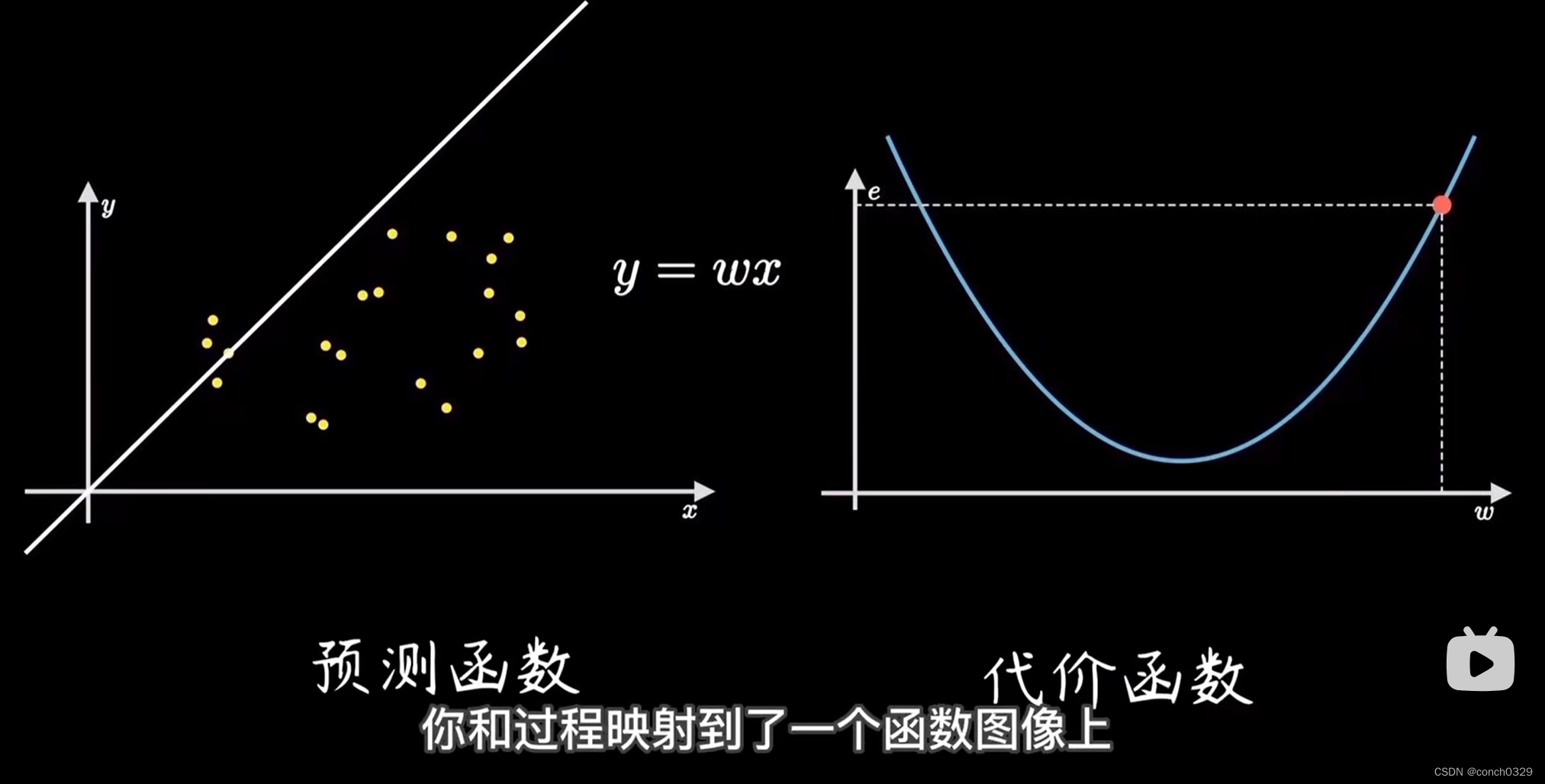
神经网络的权重是什么?
请参考这个视频https://www.bilibili.com/video/BV18P4y1j7uH/?spm_id_from333.788&vd_source1a3cc412e515de9bdf104d2101ecc26a左边是拟合的函数,右边是均方和误差,也就是把左边的拟合函数隐射到了右边,右边是真实值与预测值之间的均方…...

C语言代码 在屏幕上输出9*9乘法口诀表
在屏幕上输出9*9乘法口诀表。 代码示例: #include <stdio.h>int main() {int i 0;for (i 1; i < 9; i)//打印所有行的循环{int j 0;for (j 1; j < i; j)//打印每一行中所有列的循环{printf("%d*%d%-2d ", i, j, i * j);//%-2d的意思是两…...
11.0 Zookeeper watcher 事件机制原理剖析
zookeeper 的 watcher 机制,可以分为四个过程: 客户端注册 watcher。服务端处理 watcher。服务端触发 watcher 事件。客户端回调 watcher。 其中客户端注册 watcher 有三种方式,调用客户端 API 可以分别通过 getData、exists、getChildren …...

MCP Jenkins Intelligence:基于AI的Jenkins智能运维与效率提升实践
1. 项目概述:当Jenkins遇上AI,DevOps的“副驾驶”来了如果你和我一样,每天都要和Jenkins打交道,盯着那些流水线看构建状态、查失败日志、分析性能瓶颈,那你肯定也幻想过:要是能像聊天一样问它问题就好了。比…...

大模型微调实战:用百元级GPU打造专属AI助手
测试工程师的AI困局与破局在软件测试领域,我们每天都在与各种文本打交道——测试用例、缺陷报告、自动化脚本、需求文档、评审记录。大语言模型(LLM)的爆发让我们看到了提效的曙光,但很快就会发现,通用模型对测试业务的…...

抖音去水印免费版哪个好用?2026实测推荐与软件对比
抖音去水印免费版哪个好用?2026实测推荐与软件对比 刷到一条有意思的视频想保存下来发给朋友,下载后却发现左上角顶着一串"用户名"水印;好不容易找到一段适合做素材的内容,画面边缘那行字怎么裁都裁不干净。这几乎是每个…...

Node.js 与前端 JavaScript 的区别:不止运行环境,底层完全不一样
很多开发者误以为 Node.js 和浏览器 JavaScript 只是运行地方不同、语法一样,实际二者虽共用 ECMAScript 语法规范,但在全局对象、API 能力、DOM/BOM、模块系统、事件循环、系统权限、应用场景等方面存在本质差异。本文从技术底层全面对比,帮…...

Marchand Balun设计原理与IE3D电磁仿真实践
1. Marchand Balun设计基础与电磁仿真原理在射频和微波电路设计中,平衡-不平衡转换器(Balun)是实现单端信号与差分信号相互转换的关键无源器件。作为从业15年的射频工程师,我经常需要在各类高频电路中使用Balun结构,而…...

从德雷科风暴看关键通信网络备用电源失效与韧性加固策略
1. 从一场风暴看关键通信网络的脆弱性2012年6月底,一场被称为“德雷科”的强对流风暴席卷了美国中西部,其影响一直延伸到东海岸。这场风暴带来的不仅仅是狂风和暴雨,更是一次对现代基础设施,特别是关键通信网络的极端压力测试。风…...

【场景生成与研究】考虑时序相关性MC的场景生成与削减研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

解锁iPad生产力:一文详解连接Windows作副屏的实用方案
1. 为什么需要把iPad变成Windows副屏? 作为一名常年奔波在客户现场的技术顾问,我的背包里永远装着三样东西:Windows笔记本、iPad和充电宝。有次在高铁上赶方案,盯着13寸的笔记本屏幕同时开PS修图、写文档和查资料,差点…...

AI智能体自动化部署:Agent Factory 两分钟构建专家级AI助手
1. 项目概述:Agent Factory 是什么? 如果你和我一样,对AI智能体(AI Agent)的潜力感到兴奋,但又对部署一个功能完整、面向公众的专家级Agent感到头疼——需要配置身份、记忆、知识库、Web界面,还…...
)
拒绝纸上谈兵!深度拆解 hello-agents:从零开始构建你的第一个智能体 (AI Agent)
发布日期: 2026-02-10标签: #AIAgent #智能体 #Datawhale #大模型 #Python #人工智能入门一、 引言如果说 2024 年是大模型的元年,那么 2026 年则是 AI Agent(智能体) 的应用爆发年。单纯的对话已经无法满足需求&#…...