【Java万花筒】图数据库 vs 多模型数据库:哪种数据库适合你的应用场景?
解密图数据库与多模型数据库:特性、查询语言和成功案例的全景展示
前言
图数据库和多模型数据库在当今数据处理领域扮演着重要的角色。本文将介绍四个主要的图数据库和多模型数据库:Neo4j、Apache TinkerPop、JGraphT和ArangoDB,探索它们的特点、查询语言以及适用的应用场景。
欢迎订阅专栏:Java万花筒
文章目录
- 解密图数据库与多模型数据库:特性、查询语言和成功案例的全景展示
- 前言
- 1. Neo4j(图数据库)
- 1.1 特点与优势
- 1.2 数据模型与存储结构
- 1.2.1 图节点(Node)
- 1.2.2 图关系(Relationship)
- 1.3 查询语言与API
- 1.3.1 Cypher 查询语言
- 1.3.2 Java API
- 1.4 应用场景与案例
- 2. Apache TinkerPop(图处理框架)
- 2.1 概述与背景
- 2.2 图处理模型
- 2.2.1 图遍历(Traversal)
- 2.3 Gremlin 语言
- 2.3.1 Gremlin 查询语言
- 2.3.2 Gremlin 语言特性
- 2.4 应用场景与案例
- 3. JGraphT(图理论库)
- 3.1 库概述
- 3.2 图模型与数据结构
- 3.2.1 有向图(Directed Graph)
- 3.2.2 无向图(Undirected Graph)
- 3.3 图算法与操作
- 3.3.1 最短路径算法
- 3.3.2 最小生成树算法
- 3.4 图可视化与扩展
- 3.4.1 图可视化工具
- 3.4.2 JGraphT 扩展模块
- 4. ArangoDB(多模型数据库)
- 4.1 多模型数据库概述
- 4.2 数据模型与查询语言
- 4.2.1 文档型数据模型
- 4.2.2 图型数据模型
- 4.2.3 键-值型数据模型
- 4.3 多模型数据操作与API
- 4.3.1 AQL 查询语言
- 4.3.2 Java API
- 4.4 应用场景与案例
- 总结
1. Neo4j(图数据库)
1.1 特点与优势
Neo4j是一种流行的图数据库,具有以下特点和优势:
- 高性能:Neo4j通过使用原生图存储和查询模型,实现了高效的图操作和查询。
- 灵活的数据模型:Neo4j的数据模型是基于节点和关系的图结构,可以轻松表示复杂的关系和连接。
- 高度可扩展:Neo4j支持水平扩展,可以处理大规模的图数据。
- 冗余数据消除:Neo4j使用索引和数据压缩技术来减少冗余数据,提高存储效率。
- ACID事务支持:Neo4j支持ACID(原子性、一致性、隔离性和持久性)事务,确保数据一致性和完整性。
1.2 数据模型与存储结构
Neo4j的数据模型是基于节点和关系的图结构。
1.2.1 图节点(Node)
图节点是数据的基本单元,可以存储属性和标签。节点通过唯一的标识符(ID)进行引用,可以通过属性进行查询。
import org.neo4j.driver.*;
import static org.neo4j.driver.Values.parameters;public class Neo4jNodeExample {public static void main(String[] args) {try (Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "password"))) {try (Session session = driver.session()) {session.run("CREATE (n:Person {name: $name, age: $age})", parameters("name", "John", "age", 30));session.run("CREATE (n:Person {name: $name, age: $age})", parameters("name", "Alice", "age", 25));}}}
}
1.2.2 图关系(Relationship)
图关系用于表示节点之间的连接和关系。关系具有类型、方向和属性,并且可以具有唯一的标识符。关系可以通过节点和属性进行查询。
import org.neo4j.driver.*;
import static org.neo4j.driver.Values.parameters;public class Neo4jRelationshipExample {public static void main(String[] args) {try (Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "password"))) {try (Session session = driver.session()) {session.run("MATCH (a:Person), (b:Person) WHERE a.name = $name1 AND b.name = $name2 " +"CREATE (a)-[r:KNOWS {since: $year}]->(b)", parameters("name1", "John", "name2", "Alice", "year", 2020));}}}
}
1.3 查询语言与API
Neo4j提供了Cypher查询语言和Java API来进行图数据库的查询和操作。
1.3.1 Cypher 查询语言
Cypher是Neo4j的查询语言,用于在图数据库中执行查询和操作。
import org.neo4j.driver.*;
import static org.neo4j.driver.Values.parameters;public class Neo4jCypherExample {public static void main(String[] args) {try (Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "password"))) {try (Session session = driver.session()) {StatementResult result = session.run("MATCH (n:Person) WHERE n.age > $age RETURN n.name", parameters("age", 25));while (result.hasNext()) {Record record = result.next();System.out.println(record.get("n.name").asString());}}}}
}
1.3.2 Java API
Neo4j还提供了完整的Java API,使开发人员可以使用Java编程语言访问和操纵图数据库。
import org.neo4j.driver.*;
import static org.neo4j.driver.Values.parameters;public class Neo4jJavaAPIExample {public static void main(String[] args) {try (Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "password"))) {try (Session session = driver.session()) {Transaction transaction = session.beginTransaction();transaction.run("CREATE (n:Person {name: $name, age: $age})", parameters("name", "John", "age", 30));transaction.run("CREATE (n:Person {name: $name, age: $age})", parameters("name", "Alice", "age", 25));transaction.commit();}}}
}
1.4 应用场景与案例
Neo4j广泛应用于各种领域的图数据管理,例如:
- 社交网络分析:通过表示用户、朋友关系和兴趣等关系,进行社交网络分析和推荐系统。
- 知识图谱:构建和查询关于实体和关系的图谱,用于语义搜索和知识图谱的构建。
- 身份和访问管理:使用图数据库来处理和查询用户、组织和权限之间的关系,实现高效的身份和访问管理系统。
2. Apache TinkerPop(图处理框架)
2.1 概述与背景
Apache TinkerPop是一个开源的图计算框架,旨在统一不同图数据库的查询和操作接口。它提供了一种通用的图处理模型和查询语言,称为Gremlin。
2.2 图处理模型
TinkerPop的图处理模型基于图遍历,可以通过一系列步骤来遍历和查询图中的节点和关系。遍历可以定义复杂的图查询逻辑。
2.2.1 图遍历(Traversal)
图遍历是指从图中的一个或多个起始节点出发,按照一定的规则遍历图中的节点和关系。TinkerPop使用Gremlin遍历语言来定义图遍历。
import org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversalSource;
import org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversal;
import org.apache.tinkerpop.gremlin.structure.Vertex;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerGraph;public class TinkerPopTraversalExample {public static void main(String[] args) {TinkerGraph graph = TinkerGraph.open();GraphTraversalSource g = graph.traversal();g.addV("person").property("name", "John").property("age", 30).next();g.addV("person").property("name", "Alice").property("age", 25).next();GraphTraversal<Vertex, String> traversal = g.V().has("age", P.gt(25)).values("name");while (traversal.hasNext()) {System.out.println(traversal.next());}}
}
2.3 Gremlin 语言
2.3.1 Gremlin 查询语言
Gremlin是TinkerPop的查询语言,用于在不同的图数据库上执行通用的图查询操作。它具有类似SQL的语法,支持复杂的图查询和数据操作。
2.3.2 Gremlin 语言特性
Gremlin具有许多强大的特性,例如条件过滤、遍历步骤、聚合操作和图形操作。它还提供了丰富的内置函数和操作符来处理图数据。
import org.apache.tinkerpop.gremlin.structure.Graph;
import org.apache.tinkerpop.gremlin.structure.T;
import org.apache.tinkerpop.gremlin.structure.Vertex;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerGraph;
import static org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.*;public class GremlinLanguageExample {public static void main(String[] args) {Graph graph = TinkerGraph.open();Vertex john = graph.addVertex(T.label, "person", "name", "John", "age", 30).next();Vertex alice = graph.addVertex(T.label, "person", "name", "Alice", "age", 25).next();graph.traversal().V().has("age", P.gt(25)).values("name").forEachRemaining(System.out::println);}
}
2.4 应用场景与案例
Apache TinkerPop广泛应用于以下领域:
- 图分析和挖掘:使用TinkerPop进行复杂的图分析和挖掘任务,如社区检测、路径分析和影响力分析。
- 图数据库中间件:作为图数据库中间件,提供统一的查询接口和图处理能力,使不同的图数据库可以互操作。
- 大数据图处理:与大数据处理框架(如Apache Spark和Apache Flink)集成,进行大规模图处理和分布式图计算。
以上是关于图数据库和图处理库的简介和示例代码。希望对您有帮助!如果您有任何问题,请随时提问。
3. JGraphT(图理论库)
3.1 库概述
JGraphT是一个开源的Java图理论库,用于表示和操作各种类型的图。它提供了丰富的图模型、图算法和图操作,使开发人员能够使用图理论进行复杂的图分析和处理。
3.2 图模型与数据结构
JGraphT支持多种图模型和数据结构,包括有向图和无向图。
3.2.1 有向图(Directed Graph)
有向图是一种图模型,其中每条边都有一个方向。有向图中的边称为有向边,表示从一个顶点指向另一个顶点的方向。
import org.jgrapht.Graph;
import org.jgrapht.graph.DefaultDirectedGraph;
import org.jgrapht.graph.DefaultEdge;public class JGraphTDirectedGraphExample {public static void main(String[] args) {Graph<String, DefaultEdge> directedGraph = new DefaultDirectedGraph<>(DefaultEdge.class);directedGraph.addVertex("A");directedGraph.addVertex("B");directedGraph.addVertex("C");directedGraph.addEdge("A", "B");directedGraph.addEdge("B", "C");directedGraph.addEdge("C", "A");}
}
3.2.2 无向图(Undirected Graph)
无向图是一种图模型,其中边没有方向。无向图中的边可以双向连接两个顶点。
import org.jgrapht.Graph;
import org.jgrapht.graph.DefaultUndirectedGraph;
import org.jgrapht.graph.DefaultEdge;public class JGraphTUndirectedGraphExample {public static void main(String[] args) {Graph<String, DefaultEdge> undirectedGraph = new DefaultUndirectedGraph<>(DefaultEdge.class);undirectedGraph.addVertex("A");undirectedGraph.addVertex("B");undirectedGraph.addVertex("C");undirectedGraph.addEdge("A", "B");undirectedGraph.addEdge("B", "C");undirectedGraph.addEdge("C", "A");}
}
3.3 图算法与操作
JGraphT提供了许多常用的图算法和操作,使开发人员能够对图进行复杂的分析和操作。
3.3.1 最短路径算法
JGraphT提供了多种最短路径算法,如Dijkstra算法和Floyd-Warshall算法,用于在图中查找两个顶点之间的最短路径。
import org.jgrapht.Graph;
import org.jgrapht.alg.shortestpath.DijkstraShortestPath;
import org.jgrapht.graph.DefaultDirectedGraph;
import org.jgrapht.graph.DefaultEdge;public class JGraphTShortestPathExample {public static void main(String[] args) {Graph<String, DefaultEdge> directedGraph = new DefaultDirectedGraph<>(DefaultEdge.class);directedGraph.addVertex("A");directedGraph.addVertex("B");directedGraph.addVertex("C");directedGraph.addEdge("A", "B");directedGraph.addEdge("B", "C");directedGraph.addEdge("C", "A");DijkstraShortestPath<String, DefaultEdge> shortestPath = new DijkstraShortestPath<>(directedGraph);double distance = shortestPath.getPathWeight("A", "C");}
}
3.3.2 最小生成树算法
JGraphT提供了多种最小生成树算法,如Prim算法和Kruskal算法,用于在图中查找生成树。
import org.jgrapht.Graph;
import org.jgrapht.alg.spanning.PrimMinimumSpanningTree;
import org.jgrapht.graph.DefaultUndirectedGraph;
import org.jgrapht.graph.DefaultEdge;public class JGraphTMinimumSpanningTreeExample {public static void main(String[] args) {Graph<String, DefaultEdge> undirectedGraph = new DefaultUndirectedGraph<>(DefaultEdge.class);undirectedGraph.addVertex("A");undirectedGraph.addVertex("B");undirectedGraph.addVertex("C```javaGraph<String, DefaultEdge> undirectedGraph = new DefaultUndirectedGraph<>(DefaultEdge.class);undirectedGraph.addVertex("A");undirectedGraph.addVertex("B");undirectedGraph.addVertex("C");undirectedGraph.addEdge("A", "B");undirectedGraph.addEdge("B", "C");undirectedGraph.addEdge("C", "A");PrimMinimumSpanningTree<String, DefaultEdge> mst = new PrimMinimumSpanningTree<>(undirectedGraph);SpanningTree<DefaultEdge> spanningTree = mst.getSpanningTree();double weight = spanningTree.getTotalWeight();}
}
3.4 图可视化与扩展
3.4.1 图可视化工具
JGraphT本身并不提供图可视化功能,但可以与其他图可视化工具集成,如JUNG、GraphStream和yFiles。
3.4.2 JGraphT 扩展模块
JGraphT还提供了一些扩展模块,如jgrapht-ext模块,它包含了一些额外的图算法和数据结构,如流网络算法、最大流算法和图的拓扑排序算法。
<dependency><groupId>org.jgrapht</groupId><artifactId>jgrapht-ext</artifactId><version>1.5.1</version>
</dependency>
4. ArangoDB(多模型数据库)
4.1 多模型数据库概述
ArangoDB是一个多模型数据库,可以存储和查询多种类型的数据模型,包括文档型、图型和键-值型数据模型。它提供了一个统一的查询语言和API,使开发人员能够灵活地处理不同类型的数据。
4.2 数据模型与查询语言
ArangoDB支持多种数据模型,包括文档型、图型和键-值型数据模型。每种数据模型都有自己的查询语言和操作。
4.2.1 文档型数据模型
文档型数据模型是一种基于文档的数据模型,数据以文档的形式存储,并使用类似JSON的格式表示。ArangoDB使用AQL(ArangoDB Query Language)作为文档型数据模型的查询语言。
4.2.2 图型数据模型
图型数据模型是一种用于表示实体和它们之间关系的数据模型。ArangoDB使用AQL和图查询语言(Gharial)来查询和操作图数据。
4.2.3 键-值型数据模型
键-值型数据模型是一种简单的键值对存储模型,每个数据项由一个唯一的键和对应的值组成。ArangoDB提供了键-值型数据存储引擎,并使用AQL进行查询操作。
4.3 多模型数据操作与API
ArangoDB提供了多种API来操作多模型数据,包括AQL查询语言和Java API。
4.3.1 AQL 查询语言
AQL是ArangoDB的查询语言,用于在多模型数据上执行查询和操作。它支持文档型数据和图数据的查询,提供了丰富的查询语法和操作符。
4.3.2 Java API
ArangoDB还提供了Java API,用于在Java应用程序中与ArangoDB进行交互。Java API提供了对多模型数据的CRUD操作和查询功能。
4.4 应用场景与案例
ArangoDB适用于多种应用场景,包括:
- 文档存储和查询:适用于存储和查询具有复杂结构的文档数据,如博客、新闻和社交媒体数据。
- 图分析和图数据库:适用于构建和查询具有复杂关系的图数据,如社交网络、知识图谱和推荐系统。
- 键值存储和缓存:适用于快速存储和检索键值对数据,如用户会话信息和配置数据。
- 分布式应用程序:适用于构建分布式应用程序,通过分片和复制来提供高可用性和可伸缩性。
一些使用ArangoDB的案例包括:
- 阿里巴巴:使用ArangoDB构建大规模的线上图数据库,用于社交网络分析和推荐系统。
- Grindr:使用ArangoDB构建社交网络应用程序的后端,用于存储和查询用户数据和关系。
- ArangoDB自身:ArangoDB使用自己的多模型能力来存储和查询文档、图和键值数据,以提供高性能和灵活性。
ArangoDB是一种多模型数据库,支持文档型、图型和键-值型数据模型。以下是一个使用ArangoDB Java API进行多模型数据操作的示例代码:
import com.arangodb.ArangoDB;
import com.arangodb.ArangoDatabase;
import com.arangodb.entity.CollectionEntity;
import com.arangodb.entity.DocumentCreateEntity;
import com.arangodb.entity.EdgeDefinition;
import com.arangodb.entity.GraphEntity;
import com.arangodb.model.DocumentCreateOptions;
import com.arangodb.model.EdgeCreateOptions;
import com.arangodb.model.GraphCreateOptions;public class ArangoDBExample {public static void main(String[] args) {// 连接到ArangoDB数据库ArangoDB arangoDB = new ArangoDB.Builder().build();// 创建数据库String dbName = "myDatabase";arangoDB.createDatabase(dbName);// 切换到指定数据库ArangoDatabase db = arangoDB.db(dbName);// 创建文档集合String collectionName = "myCollection";CollectionEntity collection = db.createCollection(collectionName);// 插入文档数据DocumentCreateEntity<MyDocument> document = db.collection(collectionName).insertDocument(new MyDocument("1", "John Doe"), new DocumentCreateOptions());// 创建图String graphName = "myGraph";EdgeDefinition edgeDefinition = new EdgeDefinition().collection(collectionName).from("vertexCollection").to("vertexCollection");GraphEntity graph = db.createGraph(graphName, edgeDefinition, new GraphCreateOptions());// 创建顶点DocumentCreateEntity<MyVertex> vertex1 = db.graph(graphName).vertexCollection("vertexCollection").insertVertex(new MyVertex("1", "Alice"));DocumentCreateEntity<MyVertex> vertex2 = db.graph(graphName).vertexCollection("vertexCollection").insertVertex(new MyVertex("2", "Bob"));// 创建边EdgeCreateOptions options = new EdgeCreateOptions().waitForSync(true);db.graph(graphName).edgeCollection(collectionName).insertEdge(new MyEdge("1", vertex1.getId(), vertex2.getId()), options);// 关闭数据库连接arangoDB.shutdown();}
}// 自定义文档类型
class MyDocument {private String id;private String name;// 构造函数、Getter和Setter省略// ...
}// 自定义顶点类型
class MyVertex {private String id;private String name;// 构造函数、Getter和Setter省略// ...
}// 自定义边类型
class MyEdge {private String id;private String from;private String to;// 构造函数、Getter和Setter省略// ...
}
在这个示例代码中,我们将ArangoDB的相关操作嵌入到 ArangoDBExample 类的 main 方法中。这里使用了ArangoDB的Java API来连接到ArangoDB数据库,并进行多模型数据操作。
请注意,你需要根据自己的环境和需求进行适当的配置和调整,例如更改数据库名称、集合名称以及自定义数据类型的属性。确保在运行代码之前,已经正确安装ArangoDB,并导入相应的ArangoDB Java驱动程序。
这个示例代码演示了如何创建ArangoDB数据库、集合、文档和图,以及如何插入和操作数据。根据你的具体需要,你可以根据ArangoDB的API文档进行更多的操作和查询。
总结
本文对Neo4j、Apache TinkerPop、JGraphT和ArangoDB进行了全面的介绍和比较。我们探讨了它们的特点、数据模型、查询语言和API,以及适用的应用场景。无论是需要处理复杂关系数据的图数据库,还是支持多种数据模型的多模型数据库,读者都可以根据自己的需求做出明智的选择。这些数据库在各自的领域中都有广泛的应用,可以帮助开发人员构建高效和灵活的数据处理解决方案。
相关文章:

【Java万花筒】图数据库 vs 多模型数据库:哪种数据库适合你的应用场景?
解密图数据库与多模型数据库:特性、查询语言和成功案例的全景展示 前言 图数据库和多模型数据库在当今数据处理领域扮演着重要的角色。本文将介绍四个主要的图数据库和多模型数据库:Neo4j、Apache TinkerPop、JGraphT和ArangoDB,探索它们的…...
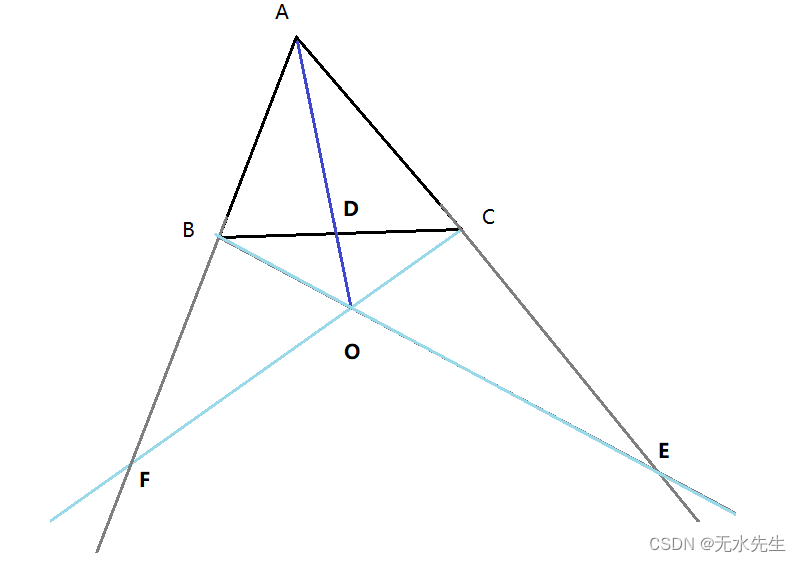
【射影几何13 】梅氏定理和塞瓦定理探讨
梅氏定理和塞瓦定理 目录 一、说明二、梅涅劳斯(Menelaus)定理三、塞瓦(Giovanni Ceva)定理四、塞瓦点的推广 一、说明 在射影几何中,梅涅劳斯(Menelaus)定理和塞瓦定理是非常重要的基本定理。通过这两个定…...

Powershell Install 一键部署Openssl+certificate证书创建
前言 Openssl 是一个方便的实用程序,用于创建自签名证书。您可以在所有操作系统(如 Windows、MAC 和 Linux 版本)上使用 OpenSSL。 Windows openssl 下载 前提条件 开启wmi,配置网卡,参考 自签名证书 创建我们自己的根 CA 证书和 CA 私钥(我们自己充当 CA)创建服务器…...

SERVLET线程模型
1. SERVLET线程模型 Servlet规范定义了两种线程模型来阐明Web容器应该如何在多线程环境中处理servlet。第一种模型称为多线程模型,默认在此模型内执行所有servlet。在此模型中,每次客户机向servlet发送请求时Web容器都启动一个新线程。这意味着可能有多个线程同时访问servle…...

【开源】基于JAVA+Vue+SpringBoot的新能源电池回收系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 用户档案模块2.2 电池品类模块2.3 回收机构模块2.4 电池订单模块2.5 客服咨询模块 三、系统设计3.1 用例设计3.2 业务流程设计3.3 E-R 图设计 四、系统展示五、核心代码5.1 增改电池类型5.2 查询电池品类5.3 查询电池回…...

【蓝桥杯冲冲冲】Prime Gift
【蓝桥杯冲冲冲】Prime Gift 蓝桥杯备赛 | 洛谷做题打卡day31 文章目录 蓝桥杯备赛 | 洛谷做题打卡day31Prime Gift题面翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 提示题解代码我的一些话 Prime Gift 题面翻译 给你 n n n 个…...
【PyQt】06-.ui文件转.py文件
文章目录 前言方法一、基本脚本查看自己的uic安装目录 方法二、添加到扩展工具里面(失败了)方法二的成功步骤总结 前言 方法一、基本脚本 将Qt Designer(一种图形用户界面设计工具)生成的.ui文件转换为Python代码的脚本。 pytho…...

λ-矩阵知识点
原文:链接 λ-矩阵 若矩阵 A \mathbf{A} A 的元素为关于 λ λ λ 的多项式,则称 A \mathbf{A} A 为 λ λ λ-矩阵 (表示为 A ( λ ) \mathbf{A}(λ) A(λ)). λ λ λ-矩阵也存在秩、逆、初等变换、相抵的概念, 但是有一些不同. 定义. λ λ λ-矩阵的秩是…...
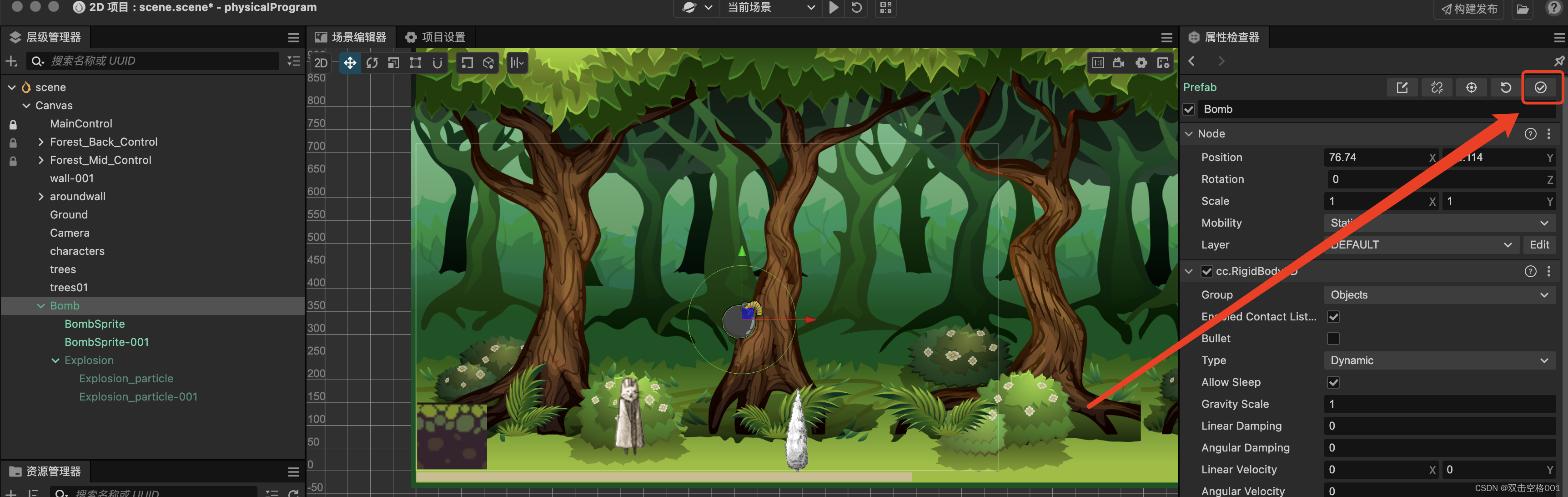
cocos creator 3.x 预制体无法显示
双击预制体,进入详情页,没有显示资源 Bomb 是个预制体,但是当我双击进来什么都没有了,无法对预制体进行可视化编辑 目前我只试出来一个解决方法: 把预制体拖进Canvas文件中,这样就能展示到屏幕上ÿ…...

Tomcat之虚拟主机
1.创建存放网页的目录 mkdir -p /web/{a,b} 2.添加jsp文件 vi /web/a/index.jsp <% page language"java" import"java.util.*" pageEncoding"UTF-8"%> <html> <head><title>JSP a page</title> </head> …...
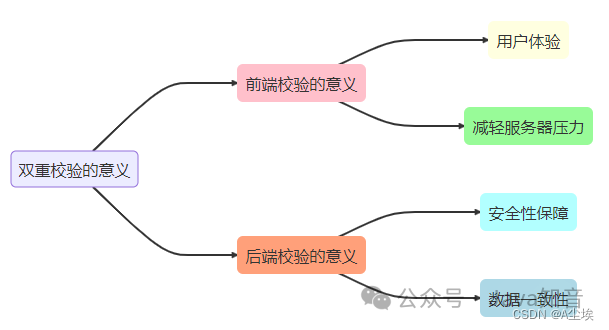
前后端数据校验
前端校验内容 前端开发中的必要校验,可以保证用户输入的数据的准确性、合法性和安全性。同时,这些校验也有助于提供良好的用户体验和防止不必要的错误提交到后端。 1、必填字段校验: 对于必填的字段,需确保用户输入了有效的数据…...

Python把png图片转成jpg图片
在Python中,您可以使用PIL(Python Imaging Library,也被称为Pillow)库来将PNG图片转换为JPG格式。以下是一个简单的示例: 首先,确保你已经安装了Pillow库。如果没有安装,可以使用pip来安装&…...
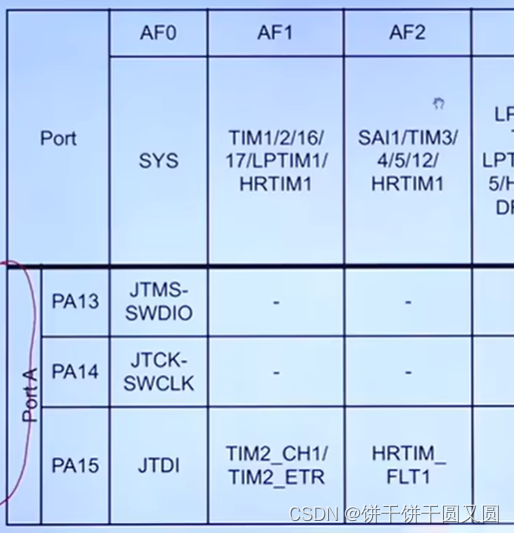
STM32搭建开发环境
常用开发工具简介 集成开发环境 MDK:全名RealViewMDK,是Keil公司(已被ARM收购的)一款集成开发环境,界面美观,简单易用,是STM32最常用的集成开发环境EWARM:IAR公司的一款集成开发环…...
C#入门详解_01_课程简介、C#语言简介、开发环境和学习资料的准备
文章目录 1. 课程简介2. C#语言简介3.开发环境与学习资料 1. 课程简介 开设本课程的目的 传播C#开发的知识,让更多的人有机会接触到软件开发行业引导有兴趣或者想转行的朋友进入软件开发行业 课程内容 完整讲述C#语言在实际软件开发中的应用采用知识讲述加实例程序…...
:确定服务器框架)
C++服务器端开发(2):确定服务器框架
选择C服务器框架时,可以考虑: 并发性能:C的强项之一是其并发性能。选择一个具有高并发处理能力的服务器框架,可以更好地满足大量并发请求的需求。例如,libevent、Boost.Asio和CppServer都是具有良好并发性能的C服务器框…...

CGAL::2D Arrangements-5
5.Arrangement无界曲线 前几章中构建和操作的所有Arrangement都只由线段引起,线段尤其是有界曲线。这样的Arrangement总是具有一个包含所有其他Arrangement特征的unbounded face。在本节中,我们将解释如何构造无界曲线的Arrangement。为了简化说明&…...
登录+JS逆向进阶【过咪咕登录】(附带源码)
JS渗透之咪咕登录 每篇前言:咪咕登录参数对比 captcha参数enpassword参数搜索enpassword参数搜索J_RsaPsd参数setPublic函数encrypt加密函数运行时可能会遇到的问题此部分改写的最终形态JS代码:运行结果python编写脚本运行此JS代码:运行结果&…...

CTF秀 ctfshow WEB入门 web1-10 wp精讲
目录 web1_查看源码 web3_抓包 web4-9_目录文件 web10_cookie web1_查看源码 ctrlu 查看源码 web3_抓包 查看源码,无果 抓包,找到flag web4-9_目录文件 GitHub - maurosoria/dirsearch: Web path scanner 下载dirsearch工具扫一下就都出来了 web4-…...
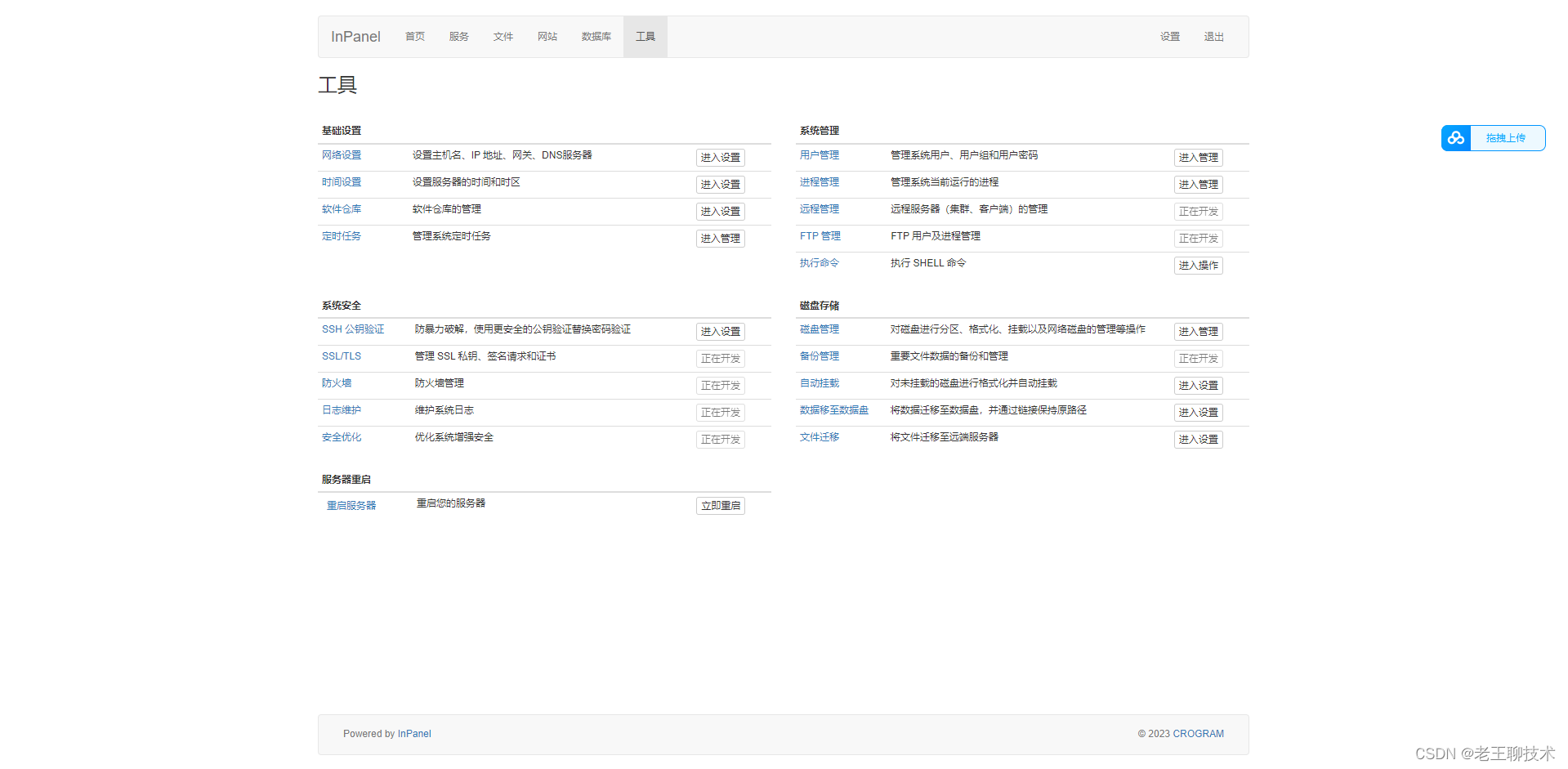
centos安装inpanel
前置条件 安装python yum -y install python 安装 cd /usr/local git clone https://gitee.com/WangZhe168_admin/inpanel.git cd inpanel python install.py 安装过程需要设置账户 密码 端口号 我设置的是admin:admin 10050 使用 打开浏览器,输入 http://192.168.168.…...

聊聊PowerJob Worker的ServerAddress
序 本文主要研究一下PowerJob Worker的ServerAddress PowerJobAutoConfiguration tech/powerjob/worker/autoconfigure/PowerJobAutoConfiguration.java BeanConditionalOnMissingBeanpublic PowerJobSpringWorker initPowerJob(PowerJobProperties properties) {PowerJobPr…...

Webots仿真实战:如何用C语言控制四轮小车实现自动行驶
Webots仿真实战:C语言控制四轮小车自动行驶全攻略 引言 在机器人开发领域,仿真环境的重要性不言而喻。它不仅能大幅降低硬件成本,还能加速开发周期,让开发者专注于算法和控制逻辑的优化。Webots作为一款专业的机器人仿真软件&…...

借助yakit高效构建渗透字典:从历史流量中智能提取关键参数
1. 为什么需要从历史流量中提取渗透字典? 做过渗透测试的朋友都知道,字典的质量直接影响测试效率。传统方式要么用现成的通用字典,要么手动收集整理,前者命中率低,后者耗时费力。我遇到过最头疼的情况是测试一个Web系统…...

java毕业设计基于springboot+vue的电影院座位管理系统
前言 该系统旨在实现电影院座位的高效管理,包括座位预订、售票、座位状态实时监控等功能。通过该系统,电影院可以提高售票效率,优化座位使用率,同时为顾客提供便捷的购票体验。 一、项目介绍 开发语言:Java 框架&…...

2026年AI大爆发:DeepSeek、Claude、Gemini三强鼎立,智能体应用成为新战场
进入2026年,AI领域迎来前所未有的激烈竞争格局。DeepSeek凭借极低的训练成本和开源策略强势出圈,R1模型在推理能力上直追GPT-o1,引发全球AI圈震动;Anthropic的Claude 3.7 Sonnet推出了扩展思考模式,在代码和复杂推理任…...

ComfyUI实战:如何加载基于Flux.1微调的LoRA模型并优化推理流程
最近在项目里用 ComfyUI 部署基于 Flux.1 微调的 LoRA 模型,踩了不少坑。从模型加载失败到推理时显存爆炸,问题层出不穷。经过一番折腾,总算梳理出一套比较稳定的流程,这里把实战经验记录下来,希望能帮到有同样需求的同…...

实战演练,用快马生成GitHub团队协作项目,掌握Issue管理和CI/CD集成
最近在团队协作开发时,发现很多新成员对GitHub的完整工作流不太熟悉。于是我用InsCode(快马)平台快速搭建了一个GitHub实战项目,模拟真实开发场景。这个项目特别适合想系统学习团队协作的小伙伴,下面分享我的实践过程: 项目初始化…...

FFXIV国际服中文补丁解决方案:零基础上手实战指南
FFXIV国际服中文补丁解决方案:零基础上手实战指南 【免费下载链接】FFXIVChnTextPatch 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIVChnTextPatch 你是否曾在《最终幻想XIV》国际服中因语言障碍错失关键剧情?是否因英文界面降低了游戏沉浸…...
)
隔离变送器VS普通变送器:为什么你的PLC信号总受干扰?(实测XYS-5531抗干扰性能)
隔离变送器VS普通变送器:为什么你的PLC信号总受干扰?(实测XYS-5531抗干扰性能) 在工业自动化现场,信号干扰就像潜伏的"隐形杀手"——它不会直接摧毁设备,却能让控制系统频繁误动作、数据采集失真…...

成本控制艺术:OpenClaw+百川2-13B量化版的Token节省技巧
成本控制艺术:OpenClaw百川2-13B量化版的Token节省技巧 1. 为什么需要关注Token消耗? 当我第一次在本地部署OpenClaw并接入百川2-13B量化版模型时,就被它强大的自动化能力震撼了。这个组合可以让我的电脑像真人一样处理各种任务——从整理文…...
)
c++ 短信验证码 API 示例代码(接口开发专用)
在C服务端、嵌入式设备、桌面应用的开发场景中,短信验证码是用户注册、登录、身份校验的必备安全功能。C开发者常面临网络请求封装繁琐、接口参数不规范、调试无标准方案等痛点。本文提供c短信验证码API示例代码,基于原生C实现标准化接口对接,…...