Transformer实战-系列教程11:SwinTransformer 源码解读4(WindowAttention类)
🚩🚩🚩Transformer实战-系列教程总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
点我下载源码
SwinTransformer 算法原理
SwinTransformer 源码解读1(项目配置/SwinTransformer类)
SwinTransformer 源码解读2(PatchEmbed类/BasicLayer类)
SwinTransformer 源码解读3(SwinTransformerBlock类)
SwinTransformer 源码解读4(WindowAttention类)
SwinTransformer 源码解读5(Mlp类/PatchMerging类)
6、WindowAttention类
6.1 构造函数
class WindowAttention(nn.Module):def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_sizeself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))coords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w]))coords_flatten = torch.flatten(coords, 1)relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]relative_coords = relative_coords.permute(1, 2, 0).contiguous()relative_coords[:, :, 0] += self.window_size[0] - 1relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1)self.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)
- dim:输入特征维度
- window_size:窗口大小
- num_heads:多头注意力头数
- head_dim:每头注意力的头数
- scale :缩放因子
- relative_position_bias_table:相对位置偏置表,它对每个头存储不同窗口位置之间的偏置,以模拟位置信息
- coords_h 、coords_w、coords:窗口内每个位置的坐标
- coords_flatten :将坐标展平,为计算相对位置做准备
- 第1个relative_coords:计算窗口内每个位置相对于其他位置的坐标差
- 第2个relative_coords:重排坐标差的维度以符合预期的格式
- relative_coords[:, :, 0]、relative_coords[:, :, 1]、relative_coords[:, :, 0]:调整坐标差,使其能够映射到相对位置偏置表中的索引
- relative_position_index :计算每对位置之间的相对位置索引
- register_buffer:将相对位置索引注册为模型的缓冲区,这样它就不会在训练过程中被更新
- qkv :创建一个线性层,用于生成QKV
- attn_drop、proj、proj_drop:初始化注意力dropout、输出投影层及其dropout
- trunc_normal_:使用截断正态分布初始化相对位置偏置表
- softmax :初始化softmax层,用于计算注意力权重
6.2 前向传播
def forward(self, x, mask=None):B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return x
B_, N, C = x.shape原始输入: torch.Size([256, 49, 96]),B_, N, C即原始输入的维度qkv = self.qkv(x).reshape...qkv: torch.Size([3, 256, 3, 49, 32]),被重塑的一个五维张量,分别代表qkv三个维度、256个窗口、3个注意力头数但是不会一直是3越往后会越多、49是一个窗口有7*7=49元素、每个头的特征维度。在之前的Transformer以及Vision Transformer中,都是用x接上各自的全连接后分别生成QKV,这这里直接一起生成了。- q: torch.Size([256, 3, 49, 32]),k: torch.Size([256, 3, 49, 32]),v: torch.Size([256, 3, 49, 32]),从qkv中分解出q、k、v,而且已经包含了多头注意力机制
- attn: torch.Size([256, 3, 49, 49]),attn是q和k的点积
- relative_position_bias: torch.Size([49, 49, 3]),从相对位置偏置表中索引出每对位置之间的偏置,并重塑以匹配注意力分数的形状
- relative_position_bias: torch.Size([3, 49, 49]),重新排列,位置编码在Transformer中一直当成偏置加进去的,而这个位置编码是对一个窗口的,所以每一个窗口的都对应了相同的位置编码
- attn: torch.Size([256, 3, 49, 49]),将位置编码加到注意力分数上,到这里就算完了全部的注意力机制了
- attn: torch.Size([256, 3, 49, 49]),掩码加到注意力分数上,使用softmax函数归一化注意力分数,得到注意力权重,应用注意力dropout
- x: torch.Size([256, 49, 96]),使用注意力权重对v向量进行重构,然后对结果进行转置和重塑
- x: torch.Size([256, 49, 96]),将加权的注意力输出通过一个线性投影层,应用输出dropout,这就是最后WindowAttention的输出,一共256个窗口,每个窗口有49个特征,每个特征对应96维的向量
SwinTransformer 算法原理
SwinTransformer 源码解读1(项目配置/SwinTransformer类)
SwinTransformer 源码解读2(PatchEmbed类/BasicLayer类)
SwinTransformer 源码解读3(SwinTransformerBlock类)
SwinTransformer 源码解读4(WindowAttention类)
SwinTransformer 源码解读5(Mlp类/PatchMerging类)
相关文章:
Transformer实战-系列教程11:SwinTransformer 源码解读4(WindowAttention类)
🚩🚩🚩Transformer实战-系列教程总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 SwinTransformer 算法原理 SwinTransformer 源码解读1(项目配置/SwinTr…...
Jenkins(本地Windows上搭建)上传 Pipeline构建前端项目并将生成dist文件夹上传至指定服务器
下载安装jdk https://www.oracle.com/cn/java/technologies/downloads/#jdk21-windows 下载jenkins window版 双击安装 https://www.jenkins.io/download/thank-you-downloading-windows-installer-stable/ 网页输入 http://localhost:8088/ 输入密码、设置账号、安装推…...

Elasticsearch 安装和配置脚本文档
Elasticsearch 安装和配置脚本文档 目录 **Elasticsearch 安装和配置脚本文档**0.**概述**1.**使用方法:**2.**脚本步骤:**3. **完整代码如下:** 0.概述 此Bash脚本用于自动化在CentOS 7系统上安装和配置Elasticsearch(ES&#x…...

【Android辟邪】之:gradle——在项目间共享依赖关系版本
翻译和简单修改自:https://docs.gradle.org/current/userguide/platforms.html#sec:sharing-catalogs 建议看原文(有能力的话) 现在 Gradle 脚本可以使用两种语法编写:Kotlin 和 Groovy 本文只使用kotlin脚本语法,更…...

Qt 项目树工程,拷贝子项目dll到子项目exe运行路径
1、项目树工程 2、项目树列表 ---- BuildAll -------- App (exe) -------- Database (dll) 注:使用 子项目–>添加库–>内部库 的方式 3、qmake 内置的变量 $$OUT_PWD 表示输出文件(如可执行文件…...

进程间通信方式
1>内核提供的原始通信方式有三种 1)无名管道 2)有名管道 3)信号 2>System V提供了三种通信方式 4)消息队列 5)共享内存 6)信号量(信号灯集) 3>套接字通信 7)socke…...

[linux]:匿名管道和命名管道(什么是管道,怎么创建管道(函数),匿名管道和命名管道的区别,代码例子)
目录 一、匿名管道 1.什么是管道?什么是匿名管道? 2.怎么创建匿名管道(函数) 3.匿名管道的4种情况 4.匿名管道有5种特性 5.怎么使用匿名管道?匿名管道有什么用?(例子) 二、命名…...
Python调用matlab程序
matlab官网:https://ww2.mathworks.cn/?s_tidgn_logo matlab外部语言和库接口,包括 Python、Java、C、C、.NET 和 Web 服务。 matlab和python的版本 安装依赖配置 安装matlab的engine 找到matlab的安装目录:“xxx\ extern\engines\python…...
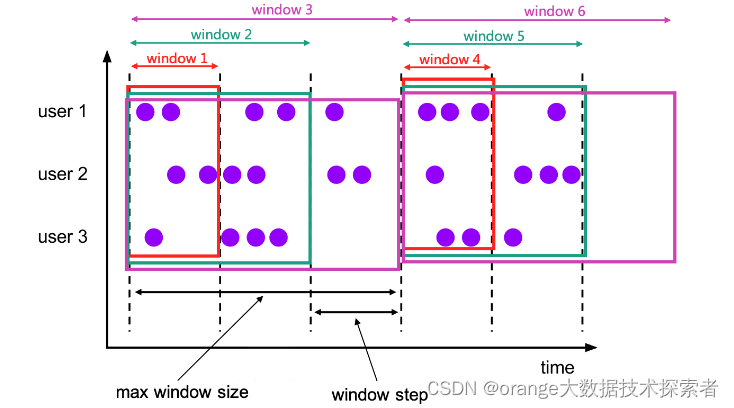
FlinkSql 窗口函数
Windowing TVF 以前用的是Grouped Window Functions(分组窗口函数),但是分组窗口函数只支持窗口聚合 现在FlinkSql统一都是用的是Windowing TVFs(窗口表值函数),Windowing TVFs更符合 SQL 标准且更加强大…...
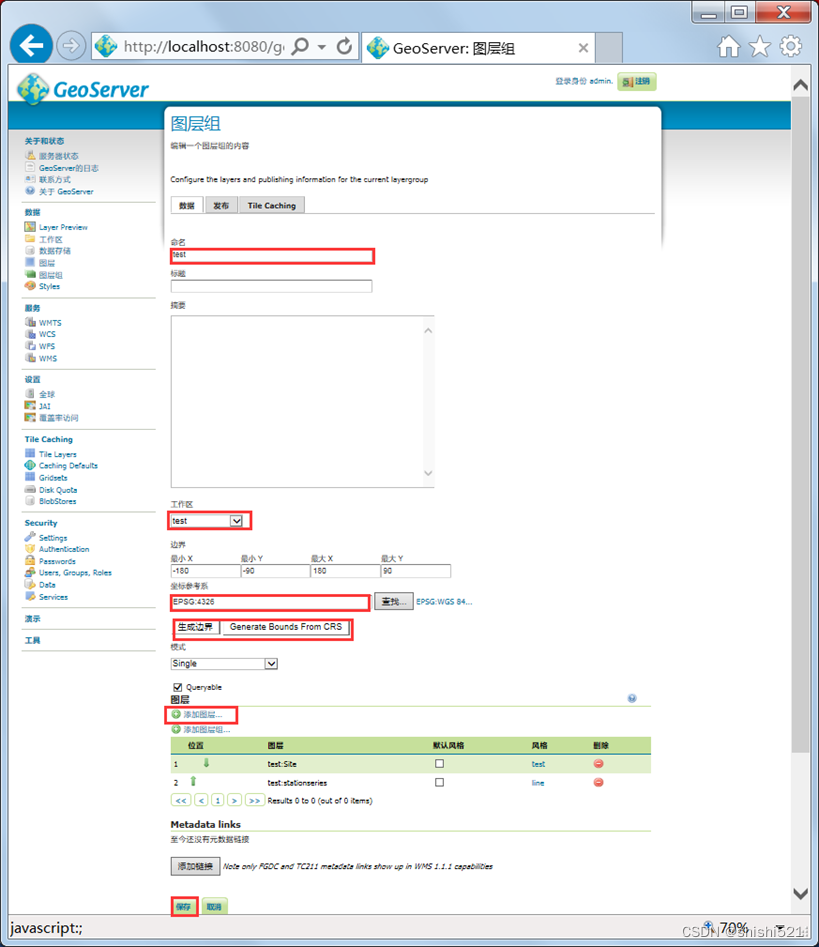
十分钟GIS——geoserver+postgis+udig从零开始发布地图服务
1数据库部署 1.1PostgreSql安装 下载到安装文件后(postgresql-9.2.19-1-windows-x64.exe),双击安装。 指定安装目录,如下图所示 指定数据库文件存放目录位置,如下图所示 指定数据库访问管理员密码,如下图所…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Span组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Span组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、Span组件 鸿蒙(HarmonyOS)作为Text组件的子组件࿰…...
Leetcode—42. 接雨水【困难】
2024每日刷题(112) Leetcode—42. 接雨水 空间复杂度为O(n)的算法思想 实现代码 class Solution { public:int trap(vector<int>& height) {int ans 0;int n height.size();vector<int> l(n);vector<int> r(n);for(int i 0; …...
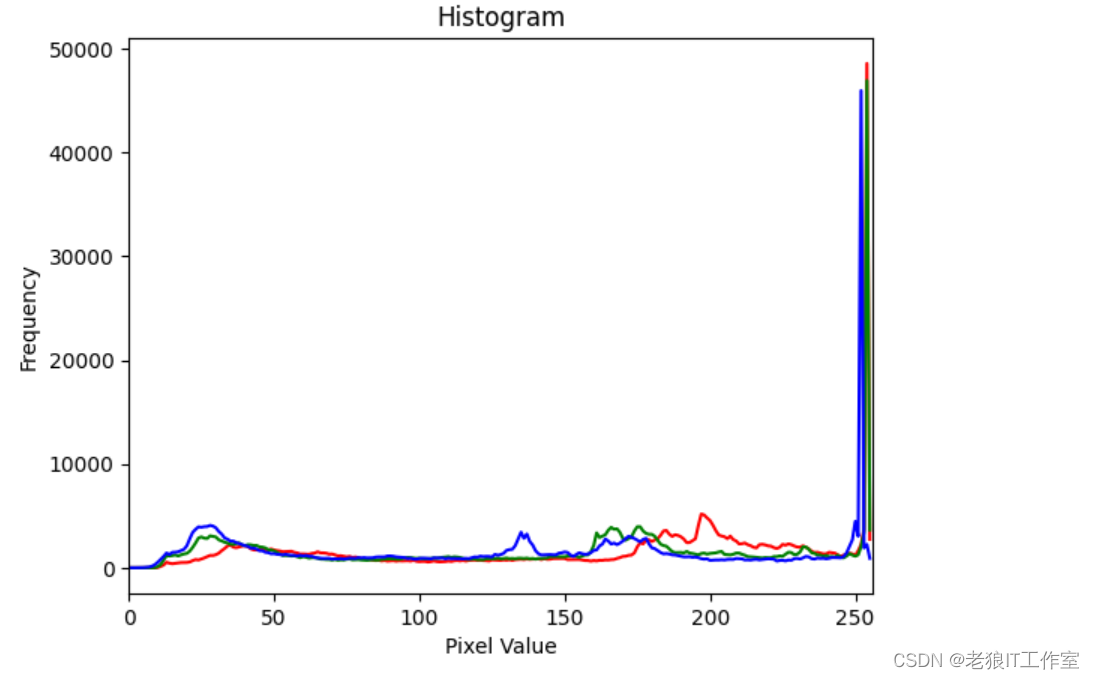
[Python] opencv - 什么是直方图?如何绘制图像的直方图?如何对直方图进行均匀化处理?
什么是直方图? 直方图是一种统计图,用于展示数据的分布情况。它将数据按照一定的区间或者组进行划分,然后计算在每个区间或组内的数据频数或频率(即数据出现的次数或占比),然后用矩形或者柱形图的形式将这…...

ppi rust开发 python调用
创建python的一个测试工程 python -m venv venv .\venv\Scripts\activatepip install cffi创建一个rust的lib项目 cargo new --lib pyrustlib.rs #[no_mangle] pub extern "C" fn rust_add(x: i32, y: i32) -> i32 {x y }Cargo.toml [package] name "p…...
)
网站后端开发 thinkphp6 入门教程合集(更新中)
thinkphp6 入门(1)--安装、路由规则、多应用模式 thinkphp6 入门(1)--安装、路由规则、多应用模式_软件工程小施同学的博客-CSDN博客 thinkphp6 入门(2)--视图、渲染html页面、赋值 thinkphp6 入门&#x…...
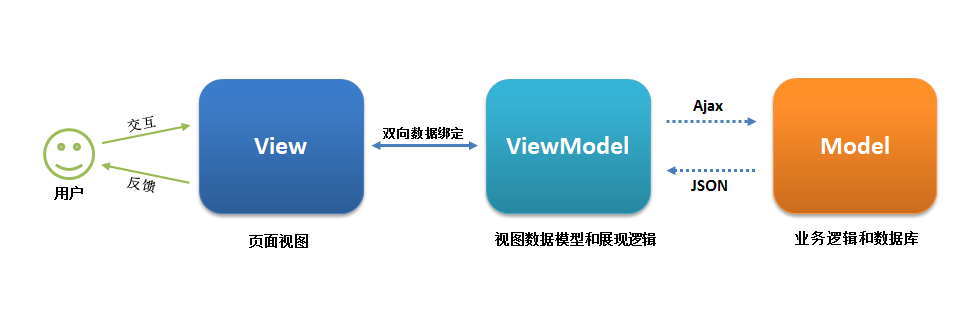
Web前端框架-Vue(初识)
文章目录 web前端三大主流框架**1.Angular****2.React****3.Vue**什么是Vue.js 为什么要学习流行框架框架和库和插件的区别一.简介指令v-cloakv-textv-htmlv-pre**v-once**v-onv-on事件函数中传入参数事件修饰符双向数据绑定v-model 按键修饰符自定义按键修饰符别名v-bind(属性…...
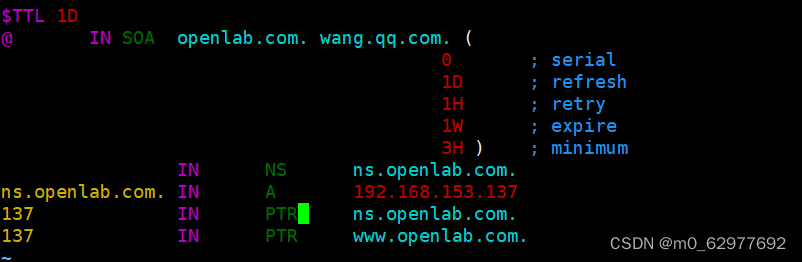
配置dns服务的正反向解析
服务端IP客户端IP网址192.168.153.137192.168.153.www.openlab.com 1:正向解析 1.1关闭客户端和服务端的安全软件,安装bind软件 [rootserver ~]# setenforce 0 [rootserver ~]# systemctl stop firewalld [rootserver ~]# yum install bind -y [rootnod…...

小白水平理解面试经典题目LeetCode 71. Simplify Path【Stack类】
71. 简化路径 小白渣翻译 给定一个字符串 path ,它是 Unix 风格文件系统中文件或目录的绝对路径(以斜杠 ‘/’ 开头),将其转换为简化的规范路径。 在 Unix 风格的文件系统中,句点 ‘.’ 指的是当前目录,…...
电力负荷预测 | 电力系统负荷预测模型(Python线性回归、随机森林、支持向量机、BP神经网络、GRU、LSTM)
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 电力系统负荷预测模型(Python线性回归、随机森林、支持向量机、BP神经网络、GRU、LSTM) 所谓预测,就是指通过对事物进行分析及研究,并运用合理的方法探索事物的发展变化规律,对其未来发展做出预先估计和判断。…...

YY调音台:音频后期处理
我从事影视后期处理的工作,主要负责音频、音效合成这块工作内容。在影视作品中,声音不仅仅是背景元素,它在叙事和创造情感氛围上发挥着至关重要的作用。我们的工作不仅要让听众听到声音,更要让他们通过声音感受到情感的波动和故事…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...