互联网加竞赛 基于深度学的图像修复 图像补全
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学的图像修复 图像补全
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 什么是图像内容填充修复
内容识别填充(译注: Content-aware fill ,是 photoshop
的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。
- 首先我们将图像理解为一个概率分布的样本。
- 基于这种理解,学*如何生成伪图片。
- 然后我们找到最适合填充回去的伪图片。

自动删除不需要的部分(海滩上的人)

最经典的人脸补充
补充前:

补充后:

3 原理分析
3.1 第一步:将图像理解为一个概率分布的样本
你是怎样补全缺失信息的呢?
在上面的例子中,想象你正在构造一个可以填充缺失部分的系统。你会怎么做呢?你觉得人类大脑是怎么做的呢?你使用了什么样的信息呢?
在博文中,我们会关注两种信息:
语境信息:你可以通过周围的像素来推测缺失像素的信息。
感知信息:你会用“正常”的部分来填充,比如你在现实生活中或其它图片上看到的样子。
两者都很重要。没有语境信息,你怎么知道填充哪一个进去?没有感知信息,通过同样的上下文可以生成无数种可能。有些机器学*系统看起来“正常”的图片,人类看起来可能不太正常。
如果有一种确切的、直观的算法,可以捕获前文图像补全步骤介绍中提到的两种属性,那就再好不过了。对于特定的情况,构造这样的算法是可行的。但是没有一般的方法。目前最好的解决方案是通过统计和机器学习来得到一个类似的技术。
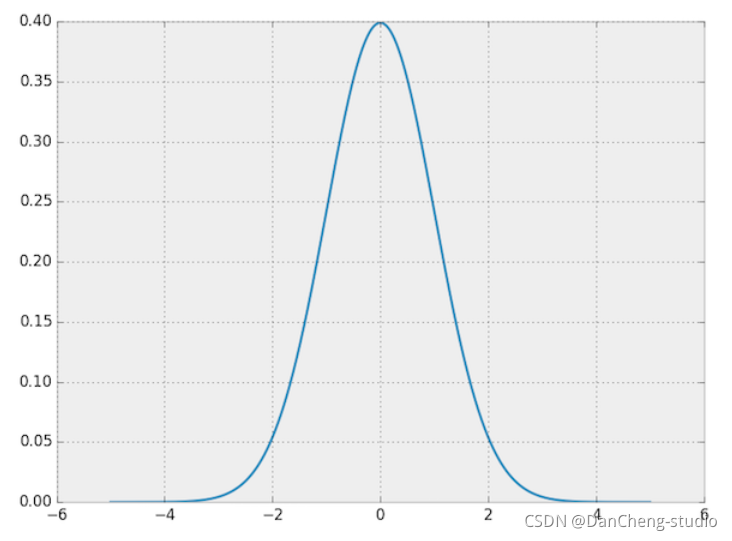
从这个分布中采样,就可以得到一些数据。需要搞清楚的是PDF和样本之间的联系。
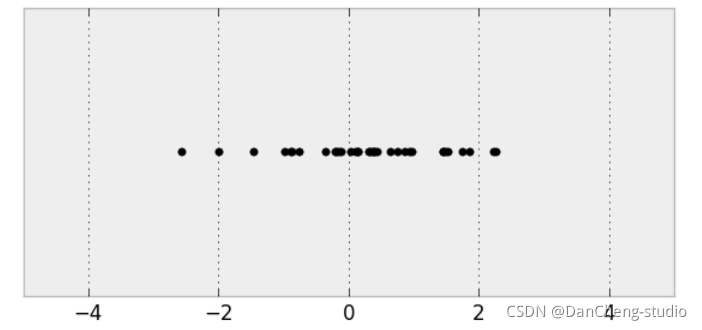
从正态分布中的采样
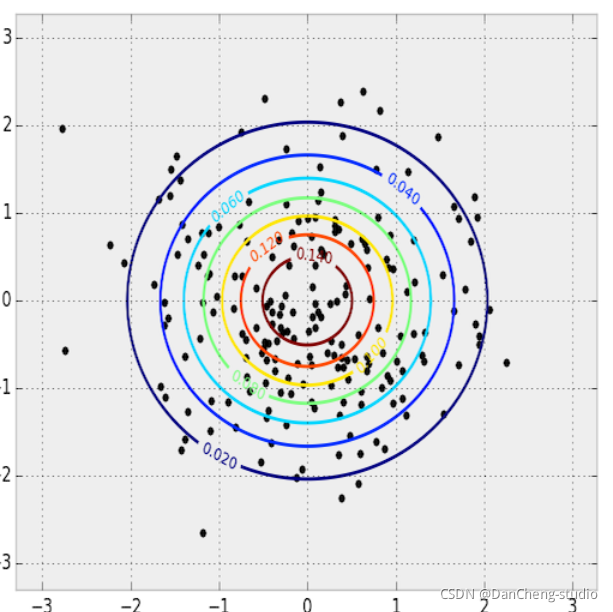
2维图像的PDF和采样。 PDF 用等高线图表示,样本点画在上面。
3.2 补全图像
首先考虑多变量正态分布, 以求得到一些启发。给定 x=1 , 那么 y 最可能的值是什么?我们可以固定x的值,然后找到使PDF最大的 y。
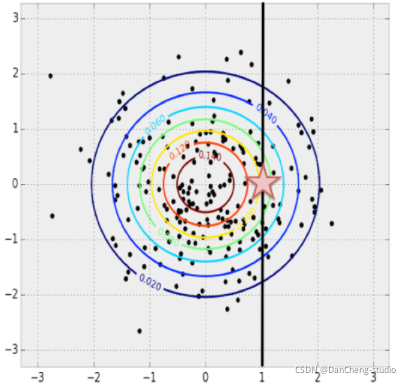
在多维正态分布中,给定x,得到最大可能的y
这个概念可以很自然地推广到图像概率分布。我们已知一些值,希望补全缺失值。这可以简单理解成一个最大化问题。我们搜索所有可能的缺失值,用于补全的图像就是可能性最大的值。
从正态分布的样本来看,只通过样本,我们就可以得出PDF。只需挑选你喜欢的 统计模型, 然后拟合数据即可。
然而,我们实际上并没有使用这种方法。对于简单分布来说,PDF很容易得出来。但是对于更复杂的图像分布来说,就十分困难,难以处理。之所以复杂,一部分原因是复杂的条件依赖:一个像素的值依赖于图像中其它像素的值。另外,最大化一个一般的PDF是一个非常困难和棘手的非凸优化问题。
3.3 快速生成假图像
在未知概率分布情况下,学习生成新样本
除了学 如何计算PDF之外,统计学中另一个成熟的想法是学 怎样用 生成模型
生成新的(随机)样本。生成模型一般很难训练和处理,但是后来深度学*社区在这个领域有了一个惊人的突破。Yann LeCun 在这篇 Quora
回答中对如何进行生成模型的训练进行了一番精彩的论述,并将它称为机器学习领域10年来最有意思的想法。
3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构
使用微步长卷积,对图像进行上采样
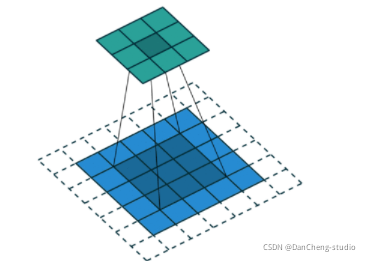
现在我们有了微步长卷积结构,可以得到G(z)的表达,以一个向量z∼pz 作为输入,输出一张 64x64x3 的RGB图像。
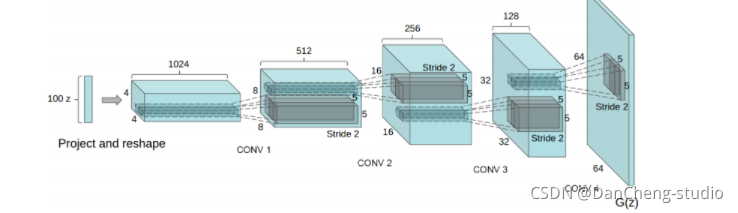
3.5 使用G(z)生成伪图像
基于DCGAN的人脸代数运算 DCGAN论文 。

4 在Tensorflow上构建DCGANs
部分代码:
def generator(self, z):self.z_, self.h0_w, self.h0_b = linear(z, self.gf_dim*8*4*4, 'g_h0_lin', with_w=True)self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])h0 = tf.nn.relu(self.g_bn0(self.h0))self.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True)h1 = tf.nn.relu(self.g_bn1(self.h1))h2, self.h2_w, self.h2_b = conv2d_transpose(h1,[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True)h2 = tf.nn.relu(self.g_bn2(h2))h3, self.h3_w, self.h3_b = conv2d_transpose(h2,[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)h3 = tf.nn.relu(self.g_bn3(h3))h4, self.h4_w, self.h4_b = conv2d_transpose(h3,[self.batch_size, 64, 64, 3], name='g_h4', with_w=True)return tf.nn.tanh(h4)def discriminator(self, image, reuse=False):if reuse:tf.get_variable_scope().reuse_variables()h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))h4 = linear(tf.reshape(h3, [-1, 8192]), 1, 'd_h3_lin')return tf.nn.sigmoid(h4), h4
当我们初始化这个类的时候,将要用到这两个函数来构建模型。我们需要两个判别器,它们共享(复用)参数。一个用于来自数据分布的小批图像,另一个用于生成器生成的小批图像。
self.G = self.generator(self.z)
self.D, self.D_logits = self.discriminator(self.images)
self.D_, self.D_logits_ = self.discriminator(self.G, reuse=True)
接下来,我们定义损失函数。这里我们不用求和,而是用D的预测值和真实值之间的交叉熵(cross
entropy),因为它更好用。判别器希望对所有“真”数据的预测都是1,对所有生成器生成的“伪”数据的预测都是0。生成器希望判别器对两者的预测都是1 。
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits,tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,tf.ones_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
下面我们遍历数据。每一次迭代,我们采样一个小批数据,然后使用优化器来更新网络。有趣的是,如果G只更新一次,鉴别器的损失不会变成0。另外,我认为最后调用
d_loss_fake 和 d_loss_real 进行了一些不必要的计算, 因为这些值在 d_optim 和 g_optim 中已经计算过了。
作为Tensorflow 的一个联系,你可以试着优化这一部分,并发送PR到原始的repo。
for epoch in xrange(config.epoch):...for idx in xrange(0, batch_idxs):batch_images = ...batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \.astype(np.float32)# Update D network_, summary_str = self.sess.run([d_optim, self.d_sum],feed_dict={ self.images: batch_images, self.z: batch_z })# Update G network_, summary_str = self.sess.run([g_optim, self.g_sum],feed_dict={ self.z: batch_z })# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)_, summary_str = self.sess.run([g_optim, self.g_sum],feed_dict={ self.z: batch_z })errD_fake = self.d_loss_fake.eval({self.z: batch_z})errD_real = self.d_loss_real.eval({self.images: batch_images})errG = self.g_loss.eval({self.z: batch_z})最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
互联网加竞赛 基于深度学的图像修复 图像补全
1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学的图像修复 图像补全 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-se…...

用于制作耳机壳的UV树脂耳机壳UV胶价格高不高?
制作耳机壳的UV树脂价格相对于一些其他材料可能会略高,但具体的价格取决于多个因素,如品牌、型号、质量等。一些高端的UV树脂品牌和型号可能会价格较高,但它们也通常具有更好的性能和更广泛的应用范围。 此外,UV树脂的价格也与购买…...

【开源】JAVA+Vue+SpringBoot实现房屋出售出租系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 房屋销售模块2.2 房屋出租模块2.3 预定意向模块2.4 交易订单模块 三、系统展示四、核心代码4.1 查询房屋求租单4.2 查询卖家的房屋求购单4.3 出租意向预定4.4 出租单支付4.5 查询买家房屋销售交易单 五、免责说明 一、摘…...

Golang 并发 生产者消费者模式
Golang 并发 生产者消费者模式 生产者-消费者模式能够带来的好处 生产者消费者模式是一种常见的并发编程模式,用于解决生产者和消费者之间的数据传递和处理问题。在该模式中,生产者负责生成数据(生产),而消费者负责处…...
Win32 SDK Gui编程系列之--ListView自绘OwnerDraw
ListView自绘OwnerDraw 1.ListView自绘OwnerDraw 正在试错是否使用了列表视图,尽量制作出智能的表格编辑器。本页显示了业主抽签的表格数据(二维数组数据)的显示方法。 显示画面和整个程序如下所示。使用ListView_GetSubItemRect宏的话,就不需要getRect函数了。 当nCol的…...

深度学习本科课程 实验5 循环神经网络
循环神经网络实验 任务内容 理解序列数据处理方法,补全面向对象编程中的缺失代码,并使用torch自带数据工具将数据封装为dataloader分别采用手动方式以及调用接口方式实现RNN、LSTM和GRU,并在至少一种数据集上进行实验从训练时间、预测精度、…...

Redis篇之过期淘汰策略
一、数据的过期策略 1.什么是过期策略 Redis对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)。 2.过期策略-惰…...
【Kubernetes】kubectl top pod 异常?
目录 前言一、表象二、解决方法1、导入镜像包2、编辑yaml文件3、解决问题 三、优化改造1.修改配置文件2.检查api-server服务是否正常3.测试验证 总结 前言 各位老铁大家好,好久不见,卑微涛目前从事kubernetes相关容器工作,感兴趣的小伙伴相互…...

前后端分离项目:前端的文件夹应该叫什么名字,后端呢
在前后端分离的项目中,为了提高项目的可读性和易管理性,给前端和后端的文件夹选择合适的名字是很重要的。这里提供一些建议,但请记住,最终的命名应该根据你的团队习惯、项目特性以及可能的公司规定来决定。 ### 前端文件夹命名建…...
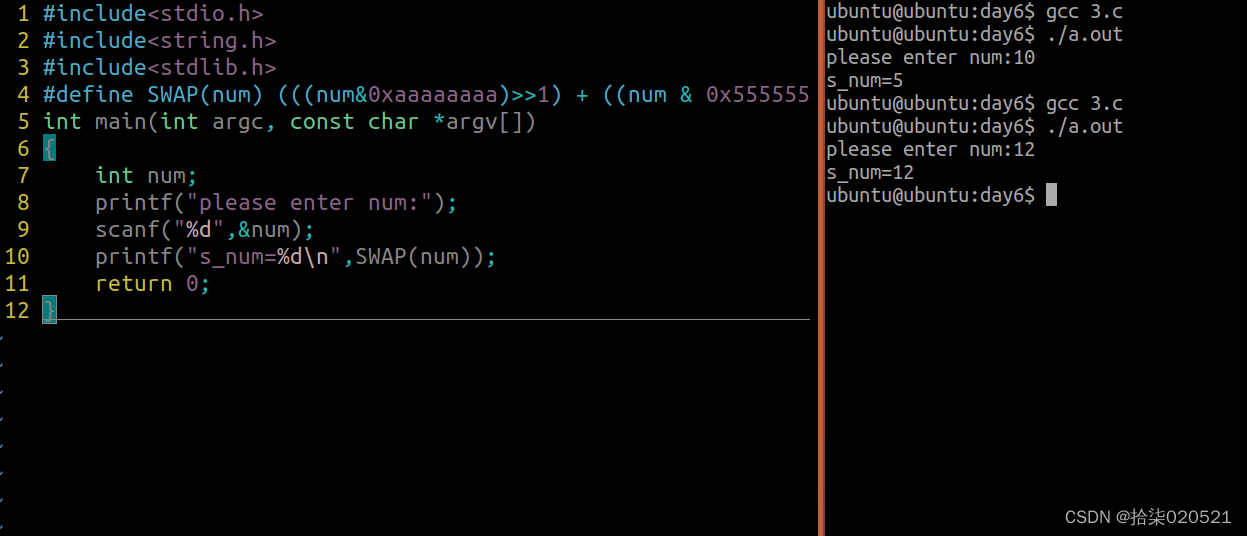
2024.2.6
1.现有无序序列数组为23,24,12,5,33,5347,请使用以下排序实现编程 函数1:请使用冒泡排序实现升序排序 函数2:请使用简单选择排序实现升序排序 函数3:请使用快速排序实现升序排序 函数4:请使用插入排序实现升序排序 #include<stdio.h> #include<string.h&g…...
如何在 Microsoft Azure 上部署和管理 Elastic Stack
作者:来自 Elastic Osman Ishaq Elastic 用户可以从 Azure 门户中查找、部署和管理 Elasticsearch。 此集成提供了简化的入门体验,所有这些都使用你已知的 Azure 门户和工具,因此你可以轻松部署 Elastic,而无需注册外部服务或配置…...
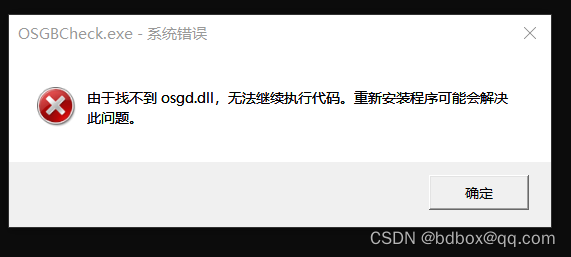
在Visual Studio中引用和链接OpenSceneGraph (OSG) 库
在Visual Studio中引用和链接OpenSceneGraph (OSG) 库,按照以下步骤操作: 构建或安装OSG库 下载OpenSceneGraph源代码(如3.0版本)并解压。使用CMake配置项目,为Visual Studio生成解决方案文件。通常您需要设置CMake中的…...

[缓存] - Redis
0.为什么要使用缓存? 用缓存,主要有两个用途:高性能、高并发。 1. 高性能 尽量使用短key 不要存过大的数据 避免使用keys *:使用SCAN,来代替 在存到Redis之前压缩数据 设置 key 有效期 选择回收策略(maxmemory-policy) 减…...
spring boot和spring cloud项目中配置文件application和bootstrap加载顺序
在前面的文章基础上 https://blog.csdn.net/zlpzlpzyd/article/details/136060312 日志配置 logback-spring.xml <?xml version"1.0" encoding"UTF-8"?> <configuration scan"true" scanPeriod"10000000 seconds" debug…...

AdaBoost算法
Boosting是一种集成学习方法,AdaBoost是Boosting算法中的一种具体实现。 Boosting方法的核心思想在于将多个弱分类器组合成一个强分类器。这些弱分类器通常是简单的模型,比如决策树,它们在训练过程中的错误会被后续的弱分类器所修正。Boosti…...

基于 elasticsearch v8 的 CRUD 操作及测试用例
基于 elasticsearch v8 的 CRUD 操作及测试用例 https://github.com/chenshijian73-qq/go-es/tree/main...

深度学习的新进展:解析技术演进与应用前景
深度学习的新进展:解析技术演进与应用前景 深度学习,作为人工智能领域的一颗璀璨明珠,一直以来都在不断刷新我们对技术和未来的认知。随着时间的推移,深度学习不断迎来新的进展,这不仅推动了技术的演进,也…...

【第二届 Runway短视频创作大赛】——截至日期2024年03月01日
短视频创作大赛 关于AI Film Festival竞赛概况参加资格报名期间报名方法 提交要求奖品附录 关于AI Film Festival 2022年成立的AIFF是一个融合了最新AI技术于电影制作中的艺术和艺术家节日,让我们得以一窥新创意时代的风采。从众多参赛作品中…...

UniApp 快速上手与深度学习指南
一、UniApp 简介 UniApp 是中国DCloud公司研发的一款创新的跨平台应用开发框架,它基于广受欢迎的前端开发库Vue.js,旨在解决多端适配和快速开发的问题。通过UniApp,开发者能够采用一套统一的代码结构、语法和API来构建应用程序,从而实现真正意义上的“一次编写,到处运行”…...
10个简单有效的编辑PDF文件工具分享
10个编辑PDF文件工具作为作家、编辑或专业人士,您可能经常发现自己在处理 PDF 文件。无论您是审阅文档、创建报告还是与他人共享工作,拥有一个可靠的 PDF 编辑器供您使用都非常重要。 10个简单适用的编辑PDF文件工具 在本文中,我们将介绍当今…...
)
实战指南:如何用Mask R-CNN在iSAID数据集上提升航空影像分割效果(附调参技巧)
航空影像实例分割实战:Mask R-CNN在iSAID数据集上的调优策略 航空影像分析正逐渐成为城市规划、灾害监测和国防安全等领域的关键技术。与常规自然图像不同,这类影像通常包含大量密集分布的小目标,且目标尺度变化极大——从几个像素的小型车辆…...

ChatTTS WebUI 字数限制解析与高效处理方案
最近在项目中用到了 ChatTTS 的 WebUI 接口进行语音合成,发现了一个挺实际的问题:它是有字数限制的。直接丢一篇长文章过去,经常会因为超限而失败,用户体验和开发流程都受到了影响。经过一番摸索和实践,我总结了一套处…...
全解析:如何高效管理企业数据库漏洞)
Oracle季度安全补丁(CPU)全解析:如何高效管理企业数据库漏洞
Oracle季度安全补丁管理实战指南:从漏洞评估到自动化部署 1. Oracle CPU机制深度解析 Oracle Critical Patch Update(CPU)作为数据库安全防护体系的核心机制,其运作逻辑远比简单的补丁合集复杂得多。每季度发布的CPU实际上是一个经…...

ONNX模型获取全攻略:从环境适配到质量验证的系统化方案
ONNX模型获取全攻略:从环境适配到质量验证的系统化方案 【免费下载链接】models A collection of pre-trained, state-of-the-art models in the ONNX format 项目地址: https://gitcode.com/gh_mirrors/model/models 模型获取是AI开发流程的关键起点&#…...
)
Zig语言实战:5分钟搞定HTTP客户端与服务端开发(附完整代码)
Zig语言Web开发实战:从零构建HTTP客户端与服务端 最近在探索新兴系统编程语言时,Zig以其简洁的语法和强大的性能引起了我的注意。特别是它的标准库中内置了完整的HTTP支持,这让Web服务开发变得异常简单。本文将带你快速上手Zig语言的Web开发&…...

htcw_esp_panel:ESP32嵌入式显示与触摸的编译期硬件抽象框架
1. htcw_esp_panel:面向嵌入式显示与人机交互的全栈式硬件抽象层htcw_esp_panel 是一个专为 ESP32 系列 SoC(包括 ESP32-S2/S3/C3/P4)设计的轻量级、可配置化硬件抽象库。它并非简单的驱动封装,而是一套覆盖显示、触摸、按键、SD …...

OpenClaw Graph Memory 知识图谱深度解析:告别 AI 记忆困境,实现去中心化自我改进!
当 AI 助手频繁出错、反复试错消耗大量 token;当跨对话的宝贵经验第二天就消失无踪;当某个 Skills 学到的孤岛知识点无法迁移——这些问题是否困扰着你?OpenClaw 开源项目 Graph Memory 登场,用知识图谱颠覆传统记忆方案ÿ…...

进程与线程:操作系统中的“公司”与“员工”
进程与线程:操作系统中的“公司”与“员工”在操作系统的宏大叙事中,进程(Process)和线程(Thread)是两个最基础也最容易混淆的概念。很多初学者容易将它们混为一谈,认为它们只是“大任务”和“小…...

ACE-Guard资源限制器完整教程:彻底解决腾讯游戏卡顿问题
ACE-Guard资源限制器完整教程:彻底解决腾讯游戏卡顿问题 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 你是否在玩《地下城与勇士》、《英雄…...

洛阳万达商场美团快闪店设计,凭什么成为商圈流量密码?肆墨设计
在商业美陈从 “装饰载体” 向 “生活场景容器” 转型的当下,洛阳万达商场美团 “美事发生” 美好生活集市快闪店,以品牌 IP 为核心锚点,融合女性消费心理与地域商业特质,构建了一场兼具视觉冲击力、情感共鸣与商业转化的沉浸式空…...