PyTorch 中音频信号处理库torchaudio的详细介绍
torchaudio 是 PyTorch 深度学习框架的一部分,是 PyTorch 中处理音频信号的库,专门用于处理和分析音频数据。它提供了丰富的音频信号处理工具、特征提取功能以及与深度学习模型结合的接口,使得在 PyTorch 中进行音频相关的机器学习和深度学习任务变得更加便捷。通过使用 torchaudio,开发者能够轻松地将音频数据转换为适合深度学习模型输入的形式,并利用 PyTorch 的高效张量运算和自动梯度功能进行训练和推理。此外,torchaudio 还支持多声道音频处理和GPU加速,以满足不同应用场景的需求。
1. torchaudio其内部构成和组织结构
torchaudio其内部构成和组织结构主要包括以下几个核心部分:
-
torchaudio.io:
这个模块主要负责音频文件的读写操作,提供load()、save()等函数来加载和保存不同格式(如 WAV、MP3、FLAC 等)的音频文件。 -
torchaudio.functional:
提供了一系列用于音频信号处理和特征提取的底层功能。例如计算短时傅里叶变换 (STFT) 和逆 STFT,梅尔频率谱图 (Mel Spectrogram),MFCCs(梅尔频率倒谱系数),重采样等。 -
torchaudio.transforms:
包含一系列预定义的音频转换类,可以作为数据预处理流水线的一部分。这些转换器能够方便地应用于音频张量上,如 MelSpectrogram、MFCC 以及各类归一化、增强技术等。 -
torchaudio.datasets:
虽然 torchaudio 不直接内置音频数据集,但该模块提供了构建和加载自定义音频数据集的基础框架,用户可以根据需要创建自己的数据加载器。 -
torchaudio.models:
提供了一些预先训练好的模型或者模型组件,用于特定的音频处理任务,比如声学特征提取等。 -
torchaudio.prototype:
试验性的新功能和算法通常会先在这个模块中发布,以便开发者尝试并提供反馈,这些功能未来可能成为稳定版的一部分。 -
其他辅助模块:
torchaudio 还包括一些辅助工具和兼容性模块,例如与 Kaldi ASR 框架相关的接口(如 torchaudio.compliance.kaldi_io)。
总之,torchaudio 的内部结构旨在简化音频数据的加载、预处理、特征提取和模型构建过程,使其无缝集成到 PyTorch 的深度学习工作流程中。
2. torchaudio.functional模块
torchaudio.functional 模块提供了许多用于音频信号处理和特征提取的功能,以下是一些 torchaudio.functional 中的关键功能:
-
频谱分析:
stft():计算短时傅里叶变换(Short-Time Fourier Transform, STFT),将时域的音频信号转换为频域-时间表示。istft():计算逆短时傅里叶变换(Inverse Short-Time Fourier Transform, iSTFT),从频域-时间表示还原回时域信号。
-
梅尔频率相关操作:
mel_spectrogram():计算 Mel 频谱图,将音频信号转换为基于 Mel 频率尺度的频谱表示。amplitude_to_db():将功率谱或 Mel 频谱图转换为对数分贝(dB)尺度。
-
MFCC 计算:
mfcc():计算梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients, MFCCs),这是一种广泛应用于语音识别和其他音频处理任务的声学特征。
-
其他音频处理函数:
griffinlim():实现 Griffin-Lim 算法,用于从幅度谱重建时域信号。mu_law_encoding()和mu_law_decoding():实现 μ-law 压缩编码和解码,常用于语音压缩和传输。resample():进行重采样操作,改变音频信号的采样率。
-
增强与预处理:
normalize():标准化音频信号,使其具有零均值和单位方差。- 其他可能的函数包括噪声添加、增益控制等,但请注意 torchaudio 的具体版本和文档以获取最新信息。
总之,torchaudio.functional 包含了一系列底层音频处理函数,这些函数在构建和训练基于音频的深度学习模型时是必不可少的。通过使用这些函数,开发者可以方便地对原始音频数据进行预处理,将其转化为适合神经网络输入的特征表示形式。
3. torchaudio.transforms模块
torchaudio.transforms 是 torchaudio 库中提供的音频转换模块,它包含了多种预定义的音频特征提取和信号处理方法,可以方便地应用于深度学习模型的输入数据预处理。以下是一些常用的 transforms:
-
MelSpectrogram:
用于将音频信号转换为梅尔频率谱图(Mel Spectrogram),这是一种在语音识别、音乐信息检索等领域广泛应用的音频表示形式。 -
MFCC:
提供了 Mel-Frequency Cepstral Coefficients (MFCCs) 的计算功能,MFCC 是一种从音频信号中提取的人耳对声音感知特性的近似表示。 -
AmplitudeToDB:
将功率谱或梅尔频谱转换为分贝(dB)表示,常用于归一化和稳定音频特征的动态范围。 -
Resample:
对音频信号进行重采样,改变其采样率以适应不同深度学习模型的要求。 -
MuLawEncoding / MuLawDecoding:
实现 A-law 或 μ-law 压缩编码和解码,通常用于降低音频数据的存储空间需求。 -
TimeStretch:
改变音频信号的时间尺度,即加快或减慢音频的速度,但保持音高不变。 -
PitchShift:
调整音频的音调(pitch),同时调整播放速度以保持原始时长。 -
Normalize:
对音频信号进行标准化处理,使其具有零均值和单位方差,有助于优化模型训练过程。
使用这些变换类,用户可以创建一个自定义的数据预处理流水线,从而轻松准备音频数据作为深度学习模型的输入。例如:
Python
1import torchaudio
2
3# 创建 Mel Spectrogram 转换器
4mel_spec = torchaudio.transforms.MelSpectrogram(sample_rate=16000, n_mels=64)
5
6# 加载音频文件
7audio, sample_rate = torchaudio.load('example_audio.wav')
8
9# 计算 Mel Spectrogram
10mel_spectrogram = mel_spec(audio)
11
12# 其他变换操作...通过这种方式,torchaudio.transforms 提供了一个简洁且统一的接口来处理各种音频预处理任务,并与 PyTorch 生态系统紧密结合,使得音频相关的深度学习研究更加便捷高效。
4. torchaudio.models
torchaudio.models 是 torchaudio 库中用于提供预训练音频处理模型的部分。尽管目前 torchaudio.models 模块提供的功能相对有限,但随着库的发展,可能会增加更多预训练模型。以下是一些可能存在的模型或组件:
-
声学特征提取器(Acoustic Feature Extractors):
在某些版本的 torchaudio 中,可能存在预定义的声学特征提取器,如 MFCC(梅尔频率倒谱系数)提取器,这类模型通常用来将原始音频数据转换为深度学习模型可以使用的特征向量。 -
语音识别相关模型(Speech Recognition Models):
虽然torchaudio.models目前并未直接提供完整的预训练语音识别模型,但可能会包含部分模型组件,例如基于 LSTM 或 Transformer 的声学模型架构的基础构建模块。 -
文本转语音(Text-to-Speech, TTS)模型组件:
可能会有一些 TTS 模型相关的基础层和组件,如 Tacotron 系列模型的一部分结构,或者 Mel-spectrogram 预测网络等。 -
声音事件检测(Sound Event Detection, SED)模型:
未来可能会支持预训练的声音事件检测模型,这些模型能够从音频片段中识别特定的声音事件。
请注意,上述内容是基于对 torchaudio 功能发展的推测和理解,并非当前最新版 torchaudio 的准确描述。实际使用时,请查阅官方文档以获取最新的模块支持信息。
5. 支持的音频数据集
torchaudio 不直接提供音频数据集,但它支持与常见的音频数据集集成,并提供了方便的接口来加载这些数据。以下是一些 torchaudio 可能会用到或官方文档中提到的音频数据集:
-
LibriSpeech:
- LibriSpeech 是一个大规模英语阅读语音数据集,包含大约 1000 小时的有声读物朗读内容,由 LibriVox 项目中的公开领域有声读物制作而成。
- 虽然 torchaudio 没有内置对 LibriSpeech 的加载器,但可以使用
torch.utils.data.Dataset和其子类自定义数据集加载方式,或者结合其他库(如datasets库)来加载 LibriSpeech。
-
VCTK:
- VCTK (Voice Cloning Toolkit) 是一个包含超过 100 名不同说话者的英语口语数据集,每个说话者都朗读了多篇文本,用于语音合成和说话人识别的研究。
- 类似于 LibriSpeech,torchaudio 并没有直接内建 VCTK 加载器,但是可以通过类似的自定义方法或第三方库加载该数据集。
-
LJSpeech:
- LJSpeech 是一个单个女性说话人的英文朗读数据集,包含约 24 小时的录音,通常用于端到端的文本转语音(TTS)系统训练。
- 使用 torchaudio 加载 LJSpeech 数据集同样需要自定义数据加载逻辑。
在实际应用中,用户可以编写脚本来下载、解压和预处理这些数据集,然后将其转换为适合 torchaudio 处理的张量格式。同时,社区中存在许多基于 PyTorch 或 torchaudio 的开源项目,它们可能已经实现了针对特定数据集的加载器和预处理步骤,可以作为参考或直接使用。
相关文章:

PyTorch 中音频信号处理库torchaudio的详细介绍
torchaudio 是 PyTorch 深度学习框架的一部分,是 PyTorch 中处理音频信号的库,专门用于处理和分析音频数据。它提供了丰富的音频信号处理工具、特征提取功能以及与深度学习模型结合的接口,使得在 PyTorch 中进行音频相关的机器学习和深度学习…...

OpenAI研究揭示:ChatGPT对生物武器制造影响有限
### OpenAI研究揭示:ChatGPT对生物武器制造影响有限 在最近的一项引人注目的研究中,OpenAI探索了其旗舰人工智能产品GPT-4在辅助制造生物武器方面的潜力。尽管公众对人工智能可能带来的潜在风险表示担忧,但OpenAI的发现却意味着这种担忧可能…...
IntelliJ IDEA 2023.3发布,AI 助手出世,新特性杀麻了!!
目录 关键亮点 对 Java 21 功能的完全支持 调试器中的 Run to Cursor(运行到光标)嵌入选项 带有编辑操作的浮动工具栏 用户体验优化 Default(默认)工具窗口布局选项 默认颜色编码编辑器标签页 适用于 macOS 的新产品图标 Speed Sear…...
async 与 await(JavaScript)
目录捏 前言一、async二、await三、使用方法总结 前言 async / await 是 ES2017(ES8) 提出的基于 Promise 解决异步的最终方案。上一篇文章介绍了 回调地狱 与 Promise(JavaScript),因为 Promise 的编程模型依然充斥着大量的 then 方法&#…...

GPT-1, GPT-2, GPT-3, GPT-3.5, GPT-4论文内容解读
目录 1 ChatGPT概述1.1 what is chatGPT1.2 How does ChatGPT work1.3 The applications of ChatGPT1.3 The limitations of ChatGPT 2 算法原理2.1 GPT-12.1.1 Unsupervised pre-training2.1.2 Supervised fine-tuning2.1.3 语料2.1.4 分析 2.2 GPT-22.3 GPT-32.4 InstructGPT…...
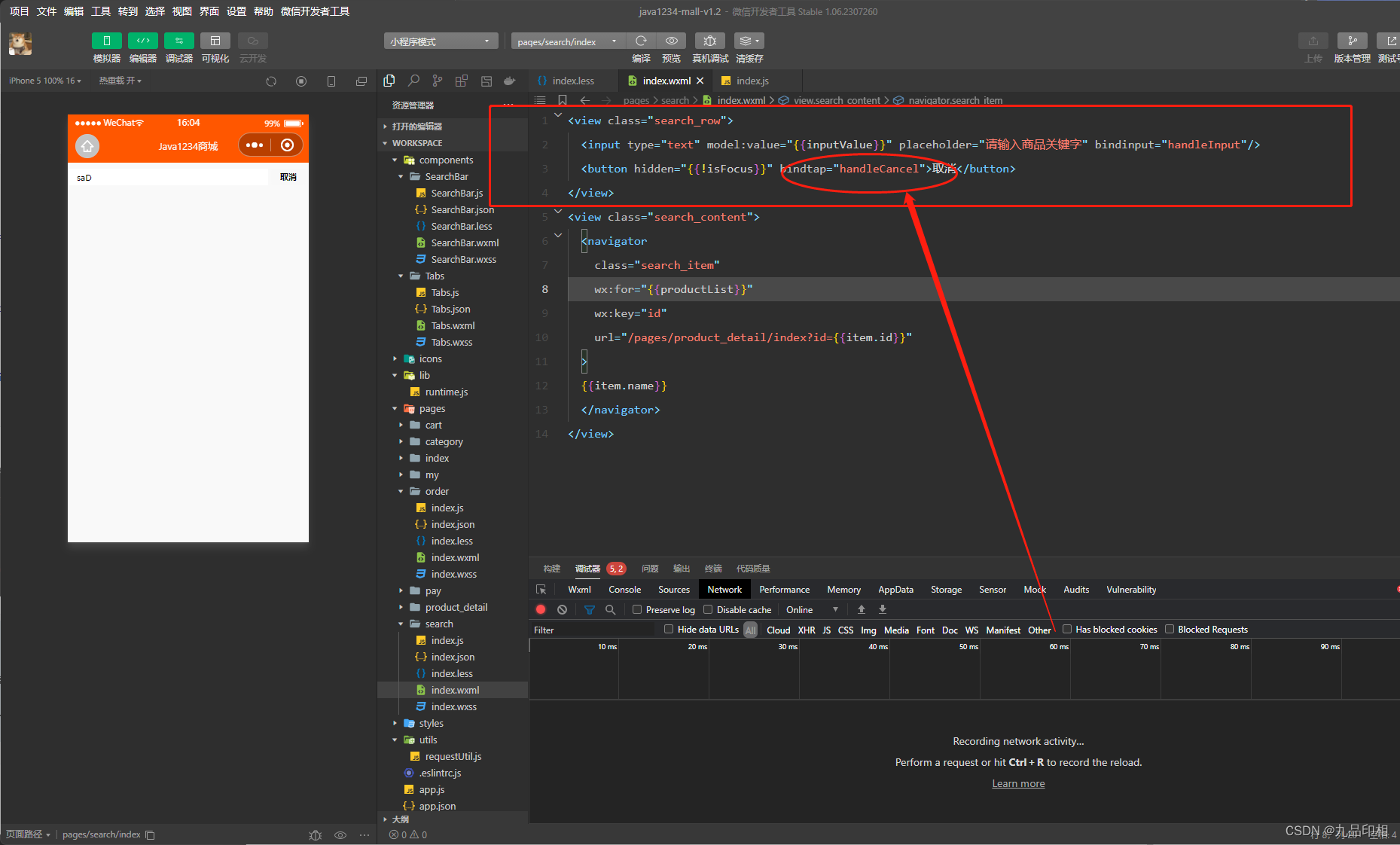
第62讲商品搜索动态实现以及性能优化
商品搜索后端动态获取数据 后端动态获取数据: /*** 商品搜索* param q* return*/GetMapping("/search")public R search(String q){List<Product> productList productService.list(new QueryWrapper<Product>().like("name", q)…...
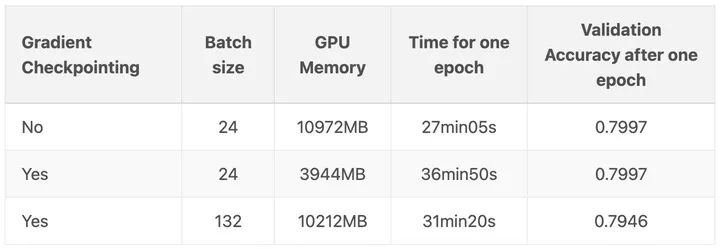
我的PyTorch模型比内存还大,怎么训练呀?
原文:我的PyTorch模型比内存还大,怎么训练呀? - 知乎 看了一篇比较老(21年4月文章)的不大可能训练优化方案,保存起来以后研究一下。 随着深度学习的飞速发展,模型越来越臃肿,哦不&a…...
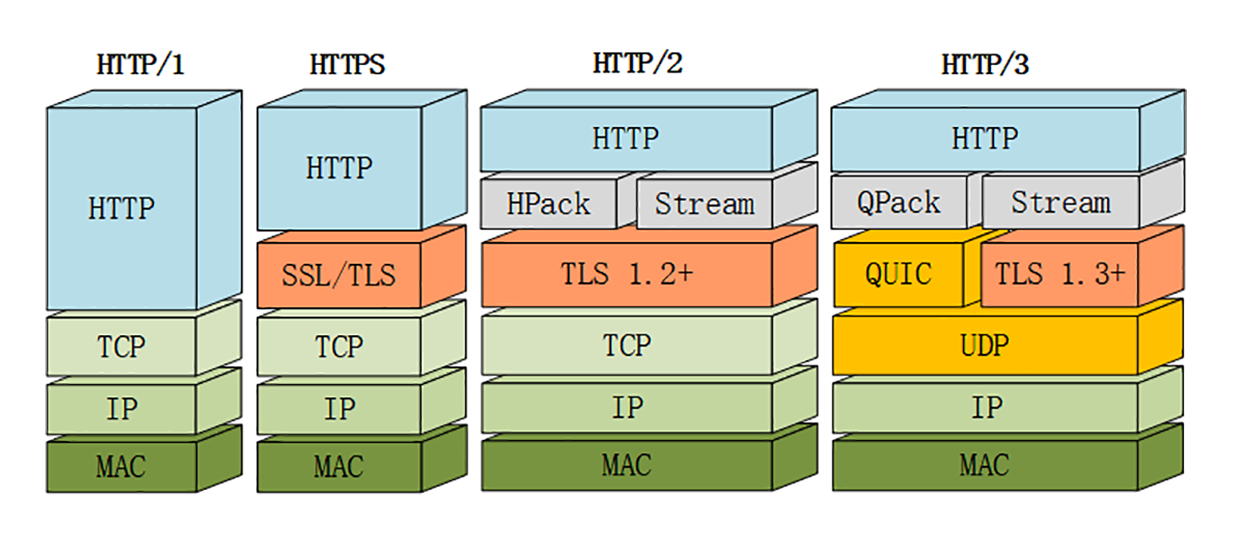
HTTP协议笔记
HTTP协议笔记 参考: (建议精读)HTTP灵魂之问,巩固你的 HTTP 知识体系 《透视 HTTP 协议》——chrono 目录: 1、说说你对HTTP的了解吧。 1. HTTP状态码。 2. HTTP请求头和响应头,其中包括cookie、跨域响…...

零基础学Python之网络编程
1.什么是socket 官方定义: 套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用…...
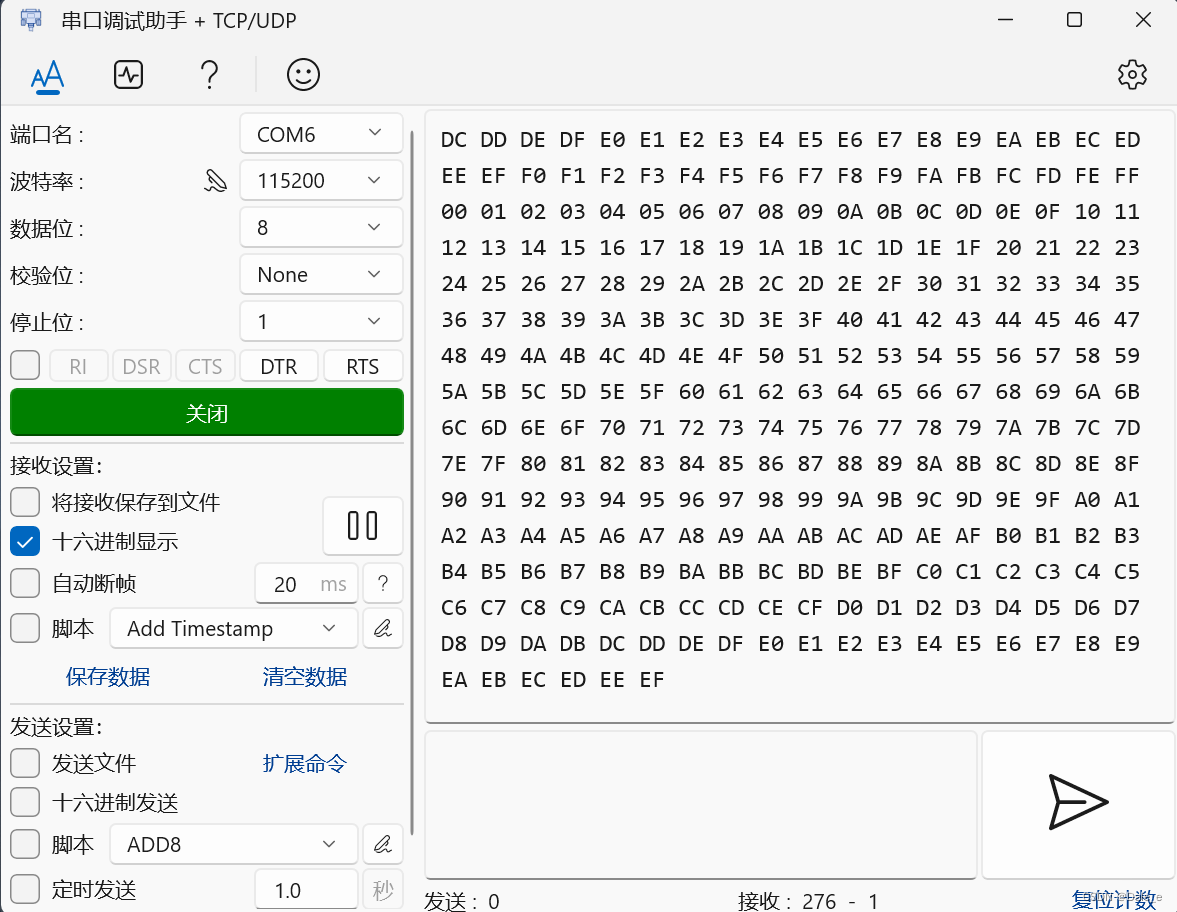
09 AB 10串口通信发送原理
通用异步收发传输器( Universal Asynchronous Receiver/Transmitter, UART)是一种异步收发传输器,其在数据发送时将并行数据转换成串行数据来传输, 在数据接收时将接收到的串行数据转换成并行数据, 可以实现…...

[145] 二叉树的后序遍历 js
题目描述:给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 解题思路: 迭代法: 后序(左右根) 先序是根左右 后序是左右根 后序翻转一下就是 根右左 所以后序的结果实际就是 先序的方法࿰…...
)
开源模型应用落地-业务优化篇(四)
一、前言 经过线程池优化、请求排队和服务实例水平扩容等措施,整个AI服务链路的性能得到了显著地提升。但是,作为追求卓越的大家,绝不会止步于此。我们的目标是在降低成本和提高效率方面不断努力,追求最佳结果。如果你们在实施AI项目方面有经验,那一定会对GPU服务器的高昂…...

MySQL的MVCC机制
MVCC机制 使用MVCC(Multi-Version Concurrency Control,多版本的并发控制协议)机制来实现可重复读(REPEATABLE READ)的隔离级别 MVCC最大的优点是读不加锁,因此读写不冲突,并发性能好。InnoDB实现MVCC,是通过保存数据在某个时间点…...
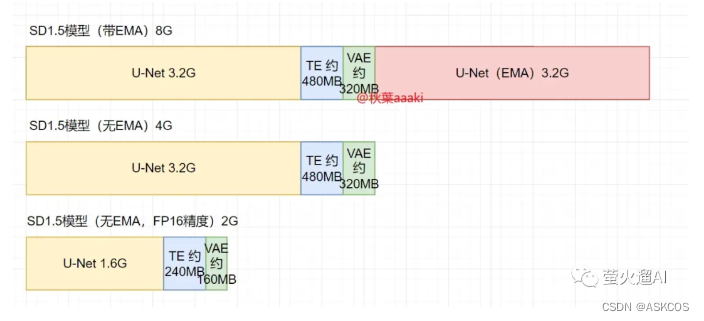
stable-diffusion | v1-5-pruned.ckpt和v1-5-pruned-emaonly.ckpt的区别
https://github.com/runwayml/stable-diffusion?tabreadme-ov-file#reference-sampling-script 对于 1.5 模型,其中可能包括四部分:标准模型、文本编码器、VAE模型、EMA模型。 标准模型:生成图片的核心模块,潜空间中的前向扩散和…...

基于Springboot的足球社区管理系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的足球社区管理系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构…...
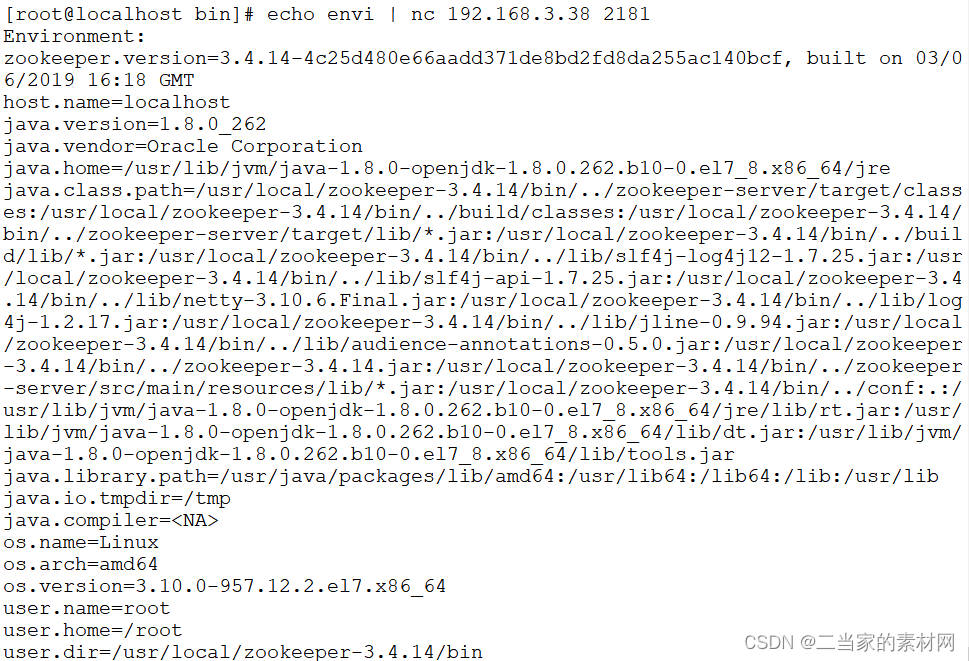
8.0 Zookeeper 四字命令教程详解
zookeeper 支持某些特定的四字命令与其交互,用户获取 zookeeper 服务的当前状态及相关信息,用户在客户端可以通过 telenet 或者 nc(netcat) 向 zookeeper 提交相应的命令。 安装 nc 命令: $ yum install nc …...

【MySQL】学习和总结DCL的权限控制
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-Bl9kYeLf8GfpdQgL {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...
React+Antd实现表格自动向上滚动
1、效果 2、环境 1、react18 2、antd 4 3、代码实现 原理:创建一个定时器,修改表格ant-table-body的scrollTop属性实现滚动,监听表层的元素div的鼠标移入和移出实现实现鼠标进入元素滚动暂停,移出元素的时候表格滚动继续。 一…...

网络安全产品之认识准入控制系统
文章目录 一、什么是准入控制系统二、准入控制系统的主要功能1. 接入设备的身份认证2. 接入设备的安全性检查 三、准入控制系统的工作原理四、准入控制系统的特点五、准入控制系统的部署方式1. 网关模式2. 控制旁路模式 六、准入控制系统的应用场景七、企业如何利用准入控制系统…...

Text2SQL研究-Chat2DB体验与剖析
文章目录 概要业务数据库配置Chat2DB安装设置原理剖析 小结 概要 近期笔者在做Text2SQL的研究,于是调研了下Chat2DB,基于车辆订单业务做了一些SQL生成验证,有了一点心得,和大家分享一下.: 业务数据库设置 基于车辆订…...

吃透MQ:从原理到落地,解决分布式系统的核心痛点
在分布式系统与微服务架构普及的今天,“高并发、高可用、低耦合”成为系统设计的核心诉求。而消息队列(Message Queue,简称MQ),作为分布式架构中的“通信枢纽”,凭借异步通信、流量削峰、系统解耦等核心能力…...

OpenClaw快速安装部署:让AI住进你的电脑
一、前言 上篇说完OpenClaw是什么,有小伙伴留言说:“听起来挺猛,但安装肯定很复杂吧?”确实,之前我也有这个顾虑。毕竟涉及到Gateway、Agent、多渠道配置,听起来就头大。 但实际搞下来——就两条命令。 今天…...
)
新手必看!用PHPStudy一键搭建DVWA靶场(附常见错误解决)
零基础实战:用PHPStudy快速搭建DVWA漏洞靶场全指南 第一次接触网络安全实战时,很多人会被复杂的实验环境搭建劝退。作为过来人,我完全理解那种面对满屏报错信息的无力感。本文将手把手带你用PHPStudy这个神器,在Windows系统上快速…...

开发者社区生存手册:从潜水到活跃贡献者的5个关键步骤
开发者社区生存手册:从潜水到活跃贡献者的5个关键步骤 在数字时代的代码丛林里,开发者社区如同一个个闪烁着智慧火光的营地。你可能已经加入了几十个Slack频道,关注了无数技术大牛的Twitter,在GitHub上star了上百个仓库࿰…...
)
MCP开发环境搭建全攻略(VS Code插件安装避坑白皮书·2024官方认证版)
第一章:MCP开发环境搭建全攻略(VS Code插件安装避坑白皮书2024官方认证版)前置依赖检查与系统准备 在安装任何 MCP 相关插件前,请确保已安装以下基础组件:VS Code 1.85(推荐 1.87.2)、Node.js 1…...

终极实战指南:在Docker容器中运行Windows系统的完整解决方案
终极实战指南:在Docker容器中运行Windows系统的完整解决方案 【免费下载链接】windows Windows inside a Docker container. 项目地址: https://gitcode.com/GitHub_Trending/wi/windows 还在为Windows虚拟机占用大量系统资源而烦恼吗?想体验在容…...

实战数据可视化:基于快马平台构建小龙虾销售趋势分析看板
实战数据可视化:基于快马平台构建小龙虾销售趋势分析看板 最近帮朋友的小龙虾连锁店做数据分析,发现传统Excel报表根本满足不了实时决策的需求。老板们需要一眼就能看懂销售趋势、口味偏好和地区差异,于是我尝试用InsCode(快马)平台快速搭建…...

实战指南:基于Cursor与快马平台,从零搭建一个可用的商品管理后台
今天想和大家分享一个实战项目——用Cursor和InsCode(快马)平台从零搭建商品管理后台的全过程。这个项目麻雀虽小五脏俱全,包含了前后端完整链路,特别适合想练手全栈开发的朋友。 项目架构设计 整个系统采用前后端分离模式。后端用Spring Boot搭建RESTfu…...

深度解析:Markdown Viewer v5.3如何通过自定义主题功能彻底改变文档阅读体验
深度解析:Markdown Viewer v5.3如何通过自定义主题功能彻底改变文档阅读体验 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer作为一款备受开发者喜爱的…...

3.25mysql课堂笔记
1.字符串函数2.时间操作函数3.数字函数...