NLP_语言模型的雏形 N-Gram 模型
文章目录
- N-Gram 模型
- 1.将给定的文本分割成连续的N个词的组合(N-Gram)
- 2.统计每个N-Gram在文本中出现的次数,也就是词频
- 3.为了得到一个词在给定上下文中出现的概率,我们可以利用条件概率公式计算。具体来讲,就是计算给定前N-1个词时,下一个词出现的概率。这个概率可以通过计算某个N-Gram出现的次数与前N-1个词(前缀)出现的次数之比得到
- 4.可以使用这些概率来预测文本中下一个词出现的可能性。多次迭代这个过程,甚至可以生成整个句子,也可以算出每个句子在语料库中出现的概率
- “词”是什么,如何“分词”
- 创建一个Bigram字符预测模型
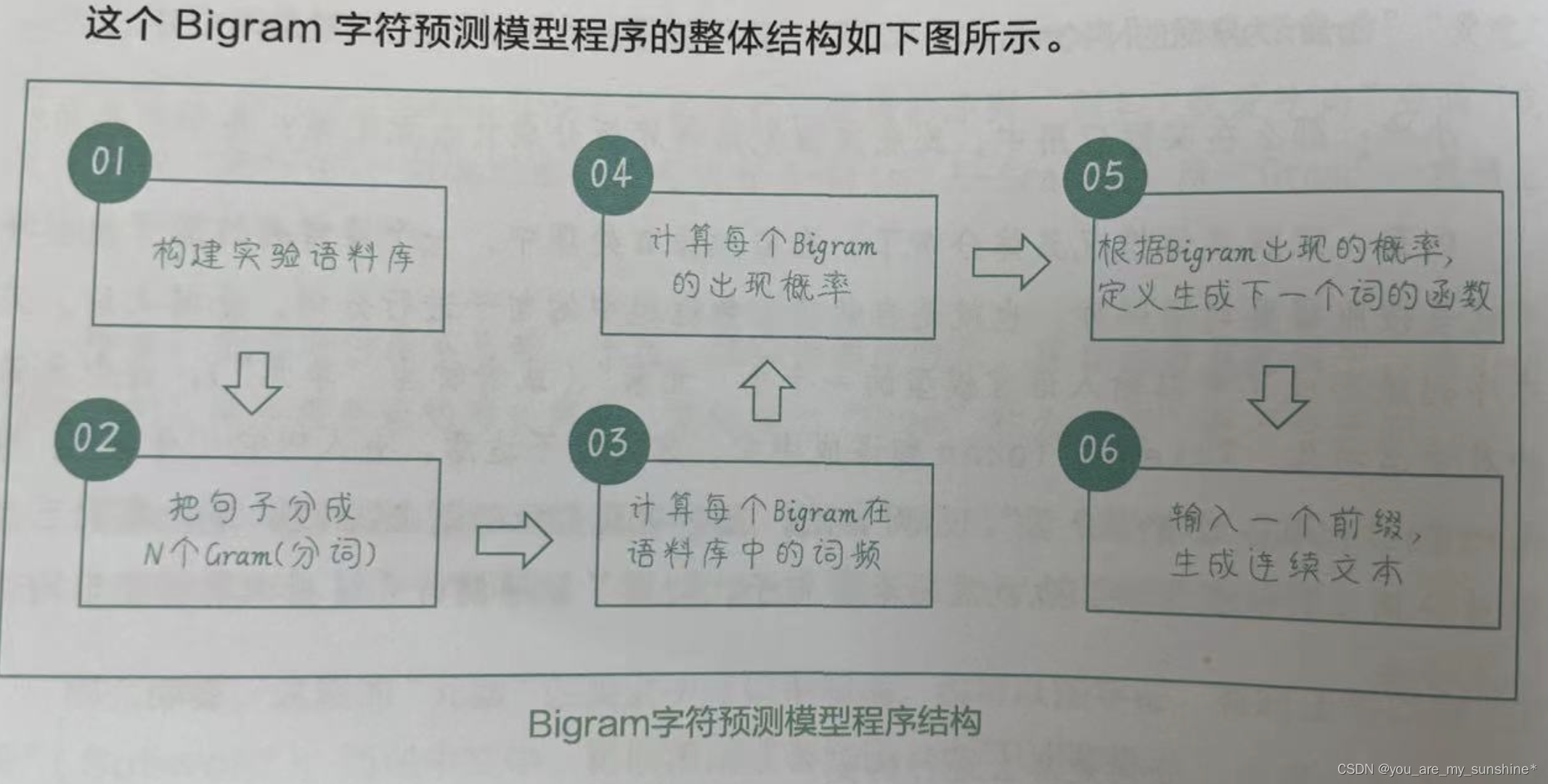
- 1.构建实验语料库
- 2.把句子分成N个Gram(分词)
- 3.计算每个Bigram在语料库中的词频
- 4.计算每个Bigram的出现概率
- 5.根据Bigram出现的概率,定义生成下一个词的函数
- 6.输入一个前缀,生成连续文本
- N-Gram 模型小结
N-Gram 模型
N-Gram 模型的构建过程如下:
1.将给定的文本分割成连续的N个词的组合(N-Gram)
比如,在Bigram 模型(2-Gram 模型,即二元模型)中,我们将文本分割成多个由相邻的两个词构成的组合,称它们为“二元组”(2-Gram )。
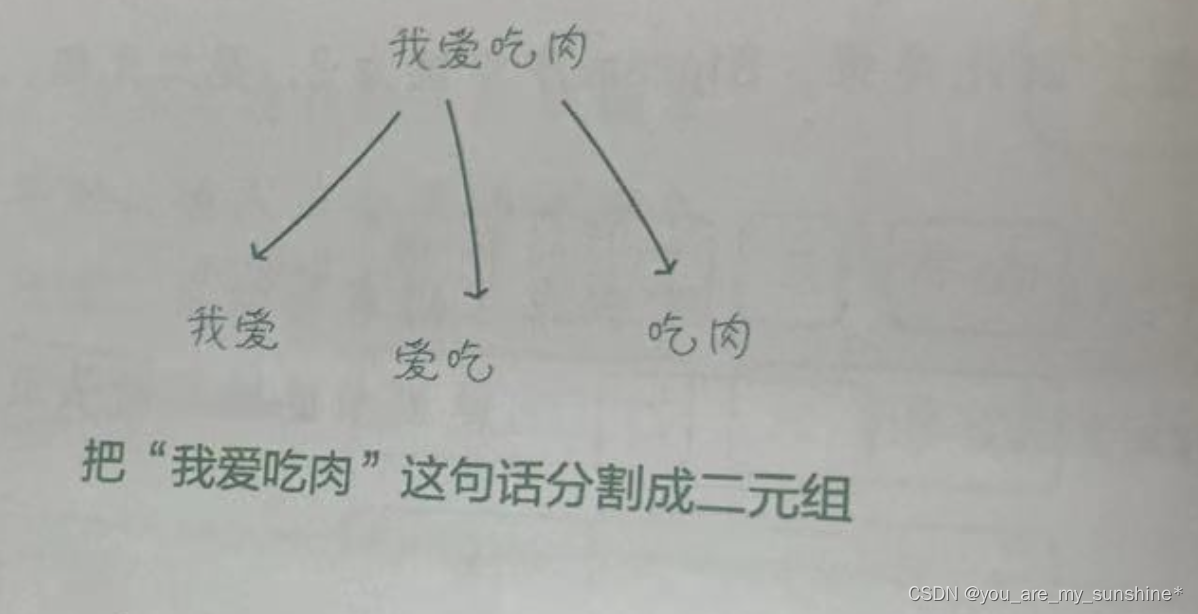
2.统计每个N-Gram在文本中出现的次数,也就是词频
比如,二元组“我爱”在语料库中出现了3次(如下页图所示),即这个二元组的词频为3。

3.为了得到一个词在给定上下文中出现的概率,我们可以利用条件概率公式计算。具体来讲,就是计算给定前N-1个词时,下一个词出现的概率。这个概率可以通过计算某个N-Gram出现的次数与前N-1个词(前缀)出现的次数之比得到
比如,二元组“我爱”在语料库中出现了3次,而二元组的前缀“我”在语料库中出现了10次,则给定“我”,下一个词为“爱”的概率为30%(如下图所示)。

4.可以使用这些概率来预测文本中下一个词出现的可能性。多次迭代这个过程,甚至可以生成整个句子,也可以算出每个句子在语料库中出现的概率
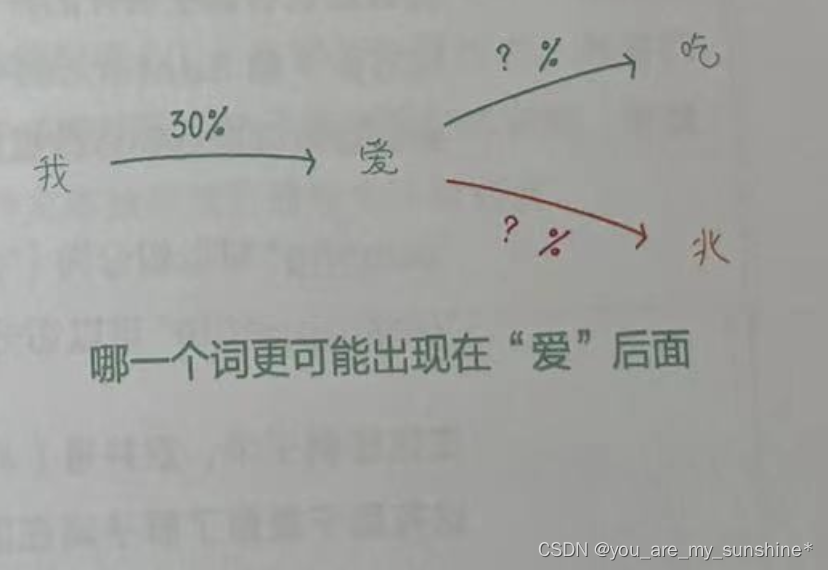
比如,从一个字“我”,生成“爱”,再继续生吃
成“吃”,直到“我爱吃肉”这个句子。计算“我爱”“爱吃”“吃肉”出现的概率,然后乘以各自的条件概率,就可以得到这个句子在语料库中出现的概率了。如上图所示。
“词”是什么,如何“分词”
在N-Gram 模型中,它表示文本中的一个元素,“N-Gram”指长度为N的连续元素序列。
这里的“元素”在英文中可以指单词,也可以指字符,有时还可以指“子词”(Subword );而在中文中,可以指词或者短语,也可以指字。
一般的自然语言处理工具包都为我们提供好了分词的工具。比如,英文分词通常使用 NLTK、spaCy等自然语言处理库,中文分词通常使用jieba库(中文NLP工具包),而如果你将来会用到BERT这样的预训 I练模型,那么你就需要使用BERT 的专属分词器Tokenizer,它会把每个单词拆成子词一这是 BERT处理生词的方法。
创建一个Bigram字符预测模型
1.构建实验语料库
# 构建一个数据集
corpus = ["小张每天喜欢学习","小张周末喜欢徒步","小李工作日喜欢加班","小李周末喜欢爬山","小张周末喜欢爬山","小李不喜欢躺平"]
2.把句子分成N个Gram(分词)
# 定义一个分词函数,将文本转换为单个字符的列表
def tokenize(text):return [char for char in text] # 将文本拆分为字符列表
# 对每个文本进行分词,并打印出对应的单字列表
print("单字列表:")
for text in corpus:tokens = tokenize(text)print(tokens)

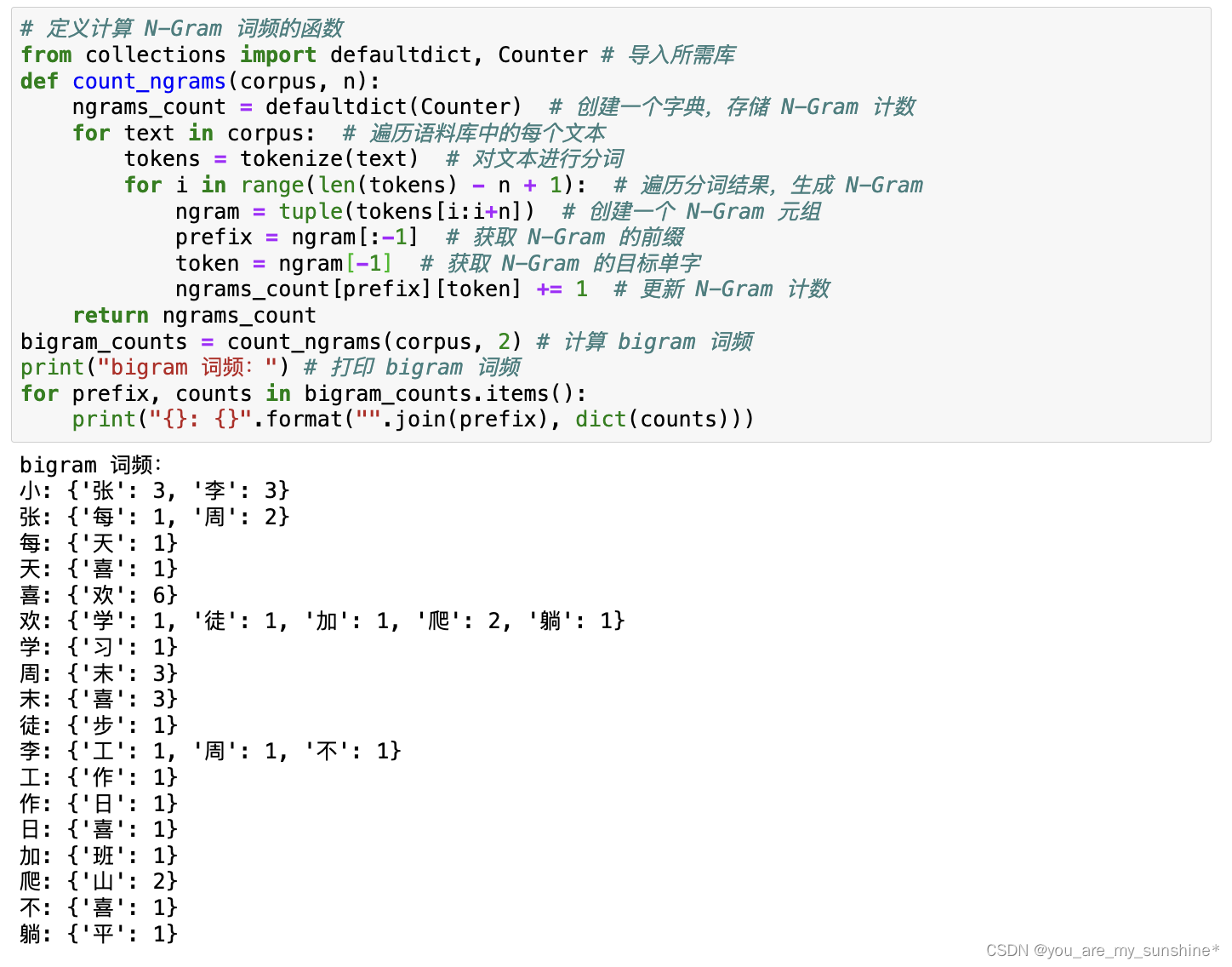
3.计算每个Bigram在语料库中的词频
# 定义计算 N-Gram 词频的函数
from collections import defaultdict, Counter # 导入所需库
def count_ngrams(corpus, n):ngrams_count = defaultdict(Counter) # 创建一个字典,存储 N-Gram 计数for text in corpus: # 遍历语料库中的每个文本tokens = tokenize(text) # 对文本进行分词for i in range(len(tokens) - n + 1): # 遍历分词结果,生成 N-Gramngram = tuple(tokens[i:i+n]) # 创建一个 N-Gram 元组prefix = ngram[:-1] # 获取 N-Gram 的前缀token = ngram[-1] # 获取 N-Gram 的目标单字ngrams_count[prefix][token] += 1 # 更新 N-Gram 计数return ngrams_count
bigram_counts = count_ngrams(corpus, 2) # 计算 bigram 词频
print("bigram 词频:") # 打印 bigram 词频
for prefix, counts in bigram_counts.items():print("{}: {}".format("".join(prefix), dict(counts)))
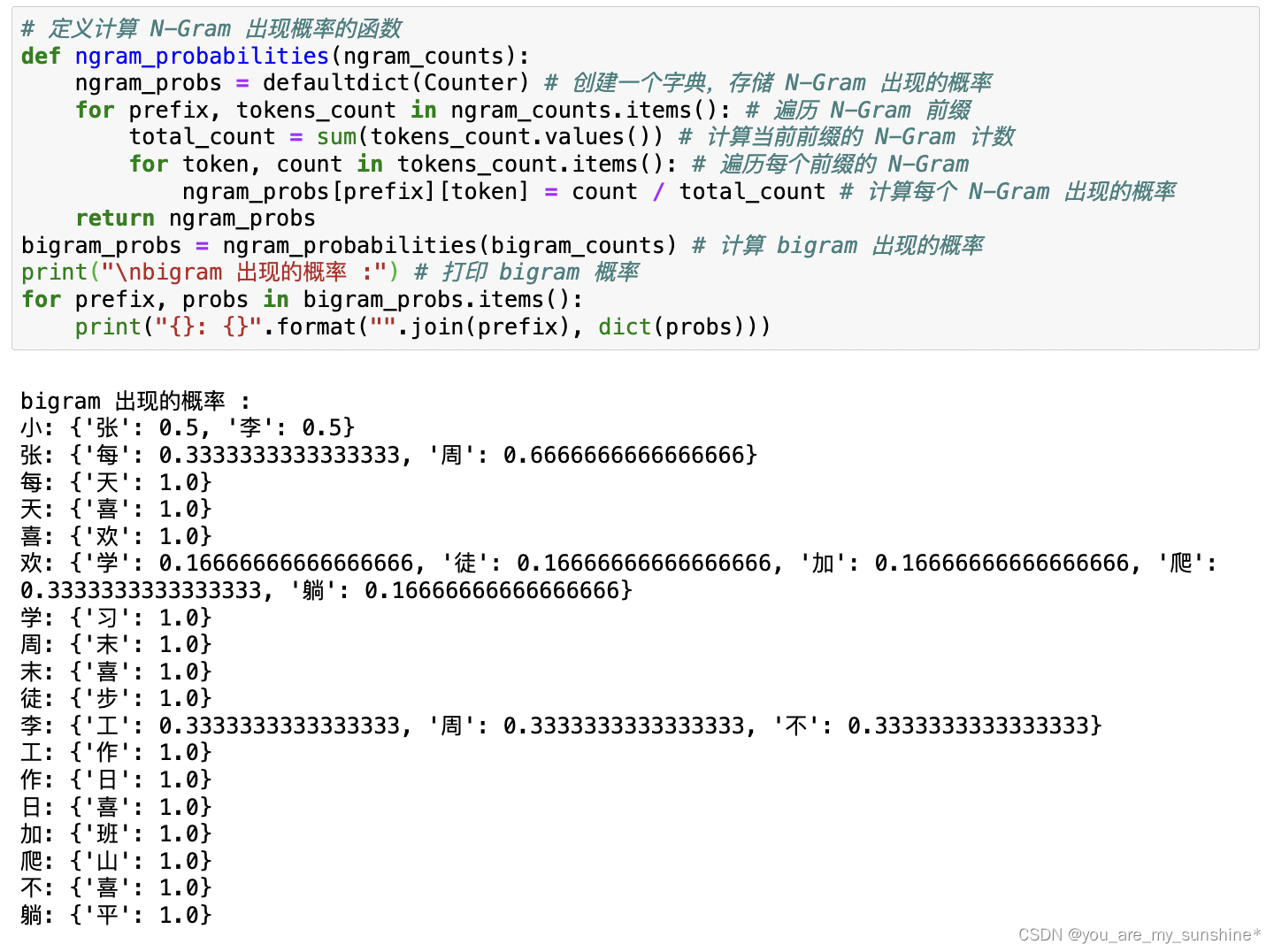
4.计算每个Bigram的出现概率
# 定义计算 N-Gram 出现概率的函数
def ngram_probabilities(ngram_counts):ngram_probs = defaultdict(Counter) # 创建一个字典,存储 N-Gram 出现的概率for prefix, tokens_count in ngram_counts.items(): # 遍历 N-Gram 前缀total_count = sum(tokens_count.values()) # 计算当前前缀的 N-Gram 计数for token, count in tokens_count.items(): # 遍历每个前缀的 N-Gramngram_probs[prefix][token] = count / total_count # 计算每个 N-Gram 出现的概率return ngram_probs
bigram_probs = ngram_probabilities(bigram_counts) # 计算 bigram 出现的概率
print("\nbigram 出现的概率 :") # 打印 bigram 概率
for prefix, probs in bigram_probs.items():print("{}: {}".format("".join(prefix), dict(probs)))
5.根据Bigram出现的概率,定义生成下一个词的函数
# 定义生成下一个词的函数
def generate_next_token(prefix, ngram_probs):if not prefix in ngram_probs: # 如果前缀不在 N-Gram 中,返回 Nonereturn Nonenext_token_probs = ngram_probs[prefix] # 获取当前前缀的下一个词的概率next_token = max(next_token_probs, key=next_token_probs.get) # 选择概率最大的词作为下一个词return next_token
6.输入一个前缀,生成连续文本
# 定义生成连续文本的函数
def generate_text(prefix, ngram_probs, n, length=8):tokens = list(prefix) # 将前缀转换为字符列表for _ in range(length - len(prefix)): # 根据指定长度生成文本 # 获取当前前缀的下一个词next_token = generate_next_token(tuple(tokens[-(n-1):]), ngram_probs) if not next_token: # 如果下一个词为 None,跳出循环breaktokens.append(next_token) # 将下一个词添加到生成的文本中return "".join(tokens) # 将字符列表连接成字符串
# 输入一个前缀,生成文本
generated_text = generate_text("小", bigram_probs, 2)
print("\n 生成的文本:", generated_text) # 打印生成的文本

N-Gram 模型小结
N-Gram 是一种用于语言建模的技术,它用来估计文本中词序列的概率分布。 N-Gram 模型将文本看作一个由词序列构成的随机过程,根据已有的文本数据,计算出词序列出现的概率。因此,N-Gram主要用于语言建模、文本生成、语音识别等自然语言处理任务中。
- (1)N-Gram是一种基于连续词序列的文本表示方法。它将文本分割成由连续的 N个词组成的片段,从而捕捉局部语序信息。
- (2)N-Gram 可以根据不同的N值捕捉不同程度的上下文信息。例如,1-Gram(Unigram)仅关注单个词,而2-Gram(Bigram)关注相邻的两个词的组合,以此类推。
- (3)随着N的增加,模型可能会遇到数据稀疏性问题,导致模型性能下降。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…
相关文章:
NLP_语言模型的雏形 N-Gram 模型
文章目录 N-Gram 模型1.将给定的文本分割成连续的N个词的组合(N-Gram)2.统计每个N-Gram在文本中出现的次数,也就是词频3.为了得到一个词在给定上下文中出现的概率,我们可以利用条件概率公式计算。具体来讲,就是计算给定前N-1个词时࿰…...

mac电脑flutter环境配置,解决疑难问题
准备工作 首先搭建flutter的环境需要使用到flutter的sdk,可以直接跳去官网下载:Choose your first type of app - Flutter 中文文档 - Flutter 中文开发者网站 - Flutter,下载时要注意你电脑所使用的芯片是Intel的还是苹果的芯片。 下载好的…...

C++ bool 布尔类型
在C 中 bool类型占用1个字节长度,bool 类型只有两个取值,true 和 false,true 表示“真”,false 表示“假”。 需要注意的C中使用cout 打印的时候是没有true 和 false 的 只有0和1 ,这里0表示假,非0表示真 …...
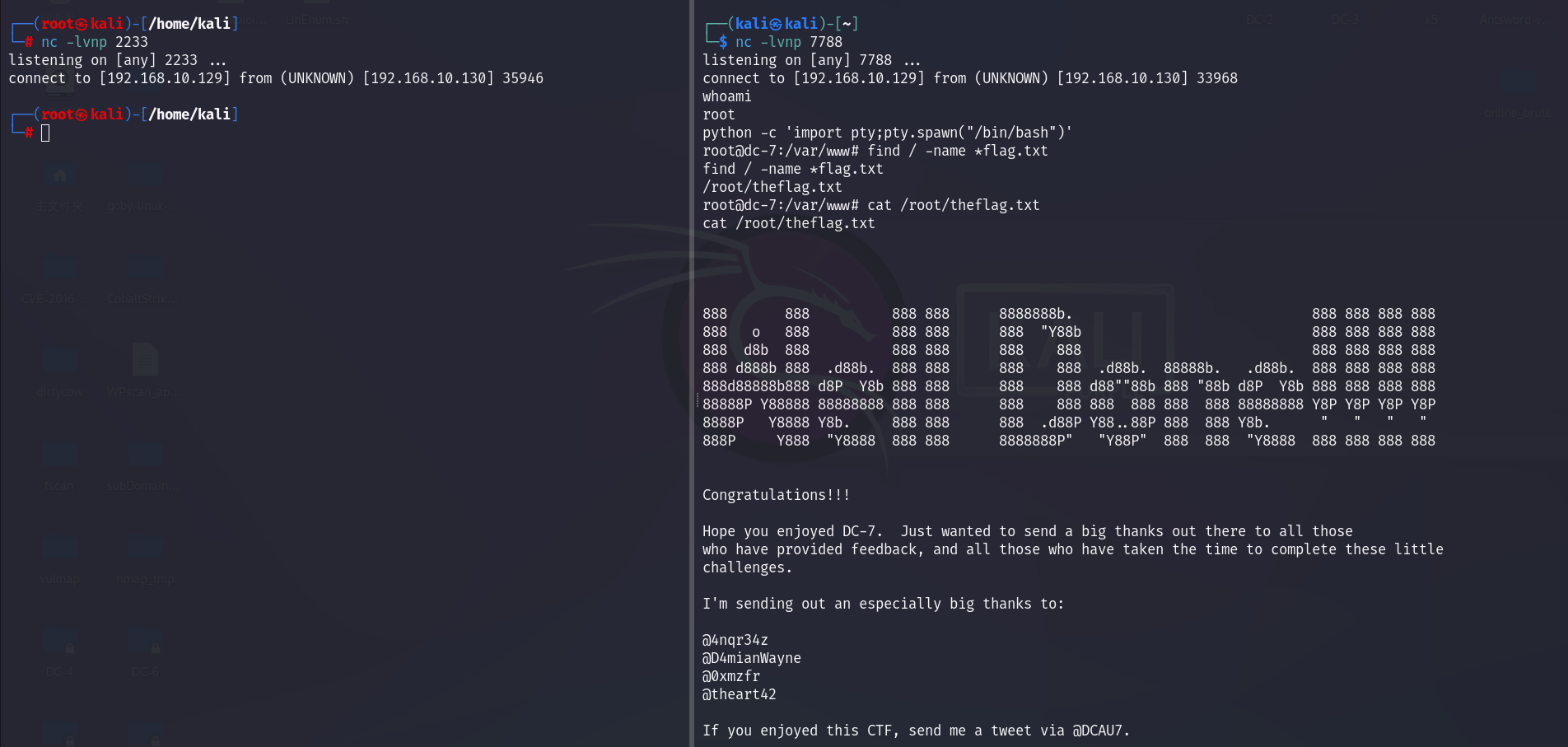
DC-7靶机渗透详细流程
信息收集: 1.存活扫描: 由于靶机和kali都是nat的网卡,都在一个网段,我们用arp-scan会快一点: arp-scan arp-scan -I eth0 -l └─# arp-scan -I eth0 -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:dd:ee:6…...

提速MySQL:数据库性能加速策略全解析
提速MySQL:数据库性能加速策略全解析 引言理解MySQL性能指标监控和评估性能指标索引优化技巧索引优化实战案例 查询优化实战查询优化案例分析 存储引擎优化InnoDB vs MyISAM选择和优化存储引擎存储引擎优化实例 配置调整与系统优化配置调整系统优化优化实例 实战案例…...
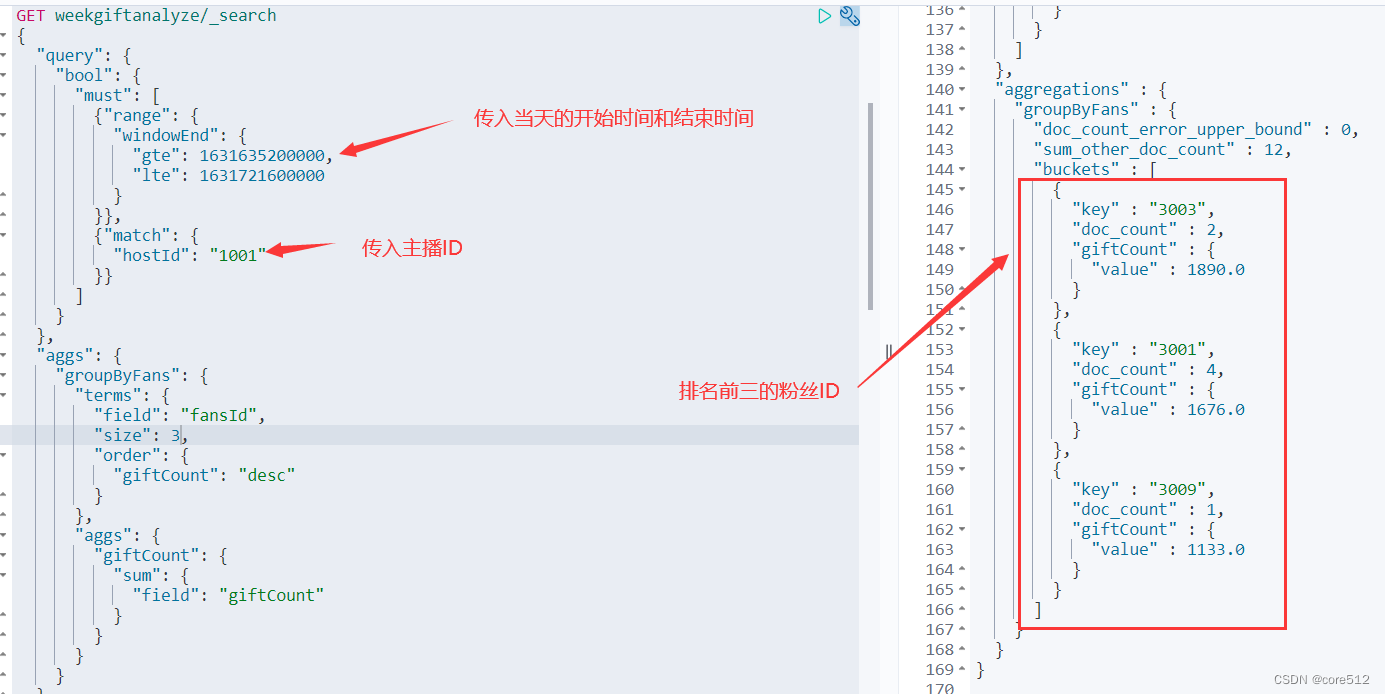
Flink实战六_直播礼物统计
接上文:Flink实战五_状态机制 1、需求背景 现在网络直播平台非常火爆,在斗鱼这样的网络直播间,经常可以看到这样的总榜排名,体现了主播的人气值。 人气值计算规则:用户发送1条弹幕互动,赠送1个荧光棒免费…...
 | Scaffold - 脚手架)
Compose | UI组件(十五) | Scaffold - 脚手架
文章目录 前言一、Scaffold脚手架简介二、Scaffold的主要组件三、如何使用Scaffold四、Compose中Scaffold脚手架的具体例子例子1:基本Scaffold布局例子2:带有Drawer的Scaffold布局例子3:带有Snackbar的Scaffold布局 总结 前言 Compose中的Sca…...

Vue-60、Vue技术router-link的replace属性
1、作用:控制路由跳转时操作浏览器历史记录的模式 2、浏览器的历史记录有两种写入方式:分别是push和replace,push是追加历史记录,replace是替换当前记录。路由跳转时候默认为push 3、如何开启replace模式: <router-link rep…...

Hive与Presto中的列转行区别
Hive与Presto列转行的区别 1、背景描述2、Hive/Spark列转行3、Presto列转行 1、背景描述 在处理数据时,我们经常会遇到一个字段存储多个值,这时需要把一行数据转换为多行数据,形成标准的结构化数据 例如,将下面的两列数据并列转换…...

探讨CSDN等级制度:博客等级、原力等级、创作者等级
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...

2.8作业
sqlite3数据库操作接口详细整理,以及常用的数据库语句 头文件: #include <sqlite3.h> 编译时候要加上-lsqlite3 gcc a.c -lsqlite3 1)sqlite3_open 打开一个数据库,如果数据库不存在,则创建一个数据库 2&am…...

机器学习中常用的性能度量—— ROC 和 AUC
什么是泛化能力? 通常我们用泛化能力来评判一个模型的好坏,通俗的说,泛化能力是指一个机器学期算法对新样本(即模型没有见过的样本)的举一反三的能力,也就是学以致用的能力。 举个例子,高三的…...

微服务入门篇:Nacos注册中心(Nacos安装,快速入门,多级存储,负载均衡,环境隔离,配置管理,热更新,集群搭建,nginx反向代理)
目录 1.Nacos安装1.官网下载2.解压到本地3.启动nacos 2.Nacos快速入门1.在父工程中导入nacos依赖2.给子项目添加客户端依赖3.修改对应服务的配置文件4.启动服务,查看nacos发现情况 3.Nacos服务多级存储模型4.NacosRule负载均衡5. 服务实例的权重设置6.环境隔离&…...

解决CORS错误(Spring Boot)
记录一下错误,以博客的形式 前言 跨域(Cross-Origin)是指在Web开发中,当一个Web应用试图从一个源(域名、协议、端口组合)获取资源时,该请求的目标与当前页面的源不同。具体来说,当一…...
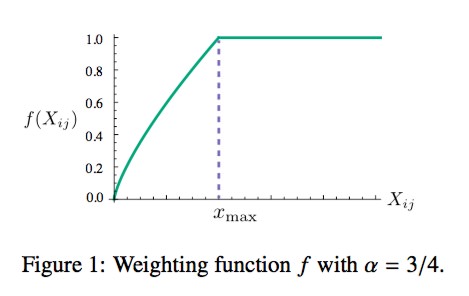
NLP入门系列—词嵌入 Word embedding
NLP入门系列—词嵌入 Word embedding 2013年,Word2Vec横空出世,自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的wor…...

JUnit5单元测试框架提供的注解
目录 第一章、注释在类上的注解1.1)JUnit5注释在类上的注解集成测试:SpringBootTest集成测试:ExtendWith(SpringExtension.class)单元测试:ExtendWith(MockitoExtension.class)切片测试:WebMvcTest和DataJpaTest<font colorred…...
ThinkPHP 中使用Redis
环境.env [app] app_debug "1" app_trace ""[database] database "" hostname "127.0.0.1" hostport "" password "" prefix "ls_" username ""[redis] hostname "127.0.0.1…...

Go语言Gin框架安全加固:全面解析SQL注入、XSS与CSRF的解决方案
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站https://www.captainbed.cn/kitie。 前言 在使用 Gin 框架处理前端请求数据时,必须关注安全性问题,以防范常见的攻击…...

MySQL数据库基础与SELECT语句使用梳理
MySQL数据库基础与SELECT语句使用梳理 注意:本文操作全部在终端进行 数据库基础知识 什么是数据库 数据库(database)是保存有组织的数据的容器(通常是一个文件或一组文件),实质上数据库是一个以某种 有组…...

scikit-learn 1.3.X 版本 bug - F1 分数计算错误
如果您正在使用 scikit-learn 1.3.X 版本,在使用 f1_score() 或 classification_report() 函数时,如果参数设置为 zero_division1.0 或 zero_divisionnp.nan,那么函数的输出结果可能会出错。错误的范围可能高达 100%,具体取决于数…...

神经高利贷:预支未来技能导致认知崩溃
在软件测试领域,从业者常面临一个隐形威胁:过度追求新技能而忽视认知极限,最终引发崩溃。这种现象被称为“神经高利贷”,即通过预支未来学习能力来应对当前挑战,结果导致认知资源枯竭、错误率飙升,甚至职业…...
)
S32DS隐藏技巧:用FTM定时器实现精准延时(替代低效for循环)
S32DS隐藏技巧:用FTM定时器实现精准延时(替代低效for循环) 在嵌入式开发中,延时功能几乎是每个项目都无法绕开的基础需求。从简单的LED闪烁到复杂的通信协议时序控制,精准的延时控制直接影响着系统的稳定性和响应速度。…...

Qt安卓开发实战:从红米K60调试到多机型适配指南
1. Qt安卓开发环境准备 搞Qt安卓开发,首先得把环境搭好。这里假设你已经按照官方文档或者教程配置好了Qt Creator和Android SDK/NDK。如果还没搞定,建议先去Qt官网把Android开发套件下载齐全,包括: Qt for Android(建议…...

Frida启动报错invalid address?手把手教你修复Android逆向工程环境
Frida启动报错invalid address?手把手教你修复Android逆向工程环境 当你满怀期待地启动Frida准备进行Android应用动态分析时,控制台突然抛出"invalid address"错误,那种感觉就像赛车手在起跑线上发现引擎故障。这个看似简单的错误信…...

Element React:革新性UI组件库助力React开发者高效构建企业级应用界面
Element React:革新性UI组件库助力React开发者高效构建企业级应用界面 【免费下载链接】element-react Element UI 项目地址: https://gitcode.com/gh_mirrors/el/element-react 在现代Web应用开发中,界面构建往往占据了开发者大量时间与精力。El…...

如何快速解放双手:MaaYuan游戏日常任务自动化完整指南
如何快速解放双手:MaaYuan游戏日常任务自动化完整指南 【免费下载链接】MaaYuan 代号鸢 / 如鸢 一键长草小助手 项目地址: https://gitcode.com/gh_mirrors/ma/MaaYuan 厌倦了每天花费大量时间在重复的游戏日常任务上吗?MaaYuan作为一款免费开源的…...

3步实现B站视频音频高效下载:BilibiliDown终极解决方案全指南
3步实现B站视频音频高效下载:BilibiliDown终极解决方案全指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mi…...

罗斯蒙特RoseMount手操器TREXLFPKL9S1
罗斯蒙特475手操器是一款由艾默生(Emerson)推出的高性能现场通讯设备,广泛应用于工业自动化领域,用于配置、校准和诊断HART及Foundation Fieldbus协议的智能仪表设备。它具备彩色图形界面、蓝牙通信、强大的现场诊断功能和可用户升…...

STM32 USART串口调试避坑指南:从波特率配置到数据帧异常排查
STM32 USART串口调试避坑指南:从波特率配置到数据帧异常排查 在嵌入式开发中,USART串口通信是最基础却又最容易出问题的环节之一。许多开发者都曾经历过这样的场景:代码编译通过,硬件连接无误,但串口就是无法正常通信&…...

无人机远程识别系统如何解决合规飞行的技术痛点:基于ESP32的开源实现方案
无人机远程识别系统如何解决合规飞行的技术痛点:基于ESP32的开源实现方案 【免费下载链接】ArduRemoteID RemoteID support using OpenDroneID 项目地址: https://gitcode.com/gh_mirrors/ar/ArduRemoteID 随着全球无人机监管政策的收紧,远程识别…...