3.0 Hadoop 概念
本章着重介绍 Hadoop 中的概念和组成部分,属于理论章节。如果你比较着急可以跳过。但作者不建议跳过,因为它与后面的章节息息相关。
Hadoop 整体设计
Hadoop 框架是用于计算机集群大数据处理的框架,所以它必须是一个可以部署在多台计算机上的软件。部署了 Hadoop 软件的主机之间通过套接字 (网络) 进行通讯。
Hadoop 主要包含 HDFS 和 MapReduce 两大组件,HDFS 负责分布储存数据,MapReduce 负责对数据进行映射、规约处理,并汇总处理结果。
Hadoop 框架最根本的原理就是利用大量的计算机同时运算来加快大量数据的处理速度。例如,一个搜索引擎公司要从上万亿条没有进行规约的数据中筛选和归纳热门词汇就需要组织大量的计算机组成集群来处理这些信息。如果使用传统数据库来处理这些信息的话,那将会花费很长的时间和很大的处理空间来处理数据,这个量级对于任何单计算机来说都变得难以实现,主要难度在于组织大量的硬件并高速地集成为一个计算机,即使成功实现也会产生昂贵的维护成本。
Hadoop 可以在多达几千台廉价的量产计算机上运行,并把它们组织为一个计算机集群。
一个 Hadoop 集群可以高效地储存数据、分配处理任务,这样会有很多好处。首先可以降低计算机的建造和维护成本,其次,一旦任何一个计算机出现了硬件故障,不会对整个计算机系统造成致命的影响,因为面向应用层开发的集群框架本身就必须假定计算机会出故障。
HDFS
Hadoop Distributed File System,Hadoop 分布式文件系统,简称 HDFS。
HDFS 用于在集群中储存文件,它所使用的核心思想是 Google 的 GFS 思想,可以存储很大的文件。
在服务器集群中,文件存储往往被要求高效而稳定,HDFS同时实现了这两个优点。
HDFS 高效的存储是通过计算机集群独立处理请求实现的。因为用户 (一半是后端程序) 在发出数据存储请求时,往往响应服务器正在处理其他请求,这是导致服务效率缓慢的主要原因。但如果响应服务器直接分配一个数据服务器给用户,然后用户直接与数据服务器交互,效率会快很多。
数据存储的稳定性往往通过"多存几份"的方式实现,HDFS 也使用了这种方式。HDFS 的存储单位是块 (Block) ,一个文件可能会被分为多个块储存在物理存储器中。因此 HDFS 往往会按照设定者的要求把数据块复制 n 份并存储在不同的数据节点 (储存数据的服务器) 上,如果一个数据节点发生故障数据也不会丢失。
HDFS 的节点
HDFS 运行在许多不同的计算机上,有的计算机专门用于存储数据,有的计算机专门用于指挥其它计算机储存数据。这里所提到的"计算机"我们可以称之为集群中的节点。
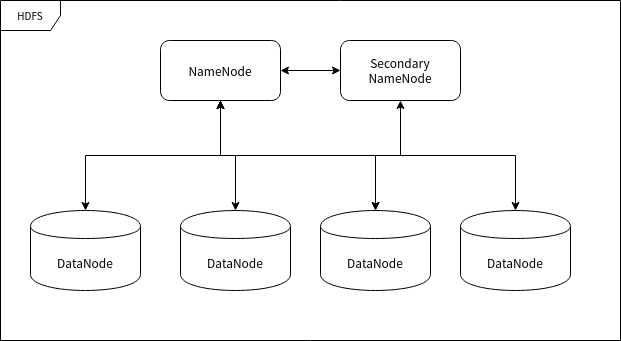
命名节点 (NameNode)
命名节点 (NameNode) 是用于指挥其它节点存储的节点。任何一个"文件系统"(File System, FS) 都需要具备根据文件路径映射到文件的功能,命名节点就是用于储存这些映射信息并提供映射服务的计算机,在整个 HDFS 系统中扮演"管理员"的角色,因此一个 HDFS 集群中只有一个命名节点。
数据节点 (DataNode)
数据节点 (DataNode) 使用来储存数据块的节点。当一个文件被命名节点承认并分块之后将会被储存到被分配的数据节点中去。数据节点具有储存数据、读写数据的功能,其中存储的数据块比较类似于硬盘中的"扇区"概念,是 HDFS 存储的基本单位。
副命名节点 (Secondary NameNode)
副命名节点 (Secondary NameNode) 别名"次命名节点",是命名节点的"秘书"。这个形容很贴切,因为它并不能代替命名节点的工作,无论命名节点是否有能力继续工作。它主要负责分摊命名节点的压力、备份命名节点的状态并执行一些管理工作,如果命名节点要求它这样做的话。如果命名节点坏掉了,它也可以提供备份数据以恢复命名节点。副命名节点可以有多个。
MapReduce
MapReduce 的含义就像它的名字一样浅显:Map 和 Reduce (映射和规约) 。
大数据处理
大量数据的处理是一个典型的"道理简单,实施复杂"的事情。之所以"实施复杂",主要是大量的数据使用传统方法处理时会导致硬件资源 (主要是内存) 不足。
现在有一段文字 (真实环境下这个字符串可能长达 1 PB 甚至更多) ,我们执行一个简单的"数字符"统计,即统计出这段文字中所有出现过的字符出现的数量:
AABABCABCDABCDE
统计之后的结果应该是:
| 字符 | 出现次数 |
|---|---|
| A | 5 |
| B | 4 |
| C | 3 |
| D | 2 |
| E | 1 |
统计的过程实际上很简单,就是每读取一个字符就要检查表中是否已经有相同的字符,如果没有就添加一条记录并将记录值设置为 1 ,如果有的话就直接将记录值增加 1。
但是如果我们将这里的统计对象由"字符"变成"词",那么样本容量就瞬间变得非常大,以至于一台计算机可能难以统计数十亿用户一年来用过的"词"。
在这种情况下我们依然有办法完成这项工作——我们先把样本分成一段段能够令单台计算机处理的规模,然后一段段地进行统计,每执行完一次统计就对映射统计结果进行规约处理,即将统计结果合并到一个更庞大的数据结果中去,最终就可以完成大规模的数据规约。
在以上的案例中,第一阶段的整理工作就是"映射",把数据进行分类和整理,到这里为止,我们可以得到一个相比于源数据小很多的结果。第二阶段的工作往往由集群来完成,整理完数据之后,我们需要将这些数据进行总体的归纳,毕竟有可能多个节点的映射结果出现重叠分类。这个过程中映射的结果将会进一步缩略成可获取的统计结果。
MapReduce 概念
我在 IBM 的网站上找到了一篇 MapReduce 文章,地址:What is Apache MapReduce? | IBM 。现在我改编其中的一个 MapReduce 的处理案例来介绍 MapReduce 的原理细节以及相关概念。
这是一个非常简单的 MapReduce 示例。无论需要分析多少数据,关键原则都是相同的。
假设有 5 个文件,每个文件包含两列,分别记录一个城市的名称以及该城市在不同测量日期记录的相应温度。城市名称是键 (Key) ,温度是值 (Value) 。例如:(厦门,20)。现在我们要在所有数据中找到每个城市的最高温度 (请注意,每个文件中可能出现相同的城市)。
使用 MapReduce 框架,我们可以将其分解为 5 个映射任务,其中每个任务负责处理五个文件中的一个。每个映射任务会检查文件中的每条数据并返回该文件中每个城市的最高温度。
例如,对于以下数据:
| 城市 | 温度 |
|---|---|
| 厦门 | 12 |
| 上海 | 34 |
| 厦门 | 20 |
| 上海 | 15 |
| 北京 | 14 |
| 北京 | 16 |
| 厦门 | 24 |
上述数据的一个映射任务产生的结果如下所示:
| 城市 | 最高温度 |
|---|---|
| 厦门 | 24 |
| 上海 | 34 |
| 北京 | 16 |
假设其他四个映射器任务产生以下结果:
| 城市 | 最高温度 |
|---|---|
| 厦门 | 17 |
| 杭州 | 25 |
| 上海 | 29 |
| 北京 | 36 |
| 厦门 | 30 |
| 杭州 | 17 |
| 上海 | 31 |
| 北京 | 35 |
| 厦门 | 18 |
| 杭州 | 17 |
| 上海 | 17 |
| 北京 | 27 |
| 厦门 | 28 |
| 杭州 | 18 |
| 上海 | 14 |
| 北京 | 27 |
所有这 5 个结果将被输入到 Reduce 任务中,该任务组合输入结果并输出每个城市的单个值,产生如下的最终结果:
| 城市 | 最高温度 |
|---|---|
| 厦门 | 30 |
| 上海 | 34 |
| 北京 | 36 |
| 杭州 | 25 |
打个比方,你可以把 MapReduce 想象成人口普查,人口普查局会把若干个调查员派到每个城市。每个城市的每个人口普查人员都将统计该市的部分人口数量,然后将结果汇总返回首都。在首都,每个城市的统计结果将被规约到单个计数(各个城市的人口),然后就可以确定国家的总人口。这种人到城市的映射是并行的,然后合并结果(Reduce)。这比派一个人以连续的方式清点全国中的每一个人效率高得多。
希望你也学会了,更多编程源码模板请来二当家的素材网:https://www.erdangjiade.com
相关文章:
3.0 Hadoop 概念
本章着重介绍 Hadoop 中的概念和组成部分,属于理论章节。如果你比较着急可以跳过。但作者不建议跳过,因为它与后面的章节息息相关。 Hadoop 整体设计 Hadoop 框架是用于计算机集群大数据处理的框架,所以它必须是一个可以部署在多台计算机上…...

mysql 对于null字段排序处理
最近遇到一个需求 ,需要对一个报表的多个字段进行多字段复杂条件排序 排序字段为NULL时 Mysql对于排序字段为NULL时,有自身默认的排序规则,默认是认为null 值 是无穷小 ELECT id,script_id,last_modified,live_count,next_show FROM virtua…...

NLP_语言模型的雏形 N-Gram 模型
文章目录 N-Gram 模型1.将给定的文本分割成连续的N个词的组合(N-Gram)2.统计每个N-Gram在文本中出现的次数,也就是词频3.为了得到一个词在给定上下文中出现的概率,我们可以利用条件概率公式计算。具体来讲,就是计算给定前N-1个词时࿰…...

mac电脑flutter环境配置,解决疑难问题
准备工作 首先搭建flutter的环境需要使用到flutter的sdk,可以直接跳去官网下载:Choose your first type of app - Flutter 中文文档 - Flutter 中文开发者网站 - Flutter,下载时要注意你电脑所使用的芯片是Intel的还是苹果的芯片。 下载好的…...

C++ bool 布尔类型
在C 中 bool类型占用1个字节长度,bool 类型只有两个取值,true 和 false,true 表示“真”,false 表示“假”。 需要注意的C中使用cout 打印的时候是没有true 和 false 的 只有0和1 ,这里0表示假,非0表示真 …...
DC-7靶机渗透详细流程
信息收集: 1.存活扫描: 由于靶机和kali都是nat的网卡,都在一个网段,我们用arp-scan会快一点: arp-scan arp-scan -I eth0 -l └─# arp-scan -I eth0 -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:dd:ee:6…...

提速MySQL:数据库性能加速策略全解析
提速MySQL:数据库性能加速策略全解析 引言理解MySQL性能指标监控和评估性能指标索引优化技巧索引优化实战案例 查询优化实战查询优化案例分析 存储引擎优化InnoDB vs MyISAM选择和优化存储引擎存储引擎优化实例 配置调整与系统优化配置调整系统优化优化实例 实战案例…...
Flink实战六_直播礼物统计
接上文:Flink实战五_状态机制 1、需求背景 现在网络直播平台非常火爆,在斗鱼这样的网络直播间,经常可以看到这样的总榜排名,体现了主播的人气值。 人气值计算规则:用户发送1条弹幕互动,赠送1个荧光棒免费…...
 | Scaffold - 脚手架)
Compose | UI组件(十五) | Scaffold - 脚手架
文章目录 前言一、Scaffold脚手架简介二、Scaffold的主要组件三、如何使用Scaffold四、Compose中Scaffold脚手架的具体例子例子1:基本Scaffold布局例子2:带有Drawer的Scaffold布局例子3:带有Snackbar的Scaffold布局 总结 前言 Compose中的Sca…...

Vue-60、Vue技术router-link的replace属性
1、作用:控制路由跳转时操作浏览器历史记录的模式 2、浏览器的历史记录有两种写入方式:分别是push和replace,push是追加历史记录,replace是替换当前记录。路由跳转时候默认为push 3、如何开启replace模式: <router-link rep…...

Hive与Presto中的列转行区别
Hive与Presto列转行的区别 1、背景描述2、Hive/Spark列转行3、Presto列转行 1、背景描述 在处理数据时,我们经常会遇到一个字段存储多个值,这时需要把一行数据转换为多行数据,形成标准的结构化数据 例如,将下面的两列数据并列转换…...

探讨CSDN等级制度:博客等级、原力等级、创作者等级
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...

2.8作业
sqlite3数据库操作接口详细整理,以及常用的数据库语句 头文件: #include <sqlite3.h> 编译时候要加上-lsqlite3 gcc a.c -lsqlite3 1)sqlite3_open 打开一个数据库,如果数据库不存在,则创建一个数据库 2&am…...

机器学习中常用的性能度量—— ROC 和 AUC
什么是泛化能力? 通常我们用泛化能力来评判一个模型的好坏,通俗的说,泛化能力是指一个机器学期算法对新样本(即模型没有见过的样本)的举一反三的能力,也就是学以致用的能力。 举个例子,高三的…...

微服务入门篇:Nacos注册中心(Nacos安装,快速入门,多级存储,负载均衡,环境隔离,配置管理,热更新,集群搭建,nginx反向代理)
目录 1.Nacos安装1.官网下载2.解压到本地3.启动nacos 2.Nacos快速入门1.在父工程中导入nacos依赖2.给子项目添加客户端依赖3.修改对应服务的配置文件4.启动服务,查看nacos发现情况 3.Nacos服务多级存储模型4.NacosRule负载均衡5. 服务实例的权重设置6.环境隔离&…...

解决CORS错误(Spring Boot)
记录一下错误,以博客的形式 前言 跨域(Cross-Origin)是指在Web开发中,当一个Web应用试图从一个源(域名、协议、端口组合)获取资源时,该请求的目标与当前页面的源不同。具体来说,当一…...
NLP入门系列—词嵌入 Word embedding
NLP入门系列—词嵌入 Word embedding 2013年,Word2Vec横空出世,自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的wor…...

JUnit5单元测试框架提供的注解
目录 第一章、注释在类上的注解1.1)JUnit5注释在类上的注解集成测试:SpringBootTest集成测试:ExtendWith(SpringExtension.class)单元测试:ExtendWith(MockitoExtension.class)切片测试:WebMvcTest和DataJpaTest<font colorred…...
ThinkPHP 中使用Redis
环境.env [app] app_debug "1" app_trace ""[database] database "" hostname "127.0.0.1" hostport "" password "" prefix "ls_" username ""[redis] hostname "127.0.0.1…...

Go语言Gin框架安全加固:全面解析SQL注入、XSS与CSRF的解决方案
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站https://www.captainbed.cn/kitie。 前言 在使用 Gin 框架处理前端请求数据时,必须关注安全性问题,以防范常见的攻击…...

巨有科技智慧市集系统,数字化工具降本增效!
从城市商圈到景区古镇,从乡村田园到文创园区,各类市集遍地开花,但管理难题始终是制约行业发展的最大瓶颈。人工登记杂乱、对账结算繁琐、现场管控滞后、数据完全空白,一场中型市集就要耗费大量人力物力,大型市集更是纠…...

Termius vs SecureCRT:为什么这款内置FTP的SSH工具更适合中文用户?
Termius vs SecureCRT:为什么这款内置FTP的SSH工具更适合中文用户? 作为开发者,每天与服务器打交道是家常便饭。选择一款趁手的SSH工具,就像程序员挑选键盘一样重要——不仅要功能强大,更要符合个人使用习惯。对于中文…...

ConcurrentHashMap讲解
在 Java 并发编程中,ConcurrentHashMap 是高频使用的线程安全 Map 实现,也是面试中几乎必问的核心知识点。它完美解决了 HashMap 线程不安全、Hashtable 性能极差的痛点,在高并发场景下实现了安全与性能的平衡。本文将从设计背景、JDK1.7/JDK…...
)
Python办公自动化:用PyMuPDF+pdfplumber一键提取PDF文字/图片/表格(附完整代码)
Python办公自动化实战:PyMuPDF与pdfplumber高效提取PDF三要素 每天面对堆积如山的PDF文档,行政和财务人员最头疼的莫过于手动复制粘贴文字、截图保存图片、重新绘制表格。我曾见过一位财务同事为了处理200份供应商报价单,连续加班一周手工录入…...

小米多看电纸书刷机全攻略:从墨案系统回退到原厂固件的保姆级教程
小米多看电纸书系统恢复指南:从第三方固件回归官方体验 作为一名长期使用电子墨水设备的深度用户,我完全理解那种尝试新系统后又怀念原厂体验的矛盾心理。去年冬天,我的小米多看电纸书也经历了从墨案系统回退到官方固件的完整过程,…...

SQL入门学习笔记
一、一些必备“常识” 数据库是指任何相关信息得集合,可以用不同的方式存储。(如:电话簿,购物清单) 两种主要的数据库类型:关系型数据库(SQL)例如mysql,postgresql(pg)与非关系型数据库(NoSQL)例如mogodb…...

Python离线环境搭建全攻略:从虚拟机到生产服务器的完整迁移方案
Python离线环境搭建全攻略:从虚拟机到生产服务器的完整迁移方案 在金融、军工等对网络安全要求极高的行业,服务器通常运行在完全隔离的离线环境中。这种环境下,如何部署Python运行环境并确保所有依赖库正常工作,成为许多运维工程师…...

任务式智能客服工作流架构设计与性能优化实战
最近在重构公司的智能客服系统,原来的系统在高并发时经常卡顿,用户排队时间长得让人抓狂。经过一番折腾,我们设计了一套基于事件驱动的任务式工作流,效果拔群,吞吐量直接翻了好几倍。今天就来聊聊这套架构的设计思路和…...

OpenRocket:重新定义模型火箭设计与仿真的开源力量
OpenRocket:重新定义模型火箭设计与仿真的开源力量 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 核心价值:破解模型火箭开发的效…...

清华大学学位论文LaTeX模板:thuthesis完整使用指南
清华大学学位论文LaTeX模板:thuthesis完整使用指南 【免费下载链接】thuthesis LaTeX Thesis Template for Tsinghua University 项目地址: https://gitcode.com/gh_mirrors/th/thuthesis 清华大学thuthesis LaTeX模板是专为清华学子设计的学位论文写作工具&…...