ElasticSearch之倒排索引
写在前面
本文看下es的倒排索引相关内容。
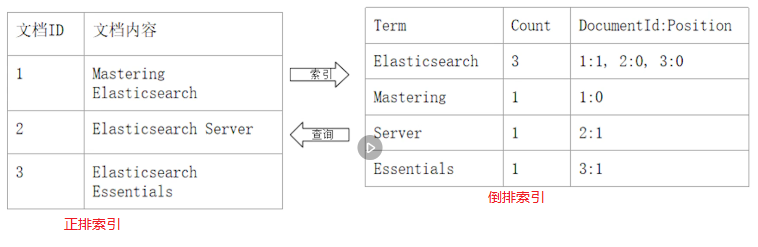
1:正排索引和倒排索引
正排索引就是通过文档id找文档内容,而倒排索引就是通过文档内容找文档id,如下图:
2:倒排索引原理
假定我们有如下的数据:
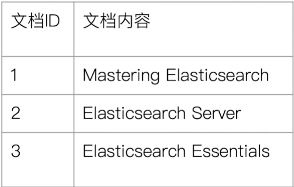
为了建立倒排索引,我们需要先对文档进行分词,如下:
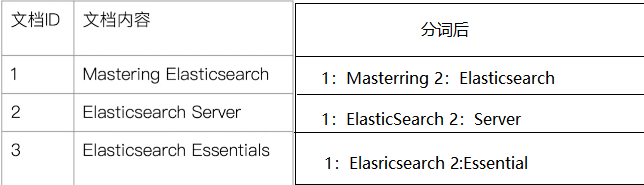
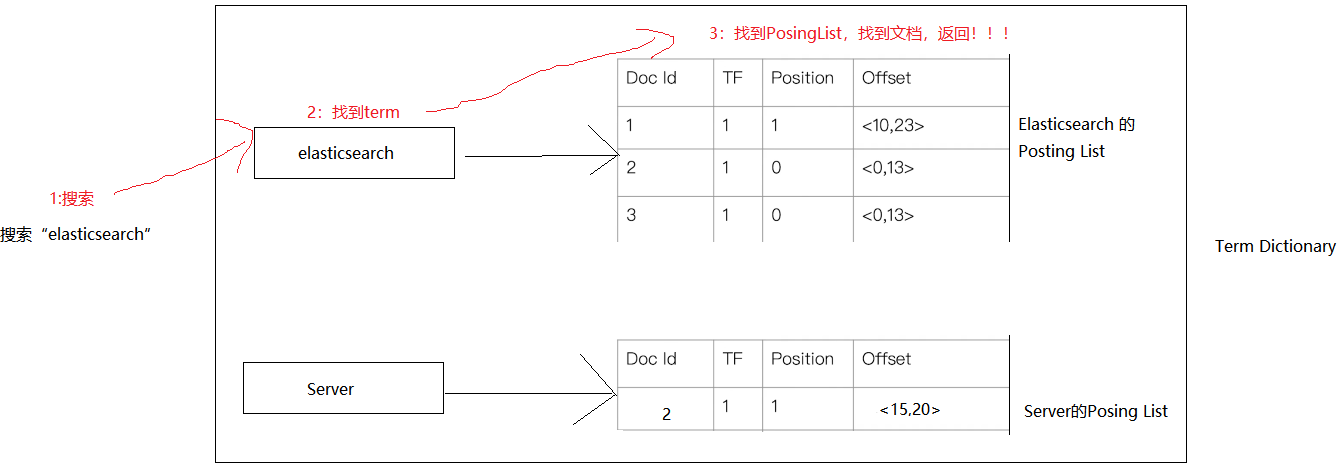
分词后每一个词有一个专门的名词来表示,叫做Term,term就是我们要搜索的目标,但是找到了term并不能找到文档,为了找到文档,每一个term对应一个[<文档id,偏移量,出现次数>]的数组,这个数组我们叫做Posting List,其中每个term对应一个Posing List,如下图:

为了方便查找term,term+Posing List组合在字典的数据结构,叫做Term Dictionary,(注意term是排好序的,所以可以顺序查找,后面会用到!!!),如下图:
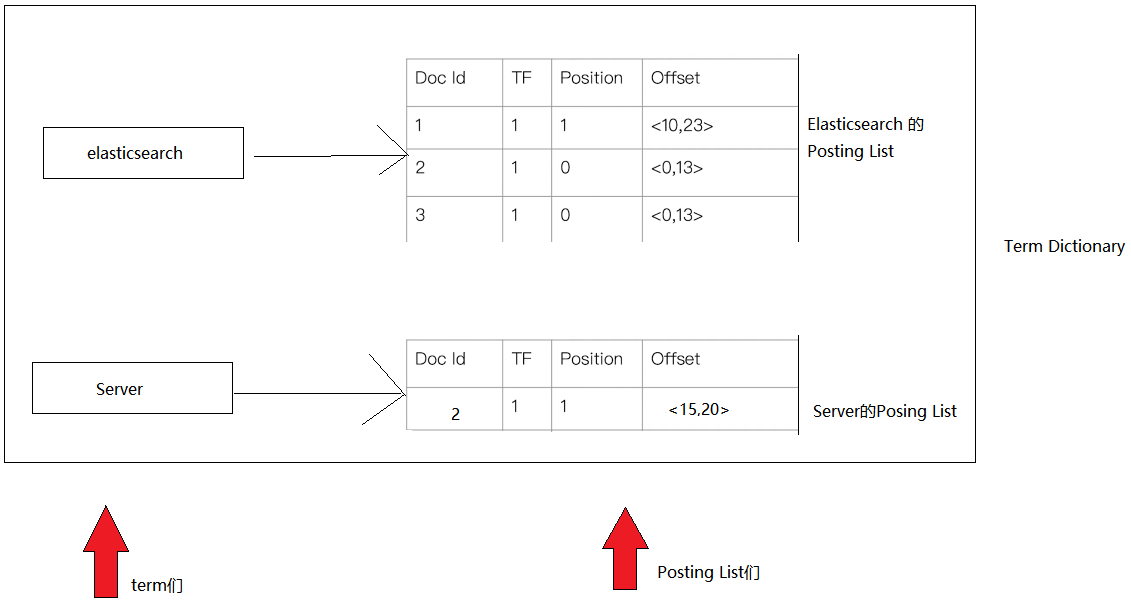
这样,当我们搜索Elasticsearch,可以通过Term Disctionary,查到对应的term,然后通过term就可以找到对应的PosingList,就找到文档了,这个过程如下:
但,实际上我们搜索的关键词,是没有办法直接按照上述流程找到term的,因为term dictionary比较大,是保存在磁盘上的,直接基于磁盘查找,速度就可想而知了,所以,es还设计了另外一种数据结果term index,用来在内存中保存关键词对应的term磁盘页位置,term index是一种基于trie tree的数据结构,大概如下图:
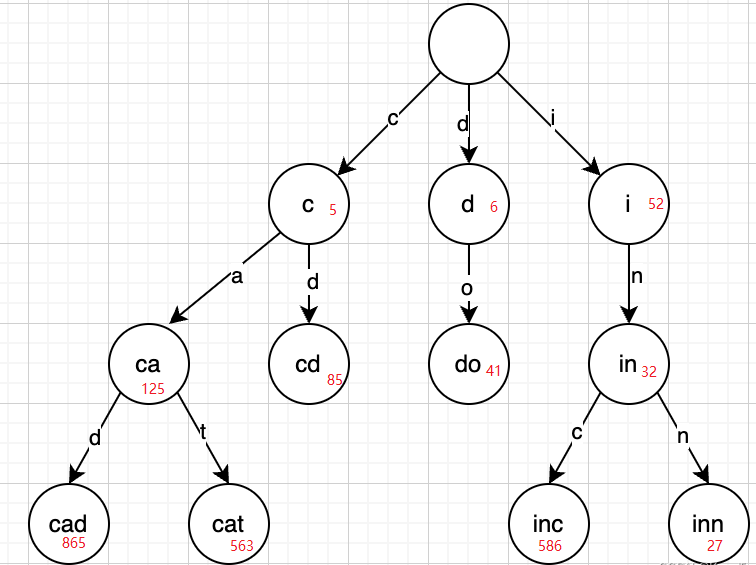
其中红色的就是位置信息,但是注意在term index中只会存储前缀,所以可以定位到一个大概的位置,而因为term是顺序存储的,所以可以顺序读盘,找到目标term,这里我们简单的以直接定位到term为例看下这个过程:
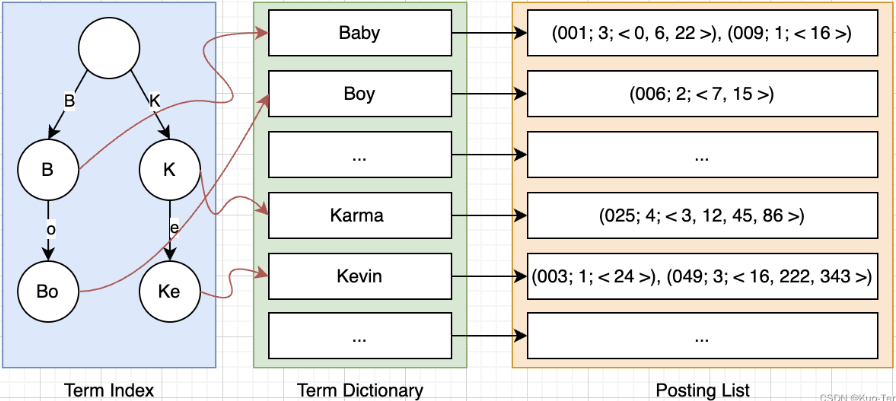
最后,es为了能够将term index存储在内存中,还是用了FST的算法,来压缩空间。则最终查找过程就如下图了:

以上过程分词是及其重要的一个环节,所以我们接下来也来看下分词相关的内容。
3:分词
3.1:什么是分词和分词器
分词:analysis,即将一句话分为多个词(term)的过程。
分词器:analyzer,完成分词这个操作的工具。
如下图:
所以,分词是个动词,分词器是个名词。
分词器在我们写入数据构建倒排索引的时候会用到,在输入一句话进行搜索的时候也会用到。
3.2:分词器的工作原理
一个标准的分词器由以下三部分组成:
Charancter Filters:对原始的内容进行处理,如删除html字符,等
Tokenizer:按照某种规则切分为一组单词(term),这部分功能不仅每种分词器都有,而且还可能包含Token Filters的功能(可以看作是分词器的非标准实现)
Token Filters:对切分后的次进行处理,如转小写,删除停用词等
如下简单例子:
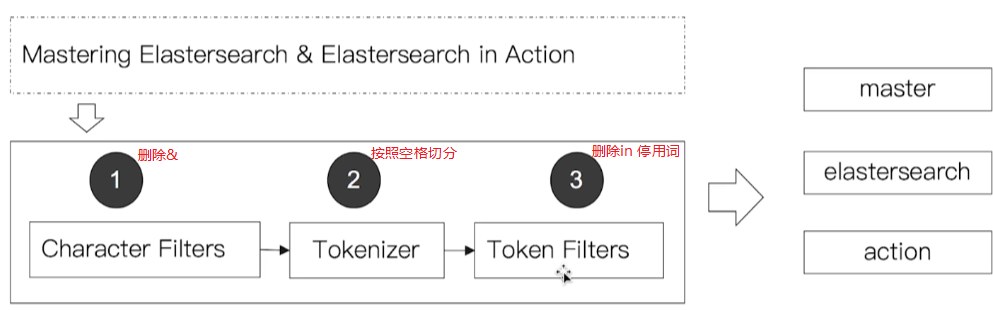
注意这只是一个标准的分词器需要具备的三个部分,但除了Tokennizer必须提供具体的实现外,Chracter Filters和Token Filters并不是必须提供实现的。
3.3:分词器都有哪些

为了方便你我们查看不同的分词效果,es提供了_analysis 的rest api,如下:

3.3.1:Standard Analyzer
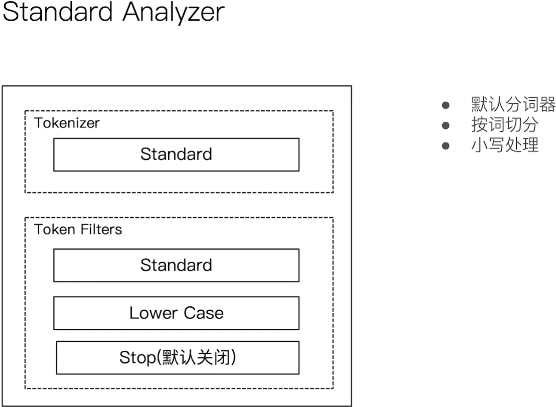
默认分词器,标准分词器三部分提供如下:
charanter Filters:无
Tokennizer:按词切分,就是按照空格切分吧
Token Filters:小写处理
如下图:
首先,我们来看下standard analyzer的执行效果:
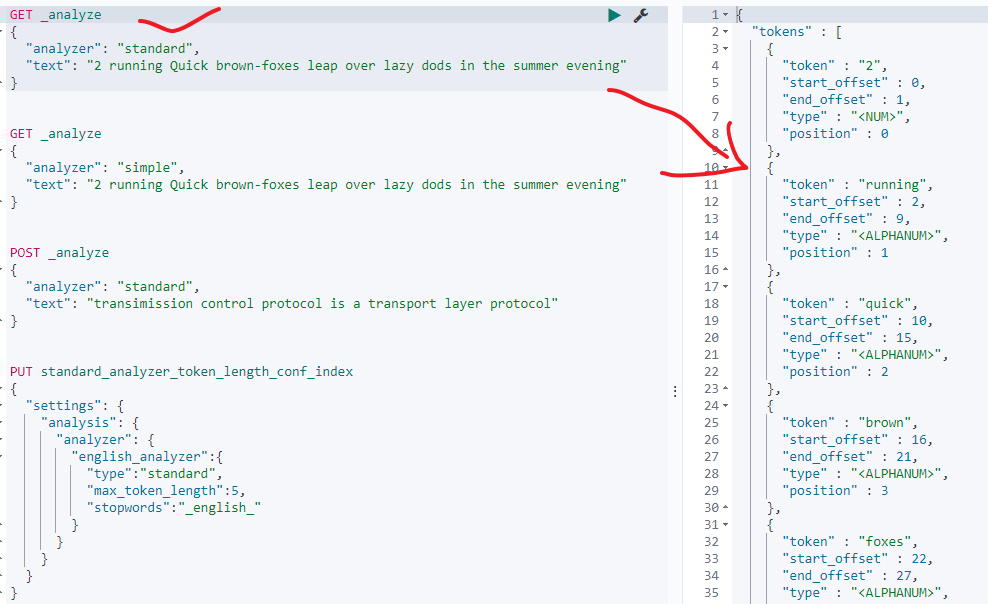
可以看到只是空格划分后转小写了。
如果我们想要启动token fitlers中的停用词该怎么办呢?可以这样,我们来自定义一个分词器,并指定配置,因为在es中自定义分词需要定义在索引下,所以我们需要指定索引来创建(其实就是设置索引的setting),如下:
PUT standard_analyzer_token_length_conf1_index
{"settings": {"analysis": {"analyzer": {"english_1analyzer":{"type":"standard","max_token_length":5,"stopwords":"_english_"}}}}
}
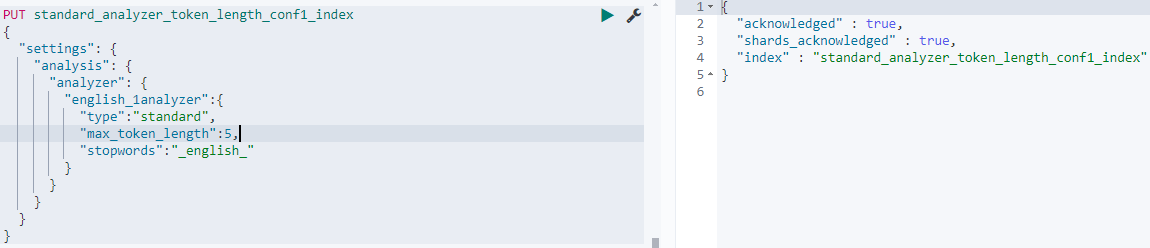
在索引standard_analyzer_token_length_conf1_index中我们定义了一个名称为english_1analyzer的自定义索引,其中的配置项如下:
"type":"standard",基于standard分词器
"max_token_length":5,token最大长度为5,即如果term长度大于5则回分为2个,如ABCDEFGHI,会分为ABCDE和FGHI
"stopwords":"_english_"使用标准的eglish停用词语,也可以通过stopwords_path来指定停用词
测试如下:

可以看到is a这些就没了,并且每个term的最大长度是5,超过5的也被分成了多个。
3.3.2:Simple Analyzer
简单分词器,标准分词器三部分提供如下:
Charanter filters:不提供实现
Tokennizer:按照非字母进行切分(可对比standard分词器只按照空格进行切分),然后还抢了本该属于Token Filters的活,会转小写
Token filters:不提供实现
测试如下:

3.3.3:White space Analyzer
空格分词器,标准分词器三部分提供如下:
Character Filters:不提供实现
Tokenizer:按照空格切分(简单粗暴)
Token Filters:不提供实现
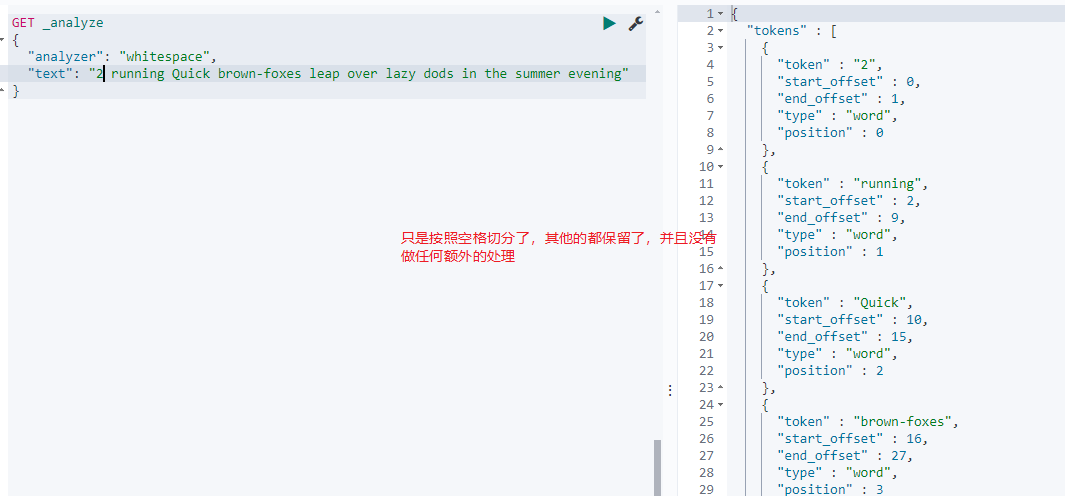
测试如下:
3.3.4:stop anylizer
停用词分词器,标准分词器三部分提供如下:
Character Filters:不提供实现
Tokenizer:按照空格切分
Token Filters:删除is,a等修饰词
可以看到相比于simple analyzer,只是多了tokenfilters的删除修饰词功能。
测试如下:

3.3.5:keyword anylizer
关键词分词器,标准分词器三部分提供如下:
Charater Fitlers:不提供实现
Tokennizer:原样输出,也是一种特殊的分割,不是嘛!!!
Token Filters:不提供实现
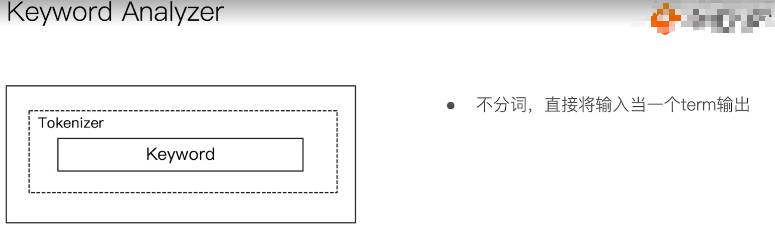
测试如下:

3.3.6:Pattern anylizer
模式分词器,标准分词器三部分提供如下:
Character Fiters:不提供实现
Tokennizer:默认按照\W+进行分割,即按照[0-9a-zA-Z_]之外的字符进行分割
Token Fiters:转小写,以及停用词
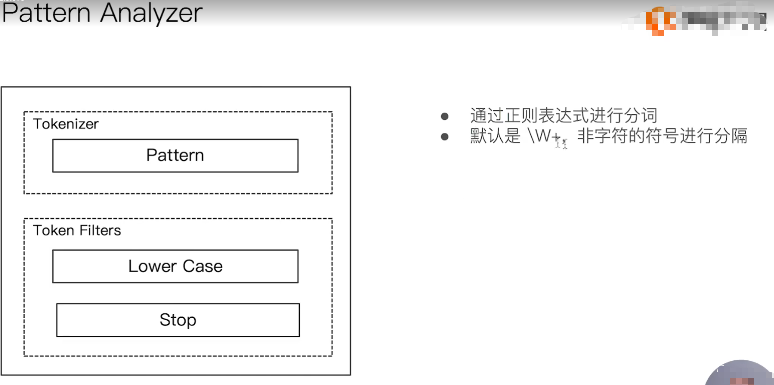
测试如下:
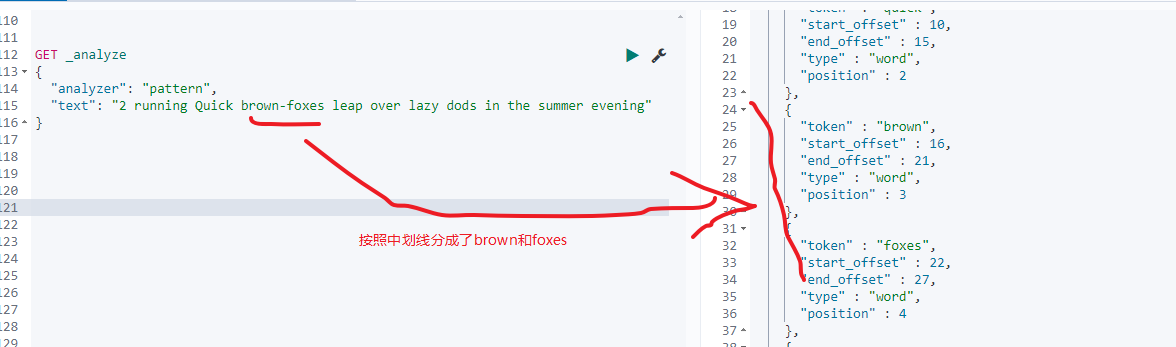
3.3.7:language anylizer
这并不是一个分词器,而是一组分词器,一组针对特定语言的分词器,支持语言如下:

以english为例看下,其token filters还会将一些特定语态的单词变为正常的,如xxxIng变为xxx,如:
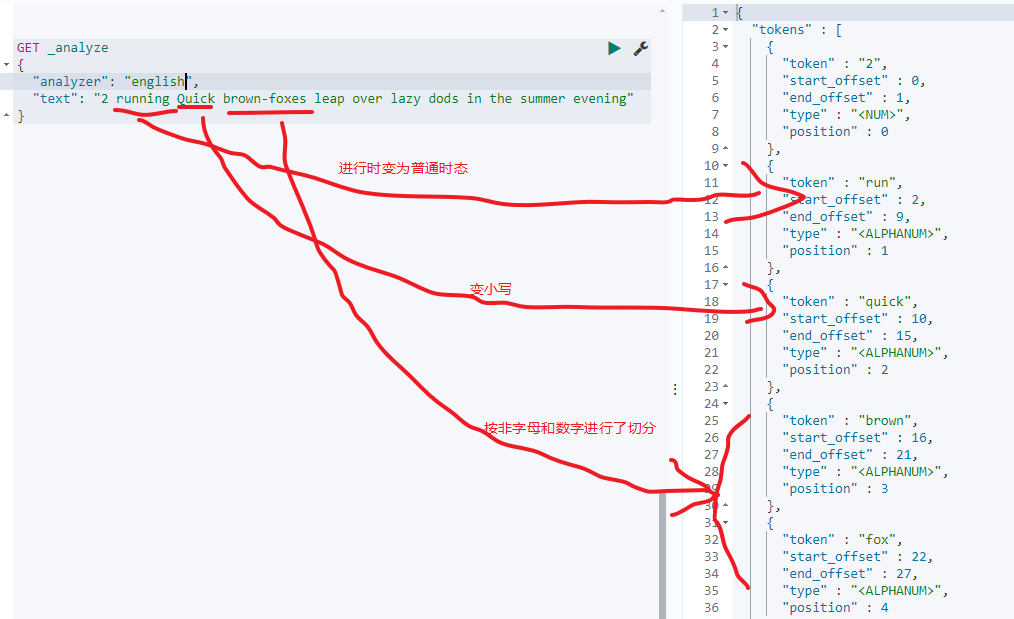
3.3.8:中文分词
因为中华文字,博大精深,变化多端,所以分词的难度相当之大,具体点如下:

为了测试中文分词我们可以来自定义一个安装了ik插件的新镜像,参考docker自定义镜像并使用 。只需要将docker-compose中的es imga改成我们自己定义的就可以测试了,如:
3.3.9:自定义分词器
https://blog.csdn.net/weixin_28906733/article/details/106610972 如果希望自定义一个与standard类似的analyzer,只需要在原定义
- 自定义一个与standard类似的analyzer
先再来看下standard分词器:
charanter Filters:无
Tokennizer:按词切分,就是按照空格切分吧
Token Filters:小写处理
定义和使用:
//测试自定义analyzer
PUT custom_rebuild_standard_analyzer_index
{"settings": {"analysis": {"analyzer": {"rebuild_analyzer":{"type":"custom","tokenizer":"standard","filter":["lowercase"]}}}}
}//测试请求参数
POST custom_rebuild_standard_analyzer_index/_analyze
{"text": "transimission control protocol is a transport layer protocol"
}
- 自定义一个与simple类似的analyzer
先再来看下simple分词器:
Charanter filters:不提供实现
Tokennizer:按照非字母进行切分(可对比standard分词器只按照空格进行切分),然后还抢了本该属于Token Filters的活,会转小写
Token filters:不提供实现
测试和使用:
//测试自定义analyzer
PUT custom_rebuild_simple_analyzer_index
{"settings": {"analysis": {"analyzer": {"rebuild_simple":{"tokenizer":"lowercase","filter":[]}}}}
}//测试请求参数
POST custom_rebuild_simple_analyzer_index/_analyze
{"text": "transimission control protocol is a transport layer protocol"
}
写在后面
参考文章列表
Elasticsearch 学习笔记
Elasticsearch是如何做到快速索引的
相关文章:
ElasticSearch之倒排索引
写在前面 本文看下es的倒排索引相关内容。 1:正排索引和倒排索引 正排索引就是通过文档id找文档内容,而倒排索引就是通过文档内容找文档id,如下图: 2:倒排索引原理 假定我们有如下的数据: 为了建立倒…...

win11安装mysql8.3.0压缩包版 240206
mysql社区版安装包版windows安装包下载地址 在系统环境变量path无点.的情况下 powershell 可以 .\ 或 ./ 开头表示当前文件夹cmd 可以直接命令或.\开头, 不能./开头 所以 .\ 在cmd和powershell中通用 步骤 在解压目录 .\mysqld --initialize-insecure root无密码初始化.\m…...

数据库索引与优化:深入了解索引的种类、使用与优化
数据库索引与优化:深入了解索引的种类、使用与优化 索引的种类 数据库索引是提高查询速度的重要手段之一,主要分为以下几种类型: 主键索引(Primary Key Index): 唯一标识表中的每一行数据,保…...

React 错误边界组件 react-error-boundary 源码解析
文章目录 捕获错误 hook创建错误边界组件 Provider定义错误边界组件定义边界组件状态捕捉错误渲染备份组件重置组件通过 useHook 控制边界组件 捕获错误 hook getDerivedStateFromError 返回值会作为组件的 state 用于展示错误时的内容 componentDidCatch 创建错误边界组件 P…...

分享66个相册特效,总有一款适合您
分享66个相册特效,总有一款适合您 66个相册特效下载链接:https://pan.baidu.com/s/1jqctaho4sL_iGSNExhWB6A?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集整理更不…...

chagpt的原理详解
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的生成式预训练模型。GPT-3是其中的第三代,由OpenAI开发。下面是GPT的基本原理: Transformer架构: GPT基于Transformer架构,该架构由Att…...

dockerfile 详细讲解
当编写 Dockerfile 时,你需要考虑你的应用程序所需的环境和依赖项,并将其描述为一系列指令。下面是一个简单的示例,演示如何编写一个用于部署基于 Node.js 的网站的 Dockerfile: Dockerfile # 使用官方 Node.js 镜像作为基础镜像…...
跟着pink老师前端入门教程-day23
苏宁网首页案例制作 设置视口标签以及引入初始化样式 <meta name"viewport" content"widthdevice-width, user-scalableno, initial-scale1.0, maximum-scale1.0, minimum-scale1.0"> <link rel"stylesheet" href"css/normaliz…...
JRT监听程序
本次设计避免以往设计缺陷,老的主要为了保持兼容性,在用的设计就不好调了。 首先,接口抽象时候就不在给参数放仪器ID和处理类了,直接放仪器配置实体,接口实现想用什么属性就用什么属性,避免老方式要扩参数时…...
MCU+SFU视频会议一体化,视频监控,指挥调度(AR远程协助)媒体中心解决方案。
视频互动应用已经是政务和协同办公必备系统,早期的分模块,分散的视频应该不能满足业务需要,需要把视频监控,会议,录存一体把视频资源整合起来,根据客户需求,需要能够多方视频互动,直…...
)
1184. 欧拉回路(欧拉回路,模板题)
活动 - AcWing 给定一张图,请你找出欧拉回路,即在图中找一个环使得每条边都在环上出现恰好一次。 输入格式 第一行包含一个整数 t,t∈{1,2},如果 t1,表示所给图为无向图,如果 t2,表示所给图为…...

学习 Redis 基础数据结构,不讲虚的。
学习 Redis 基础数据结构,不讲虚的。 一个群友给我发消息,“该学的都学了,怎么就找不到心意的工作,太难了”。 很多在近期找过工作的同学一定都知道了,背诵八股文已经不是找工作的绝对王牌。企业最终要的是可以创造价…...

Android 11 webview webrtc无法使用问题
问题:Android 11 webview 调用webrtc无法使用, 看logcat日志会报如下错误 [ERROR:address_tracker_linux.cc(245)] Could not send NETLINK request: Permission denied (13) 查了下相关的网络权限都有配置了还是不行,还是报这个权限问题 原因࿱…...
嵌入式单片机中晶振的工作原理
晶振在单片机中是必不可少的元器件,只要用到CPU的地方就必定有晶振的存在,那么晶振是如何工作的呢? 什么是晶振 晶振一般指晶体振荡器,晶体振荡器是指从一块石英晶体上按一定方位角切下的薄片,简称为晶片。 石英晶体谐…...
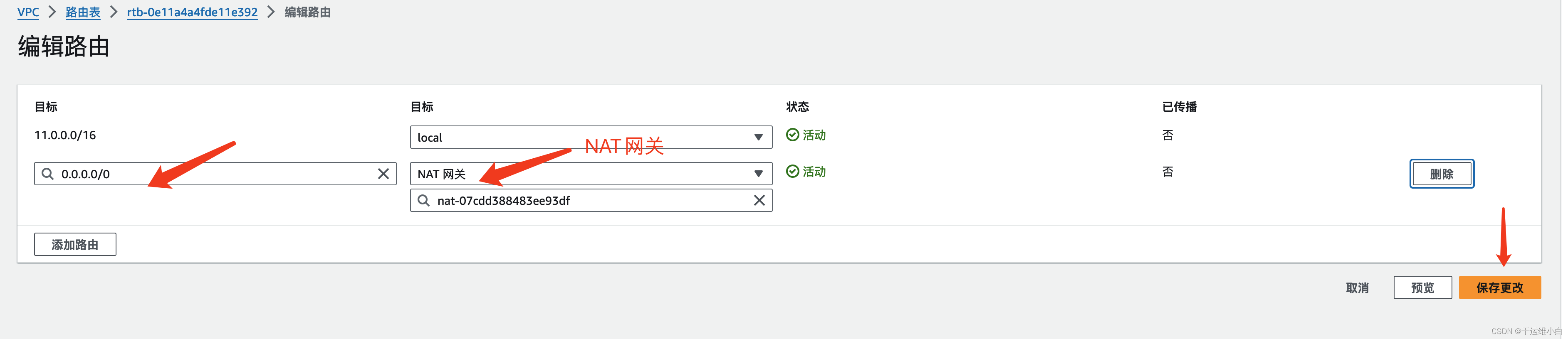
AWS配置内网EC2服务器上网【图形化配置】
第一种方法:创建EC2选择启用分配公网ip 1. 创建vpc 2. 创建子网 3. 创建互联网网关 创建互联网网关 创建互联网网关 ,设置名称即可 然后给网关附加到新建的vpc即可 4. 给新建子网添加路由规则,添加新建的互联网网关然后点击保存更改 5. 新建…...
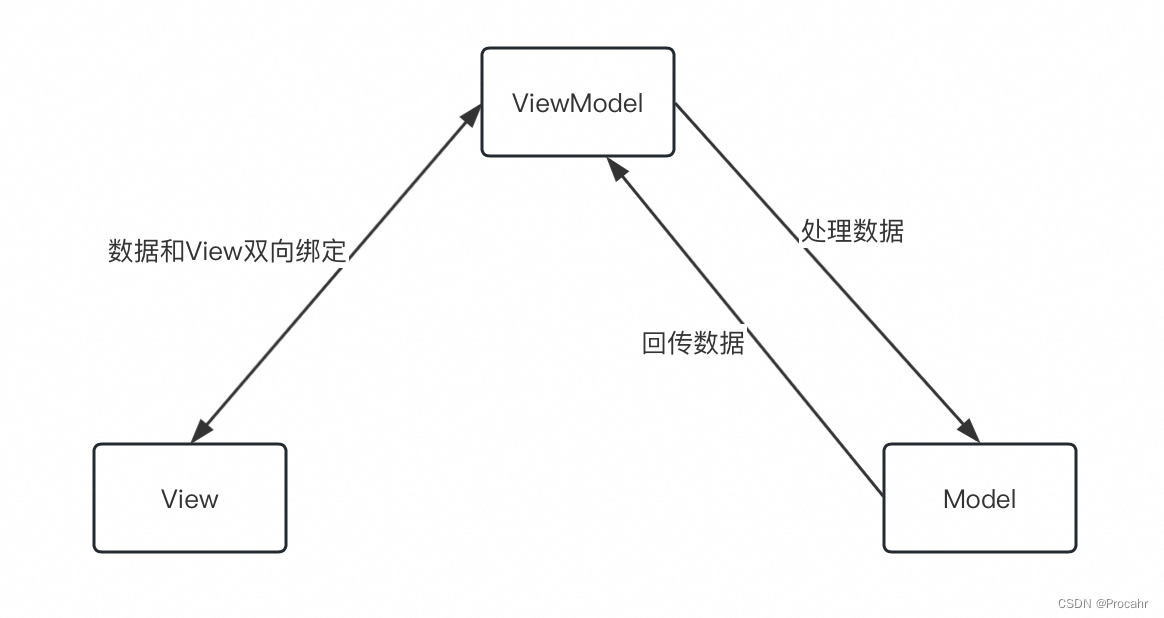
Android中的MVVM
演变 开发常用的框架包括MVC、MVP和本文的MVVM,三种框架都是为了分离ui界面和处理逻辑而出现的框架模式。mvp、mvvm都由mvc演化而来,他们不属于某种语言的框架,当存在ui页面和逻辑代码时,我们就可以使用这三种模式。 model和vie…...

制作耳机壳的UV树脂和塑料材质相比劣势有哪些?
以下是UV树脂相比塑料材质可能存在的劣势: 价格较高:相比一些常见的塑料材质,UV树脂的价格可能较高。这主要是因为UV树脂的生产过程较为复杂,需要较高的技术和设备支持。加工难度大:虽然UV树脂的加工过程相对简单&…...

CSP-202012-1-期末预测之安全指数
CSP-202012-1-期末预测之安全指数 题目很简单,直接上代码 #include <iostream> using namespace std; int main() {int n, sum 0;cin >> n;for (int i 0; i < n; i){int w, score;cin >> w >> score;sum w * score;}if (sum > 0…...

Doris中的本地routineload环境,用于开发回归测试用例
----------------2024-2-6-更新-------------- doris的routineload,就是从kafka中加载数据到表,特点是定时、周期性的从kafka取数据。 要想在本地开发测试routine load相关功能,需要配置kafka环境,尤其是需要增加routine load回…...
【开源项目阅读】Java爬虫抓取豆瓣图书信息
原项目链接 Java爬虫抓取豆瓣图书信息 本地运行 运行过程 另建项目,把四个源代码文件拷贝到自己的包下面 在代码爆红处按ALTENTER自动导入maven依赖 直接运行Main.main方法,启动项目 运行结果 在本地磁盘上生成三个xml文件 其中的内容即位爬取…...
)
RabbitMQ MQTT插件实战:5分钟搞定物联网设备消息通信(含WebSocket配置)
RabbitMQ MQTT插件实战:5分钟搞定物联网设备消息通信(含WebSocket配置) 物联网设备通信的核心挑战在于如何在资源受限的环境中实现高效、可靠的消息传递。RabbitMQ作为企业级消息中间件,通过MQTT插件完美解决了这一难题。本文将带…...

零基础玩转OpenClaw:ollama GLM-4-7-Flash镜像入门十步曲
零基础玩转OpenClaw:ollama GLM-4-7-Flash镜像入门十步曲 1. 为什么选择OpenClawGLM-4-7-Flash组合 去年我在整理个人知识库时,每天要花2小时重复处理Markdown文档和截图。直到发现OpenClaw这个能像真人一样操作电脑的开源智能体,配合ollam…...

【Unity3D】从零打造动态天空盒:Cubemap生成与实时环境映射实战
1. 动态天空盒的核心原理与场景价值 第一次在Unity里看到动态天空盒效果时,我盯着屏幕愣了三秒——云层在头顶流动,夕阳的光影实时投射在建筑表面,整个场景瞬间有了生命力。这种魔法般的体验,其实都建立在立方体贴图(C…...

ORCAD TCL脚本菜单化加载与性能调优实践
1. ORCAD TCL脚本菜单化加载的必要性 作为一名在电子设计自动化领域摸爬滚打多年的工程师,我深刻理解ORCAD用户在使用TCL脚本时遇到的痛点。当你的脚本库逐渐壮大,每次启动ORCAD都要自动加载几十个脚本文件,那种等待的煎熬简直让人抓狂。我曾…...

从‘基’到‘坐标变换’:用Python和NumPy手把手理解线性空间的‘换地图’操作
从‘基’到‘坐标变换’:用Python和NumPy手把手理解线性空间的‘换地图’操作 想象一下,你正在使用导航软件规划路线。同一个地点,在高德地图和百度地图上显示的坐标可能完全不同——这就像线性代数中的基变换。本文将用Python代码和可视化手…...

当固体力学遇上AI:Energy-based PINN如何搞定超弹性橡胶材料仿真?
Energy-based PINN:颠覆超弹性材料仿真的无网格革命 橡胶密封圈在高压环境下的变形预测误差超过40%、人工心脏瓣膜材料的疲劳寿命仿真需要72小时计算、柔性电子器件在弯曲状态下的应力分布难以精确建模——这些困扰研究者的难题,正在被一种结合深度学习和…...
)
ArcMap新手必看:5分钟搞定面要素的四至信息提取(附字段重命名技巧)
ArcMap新手实战:5分钟高效提取面要素四至信息与字段优化技巧 刚接触ArcMap的GIS实习生或规划人员,常常需要快速处理行政区划数据并生成规范的四至报告。面对属性表中密密麻麻的英文字段名和冗余数据,如何高效完成从数据加载到结果美化的全流程…...

.NET校招真实面经:手写代码、项目深挖、算法到底考什么
文章目录写在前面:校招面试就像相亲,你得先过了"眼缘"这一关第一部分:手写代码——别做"嘴强王者",要做"手速达人"1.1 面试官为啥非要你手写代码?1.2 .NET校招手写代码到底考啥…...

从手机到充电宝:拆解NTC热敏电阻在消费电子里的那些‘保命’用法
从手机到充电宝:拆解NTC热敏电阻在消费电子里的那些‘保命’用法 当你手握发烫的手机时,是否想过是什么在默默守护着电池的安全?当快充头以惊人速度输送电能时,又是什么在防止电路因过热而损毁?答案往往藏在一块米粒大…...

Z-Image-GGUF实战:为Android应用集成AI头像生成功能
Z-Image-GGUF实战:为Android应用集成AI头像生成功能 最近在做一个社交类的Android应用,产品经理提了个需求,想加入一个“AI生成个性头像”的功能。用户上传一张自己的照片,选择喜欢的风格(比如动漫风、油画感、像素艺…...