【Iceberg学习三】Reporting和Partitioning原理
Metrics Reporting
Type of Reports
从 1.1.0 版本开始,Iceberg 支持 MetricsReporter 和 MetricsReport API。这两个 API 允许表达不同的度量报告,并支持一种可插拔的方式来报告这些报告。
ScanReport(扫描报告)
扫描报告(ScanReport)记录了在对一个给定表进行扫描规划时收集的度量指标。除了包含一些关于该表的一般信息,如快照 ID 或表名,它还包括以下度量指标:
- 总扫描规划持续时间
- 结果中包含的数据/删除文件数量
- 扫描/跳过的数据/删除清单文件数量
- 扫描/跳过的数据/删除文件数量
- 扫描的等值/位置删除文件数量
CommitReport(提交报告)
提交报告记录了在提交对表的更改(也就是生成快照)之后收集的度量指标。除了包含一些关于该表的一般信息,如快照 ID 或表名,它还包括以下度量指标:
- 总持续时间
- 提交成功所需的尝试次数
- 增加/移除的数据/删除文件数量
- 增加/移除的等值/位置删除文件数量
- 增加/移除的等值/位置删除操作数量
Available Metrics Reporters
LoggingMetricsReporter
这是在没有配置其他指标报告器时的默认指标报告器,其目的是将结果记录到日志文件中。示例输出如下所示:
INFO org.apache.iceberg.metrics.LoggingMetricsReporter - Received metrics report:
ScanReport{tableName=scan-planning-with-eq-and-pos-delete-files, snapshotId=2, filter=ref(name="data") == "(hash-27fa7cc0)", schemaId=0, projectedFieldIds=[1, 2], projectedFieldNames=[id, data], scanMetrics=ScanMetricsResult{totalPlanningDuration=TimerResult{timeUnit=NANOSECONDS, totalDuration=PT0.026569404S, count=1}, resultDataFiles=CounterResult{unit=COUNT, value=1}, resultDeleteFiles=CounterResult{unit=COUNT, value=2}, totalDataManifests=CounterResult{unit=COUNT, value=1}, totalDeleteManifests=CounterResult{unit=COUNT, value=1}, scannedDataManifests=CounterResult{unit=COUNT, value=1}, skippedDataManifests=CounterResult{unit=COUNT, value=0}, totalFileSizeInBytes=CounterResult{unit=BYTES, value=10}, totalDeleteFileSizeInBytes=CounterResult{unit=BYTES, value=20}, skippedDataFiles=CounterResult{unit=COUNT, value=0}, skippedDeleteFiles=CounterResult{unit=COUNT, value=0}, scannedDeleteManifests=CounterResult{unit=COUNT, value=1}, skippedDeleteManifests=CounterResult{unit=COUNT, value=0}, indexedDeleteFiles=CounterResult{unit=COUNT, value=2}, equalityDeleteFiles=CounterResult{unit=COUNT, value=1}, positionalDeleteFiles=CounterResult{unit=COUNT, value=1}}, metadata={iceberg-version=Apache Iceberg 1.4.0-SNAPSHOT (commit 4868d2823004c8c256a50ea7c25cff94314cc135)}}
INFO org.apache.iceberg.metrics.LoggingMetricsReporter - Received metrics report:
CommitReport{tableName=scan-planning-with-eq-and-pos-delete-files, snapshotId=1, sequenceNumber=1, operation=append, commitMetrics=CommitMetricsResult{totalDuration=TimerResult{timeUnit=NANOSECONDS, totalDuration=PT0.098429626S, count=1}, attempts=CounterResult{unit=COUNT, value=1}, addedDataFiles=CounterResult{unit=COUNT, value=1}, removedDataFiles=null, totalDataFiles=CounterResult{unit=COUNT, value=1}, addedDeleteFiles=null, addedEqualityDeleteFiles=null, addedPositionalDeleteFiles=null, removedDeleteFiles=null, removedEqualityDeleteFiles=null, removedPositionalDeleteFiles=null, totalDeleteFiles=CounterResult{unit=COUNT, value=0}, addedRecords=CounterResult{unit=COUNT, value=1}, removedRecords=null, totalRecords=CounterResult{unit=COUNT, value=1}, addedFilesSizeInBytes=CounterResult{unit=BYTES, value=10}, removedFilesSizeInBytes=null, totalFilesSizeInBytes=CounterResult{unit=BYTES, value=10}, addedPositionalDeletes=null, removedPositionalDeletes=null, totalPositionalDeletes=CounterResult{unit=COUNT, value=0}, addedEqualityDeletes=null, removedEqualityDeletes=null, totalEqualityDeletes=CounterResult{unit=COUNT, value=0}}, metadata={iceberg-version=Apache Iceberg 1.4.0-SNAPSHOT (commit 4868d2823004c8c256a50ea7c25cff94314cc135)}}
RESTMetricsReporter
当使用 RESTCatalog 时,这是默认配置,其目的是将指标发送到 REST 服务器,在 /v1/{prefix}/namespaces/{namespace}/tables/{table}/metrics 端点,如 REST OpenAPI 规范中所定义。
通过 REST 发送指标可以通过 rest-metrics-reporting-enabled(默认为 true)属性进行控制。
Implementing a custom Metrics Reporter
实现 MetricsReporter API 在处理传入的 MetricsReport 实例时提供了完全的灵活性。例如,可以将结果发送到 Prometheus 端点或任何其他可观测性框架/系统。
下面是一个简短的示例,说明了一个 InMemoryMetricsReporter,它将报告存储在一个列表中并使其可用:
public class InMemoryMetricsReporter implements MetricsReporter {private List<MetricsReport> metricsReports = Lists.newArrayList();@Overridepublic void report(MetricsReport report) {metricsReports.add(report);}public List<MetricsReport> reports() {return metricsReports;}
}
Registering a custom Metrics Reporter
Via Catalog Configuration
目录属性 metrics-reporter-impl 通过指定其完全限定类名来允许注册一个指定的 MetricsReporter,例如 metrics-reporter-impl=org.apache.iceberg.metrics.InMemoryMetricsReporter。
Via the Java API during Scan planning
即使已经通过 metrics-reporter-impl 属性在目录级别注册了 MetricsReporter,也可以在扫描规划期间提供额外的报告器,如下所示:
TableScan tableScan = table.newScan().metricsReporter(customReporterOne).metricsReporter(customReporterTwo);try (CloseableIterable<FileScanTask> fileScanTasks = tableScan.planFiles()) {// ...
}
Partitioning(分区)
什么是分区
分区是一种通过在写入时将相似的行分组在一起来加速查询的方法。
例如,从日志表查询日志条目通常会包含一个时间范围,就像这个查询在上午10点到12点之间的日志:
SELECT level, message FROM logs
WHERE event_time BETWEEN '2018-12-01 10:00:00' AND '2018-12-01 12:00:00';
将日志表配置为按 event_time 的日期进行分区,将把具有相同事件日期的日志事件分组到同一个文件中。Iceberg 跟踪那个日期,并将使用它来跳过其他没有有用数据的日期的文件。
Iceberg 可以按年、月、日和小时的粒度来分区时间戳。它还可以使用分类列,比如在这个日志示例中的 level,将行存储在一起以加速查询。
iceberg做了什么不一样的地方
其他表格格式如 Hive 支持分区,但 Iceberg 支持隐藏分区。
- Iceberg 处理了表中行生成分区值的繁琐且容易出错的任务。
- Iceberg 自动避免读取不必要的分区。使用者无需知晓表是如何分区的,也无需在他们的查询中添加额外的过滤器。
- Iceberg 的分区布局可以根据需要进行演变。
HIVE中的分区
为了演示差异,考虑一下 Hive 将如何处理日志表。
在 Hive 中,分区是显式的并且表现为一个列,所以日志表会有一个名为 event_date 的列。在写入时,插入操作需要为 event_date 列提供数据:
INSERT INTO logs PARTITION (event_date)SELECT level, message, event_time, format_time(event_time, 'YYYY-MM-dd')FROM unstructured_log_source;
同样,搜索日志表的查询除了需要一个 event_time 过滤器外,还必须有一个 event_date 过滤器。
SELECT level, count(1) as count FROM logs
WHERE event_time BETWEEN '2018-12-01 10:00:00' AND '2018-12-01 12:00:00'AND event_date = '2018-12-01';
如果缺少 event_date 过滤器,Hive 会扫描表中的每一个文件,因为它不知道 event_time 列与 event_date 列之间的关系。
Hive分区方式的问题
Hive 必须被给定分区值。在日志示例中,它不知道 event_time 和 event_date 之间的关系。
这导致了几个问题:
- Hive 不能验证分区值 —— 正确值的产生取决于写入者
- 使用错误的格式,例如使用 2018-12-01 而不是 20181201,会导致悄无声息的错误结果,而不是查询失败
- 使用错误的源列,如 processing_time,或者错误的时区,也会导致错误的结果,而不是失败
- 用户需要正确编写查询
- 使用错误的格式也会导致悄无声息的错误结果
- 不理解表的物理布局的用户会遇到不必要的慢查询 —— Hive 不能自动转换过滤器
- 正常工作的查询与表的分区方案绑定,因此分区配置不能在不破坏查询的情况下更改
Iceberg的隐藏分区
Iceberg 通过获取列值并可选择对其进行转换来产生分区值。Iceberg 负责将 event_time 转换为 event_date,并跟踪这种关系。
表的分区是使用这些关系来配置的。日志表将按照 date(event_time) 和 level 来进行分区。
因为 Iceberg 不要求用户维护分区列,所以它可以隐藏分区。分区值每次都能正确产生,并且总是在可能的情况下用于加速查询。生产者和消费者甚至可能看不到 event_date。
最重要的是,查询不再依赖于表的物理布局。有了物理和逻辑之间的分离,Iceberg 表可以随着数据量的变化,随时间演进其分区方案。配置错误的表可以在不进行昂贵迁移的情况下修复。
有关所有支持的隐藏分区转换的详细信息,请参阅分区转换部分。
有关更新表的分区规范的详细信息,请参阅分区演化部分。
相关文章:

【Iceberg学习三】Reporting和Partitioning原理
Metrics Reporting Type of Reports 从 1.1.0 版本开始,Iceberg 支持 MetricsReporter 和 MetricsReport API。这两个 API 允许表达不同的度量报告,并支持一种可插拔的方式来报告这些报告。 ScanReport(扫描报告) 扫描报告&am…...
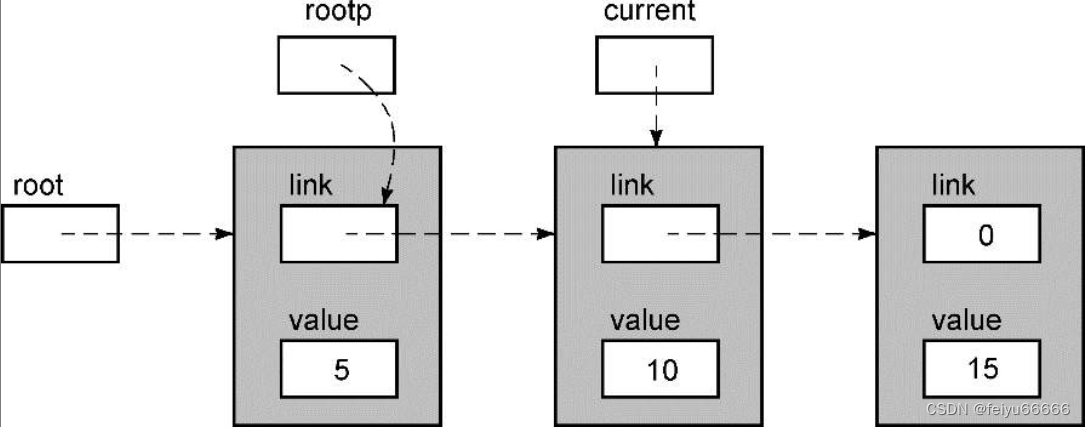
肯尼斯·里科《C和指针》第12章 使用结构和指针(1)链表
只恨当时学的时候没有读到这本书,,,,,, 12.1 链表 有些读者可能还不熟悉链表,这里对它作一简单介绍。链表(linked list)就一些包含数据的独立数据结构(通常称为节点)的集…...
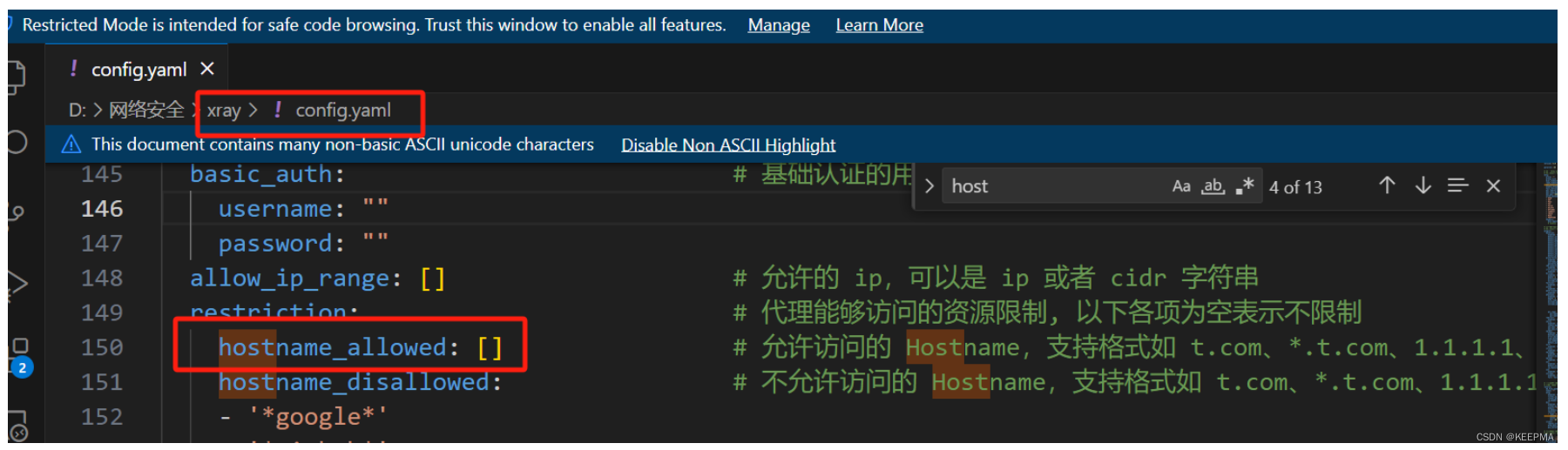
Xray 工具笔记
Xray 官方文档 扫描单个url(非爬虫) 并输出文件(不同文件类型) .\xray.exe webscan --url 10.0.0.6:8080 --text-output result.txt --json-output result.json --html-output report.html默认启动所以内置插件 ,指定…...

Linux环境下配置HTTP代理服务器教程
大家好,我是你们可爱的Linux小助手!今天,我将带你们一起探索如何在Linux环境下配置一个HTTP代理服务器。请注意,这不是一次火箭科学的实验,而是一次简单而有趣的冒险。 首先,我们需要明确什么是HTTP代理服…...
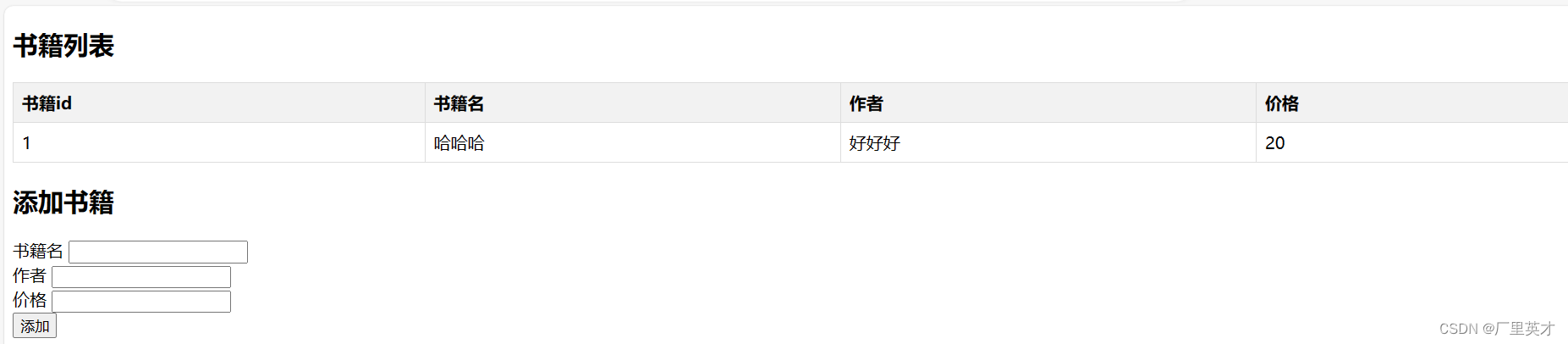
JavaEE作业-实验三
目录 1 实验内容 2 实验要求 3 思路 4 核心代码 5 实验结果 1 实验内容 简单的线上图书交易系统的web层 2 实验要求 ①采用SpringMVC框架,采用REST风格 ②要求具有如下功能:商品分类、订单、购物车、库存 ③独立完成,编写实验报告 …...

K8S容器挂了后重启状态正常,但应用无法访问排查处理
K8S容器挂了后重启状态正常,但应用无法访问排查处理 背景: 应用迁移K8S后因POD OOM挂了后重启,集群上POD状态正常,但应用无法访问。 排查: 查看应用日志,是启动时调用特权账号管理系统超时,…...
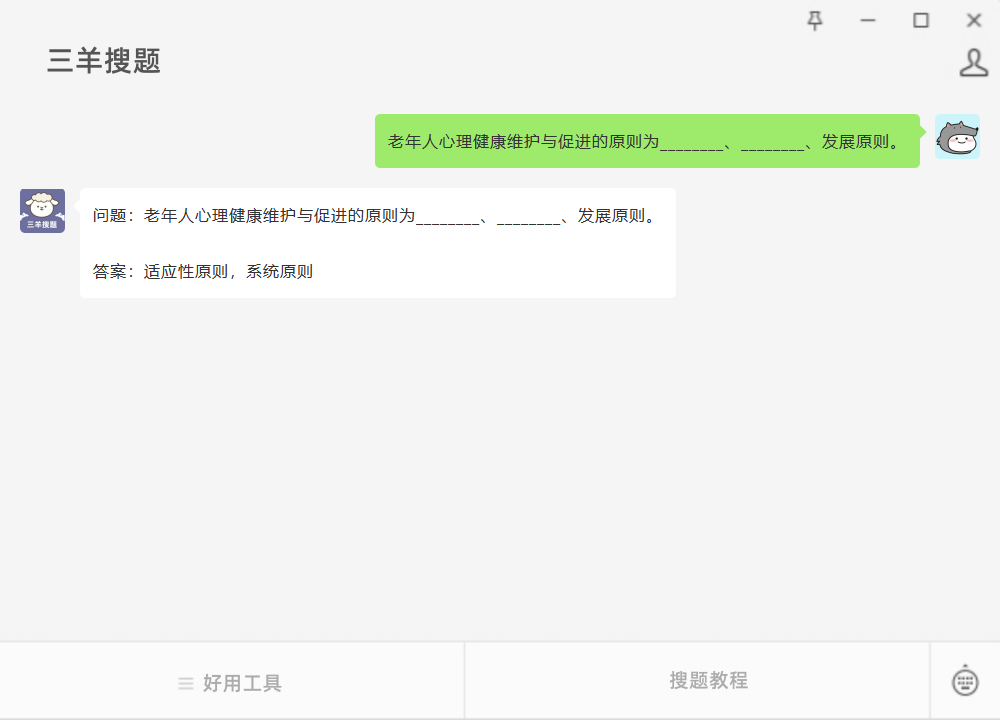
问题:老年人心理健康维护与促进的原则为________、________、发展原则。 #媒体#知识分享
问题:老年人心理健康维护与促进的原则为________、________、发展原则。 参考答案如图所示...

【超高效!保护隐私的新方法】针对图像到图像(l2l)生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据
针对图像到图像生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据 提出背景如何在不重训练模型的情况下从I2I生成模型中移除特定数据? 超高效的机器遗忘方法子问题1: 如何在图像到图像(I2I)生成模型中进行高效…...
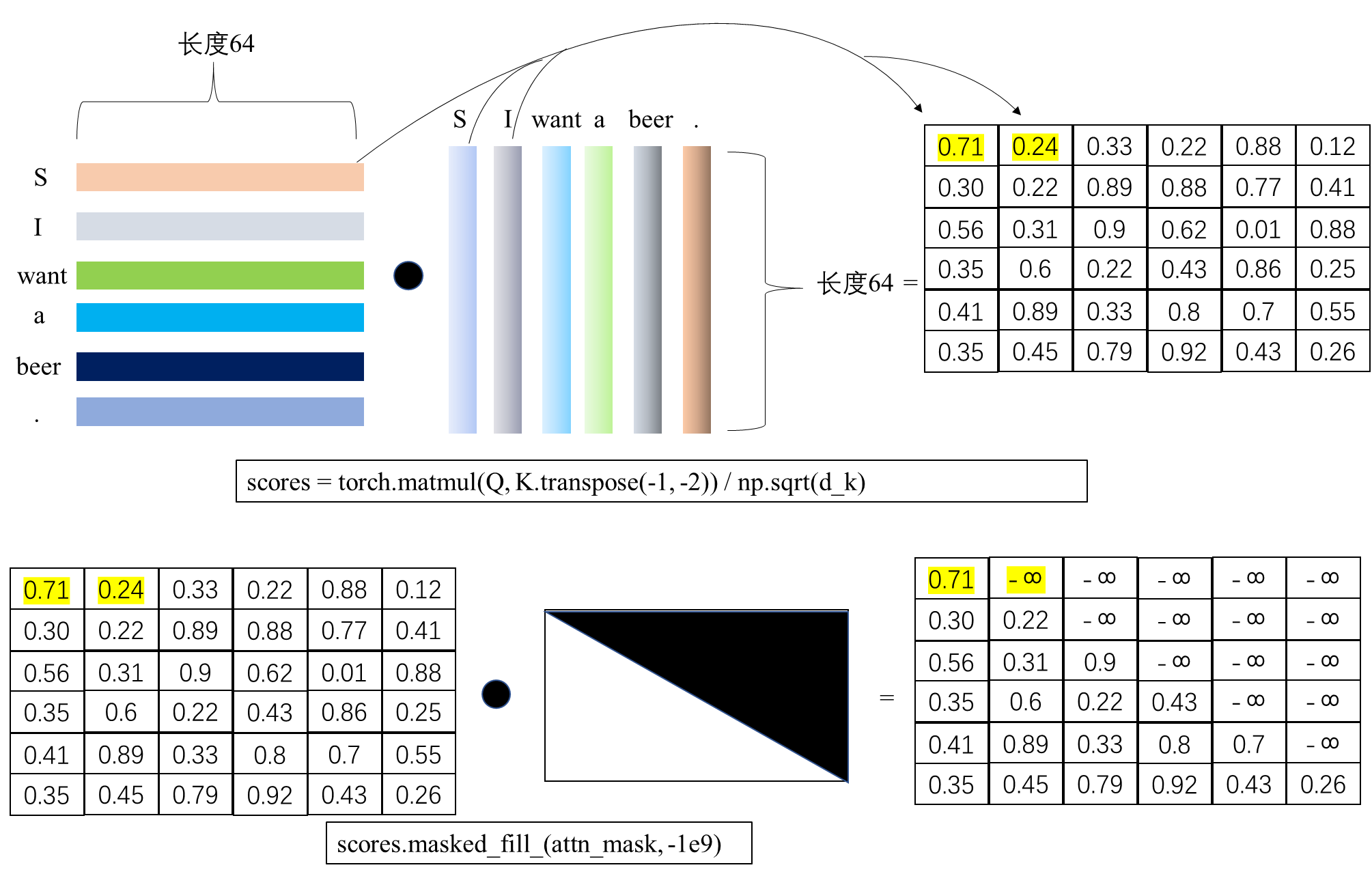
Transformer的PyTorch实现之若干问题探讨(二)
在《Transformer的PyTorch实现之若干问题探讨(一)》中探讨了Transformer的训练整体流程,本文进一步探讨Transformer训练过程中teacher forcing的实现原理。 1.Transformer中decoder的流程 在论文《Attention is all you need》中࿰…...
及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别)
解释Python中的GIL(全局解释器锁)及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别
解释Python中的GIL(全局解释器锁)及其影响 Python中的GIL(全局解释器锁)是CPython解释器中的一个机制,用于同步线程的执行。GIL确保任何时候只有一个线程在执行Python字节码。这意味着,即使在多核或多处理器…...
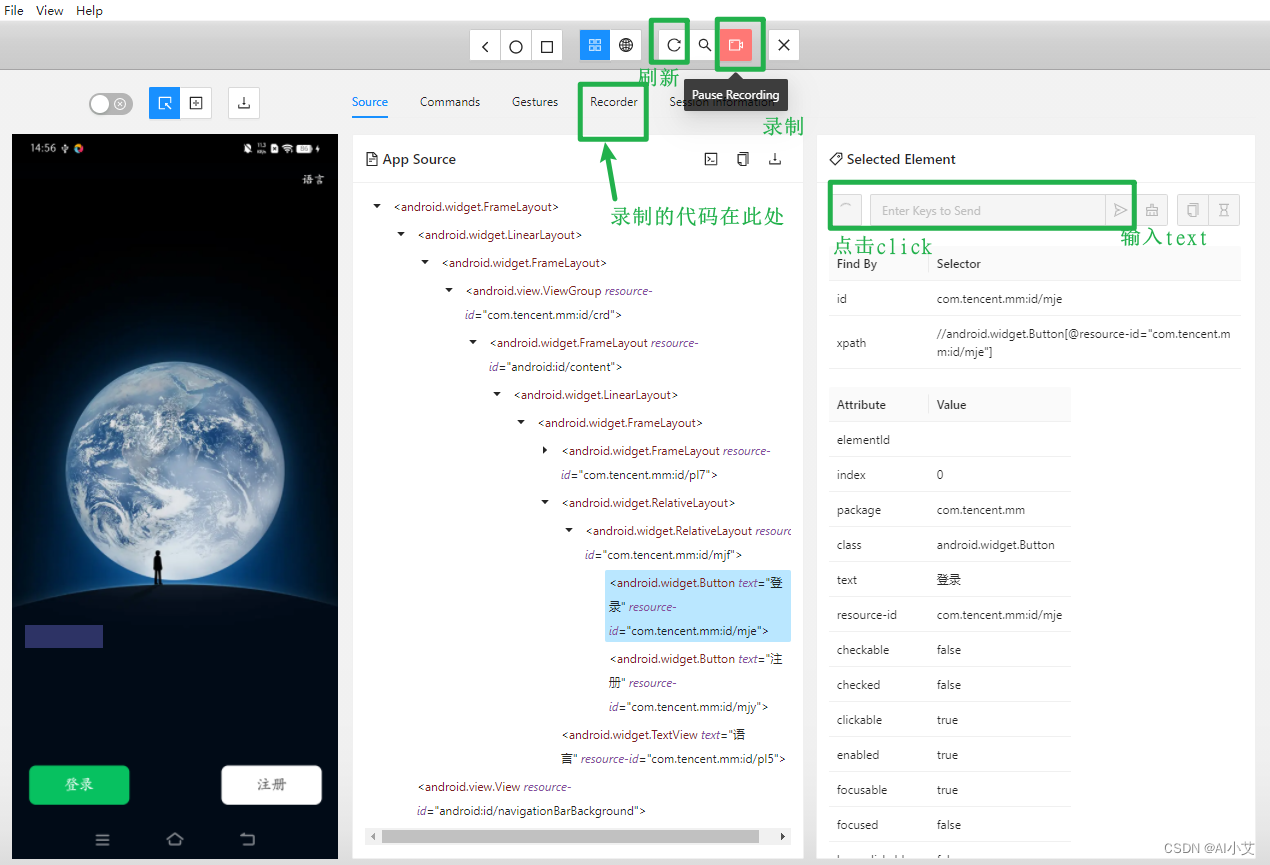
Appium使用初体验之参数配置,简单能够运行起来
一、服务器配置 Appium Server配置与Appium Server GUI(可视化客户端)中的配置对应,尤其是二者如果不在同一台机器上,那么就需要配置Appium Server GUI所在机器的IP(Appium Server GUI的HOST也需要配置本机IP…...

Java:JDK8新特性(Stream流)、File类、递归 --黑马笔记
一、JDK8新特性(Stream流) 接下来我们学习一个全新的知识,叫做Stream流(也叫Stream API)。它是从JDK8以后才有的一个新特性,是专业用于对集合或者数组进行便捷操作的。有多方便呢?我们用一个案…...

【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置【文末送书】
前言 【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置一、效果展示二、根据坐标控制溶解的位置,物体靠近局部溶解三、应用实例👑评论区抽奖送书 前言 本文将使用ShaderGraph制作一个根据坐标控制溶解的位置,物…...

测试OpenSIPS3.4.3的lua模块
这几天测试OpenSIPS3.4.3的lua模块,记录如下: 有bug,但能用 但现实世界就是这样,总是不完美的,发现之后马上提了issue 下面这段代码运行报错: function func1(msg) xlog("ERR","…...

【机器学习】数据清洗之处理缺失点
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步…...

Linux 命令行的世界 :2.文件系统中跳转
我们需要学习的第一件事(除了打字之外)是如何在 Linux 文件系统中跳转。在这一章节中,我们将介绍以下命令:pwd 打印出当前工作目录名 cd 更改目录 ls 列出目录内容 Linux以分层目录结构来组织所有文件。这就意味着所有文件…...
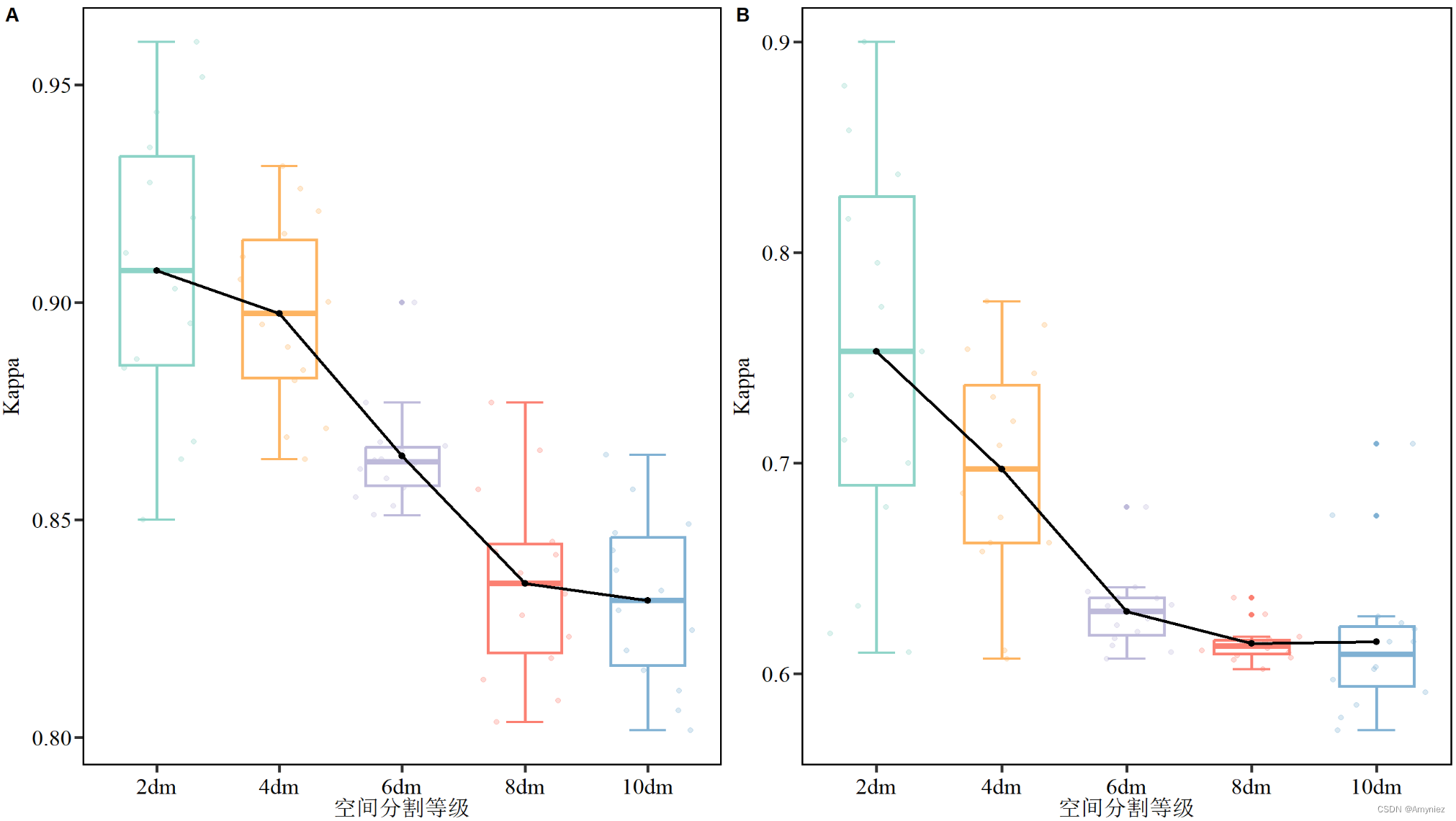
R语言:箱线图绘制(添加平均值趋势线)
箱线图绘制 1. 写在前面2.箱线图绘制2.1 相关R包导入2.2 数据导入及格式转换2.3 ggplot绘图 1. 写在前面 今天有时间把之前使用过的一些代码和大家分享,其中箱线图绘制我认为是非常有用的一个部分。之前我是比较喜欢使用origin进行绘图,但是绘制的图不太…...

Open3D 模型切片
目录 一、算法原理1、算法过程2、主要函数二、代码实现三、结果展示1、原始数据2、切片结果本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理...
KtConnect 本地连接连接K8S工具
KT Connect简介 Kt Connect (Kubernetes Developer Tool)是一个阿里开源、轻量级的面向 Kubernetes 用户的开发测试环境治理辅助工具。其核心是通过建立本地到集群以及集群到本地的双向通道。 1.阿里开源,轻量级, 2. 安装快捷简单…...

【Java万花筒】数据的安全钥匙:Java的加密与保护方法
编码的盾牌:Java开发人员的安全性武器库 前言 在当今数字化时代,保护用户数据和信息的安全已成为开发人员的首要任务。无论是在Web应用程序开发还是安全测试中,加密和安全性都是至关重要的。本文将介绍六个Java库和工具,它们为开…...

2026 年 30 个 MCP Server 实测评:Claude Code 集成效果与响应延迟对比数据
1. 30个MCP Server实测评背后的真实问题:Claude Code不是“插上就快”,而是“配错就崩” 我上线第三个内部MCP Server时,CI流水线里一个原本2秒完成的代码补全请求,突然卡在waiting for MCP response状态长达17秒。日志里没有报错,只有反复重试的HTTP 504。排查了两天,最…...
信息收集)
CTFSHOW-WEB入门(1)信息收集
web1f12得到flagweb2虽然f12不能打开,但是curlU就直接开了得到flag也可以在url前面加个view-source,效果一样也可以通过浏览器打开开发者工具web3没思路的时候抓个包看看,可能会有意外收获得到flagweb4总有人把后台地址写入robots,…...

TS9580,TS3440,TS3400,G3000,G1810,G2810,G3810,G4810,TS9020,TS9120报错5B00,P07,E08,1700,5b04废墨垫清零,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

深入Keil5编译器:解读#1295-D警告背后的C语言函数原型进化史
深入Keil5编译器:解读#1295-D警告背后的C语言函数原型进化史 当你在Keil5环境下打开一个遗留的单片机项目时,那个看似微不足道的#1295-D: Deprecated declaration警告可能正暗示着一段跨越四十年的编程语言进化史。这个关于函数声明的警告不是Keil5的任…...

微积分入门书籍之日韩篇
微积分的奇幻旅程(2020.02) 超简单的微积分 函数、图、斜率、面积 ,一小时掌握微积分的本质(2024.03) 简单微积分 学校未教过的超简易入门技巧(2018.07) 数学女孩的秘密笔记:微分篇 数学女孩的秘密笔记:积分篇 超图解趣…...
)
不止图表引用!VSCode+LaTeX完整编译链配置指南(含BibTeX文献处理)
VSCodeLaTeX高效工作流:从交叉引用到文献管理的全栈配置指南 当你第一次在VSCode中尝试用LaTeX撰写学术论文时,是否曾被那些顽固的"??"标记困扰?这些问号背后隐藏着LaTeX编译机制的核心逻辑——交叉引用需要多轮编译才能正确解析…...

Solidworks 2018+ 机器人模型避坑指南:用SW2URDF插件导出URDF,再导入Webots R2023a完整流程
SolidWorks 2018机器人模型导入Webots全流程避坑指南 在机器人仿真领域,将SolidWorks设计的机械模型准确导入Webots仿真环境是一个关键但充满挑战的环节。许多工程师和学生在初次尝试这一流程时,往往会在版本兼容性、文件路径、坐标系设置等环节遭遇各种…...

【亲测免费】 DXF轨迹图转G代码工具:高效、精准的数控编程利器
DXF轨迹图转G代码工具:高效、精准的数控编程利器 【下载地址】DXF轨迹图转G代码工具介绍 DXF轨迹图转G代码工具介绍本仓库提供了一个资源文件,用于将DXF格式的轨迹图转换为G代码 项目地址: https://gitcode.com/open-source-toolkit/528cd 项目介…...

如何在MATLAB中调用Taotoken聚合大模型API进行智能分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在MATLAB中调用Taotoken聚合大模型API进行智能分析 对于使用MATLAB进行科学计算、数据分析或算法开发的工程师和研究人员而言&…...
Linux屏幕取词翻译终极指南:CuteTranslation让你的跨语言阅读变得简单高效
Linux屏幕取词翻译终极指南:CuteTranslation让你的跨语言阅读变得简单高效 【免费下载链接】CuteTranslation Linux屏幕取词翻译软件 项目地址: https://gitcode.com/gh_mirrors/cu/CuteTranslation 你是否经常在Linux系统上阅读外文资料时遇到语言障碍&…...