zk集群--集群同步
1.概述
前面一章分析了集群下启动阶段选举过程,一旦完成选举,通过执行QuorumPeer的setPeerState将设置好选举结束后自身的状态。然后,将再次执行QuorumPeer的run的新的一轮循环,
QuorumPeer的run的每一轮循环,先判断自身当前状态:
(1). 自身为LOOKING
则需在本轮循环开启选举,并完成选举。
(2). 自身为FOLLOWING
protected Follower makeFollower(FileTxnSnapLog logFactory) throws IOException {return new Follower(this, new FollowerZooKeeperServer(logFactory, this, this.zkDb));
}try {LOG.info("FOLLOWING");setFollower(makeFollower(logFactory));follower.followLeader();
} catch (Exception e) {LOG.warn("Unexpected exception", e);
} finally {follower.shutdown();setFollower(null);updateServerState();
}
则应转换为从节点,先通过follower.followLeader();与主同步,再履行起从节点的角色任务。
(3). 自身为LEADING
protected Leader makeLeader(FileTxnSnapLog logFactory) throws IOException, X509Exception {return new Leader(this, new LeaderZooKeeperServer(logFactory, this, this.zkDb));
}try {setLeader(makeLeader(logFactory));leader.lead();setLeader(null);
} catch (Exception e) {LOG.warn("Unexpected exception", e);
} finally {if (leader != null) {leader.shutdown("Forcing shutdown");setLeader(null);}updateServerState();
}
则应转换为主节点,先通过leader.lead();完成集群同步后,再履行起主节点的角色任务。
本部分讨论集群同步过程。集群同步是一个完成选举的主和从相互协作最终大家达成一致的过程。
2.集群同步过程前的两次同步
2.1.主节点的leader.lead()
self.setZabState(QuorumPeer.ZabState.DISCOVERY);
self.tick.set(0);
zk.loadData();
leaderStateSummary = new StateSummary(self.getCurrentEpoch(), zk.getLastProcessedZxid());
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start();
上述动作里,先是设置ZabState为DISCOVERY。启动节点一开始是ELECTION来着。
其中zk.loadData();由于在启动节点选举前已经执行过了一次基于快照+redo的数据实体恢复,所以这里啥也不用做。
构建一个StateSummary实例,这个实例包含了主节点下数据实体阶段性的一个反映。对应的那个集群轮次,最后一个zxid是啥。
通过cnxAcceptor.start();使得主节点开始作为一个服务端,允许其他集群成员来连接以便执行集群同步及后续的请求处理。
对每个接入的集群成员,在主节点方面将通过accept得到通信套接字,并分配一个LearnerHandler来维护和集群成员的通信。
LearnerHandler fh = new LearnerHandler(socket, is, Leader.this);
fh.start();
fh.start();将开启一个线程,在此线程中将接收来自连接对端的包,并对其执行处理。
接下来,主节点执行的是:
long epoch = getEpochToPropose(self.getId(), self.getAcceptedEpoch());
主节点执行getEpochToPropose的目的是为了获得新产生的集群的轮次要设置为何值?
此处将产生同步等待,直到算上主节点自身,有半数以上集群成员连接到的主节点并执行了getEpochToPropose才能获得继续。
对主节点,此处的同步等待超时下,将引发主节点停止。并设置自身状态为LOOKING。这样,在QuorumPeer的run的新一轮循环里,将重新开始选举过程。
2.2.从节点的follower.followLeader()
self.setZabState(QuorumPeer.ZabState.DISCOVERY);
QuorumServer leaderServer = findLeader();
connectToLeader(leaderServer.addr, leaderServer.hostname);
connectionTime = System.currentTimeMillis();
上述动作里,先是设置ZabState为DISCOVERY。启动节点一开始是ELECTION来着。
然后,执行findLeader找到主节点。借助自身的投票和集群全局配置很容易定位出来。
connectToLeader将同步方式发起到服务端连接。
若指定时间或指定次数内连接未建立,将引发从节点停止。并设置自身状态为LOOKING。这样,在QuorumPeer的run的新一轮循环里,将重新开始选举过程。
若连接成功,在异步发包下会启动一个线程用于异步发包。
从节点接下来执行:
long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO);
这里面从节点先向主节点发一个包
long lastLoggedZxid = self.getLastLoggedZxid();
QuorumPacket qp = new QuorumPacket();
qp.setType(Leader.FOLLOWERINFO);// 包类型
qp.setZxid(ZxidUtils.makeZxid(self.getAcceptedEpoch(), 0));// 包里的zxid
LearnerInfo li = new LearnerInfo(self.getId(), 0x10000, self.getQuorumVerifier().getVersion());
ByteArrayOutputStream bsid = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(bsid);
boa.writeRecord(li, "LearnerInfo");
qp.setData(bsid.toByteArray());// 包的数据体是一个LearnerInfo实例。包含从节点sid,0x10000,集群全局信息。
writePacket(qp, true);
现在从节点等待主节点的回复。
2.3.主节点实现从节点接入及收包处理
主节点会为每个接入到其的从节点,分配一个LearnerHandler实例,此实例将占据一个独立的线程来处理来自对应从节点的数据包收取和处理。
LeaderHandler的run一开始执行:
learnerMaster.addLearnerHandler(this);
这样将向leader的learners集合中加入此LearnerHandler实例。
然后主将开始收取首个包。并对首个包进行合法性检测(对从节点必须是Leader.FOLLOWERINFO)。
若检测失败,服务端方面会停止线程,关闭被动连接,从leader的learners,forwardingFollowers,observingLearners集合移除此LearnerHandler实例。客户端方面则将引发从节点停止。并设置自身状态为LOOKING。这样,在QuorumPeer的run的新一轮循环里,将重新开始选举过程。后续分析过程失败过程处理类似。我们将按成功的流程去分析。
我们分析主节点这边对首个包的解析
QuorumPacket qp = new QuorumPacket();
// 反向序列化获得包
ia.readRecord(qp, "packet");
byte[] learnerInfoData = qp.getData();// 获得包中数据体
ByteBuffer bbsid = ByteBuffer.wrap(learnerInfoData);
this.sid = bbsid.getLong();
this.version = bbsid.getInt(); // protocolVersion--0x10000
String followerInfo = learnerMaster.getPeerInfo(this.sid);
// 这样将获得从节点首个包里的zxid,从中提取出epoch
long lastAcceptedEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());
long peerLastZxid;
StateSummary ss = null;
long zxid = qp.getZxid();
long newEpoch = learnerMaster.getEpochToPropose(this.getSid(), lastAcceptedEpoch);
2.4. 集群同步阶段确定新集群的epoch
通过2.1到2.3我们知道。
选举结束后,主节点作为服务端允许集群从节点的接入。
然后,集群主节点将阻塞等待。
对每个结束选举的从节点,将连接主节点,成功后,发出首个Leader.FOLLOWERINFO包。然后等待回复。
主节点为每个接入的从节点分配LearnerHandler实例,并启动线程,处理收包和收包处理。
每个LearnerHandler的线程收取首个包Leader.FOLLOWERINFO后,通过learnerMaster.getEpochToPropose陷入与主节点一样的阻塞等待。
当算上主节点自身有半数以上成员陷入上述阻塞等待后,将基于所有等待成员中acceptedEpoch最大值+1作为新集群的epoch设置到leader的epoch。
若上述过程某个成员连接上出现错误或等待超时,则将执行连接断开。角色的集群同步停止。重新变为LOOKING状态,并进入选举过程这样的处理。
主节点自己等待超时或出错,则主节点的集群同步停止。重新变为LOOKING状态,并进入选举流程。主节点集群同步停止时会引发每个连到主节点的从节点和主节点的连接断开。使得从节点停止。重新变为LOOKING状态。
2.5.我们分别针对主节点,从节点分析完成getEpochToPropose等待后的处理流程
2.5.1.对主节点
zk.setZxid(ZxidUtils.makeZxid(epoch, 0));
synchronized (this) {lastProposed = zk.getZxid();
}
newLeaderProposal.packet = new QuorumPacket(NEWLEADER, zk.getZxid(), null, null);
newLeaderProposal.addQuorumVerifier(self.getQuorumVerifier());
waitForEpochAck(self.getId(), leaderStateSummary);
主节点,后续执行waitForEpochAck。
主节点执行此步骤会阻塞,在waitForEpochAck中收集到半数以上的成员及其StateSummary后,在满足:
(1). 完成收集未引发超时
(2). 不存在从节点StateSummary领先主节点的情况。
满足上述两个条件,主节点将继续。并设置electionFinished为true。
若某个条件不满足,主节点将停止,并断开与连到其的从的连接,这样将引发从节点也停止。最终主,从均停止。并发起下一轮选举。
2.5.2.对从节点
long newLeaderZxid = ZxidUtils.makeZxid(newEpoch, 0);
byte[] ver = new byte[4];
ByteBuffer.wrap(ver).putInt(0x10000);
QuorumPacket newEpochPacket = new QuorumPacket(Leader.LEADERINFO, newLeaderZxid, ver, null);
oa.writeRecord(newEpochPacket, "packet");
messageTracker.trackSent(Leader.LEADERINFO);
bufferedOutput.flush();// 立即发送
QuorumPacket ackEpochPacket = new QuorumPacket();
ia.readRecord(ackEpochPacket, "packet");
主这边会向其回复一个Leader.LEADERINFO包,其中包含基于新集群epoch得到的zxid,版本信息(0x10000)。
从节点这边:
readPacket(qp);
final long newEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());// 取得回复包里的zxid
leaderProtocolVersion = ByteBuffer.wrap(qp.getData()).getInt();// 取得ver
byte[] epochBytes = new byte[4];
final ByteBuffer wrappedEpochBytes = ByteBuffer.wrap(epochBytes);
wrappedEpochBytes.putInt((int) self.getCurrentEpoch());// 放入自身currentEpoch
self.setAcceptedEpoch(newEpoch);// 用回复包里zxid导出的epoch设置自身acceptedEpoch
QuorumPacket ackNewEpoch = new QuorumPacket(Leader.ACKEPOCH, lastLoggedZxid, epochBytes, null);
writePacket(ackNewEpoch, true);// 向主节点发包
return ZxidUtils.makeZxid(newEpoch, 0);
再来看主节点这边:
QuorumPacket ackEpochPacket = new QuorumPacket();
ia.readRecord(ackEpochPacket, "packet");// 等待连主成员对回复包1的回复
messageTracker.trackReceived(ackEpochPacket.getType());
ByteBuffer bbepoch = ByteBuffer.wrap(ackEpochPacket.getData());//
ss = new StateSummary(bbepoch.getInt(), ackEpochPacket.getZxid());// 从节点的currentEpoch,从节点的zxid
learnerMaster.waitForEpochAck(this.getSid(), ss);// 连主的多数一起同步等待,然后继续运行。
waitForEpochAck这个执行中将陷入等待。直到满足:
(1). waitForEpochAck使得主节点收集到多数以上成员的sid,ss。
(2). 收集达到半数以上未超时。
(3). 未出现从节点的ss领先主节点。
上述三者满足时,等待者和主节点继续运行。
对LearnerHandler中执行waitForEpochAck超时,将断开与从节点连接。引发从节点停止,并重新进入下一轮选举。
这一同步达成后,主节点中electionFinished设置为true。
到目前为止,我们分析了成员完成选举确认自身身份后,经历过了两个由主节点这边主导的阻塞等待。
第一个阻塞等待是getEpochToPropose,通过此等待基于所有连主成员中acceptedEpoch最大值+1作为新集群epoch。
此阶段,对从节点等待超时或出错,会使得其停止作为从,并重新进入选举。
此节点,对主节点等待超时或出错,会使得其自身和所有从均停止自身角色,并重新进入选举。
成功则,使得我们获得新集群的epoch,及基于epoch的zxid。
第二个阻塞等待是waitForEpochAck,通过此等待主要是再一次确认主节点的合法性。即主节点自身的进度确实是参与选举的各个节点中最靠前的。
比如一个1,2,3三个成员的集群。
(1). 1,2,3启动,并运行很长时间。
(2). 全部停止。
(3). 手动删除1,2的快照,redo。
(4). 启动1,2。使得1,2各自完成选举,预期2为主,1为从。
(5). 启动3,假设此时1,2各自处于waitForEpochAck。3选举结束,依据收到的Notification确定2为主。并连接2,也进入waitForEpochAck。此时就会产生某个从节点的状态领先主节点的情况。这时,就要使得主和从全部停止角色,并再次选举。再次选举,将选择3为主。此时,waitForEpochAck将获得通过。一旦主和从的waitForEpochAck结束。此时及时有新的从连到主,且领先于主,也不会被考虑了。
下面,将进入真正的集群同步阶段。
3. 集群同步
我们继续分别从主节点,从节点角度分析其后续流程。
3.1. 主节点
self.setCurrentEpoch(epoch);
self.setLeaderAddressAndId(self.getQuorumAddress(), self.getId());
self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION);
waitForNewLeaderAck(self.getId(), zk.getZxid());
只有完成前述两个节点的同步,且未出错。主节点采用将新集群的epoch设置到其currentEpoch中。
注意,对主节点和从节点,只要其完成了前述中第一个同步,就会各自设置自己的acceptedEpoch。
所以,accepted反映的是集群已经完成的集群选举次数。(一个完成的集群选举的集群并不一定可以成为对外服务的集群。必须继续完成前述第二个同步,及完成后续集群同步才可以。)
主节点执行waitForNewLeaderAck是我们遇到的新集群形成中主节点主导的第三次同步。
先分析,从节点方面在第二个同步完成后的后续动作,再分析第三次同步等待的意义。
3.2.从节点
先分析LearnerHandler中后续处理
peerLastZxid = ss.getLastZxid();
// 这个函数完成的同步请求及主节点中尚未提交请求的排队
boolean needSnap = syncFollower(peerLastZxid, learnerMaster);
// 在需要快照的情况下
if (needSnap) {try {long zxidToSend = learnerMaster.getZKDatabase().getDataTreeLastProcessedZxid();// 立即发一个快照包。这样保证快照,DIFF,TRUNC三种同步方式下,均是先处理同步。再继续处理主节点中尚未提交请求。oa.writeRecord(new QuorumPacket(Leader.SNAP, zxidToSend, null, null), "packet");messageTracker.trackSent(Leader.SNAP);bufferedOutput.flush()learnerMaster.getZKDatabase().serializeSnapshot(oa);oa.writeString("BenWasHere", "signature");bufferedOutput.flush();} finally {ServerMetrics.getMetrics().SNAP_COUNT.add(1);}
} else {ServerMetrics.getMetrics().DIFF_COUNT.add(1);
}
// 同步+尚未提交包+Leader.NEWLEADER
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER, newLeaderZxid, learnerMaster.getQuorumVerifierBytes(), null);
queuedPackets.add(newLeaderQP);
bufferedOutput.flush();
startSendingPackets();
我们分析上述过程,现在我们已经针对新集群完成了两个同步。
且知道从节点的lastzxid,也知道主节点的lastzxid。
那么我们要做的就是让从节点和主节点同步,同步的结果就是从节点的lastzxid变成和主节点的一样。
具体分析之前,可以直观想到同步的几种情况:
(1). 从节点落后于主节点
落后的不多。
落后的较多。
(2). 从节点领先于主节点
我们继续分析syncFollower:
private void queueOpPacket(int type, long zxid) {QuorumPacket packet = new QuorumPacket(type, zxid, null, null);queuePacket(packet);
}// 若是差异化同步或截断同步,将在此函数内得到处理
// 若是快照同步,得外部处理。// 进入是
// needOpPacket 为true
// needSnap 也为true// 这样的话,从节点方面的lastZxid中序号为0,表示过对于epoch下没处理过具体事务。
boolean isPeerNewEpochZxid = (peerLastZxid & 0xffffffffL) == 0;
long currentZxid = peerLastZxid;
boolean needSnap = true;
ZKDatabase db = learnerMaster.getZKDatabase();
boolean txnLogSyncEnabled = db.isTxnLogSyncEnabled();
ReentrantReadWriteLock lock = db.getLogLock();
ReadLock rl = lock.readLock();
try {rl.lock();// 快照恢复后,主节点后续落地的集群类型的请求最近N个请求中// 最大者的zxidlong maxCommittedLog = db.getmaxCommittedLog();// 最小者的zxidlong minCommittedLog = db.getminCommittedLog();// 这个是主节点最后落地的zxid。一般可认为就是maxCommittedLog。long lastProcessedZxid = db.getDataTreeLastProcessedZxid();if (db.getCommittedLog().isEmpty()) {minCommittedLog = lastProcessedZxid;maxCommittedLog = lastProcessedZxid;}if (lastProcessedZxid == peerLastZxid) { // 如果从节点的lastZxid和主节点的一致// 使用一个Leader.DIFF完成同步queueOpPacket(Leader.DIFF, peerLastZxid);// 差异化同步needOpPacket = false;needSnap = false;} else if (peerLastZxid > maxCommittedLog && !isPeerNewEpochZxid) {// 这里的意思是从节点领先于主节点// 通过一个TRUNC完成同步queueOpPacket(Leader.TRUNC, maxCommittedLog);// 同步节点结束时,从节点的lastZxidcurrentZxid = maxCommittedLog;needOpPacket = false;needSnap = false;} else if ((maxCommittedLog >= peerLastZxid) && (minCommittedLog <= peerLastZxid)) {// 这意味着,从节点落后于主节点。但落后的不算多。// 情况1:当peerLastZxid在迭代范围内出现时,同步过程为:// DIFF+peerLastZxid后的每个包{packet+COMMIT}// 情况2:当peerLastZxid在迭代范围内没出现,且peerLastZxid对应轮次下没事务请求被处理// DIFF+首个大于peerLastZxid及其后的每个包{packet+COMMIT}// 情况3:当peerLastZxid在迭代范围内没出现,从节点处理了某些请求,首个大于peerLastZxid的packetZxid属于后续轮次// 最终将采用快照完成同步阶段// 情况4:当peerLastZxid在迭代范围内没出现,从节点处理了某些请求,首个大与peerLastZxid的packetZxid属于相同轮次// TRUNC{截掉从节点中不在主节点中的请求}+对主节点中大于peerLastZxid的每个包{packet+COMMIT}Iterator<Proposal> itr = db.getCommittedLog().iterator();currentZxid = queueCommittedProposals(itr, peerLastZxid, null, maxCommittedLog);needSnap = false;} else if (peerLastZxid < minCommittedLog && txnLogSyncEnabled) {// 这意味着,从节点落后主节点比较多,且设置了需要较多redo下优先选择快照long sizeLimit = db.calculateTxnLogSizeLimit();// 计算redo尺寸限制Iterator<Proposal> txnLogItr = db.getProposalsFromTxnLog(peerLastZxid, sizeLimit);// 在估算所需redo尺寸达到限制时,hasNext为false。// 此时采用快照来同步,相应的currentZxid = db.getDataTreeLastProcessedZxid();if (txnLogItr.hasNext()) {currentZxid = queueCommittedProposals(txnLogItr, peerLastZxid, minCommittedLog, maxCommittedLog);if (currentZxid < minCommittedLog) {currentZxid = peerLastZxid;queuedPackets.clear();needOpPacket = true;} else {Iterator<Proposal> committedLogItr = db.getCommittedLog().iterator();currentZxid = queueCommittedProposals(committedLogItr, currentZxid, null, maxCommittedLog);needSnap = false;}}if (txnLogItr instanceof TxnLogProposalIterator) {TxnLogProposalIterator txnProposalItr = (TxnLogProposalIterator) txnLogItr;txnProposalItr.close();}}if (needSnap) {currentZxid = db.getDataTreeLastProcessedZxid();}// 主节点继续将一些尚未落地的包发给从节点leaderLastZxid = learnerMaster.startForwarding(this, currentZxid);
} finally {rl.unlock();
}
if (needOpPacket && !needSnap) {needSnap = true;// 采用快照来同步
}
return needSnap;
关于queueCommittedProposals的分析:
protected long queueCommittedProposals(Iterator<Proposal> itr, long peerLastZxid, Long maxZxid, Long lastCommittedZxid) {boolean isPeerNewEpochZxid = (peerLastZxid & 0xffffffffL) == 0;long queuedZxid = peerLastZxid;long prevProposalZxid = -1;while (itr.hasNext()) {Proposal propose = itr.next();long packetZxid = propose.packet.getZxid();if ((maxZxid != null) && (packetZxid > maxZxid)) {break;}// 若maxZxid存在,至多处理到maxZxidif (packetZxid < peerLastZxid) {prevProposalZxid = packetZxid;// zxid过小,对端已经处理过。略过。continue;}// 对迭代范围内首个大于或等于peerLastZxid的packetZxidif (needOpPacket) {// 情况1:这个packetZxid等于peerLastZxidif (packetZxid == peerLastZxid) {queueOpPacket(Leader.DIFF, lastCommittedZxid);needOpPacket = false;continue;}// 情况:这个packetZxid大于peerLastZxid。// 这样,迭代范围前一部分均小于peerLastZxid,后一部分均大于peerLastZxidif (isPeerNewEpochZxid) {// 情况2:peerLastZxid对应轮次下从节点没处理过事务// 此时忽略此peerLastZxidqueueOpPacket(Leader.DIFF, lastCommittedZxid);needOpPacket = false;// 不再需要发op包了} else {// peerLastZxid对应轮次是处理过事务请求。// 情况3:主节点中首个大于peerLastZxid的包已经是后续轮次的包了。// 这样最终会用快照方式来处理同步if (ZxidUtils.getEpochFromZxid(packetZxid) != ZxidUtils.getEpochFromZxid(peerLastZxid)) {return queuedZxid;// 直接返回peerLastZxid} // 情况4:主节点处理的请求中跳过了某些从节点轮次下处理过的请求queueOpPacket(Leader.TRUNC, prevProposalZxid);needOpPacket = false;}}// 情况1:当peerLastZxid在迭代范围内出现时,同步过程为:// DIFF+peerLastZxid后的每个包{packet+COMMIT}// 情况2:当peerLastZxid在迭代范围内没出现,且peerLastZxid对应轮次下没事务请求被处理// DIFF+首个大于peerLastZxid及其后的每个包{packet+COMMIT}// 情况3:当peerLastZxid在迭代范围内没出现,从节点处理了某些请求,首个大与peerLastZxid的packetZxid属于后续轮次// 最终将采用快照完成同步阶段// 情况4:当peerLastZxid在迭代范围内没出现,从节点处理了某些请求,首个大与peerLastZxid的packetZxid属于相同轮次// TRUNC{截掉从节点中不在主节点中的请求}+对主节点中大于peerLastZxid的每个包{packet+COMMIT}if (packetZxid <= queuedZxid) {continue;}queuePacket(propose.packet);queueOpPacket(Leader.COMMIT, packetZxid);queuedZxid = packetZxid;}return queuedZxid;}
分析下来结论为:
(1). 情况1:当peerLastZxid在迭代范围内出现
同步策略为:DIFF+peerLastZxid后的每个包{packet+COMMIT}
currentZxid为maxCommittedLog
(2). 情况2:当peerLastZxid在迭代范围内没出现,且peerLastZxid对应轮次下没事务请求被处理
同步策略为:DIFF+首个大于peerLastZxid及其后的每个包{packet+COMMIT}
currentZxid为maxCommittedLog
(3). 情况3:当peerLastZxid在迭代范围内没出现,peerLastZxid所在轮次下从节点处理了某些请求,首个大于peerLastZxid的packetZxid属于后续轮次
同步策略为:采用快照完成同步阶段
currentZxid为peerLastZxid
(4). 情况4:当peerLastZxid在迭代范围内没出现,从节点处理了某些请求,首个大与peerLastZxid的packetZxid属于相同轮次
同步策略为:TRUNC{截掉从节点中不在主节点中的请求}+对主节点中大于peerLastZxid的每个包{packet+COMMIT}
currentZxid为maxCommittedLog
关于queueCommittedProposals的分析:
针对peerLastZxid < minCommittedLog && txnLogSyncEnabled来分析:
此场景可认为是从节点和主节点差的比较多,且指定了在差的达到一定量时优先采用快照来同步。
此情况下,在估算所需redo尺寸达到限制时,hasNext将为false。
此时采用快照来同步,相应的:currentZxid = db.getDataTreeLastProcessedZxid();
估算所需redo尺寸没达到限制时,hasNext将为true:
currentZxid = queueCommittedProposals(txnLogItr, peerLastZxid, minCommittedLog, maxCommittedLog);
// 只有选择快照同步策略下,返回值才会小于minCommittedLog
if (currentZxid < minCommittedLog) {// 此时将采用快照来同步,currentZxid = db.getDataTreeLastProcessedZxid();currentZxid = peerLastZxid;queuedPackets.clear();needOpPacket = true;
} else {// 此时采用DIFF同步,currentZxid = maxCommittedLog;Iterator<Proposal> committedLogItr = db.getCommittedLog().iterator();currentZxid = queueCommittedProposals(committedLogItr, currentZxid, null, maxCommittedLog);needSnap = false;
}
结合前述分析。这里,只有在queueCommittedProposals返回值为peerLastZxid时,会采用快照同步。且此时currentZxid = db.getDataTreeLastProcessedZxid();
其他情况下,将采用DIFF/TRUNC+主节点后续包方式来同步,此时currentZxid = maxCommittedLog;
syncFollower中先是同步,同步后执行:leaderLastZxid = learnerMaster.startForwarding(this, currentZxid);以继续向从节点发一些需要确认的尚未提交的包。
public synchronized long startForwarding(LearnerHandler handler, long lastSeenZxid) {if (lastProposed > lastSeenZxid) {for (Proposal p : toBeApplied) {if (p.packet.getZxid() <= lastSeenZxid) {continue;}// 这里继续向从节点发一些主节点这边需要应用(应用到整个集群)且zxid大于同步后从节点这边zxid的包handler.queuePacket(p.packet);QuorumPacket qp = new QuorumPacket(Leader.COMMIT, p.packet.getZxid(), null, null);handler.queuePacket(qp);}if (handler.getLearnerType() == LearnerType.PARTICIPANT) {// outstandingProposals含义后续分析List<Long> zxids = new ArrayList<Long>(outstandingProposals.keySet());Collections.sort(zxids);for (Long zxid : zxids) {if (zxid <= lastSeenZxid) {continue;}handler.queuePacket(outstandingProposals.get(zxid).packet);}}}if (handler.getLearnerType() == LearnerType.PARTICIPANT) {// 将从节点加入主节点的forwardingFollowers集合addForwardingFollower(handler);// } else {addObserverLearnerHandler(handler);}return lastProposed;
}
前面分析中LearnerHandler这边执行集群同步的三个阶段为:
(1). 与主同步
(2). 继续向从发送主节点这边需要应用的包
(3). 发NEWLEADER包
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER, newLeaderZxid, learnerMaster.getQuorumVerifierBytes(), null);
queuedPackets.add(newLeaderQP);
然后执行:
qp = new QuorumPacket();
ia.readRecord(qp, "packet");
messageTracker.trackReceived(qp.getType());
learnerMaster.waitForNewLeaderAck(getSid(), qp.getZxid());
我们接着分析从节点对集群同步节点收到的这些包的处理。
3.3.从节点对集群同步包的处理
从节点在registerWithLeader后执行的流程为:
// 取得新集群epoch
long newEpoch = ZxidUtils.getEpochFromZxid(newEpochZxid);
if (newEpoch < self.getAcceptedEpoch()) {throw new IOException("Error: Epoch of leader is lower");
}
long startTime = Time.currentElapsedTime();
self.setLeaderAddressAndId(leaderServer.addr, leaderServer.getId());
self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION);
syncWithLeader(newEpochZxid);
self.setZabState(QuorumPeer.ZabState.BROADCAST);
我们分析syncWithLeader
从节点点在syncWithLeader里,依次处理同步,主节点同步后的包,NEWLEADER。
其中处理NewLeader包将向主发一个writePacket(new QuorumPacket(Leader.ACK, newLeaderZxid, null, null), true);
3.4.主节点这边收到Leader.ACK时处理
由于前述可知,主节点这边主节点自己,和负责与从节点通信的LearnerHandler此时均执行waitForNewLeaderAck。
当达到半数以上的Leader.ACK收集而未发生超时时,将一起继续后续动作。
对LearnerHandler为:
learnerMaster.waitForStartup();
queuedPackets.add(new QuorumPacket(Leader.UPTODATE, -1, null, null));
即先等待主节点作为服务端对外提供服务后,再向从节点发送Leader.UPTODATE。
我们继续分析从节点这边收到Leader.UPTODATE的处理:
// 向主节点发送Leader.ACK
QuorumPacket ack = new QuorumPacket(Leader.ACK, 0, null, null);
ack.setZxid(ZxidUtils.makeZxid(newEpoch, 0));
writePacket(ack, true);
// 启动对外服务端
zk.startServing();
// 更新自身选票中集群的epoch
self.updateElectionVote(newEpoch);
if (zk instanceof FollowerZooKeeperServer) {FollowerZooKeeperServer fzk = (FollowerZooKeeperServer) zk;// 对未提交包for (PacketInFlight p : packetsNotCommitted) {fzk.logRequest(p.hdr, p.rec, p.digest);// 日志}for (Long zxid : packetsCommitted) {fzk.commit(zxid);// 提交}
}
此后进入从节点常规运行阶段:
self.setZabState(QuorumPeer.ZabState.BROADCAST);
completedSync = true;
QuorumPacket qp = new QuorumPacket();
while (this.isRunning()) {// 接收来自主节点的包readPacket(qp);// 处理processPacket(qp);
}
3.5.主节点waitForNewLeaderAck的后续处理
startZkServer();// 起点服务端,开启外部服务
if (!System.getProperty("zookeeper.leaderServes", "yes").equals("no")) {self.setZooKeeperServer(zk);
}
self.setZabState(QuorumPeer.ZabState.BROADCAST);
self.adminServer.setZooKeeperServer(zk);
boolean tickSkip = true;
String shutdownMessage = null;
while (true) {synchronized (this) {long start = Time.currentElapsedTime();long cur = start;long end = start + self.tickTime / 2;while (cur < end) {wait(end - cur);cur = Time.currentElapsedTime();}if (!tickSkip) {self.tick.incrementAndGet();}SyncedLearnerTracker syncedAckSet = new SyncedLearnerTracker();syncedAckSet.addQuorumVerifier(self.getQuorumVerifier());syncedAckSet.addAck(self.getId());for (LearnerHandler f : getLearners()) {if (f.synced()) {syncedAckSet.addAck(f.getSid());}}if (!this.isRunning()) {shutdownMessage = "Unexpected internal error";break;}if (!tickSkip && !syncedAckSet.hasAllQuorums() && !(self.getQuorumVerifier().overrideQuorumDecision(getForwardingFollowers()) && self.getQuorumVerifier().revalidateOutstandingProp(this, new ArrayList<>(outstandingProposals.values()), lastCommitted))) {shutdownMessage = "Not sufficient followers synced, only synced with sids: [ " + syncedAckSet.ackSetsToString() + " ]";break;}tickSkip = !tickSkip;}for (LearnerHandler f : getLearners()) {f.ping();}
}
if (shutdownMessage != null) {shutdown(shutdownMessage);
}
上述可认为是集群正常运行中,主节点不断检测各个从节点的连接情况,一旦出现连接人数不足等异常情况。及时停止主节点运行,以便重新选举出合适集群。
相关文章:

zk集群--集群同步
1.概述 前面一章分析了集群下启动阶段选举过程,一旦完成选举,通过执行QuorumPeer的setPeerState将设置好选举结束后自身的状态。然后,将再次执行QuorumPeer的run的新的一轮循环, QuorumPeer的run的每一轮循环,先判断…...

复习面经哦
1.函数可以变量提升 JavaScript 中的函数存在变量提升的概念,这意味着在执行代码之前,函数声明会被提升到其作用域的顶部。这使得你可以在函数声明之前调用函数。然而,这种行为只适用于函数声明,而不是函数表达式。 下面是一些关…...
vector)
c++ STL系列——(二)vector
引言 在现代C编程中,std::vector是最常用的动态数组实现之一,它是C标准模板库(STL)的一部分。vector提供了一种方式,以单一数据结构来存储元素集合,并且可以动态地调整大小以适应新元素。本文将深入探讨ve…...
STM32能够做到数据采集和发送同时进行吗?
STM32能够做到数据采集和发送同时进行吗? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「STM32的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!&am…...

5.Swift常量
Swift 常量 在 Swift 中,除了可以声明变量(使用 var 关键字),还可以声明常量(使用 let 关键字)。常量在赋值后就不能再修改其值,适合用于存储不会改变的数据。以下是关于 Swift 常量的一些重要…...
Linux运行级别 | 管理Linux服务
Linux运行级别 级别: 0关机1单用户2多用户但是不运行nfs网路文件系统3默认的运行级别,给一个黑的屏幕,只能敲命令4未使用5默认的运行级别,图形界面6重启切换运行级别: init x管理Linux服务 systemctl命令…...

Nginx 配置 SSL证书
成功配置SSL证书后,您将能够通过HTTPS加密通道安全访问Nginx服务器。 一、准备材料 SSL证书绑定的域名已完成DNS解析,即您的域名与主机IP地址相互映射。您可以通过DNS验证证书工具,检测域名DNS解析是否生效。具体操作: 【1】登录…...

如何正确理解和获取S参数
S参数是网络参数,定义了反射波和入射波之间的关系,给定频率的S参数矩阵指定端口反射波b的矢量相对于端口入射波a的矢量,如下所示: bS∙a 在此基础上,如下图所示,为一个常见的双端口网络拓扑图:…...

Sping Cloud Hystrix 参数配置、简单使用、DashBoard
Sping Cloud Hystrix 文章目录 Sping Cloud Hystrix一、Hystrix 服务降级二、Hystrix使用示例三、OpenFeign Hystrix四、Hystrix参数HystrixCommand.Setter核心参数Command PropertiesFallback降级配置Circuit Breaker 熔断器配置Metrix 健康统计配置Request Context 相关参数C…...

CSS太极动态图
CSS太极动态图 1. 案例效果 我们今天学习用HTML和CSS实现动态的太极,看一下效果。 2. 分析思路 太极图是由两个旋转的圆组成,一个是黑圆,一个是白圆。实现现原理是使用CSS的动画和渐变背景属性。 首先,为所有元素设置默认值为0…...
TI毫米波雷达开发——High Accuracy Demo 串口数据接收及TLV协议解析 matlab 源码
TI毫米波雷达开发——串口数据接收及TLV协议解析 matlab 源码 前置基础源代码功能说明功能演示视频文件结构01.bin / 02.binParseData.mread_file_and_plot_object_location.mread_serial_port_and_plot_object_location.m函数解析configureSport(comportSnum)readUartCallback…...
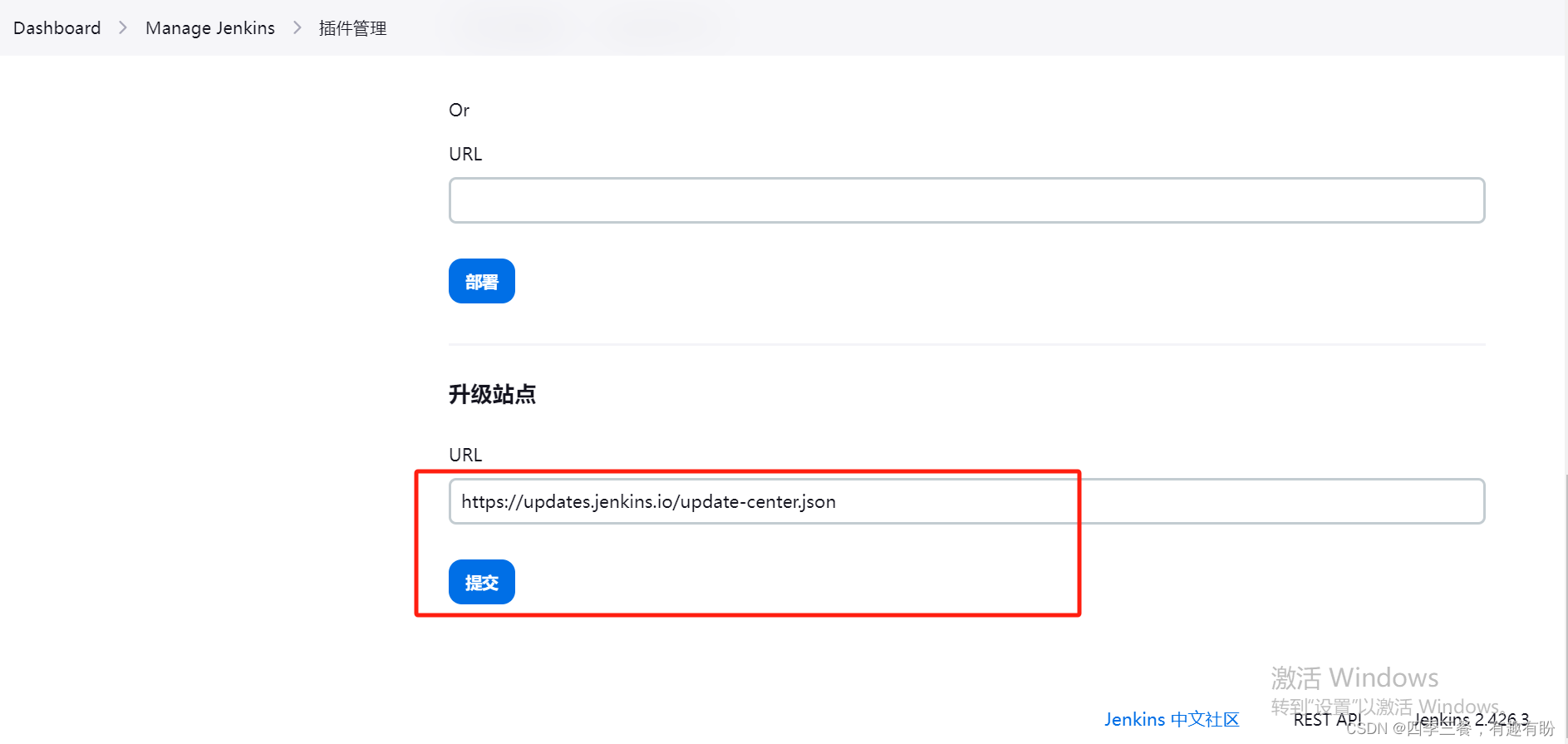
基于tomcat运行jenkins常见的报错处理
目录 1.jenkins.util.SystemProperties$Listener错误 升级jdk11可能遇到的坑 2.java.lang.RuntimeException: Fontconfig head is null, check your fonts or fonts configuration 3.There were errors checking the update sites: UnknownHostException:updates.jenkins.i…...

算法学习——LeetCode力扣二叉树篇1
算法学习——LeetCode力扣二叉树篇1 144. 二叉树的前序遍历 144. 二叉树的前序遍历 - 力扣(LeetCode) 描述 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 示例 1: 输入:root [1,null,2,3] 输出&a…...

二叉树的遍历及创建
typedef char T;struct TreeNode {T _data;TreeNode* left;TreeNode* right; }; 1、二叉树的遍历---DFS 3 5 6 …...
图形学:Transform矩阵(3维 2维) 平移,旋转,缩放
0. 简介 在图形学领域中,Transform矩阵(变换矩阵)是一种表示图形对象在二维或三维空间中的位置、方向和大小变化的数学工具。它们用于执行各种图形变换,如平移、旋转、缩放。Transform矩阵通常表示为一个二维或三维矩阵ÿ…...

Docker学习历程
Docker学习历程 Q1、docker还没启动Q2、Docker容器名称冲突的问题Q3:启动minio时发现,容器已经再重启Q4:容器被占用的情况Q5:查看日志 Q1、docker还没启动 docker run --env MODEstandalone --name nacos --restartalways -d -p …...

Android:Volley框架使用
3.15 Volley框架使用 Volley框架主要作为网络请求,图片加载工具。当应用数据量小、网络请求频繁,可以使用Volley框架。 框架Github地址:https://github.com/google/volley Volley框架的简单使用,创建项目Pro_VolleyDemo。将Github上下载Volley框架源代码,volley-master.zi…...
)
前端修炼手册(uniapp的api篇)
一、页面相关API uni.navigateTo 该API用于跳转到应用内的某个页面,可以传递参数。 uni.navigateTo({url: /pages/detail/detail?id1 })uni.redirectTo 该API用于关闭当前页面并跳转到应用内的某个页面,可以传递参数。 uni.redirectTo({url: /pages/…...

JAVA面试题16
什么是Java中的反射机制?它的用途是什么? 答案:Java的反射机制是指在运行时,通过获取类的信息来操作类的属性、方法和构造函数等。它可以用来创建对象、调用方法,以及实现动态代理等功能。 什么是Java中的泛型&#x…...

P1044 [NOIP2003 普及组] 栈题解
题目 有一个单端封闭的管子,将N(1<N<18)个不同的小球按顺序放入管子的一端。在将小球放入管子的过程中也可以将管子最顶上的一个或者多个小球倒出来。请问:倒出来的方法总数有多少种? 输入输出格式 输入格式 输入文件只含一个整数n…...

AI迈向“自动驾驶”,零售回归“人间清醒”:2026商业底层逻辑正在重组
导读:2026年的初夏,商业世界正处在一个奇妙的交汇点。一边是AI编程正式宣告进入“无人驾驶”时代,生产力工具迎来质变;另一边,零售巨头们在狂热中开始自省,重新审视效率与人性的边界。从阿里、腾讯的智能体…...

在Node.js后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken实现稳定高效的多模型调用 对于需要构建AI功能的后端开发者而言,直接对接多个模型厂商…...

从GLIBCXX_3.4.29缺失到系统库兼容性:一次深度排错与修复实践
1. 当你的程序突然罢工:GLIBCXX_3.4.29缺失的背后故事 那天我正在部署一个机器学习模型服务,突然终端弹出鲜红的报错:"libstdc.so.6: version GLIBCXX_3.4.29 not found"。这个错误看似简单,却让我花了整整一个下午才彻…...

taotoken的token plan套餐为团队开发带来的成本可控体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 Token Plan 套餐为团队开发带来的成本可控体验 在团队开发环境中,频繁调用大模型 API 已成为提升研发效率…...

手把手拆解FD-SOI工艺流程:从SOI衬底到应变硅外延的保姆级图解
从SOI衬底到应变硅外延:FD-SOI工艺全流程拆解指南 想象一下建造一座微型城市,每一栋建筑只有头发丝直径的万分之一大小。这就是FD-SOI工艺工程师的日常工作——在硅片上用原子级精度"建造"晶体管。与传统的体硅工艺不同,FD-SOI&…...

从Windows迁移者的视角:中兴新支点NewStartOS上手初体验与软件兼容性实测
从Windows迁移者的视角:中兴新支点NewStartOS上手初体验与软件兼容性实测 作为一名长期使用Windows系统的普通用户,第一次接触国产操作系统时难免会有诸多疑虑:界面是否熟悉?常用软件能否运行?外设驱动是否完善&#…...
第2小节:国内外技术参数差距)
0502光刻机破局 第五卷:EUV光源系统(S级 长期死磕突破)第2小节:国内外技术参数差距
第五卷:EUV光源系统(S级 长期死磕突破) 第2小节:国内外技术参数差距(全量化对标,ASML vs 国产,死磕数据) 前置硬核声明 本节100%量化、100%对标、100%无修饰,直接把 ASML…...

XXMI-Launcher:多游戏Mod管理平台的终极指南
XXMI-Launcher:多游戏Mod管理平台的终极指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI-Launcher是一款专为热门游戏设计的Mod管理平台,支持《原…...

思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析
思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版烦恼吗?字体选择困…...

Kali Linux 保姆级教程|从入门到渗透测试,一篇封神!
前言 Kali Linux 作为网络安全领域的「瑞士军刀」,集成 600 专业渗透工具,覆盖信息收集、漏洞利用、权限维持等全流程。本文结合最新实战场景,整理系统学习路径、核心工具解析及资源获取方式,助你快速掌握这门渗透测试必备技能。…...